

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
利用E-MapReduce构建云上数据湖
分享
点赞
3
收藏
0
分享嘉宾:E-MapReduce产品经理子关(花名),
简介:介绍如何在云上使用E-MapReduce来快速构建企业数据湖的落地方案、客户的最佳实践,
希望给大家在云上构建数据湖带来一些新的思路。

展开查看详情
1 .使用E-MapReduce构建云上数据湖 王晓平(子关) E-MapReduce 产品经理
2 . 飞天大数据图谱 飞天大数据平台 飞天AI平台PAI 全域数据综合开发治理平台 DataWorks PAI-EAS 开发平台 统一元数据中心、统一开发平台、全域数据分析、资产管理 模型在线预测服务 异构硬件的模型加载 大规模复杂模型的一键部署 数据总线 实时计算/流计算 交互式分析 图计算 搜索推荐 PAI AutoLearning 自动学习,零门槛使用 Elasticsearch 迁移学习框架 分布式全文搜索引擎 降本提升原生性能 DataHub RealTimeCompute Interactive Analytics GraphCompute 日志检索分析 PAI Studio 流式数据 (Flink) 可视化机器学习实验开发环境 PB级数据秒级 一站式图数据管理和 引擎 发布/订阅/分发, 分析引擎 OpenSearch 丰富的算法组件 查询响应, 持续不断的采集, 基于开源Flink优化 实时离线联邦查询, 超大规模和弹性扩展 分布式内容搜索引擎 自动调参引擎内置 存储和处理 支持SQL&机器学习 无缝对接大数据平台 高性能低延时 阿里NLP智能分词 轻量化容器部署 支持点查询、即席查询和 查询分析一体化 OLAP查询等 AIRec PAI DSW 深度优化的Tensorflow框架 全托管推荐引擎服务 Notebook交互式云端建模 全链路智能推荐 开源框架自由安装 MaxCompute E-MapReduce PAI-Alink 计算平台 智能云数仓,从GB到EB级数据计算,大数据&AI一体化 自研开源机器学习算法组件 基于开源体系构建,与生态无缝对接, 云弹性计算,降本增效 跨域联合计算 FlinkML内核 智能运维 飞天大数据统一管控平台 Apsara Big Data Manager 基础组件管控、运维服务管理、运维场景管理 自研产品 开源产品
3 . 01 数据湖介绍 Contents 目录 02 EMR数据湖方案 03 客户实践案例
