
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark 3.0简介:回顾过去的十年,并展望未来
分享
点赞
1
收藏
2
点击链接观看精彩回放:https://developer.aliyun.com/live/43188
Apache Spark 3.0简介:回顾过去的十年,并展望未来
李潇
Databricks Spark 研发部主管,领导 Spark,Koalas,Databricks runtime,OEM的研发团队。Apache Spark Committer、PMC成员。2011年从佛罗里达大学获得获得了博士学位。曾就职于IBM,获发明大师称号(Master Inventor),是异步数据库复制和一致性验证的领域专家,发表专利十余篇。(Github: gatorsmile)
我们将分享Apache Spark创建者Matei Zaharia的主题演讲,重点介绍Apache Spark 3.0 更易用、更快、更兼容的特点。Apache Spark 3.0 延续了项目初心,在SQL和Python API上取得了重大改进;自适应动态优化,使数据处理更易于访问,从而最大限度地减少手动配置。今年也是Spark首次开源发布的10周年纪念日,我们将回顾该项目及其用户群是如何增长的,以及Spark周围的生态系统(如Koalas, Delta Lake 和可视化工具)是如何发展的,共同探讨处理大规模数据的更简单、更有效的方案。

展开查看详情
1 .Introducing Apache Spark™ 3.0: A 10-Year Retrospective and A Look Ahead Matei Zaharia Chief Technologist & Cofounder, Databricks; Original Creator of Apache Spark
2 .This is a Special Year for Apache Spark Spark 3.0, and 10 years since the first release of Spark! What got us there and what did we learn?
3 .My Experience in Big Data
4 .2007: Start PhD at Berkeley
5 .2008: Datacenter-scale computing Takeaway: Big potential for impact, but too hard to use § Pipelines had to be written by software engineers § No support for interactive queries § No support for ML
6 .2009: Back to Berkeley Local researchers also wanted a scalable ML engine! Prize Lester Mackey August 2009: Start working on Spark
