【数据湖JindoFS+OSS 实操干货36讲】第7/8讲
分享
点赞
0
收藏
0
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
概念简述
JindoFS 作为阿里云基于 OSS 的一揽子数据湖存储优化方案,完全兼容 Hadoop/Spark 生态,并针对 Spark、Hive、Flink、Presto 等大数据组件和 AI 生态实现了大量扩展和优化。
JindoFS 项目包括 JindoFS OSS 支持、JindoFS 分布式缓存系统(JindoFS Cache 模式)和 JindoFS 分布式存储优化系统(JindoFS Block 模式)。
JindoSDK 是各个计算组件可以用来使用JindoFS 这些优化扩展功能和模式的套件,包括 Hadoop Java SDK、Python SDK 和 Fuse/POSIX 支持。JindoSDK 在阿里云 E-MapReduce 产品中被深度集成,同时也开放给非 EMR 产品用户在各种 Hadoop/Spark 环境上使用。
GitHub 地址:
https://github.com/aliyun/alibabacloud-jindofs
课程背景
为了让更多开发者了解并使用 JindoFS,由阿里云 JindoFS+OSS 团队打造的专业公开课【数据湖 JindoFS+OSS 实操干货36讲】会在每周二16:00准时开讲!从五大板块入手,玩转数据湖!
本期主题:
1、Flink 高效 sink 写入 OSS
2、Flume 高效写入 OSS
主讲人:
重湖-阿里巴巴计算平台事业部 EMR 高级工程师
焱冰-阿里巴巴计算平台事业部 EMR技术专家
展开查看详情
1 . | E-MapReduce | 对象存储OSS
数据湖 JindoFS + OSS 实操36讲
【OSS 访问加速】 Flink 高效 sink 写入 OSS
演讲人:重湖
阿里巴巴计算平台事业部 EMR 高级工程师
2021.06.02
�
2 . 背景介绍
功能介绍
CONTENT
如何配置
如何使用
�
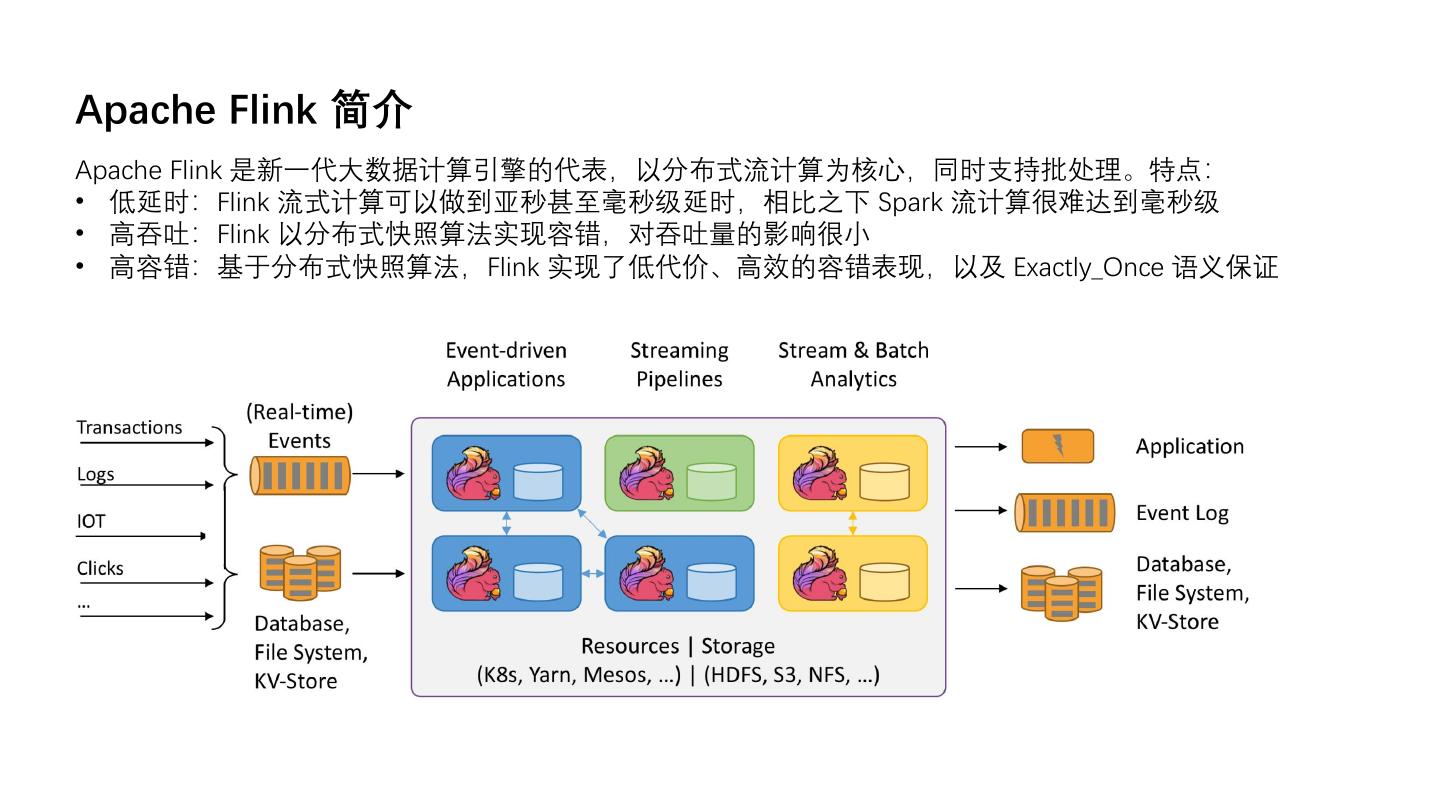
3 .Apache Flink 简介
Apache Flink 是新一代大数据计算引擎的代表,以分布式流计算为核心,同时支持批处理。特点:
• 低延时:Flink 流式计算可以做到亚秒甚至毫秒级延时,相比之下 Spark 流计算很难达到毫秒级
• 高吞吐:Flink 以分布式快照算法实现容错,对吞吐量的影响很小
• 高容错:基于分布式快照算法,Flink 实现了低代价、高效的容错表现,以及 Exactly_Once 语义保证
�
4 .JindoFS Flink Connector 产生背景
阿里云对象存储 Object Storage Service (OSS):
• 海量:无限容量,弹性伸缩
• 安全:12个9的数据安全性,多种加密方式
• 低成本:远低于云磁盘,且有多种存储方式、生命周期管理等节约成本
• 高可靠:服务可用性 99.9%
• 已服务于海量用户
Flink 应用广泛:
• 流计算领域业内主要解决方案
• Apache 基金会最活跃项目之一
• 未来:流批一体、在线分析
Flink 使用痛点:
• 开源 Apache Flink 尚不支持直接写入 OSS
• Hadoop OSS SDK 写入性能不一定满足需求
