






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2021_Spark_Rapids_Introduction(1)
Spark 3.0开始支持了数据的列式处理,同时能够将GPU作为资源进行调度。
在此基础上,Nvidia/Spark-Rapids开源项目基于Rapids库, 以plugin的方式提供了一组GPU上实现的ETL处理,利用GPU强大的并发能力加速Join, Sort, Aggregate等常见的ETL操作。
本次分享主要介绍该开源项目和目前取得的一些进展,以及使用到的一些相关技术。
项目介绍:https://nvidia.github.io/spark-rapids/
沈国一(Gary),Nvidia经理。带领上海Spark团队,专注于在大数据处理平台Apache Spark 3.0上实现GPU加速的开发和支持,通过基于GPU加速后的Spark ETL, XGBoost on Spark等来解决ML或DL中对于大数据处理的各种需求。
展开查看详情
1 .使用RAPIDS加速 APACHE SPARK 3.0
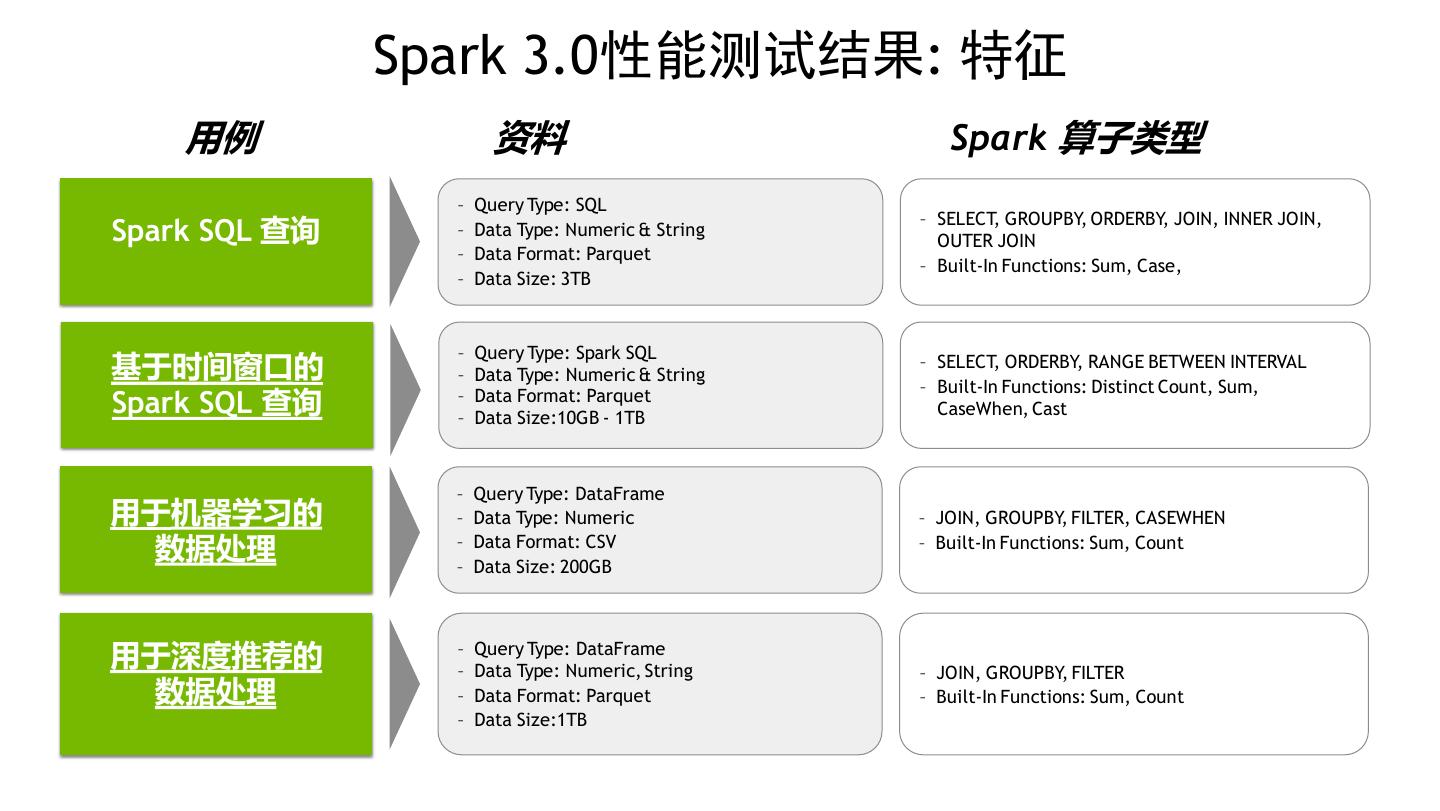
2 .AGENDA 用于 Apache Spark 3.0 的 RAPIDS 加速器 工作原理 GPU处理加速的一些技术 性能测试结果 Q&A 2
3 . 使用RAPIDS加速 APACHE SPARK 3.0 3
4 . APACHE SPARK在现代企业中的应用 Apache Spark的使用场景 原始数据源 Use Cases 源-1 1 源-2 11. Raw Data processing into data lake 原始数据 ETL 丢弃的数据 (ETL); typically streaming data 源-3 的注入 00 任务 无需分析或AI的部分 … 22. Analytics on unstructured or semi- 源-N structured data in data lake 加入数据湖 在不同的间隔上进行分析 用于将来分析用的数据 Hourly, daily, weekly, etc. (plus ad-hoc) 33. Loading data from