








































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
用Analytics-Zoo实现基于深度学习的胸腔疾病AI诊疗辅助
简介:
本次分享主要介绍如何利用Analytics Zoo和NIH胸部X光影像数据集,在Apache Spark集群上实现基于深度学习的胸腔疾病分类,为医生提供端到端的胸腔疾病AI诊疗辅助。
有兴趣的同学,可以提前关注此开源项目:https://github.com/intel-analytics/analytics-zoo
主题:
用Analytics-Zoo实现基于深度学习的胸腔疾病AI诊疗辅助
时间:
2020.4.29(周三)19:00
参与方式:
扫描下方二维码加入钉钉群,群内直接观看
或点击直播间链接:
https://developer.aliyun.com/live/2719?spm=5176.8068049.0.0.27366d19wPA7FZ
讲师简介:
龚奇源
博士,英特尔机器学习专家。从事多年数据隐私和机器学习研究,2017年加入英特尔,目前负责Analytics-Zoo中ClusterServing、Streaming、OpenVINO和推理优化等工作。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
邀请你加入钉钉群聊阿里云E-MapReduce交流2群,点击进入查看详情 https://qr.dingtalk.com/action/joingroup?code=v1,k1,cNBcqHn4TvG0iHpN3cSc1B86D1831SGMdvGu7PW+sm4=&_dt_no_comment=1&origin=11
邀请你加入钉钉群聊Apache Spark中国技术交流社区,点击进入查看详情 https://qr.dingtalk.com/action/joingroup?code=v1,k1,X7S/0/QcrLMkK7QZ5sw2oTvoYW49u0g5dvGu7PW+sm4=&_dt_no_comment=1&origin=11
微信公众号:Apache Spark技术交流社区
展开查看详情
1 . What is Analytics Zoo Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL on for Apache Spark Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale
2 .用 实现基于 的 胸腔疾病 Analytics Zoo: Building Unified Big Data Analytics and AI Pipelines 龚奇源 (Qiyuan Gong) 机器学习与数据隐私专家 2020/04/30
