展开查看详情
3 .01
Apache Flink : ververica.cn
© Apache Flink Community China
�
4 .Spark SQL is Apache Spark's module for
working with structured data.
• 灵活易用
• 功能强大
• 生态丰富
• Spark演进的基础模块
�
5 .private IntWritable one = new IntWritable(1)
private IntWritable output = new IntWritable()
proctected void map( LongWritable key, Text
value, Context context) {
String[] fields = value.split("\t") data = sc.textFile(...).split("\t")
output.set(Integer.parseInt(fields[1])) data.map(lambda x: (x[0], [x.[1], 1])) \
context.write(one, output) .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]]) \
} .map(lambda x: [x[0], x[1][0] / x[1][1]]) \
IntWritable one = new IntWritable(1) .collect()
DoubleWritable average = new DoubleWritable()
protected void reduce( IntWritable key,
Iterable<IntWritable> values, Context context)
{ int sum = 0
int count = 0
for(IntWritable value : values) {
sum += value.get()
count++ }
average.set(sum / (double) count)
context.Write(key, average) }
�
6 . Using RDDs
更少的代码 data = sc.textFile(...).split("\t") data.map(lambda x:
更易用的接
口 (x[0], [int(x[1]), 1])) \
声明式语言 .reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
\ .map(lambda x: [x[0], x[1][0] / x[1][1]]) \
.collect()
Using DataFrames
sqlCtx.table("people") \
Using SQL .groupBy("name") \
SELECT name, avg(age) FROM people GROUP BY name .agg("name", avg("age")) \
.collect()
�
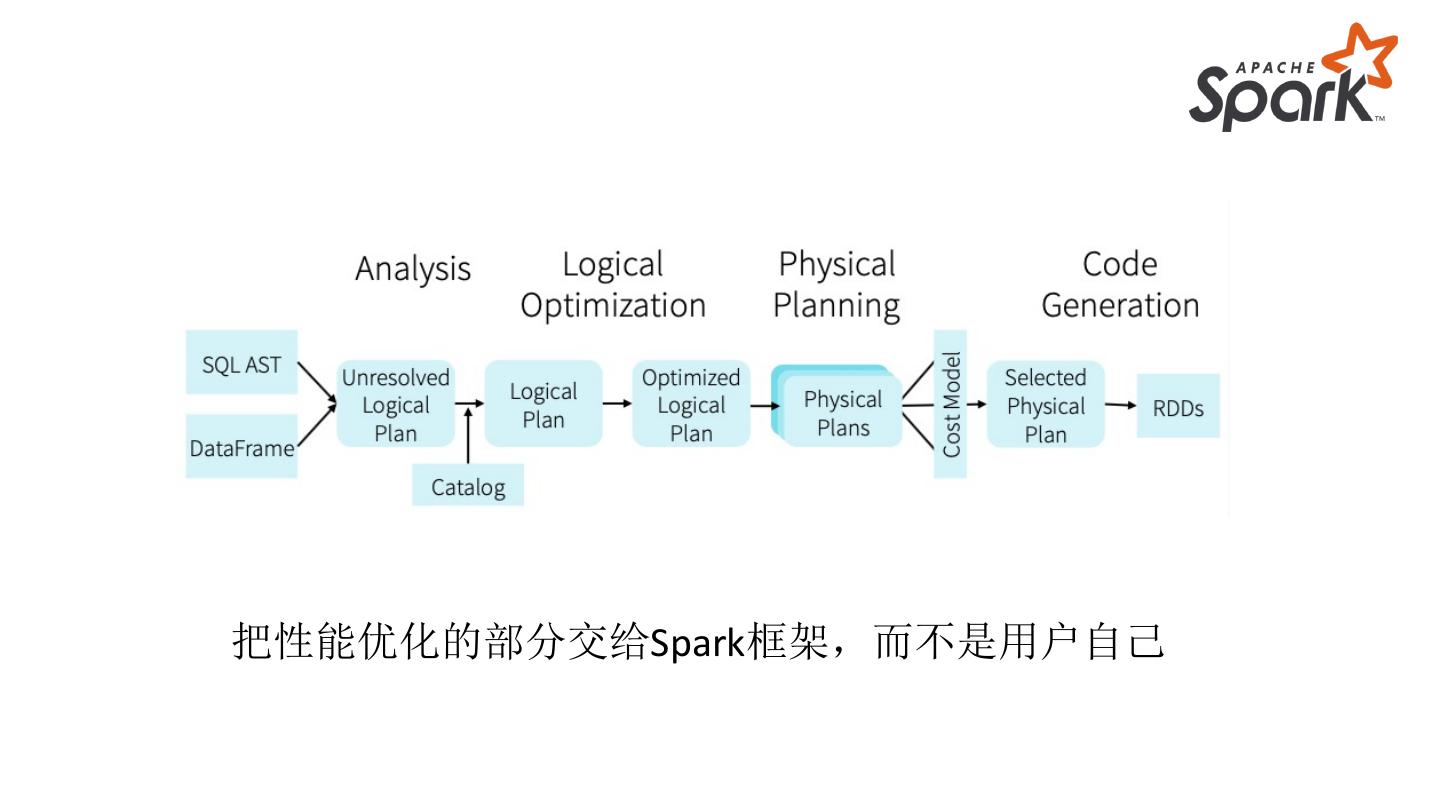
7 .把性能优化的部分交给Spark框架,而不是用户自己
�
8 .取代RDD,已经成为Spark的基础组件,加速所有数
据分析相关场景的计算。
�
9 .02
