

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
E-MapReduce产品探秘,快速构建可扩展的高性能大数据平台
分享
点赞
6
收藏
2
7月3日【E-MapReduce产品探秘,快速构建可扩展的高性能大数据平台】
讲师:夏立,花名雷飙,阿里巴巴计算平台EMR高级产品专家,2014年开始接触大数据,历经阿里内部的大数据发展,目前在阿里云上负责开源的大数据平台EMR产品,构建云上的开源生态。
直播介绍:E-MapReduce整体介绍。通过EMR如何构建一个云上的大数据集群,常见的使用场景和硬件选型指南。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .E-MapReduce(EMR)产品系列讲座 云智能-EMR 雷飙
2 . 产品介绍 架构选型 CONTENT 产品实践
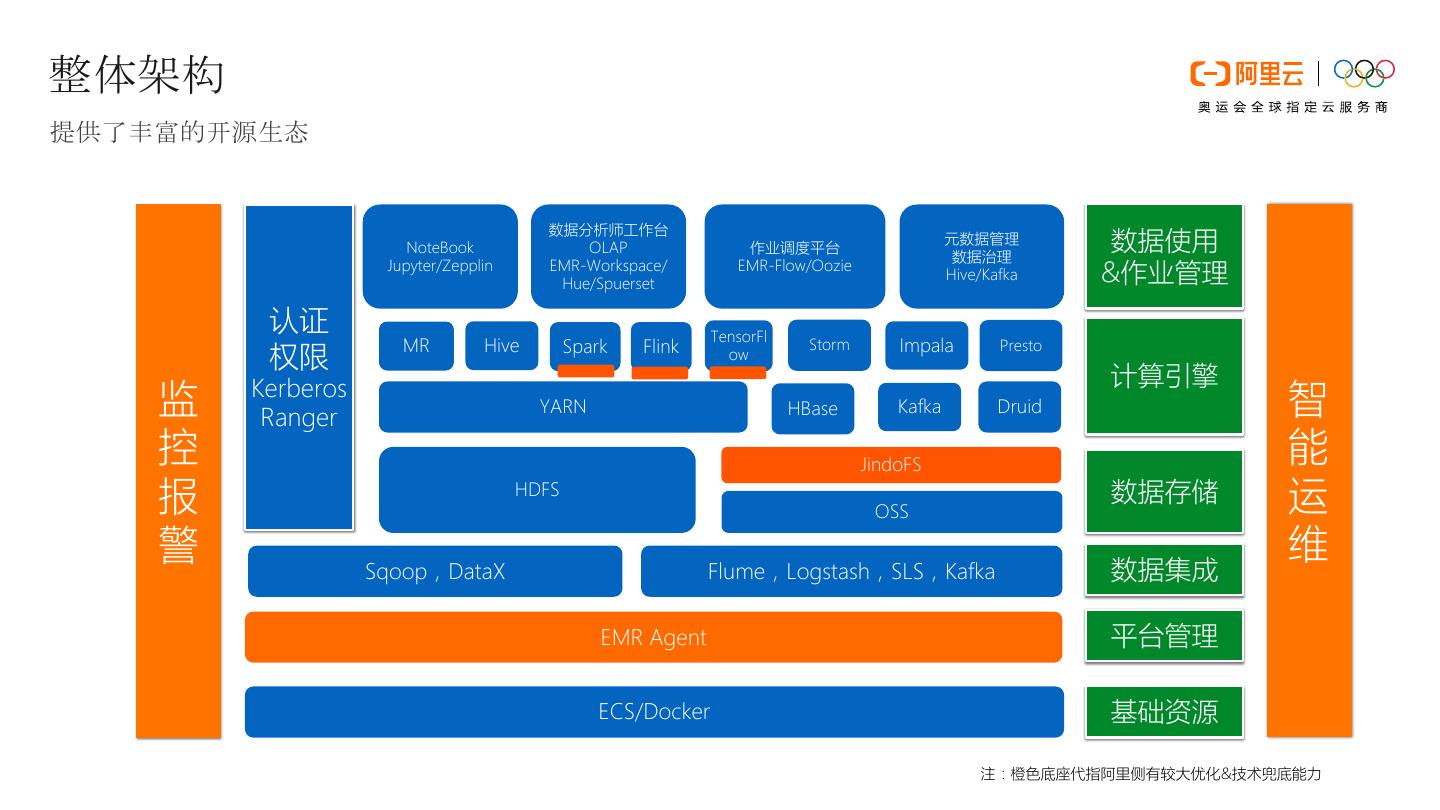
3 .整体架构 提供了丰富的开源生态 数据分析师工作台 NoteBook OLAP 作业调度平台 元数据管理 数据治理 数据使用 Jupyter/Zepplin EMR-Workspace/ Hue/Spuerset EMR-Flow/Oozie Hive/Kafka &作业管理 认证 TensorFl MR Hive Spark Flink Storm Impala Presto 权限 ow 计算引擎 监 Kerberos Ranger YARN HBase Kafka Druid 智 控 JindoFS 能 报 HDFS OSS 数据存储 运 警 维 Sqoop,DataX Flume,Logstash,SLS,Kafka 数据集成 EMR Agent 平台管理 ECS/Docker 基础资源 注:橙色底座代指阿里侧有较大优化&技术兜底能力