3 . Agenda Background • Big data & Deep Learning • Analytics Zoo AI-assisted Radiology Using Apache Spark and Analytics Zoo • Motivation & Problem statement • Training Chest X-ray Model • Inference & Serving Q&A
4 .Background
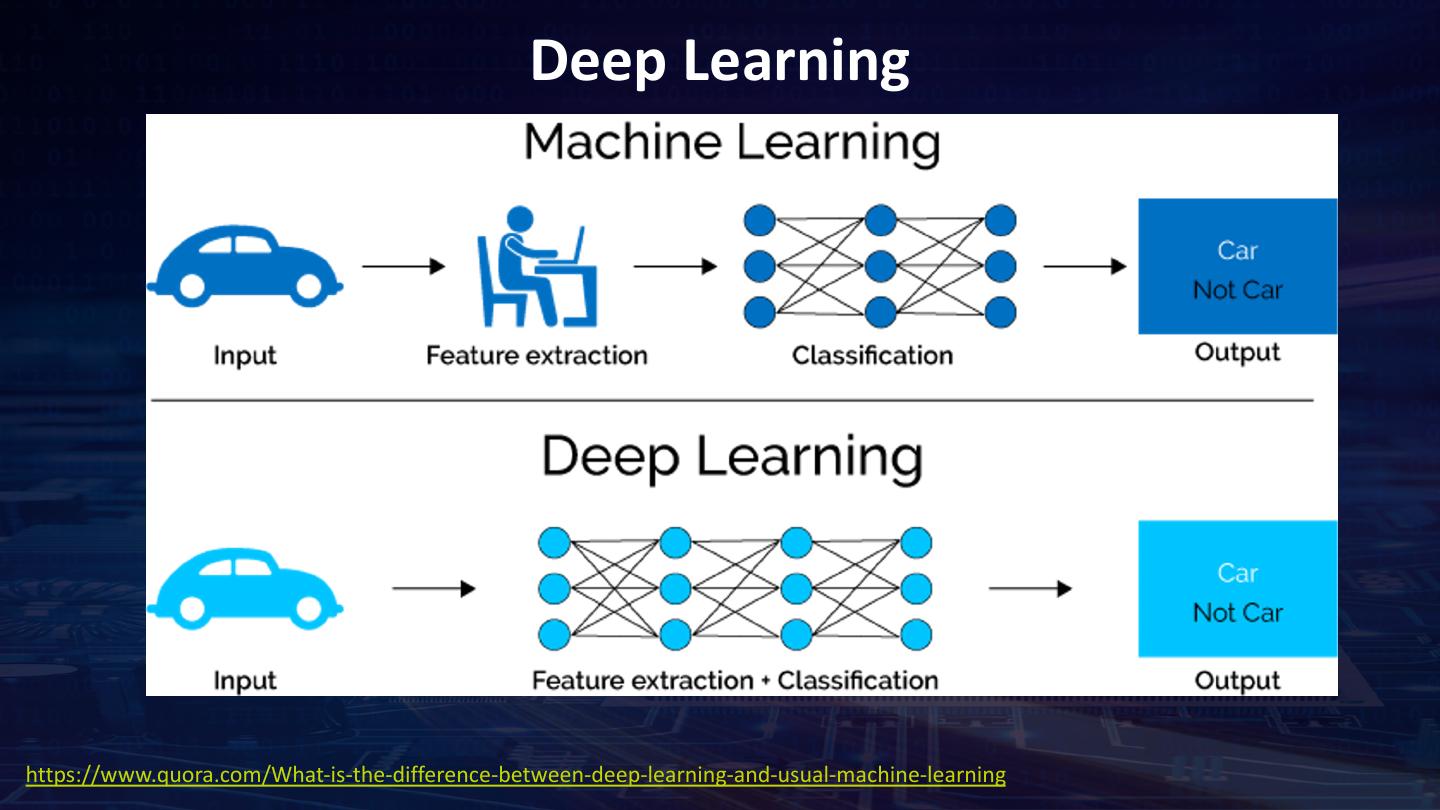
5 . Deep Learning https://www.quora.com/What-is-the-difference-between-deep-learning-and-usual-machine-learning
6 .Deep Learning
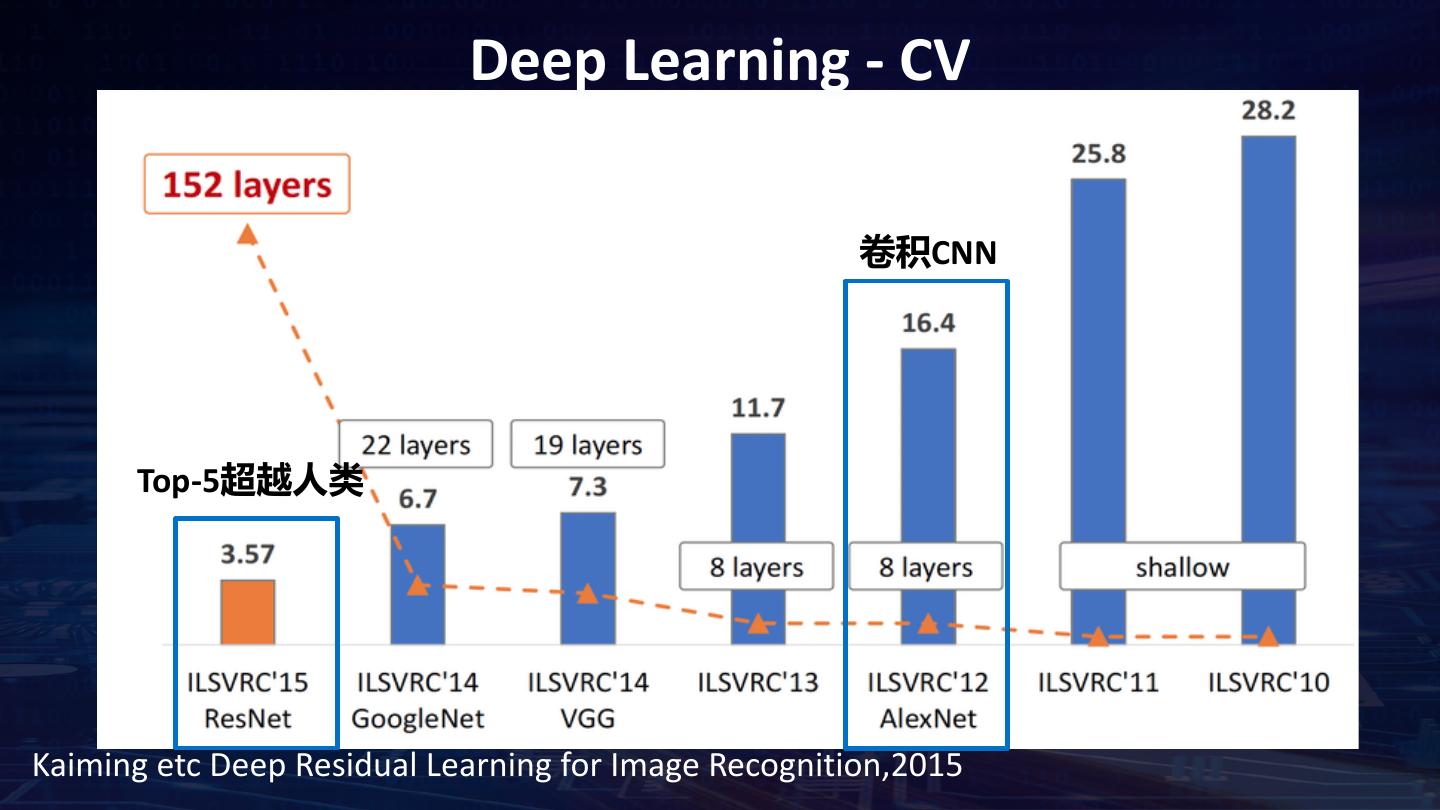
7 . Deep Learning - CV 卷积CNN Top-5超越人类 Kaiming etc Deep Residual Learning for Image Recognition,2015
8 .Deep Learning “Machine Learning Yearning”, Andrew Ng, 2016
9 . Deep Learning 但天下没有免费的午餐 (no free launch) • Deep Learning需要大量算力 (计算密集) • Deep Learning需要大量数据 (data hungry) “人工”智能 足够的存储和算力 https://medium.com/syncedreview/data-annotation-the-billion-dollar-business-behind-ai-breakthroughs-d929b0a50d23
10 . Deep Learning 2016年 Google Alpha Go 击败李世石 • 现场的Alpha Go所使用的计算资源 • 48 CPU, 8 GPU ≈ 24 Servers • 其实还有一个Distributed Alpha Go • 1202 CPU, 176 GPU ≈ 601 Servers https://www.nature.com/articles/nature16961 https://newsroom.intel.com/editorials/re-architecting-data-center- intel-xeon-processor-scalable-family/#gs.hi35lo
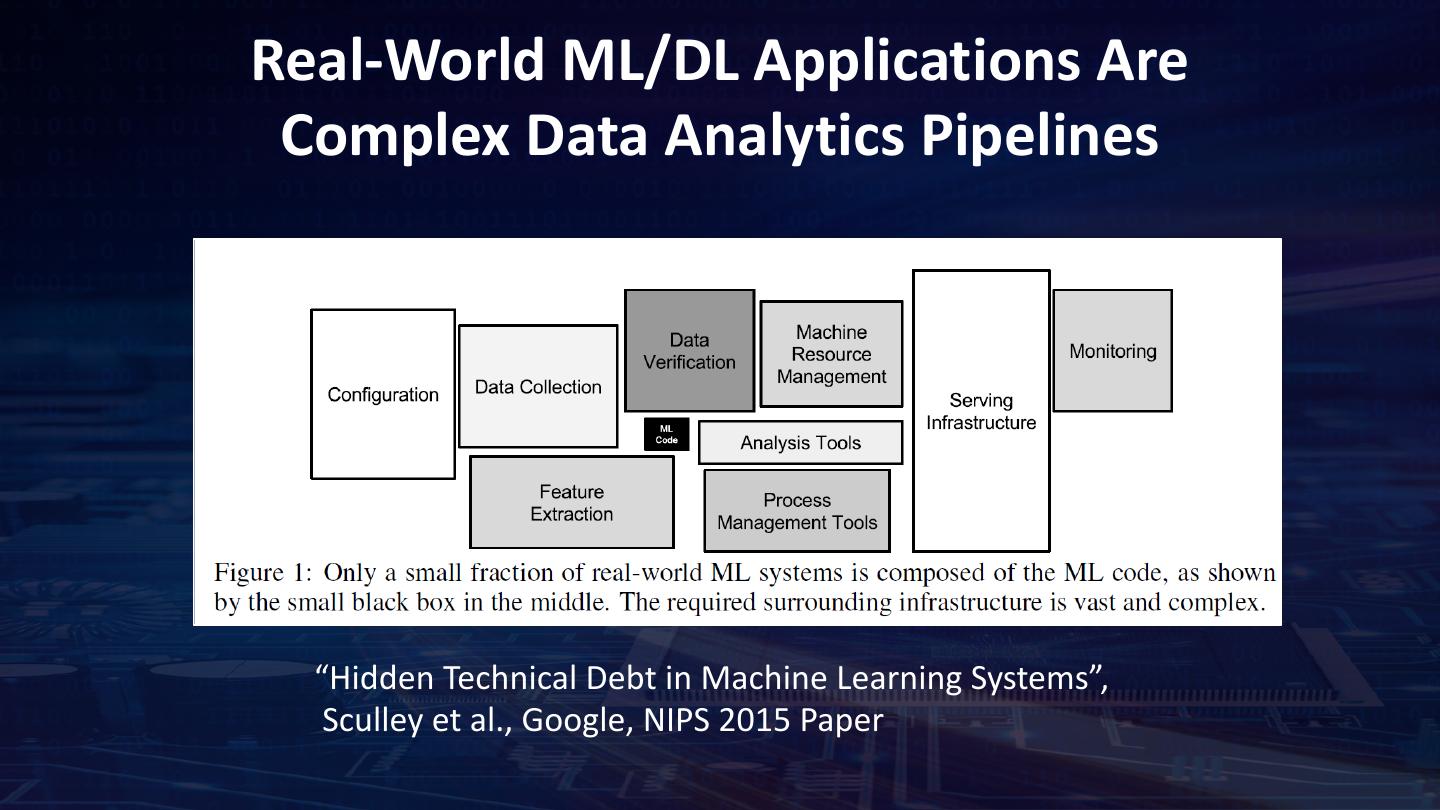
11 .Real-World ML/DL Applications Are Complex Data Analytics Pipelines “Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 Paper
12 . Deep Learning 获取 / 存储 清洗 / 准备 分析 / 建模 部署 / 可视化 集成的数据流水线 数据管理 数据分析 数据科学及人工智能
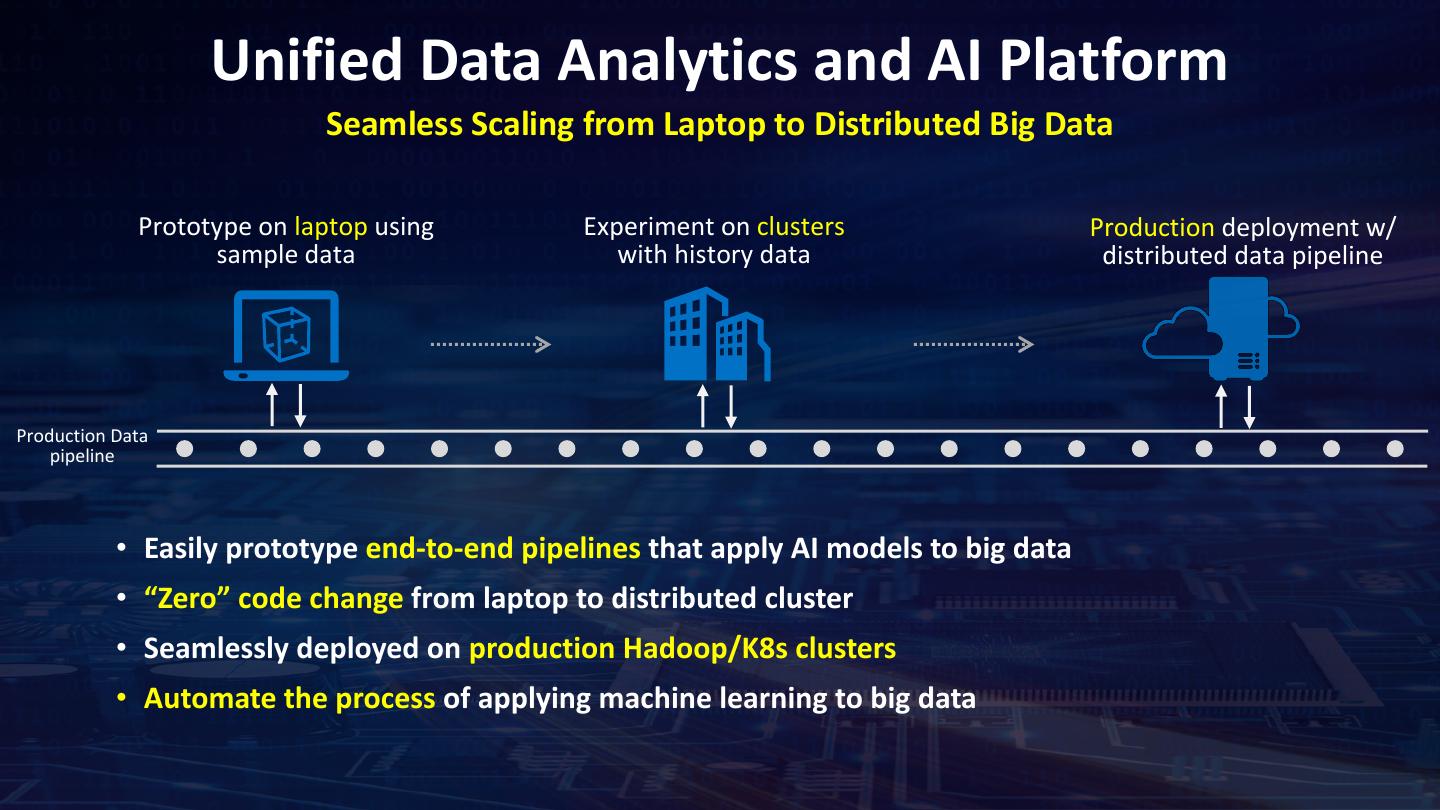