Apache Flink : ververica.cn
© Apache Flink Community China
�
10 .Catalyst介绍
一个关系型数据执行计划框架及优化器
• Row & DataType’s
• Trees & Rules
• Logical Operators
• Expressions
• Optimizations Catalyst
�
11 .Catalyst介绍: Row & Data Type
o.a.s.sql.catalyst.types.DataType
• Long, Int, Short, Byte, Float, Double, Decimal
• String, Binary, Boolean, Timestamp
• Array, Map, Struct
o.a.s.sql.catalyst.expressions.Row
• Represents a single row.
• Can contain complex types.
�
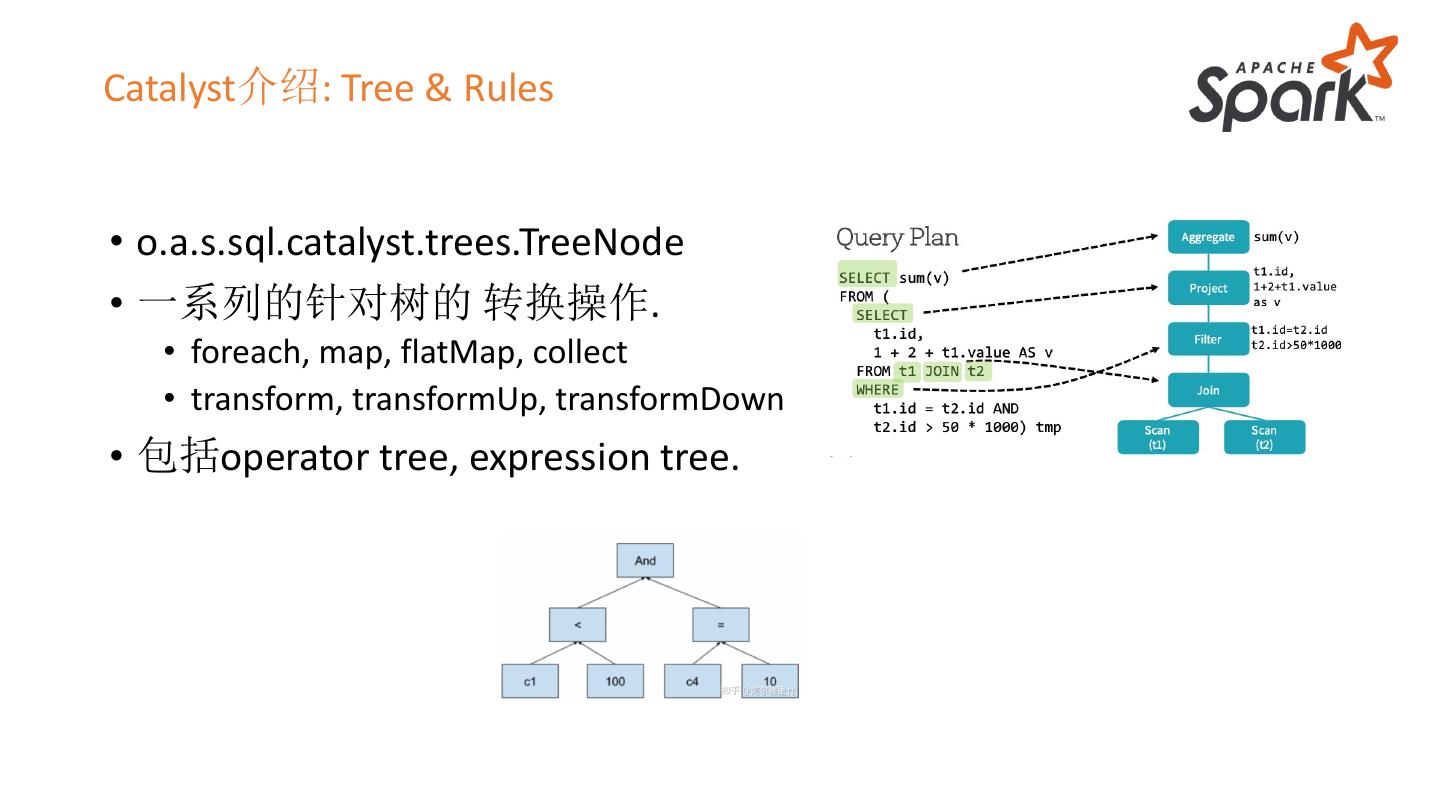
12 .Catalyst介绍: Tree & Rules
• o.a.s.sql.catalyst.trees.TreeNode
• 一系列的针对树的 转换操作.
• foreach, map, flatMap, collect
• transform, transformUp, transformDown
• 包括operator tree, expression tree.
�
13 .Catalyst介绍: Tree & Rules
• o.a.s.sql.catalyst.rules.Rule