4 .数据湖介绍 01
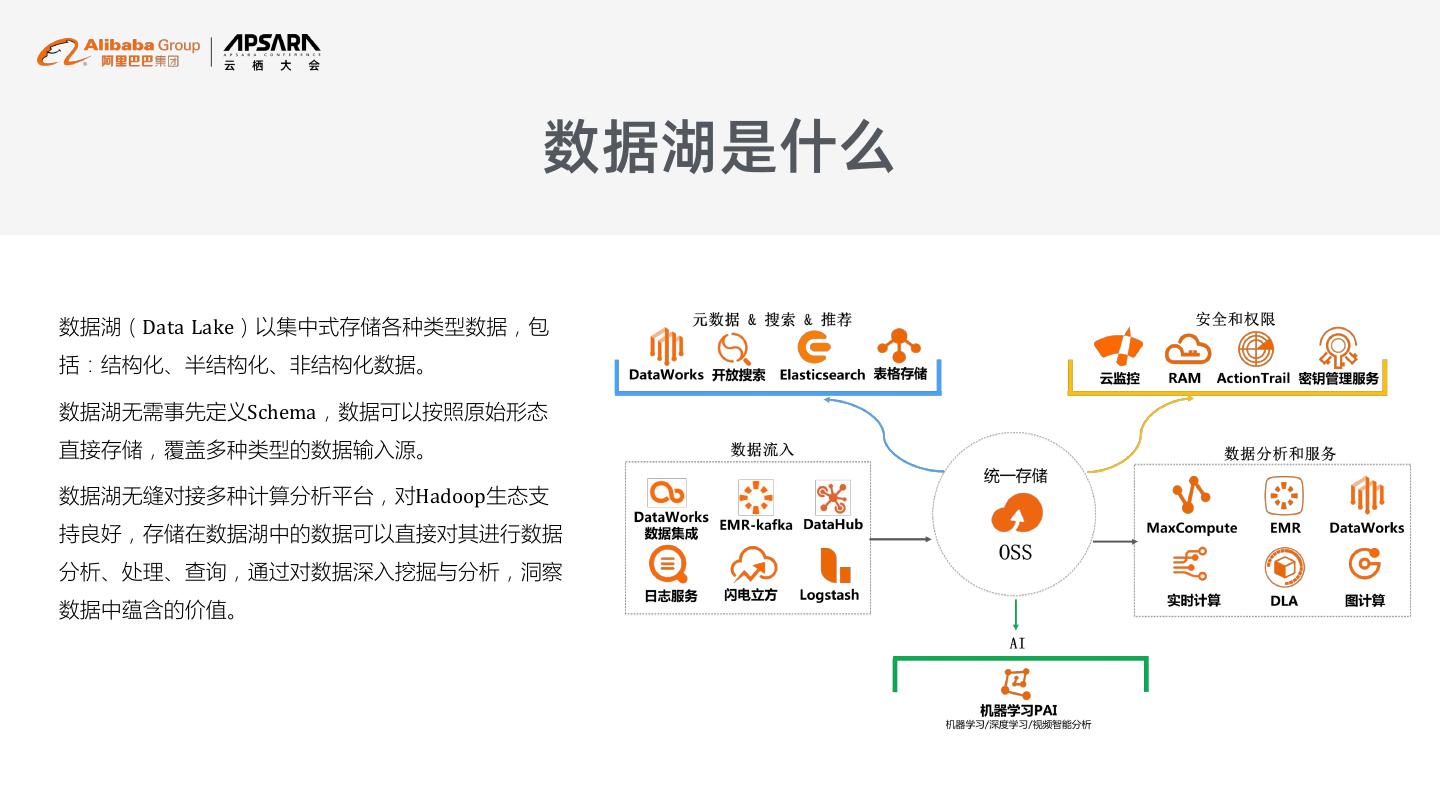
5 . 数据湖是什么 数据湖(Data Lake)以集中式存储各种类型数据,包 括:结构化、半结构化、非结构化数据。 数据湖无需事先定义Schema,数据可以按照原始形态 直接存储,覆盖多种类型的数据输入源。 数据湖无缝对接多种计算分析平台,对Hadoop生态支 持良好,存储在数据湖中的数据可以直接对其进行数据 分析、处理、查询,通过对数据深入挖掘与分析,洞察 数据中蕴含的价值。
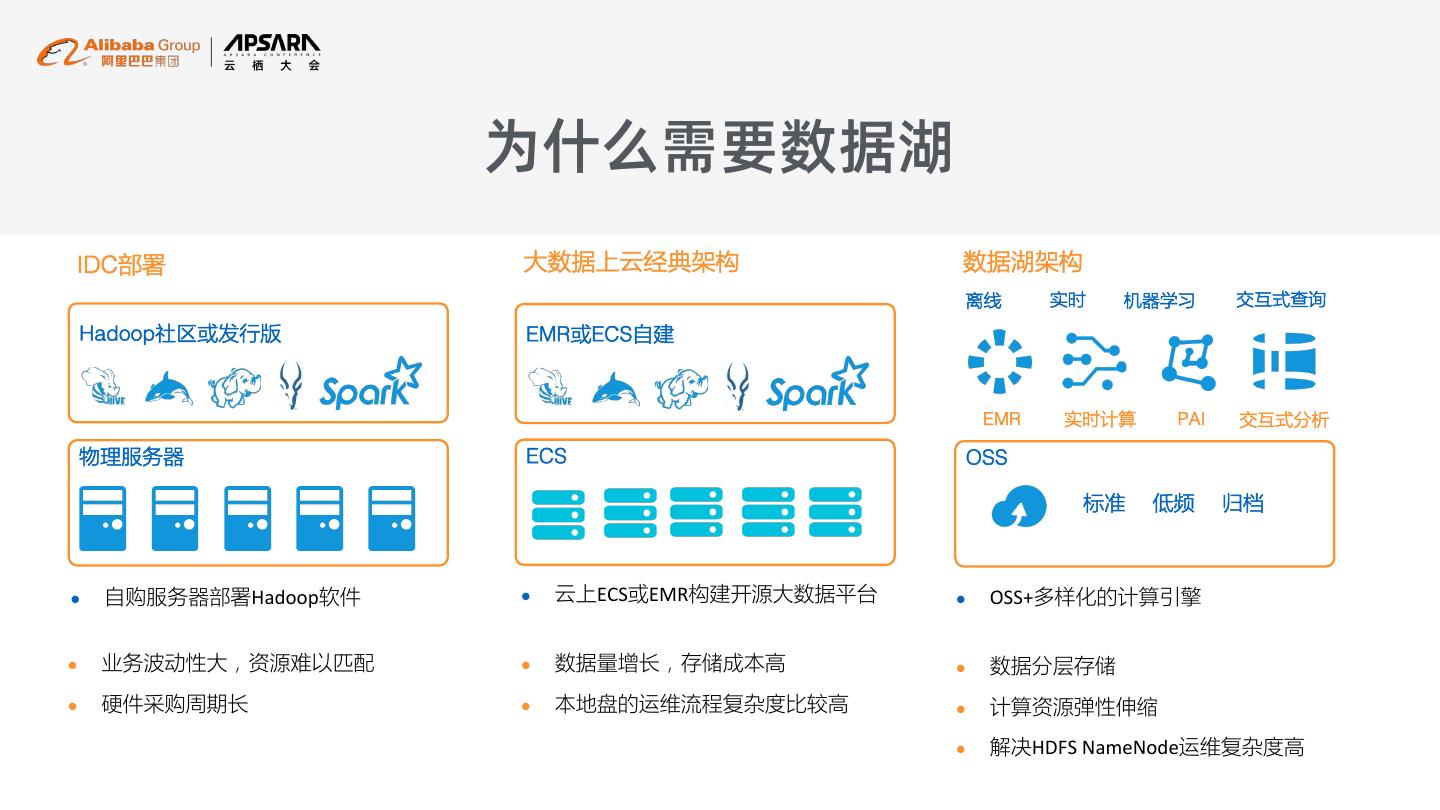
6 . 为什么需要数据湖 IDC部署 大数据上云经典架构 数据湖架构 离线 实时 机器学习 交互式查询 Hadoop社区或发行版 EMR或ECS自建 EMR 实时计算 PAI 交互式分析 物理服务器 ECS OSS 标准 低频 归档 l 自购服务器部署Hadoop软件 l 云上ECS或EMR构建开源大数据平台 l OSS+多样化的计算引擎 l 业务波动性大,资源难以匹配 l 数据量增长,存储成本高 l 数据分层存储 l 硬件采购周期长 l 本地盘的运维流程复杂度比较高 l 计算资源弹性伸缩 l 解决HDFS NameNode运维复杂度高
7 .EMR数据湖方案 02
8 . 什么是E-MapReduce(EMR) Time line Product Features 云原生阿里云生态 16 6月 EMR 正式上线公测 • ECS数十款实例族,计算型/内存型/通用型/大数据型/GPU异构计算 16 9月 EMR 商业化版本发布 • 分钟级别集群创建/扩容 • 支持动态弹性伸缩/竞价实例 17 9月 Data Science集成集成 • 原生支持阿里云OSS,采用JindoFS 加速OSS性能 19 8月 EMR 敏捷版发布(基于Kubernetes) • 阿里云DataWorks,PAI,SLS,OTS,MaxCompute 19 12月 EMR 4.0 发布,支持Hadoop 3.1 100%开源大数据 组件 • 所有组件均使用开源Apache社区版本 • 跟随社区版本迭代演进 • Spark, Hadoop, Kafka 组件性能/易用性优化,采用plugin方式用户自主开启关闭 • 半托管架构,用户自主可控,现有大数据资产无缝迁移 企业级特性 • EMR APM在集群/主机/服务/作业层面监控/告警/诊断 • 支持MIT Kerberos/RAM/HAS作为鉴权平台 • Apache Rnager统一的权限管理