13 . Unified Data Analytics and AI Platform Seamless Scaling from Laptop to Distributed Big Data Prototype on laptop using Experiment on clusters Production deployment w/ sample data with history data distributed data pipeline Production Data pipeline • Easily prototype end-to-end pipelines that apply AI models to big data • “Zero” code change from laptop to distributed cluster • Seamlessly deployed on production Hadoop/K8s clusters • Automate the process of applying machine learning to big data
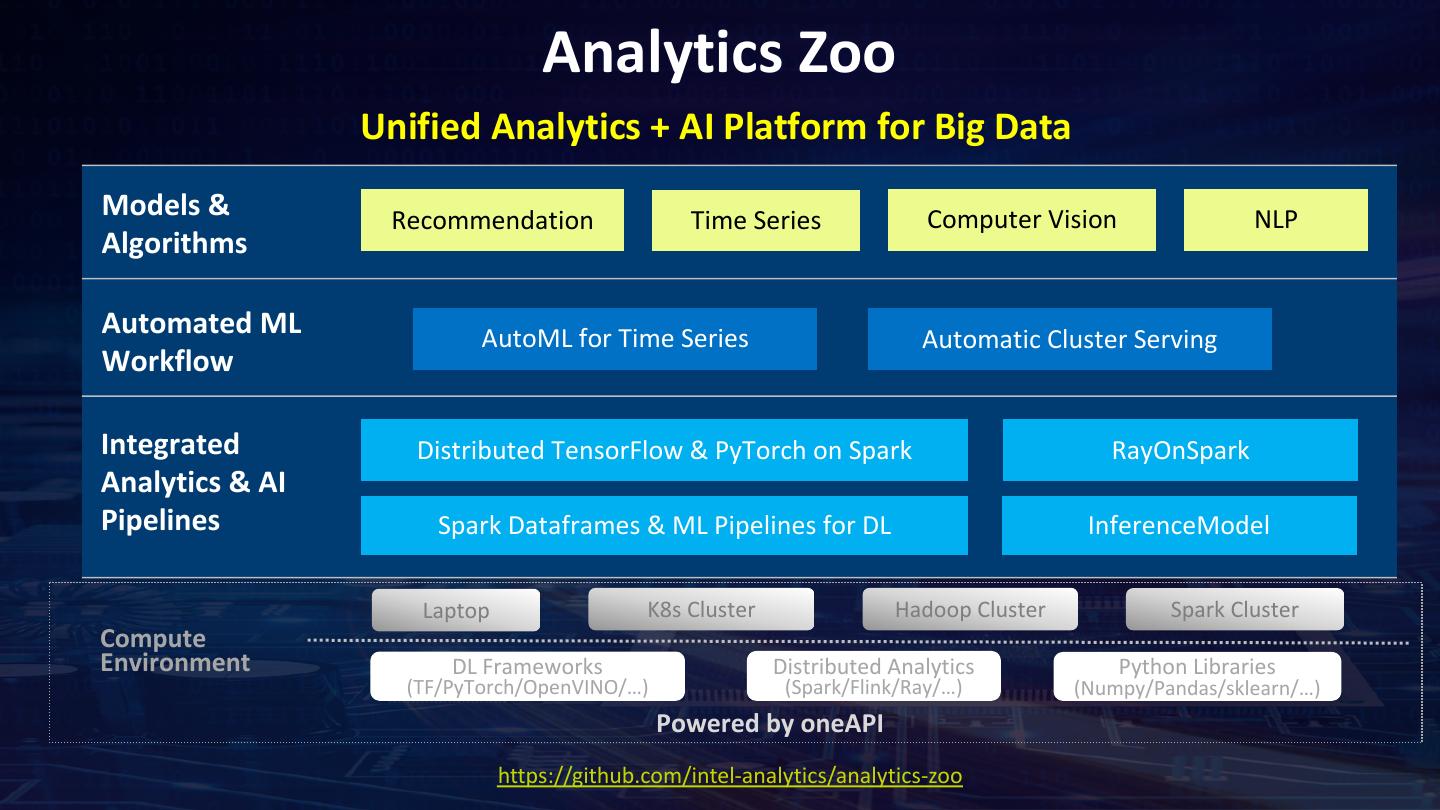
14 . Analytics Zoo Unified Analytics + AI Platform for Big Data Models & Recommendation Time Series Computer Vision NLP Algorithms Automated ML AutoML for Time Series Automatic Cluster Serving Workflow Integrated Distributed TensorFlow & PyTorch on Spark RayOnSpark Analytics & AI Pipelines Spark Dataframes & ML Pipelines for DL InferenceModel Laptop K8s Cluster Hadoop Cluster Spark Cluster Compute Environment DL Frameworks Distributed Analytics Python Libraries (TF/PyTorch/OpenVINO/…) (Spark/Flink/Ray/…) (Numpy/Pandas/sklearn/…) Powered by oneAPI https://github.com/intel-analytics/analytics-zoo
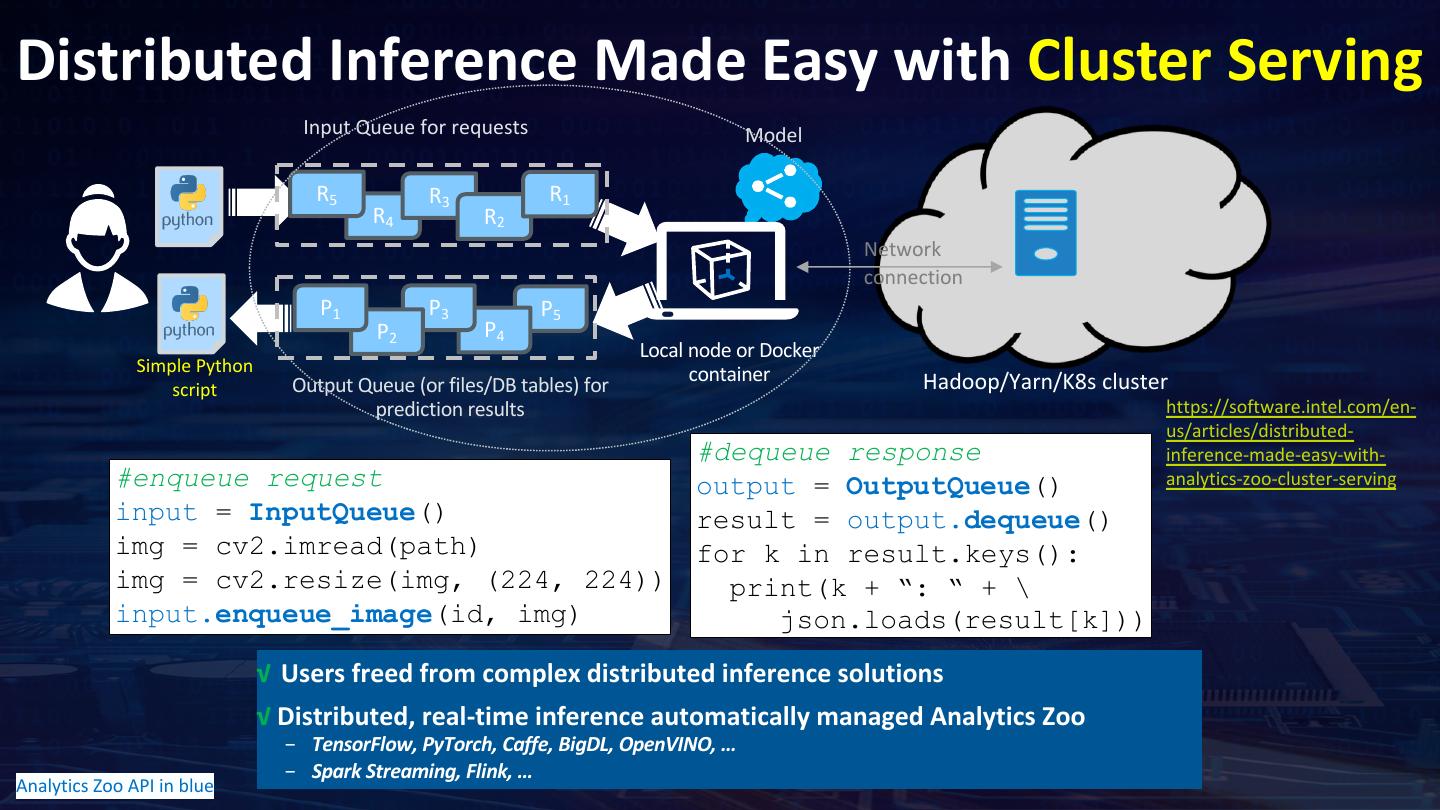