data lake into Enterprise Data Warehouse (ETL) <store> 2 44. Pre-processing (feature 非结构化数据 engineering) data from data lake (Hadoop/Object for training 大数据/分析 Storage) 分析任务 团队 Data Lake 3 4 传统数据 ETL ETL Train Inference AI / 数据科 仓库 任务 任务 学团队 结构化数据 机器学习 (relational DB) 4
5 . 结合NVIDIA GPU的SPARK 3.0 无代码修改,加速数据处理 更快的执行时间 简化从分析到AI 降低基础架构费用 加速数据准备 端到端的流水线 用更少的硬件更快地完成工作 快速的进入下个处理阶段 从ETL到训练,再到呈现 节省在内部或云端的部署 专注于最重要的活动 对Spark和ML/DL框架的统一 以少做多 5
6 . 为什么要迁移到SPARK 3.0? Spark 3中的主要特点 ETL和DL的整合 Spark 2.x – CPU ONLY! ❏ 新的Spark平台特点 和一些开源库 (Horvod, XGBoost4J)更好的 Data Preparation Model Training 支持ML/DL框架 XGBoost | TensorFlow | Spark PyTorch 性能上的提升 GPUs are key to both CPU Powered Cluster GPU Powered Cluster ❏ GPU作为可调度资源用于加速处理 Data Spark Orchestrated Sources GPUs lower TCO Shared Storage ❏ 自适应查询执行(Adaptive Query Execution) ❏ 动态分区裁剪(Dynamic Partition Pruning) Spark 3.x + GPUS 其他 Data Preparation Model Training ❏ 增强的Graph支持 Spark XGBoost | TensorFlow | ❏ 更好的Kubernetes支持 PyTorch GPU Powered Cluster ❏ 改进的语言支持 Data Spark Orchestrated Sources