9 . EMR开源大数据生态 PAI DataWorks NoteBook Application DEV & Jupyter/Zepplin Data Science workbench Metadata Job Scheduler 社区开源组件 Job Scheduler EMR-Workspace/ management EMR-Flow/Oozie Permission Hue/Superset Hive/Kafka & TensorFl authorizatio MR Hive Spark Flink ow Storm Impala Presto EMR开源软件增强 n 监 YARN Kafka Druid Compute Engine 智 能 Kerberos HBase 控 Ranger Delta Lake JindoFS 运 EMR自研组件 & 告 HDFS Kudu OSS Data Storage 维 警 管 Sqoop,DataX Flume,Kafka Logstash,SLS Data Intergration 控 阿里云其他云产品 Data Platform EMR Agent Management Basic Compute ECS/ECI/ACK(K8s) Source
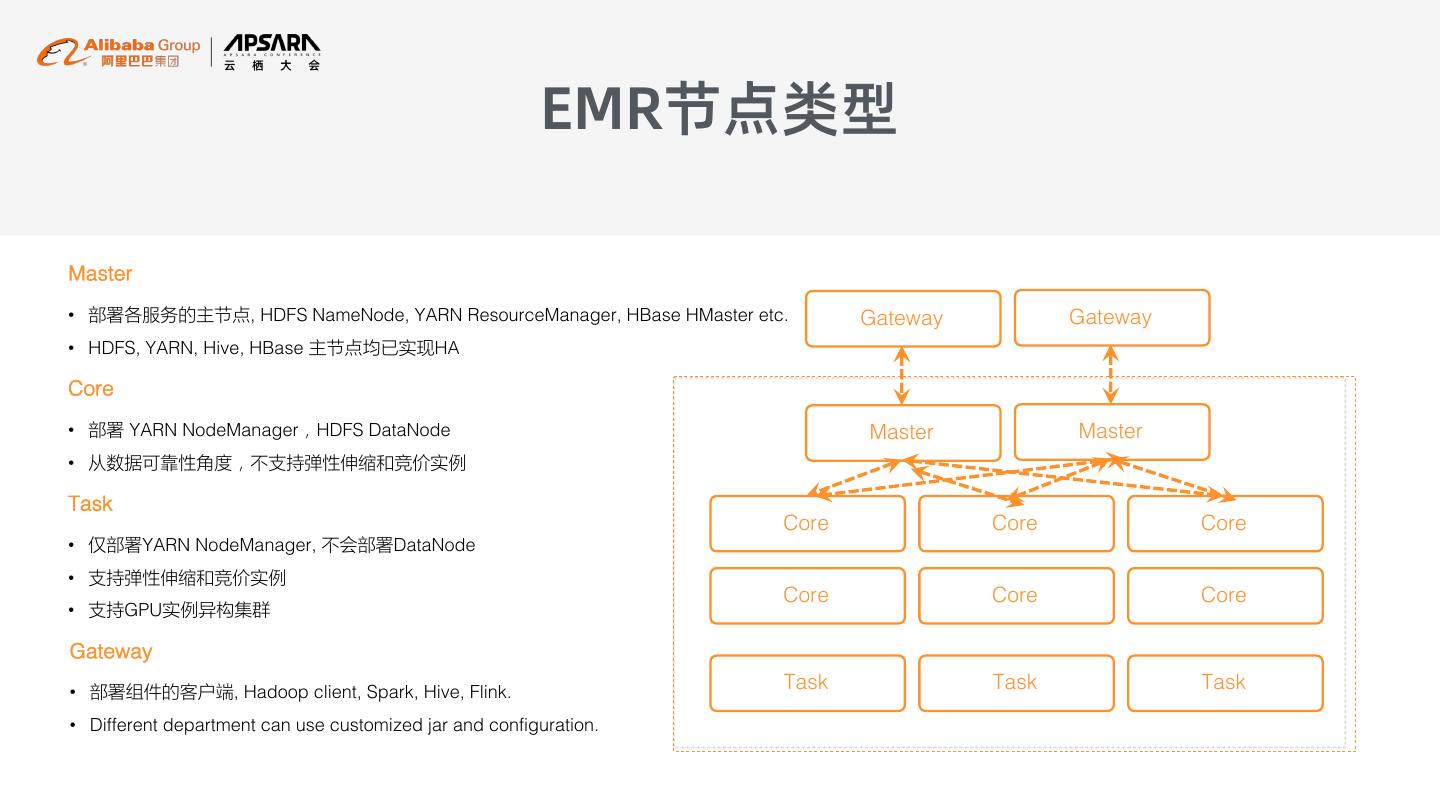
10 . EMR节点类型 Master • 部署各服务的主节点, HDFS NameNode, YARN ResourceManager, HBase HMaster etc. Gateway Gateway • HDFS, YARN, Hive, HBase 主节点均已实现HA Core • 部署 YARN NodeManager,HDFS DataNode Master Master • 从数据可靠性角度,不支持弹性伸缩和竞价实例 Task Core Core Core • 仅部署YARN NodeManager, 不会部署DataNode • 支持弹性伸缩和竞价实例 Core Core Core • 支持GPU实例异构集群 Gateway • 部署组件的客户端, Hadoop client, Spark, Hive, Flink. Task Task Task • Different department can use customized jar and configuration.