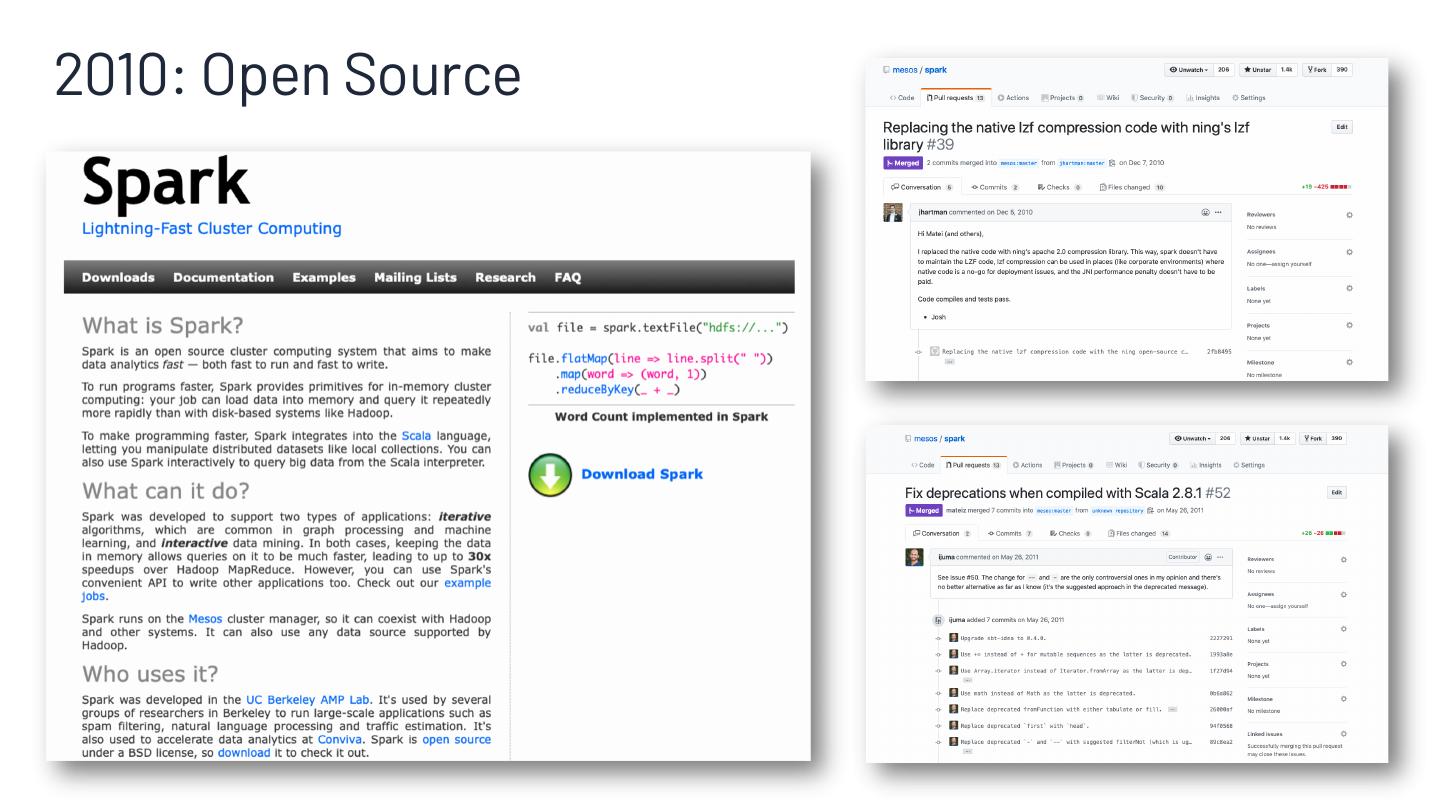
7 .2010: Open Source
8 .2010-11: Early Users Exciting, unexpected use cases: § Power interactive, operational apps § Update datasets incrementally in memory (streaming) § Accelerate R and SQL workloads
9 .2012-15: Expand Access to Spark Languages: Python, R and SQL Libraries: ML, Graphs and Streaming New high-level API: DataFrames, built on the Spark SQL engine
10 .Apache Spark Today: Python Language Use in Notebooks SQL 68% 18% Scala of notebook commands on 11% Databricks are in Python R 3% Python 68%
11 .Apache Spark Today: SQL TPC-DS benchmark record >90% set using Spark SQL TPC-DS 30TB runtime 15 of Spark API calls run via Spark SQL 10 5 exabytes 0 queried/day in SQL Spark Presto Spark 2.4 3.0
12 .Apache Spark Today: Streaming >5 trillion records/day processed on Databricks with Structured Streaming
13 .Major Lessons 1 Focus on ease-of-use in both exploration and production APIs to enable software best practices: composition, 2 testability, modularity
14 .Apache Spark 3.0 Others Structured 9% Streaming Spark SQL 3400+ patches from community 4% 46% Mllib 6% Easy to switch to from Spark 2.x PySpark 7% Tests & Docs 12% Spark Core 16%
15 . 3.0: SQL Engine Adaptive Query Execution (AQE): change execution plan at runtime to automatically set # of reducers and join algorithms Users tune # of reducers in 60% of clusters!