15 .AI-assisted Radiology Using Apache Spark and Analytics Zoo AI-assisted Radiology Using Distributed Deep Learning on Apache Spark and Analytics Zoo Using Deep Learning on Apache Spark to diagnose thoracic pathology from chest X-rays https://github.com/dell-ai-engineering/BigDL-ImageProcessing-Examples
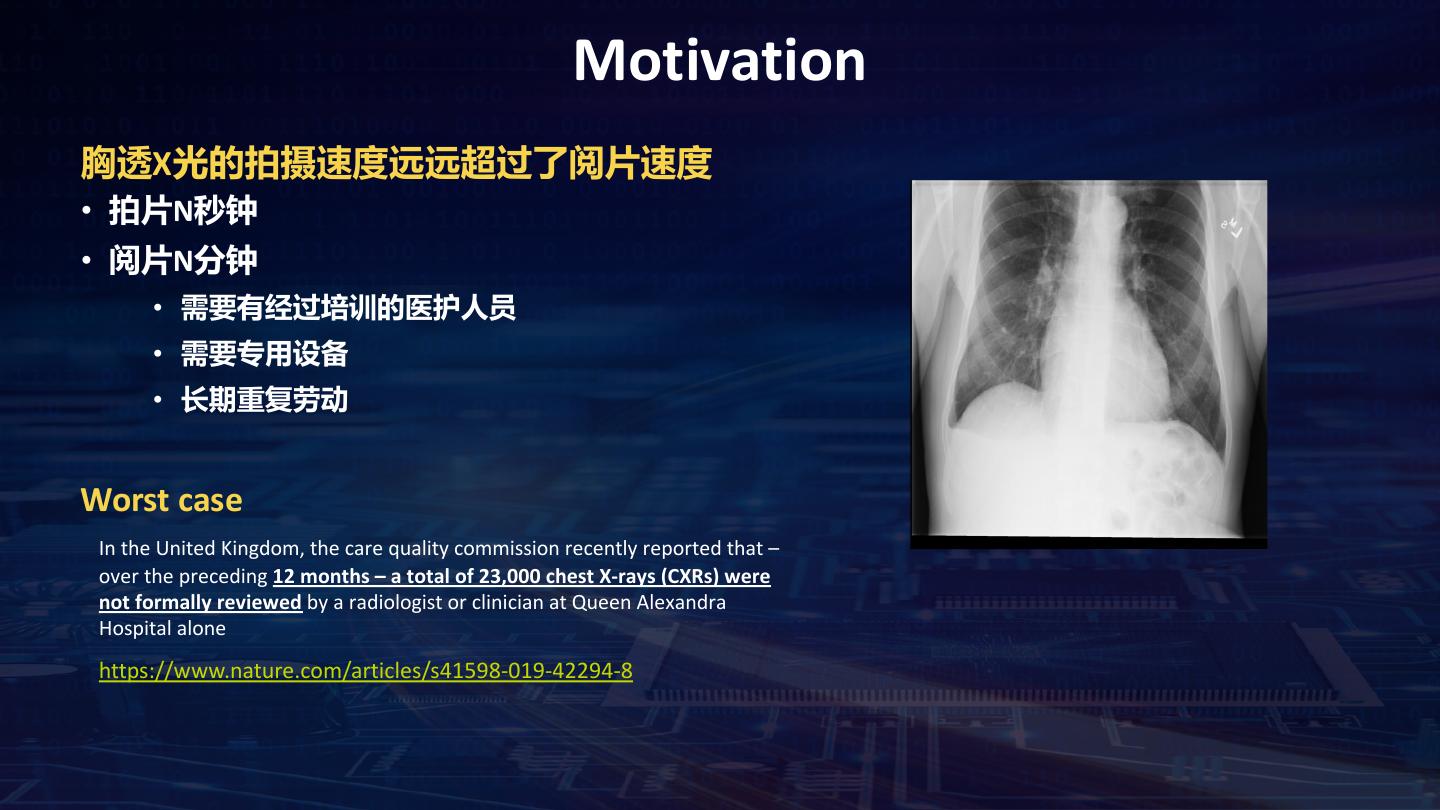
16 . Motivation 胸透X光的拍摄速度远远超过了阅片速度 • 拍片N秒钟 • 阅片N分钟 • 需要有经过培训的医护人员 • 需要专用设备 • 长期重复劳动 Worst case In the United Kingdom, the care quality commission recently reported that – over the preceding 12 months – a total of 23,000 chest X-rays (CXRs) were not formally reviewed by a radiologist or clinician at Queen Alexandra Hospital alone https://www.nature.com/articles/s41598-019-42294-8
17 . Motivation Pain points • Review X-ray is a bottleneck during X-ray related diagnosis • Long analysis time • Need radiologist or clinician • Duplicated hard work Can we use deep learning to accelerate X-ray analysis? • Do we have training dataset? (YES, ChestX-ray14) • What/which we can do? • Multiple-label image classification (YES) • Object detection (No, dataset don’t have enough annotations) • Image segmentation (No, dataset don’t have enough annotations)
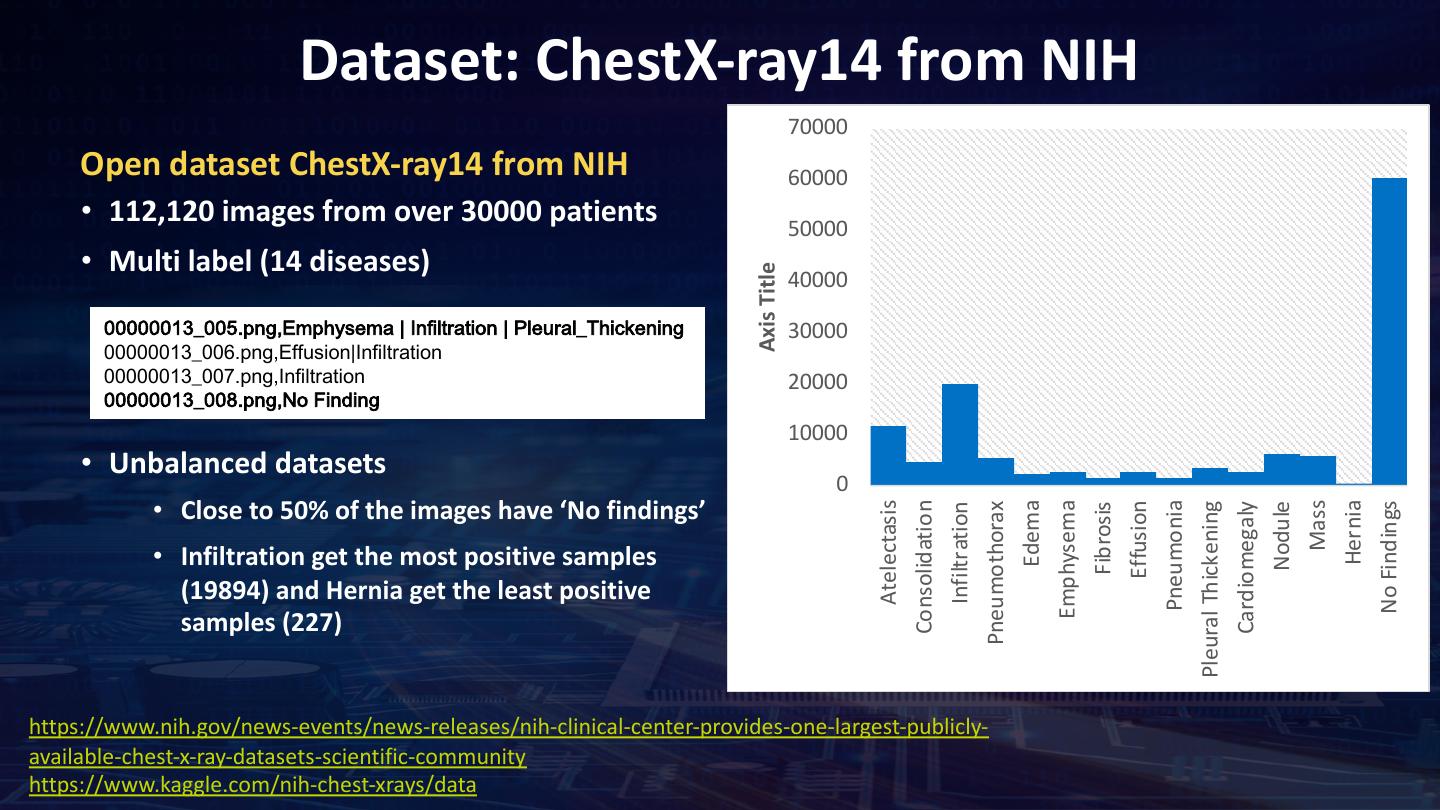
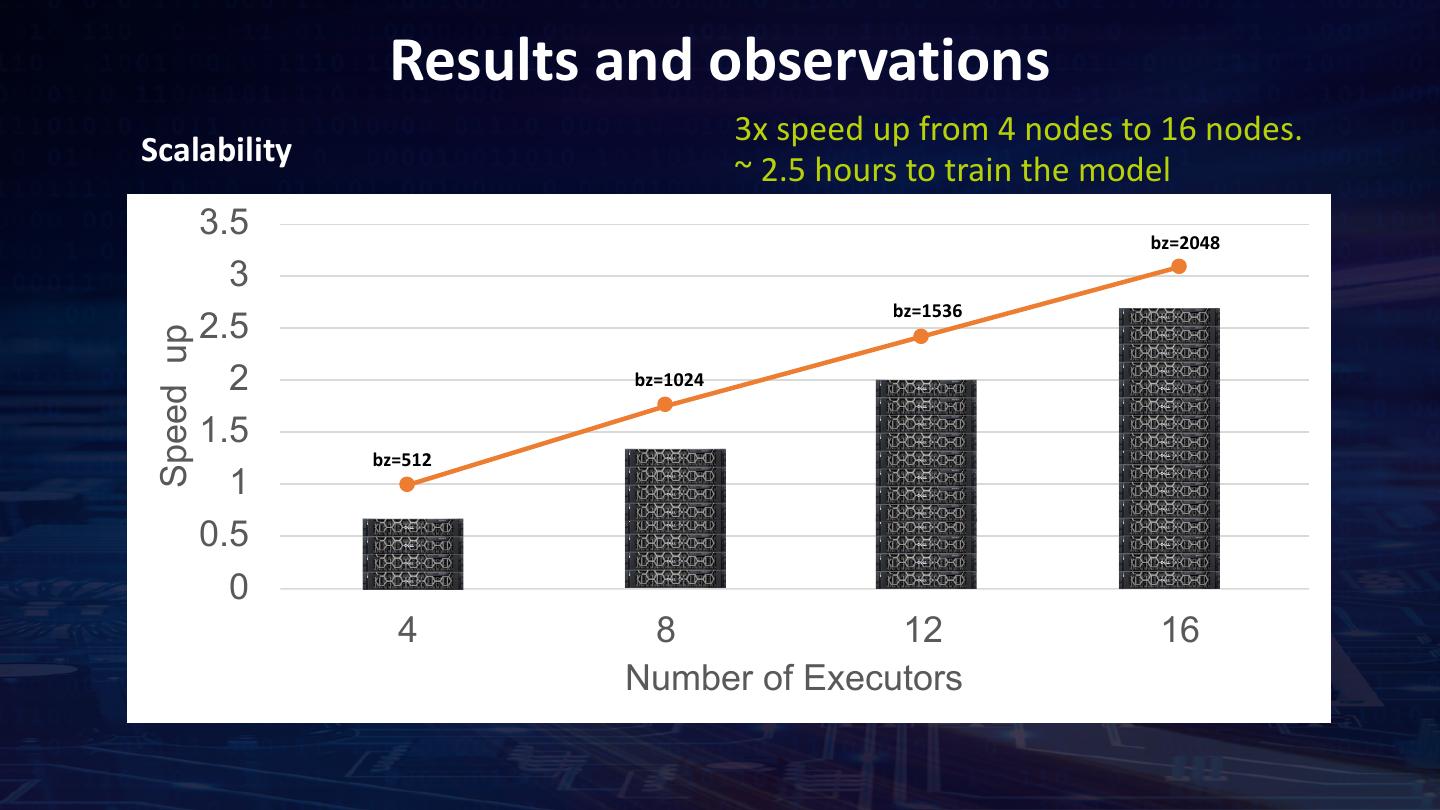
18 . Dataset: ChestX-ray14 from NIH 70000 Open dataset ChestX-ray14 from NIH 60000 • 112,120 images from over 30000 patients 50000 • Multi label (14 diseases) Axis Title 40000 00000013_005.png,Emphysema | Infiltration | Pleural_Thickening 30000 00000013_006.png,Effusion|Infiltration 00000013_007.png,Infiltration 20000 00000013_008.png,No Finding 10000 • Unbalanced datasets 0 • Close to 50% of the images have ‘No findings’ Edema Hernia Consolidation Pneumonia Mass Emphysema Atelectasis Pleural Thickening Cardiomegaly Pneumothorax Effusion No Findings Fibrosis Infiltration Nodule • Infiltration get the most positive samples (19894) and Hernia get the least positive samples (227) https://www.nih.gov/news-events/news-releases/nih-clinical-center-provides-one-largest-publicly- available-chest-x-ray-datasets-scientific-community https://www.kaggle.com/nih-chest-xrays/data
19 . Related works ChestX-Ray8 (published ChestXray14) • Transfer learning with Alexnet, Googlenet, Resnet50 • Resnet50 perform best CheXNet (by Stanford, Andrew NG etc) • Densenet121 for Pneumonia & multi-label • AI for Medical Diagnosis Others (check references) ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases https://stanfordmlgroup.github.io/projects/chexnet/ https://www.coursera.org/learn/ai-for-medical-diagnosis/
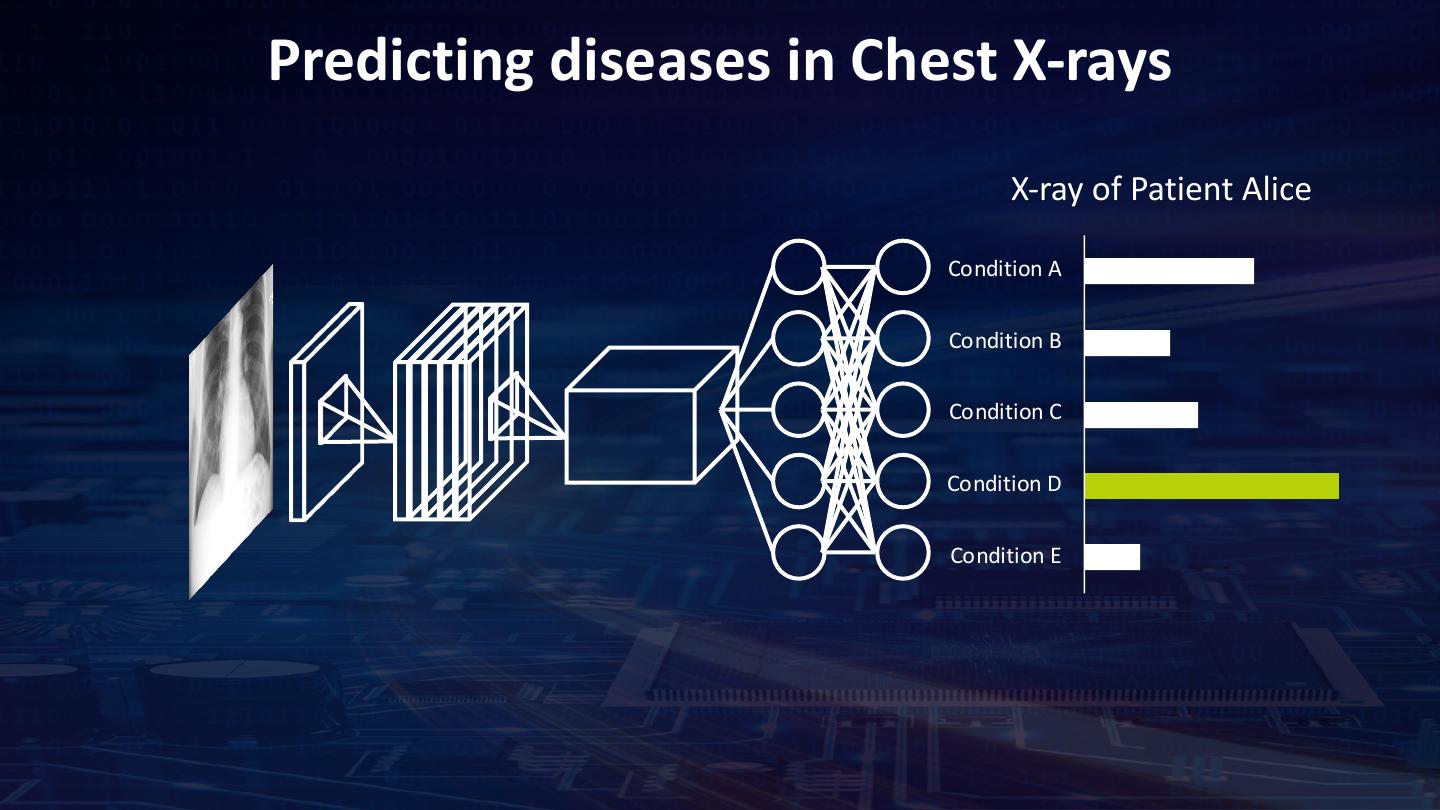
20 . Predicting diseases in Chest X-rays Develop a ML pipeline in Apache Spark and train a deep learning model to predict disease in Chest X-rays • An integrated ML pipeline with Analytics Zoo on Apache Spark • Demonstrate