11 . EMR 产品功能 JindoFS 弹性伸缩 APM 数据开发 l 云原生大数据文件系统 l 按集群负载/时间扩缩容 l 作业/服务/主机多层次 l 拖拽式开发 l 计算存储分离架构 l 竞价实例 的大数据监控报警 l DAG作业运行方式 l Cache和Block两种模式 l 多种实例规格 l 作业/服务日志查询 l 批/流作业调度 l Spark/Flink/Hive/Presto/ l 资源使用数据统计 Druid/HBase生态支持
12 . HDFS vs OSS HDFS OSS l 诞生10+年,社区和配套功能成熟 l 管理和运维成本低 l 开源生态好 l 标准/低频/归档数据分层存储,低成本 l 数据一致性好 l 海量数据存储,不会引入Federation系统复杂性 l 数据可靠性高,11个9 l 更灵活,易于构建数据湖 l HA架构复杂,服务多,可维护性差 l 性能和OSS带宽有很大关系 l Federation架构 l 云上通用场景设计 l Decomission周期长 l Spark/Flink等计算框架中的rename/list等操作性能低 l NameNode在文件数大情况重启时间长 l 数据一致性弱 l ……
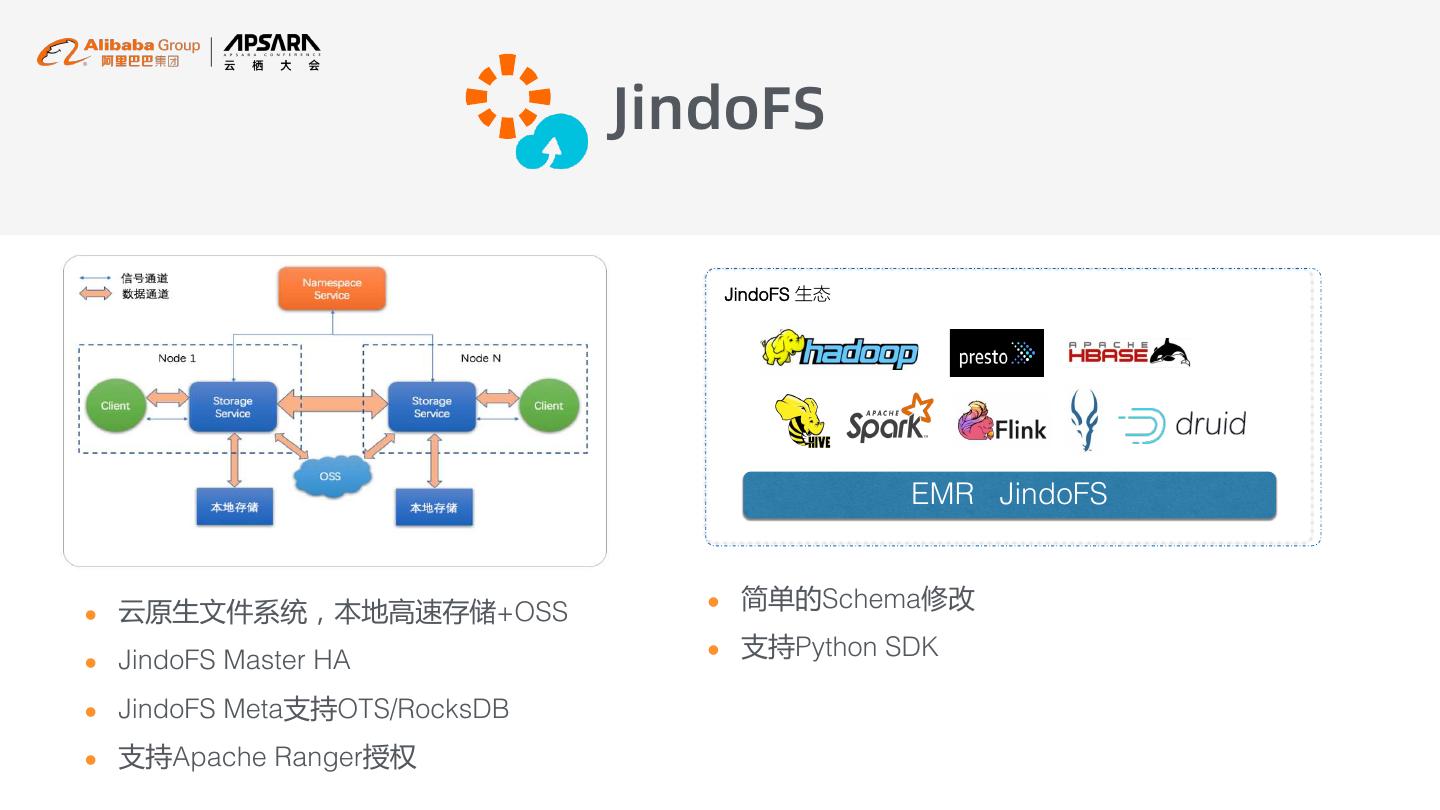
13 . JindoFS l 海量数据容量 云上计算存储分离架构 l 更灵活 l 低运维和使用成本 l 可靠性高 l 文件移动较慢 l 列式 l 带宽限制 l 高频访问
