




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark 在存储计算分离趋势下的数据缓存
点赞
11
收藏
5
7月31日【Apache Spark 在存储计算分离趋势下的数据缓存】
主讲人:辰山,阿里巴巴计算平台事业部 EMR 高级开发工程师,目前从事大数据存储方面的开发和优化工作
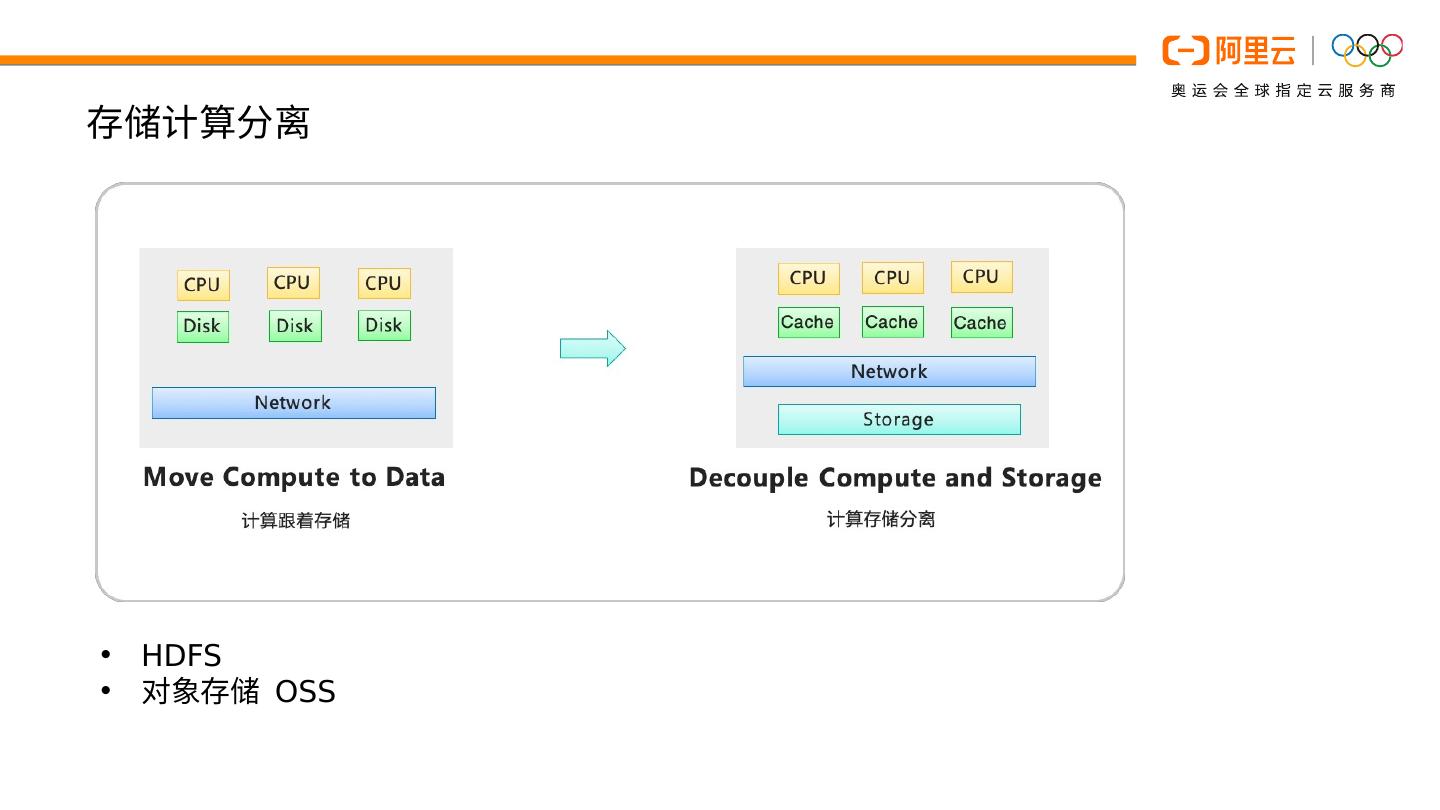
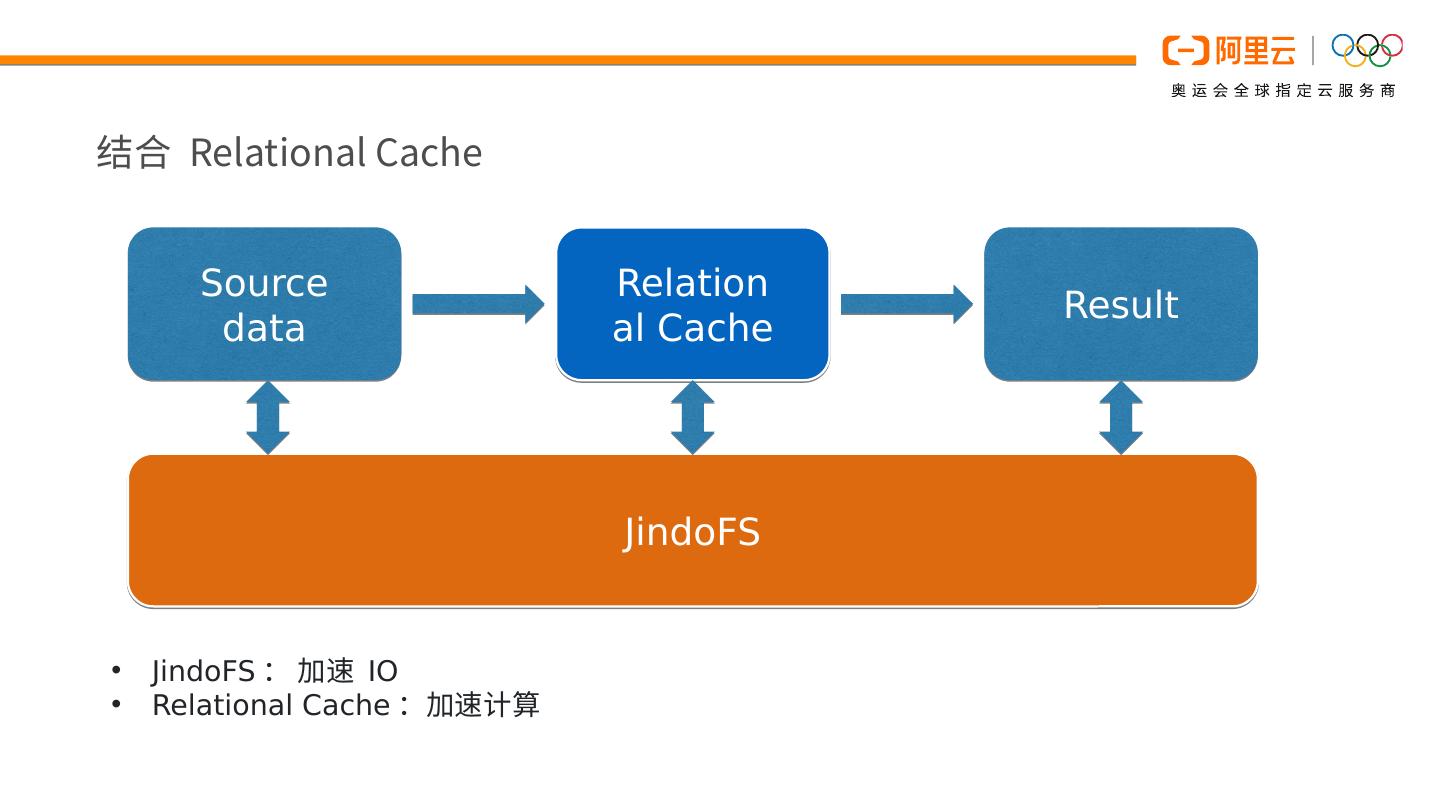
简介:在数据上云的大背景下,存储计算分离逐渐成为了大数据处理的一大趋势,计算引擎需要通过网络读写远端的数据,很多情况下 IO 成为了整个计算任务的瓶颈,因而数据缓存成为此类场景下的一个重要的优化手段。本次分享将介绍 Spark 在数据缓存上的一些做法,并将介绍 EMR 自研的 Jindo 存储系统在数据缓存上的应用。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
11点赞
5收藏
3秒后跳转登录页面
去登陆