• 通过Rule将一个执行计划转换成另外一个逻辑等价的执行计划。
• o.a.s.sql.catalyst.rules.RuleExecutor
• 一个执行Rule的引擎,根据配置的规则,确定执行rule的顺序,批次,收
敛条件等.。
�
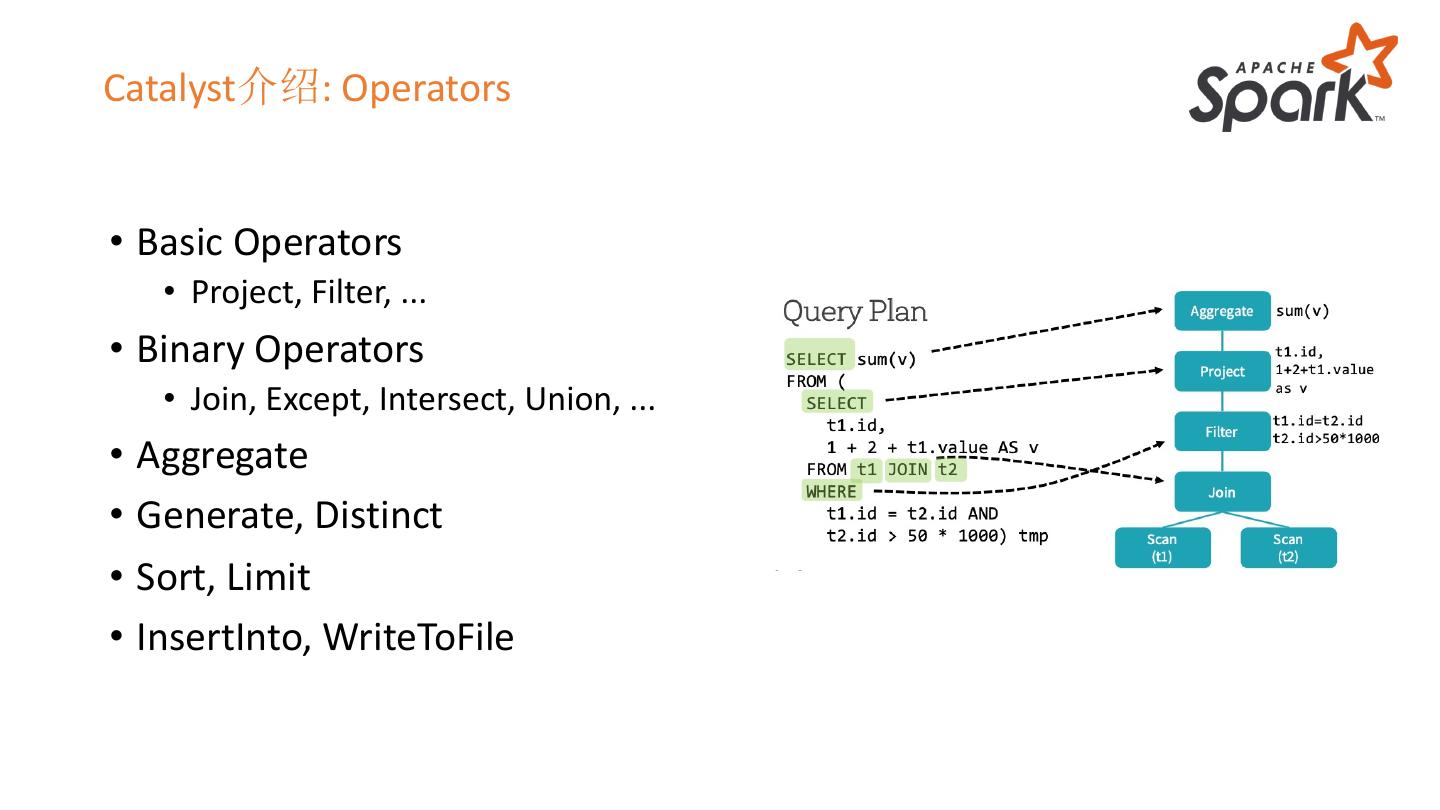
14 .Catalyst介绍: Operators
• Basic Operators
• Project, Filter, ...
• Binary Operators
• Join, Except, Intersect, Union, ...
• Aggregate
• Generate, Distinct
• Sort, Limit
• InsertInto, WriteToFile
�
15 .Catalyst介绍: Expressions
• Literal
• Arithmetics
• UnaryMinus, Sqrt, Maxof
• Add, Subtract, Multiply, …
• Predicates
• EqualTo, LessThan, LessThanOrEqual, GreaterThan, GreaterThanOrEqual
• Not, And, Or, In, If, Case When
�
16 .Catalyst介绍: Expressions
• Cast
• GetItem, GetField
• Coalesce, IsNull, IsNotNull
• StringOperations
• Like, Upper, Lower, Contains, StartsWith,
EndsWith, Substring, ...