4 .E-MapReduce开源大数据平台 Ø 管理运维能力 • 集群管理,作业管理和调度 • 操作Web化、SDK&API Ø 完全兼容开源系统,并在之基础上强化 • Hadoop, Spark性能优化 • 监控能力能整合强化 开源 企业级 Ø 伴随社区发展的生态 • 组件跟随开源社区保持版本升级 Hadoop 大数据 • 开源与阿里云平台的联结者,充分发挥云的生态能力 生态 平台 • 云产品对接(OSS,SLS,MaxCompute等) • 云能力对接,弹性等等(本地盘实例严格打散,弹性伸缩 能力,支持竞价实例) Ø 全球部署(全球15个region部署),基于企业级开源大数据生 态上多样化场景方案的快速复制 Ø 提供完整的企业级的一体化平台 • 打包计算平台能力 • 开箱即用的体验
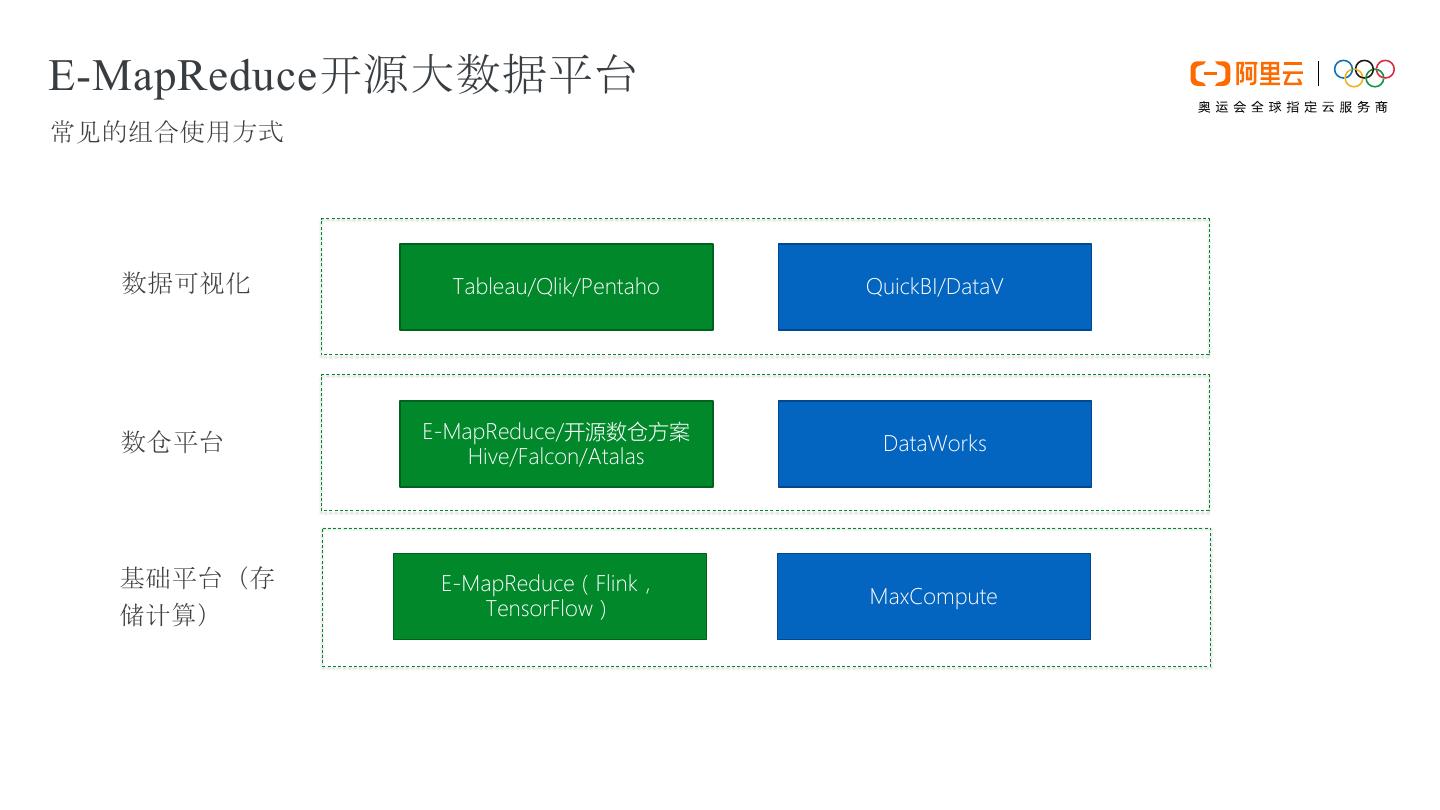
5 .E-MapReduce开源大数据平台 常见的组合使用方式 数据可视化 Tableau/Qlik/Pentaho QuickBI/DataV E-MapReduce/开源数仓方案 数仓平台 DataWorks Hive/Falcon/Atalas 基础平台(存 E-MapReduce(Flink, MaxCompute 储计算) TensorFlow)
6 .E-MapReduce开源大数据平台 Ø 通用Hadoop • 开源大数据离线、实时、Ad-hoc查询场景 • 基于开源Hadoop生态,采用YARN管理集群资源,提供Hive、Spark离线大规模分布式数据存储和计算, SparkStreaming、Flink、Storm流式数据计算,Presto、Impala交互式查询,Oozie、Pig等Hadoop生态圈的组 件,支持OSS存储,支持Kerberos的数据认证与加密。 Ø Kafka • 开源高吞吐量,可扩展性的消息系统 • E-MapReduce Kafka提供一套完整的服务监控体系和元数据管理。广泛用于日志收集、监控数据聚合等场 景,支持离线或流式数据处理、实时数据分析等。 