14 . JindoFS JindoFS 生态 EMR JindoFS l 云原生文件系统,本地高速存储+OSS l 简单的Schema修改 l JindoFS Master HA l 支持Python SDK l JindoFS Meta支持OTS/RocksDB l 支持Apache Ranger授权
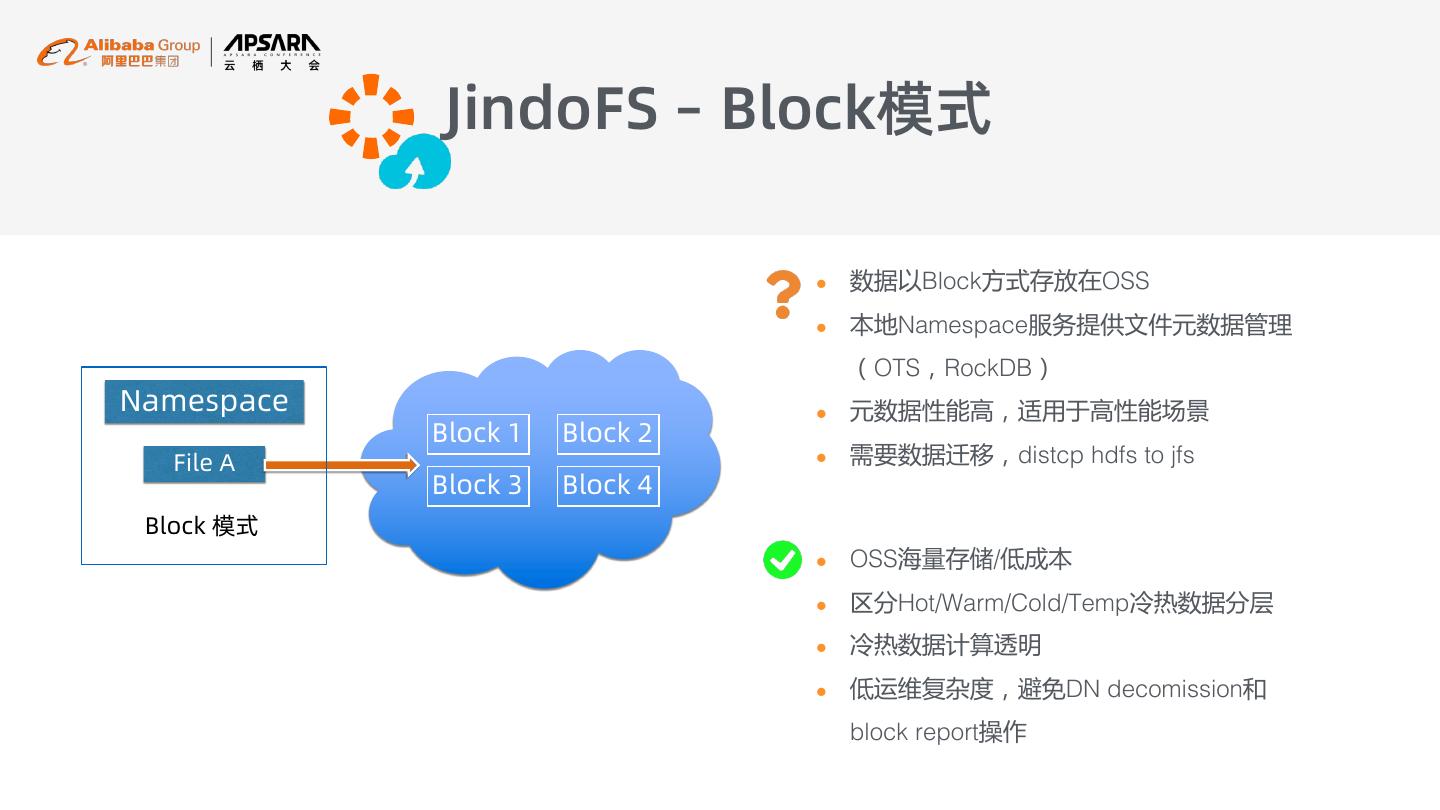
15 . JindoFS – Block模式 l 数据以Block方式存放在OSS l 本地Namespace服务提供文件元数据管理 (OTS,RockDB) Namespace l 元数据性能高,适用于高性能场景 Block 1 Block 2 File A l 需要数据迁移,distcp hdfs to jfs Block 3 Block 4 Block 模式 l OSS海量存储/低成本 l 区分Hot/Warm/Cold/Temp冷热数据分层 l 冷热数据计算透明 l 低运维复杂度,避免DN decomission和 block report操作
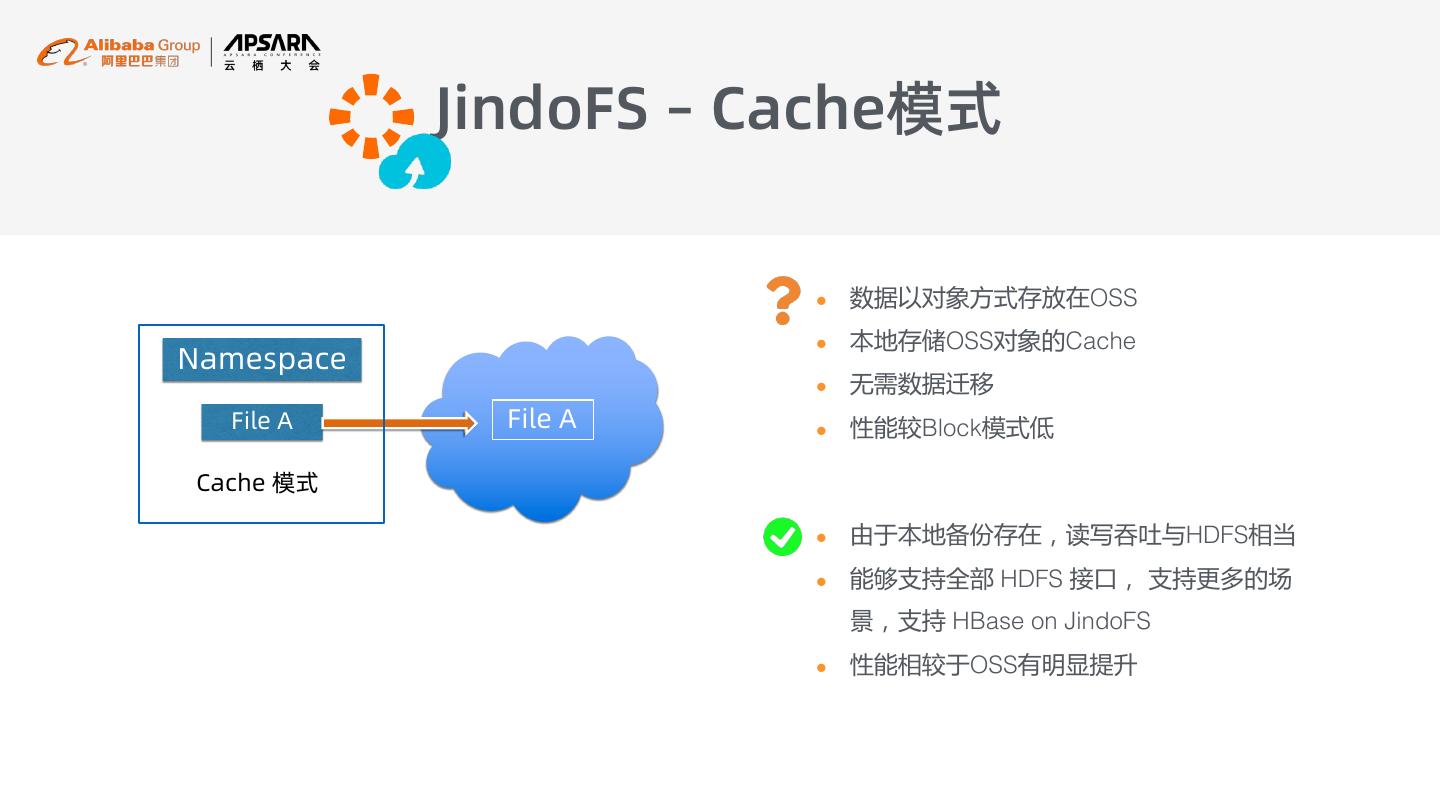
16 . JindoFS – Cache模式 l 数据以对象方式存放在OSS l 本地存储OSS对象的Cache Namespace l 无需数据迁移 File A File A l 性能较Block模式低 Cache 模式 l 由于本地备份存在,读写吞吐与HDFS相当 l 能够支持全部 HDFS 接口, 支持更多的场 景,支持 HBase on JindoFS l 性能相较于OSS有明显提升
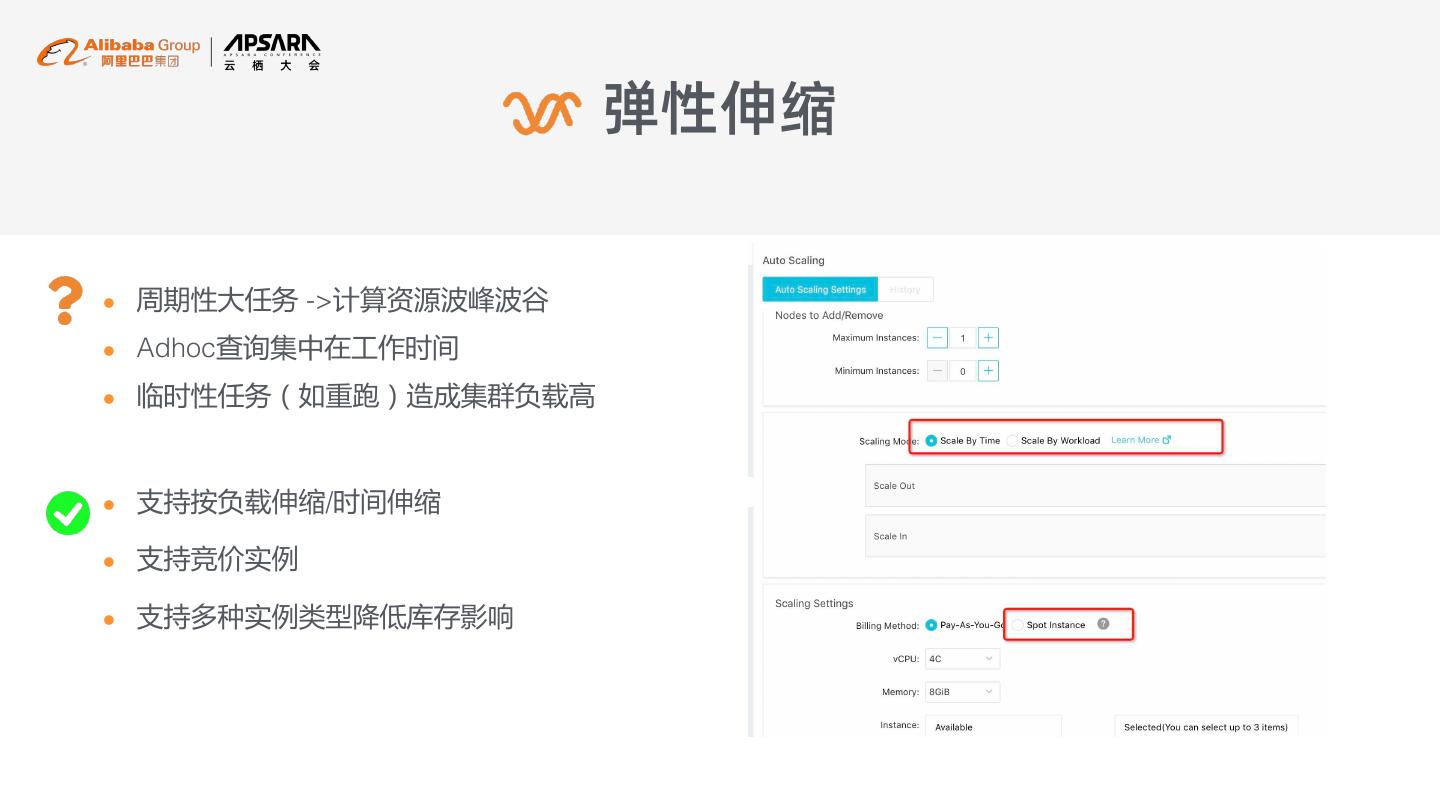