�
17 .Catalyst介绍: Optimization
�
18 .03
Apache Flink : ververica.cn
© Apache Flink Community China
�
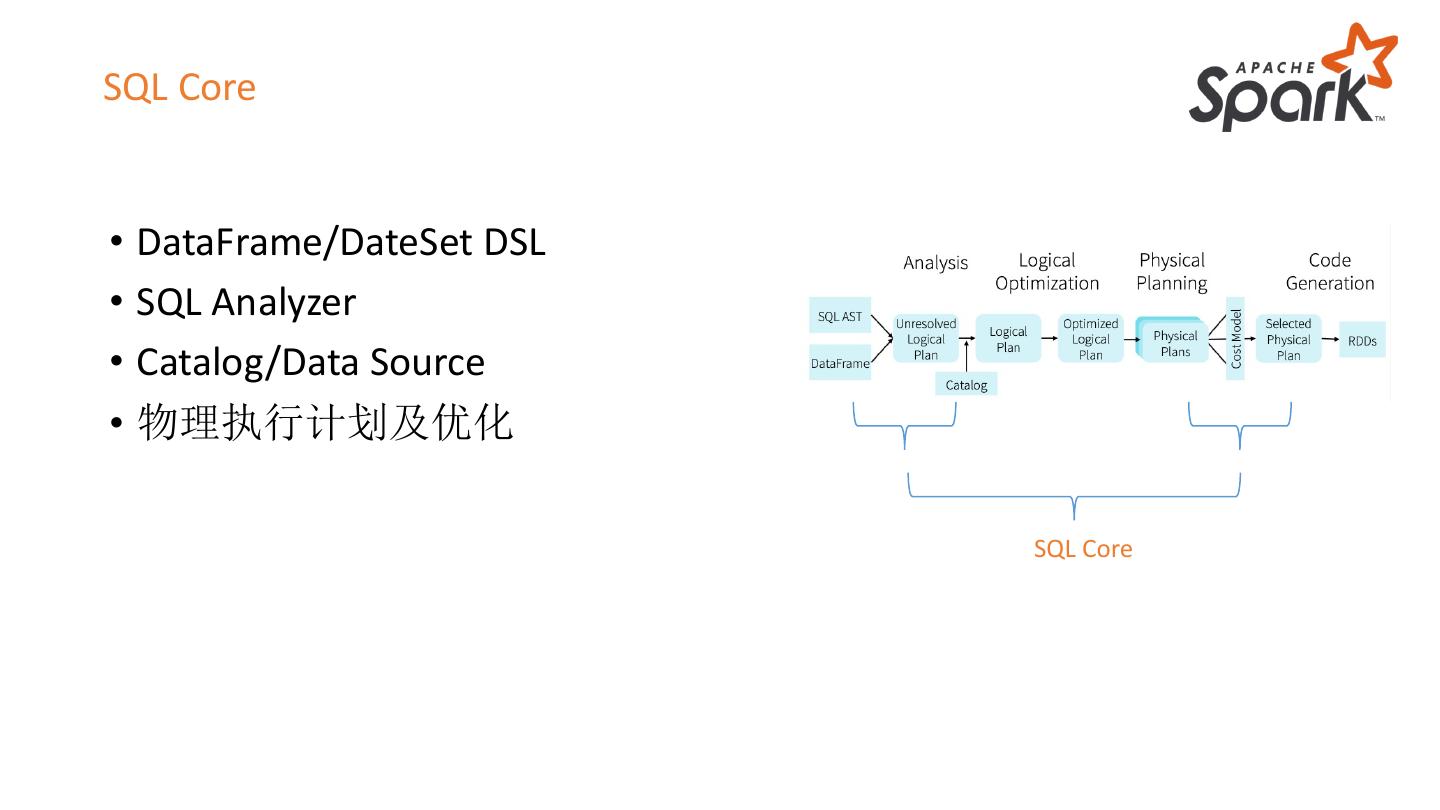
19 .SQL Core
• DataFrame/DateSet DSL
• SQL Analyzer
• Catalog/Data Source
• 物理执行计划及优化
SQL Core
�
20 .SQL Core: DataFrame API
df = sqlContext
.table ("people") \
.groupBy("name") \
.agg("name", avg("age")) \
.collect()
• 声明式
• 非类型安全
• 生成执行计划
�
21 .SQL Core: Analyzer
SELECT name, AVG(age)
FROM people
GROUP BY name;
• 基于Antlr4的词法解析。
�
22 .SQL Core: Source
df = sqlContext.read \ Save Mode
.format("json") \
.option("samplingRatio", "0.1") \