Ø DataScience • 大数据+AI场景 • Data Science针对大数据+AI场景,提供了Hive、Spark离线大数据ETL,TensorFlow模型训练,用户可以选 择CPU+GPU的异构计算框架,利用英伟达GPU对部分深度学习算法就行高性能计算。 Ø Druid • 实时交互式分析服务场景 • Druid提供了大数据查询毫秒级延迟,支持多种数据摄入方式。可与E-MapReduce Hadoop、E-MapReduce Spark、阿里云OSS、阿里云RDS等服务搭配组合使用,构建灵活稳健的实时查询解决方案。 Ø Zookeeper • 分布式锁 • 适用于大规模的Hadoop集群、HBase集群、Kafka集群独立的分布式一致性锁服务。
7 .E-MapReduce开源大数据平台 半托管模式 EMR集群 用户侧 用户可以基于平 ECS节点 ECS节点 台做上层的开发 日志收集 服务守护 指标采集 日志收集 服务守护 指标采集 适合大客户和需 求灵活的用户 EMR产品侧 云资源 报警 调度管理 巡检 智能诊断 管理 EMR管控服务
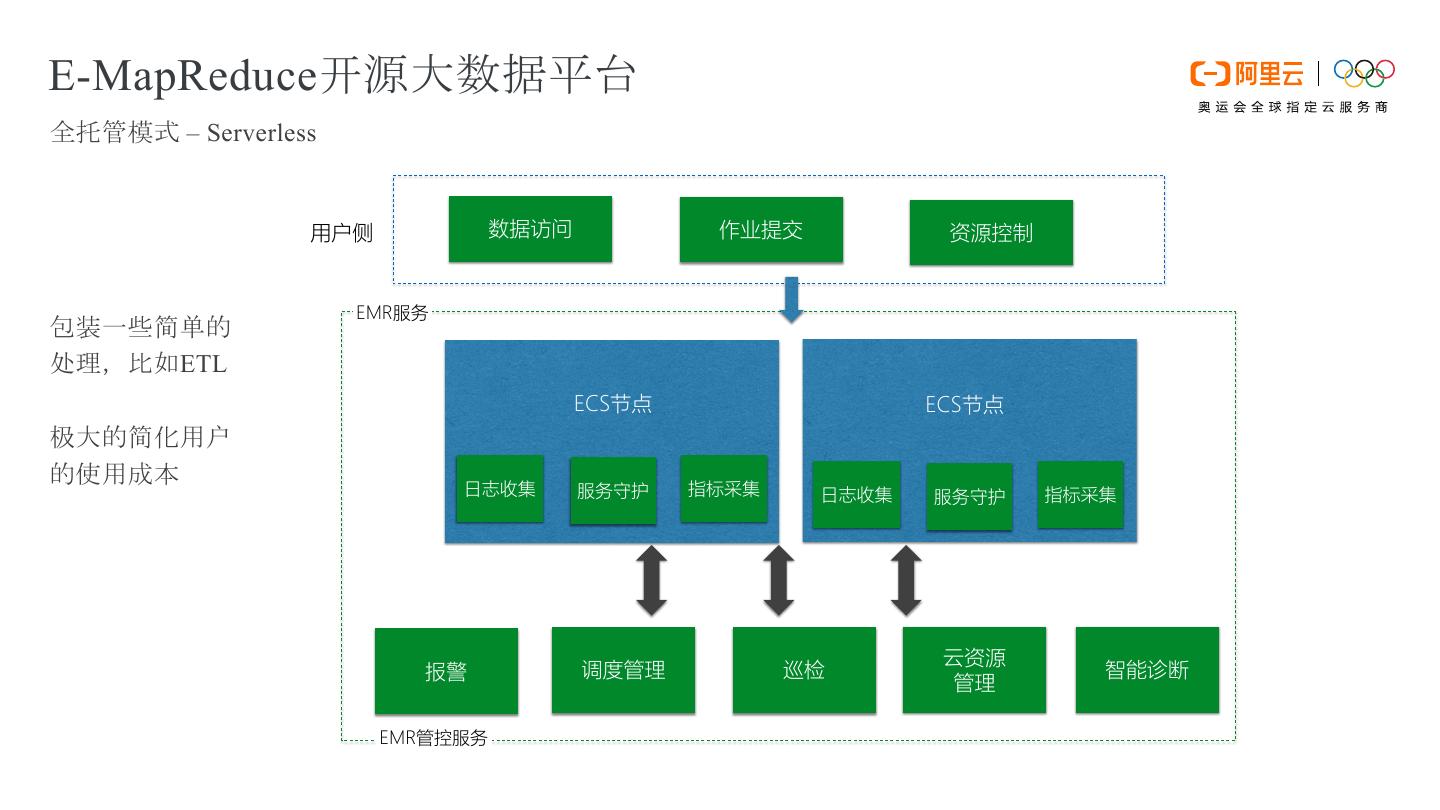
8 .E-MapReduce开源大数据平台 全托管模式 – Serverless 用户侧 数据访问 作业提交 资源控制 EMR服务 包装一些简单的 处理,比如ETL ECS节点 ECS节点 极大的简化用户 的使用成本 日志收集 指标采集 服务守护 日志收集 服务守护 指标采集 云资源 报警 调度管理 巡检 智能诊断 管理 EMR管控服务
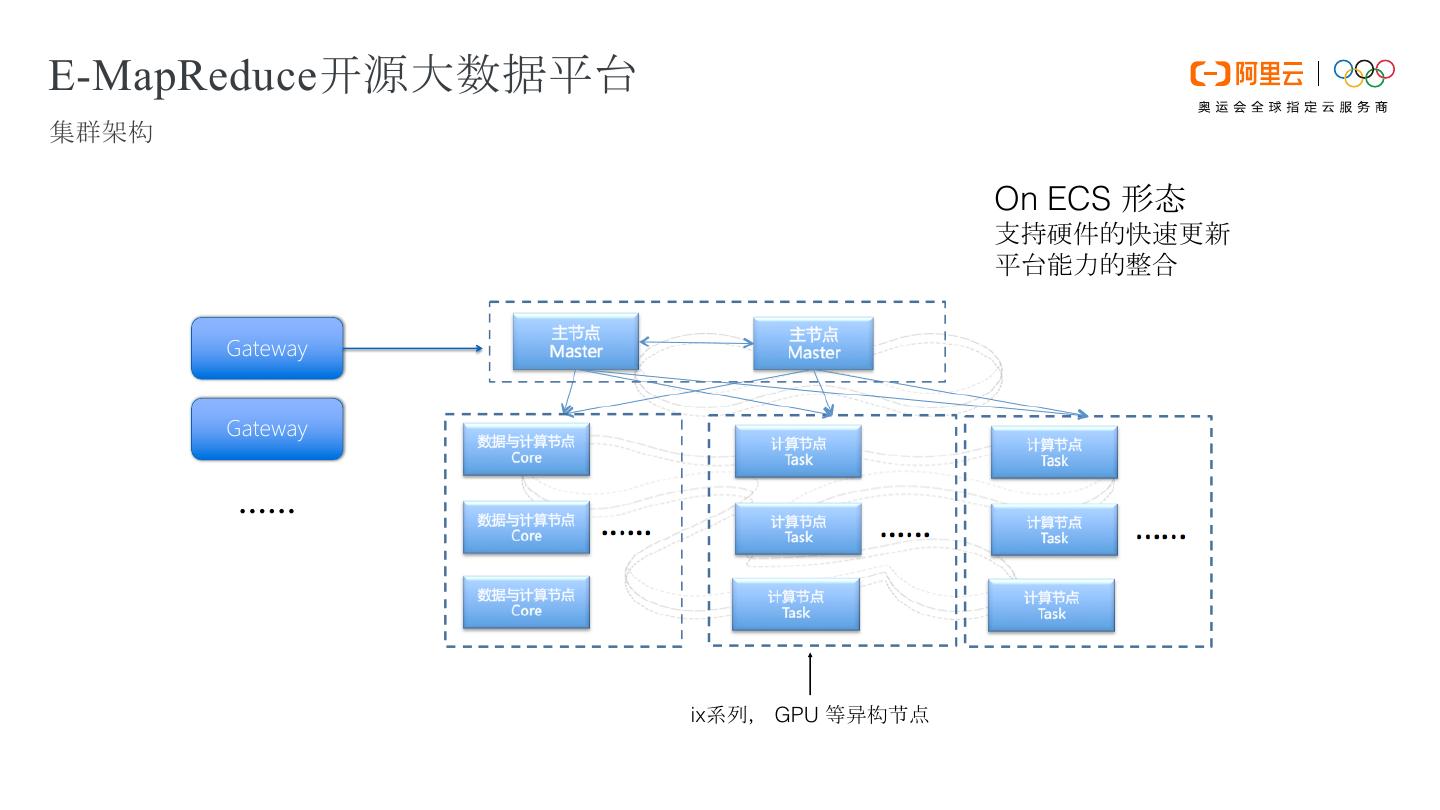
9 .E-MapReduce开源大数据平台 集群架构 On ECS 形态 支持硬件的快速更新 平台能力的整合 Gateway Gateway …… ix系列, GPU 等异构节点
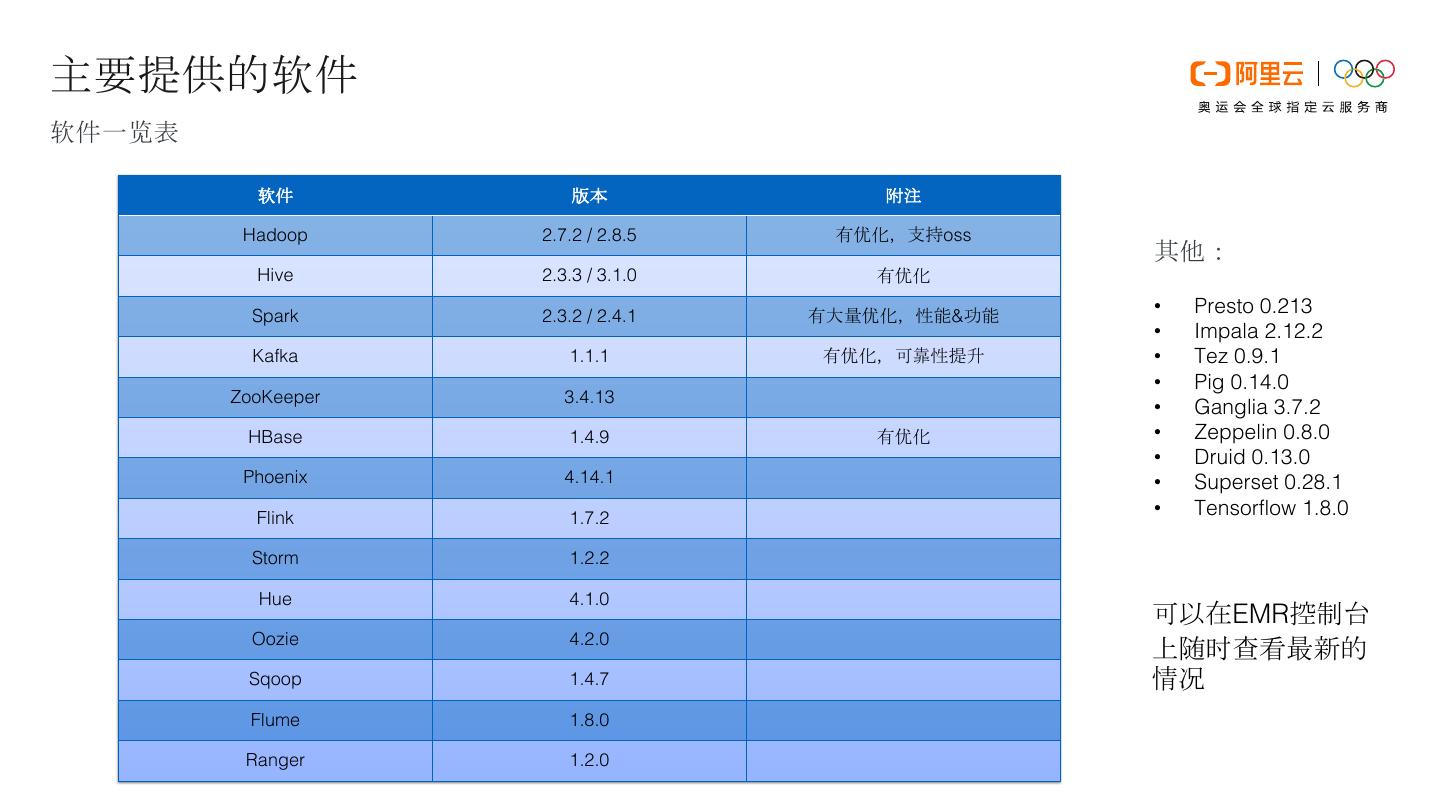
