


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark Shuffle RPMem扩展: 借助持久内存与RDMA加速Spark 数据分析
主题:
Spark Shuffle RPMem扩展: 借助持久内存与RDMA加速Spark 数据分析
时间:
10月29日 19:00
观看方式:
扫描下方二维码进钉钉群
或者登陆直播间(即回看链接)
https://developer.aliyun.com/live/245610
讲师:
张建,英特尔亚太研发有限公司大数据部门的软件工程经理,专注于大数据和机器学习中存储方案优化
议题介绍:
Spark Shuffle RPMem扩展提供了一个基于PMem 和RDMA 来加速Shuffle的方案,它采用PMem 作为Shuffle的存储介质,利用PMDK 用户态编程库进行数据读写,减小用户态、内核态切换与文件系统开销;用基于RDMA网络协议异构的传输层实现高性能数据传输;还将RDMA直接注册在PMem上,减少内存拷贝。
本次直播介绍如何利用持久化内存与高性能RDMA 网络来加速Spark Shuffle。
展开查看详情
1 .Spark Shuffle RPMem扩展: 借助持久内存与RDMA加速Spark 数据分析 Spark Shuffle RPMEM extension: Leveraging PMem and RDMA to accelerate Spark data analytics Jian Zhang 张建 Software Engineering Manager October 2020
2 .Agenda § Spark in machine learning § Remote Persistent Memory § Spark Shuffle challenges § Remote persistent memory extension for Spark shuffle § Remote persistent memory extension hands-on instructions § Summary § Call to action 2
3 .Spark in machine learning
4 .Spark usage example in DLRM § Deep Learning Recommendation Model for Personalization and Recommendation Systems. • Leverage embeddings to process sparse Features • Adopt multilayer perceptron (MLP) to process dense features • Interact features explicitly using the statistical techniques • Predict the event probability by postprocessing the interactions with another MLP § Data Processing: • For numerical features, the data preprocessing steps include filling in missing values with 0 and normalization (shifting the values to be >=1 and taking the natural logarithm). • For categorical features, the preprocessing transforms hashed values into a contiguous range of integers starting at 0. § Numpy based data utility vs. SparkSQL • The single threaded numpy takes unnecessarily longer time • runs on a single CPU thread and takes ~5.5 days to transform the whole Criteo Terabyte dataset (1.3TB) * • It takes 4025s for a much smaller dataset (4.3GB raw data) • Using SparkSQL to process the data brings 31.44x speedup § Optimize Spark Performance improves end to end Machine Learning pipeline efficiency! 4
5 .Remote Persistent Memory
6 . Persistent Memory - A New Memory Tier § IDC reports indicated that data is growing very fast • Global datasphere growth rate (CAGR) 27%* • But DRAM density scaling is becoming slower: from 4X/3yr (1997-ish) to 2X/3yr (~1997-2010) to 2X/4yr** (since 2010) • A new memory system will be needed to met the data growth needs for new cases § Persistent Memory (PMem): new category that sits between memory and storage • Delivers a unique combination of affordable large capacity and support for data persistence Storage Hierarchy*** *Source: Data Age 2025, sponsored by Seagate with data from IDC Global DataSphere, Nov 2018 **Source: ”3D NAND Technology – Implications for Enterprise Storage Applications” by J.Yoon (IBM), 2015 Flash Memory Summit *** https://www.intel.com/content/www/us/en/products/docs/memory-storage/optane-persistent-memory/optane-dc-persistent-memory-brief.html 6