16 . 3.0: SQL Engine Adaptive Query Execution (AQE): change execution plan at runtime to automatically set # of reducers and join algorithms Sort Observe Sort Sort result size Coalesce (5 part.) Shuffle (50 part.) Shuffle (50 part.) Shuffle (50 part.) Filter Execute Filter Optimize Filter Scan Scan Scan Stage 1 Stage 1 Stage 1
17 . 3.0: SQL Engine Adaptive Query Execution (AQE): change execution plan at runtime to automatically set # of reducers and join algorithms Sort Observe Sort Sort result size Coalesce (5 part.) Shuffle (50 part.) Shuffle (50 part.) Shuffle (50 part.) Filter Execute Filter Optimize Filter Scan Scan Scan Stage 1 Stage 1 Stage 1
18 . 3.0: SQL Engine Adaptive Query Execution (AQE): change execution plan at runtime to automatically set # of reducers and join algorithms Change join algorithm TPC-DS 1 TB No-Stats with and without AQE Sort Merge Join Execute Sort Merge Join Optimize Broadcast Hash Join 500 400 Time (seconds) Sort Sort Sort Sort Broadcast 300 Shuffle Shuffle Shuffle Shuffle Shuffle Shuffle 200 Scan Filter Scan Filter Scan Filter 100 Stage 1 Stage 1 Stage 1 Estimate Scan Scan Scan 0 Actual Actual size: 100 MB Stage 2 size: 86 MB Stage 2 size: 86 MB Stage 2 q77 q5 q4 q11 a74 q84 q91 q49 q64 q84 Estimate Actual Actual size: size: size: AQE OFF AQEON 30 MB 8 MB 8 MB Accelerates TPC-DS queries up to 8x
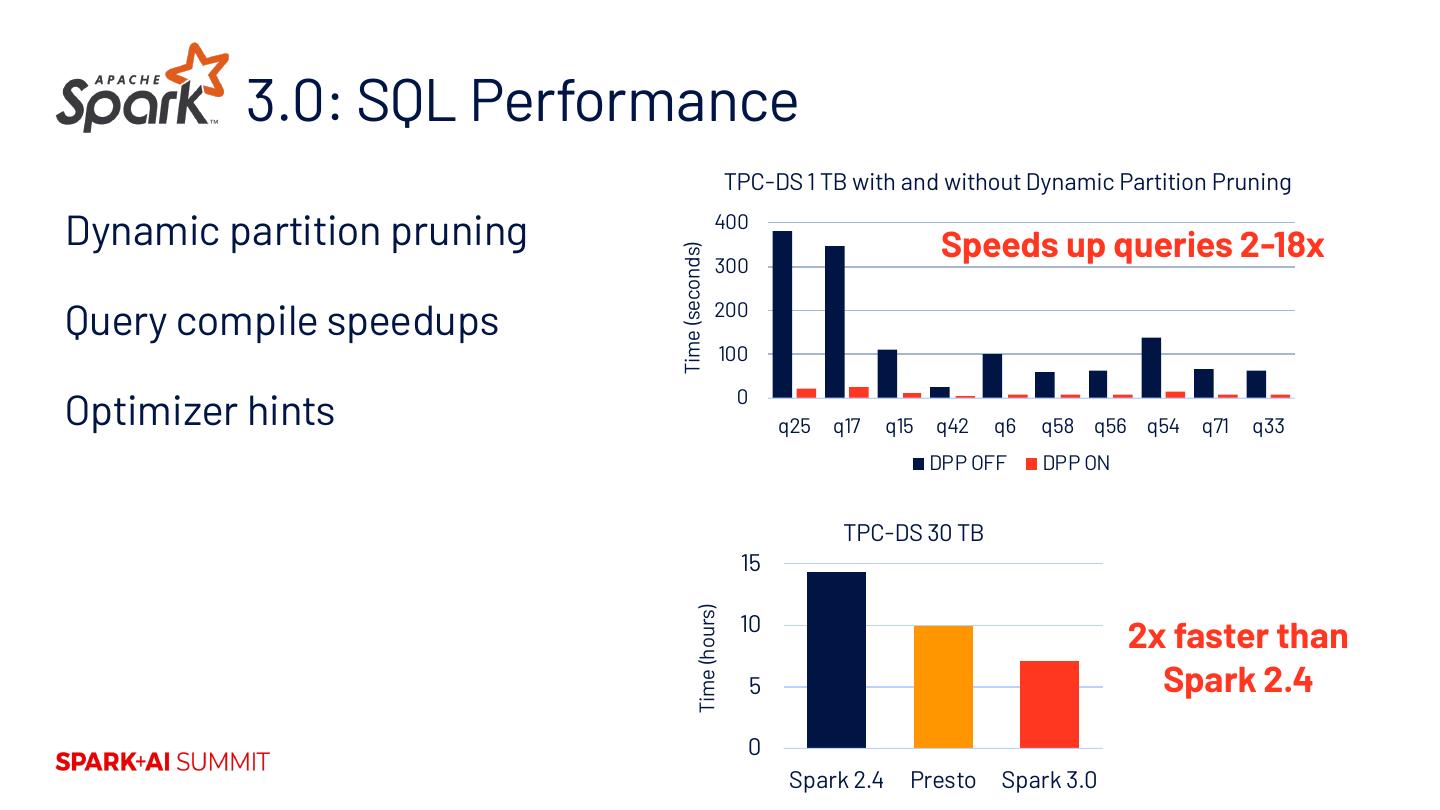