10 .主要提供的软件 软件一览表 软件 版本 附注 Hadoop 2.7.2 / 2.8.5 有优化,支持oss 其他: Hive 2.3.3 / 3.1.0 有优化 Spark 2.3.2 / 2.4.1 有大量优化,性能&功能 • Presto 0.213 • Impala 2.12.2 Kafka 1.1.1 有优化,可靠性提升 • Tez 0.9.1 • Pig 0.14.0 ZooKeeper 3.4.13 • Ganglia 3.7.2 HBase 1.4.9 有优化 • Zeppelin 0.8.0 • Druid 0.13.0 Phoenix 4.14.1 • Superset 0.28.1 Flink 1.7.2 • Tensorflow 1.8.0 Storm 1.2.2 Hue 4.1.0 可以在EMR控制台 Oozie 4.2.0 上随时查看最新的 Sqoop 1.4.7 情况 Flume 1.8.0 Ranger 1.2.0
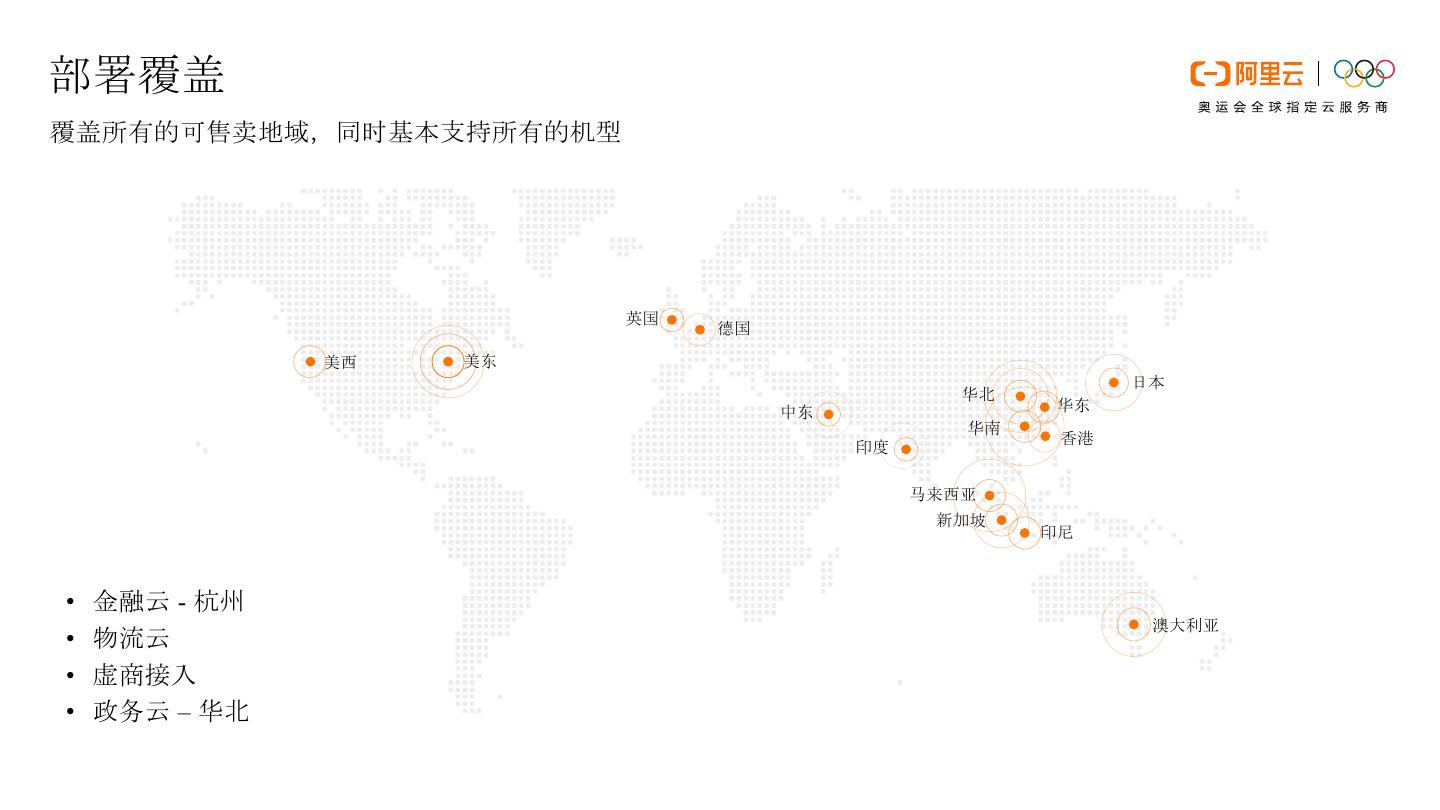
11 .部署覆盖 覆盖所有的可售卖地域,同时基本支持所有的机型 英国 德国 美西 美东 日本 华北 中东 华东 华南 香港 印度 马来西亚 新加坡 印尼 • 金融云 - 杭州 澳大利亚 • 物流云 • 虚商接入 • 政务云 – 华北
12 .产品功能点
13 .E-MapReduce产品功能点 可视化集群管理控制台
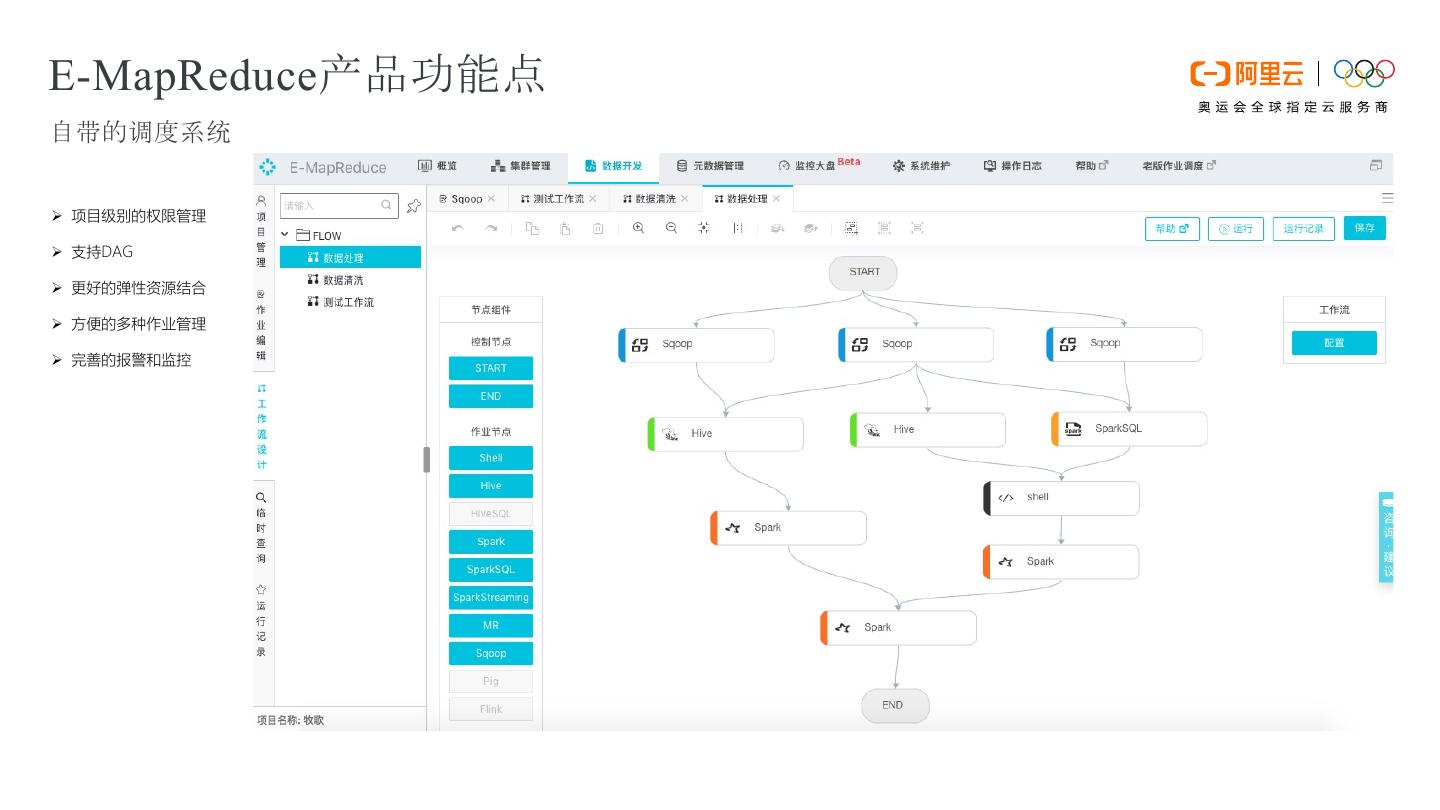
14 .E-MapReduce产品功能点 自带的调度系统 Ø 项目级别的权限管理 Ø 支持DAG Ø 更好的弹性资源结合 Ø 方便的多种作业管理 Ø 完善的报警和监控
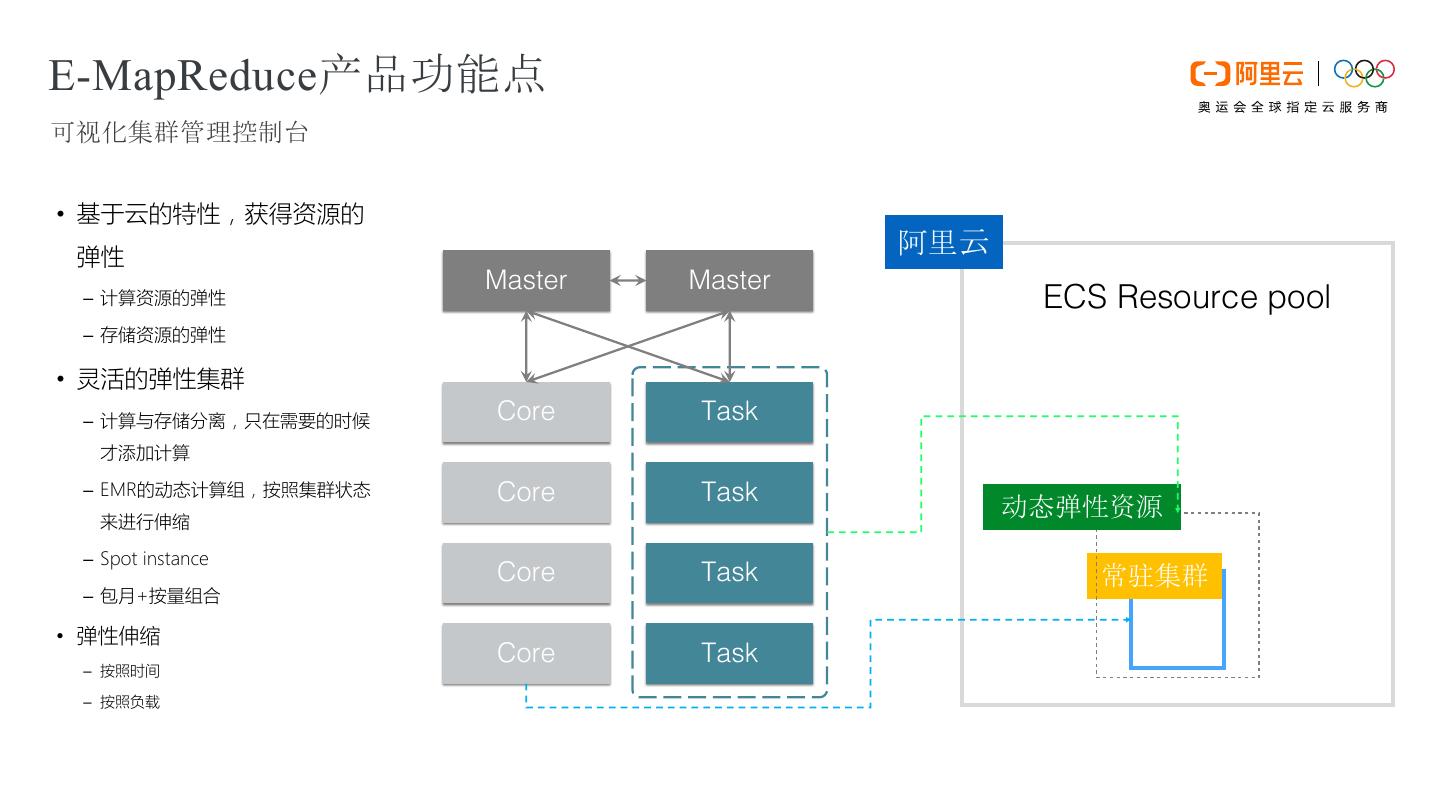
15 .E-MapReduce产品功能点 可视化集群管理控制台 • 基于云的特性,获得资源的 Active Standby 弹性 阿里云 Master Master – 计算资源的弹性 ECS Resource pool – 存储资源的弹性 • 灵活的弹性集群 – 