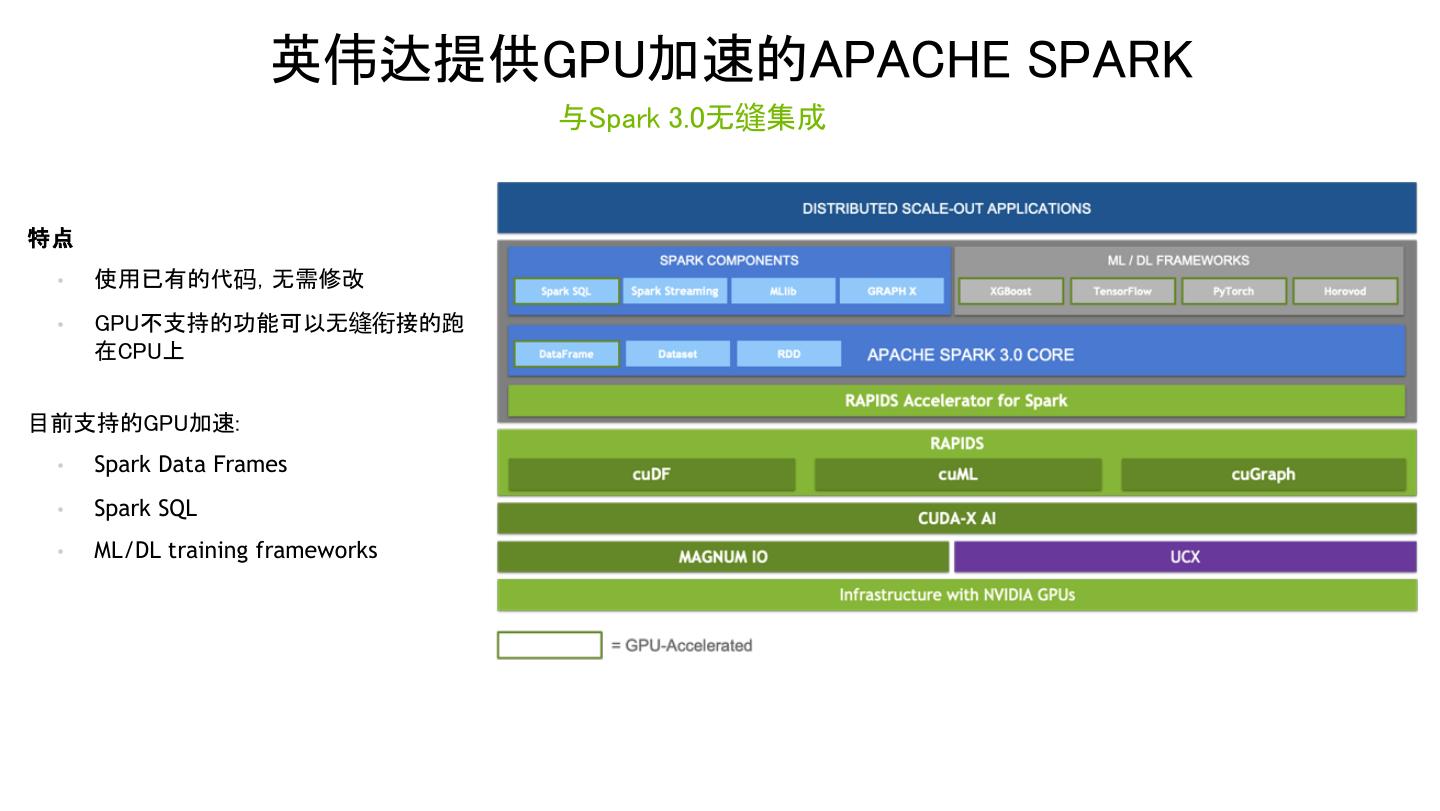
7 . 英伟达提供GPU加速的APACHE SPARK 与Spark 3.0无缝集成 特点 • 使用已有的代码,无需修改 • GPU不支持的功能可以无缝衔接的跑 在CPU上 目前支持的GPU加速: • Spark Data Frames • Spark SQL • ML/DL training frameworks 7
8 .它是如何工作的? 8
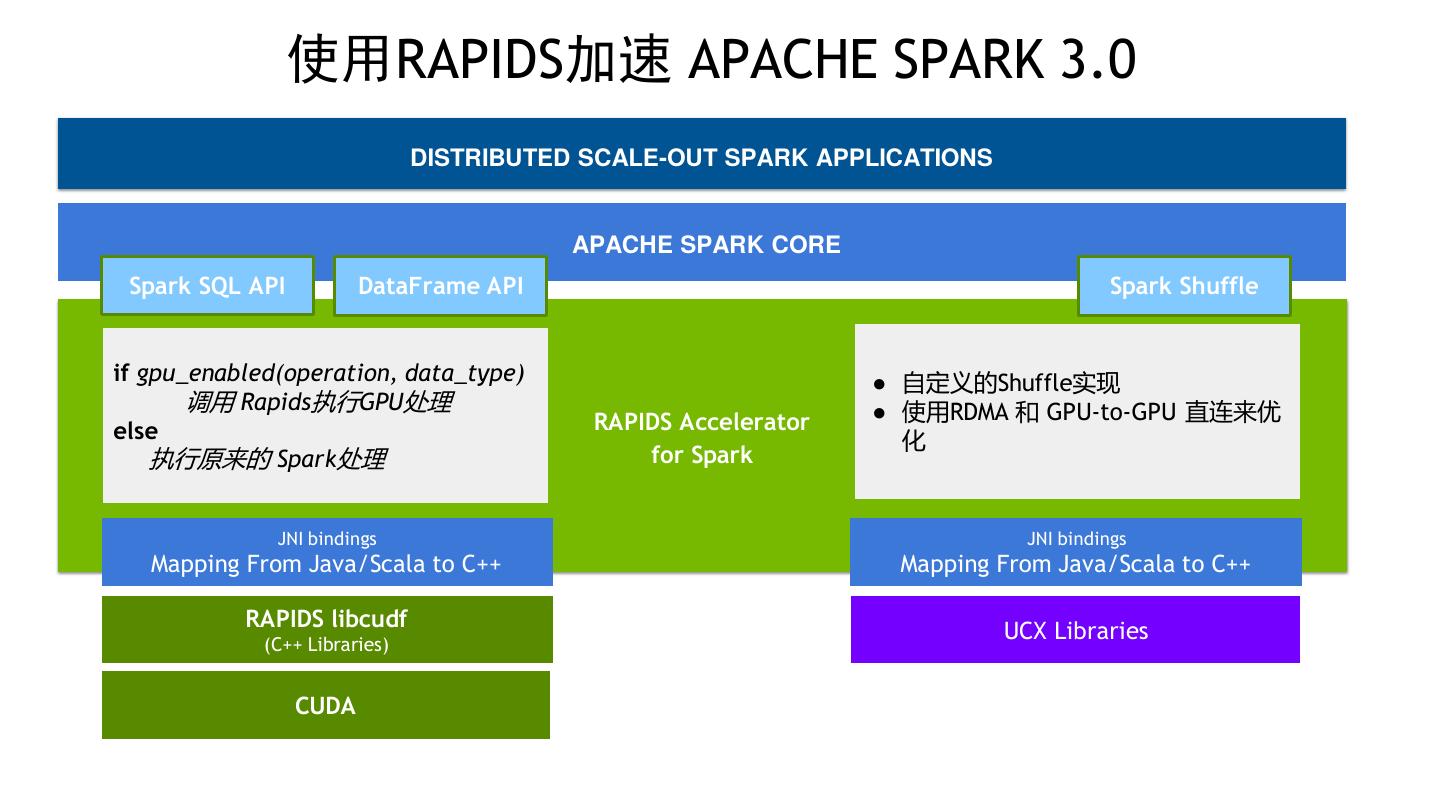
9 . 使用RAPIDS加速 APACHE SPARK 3.0 DISTRIBUTED SCALE-OUT SPARK APPLICATIONS APACHE SPARK CORE Spark SQL API DataFrame API Spark Shuffle if gpu_enabled(operation, data_type) ● 自定义的Shuffle实现 调用 Rapids执行GPU处理 ● 使用RDMA 和 GPU-to-GPU 直连来优 else RAPIDS Accelerator 化 执行原来的 Spark处理 for Spark JNI bindings JNI bindings Mapping From Java/Scala to C++ Mapping From Java/Scala to C++ RAPIDS libcudf UCX Libraries (C++ Libraries) CUDA
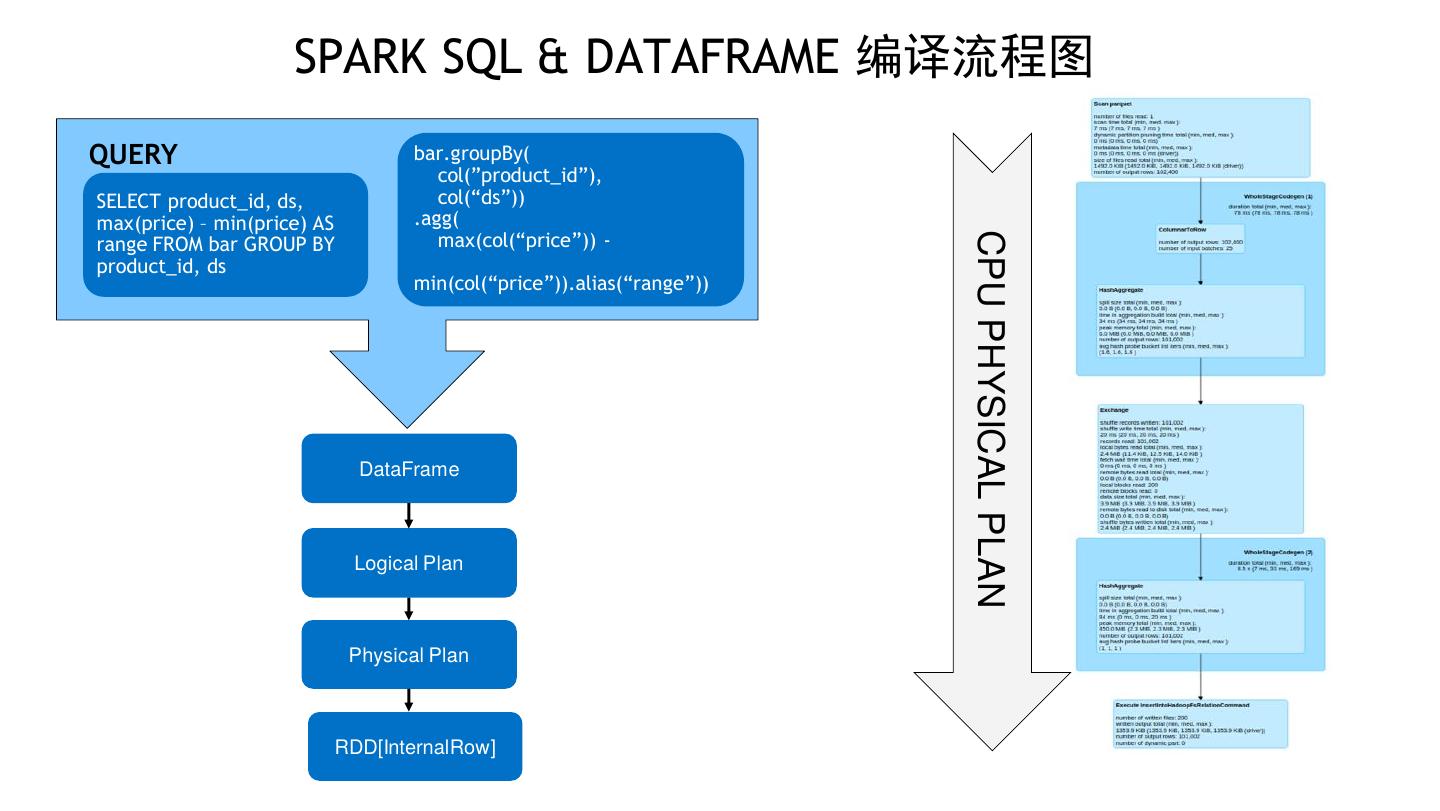
10 . SPARK SQL & DATAFRAME 编译流程图 QUERY bar.groupBy( col(”product_id”), SELECT product_id, ds, col(“ds”)) max(price) – min(price) AS .agg( max(col(“price”)) - CPU PHYSICAL PLAN range FROM bar GROUP BY product_id, ds min(col(“price”)).alias(“range”)) DataFrame Logical Plan Physical Plan RDD[InternalRow]