19 . 3.0: SQL Performance TPC-DS 1 TB with and without Dynamic Partition Pruning Dynamic partition pruning 400 Speeds up queries 2-18x Time (seconds) 300 Query compile speedups 200 100 Optimizer hints 0 q25 q17 q15 q42 q6 q58 q56 q54 q71 q33 DPP OFF DPP ON TPC-DS 30 TB 15 Time (hours) 10 2x faster than 5 Spark 2.4 0 Spark 2.4 Presto Spark 3.0
20 . 3.0: SQL Compatibility ANSI SQL language dialect and broad support ANSI Overflow ANSI Store ANSI Gregorian ANSI Reserved Checking Assignment Calendar Keywords
21 . 3.0: Python Usability Python type hints for Pandas UDFs Old API
22 . 3.0: Python and R Performance Python UDF Performance 6 Faster Apache Arrow-based Time (seconds) calls to Python user code 4 2 Vectorized SparkR calls 0 DataFrame.apply DataFrame.apply_batch (up to 40x faster) Spark 2.4.5 Spark 3.0.0 New Pandas function APIs SparkR Performance 800 699 Time (seconds) 600 400 241 202 200 21 1.2 5.7 16 6.2 0 createDF collect dapply gapply Native Vectorized
23 . 3.0: Other Features Structured Streaming UI Observable stream metrics SQL reference guide Data Source v2 API … Find out more about Spark 3.0 in Xiao Li’s talk!
24 .Other Apache Spark Ecosystem Projects Pandas API over Spark Reliable table storage Scale-out on Spark Large-scale genomics GPU-accelerated data science Visualization
25 .What is Koalas? import databricks.koalas as ks Implementation of Pandas APIs over Spark df = ks.read_csv(file) ▪ Easily port existing data science code df[‘x’] = df.y * df.z df.describe() df.plot.line(...) Launched at Spark+AI Summit 2019 Now up to 850,000 downloads per month (1/5th of PySpark!)
