展开查看详情
1 .Spark SQL 扩展开发⼊⻔
王道远(健身) · 阿⾥巴巴 / 技术专家
�
2 . 01
Spark SQL 背景介绍
02
CONTENT
Spark SQL 扩展的功能
⽬录 >> 03
Spark SQL 扩展的 API
04
如何部署开发好的插件
�
3 .01
背景介绍
关于 Spark SQL
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
4 .Spark SQL
DataFrame
SQL
/DataSet
Spark Streaming Spark MLlib …
Spark SQL
�
5 . Spark Catalyst
SQL Query
Optimized
Model
Unresolved Resolved Optimized Selected
Cost
DataFrame PhysicalPlan
LogicalPlan RDD
LogicalPlan LogicalPlan LogicalPlan PhysicalPlan PhysicalPlan
DataSet
Parser Resolver Optimizer Planner
�
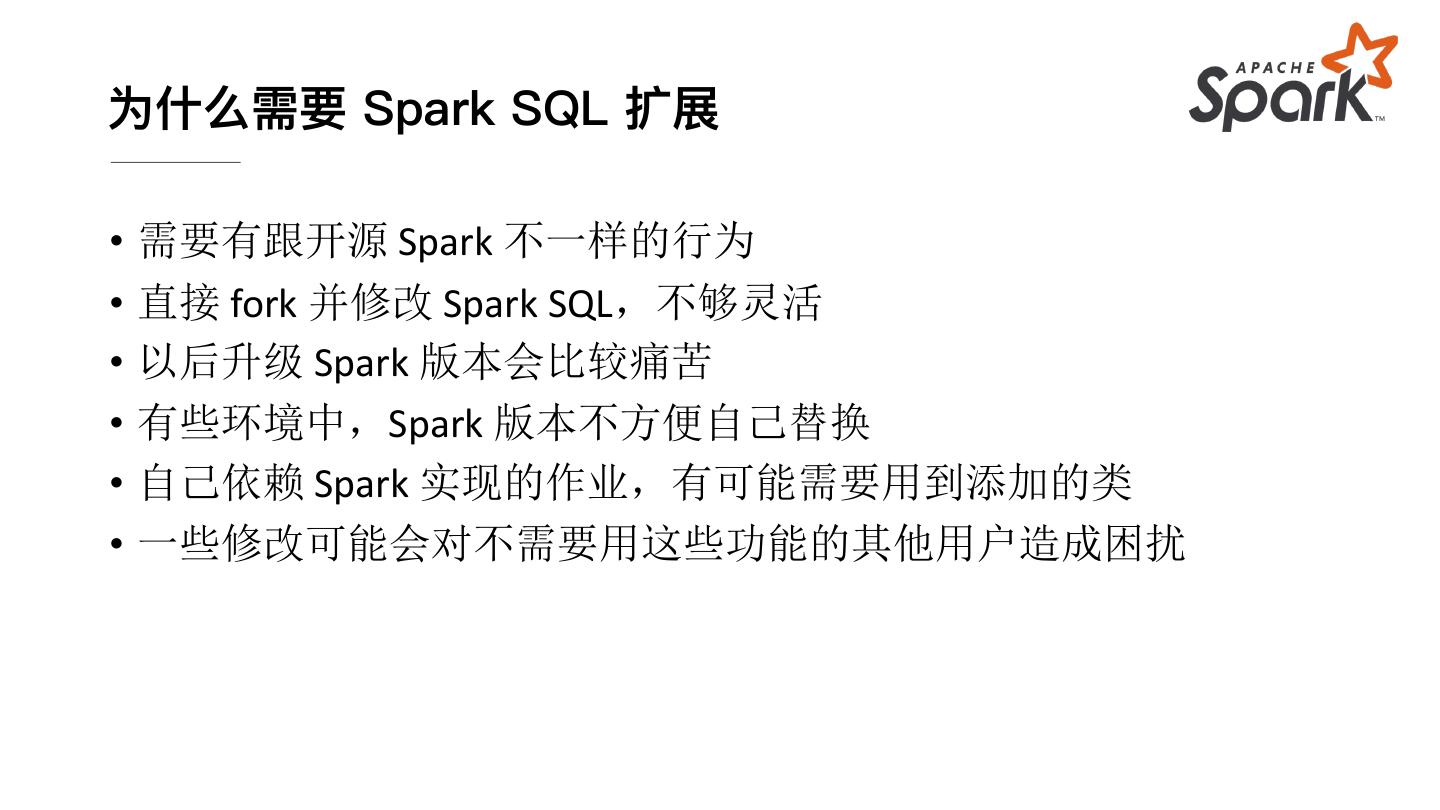
6 .为什么需要 Spark SQL 扩展
• 需要有跟开源 Spark 不一样的行为
• 直接 fork 并修改 Spark SQL,不够灵活
• 以后升级 Spark 版本会比较痛苦
• 有些环境中,Spark 版本不方便自己替换
• 自己依赖 Spark 实现的作业,有可能需要用到添加的类
• 一些修改可能会对不需要用这些功能的其他用户造成困扰
�
7 .02 功能
Spark SQL 扩展能⼲什么
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
8 .Spark SQL 扩展
允许用户定制 spark catalyst 行为
• 扩展 parser,支持自定义语法
• 修改解析规则
• 修改优化规则
• 修改物理计划生成
• ……
�
9 .Spark SQL 扩展
Spark 2.4 Spark 3.0新增
• injectResolutionRule • injectColumnar
• injectPostHocResolutionRule • injectQueryStagePrepRule
• injectCheckRule • injectFunction
• injectOptimizerRule
• injectPlannerStrategy
• injectParser
�
10 .03
API 使⽤
如何构建⾃⼰的扩展
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