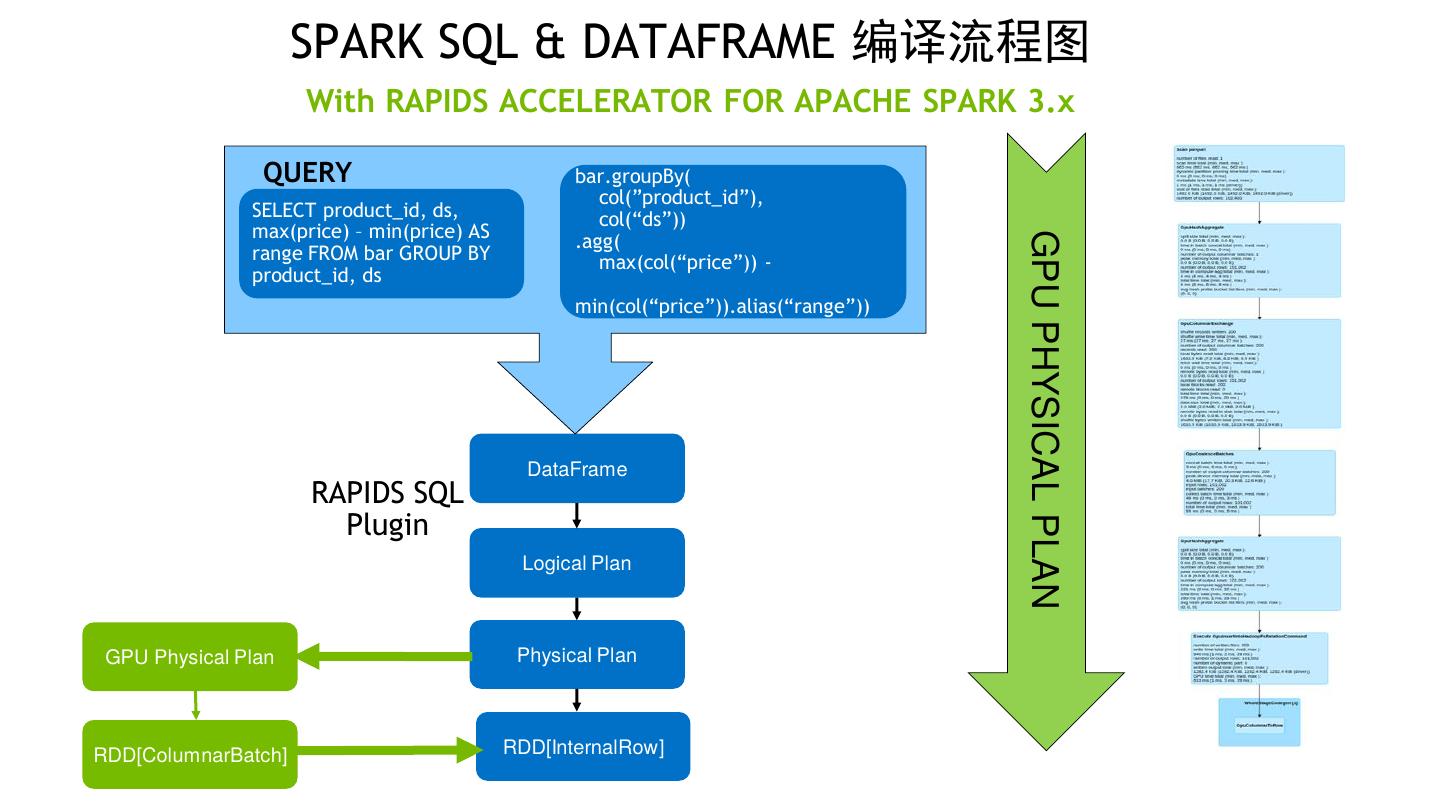
11 . SPARK SQL & DATAFRAME 编译流程图 With RAPIDS ACCELERATOR FOR APACHE SPARK 3.x QUERY bar.groupBy( col(”product_id”), SELECT product_id, ds, col(“ds”)) max(price) – min(price) AS .agg( GPU PHYSICAL PLAN range FROM bar GROUP BY max(col(“price”)) - product_id, ds min(col(“price”)).alias(“range”)) DataFrame RAPIDS SQL Plugin Logical Plan GPU Physical Plan Physical Plan RDD[ColumnarBatch] RDD[InternalRow]
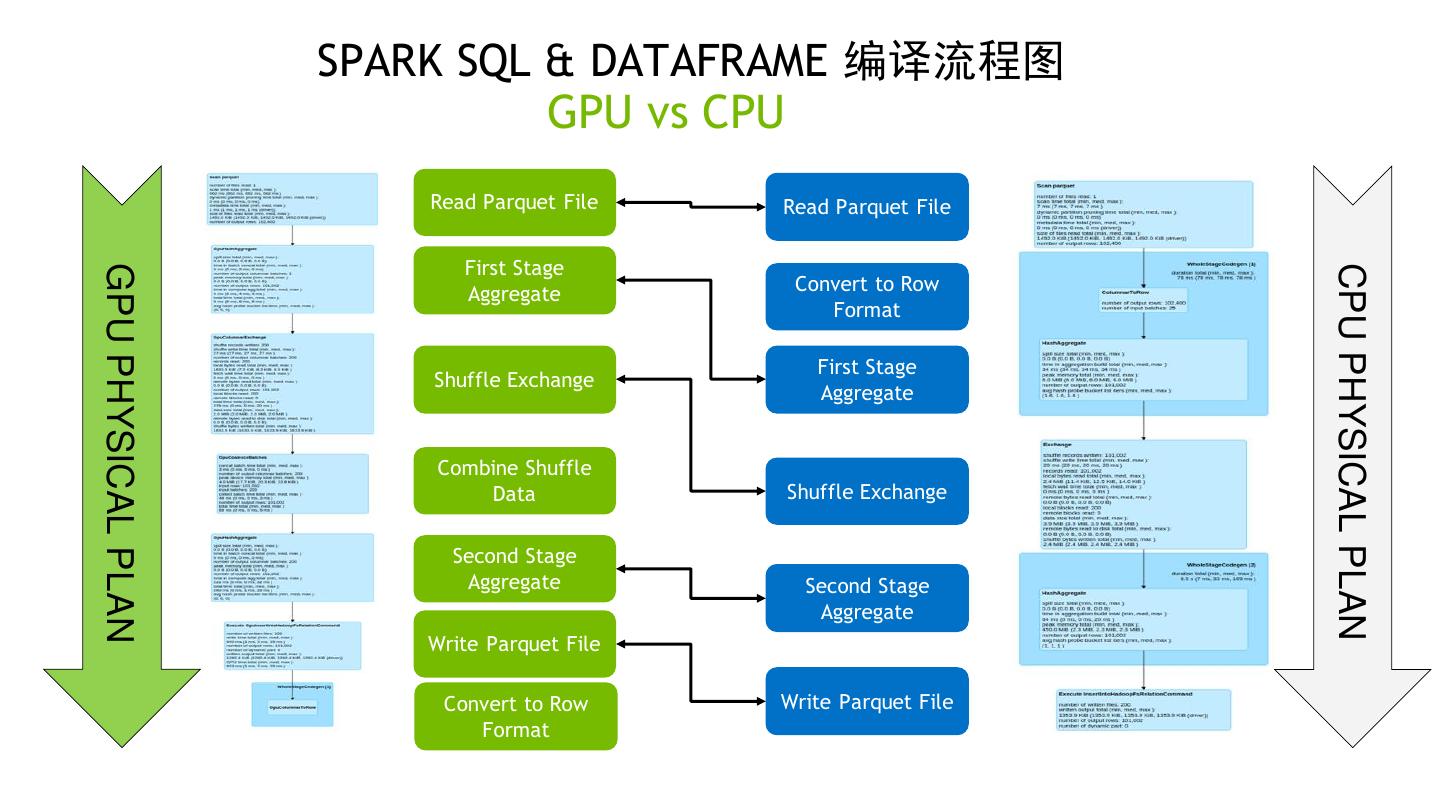
12 . SPARK SQL & DATAFRAME 编译流程图 GPU vs CPU Read Parquet File Read Parquet File First Stage CPU PHYSICAL PLAN GPU PHYSICAL PLAN Aggregate Convert to Row Format First Stage Shuffle Exchange Aggregate Combine Shuffle Data Shuffle Exchange Second Stage Aggregate Second Stage Aggregate Write Parquet File Convert to Row Write Parquet File Format
13 .无需代码更改 相同的 SQL and DataFrame 代码. 13