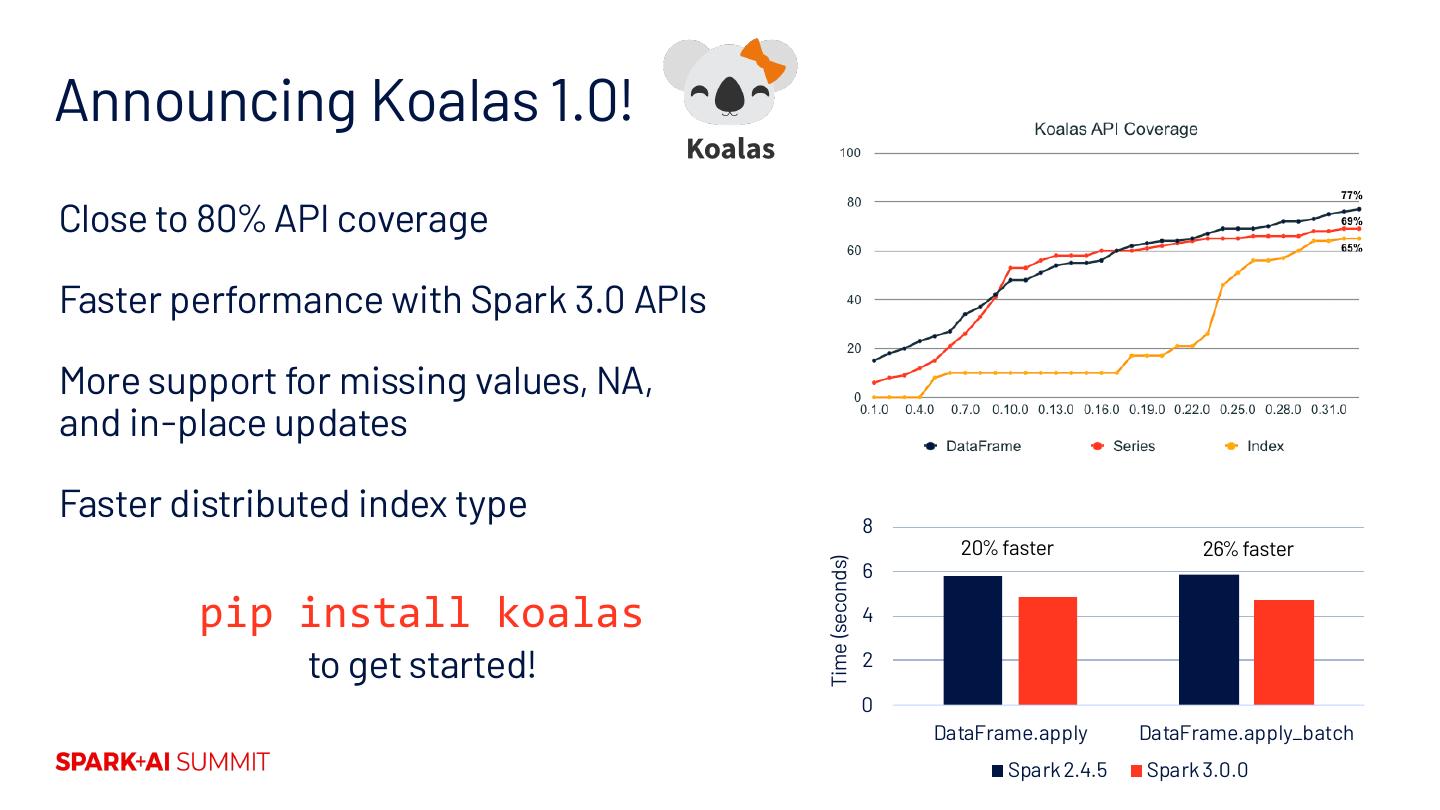
26 .Announcing Koalas 1.0! Close to 80% API coverage Faster performance with Spark 3.0 APIs More support for missing values, NA, and in-place updates Faster distributed index type 8 20% faster 26% faster Time (seconds) 6 pip install koalas 4 to get started! 2 0 DataFrame.apply DataFrame.apply_batch Spark 2.4.5 Spark 3.0.0
27 .What’s Next for the Apache Spark Ecosystem? If we step back, though software has made great strides, Data + AI apps are still more complex to build than they should be We’ll keep building on the two big lessons from past 10 years: ▪ Ease-of-use in both exploration and production ▪ APIs that connect to a rich software ecosystem
28 .OSS Spark Development Initiatives at Databricks Project Zen: Greatly improve Python usability ▪ Better error reporting ▪ API ports from Koalas ▪ Improved performance ▪ Pythonic API design Adaptive Query Execution: Cover most current optimizer decisions ANSI SQL: Run unmodified queries from major SQL engines
29 .Python Error Messages 😱 Traceback (most recent call last): Spark 2.4 File "<stdin>", line 1, in <module> File "/.../python/pyspark/sql/dataframe.py", line 427, in show print(self._jdf.showString(n, 20, vertical)) File "/.../python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__ File "/.../python/pyspark/sql/utils.py", line 98, in deco return f(*a, **kw) File "/.../python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 328, in get_return_value py4j.protocol.Py4JJavaError: An error occurred while calling o45.showString. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 10 in stage 2.0 failed 4 times, most recent failure: Lost task 10.3 in stage 2.0 (TID 18, 192.168.35.193, executor 3): org.apache.spark.api.python.PythonException: Traceback (most recent call last): File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 605, in main process() File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 597, in process serializer.dump_stream(out_iter, outfile) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 223, in dump_stream self.serializer.dump_stream(self._batched(iterator), stream) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 141, in dump_stream for obj in iterator: File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 212, in _batched for item in iterator: File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in mapper Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last): result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in <genexpr> result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 90, in <lambda> File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 605, in main return lambda *a: f(*a) File "/.../python/lib/pyspark.zip/pyspark/util.py", line 107, in wrapper return f(*args, **kwargs) File "<stdin>", line 3, in divide_by_zero process() ZeroDivisionError: division by zero at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:516) at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:81) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 597, in process at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:64) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:469) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:489) serializer.dump_stream(out_iter, outfile) at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 223, in dump_stream at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:753) at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898) self.serializer.dump_stream(self._batched(iterator), stream) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373) at org.apache.spark.rdd.RDD.iterator(RDD.scala:337) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 141, in dump_stream at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:469) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:472) for obj in iterator: at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 212, in _batched Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2117) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2066) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2065) for item in iterator: at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) Java at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2065) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in mapper at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1021) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1021) at scala.Option.foreach(Option.scala:407) stuff at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1021) result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2297) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2246) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2235) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in <genexpr> at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:823) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2108) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2129) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2148) result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:467) at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:420) at org.apache.spark.sql.execution.CollectLimitExec.executeCollect(limit.scala:47) at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3653) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 90, in <lambda> at org.apache.spark.sql.Dataset.$anonfun$head$1(Dataset.scala:2695) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3644) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) return lambda *a: f(*a) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3642) File "/.../python/lib/pyspark.zip/pyspark/util.py", line 107, in wrapper at org.apache.spark.sql.Dataset.head(Dataset.scala:2695) at org.apache.spark.sql.Dataset.take(Dataset.scala:2902) at org.apache.spark.sql.Dataset.getRows(Dataset.scala:300) at org.apache.spark.sql.Dataset.showString(Dataset.scala:337) return f(*args, **kwargs) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) File "<stdin>", line 3, in divide_by_zero at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) ZeroDivisionError: division by zero at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:748) Caused by: org.apache.spark.api.python.PythonException: Traceback (most recent call last): File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 605, in main process() File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 597, in process serializer.dump_stream(out_iter, outfile) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 223, in dump_stream self.serializer.dump_stream(self._batched(iterator), stream) File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 141, in dump_stream for obj in iterator: File "/.../python/lib/pyspark.zip/pyspark/serializers.py", line 212, in _batched for item in iterator: File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in mapper result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 450, in <genexpr> result = tuple(f(*[a[o] for o in arg_offsets]) for (arg_offsets, f) in udfs) File "/.../python/lib/pyspark.zip/pyspark/worker.py", line 90, in <lambda> return lambda *a: f(*a) File "/.../python/lib/pyspark.zip/pyspark/util.py", line 107, in wrapper return f(*args, **kwargs) File "<stdin>", line 3, in divide_by_zero ZeroDivisionError: division by zero at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.handlePythonException(PythonRunner.scala:516) at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:81) at org.apache.spark.sql.execution.python.PythonUDFRunner$$anon$2.read(PythonUDFRunner.scala:64) at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:469) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:489) at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) Java at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage2.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:753) at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898) stuff at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373) at org.apache.spark.rdd.RDD.iterator(RDD.scala:337) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:469) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:472) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more
1点赞
2收藏
3秒后跳转登录页面
去登陆

