展开查看详情
1 . Apache Spark 基于
Apache Arrow 的列式存储优化
7点开始
更更多精彩分享,请访问《Apache Spark中国技术社区》
�
2 .Apache Spark 基于 Apache Arrow 的列式存储优化
阿⾥里里云智能 E-MapReduce 诚历
2019.7
�
3 .关于我
孙⼤大鹏(花名:诚历)
计算平台事业部 E-MapReduce
开源大数据存储和优化
Apache Sentry PMC
Apache Commons Committer
Hadoop, Hive, Alluxio Contributor
EMR (E-MapReduce) https://www.aliyun.com/product/emapreduce
阿里云上基于开源生态,包括 Hadoop、Spark、Kafka、Flink、Storm 等组件,为您提供集
群、作业、数据管理等服务的⼀一站式企业大数据平台。
�
4 .Spark & Columnar Apache Arrow Spark + Arrow
�
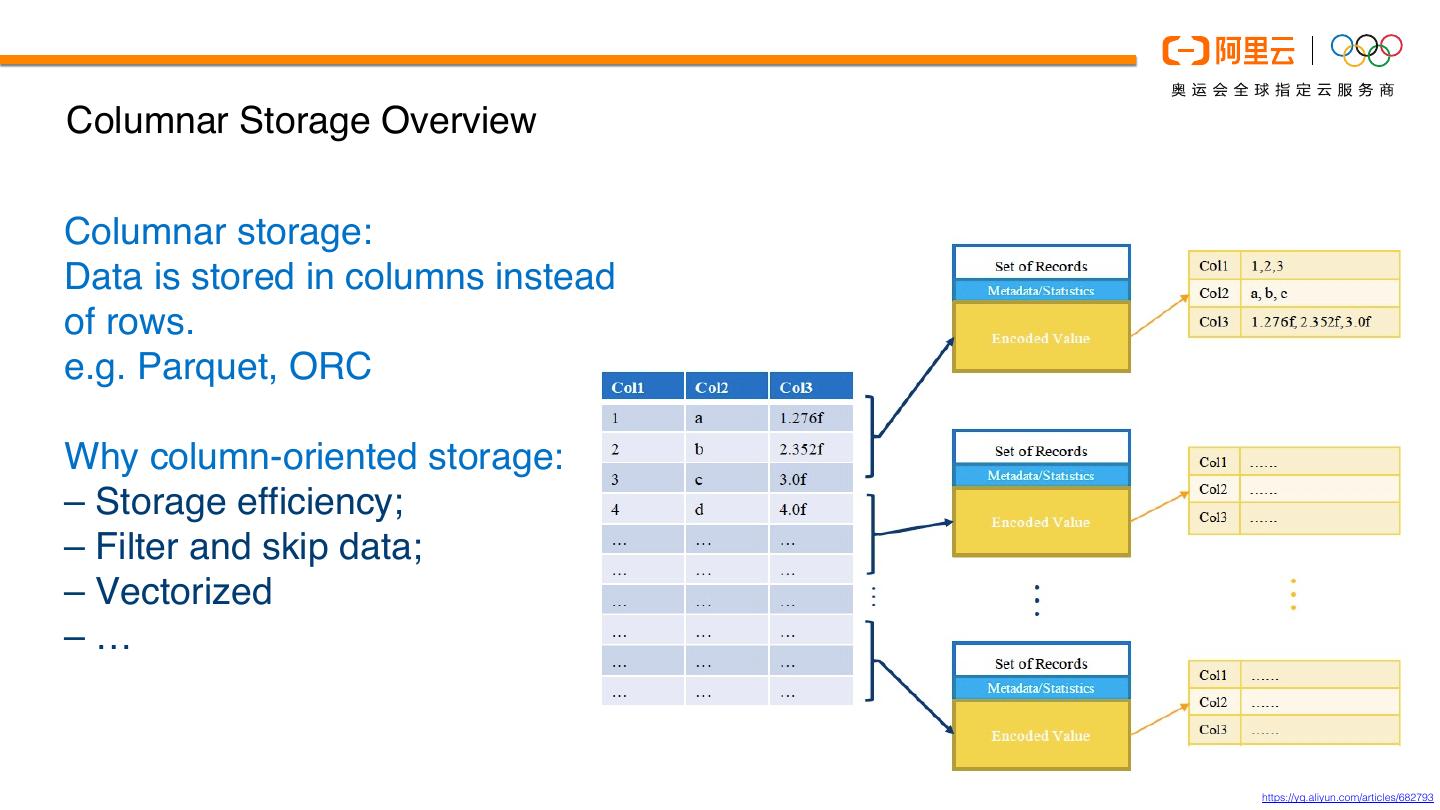
6 .Columnar Storage Overview
Columnar storage:
Data is stored in columns instead
of rows.