14 . 我们支持的算子 并且还在增加… ! abs ceiling day ifnull length mod pow sign trim TimeSub for time ranges % acos char_length dayofmonth in like monotonically_in quarter signum ucase creasing_id startswith & acosh coalesce dayofyear initcap ln radians sin upper month endswith * and concat degrees input_file_block_ locate rand* sinh weekday length nanvl contains + asin cos double log regexp_replace* smallint when input_file_block_ negative limit - asinh cosh e start log10 replace spark_partition_i window not d order by / atan cot exp input_file_name log1p rint year now sqrt group by < atanh count expm1 int log2 rollup | nullif string filter <= avg cube first isnan lower row_number ~ nvl substr union <=> bigint current_date first_value isnotnull lpad rpad CSV Reading* nvl2 substring repartition = boolean current_timesta float isnull ltrim rtrim ORC Reading mp or sum equi-joins == case/when floor last max second ORC Writing date pi tan select > cast from_unixtime last_day mean shiftleft Parquet Reading date_add pmod tanh >= cbrt hour last_value min shiftright Parquet Writing date_sub posexplode* timestamp ^ ceil if lcase minute shiftrightunsigne ANSI casts datediff position d tinyint 获取最新信息可以访问:https://nvidia.github.io/spark-rapids/docs/supported_ops.html 14
15 . 适合GPU的场合 高散列度 数据的joins 高散列度数据的aggregates 高散列度数据的sort Window operations (特别是大型 windows) 复杂计算 数据编码 (创建 Parquet 和 ORC 文件,读取 CSV) 15
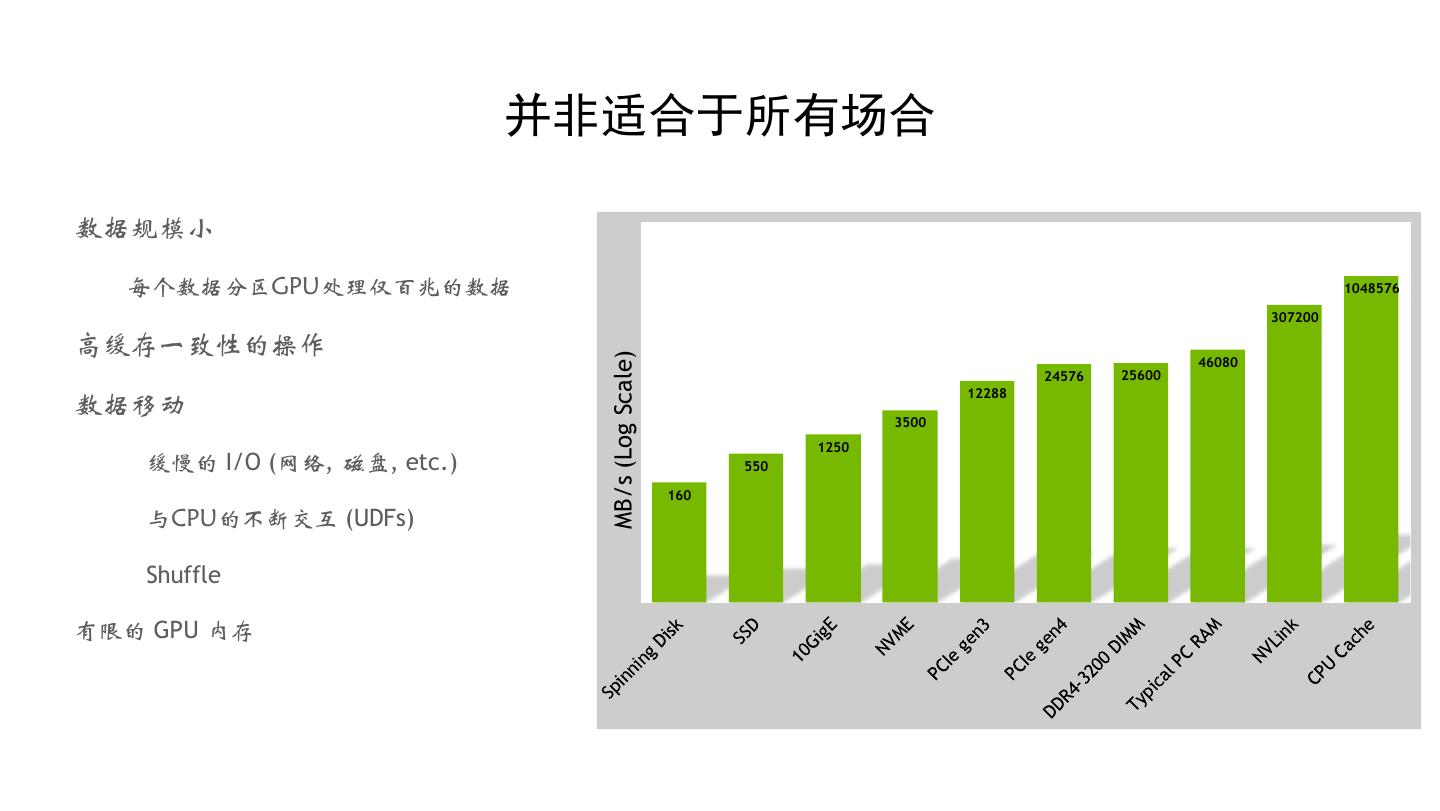
16 . 并非适合于所有场合 数据规模小 每个数据分区GPU处理仅百兆的数据 1048576 307200 高缓存一致性的操作 MB/s (Log Scale) 46080 24576 25600 12288 数据移动 3500 1250 缓慢的 I/O (网络, 磁盘, etc.) 550 160 与CPU的不断交互 (UDFs) Shuffle 有限的 GPU 内存 16
17 .GPU处理加速的一些技术 17
18 .加速 SHUFFLE 18
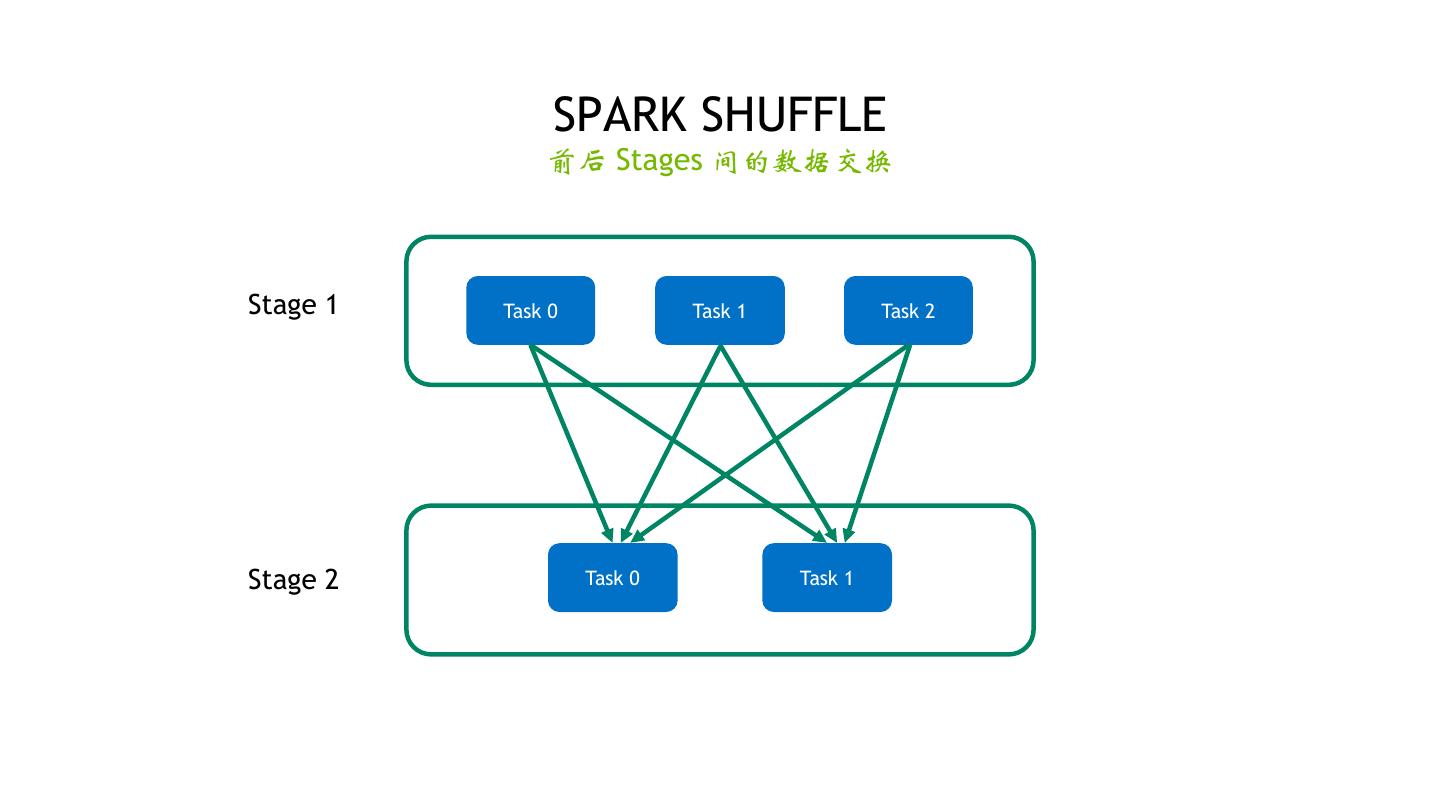
19 . SPARK SHUFFLE 前后 Stages 间的数据交换 Stage 1 Task 0 Task 1 Task 2 Stage 2 Task 0 Task 1 19
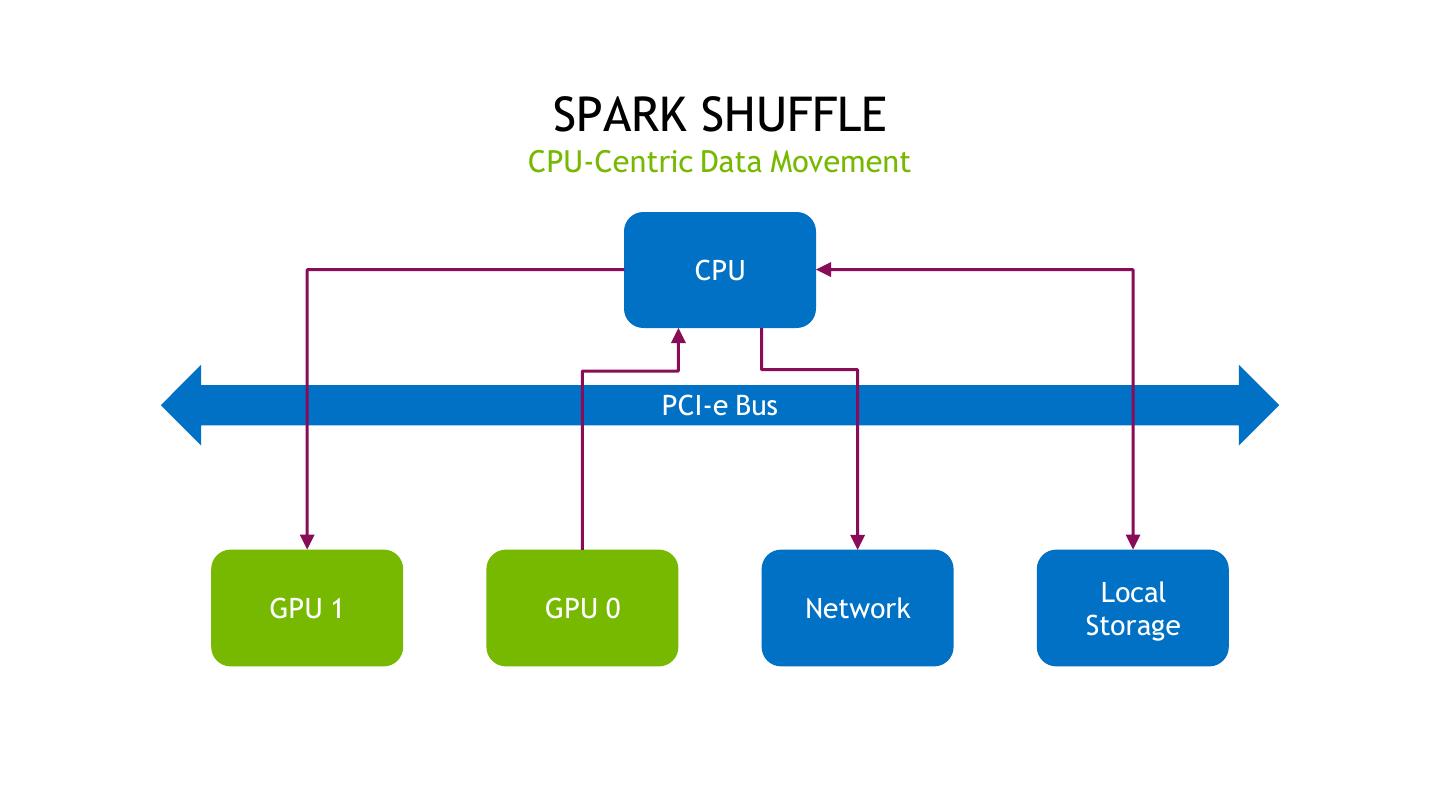
20 . SPARK SHUFFLE CPU-Centric Data Movement CPU PCI-e Bus Local GPU 1 GPU 0 Network Storage 20
21 . ACCELERATED SPARK SHUFFLE GPU-Centric Data Movement CPU PCI-e Bus RDMA GPU Direct Storage Local GPU 1 GPU 0 Network Storage NVLink 21