计算与存储分离,只在需要的时候 Core Task 才添加计算 – EMR的动态计算组,按照集群状态 Core Task 来进行伸缩 动态弹性资源 – Spot instance Core Task 常驻集群 – 包月+按量组合 • 弹性伸缩 Core Task – 按照时间 – 按照负载 计算和存储节点 计算节点
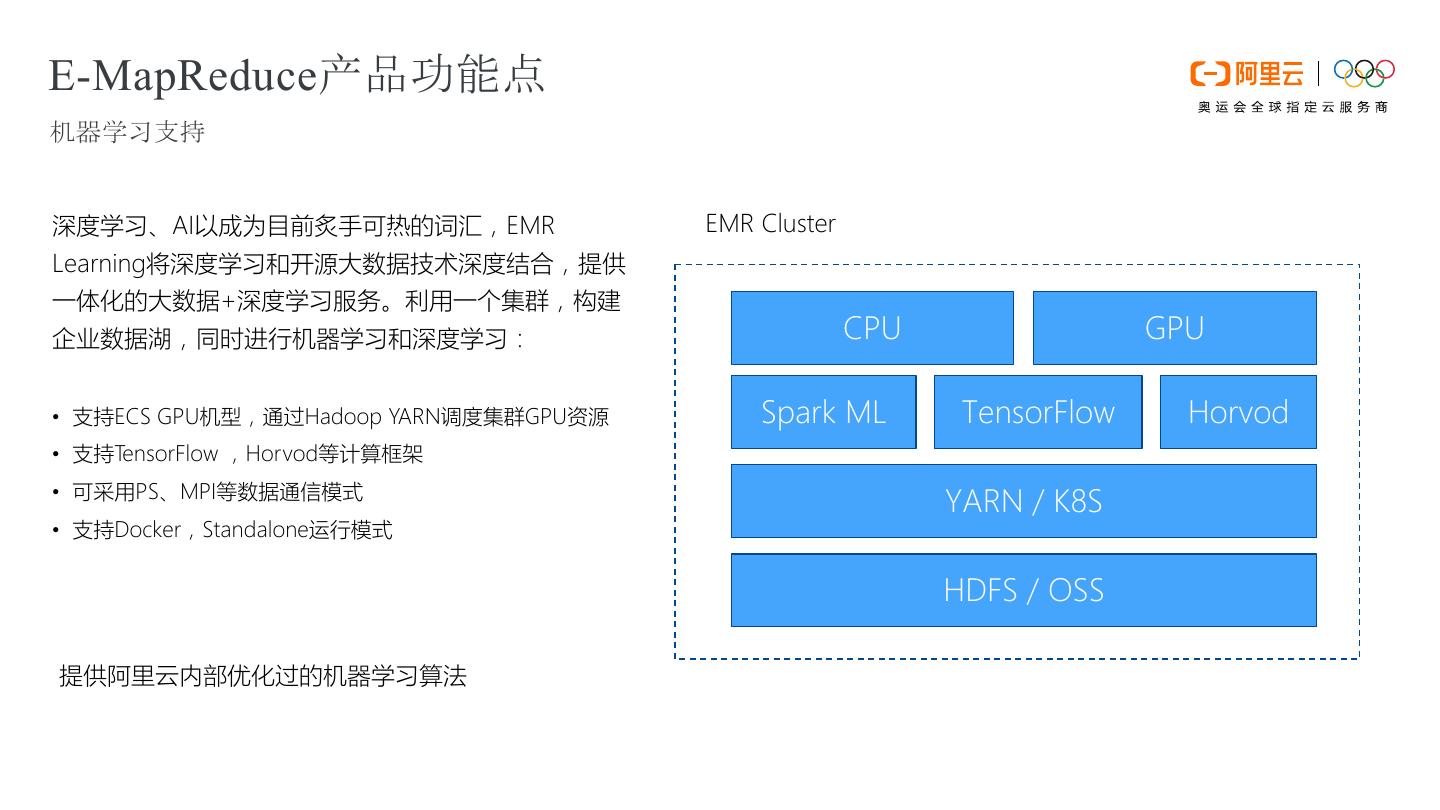
16 .E-MapReduce产品功能点 机器学习支持 深度学习、AI以成为目前炙手可热的词汇,EMR EMR Cluster Learning将深度学习和开源大数据技术深度结合,提供 一体化的大数据+深度学习服务。利用一个集群,构建 企业数据湖,同时进行机器学习和深度学习: CPU GPU • 支持ECS GPU机型,通过Hadoop YARN调度集群GPU资源 Spark ML TensorFlow Horvod • 支持TensorFlow ,Horvod等计算框架 • 可采用PS、MPI等数据通信模式 YARN / K8S • 支持Docker,Standalone运行模式 HDFS / OSS 提供阿里云内部优化过的机器学习算法
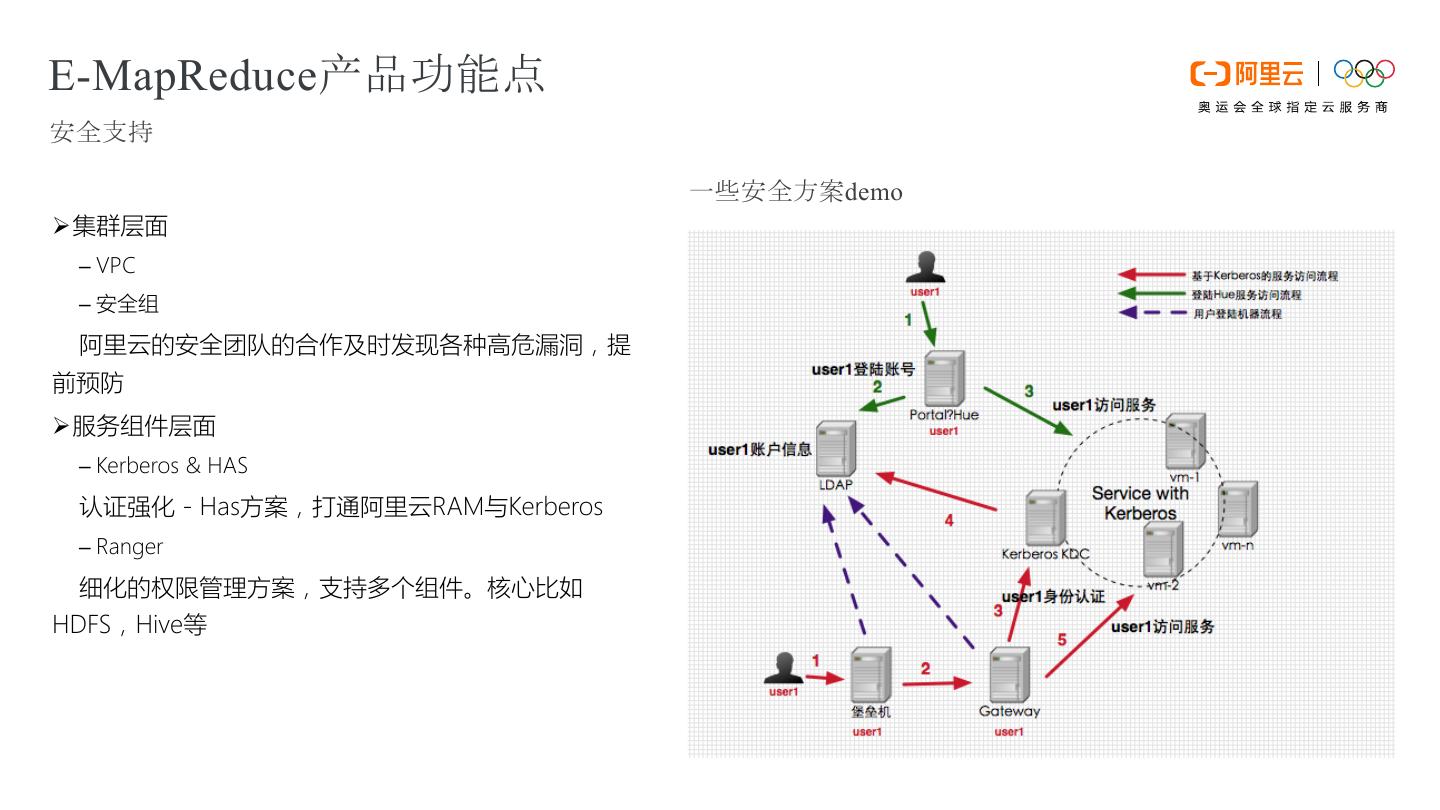
17 .E-MapReduce产品功能点 安全支持 一些安全方案demo Ø集群层面 – VPC – 安全组 阿里云的安全团队的合作及时发现各种高危漏洞,提 前预防 Ø服务组件层面 – Kerberos & HAS 认证强化 - Has方案,打通阿里云RAM与Kerberos – Ranger 细化的权限管理方案,支持多个组件。核心比如 HDFS,Hive等
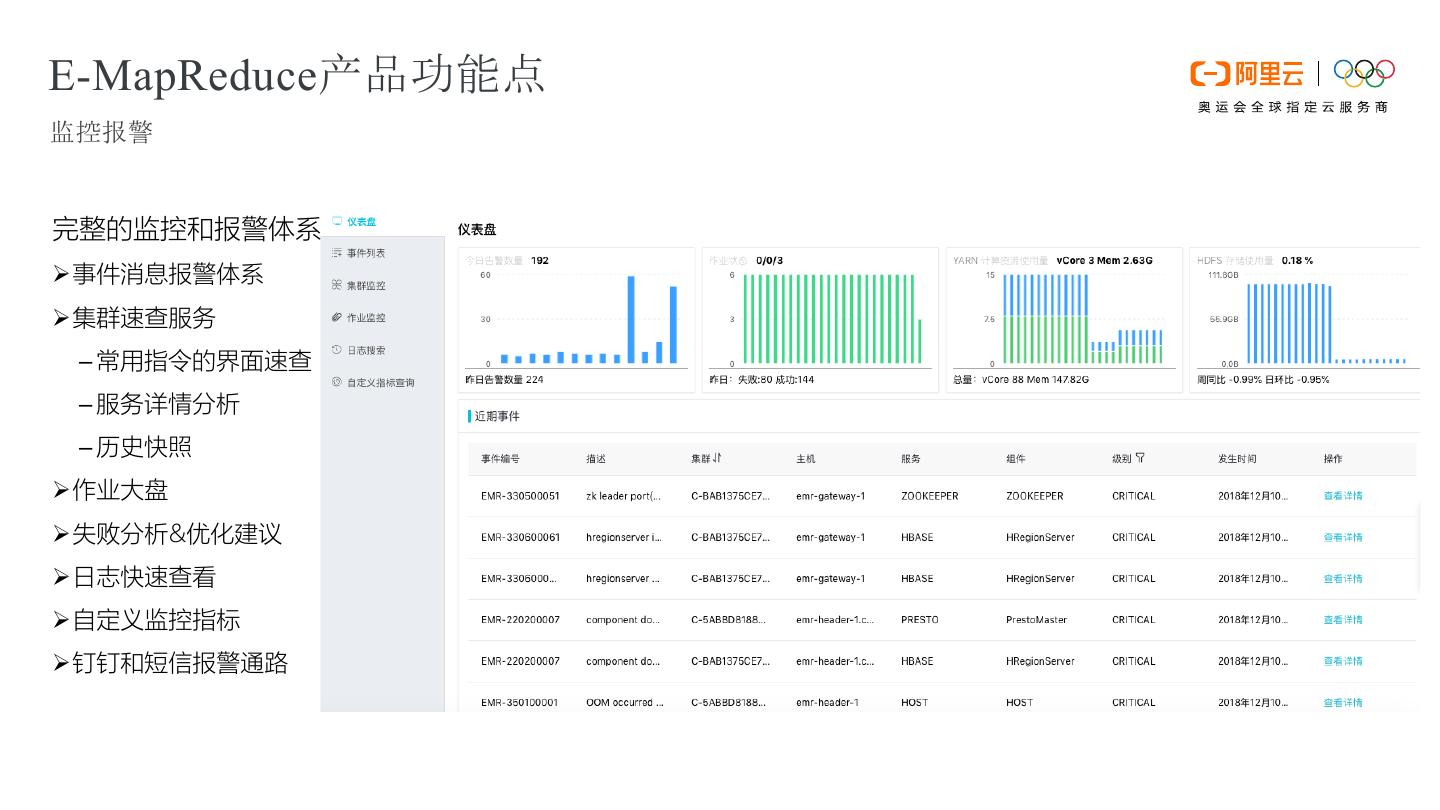
18 .E-MapReduce产品功能点 监控报警 完整的监控和报警体系 Ø事件消息报警体系 Ø集群速查服务 – 常用指令的界面速查 – 服务详情分析 – 历史快照 Ø作业大盘 Ø失败分析&优化建议 Ø日志快速查看 Ø自定义监控指标 Ø钉钉和短信报警通路