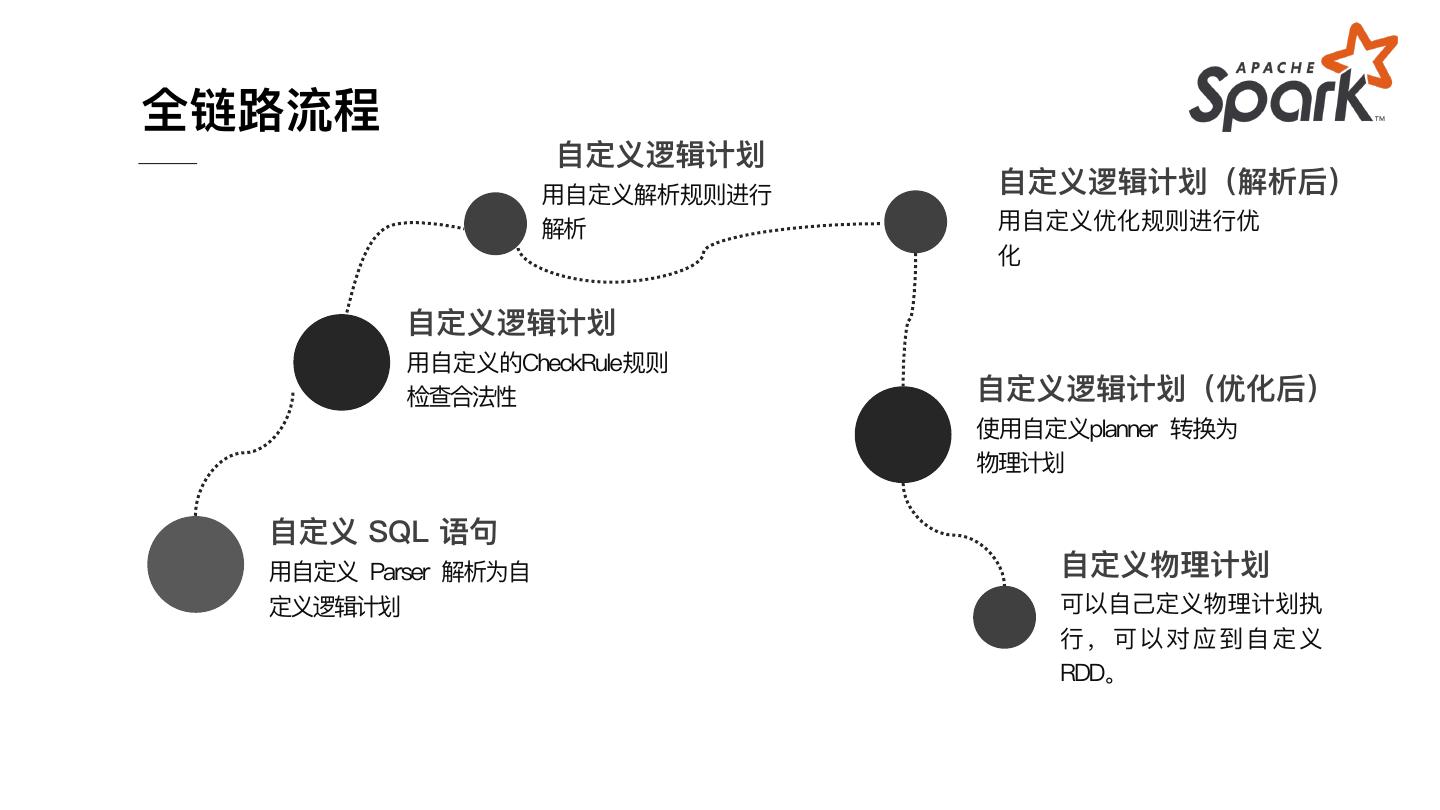
12 .全链路流程
⾃定义逻辑计划
⽤⾃定义解析规则进⾏ ⾃定义逻辑计划(解析后)
解析 ⽤⾃定义优化规则进⾏优
化
⾃定义逻辑计划
⽤⾃定义的CheckRule规则
检查合法性 ⾃定义逻辑计划(优化后)
使⽤⾃定义planner 转换为
物理计划
⾃定义 SQL 语句
⽤⾃定义 Parser 解析为⾃ ⾃定义物理计划
定义逻辑计划 可以⾃⼰定义物理计划执
⾏,可以对应到⾃定义
RDD。
�
13 .Spark SQL 扩展 - parser
type ParserBuilder = (SparkSession, ParserInterface) => ParserInterface
def injectParser(builder: ParserBuilder): Unit = {
parserBuilders += builder
}
�
14 .Spark SQL 扩展 - parser
case class SendEmailToMe() extends LeafNode {
override def output: Seq[Attribute] = Seq.empty
}
case class MyParser(spark: SparkSession, delegate: ParserInterface)
extends ParserInterface {
override def parsePlan(sqlText: String): LogicalPlan = {
val email = if (sqlText.toLowerCase.equals("email"))
Some(SendEmailToMe()) else None
email.getOrElse(delegate.parsePlan(sqlText))
}
………
}
�
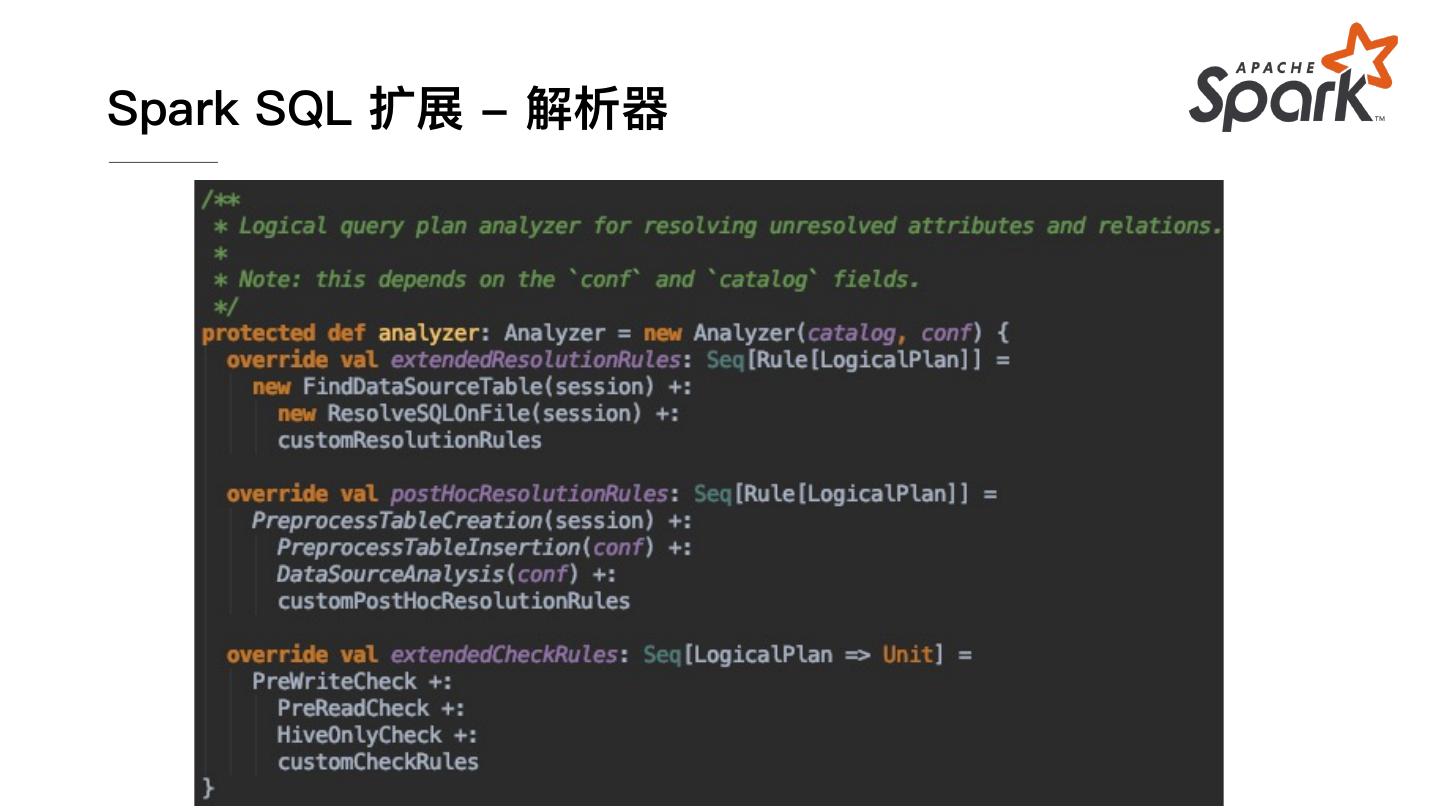
15 .Spark SQL 扩展 - 解析器
type RuleBuilder = SparkSession => Rule[LogicalPlan]
type CheckRuleBuilder = SparkSession => LogicalPlan => Unit
def injectCheckRule(builder: CheckRuleBuilder): Unit = {
checkRuleBuilders += builder
}
def injectResolutionRule(builder: RuleBuilder): Unit = {
resolutionRuleBuilders += builder
}
def injectPostHocResolutionRule(builder: RuleBuilder): Unit = {