17 . 弹性伸缩 l 周期性大任务 ->计算资源波峰波谷 l Adhoc查询集中在工作时间 l 临时性任务(如重跑)造成集群负载高 l 支持按负载伸缩/时间伸缩 l 支持竞价实例 l 支持多种实例类型降低库存影响
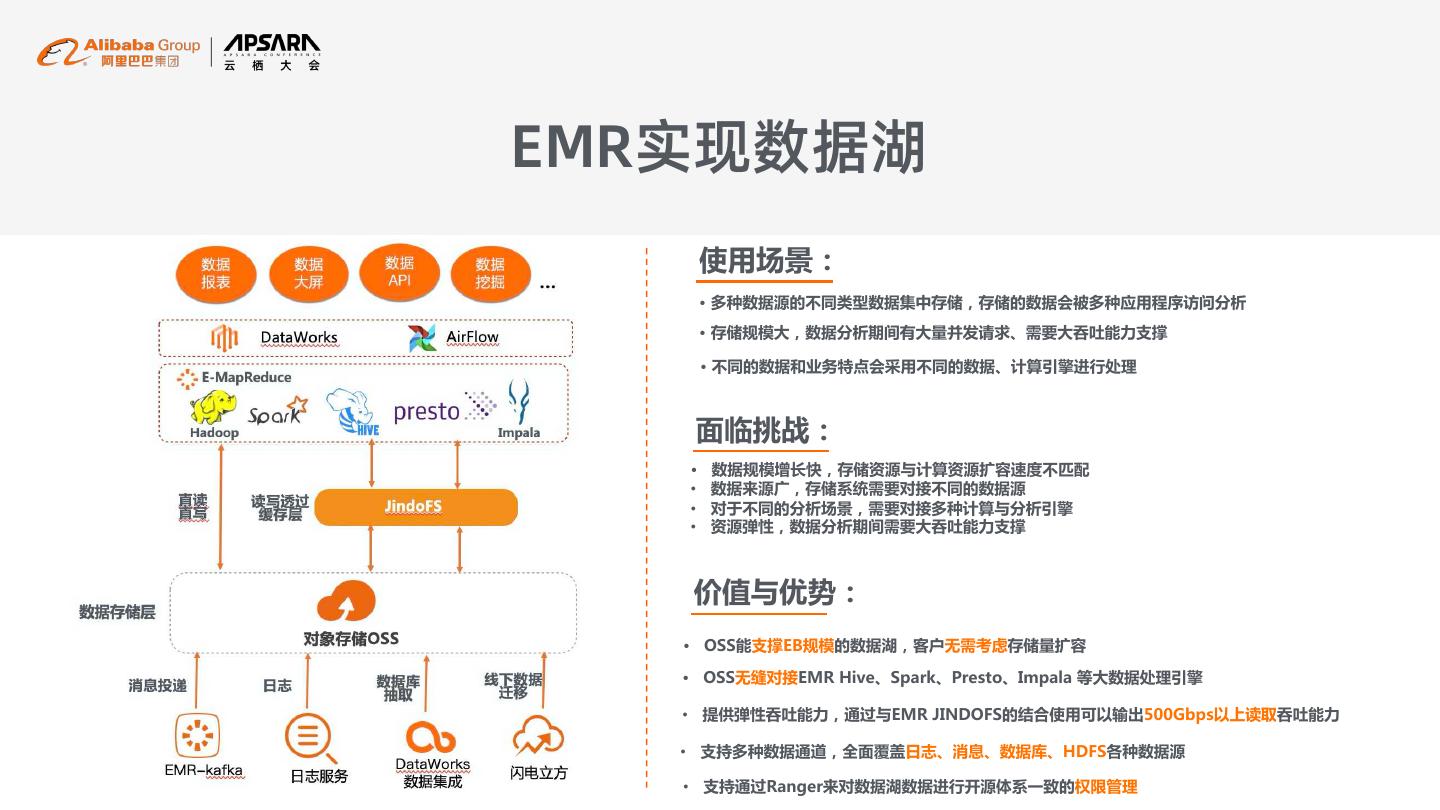
18 .EMR实现数据湖 使用场景: · 多种数据源的不同类型数据集中存储,存储的数据会被多种应用程序访问分析 · 存储规模大,数据分析期间有大量并发请求、需要大吞吐能力支撑 · 不同的数据和业务特点会采用不同的数据、计算引擎进行处理 面临挑战: · 数据规模增长快,存储资源与计算资源扩容速度不匹配 • 数据来源广,存储系统需要对接不同的数据源 • 对于不同的分析场景,需要对接多种计算与分析引擎 • 资源弹性,数据分析期间需要大吞吐能力支撑 价值与优势: · OSS能支撑EB规模的数据湖,客户无需考虑存储量扩容 · OSS无缝对接EMR Hive、Spark、Presto、Impala 等大数据处理引擎 • 提供弹性吞吐能力,通过与EMR JINDOFS的结合使用可以输出500Gbps以上读取吞吐能力 • 支持多种数据通道,全面覆盖日志、消息、数据库、HDFS各种数据源 • 支持通过Ranger来对数据湖数据进行开源体系一致的权限管理
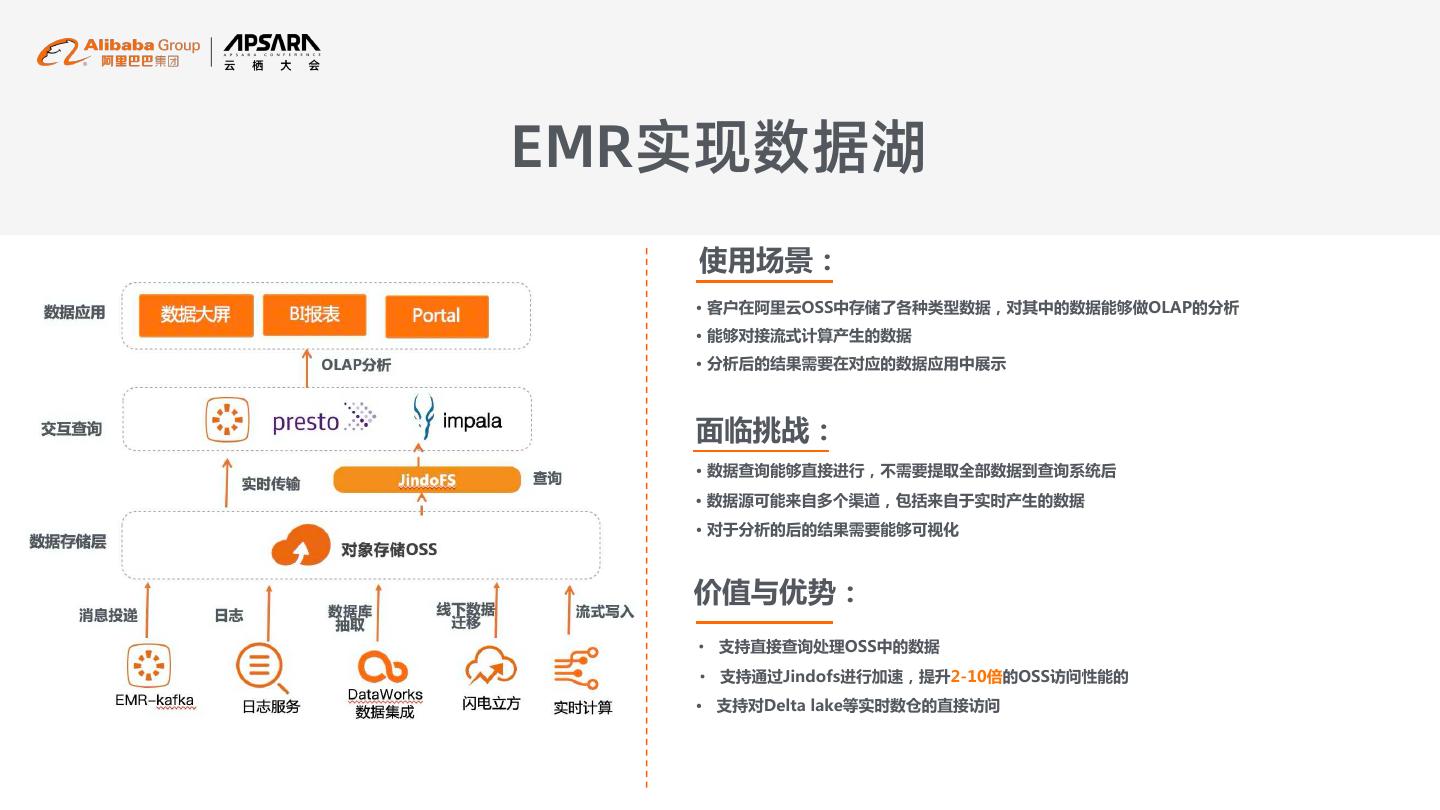