e.g. Parquet, ORC
Why column-oriented storage:
– Storage efficiency;
– Filter and skip data;
– Vectorized
–…
https://yq.aliyun.com/articles/682793
�
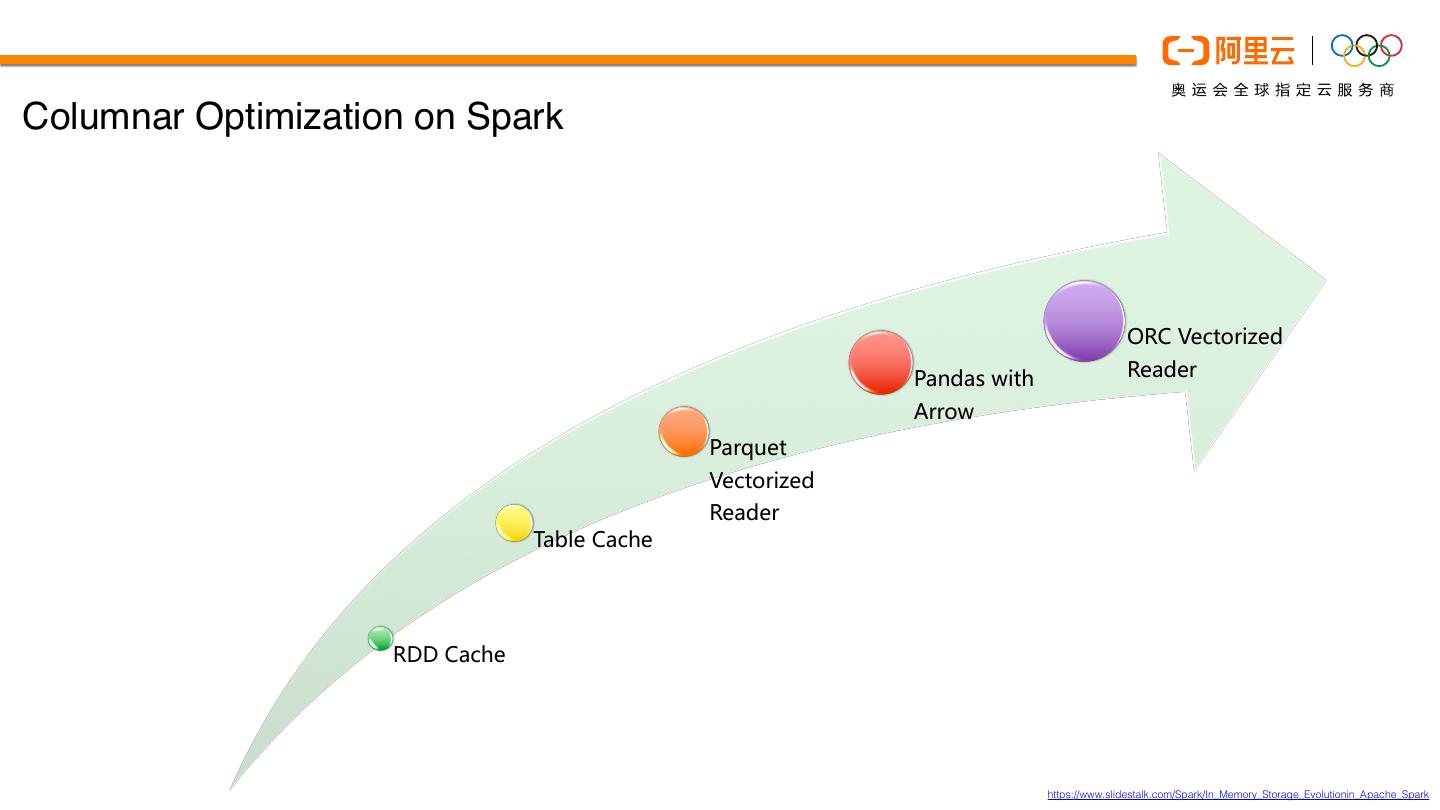
7 .Columnar Optimization on Spark
ORC Vectorized
Pandas with Reader
Arrow
Parquet
Vectorized
Reader
Table Cache
RDD Cache
https://www.slidestalk.com/Spark/In_Memory_Storage_Evolutionin_Apache_Spark
�
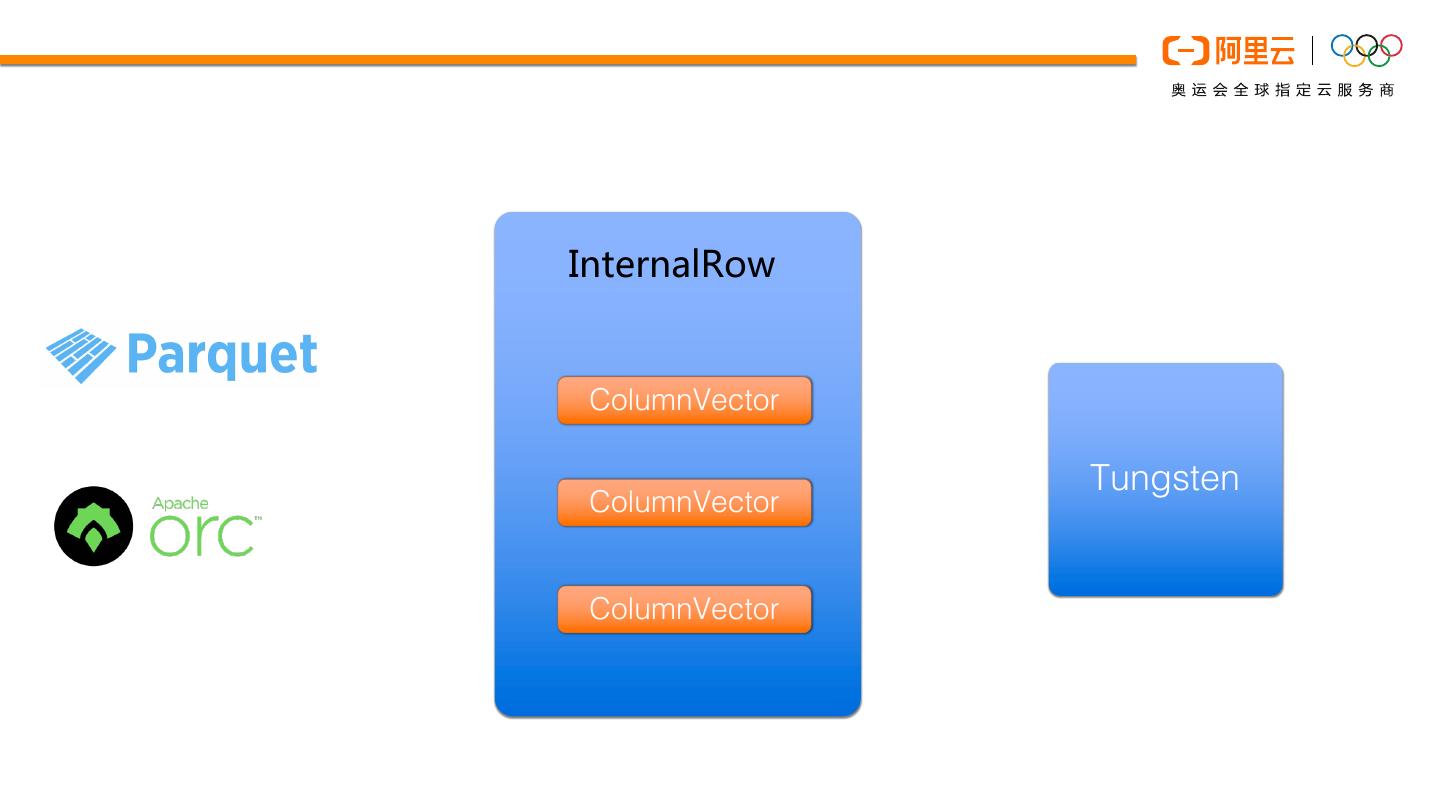
8 .InternalRow
ColumnVector
Tungsten
ColumnVector
ColumnVector
�
9 .Summary
• Columnar Optimization
Parquet Vectorized Reader (2.0+)