postHocResolutionRuleBuilders += builder
}
�
17 .Spark SQL 扩展 - 解析器 - check
case class MyCheckRule(spark: SparkSession) extends (LogicalPlan => Unit) {
override def apply(plan: LogicalPlan): Unit = plan foreach {
case Join(_, _, Cross, _) =>
throw new UnsupportedOperationException(
"not allow explicit cross join!")
}
}
�
18 .Spark SQL 扩展 - 优化器
type RuleBuilder = SparkSession => Rule[LogicalPlan]
def injectOptimizerRule(builder: RuleBuilder): Unit = {
optimizerRules += builder
}
�
19 .Spark SQL 扩展 - 优化器
object MyOptimizeRule extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case InsertIntoTable(r: HiveTableRelation, partSpec, query, overwrite, ifPartitionNotExists)
if DDLUtils.isHiveTable(r.tableMeta) =>
if (partSpec.exists(_._2.isEmpty)) {
// exists DynamicPartition
val dynPartSchema = if (partSpec.exists(_._2.isDefined)) {
query.output.takeRight(r.partitionCols.length - partSpec.count(_._2.isDefined))
} else {
query.output.takeRight(r.partitionCols.length)
}
val betterQuery = RepartitionByExpression(dynPartSchema, query, SQLConf.get.numShufflePartitions)
InsertIntoTable(r, partSpec, betterQuery, overwrite, ifPartitionNotExists)
} else {
InsertIntoTable(r, partSpec, query, overwrite, ifPartitionNotExists)