22 . ACCELERATED SPARK SHUFFLE Shuffling Spilled Data Host CPU Memory PCI-e Bus RDMA Local GPU 1 GPU 0 Network Storage 22
23 . UCX LIBRARY Unified Communication X 抽象的通信接口 选择最佳路径 TCP, RDMA, Shared Memory, GPU Zero-copy GPU memory transfers over RDMA RDMA 需要网卡支持(IB or RoCE) http://openucx.org 23
24 .UDF的部分支持 24
25 . 初步支持 SCALA UDF * Accelerate Scala UDFs on the GPU Converts Scala UDF to Catalyst spark.sql.extensions=com.nvidia.spark.udf.Plugin spark.rapids.sql.udfCompiler.enabled=true Arithmetic Original Spark Scala UDF Catalyst-Compiled Scala UDF Logical (and, or, not) val myUDF: (String) => String = { userName => Equality (==, <, <=, >, >=) if (userName.equals("Foo")) { GpuProject [ if (NOT (cast((value#106 <=> Foo) as int) = 0)) "hello" hello } else { else Bitwise "good bye" good bye } AS myUDF(value)#136] } Scala.math NVIDIA UDF Plugin The UDF is compiled to catalyst! Opaque to Spark: Type casts scala> spark.sql("select value, myUDF(value) from demo").collect SELECT myUDF(col) FROM