.load("/home/user/data.json")
df.write \
.format("parquet") \
.mode("append") \
.partitionBy("year") \
.saveAsTable("fasterData")
https://spark.apache.org/docs/latest/sql-data-sources.html
�
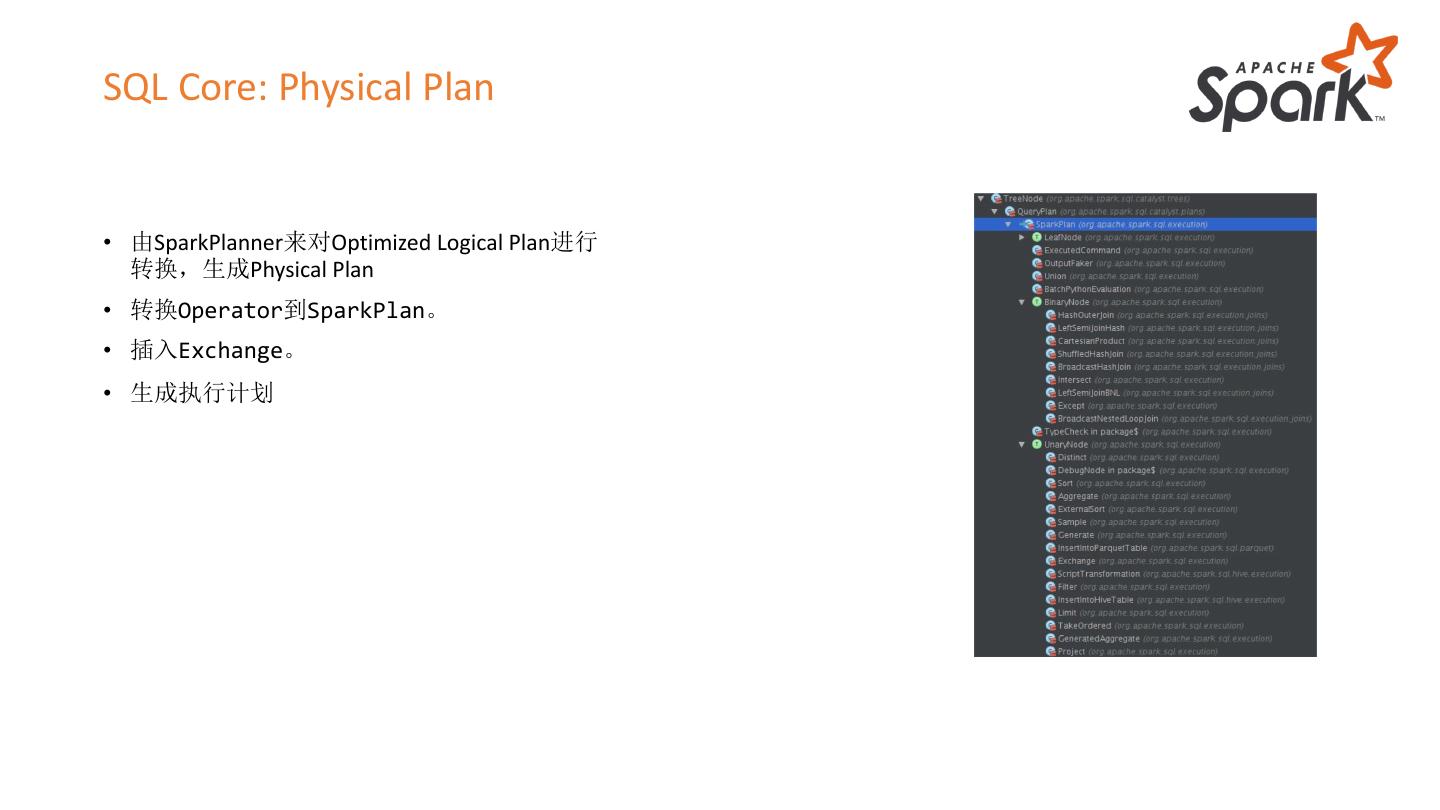
23 .SQL Core: Physical Plan
• 由SparkPlanner来对Optimized Logical Plan进行
转换,生成Physical Plan
• 转换Operator到SparkPlan。
• 插入Exchange。
• 生成执行计划
�
24 .04
Apache Flink : ververica.cn
© Apache Flink Community China
�
25 . Demo
相关资源
集群环境
Spark2.4.5, Hadoop2.8.5,Hive2.3.5. 可自建或阿里
云EMR3.28.2版本。
数据集
Star Schema Benchmark数据集scale=5,
https://github.com/Kyligence/ssb-kylin