19 .EMR实现数据湖 使用场景: · 客户在阿里云OSS中存储了各种类型数据,对其中的数据能够做OLAP的分析 · 能够对接流式计算产生的数据 · 分析后的结果需要在对应的数据应用中展示 面临挑战: · 数据查询能够直接进行,不需要提取全部数据到查询系统后 · 数据源可能来自多个渠道,包括来自于实时产生的数据 · 对于分析的后的结果需要能够可视化 价值与优势: • 支持直接查询处理OSS中的数据 • 支持通过Jindofs进行加速,提升2-10倍的OSS访问性能的 · 支持对Delta lake等实时数仓的直接访问
20 . EMR新功能与特性 新功能 近期发布 l EMR4.x 稳定版发布,Hadoop3.x/Hive3.x l Spark 3.x l DataWorks on EMR l 支持第6代c/g/r网络增强型实例 l Flink Ververica版本加入Hadoop集群 l 多机器组弹性伸缩,及成本优化模式 l Data Science机器正式上线 l APM Grafana上线 l 多Master功能 l 弹性伸缩YARN优雅下线
21 .客户实践案例 03
22 . 客户实践 – 案例1 EMR Gateway 用户需求 EMR Spark 运营报表 l 公司日报/企业运营报表 大数据 AI平台 开发平台 ETL处理 EMR Druid l XPB数据量/X千张Hive报表/X ETL任务调度 实时 Ad hoc l X万vcpu Hadoop集群 EMR Hadoop l JindoFS block模式存储亿级文件 数据采集 数据平台 l 多个Master HDFS/JindoFS/YARN分散部署 EMR Kafka Tez Presto 用户价值 消息队列 MapReduce Hive Deep Storage EMR JindoFS Block模式 