feature engineering and transfer learning APIs in Analytics Zoo • Use Spark worker nodes to train at scale X-ray of Patient Alice AI-assisted Radiology Condition A • Give real-time Suggestions Condition B • Review results Condition C Condition D Condition E ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases
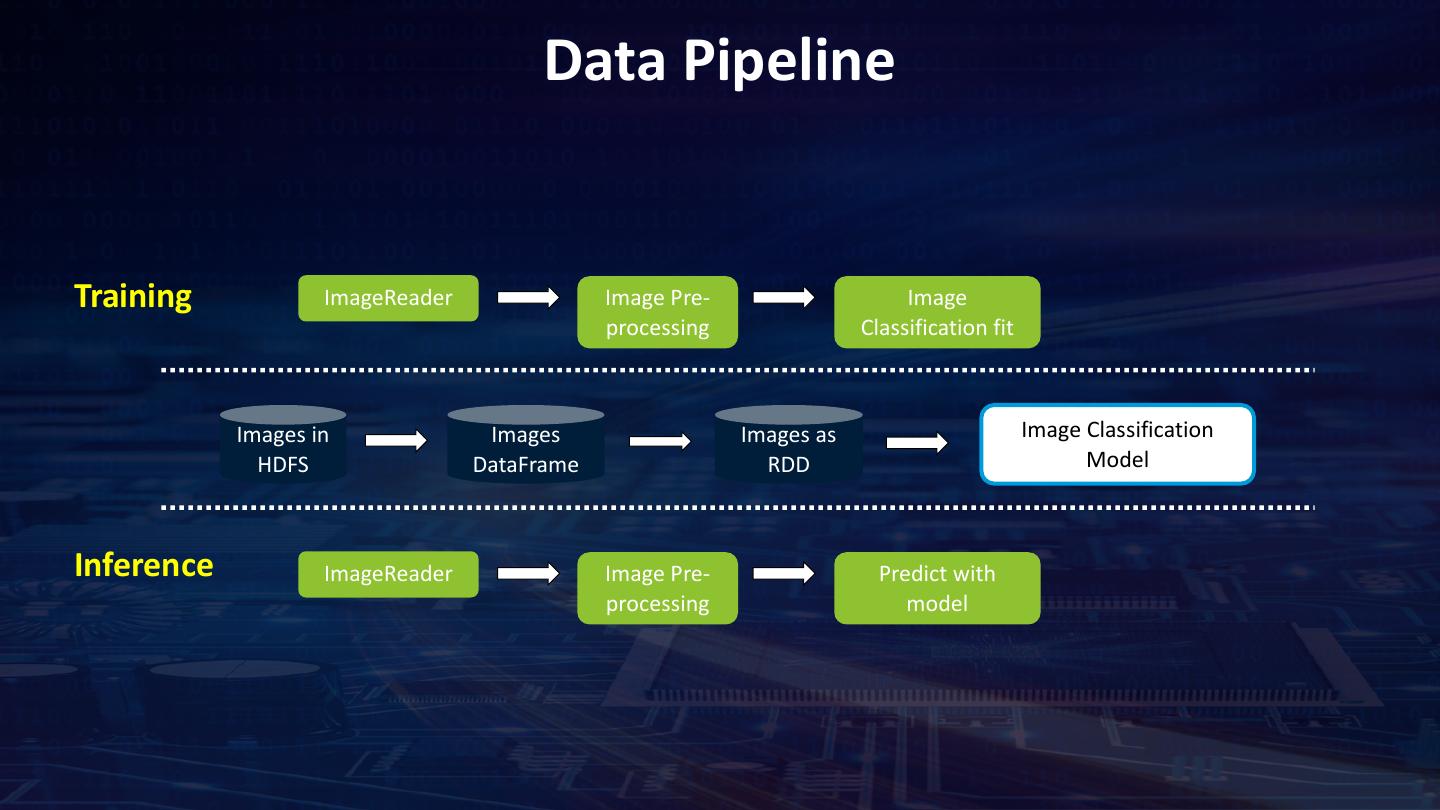
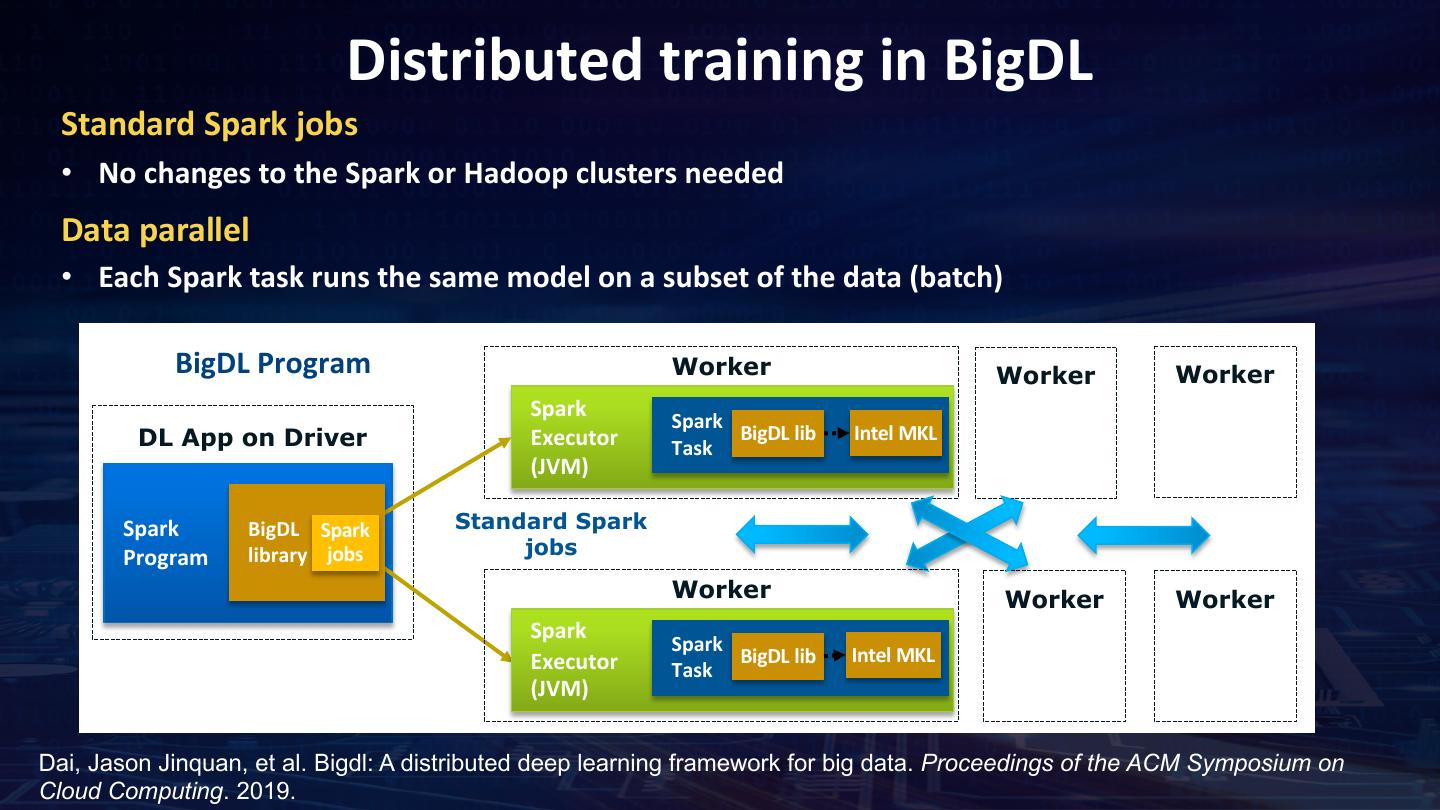
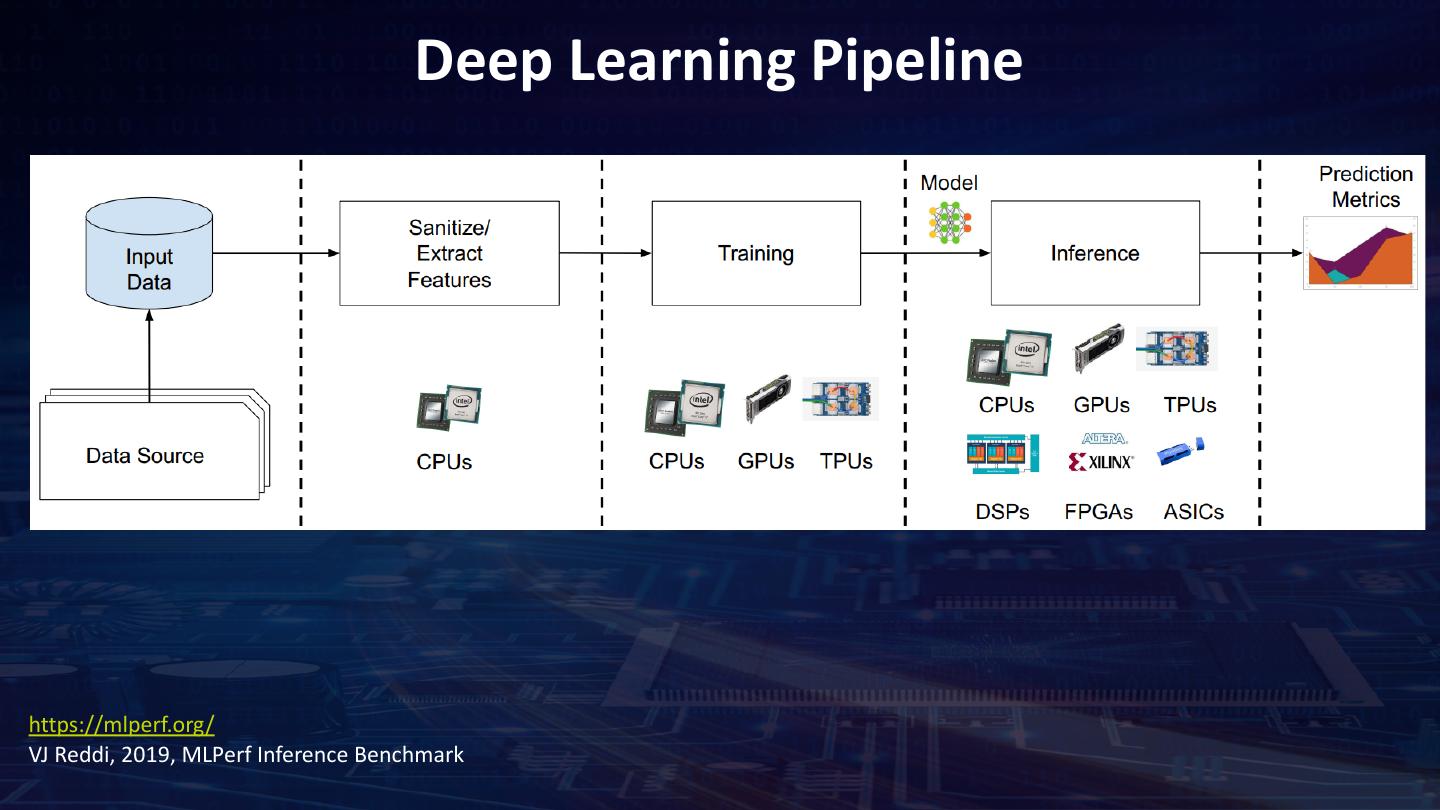
21 . Data Pipeline Training ImageReader Image Pre- Image processing Classification fit Images in Images Images as Image Classification HDFS DataFrame RDD Model Inference ImageReader Image Pre- Predict with processing model
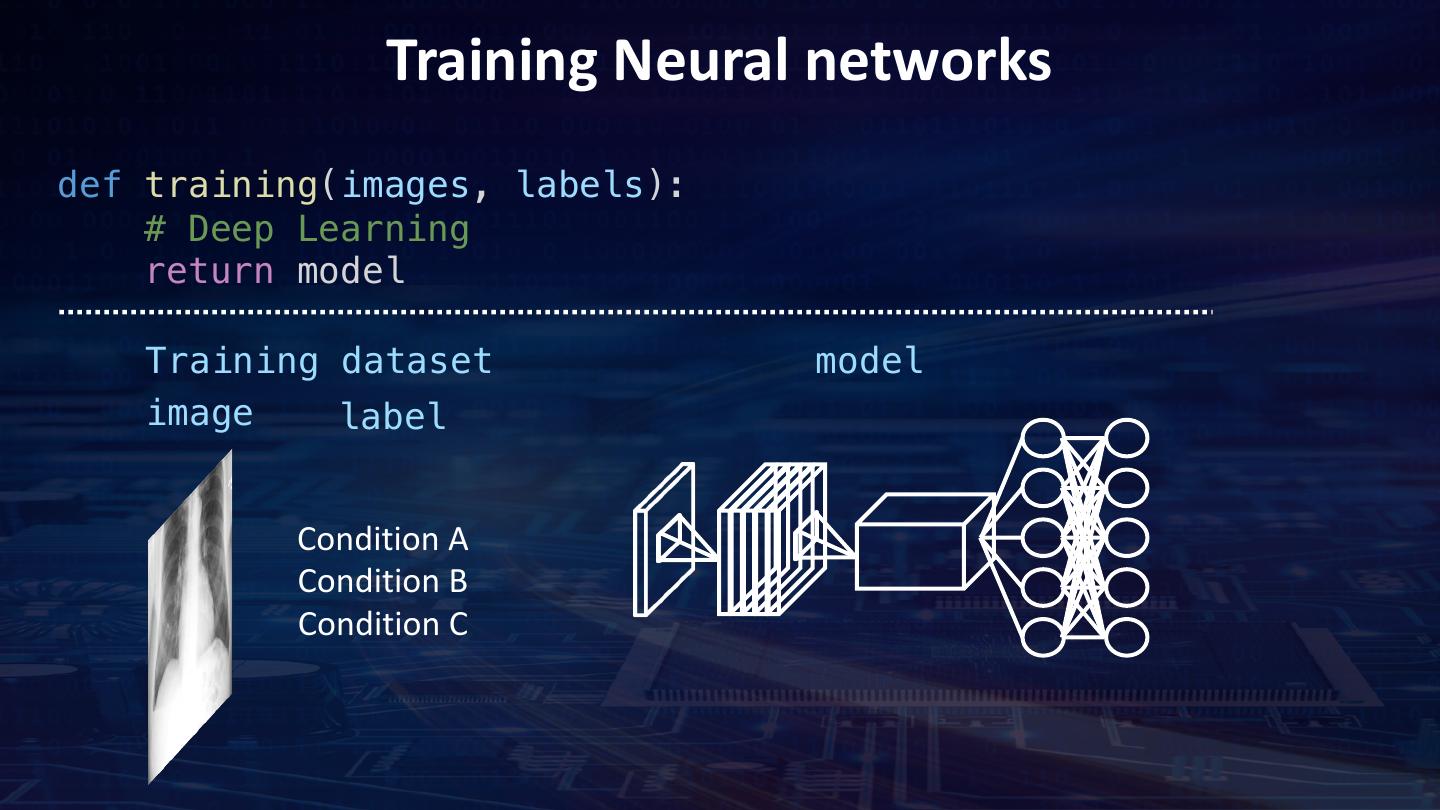
22 . Training Neural networks def training(images, labels): # Deep Learning return model Training dataset model image label Condition A Condition B Condition C
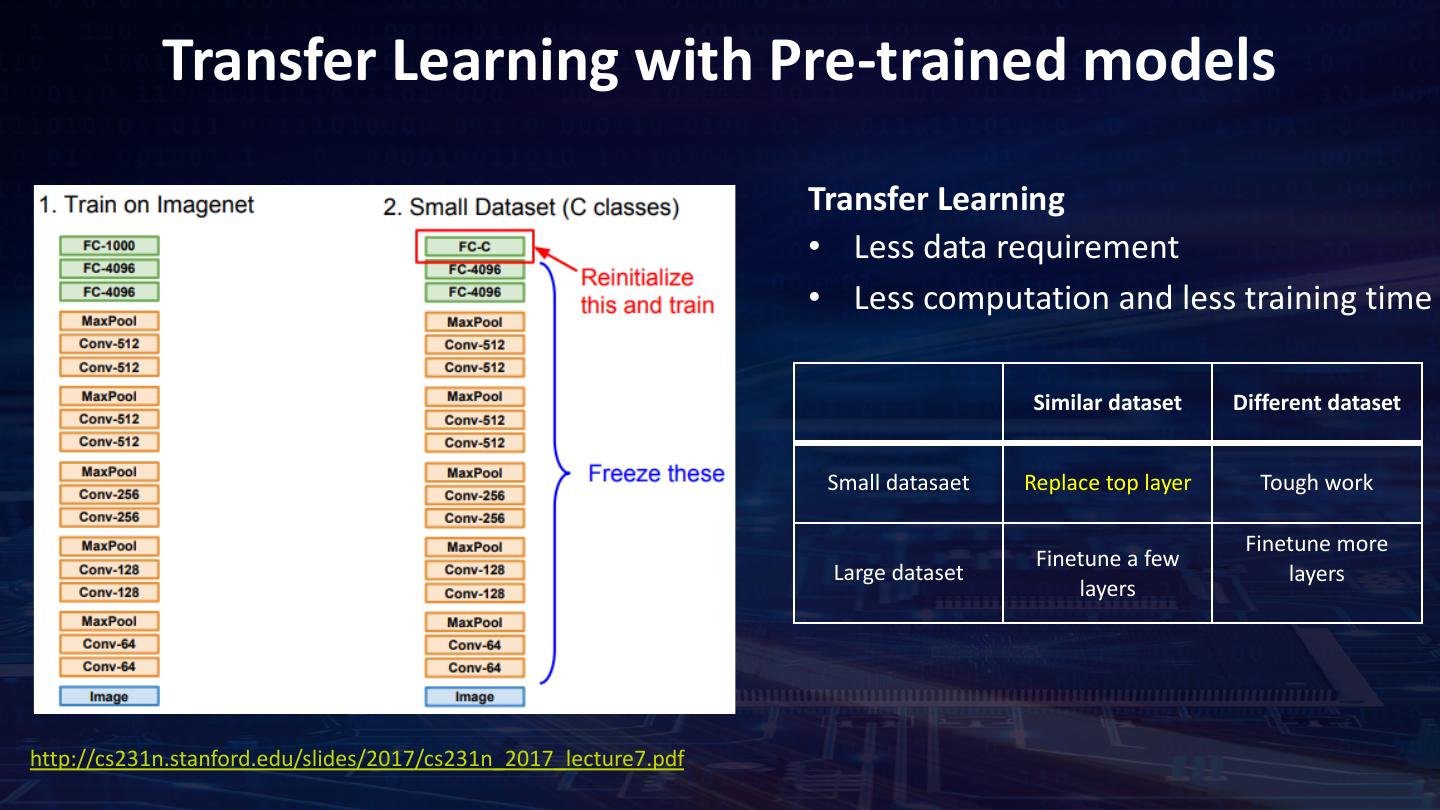
23 . Transfer Learning with Pre-trained models Transfer Learning • Less data requirement • Less computation and less training time Similar dataset Different dataset Small datasaet Replace top layer Tough work Finetune more Finetune a few Large dataset layers layers http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
24 .Training: Building the X-ray Model Read the X-ray images Pre-Processing Define the model Define optimizer Training the model