table res57: Array[org.apache.spark.sql.Row] = String ops Project [ Array([Foo,hello], [Bar,good bye]) myUDF(value#106) AS myUDF(value)#131] More support planned… *详细参考: udf-to-catalyst-expressions 25
26 . 加速 PANDAS UDFS* 两个方面 实现对Python进程的GPU资源管理,使 Spark Pandas UDFs JVM 进程与Python进程共享一个GPU,以 安全地在Pandas UDF里使用GPU AggregateInPandasExec WindowInPandasExec FlatMapGroupsInPandasExec ArrowEvalPythonExec MapInPandasExec FlatMapCoGroupsInPandasExec 优化JVM与Python进程之间的数据交换, 避免不必要的行列转换 cuDF C++ 26
27 . SCALA/JAVA/HIVE UDF支持 • 提供Scala/Java/Hive定义的UDF • 调用已有cuDF提供的Java API执行GPU处理 • 自定义GPU native处理 详细参考:rapids-accelerated-user-defined-functions 27
28 . 其他技术 加速GPU处理 • 小文件读取时,采用多线程并行以及合并(coalesce) • GPU内存不够时,spill到Host内存和磁盘 • 采用最新的Gpu Direct Storage技术,加快GPU内存到磁盘(NVMe)的I/O 28
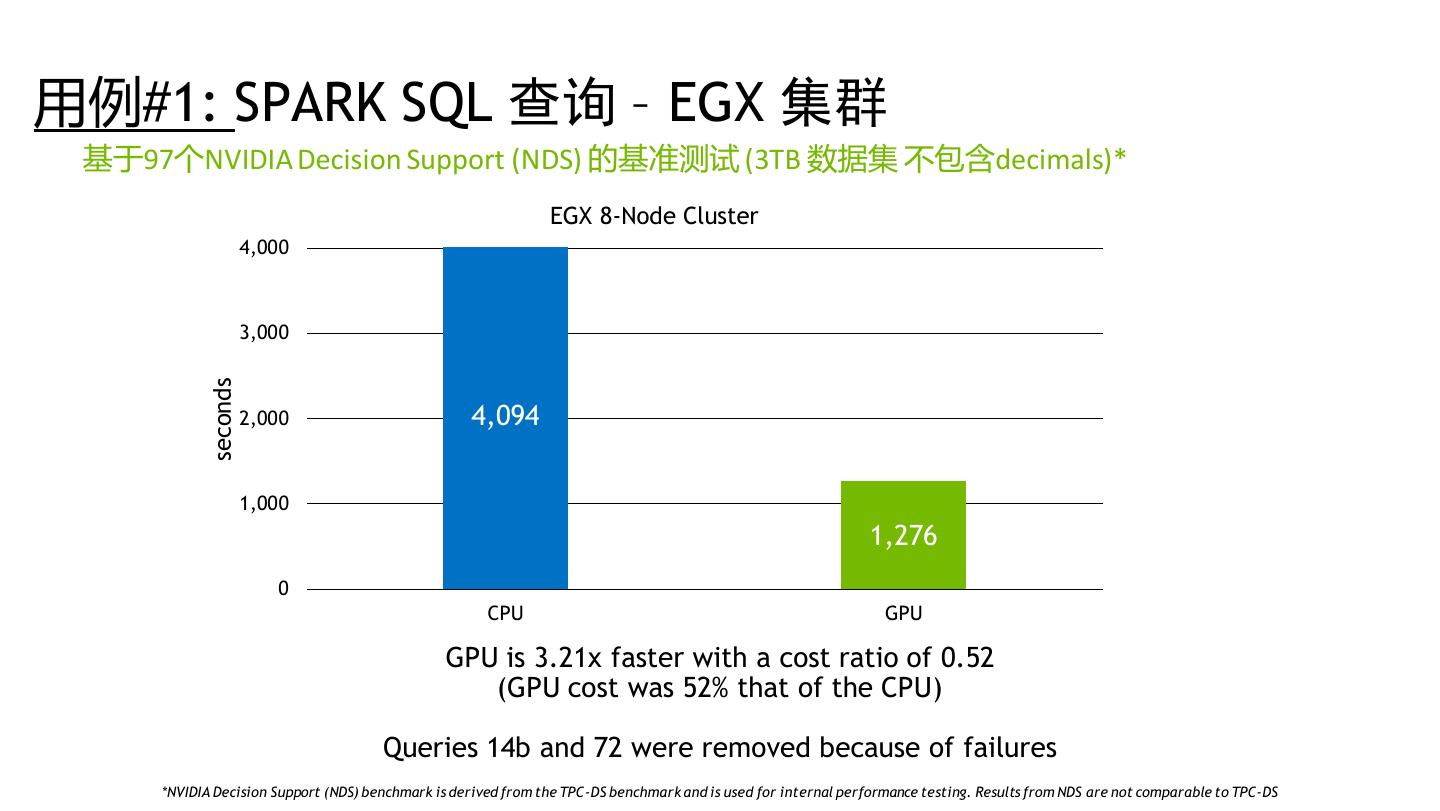
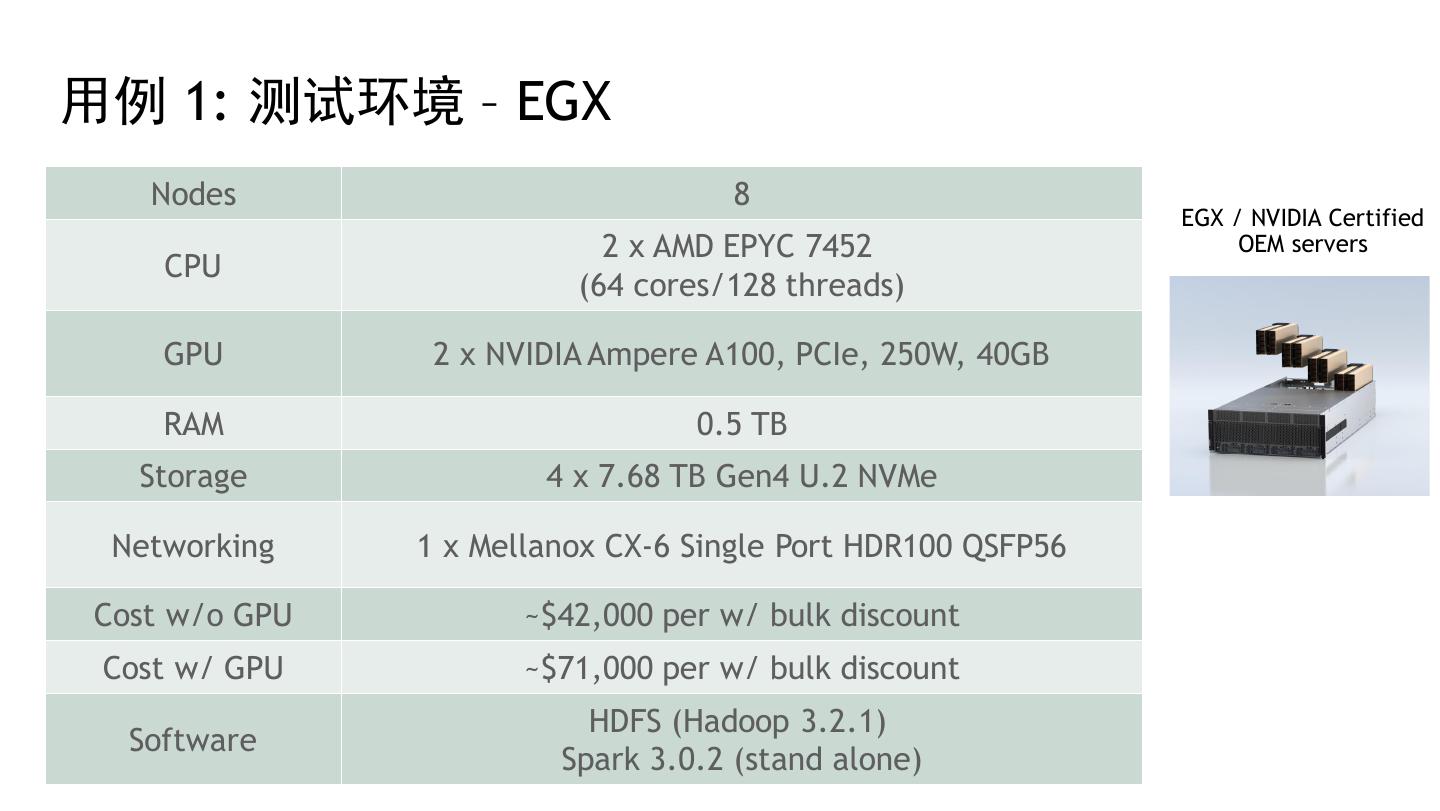
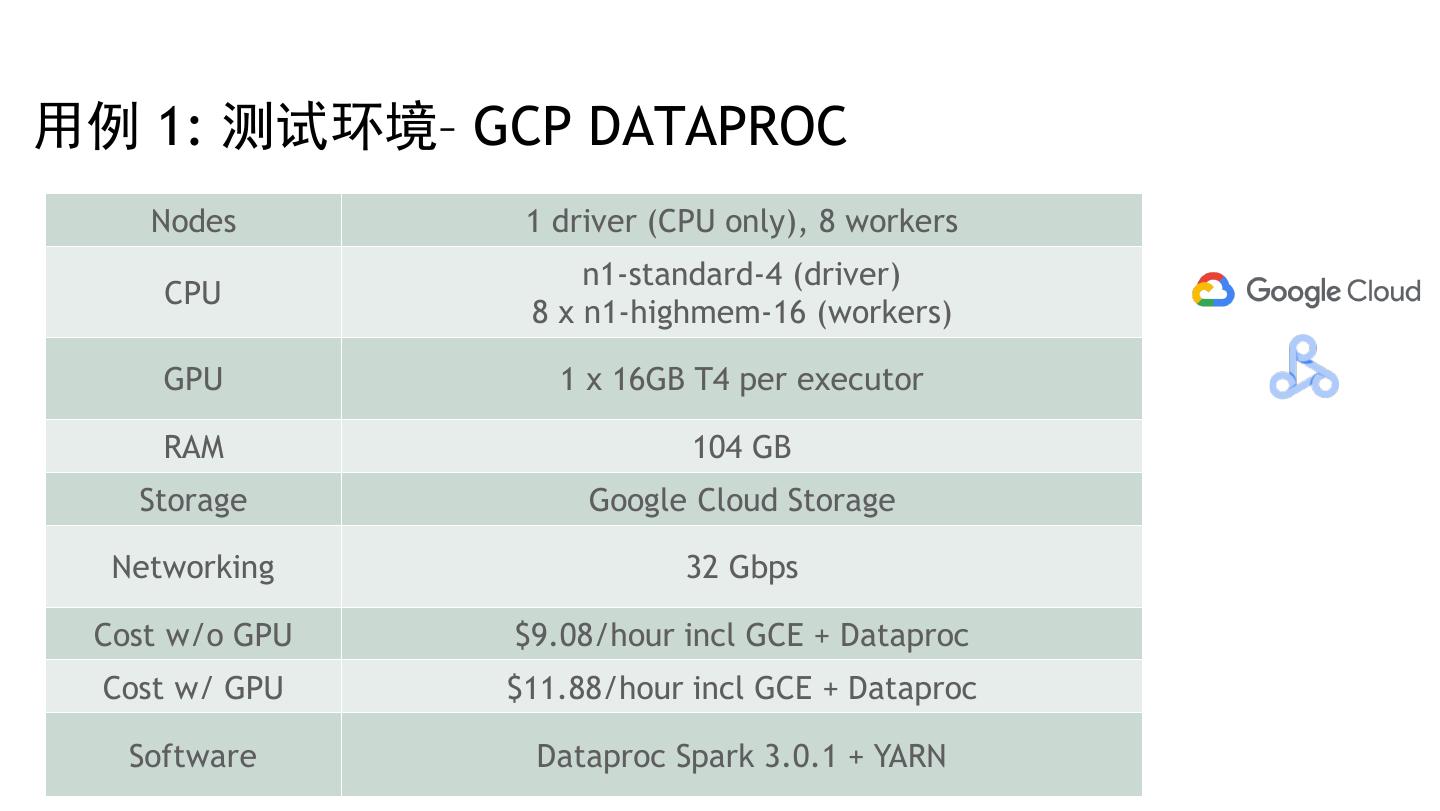
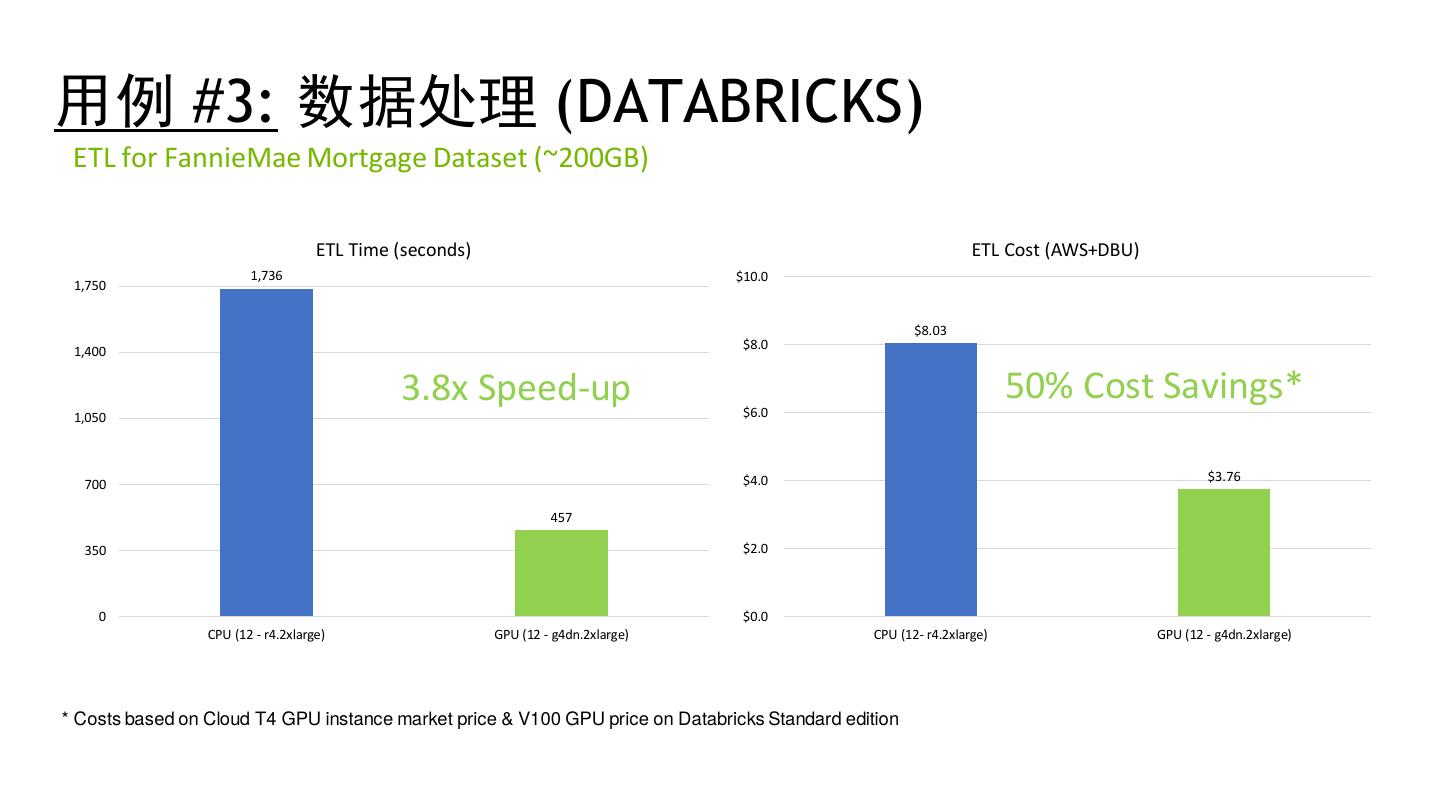
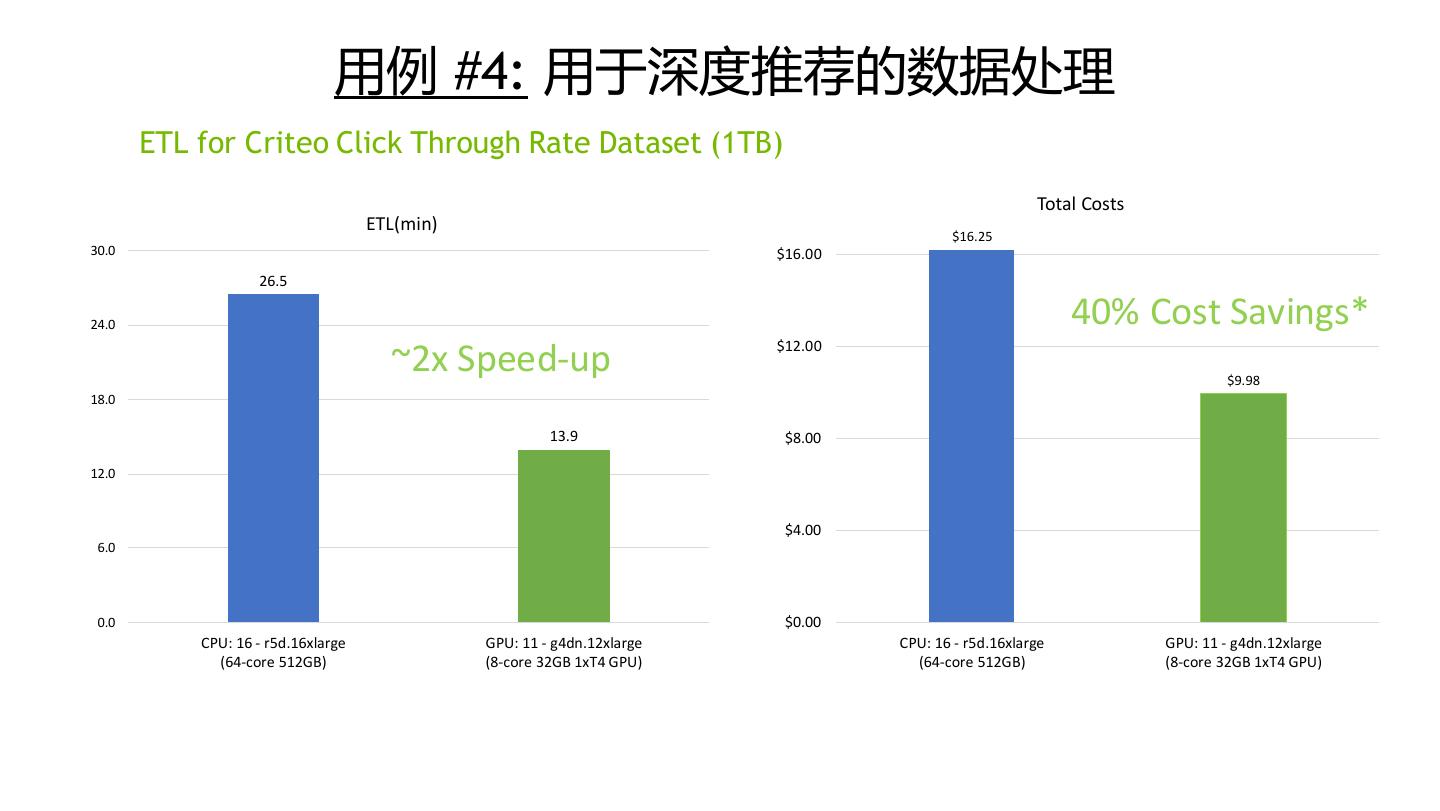
29 .性能测试结果 29
3秒后跳转登录页面
去登陆