7 .Persistent memory Introduction DRAM, or DDR4 DRAM DRAM as § Intel Optane™ PMem*. App Direct cache Storage • Memory Mode Memory • Volatile storage. Provides higher memory capacity. Cache management is handled by processor’s integrated controller. • APP Direct Mode • Non-volatile storage. Application manages its cache data by itself. Read/write bypass page cache. 1 MEMORY mode ● Larger memory at lower cost § Cost APP DIRECT ● Low latency persistent memory • Cost/GB is lower than DRAM. mode ● Persistent data for rapid recovery § Capacity 2 Storage over APP DIRECT ● Fast direct-attach storage • 128GB, 256GB, 512GB * https://www.intel.com/content/www/us/en/architecture-and-technology/optane-dc-persistent- memory.html 7
8 . Remote Persistent Memory Usage High Availability Remote PM Shared Remote PM Data Replication • Extend on-node memory • Replicate Data in local PM • PM holds SHARED data capacity (w/ or w/o persistency) across Fabric and Store in among distributed in a disaggregated architecture remote PM applications to enlarge compute node • For backup • Remote Shuffle service, memory IMDB • IMDB https://www.snia.org/sites/default/files/PM-Summit/2018/presentations/05_PM_Summit_Grun_PM_%20Final_Post_CORRECTED.pdf 8
9 .Remote Persistent Memory over RDMA Remote Persistent Memory offers RDMA offers § Remote persistence, without losing any of characteristic § Moving data between (zero-copy) two system with Volatile of memory DRAM, offload data movement from CPU to NIC § PM is Fast § Low latency § Latency < uses § Needs ultra low-latency networking § PM has very high bandwidth § High BW § 200Gb/s, 400Gb/s, zero-copy, kernel bypass, HW § Needs ultra efficient protocol, transport offload, offered one side memory to remote memory operations high BW § Reliable credit base data and control delivered by HW § Remote access must not add significant latency § Network resiliency, scale-out § Network switches & adaptors deliver predictability, fairness, zero packet loss 9
10 . Peer A Peer B Peer B Peer B APP SW RNIC RNIC Memory Controller PMEM RDMA RPMem Durability RDMA Write Posted Write Write RDMA (Non-Allocating) Write RDMA Posted Write Write (Non-Allocating) RDMA Read RDMA Read Flushing Read • RDMA Write Write • Guarantee that Data has been successfully received and accepted for Read execution by the remote HCA Read Data Read ACK • Doesn’t guarantee data has reached remote host memory – need ADR RDMA Read RDMA Read ACK ACK • Doesn’t guarantee the data can be visible/durable for other consumers accesses (other connections, host processor) Peer A Peer B Peer B Peer B • Using small RDMA read to forces write data to PMem APP SW RDMA RNIC RNIC Memory Controller PMEM Write RDMA Posted Write • New transport operation – RDMA FLUSH RDMA Write (Non-Allocating) RDMA Write Write Posted Write • New RDMA command opcode (Non-Allocating) RDMA Flush RDMA Flush • Flush all previous writes or specific regions Flush Flush • Provides memory placement guarantee to the upper layer software • RDMA Flush forces previous RDMA Write data to durability domain Flush • It makes PM operations with RDMA more efficient! Flush Flush 10