Pandas UDF with Arrow (2.3+)
ORC Vectorized Reader (2.4+)
• InternalRow & ColumnVector make Spark easy to connected to more
columnar storages
�
11 .Apache Arrow
• Arrow specifies a standardized
language-independent columnar
memory format for flat and
hierarchical data, organized for
efficient analytic operations on
modern hardware.
�
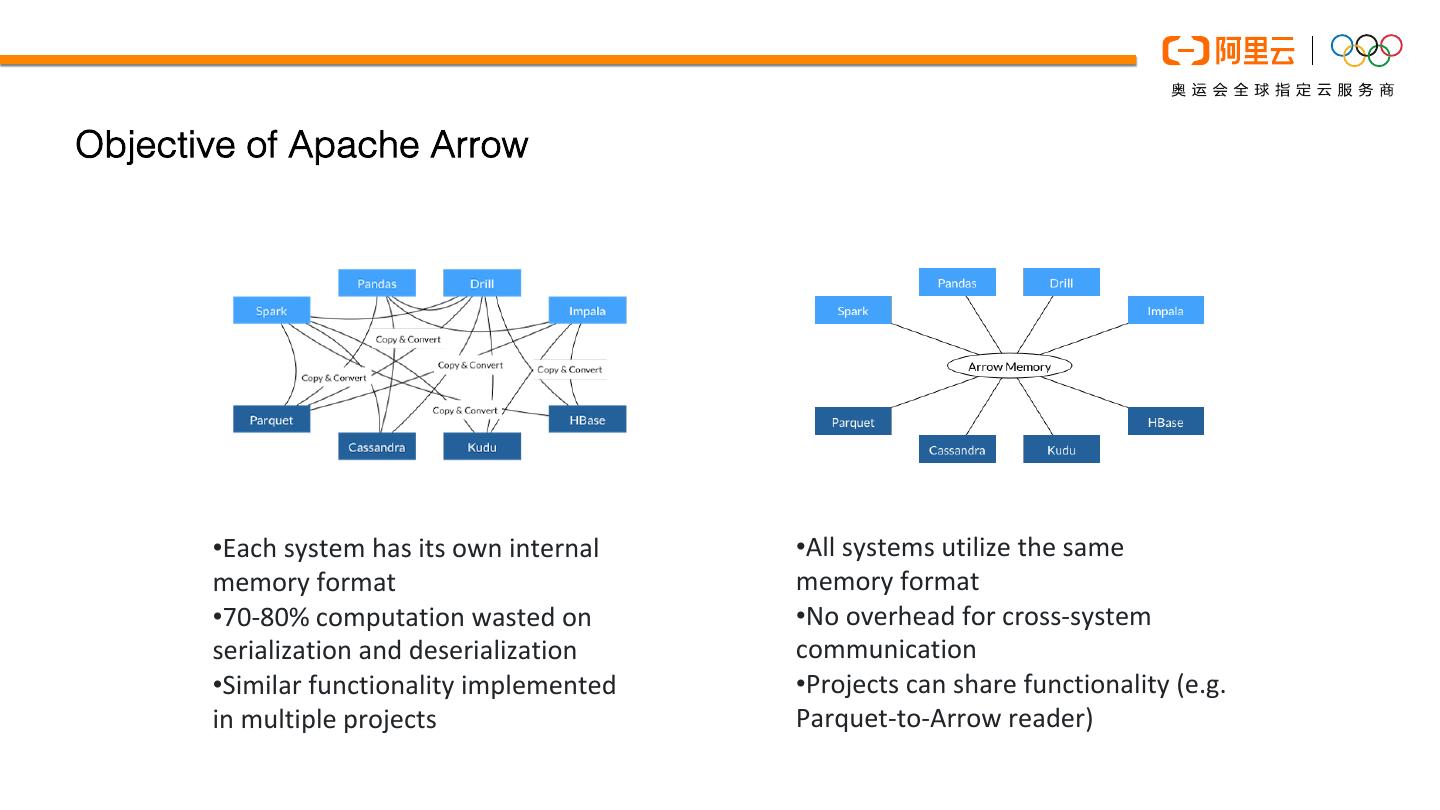
12 .Objective of Apache Arrow
•Each system has its own internal •All systems utilize the same
memory format memory format
•70-80% computation wasted on •No overhead for cross-system
serialization and deserialization communication