�
5 .JindoFS Flink Connector 介绍
整体架构:
• 两阶段 Checkpoint (检查点) 机制:
• 第一阶段 MPU (MultiPartUpload,分片上传) 写入 OSS
• 第二阶段 MPU 提交
• Recoverable Writer 可恢复性写入:
• 临时文件以普通文件格式上传 OSS
• Sink 节点状态快照
�
6 .JindoFS Flink Connector 介绍
写入 OSS vs. 写入亚马逊 S3:
• Native 实现:数据写入以 C++ 代码实现,相比 Java 更高效
• 高速读写:多线程读写临时文件,对大于 1MB 的文件优势尤其明显
• 数据缓存:读写 OSS 实现本地缓存,加速外部访问
OSS 访问加速,JindoFS 提供新支持
�
7 .如何配置 JindoFS Flink Connector
环境要求:
• 集群上有开源版本 Flink 软件,版本不低于 1.10.1
SDK 配置:
• 下载所需 SDK 文件:
• jindo-flink-sink-${version}.jar
• jindofs-sdk-${version}.jar
• 下载链接 (Github):
• https://github.com/aliyun/alibabacloud-jindofs/blob/master/docs/jindofs_sdk_download.md
• 将两个 jar 放置于集群 Flink 目录下 lib 文件夹
• Flink 根目录通常可由 $FLINK_HOME 环境变量获取
• 集群所有节点均需配置
Java SPI:自动加载资源,无需额外配置
文档链接 (Github):
• https://github.com/aliyun/alibabacloud-jindofs/blob/master/docs/flink/jindofs_sdk_on_flink_for_oss.md
�
8 .在程序中使用 JindoFS Flink Connector
确保集群能够访问 OSS Bucket
• 前提:已购买 OSS 产品,OSS 网站链接:https://www.aliyun.com/product/oss
• 确保能够访问 OSS Bucket,例如正确配置密钥或免密服务等
使用合适的路径,流式写入 OSS Bucket
• 写入 OSS 须使用 oss:// 前缀路径,类似于:oss://<user-bucket>/<user-defined-sink-dir>
�
9 .在程序中使用 JindoFS Flink Connector:Java
在程序中开启 Flink Checkpoint
• 前提:使用可重发的数据源,如 Kafka
• 通过 StreamExecutionEnvironment 对象打开 Checkpoint (示例):
• 建立:StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
• 打开:env.enableCheckpointing(<userDefinedCheckpointInterval>, CheckpointingMode.EXACTLY_ONCE);
示例程序
• 下文中,outputStream 是一个预先形成的 DataStream<String> 对象,若需写入 OSS,则可以这样添加 sink:
String outputPath = "oss://<user-bucket>/<user-defined-sink-dir>";
StreamingFileSink<String> sink = StreamingFileSink.forRowFormat(
new Path(outputPath),
new SimpleStringEncoder<String>("UTF-8")
).build();
outputStream.addSink(sink);
• 上述程序指定将 outputStream 中的 String 内容写入 OSS 路径 oss://<user-bucket>/<user-defined-sink-dir>,
最后还需用 env.execute() 语句执行 Flink 作业,env 是已建立的 StreamExecutionEnvironment 对象
• 最后,将 Java 作业打包为 jar 文件,并用 flink run 在集群提交即可
�
10 .在程序中使用 JindoFS Flink Connector:Pyflink
与 Java 示例类似,在 Pyflink 中使用 JindoFS Flink Connector 与写入 HDFS 等其他介质方式相同,只需:
• 将写入路径写作合适的 OSS 路径
• 注意打开 Checkpoint 功能
例如,下列 Python 程序定义了一张位于 OSS 的表:
sink_dest = "oss://<user-bucket>/<user-defined-sink-dir>"
sink_ddl = f"""
CREATE TABLE mySink (
uid INT,
pid INT
) PARTITIONED BY (
pid
) WITH (
'connector' = 'filesystem',
'fpath' = '{sink_dest}',
'format' = 'csv',
'sink.rolling-policy.file-size' = '2MB',
'sink.partition-commit.policy.kind' = 'success-file'
)
"""
然后将其添加到 StreamTableEnvironment t_env 中即可:t_env.sql_update(sink_ddl)
�
11 .在程序中使用 JindoFS Flink Connector:更多配置
用户通过 flink run 提交 java 或 pyflink 程序时,可以额外自定义一些参数,格式:
flink run -m yarn-cluster -yD key1=value1 -yD key2=value2 ...
目前支持“熵注入”及“分片上传并行度”两项配置
熵注入 (entropy injection):
• 功能:将写入路径的一段特定字符串匹配出来,用一段随机的字符串进行替换
• 效果:削弱所谓 “片区” (sharding) 效应,提高写入效率
• 配置参数:
oss.entropy.key=<user-defined-key>
oss.entropy.length=<user-defined-length>
分片上传并行度
• 配置参数:oss.upload.max.concurrent.uploads
• 默认值:当前可用的处理器数量