19 .E-MapReduce产品功能点 技术优势 Ø 产品性能优化 • Adaptive Execution • Spark shuffle service • Relational cache • Spark Streaming SQL • more
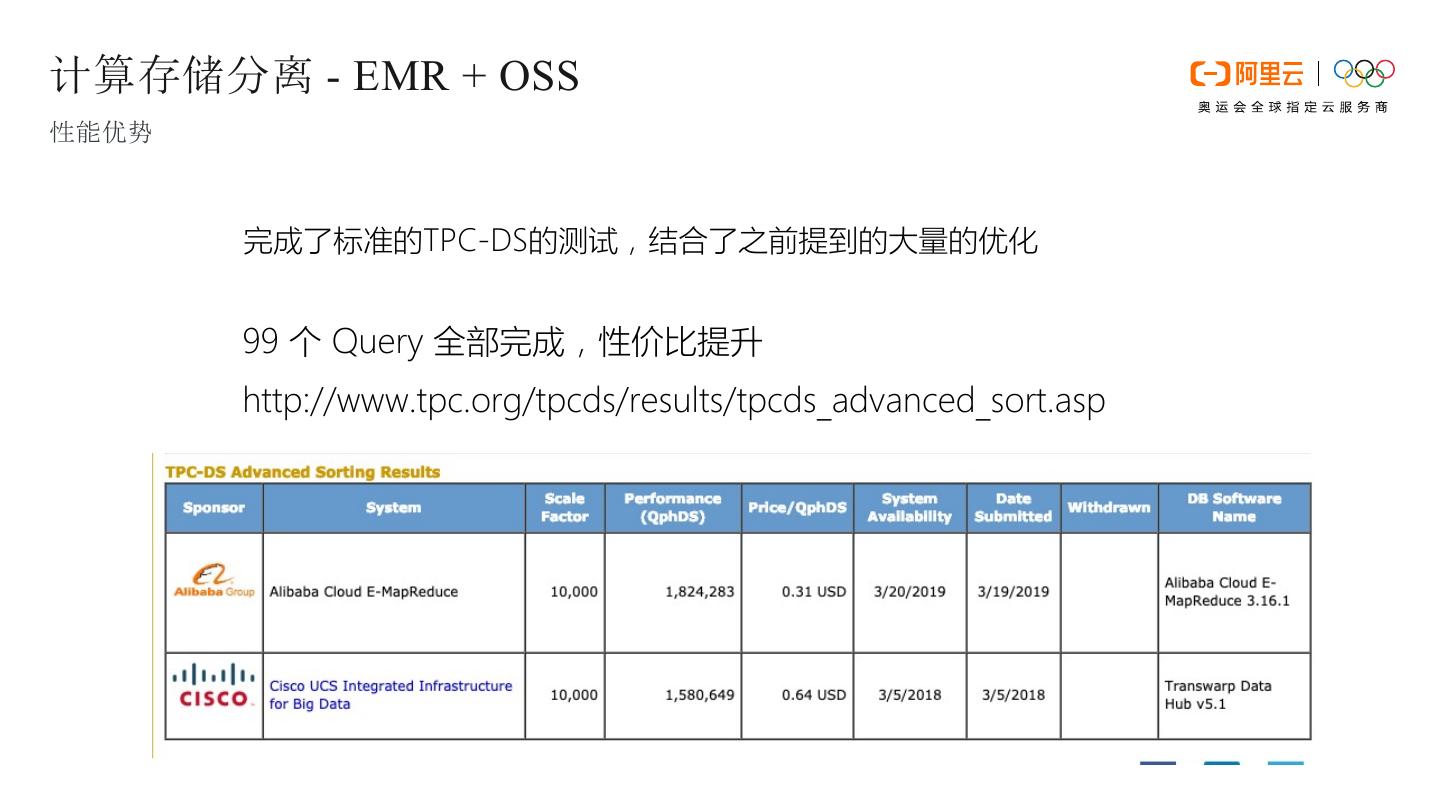
20 .产品对比概述 CDH,HDP等是现在比较流行的Hadoop的环境搭建工具,使用阿里云EMR主要有以下的优势 • 云上的弹性 • EMR可以使用动态的task节点,按需快速的临时增减节点,不需要复杂的购买配置等过程。比如临时增加100cpu400GB内存的计算能力协助 离线任务,完成以后,释放增加的这些资源。 • 部署的可靠性 • EMR会合理的选用IaaS层的部署位置,预先保证用户的集群能够高可用。并在意外出现的时候提供云上的宕机迁移,快速恢复等能力。 • 部署的性能优势 • EMR非常清楚在云上的Iaas层如何对应Hadoop的拓扑,以获得最佳的性能。并会进行对应的动态调整。 • EMR提供SDK的方式,可以将流程集成到用户系统流程中 • 对OSS的原生的集成 • EMR提供了OSS的原生集成,自动临时Ak访问。性能比Hadoop 3.0的好 30%以上 • 调度体系 • 提供了一套拖拽式的DAG作业调度系统,支持自动重试,流式作业监控等等,可以比Oozie更好的进行作业调度 • 技术支持 • 工单系统,规范的售后支持流程,快速的响应支持 • CDH,HDP一般技术团队都在国外,国内都是销售团队,深度一点的技术问题的支持不及时,沟通较低效 劣势 • 基础的运维平台的完备性 • 组件的兼容性测试 • 权限、 组件之间的关联功能点等 • 软件本身的技术优势
21 . 产品介绍 架构选型 CONTENT 产品实践
22 .E-MapReduce架构选型 我是谁? 机型怎么选? 我从哪里来? 存储怎么选? 我要到哪里去? 技术方案怎么选?