}
}
}
�
20 .Spark SQL 扩展 - planner
type StrategyBuilder = SparkSession => Strategy
def injectPlannerStrategy(builder: StrategyBuilder): Unit = {
plannerStrategyBuilders += builder
}
�
21 .Spark SQL 扩展 - planner
case class MySparkStrategy(spark: SparkSession) extends SparkStrategy {
override def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case SendEmailToMe() => SendEmailToMeExec() :: Nil
}
}
case class SendEmailToMeExec() extends LeafExecNode {
override protected def doExecute(): RDD[InternalRow] = {
sqlContext.sparkContext.parallelize(send(), 1)
}
private def send(): Seq[InternalRow] = {
// send email
...
Seq.empty[InternalRow]
}
override def output: Seq[Attribute] = Seq.empty
}
�
22 .04
部署程序
如何运⾏开发好的扩展
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
23 .Spark SQL 扩展打包
• 注意依赖与集群 Spark 相同版本的 Spark
• 把新引入的依赖打包到同一个 jar 内
• 打包时把 Spark 依赖 scope 设为 provided
• 减少包大小
• 避免类不兼容
• 建议把 Spark 版本号体现在包名中
�
24 .部署 Spark SQL 扩展
• SparkSession.Builder
• spark.sql.extensions
�
25 .注意事项
• Spark 2.4及更老的版本,只能支持一个extension
• Spark 3.0支持同时多个extension
• spark.sql.extensions 不能在 spark-sql 启动后进行设置
• 如有必要,可以通过 spark.sql.optimizer.excludedRules 屏蔽现有优
化规则
• 无法调整现有规则的执行顺序
• 如果有引入自定义RDD等需要在executor端使用的类,需要确保
executor的classpath中能加载到