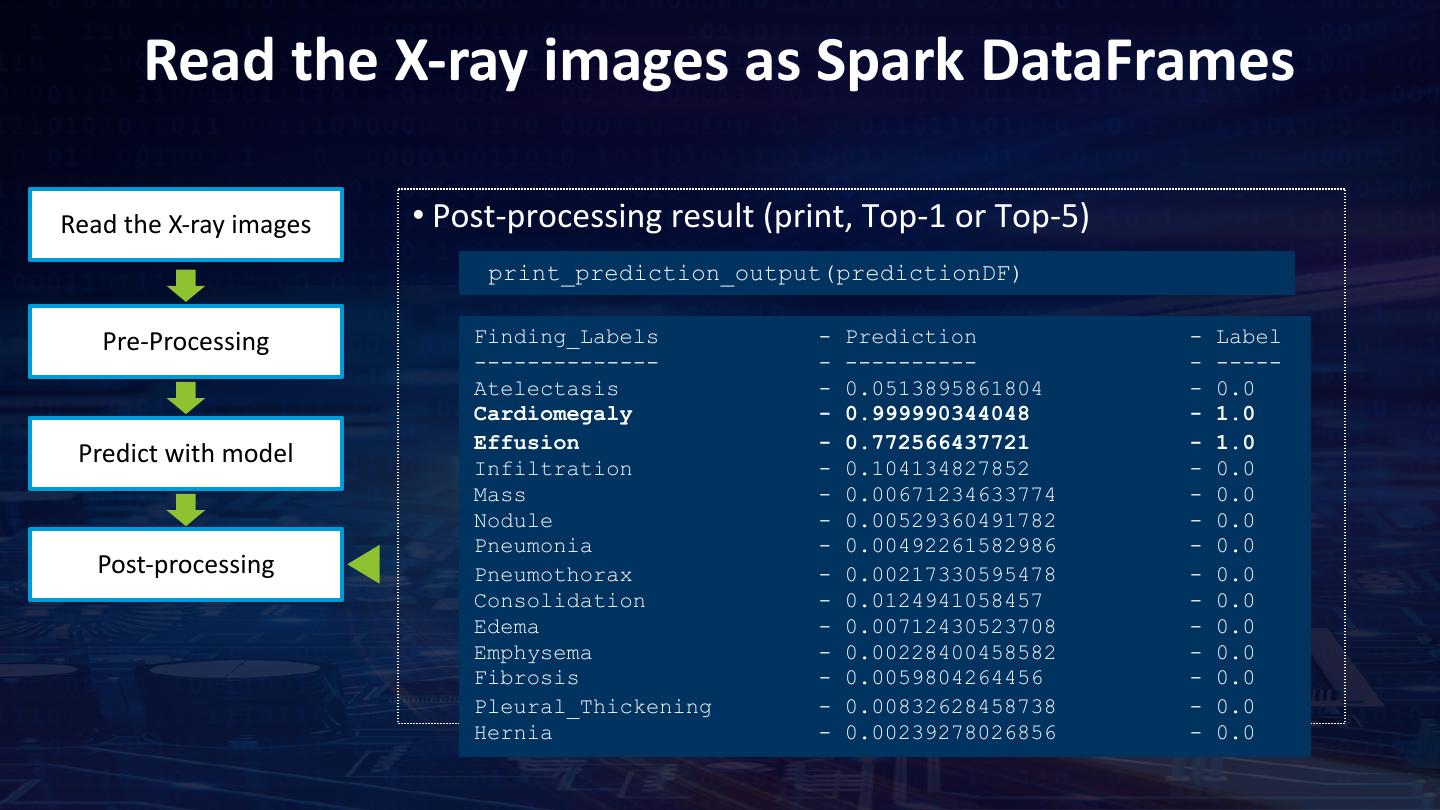
25 . Read the X-ray images as Spark DataFrames Read the X-ray images • InitializeNNContext and load Xray images into DataFrames using NNImageReader Pre-Processing from zoo.pipeline.nnframes import NNImageReader imageDF = NNImageReader.readImages(image_path, sc, resizeH=256, resizeW=256, image_codec=1) Define the model • Process loaded X-ray images and add labels (another DataFrame) using Spark transformations Define optimizer trainingDF = imageDF.join(labelDF, on="Image_Index", how="inner") Training the model
26 . Feature Engineering – Image Pre-processing Read the X-ray images In-built APIs for feature engineering using ChainedPreprocessing API ImageCenterCrop(224, 224) Pre-Processing Random flipImageFlip() and brightness Define the model ImageChannelNormalize() ImageChannelNormalize() Define optimizer ImageMatToTensor() To Tensor() Training the model
27 . Defining the model with Transfer Learning APIs Read the X-ray images • Load a pre-trained model using Net.load_bigdl. The model is trained with ImageNet dataset – ResNet 50 Pre-Processing – DenseNet – Inception • Remove the final softmax layer of ResNet-50 Define the model • Add new input (for resized x-ray images) and output layer (to predict the 14 diseases). Activation function is Sigmoid Define optimizer • Avoid overfitting – Regularization Training the model – Dropout