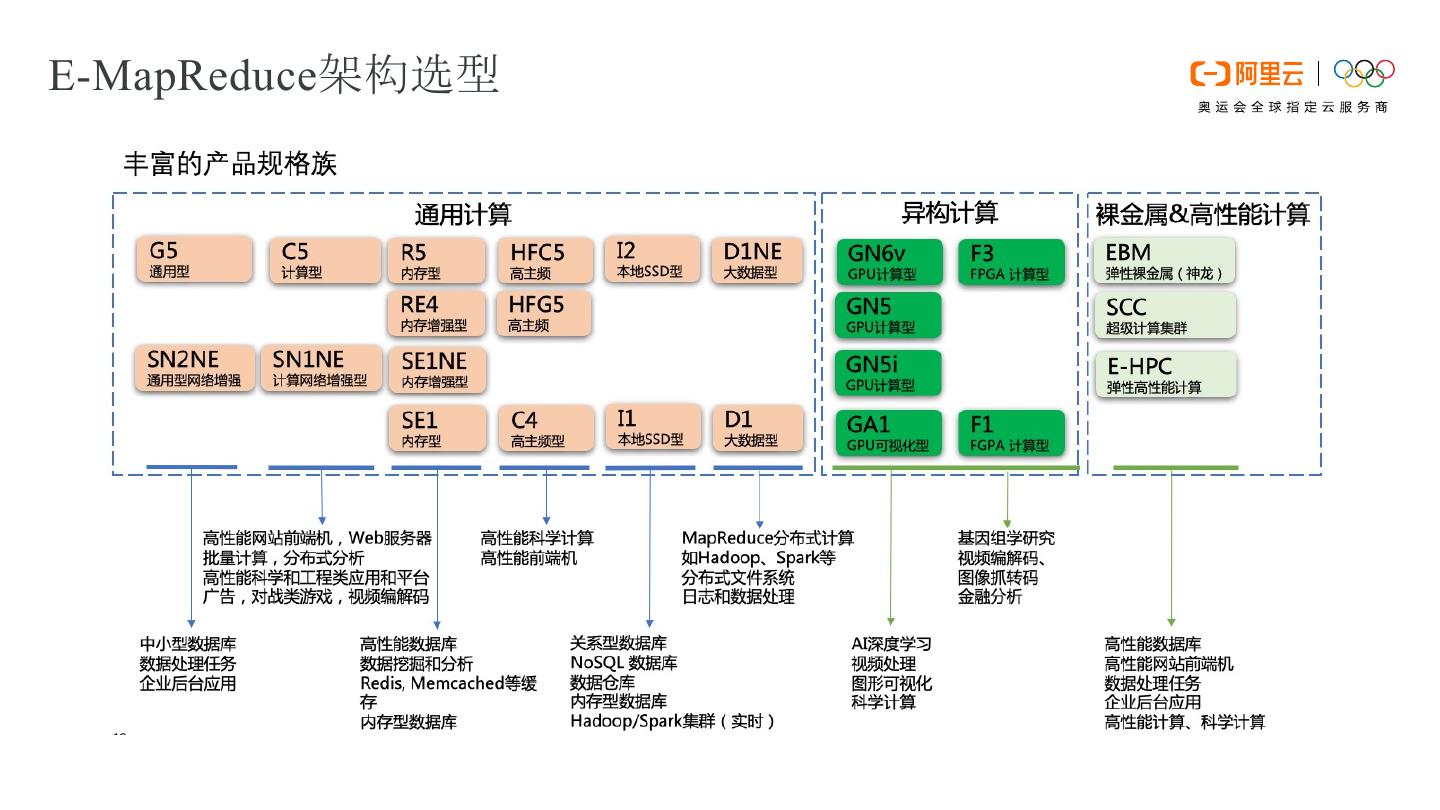
23 .E-MapReduce架构选型
24 .E-MapReduce架构选型 集群架构 使用private zone做所有节点的域名解析 Gateway Gateway …… ix系列, GPU 等异构节点
25 .E-MapReduce架构选型 Ø Master 主实例 •适合通用型或内存型实例,数据直接使用阿里云的云盘来保存,有三个备份的保证,数据高可靠。 Ø Core 核心实例 •小数据量(TB 级别以下)或者是使用 OSS 作为主要的数据存储时、可以使用通用型、计算型或内存 型。当数据量较大时(10 TB 或以上),推荐使用大数据机型,以获得极高的性价比。当 Core 核心实例 使用本地盘时,数据可靠性得不到保证,会由 EMR 平台来进行维护和保证。 Ø Task 计算实例 •作为集群的计算能力的补充,可以使用除大数据型以外的所有的机型。目前本地 SSD 型尚未支持,后续 会加入到 Task 中。 Ø Gateway实例 • 选择范围很大,没有特别的约束,推荐使用云盘。
26 .E-MapReduce架构选型 NameNode 配置评估: 依据是集群中的目录&文件的数量(Directories & Files)和数据块(Block)数量。HeapSize 推荐值是, NameNode 固定内存用量不宜超过 HeapSize 的60%。根据经验,NameNode 固定内存用量可以通过以 下公式预估: NameNode 固定内存用量 = 目录及文件数量 * 198 字节 + 数据块数量 * 176 字节 假如,HDFS 中文件数是1亿1千万,Block 数量是1亿2千万,NameNode 的固定内存用量大约为 110M * 198B + 120M * 176B ~= 21G + 20G ~= 41G,推荐 HeapSize 内存分配是 41G / 60% = 68G 以上 另外,HeapSize 不足除了会导致业务峰值时出现多次 GC 外,也会对NameNode 启动有所影响。因为 NameNode 启动时会加载 fsimage 和处理 DataNode 的 HeartBeat ,需要创建大量对象,Heap 不足也 会频繁 GC,造成启动较慢。 https://www.atatech.org/articles/114656
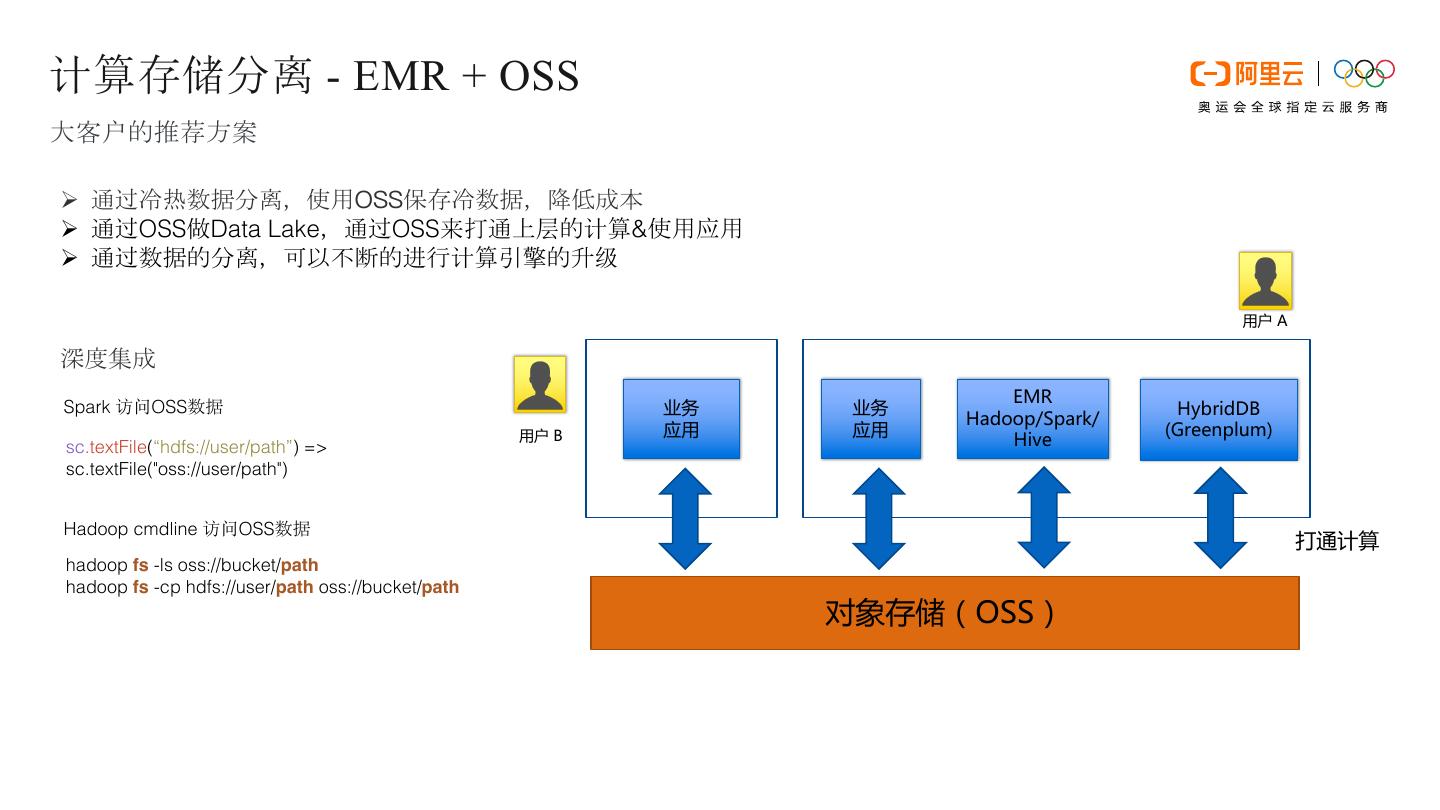