•Similar functionality implemented •Projects can share functionality (e.g.
in multiple projects Parquet-to-Arrow reader)
�
13 .Arrow Inside (1)
Arrow Format & Vector & Memory:
• Base on Flatbuffer
• Int, Decimal, Float, Varchar…
• Buffer allocate
�
14 .Record Batch Construction
�
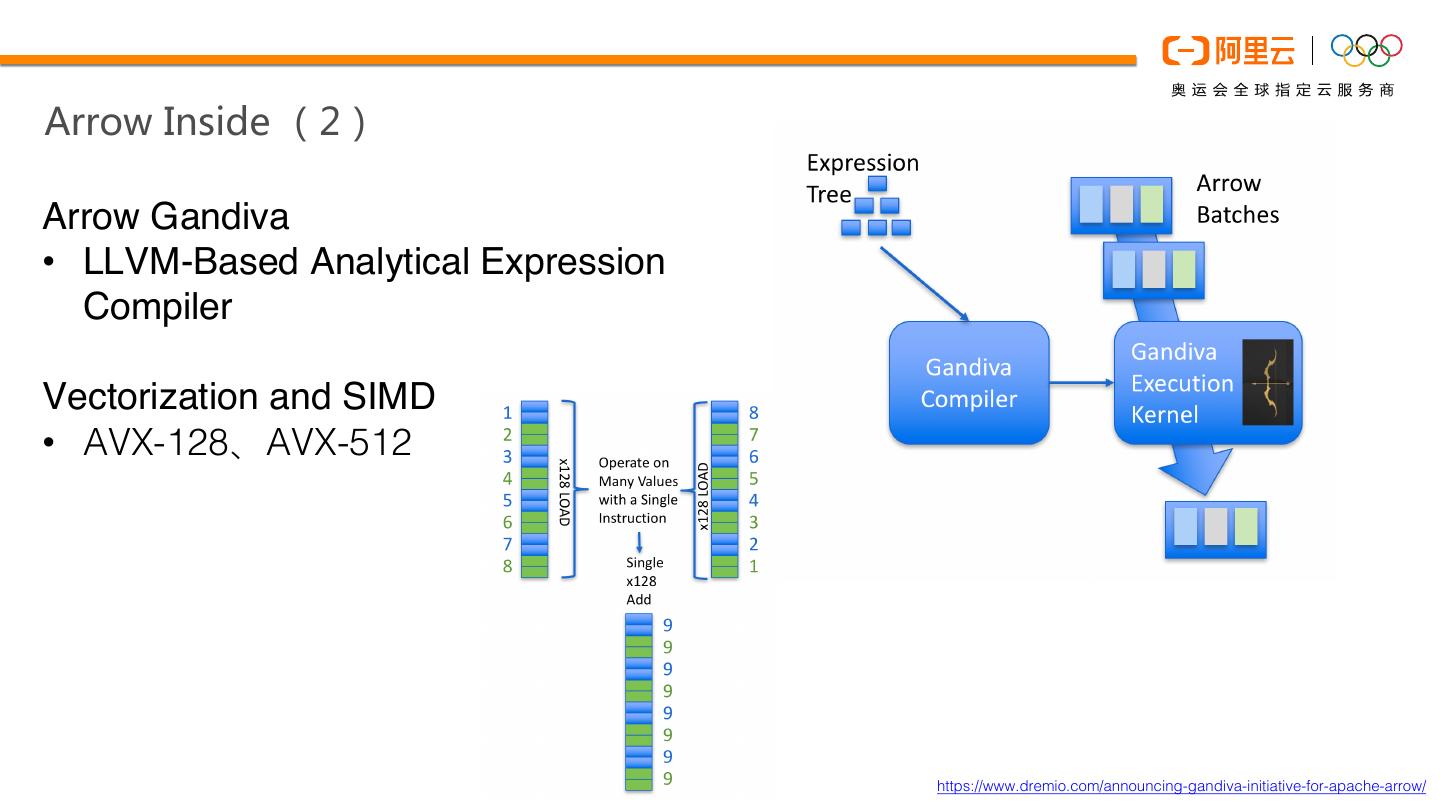
15 .Arrow Inside (2)
Arrow Gandiva
• LLVM-Based Analytical Expression
Compiler
Vectorization and SIMD
• AVX-128、AVX-512
https://www.dremio.com/announcing-gandiva-initiative-for-apache-arrow/
�
16 .Arrow Inside (3)
Arrow Plasma