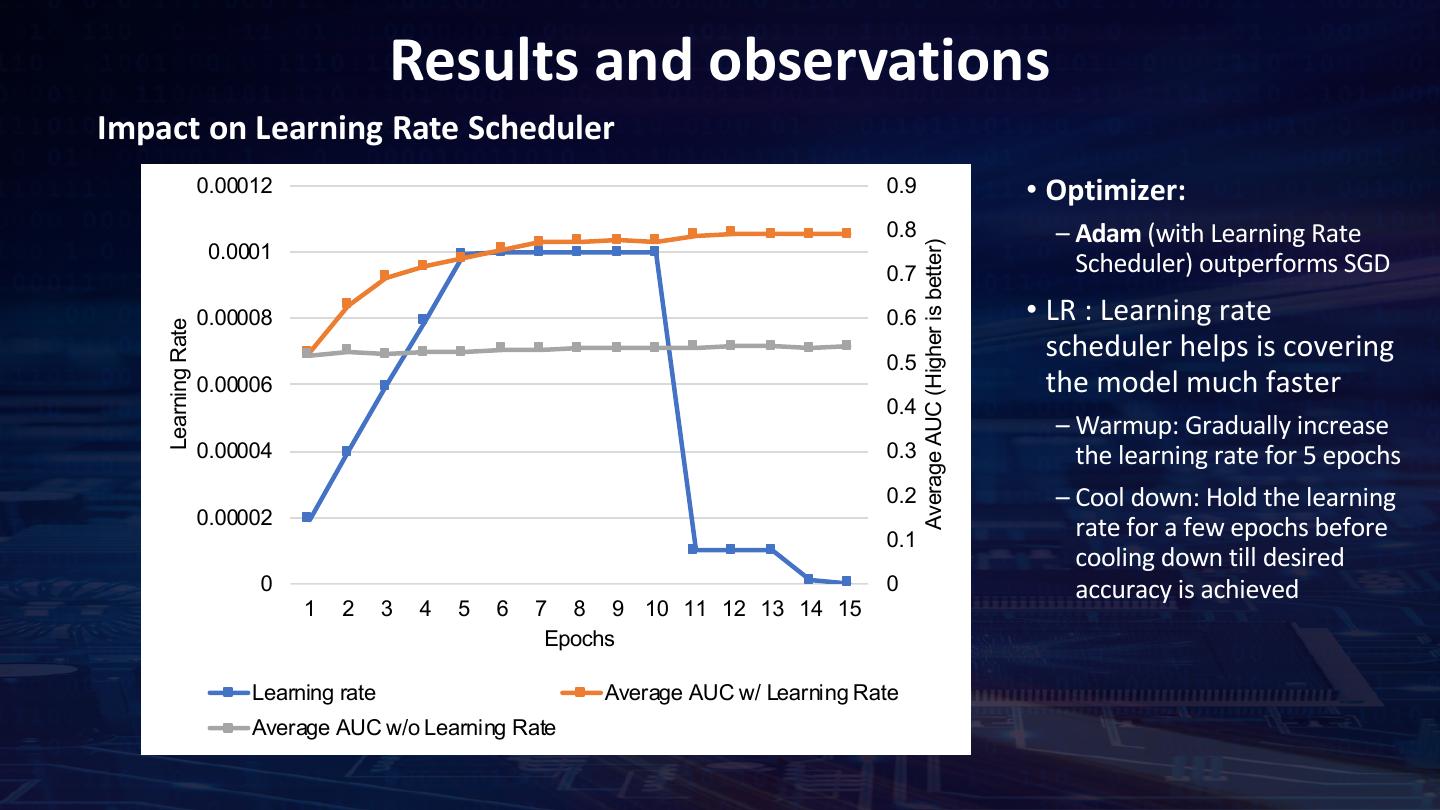
28 . Define the Optimizer Read the X-ray images • Evaluated two optimizers: SGD and Adam Optimizer • Learning rate scheduler is implemented in two phases: Pre-Processing –Warmup + Plateau schedule –Warmup: Gradually increase the learning rate for 5 epochs Define the model –Plateau: Plateau("Loss", factor=0.1, patience=1, mode="min", epsilon=0.01, cooldown=0, min_lr=1e-15) Define optimizer Training the model
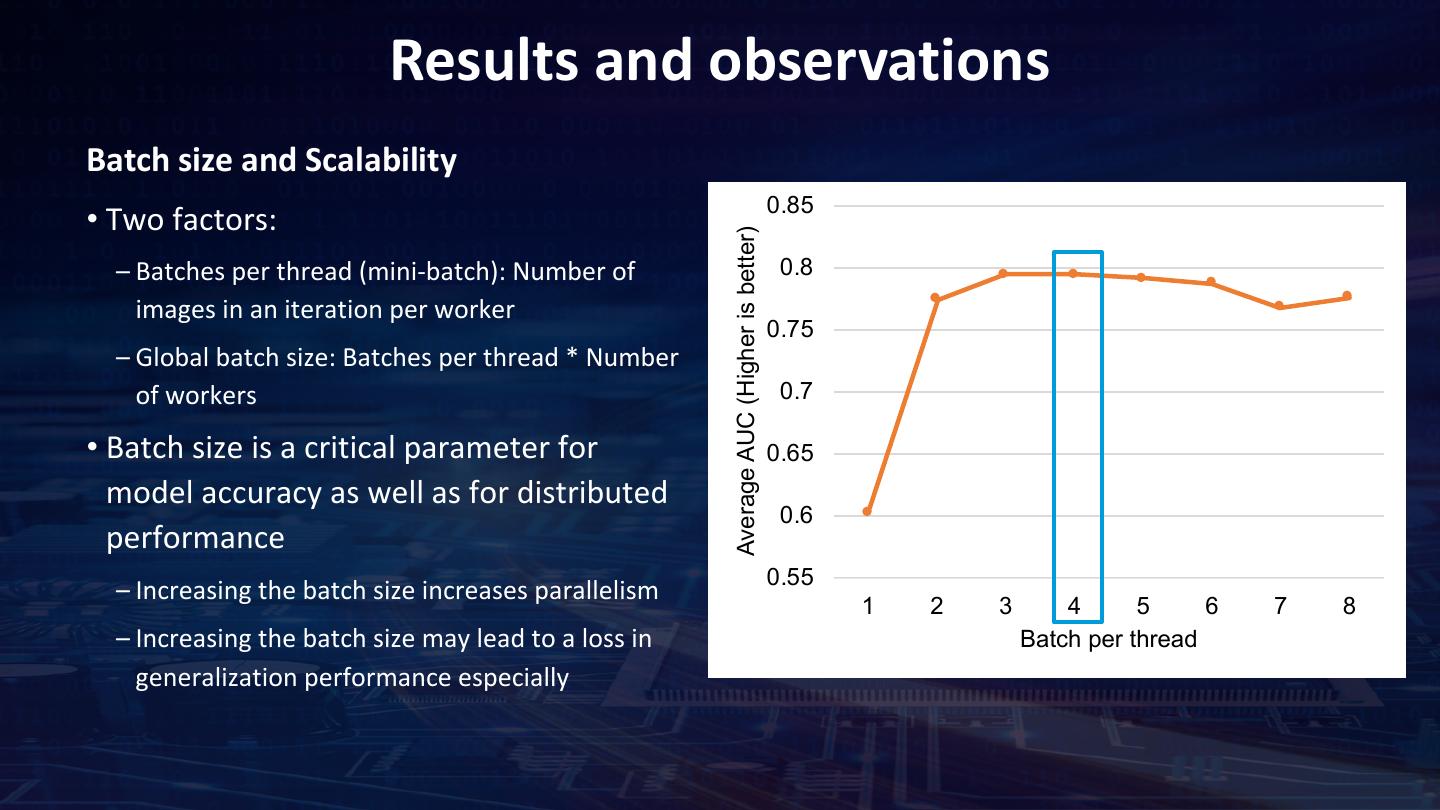
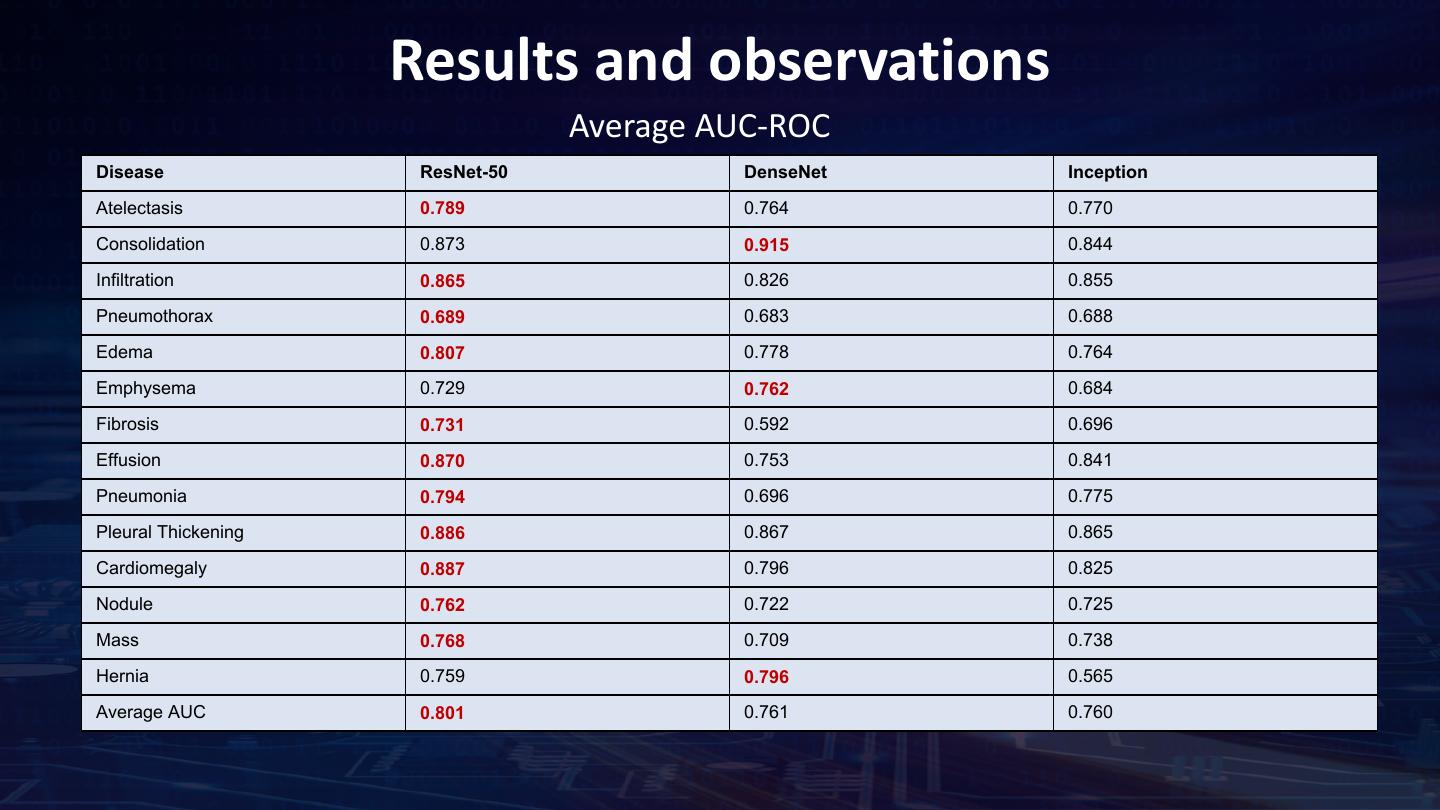
29 . Train the model using ML Pipelines Read the X-ray images • Analytics Zoo API NNEstimator to build the model • .fit() produces a neural network model which is a Transformer • You can now run .predict() on the model for inference Pre-Processing • AUC-RoC is used to measure the accuracy of the model. Spark ML pipeline API BinaryClassificationEvaluator to determine the AUC-ROC for each disease. Define the model estimator = NNEstimator(xray_model, BinaryCrossEntropy(), transformer) .setBatchSize(batch_size).setMaxEpoch(num_epoch) Define optimizer .setFeaturesCol("image").setCachingSample(False). .setValidation(EveryEpoch(), validationDF, [AUC()], batch_size) .setOptimMethod(optim_method) Xray_nnmodel = estimator.fit(trainingDF) Training the model
3秒后跳转登录页面
去登陆