Hot 1.xPB (10%-20%) l EMR JindoFS +OSS,实现PB数据分层存储 l 上云后JindoFS相较HDFS,日常性能提升x% 阿里云OSS l X百节点根据任务弹性伸缩 标准型 XPB 低频型 XPB 归档型 XPB
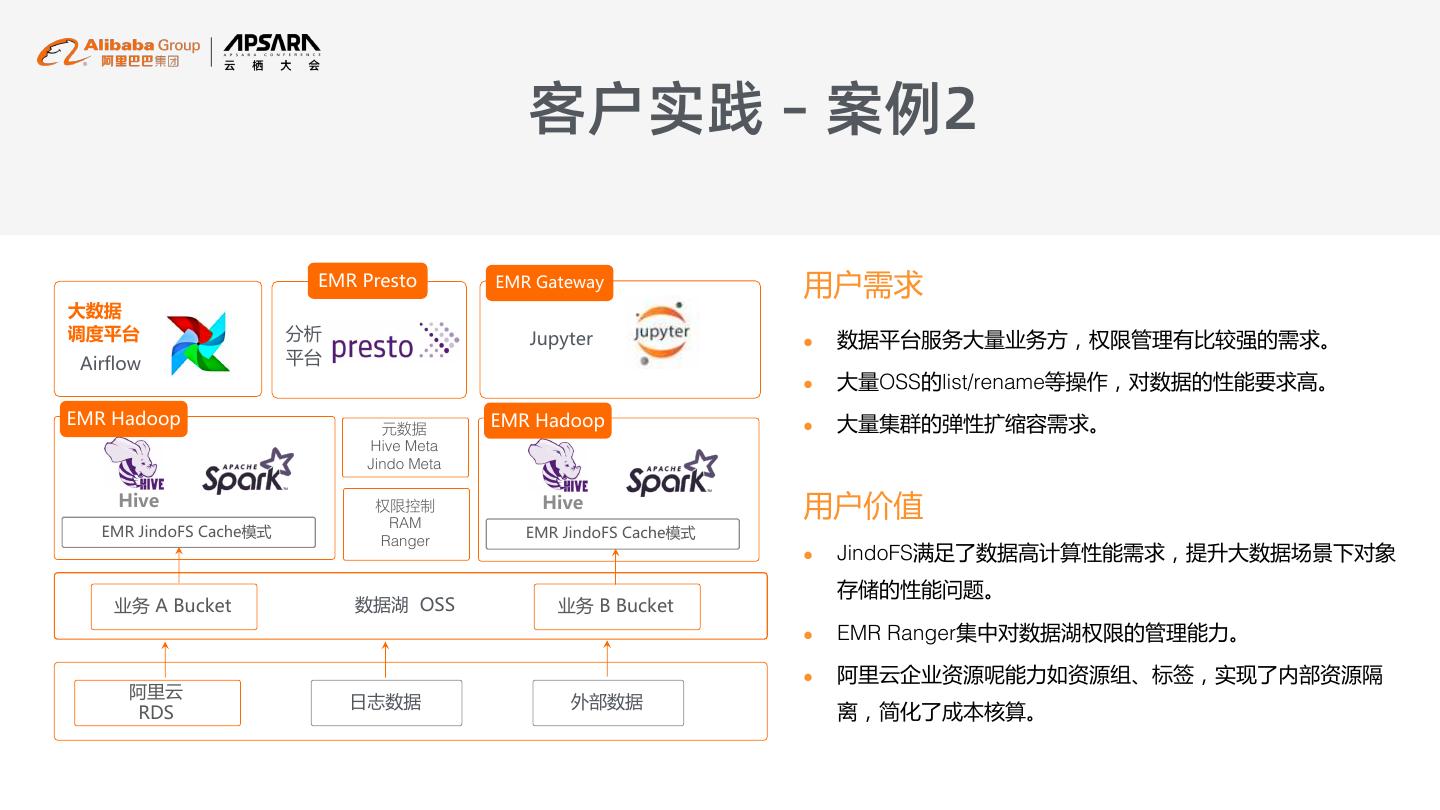
23 . 客户实践 – 案例2 EMR Presto EMR Gateway 用户需求 大数据 调度平台 分析 Jupyter l 数据平台服务大量业务方,权限管理有比较强的需求。 Airflow 平台 l 大量OSS的list/rename等操作,对数据的性能要求高。 EMR Hadoop 元数据 EMR Hadoop l 大量集群的弹性扩缩容需求。 Hive Meta Jindo Meta Hive 权限控制 RAM Hive 用户价值 EMR JindoFS Cache模式 EMR JindoFS Cache模式 Ranger l JindoFS满足了数据高计算性能需求,提升大数据场景下对象 存储的性能问题。 业务 A Bucket 数据湖 OSS 业务 B Bucket l EMR Ranger集中对数据湖权限的管理能力。 l 阿里云企业资源呢能力如资源组、标签,实现了内部资源隔 阿里云 日志数据 外部数据 RDS 离,简化了成本核算。
24 . 进一步讨论 E-MapReduce产品交流群 钉钉 Apache Spark技术交流群 钉钉 Apache Spark技术交流 微信公众号
25 .THANK !
3点赞
0收藏
3秒后跳转登录页面
去登陆