27 .E-MapReduce存储选型 Ø 云盘与本地盘 有两种类型的磁盘可以用作数据的存储:云盘 包括 SSD 云盘、高效云盘、普通云盘。 特点是,磁盘并不直接挂载在本地的计算节点上,通过网络访问远端的一个存储节点。每一份数据在 后端都有两个实时备份,一共三份数据。所以当一份数据损坏的时候(磁盘损坏,不是用户自己的业务上 的破坏),会自动的使用备份数据恢复。 本地盘 包括大数据型的 SATA 本地盘,和本地 SSD 盘。 直接挂载在计算节点上的磁盘,拥有超过云盘的性能表现。使用本地盘的时候不能选择数量,只能使 用默认配置好的数量,和线下物理机一样,数据没有后端的备份机制,需要上层的软件来保证数据可靠 性。 适用的场景 在 EMR 中,所有云盘和本地盘都会在节点释放的时候清除数据,磁盘无法独立的保存下来,并再次 使用。Hadoop HDFS 会使用所有的数据盘作为数据存储。 Hadoop YARN 也会使用所有的数据盘作为计 算的临时存储。 当业务数据量并不太大(TB 级别以下)的时候,可以使用云盘,IOPS 和吞吐相比本地盘都会小些。 数据量大的时候,推荐都使用本地盘,EMR 会来维护本地盘的数据可靠性。如果发现在使用中明显的吞 吐量不够用,可以切换到本地盘的存储上。 Ø OSS 在 EMR 中可以将 OSS 作为 HDFS 使用。 用户可以非常方便的读写 OSS,所有使用 HDFS 的代码也 可以简单的修改就能访问 OSS 上的数据。
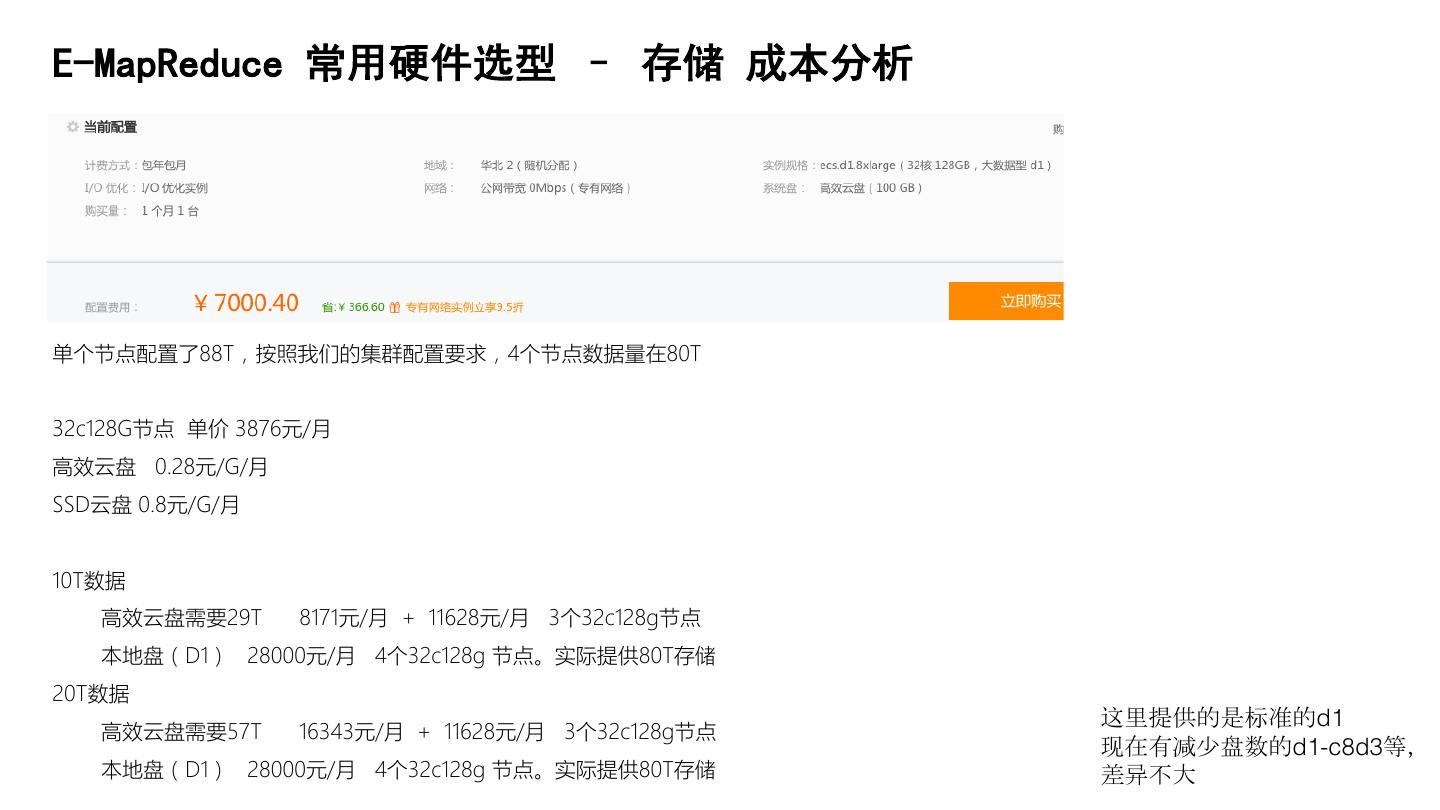
28 .E-MapReduce 常用硬件选型 – 存储 成本分析 单个节点配置了88T,按照我们的集群配置要求,4个节点数据量在80T 32c128G节点 单价 3876元/月 高效云盘 0.28元/G/月 SSD云盘 0.8元/G/月 10T数据 高效云盘需要29T 8171元/月 + 11628元/月 3个32c128g节点 本地盘(D1) 28000元/月 4个32c128g 节点。实际提供80T存储 20T数据 这里提供的是标准的d1 高效云盘需要57T 16343元/月 + 11628元/月 3个32c128g节点 现在有减少盘数的d1-c8d3等, 本地盘(D1) 28000元/月 4个32c128g 节点。实际提供80T存储 差异不大
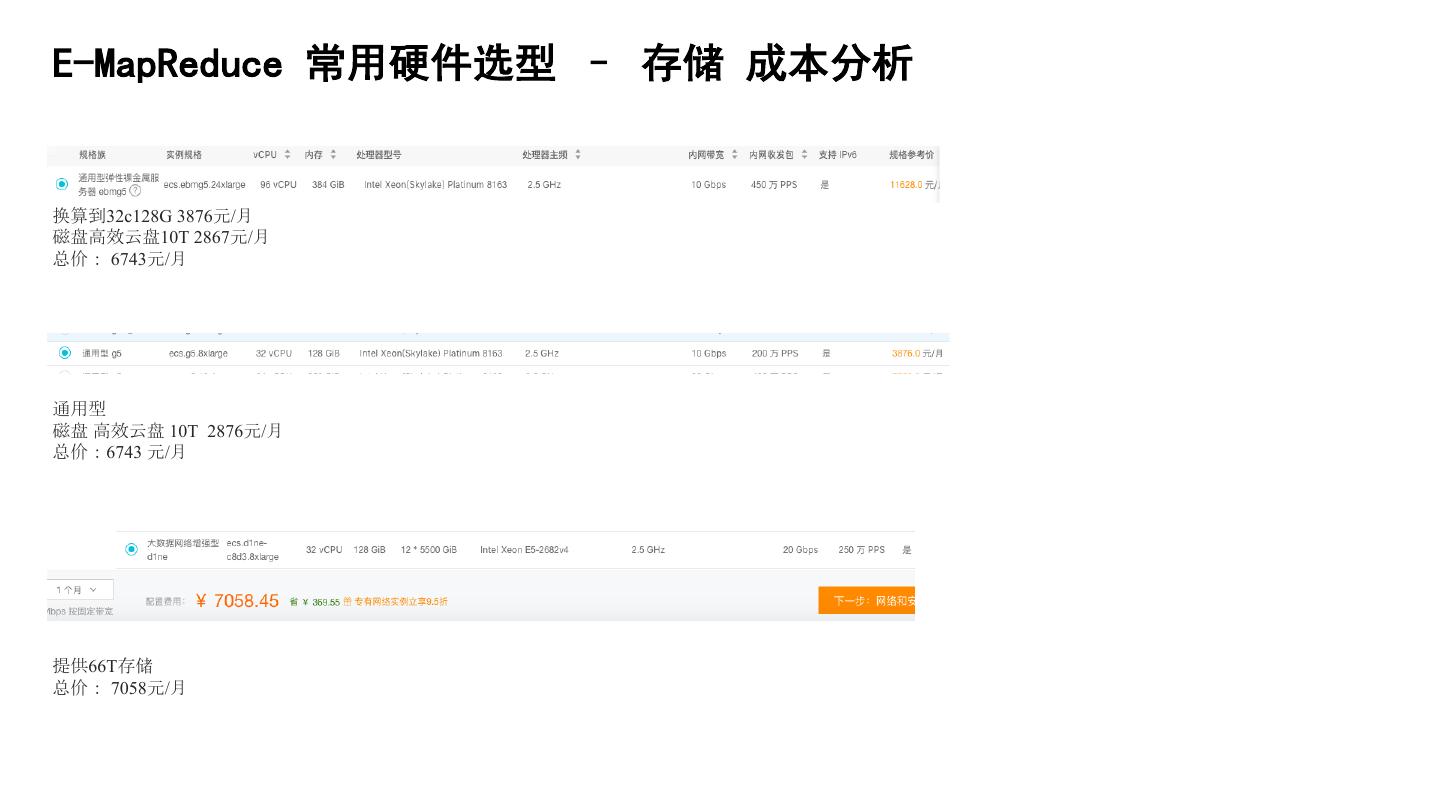
29 .E-MapReduce 常用硬件选型 – 存储 成本分析 换算到32c128G 3876元/月 磁盘高效云盘10T 2867元/月 总价: 6743元/月 通用型 磁盘 高效云盘 10T 2876元/月 总价:6743 元/月 提供66T存储 总价: 7058元/月
6点赞
2收藏
3秒后跳转登录页面
去登陆