• In-Memory Object Store holds immutable objects in
shared memory so that they can be accessed efficiently
by many clients across process boundaries
Arrow Flight
• Extend GRPC To Better Work With Arrow Streams
�
17 .Arrow Ecosystem
Parquet Arrow Arrow Arrow
File Batch Execution
Batch Gandiva
Plasma
Parquet Arrow Arrow Arrow
Execution
File Batch Batch Gandiva
Flight
Parquet Arrow Arrow Arrow
Execution
File Batch Batch Gandiva
�
19 .PySpark & Arrow
spark.sql.execution.arrow.enabled=true
DataFrame.toPandas()
�
20 .Spark & Arrow
[SPARK-27396] Public APIs for extended Columnar
Processing Support
https://issues.apache.org/jira/browse/SPARK-27396
�
21 .Spark & AI Summit (1)
Make your PySpark Data Fly with Arrow
https://www.slidestalk.com/Spark/Make_your_PySpark_Dat
a_Fly_with_Arrow
�
22 .Spark & AI Summit (2)
Apache Arrow-Based Unified Data Exchange
https://www.slidestalk.com/Spark/Apache_Arrow_Based_U
nified_Data_Sharing_and_Transferring_Format
�
23 .Spark & AI Summit (3)
Accelerating Machine Learning Workloads and Apache
Spark Applications via CUDA and NCCL
https://www.slidestalk.com/Spark/Accelerating_Machine_L
earning_Workloads_and_Apache_Spark