11 .Spark shuffle challenges
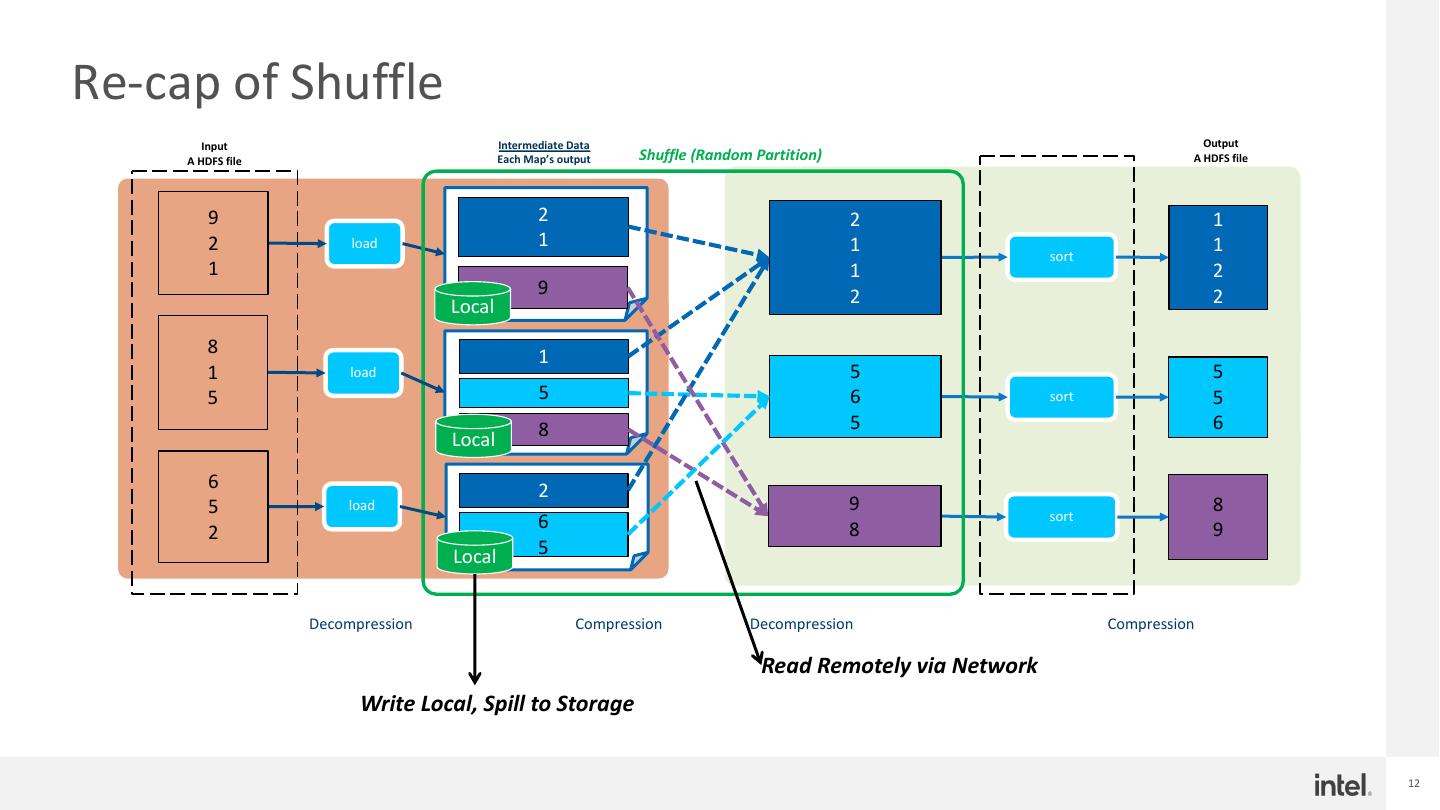
12 .Re-cap of Shuffle Input Intermediate Data Output A HDFS file Each Map’s output Shuffle (Random Partition) A HDFS file 9 2 2 1 2 load 1 1 1 sort 1 1 2 9 2 2 Local 8 1 1 load 5 5 5 5 6 sort 5 8 5 6 Local 6 2 5 load 9 8 6 sort 2 8 9 Local 5 Decompression Compression Decompression Compression Read Remotely via Network Write Local, Spill to Storage 12
13 .Challenges of Spark shuffle § Data Center Infrastructure evolution • Compute and storage disaggregation become a key trend, diskless environment becoming more and more popular • Modern datacenter is evolving: high speed network between compute and disaggregated storage and tiered storage architecture makes local storage less attractive • New storage technologies are emerging, e.g., storage class memory (or PMem) § Spark shuffle Challenges • Uneven resource utilization of CPU and Memory • Out of memory issues and GC • Disk I/O too slow • Data spill degrades performance • Shuffle I/O grows quadratically with data • Local SSDs wear out by frequent intermediate data writes • Unaffordable re-compute cost § Other related works • Intel Disaggregated shuffle w/ DAOS1, Facebook cosco2, Baidu DCE shuffle3, JD.com & Memverge RSS 4 and etc. 1. https://www.slideshare.net/databricks/improving-apache-spark-by-taking-advantage-of-disaggregated-architecture 2. https://databricks.com/session/cosco-an-efficient-facebook-scale-shuffle-service 3. http://apache-spark-developers-list.1001551.n3.nabble.com/Enabling-fully-disaggregated-shuffle-on-Spark-td28329.html 4. https://databricks.com/session/optimizing-performance-and-computing-resource-efficiency-of-in-memory-big-data-analytics-with-disaggregated-persistent-memory 13
14 .Remote persistent memory pool for spark shuffle
15 . Re-cap: Remote Persistent Memory Extension for Spark shuffle Design Worker Worker Executor JVM #1 Executor JVM #1 Shuffle write Shuffle Manager Shuffle Manager 1 Shuffle read 1 Heap obj Heap obj Shuffle Shuffle Shuffle Shuffle Writer Reader Writer(new) bytebuffer Reader(new) PMEM bytebuffer Off-heap Off-heap 2 User 2 3 User PMEM Kernel Spark.Local.dir Kernel 3 Shuffle file 4 Shuffle file Drivers SSD HDD NIC PMEM RDMA NIC § 1. Serialize obj to off-heap memory 1. Serialize obj to off-heap memory § 2. Write to local shuffle dir 2. Persistent to PMEM § 3. Read from local shuffle dir 3. Read from remote PMEM through RDMA, PMEM is § 4. Send to remote reader through TCP-IP used as RDMA memory buffer Ø Lots of context switch Ø No context switch Ø POSIX buffered read/write on shuffle disk Ø Efficient read/write on PMEM Ø TCP/IP based socket send for remote shuffle read Ø RDMA read for remote shuffle read Spark PMoF: https://github.com/intel-bigdata/spark-pmof Strata-ca-2019: https://conferences.oreilly.com/strata/strata-ca-2019/public/schedule/detail/72992 15
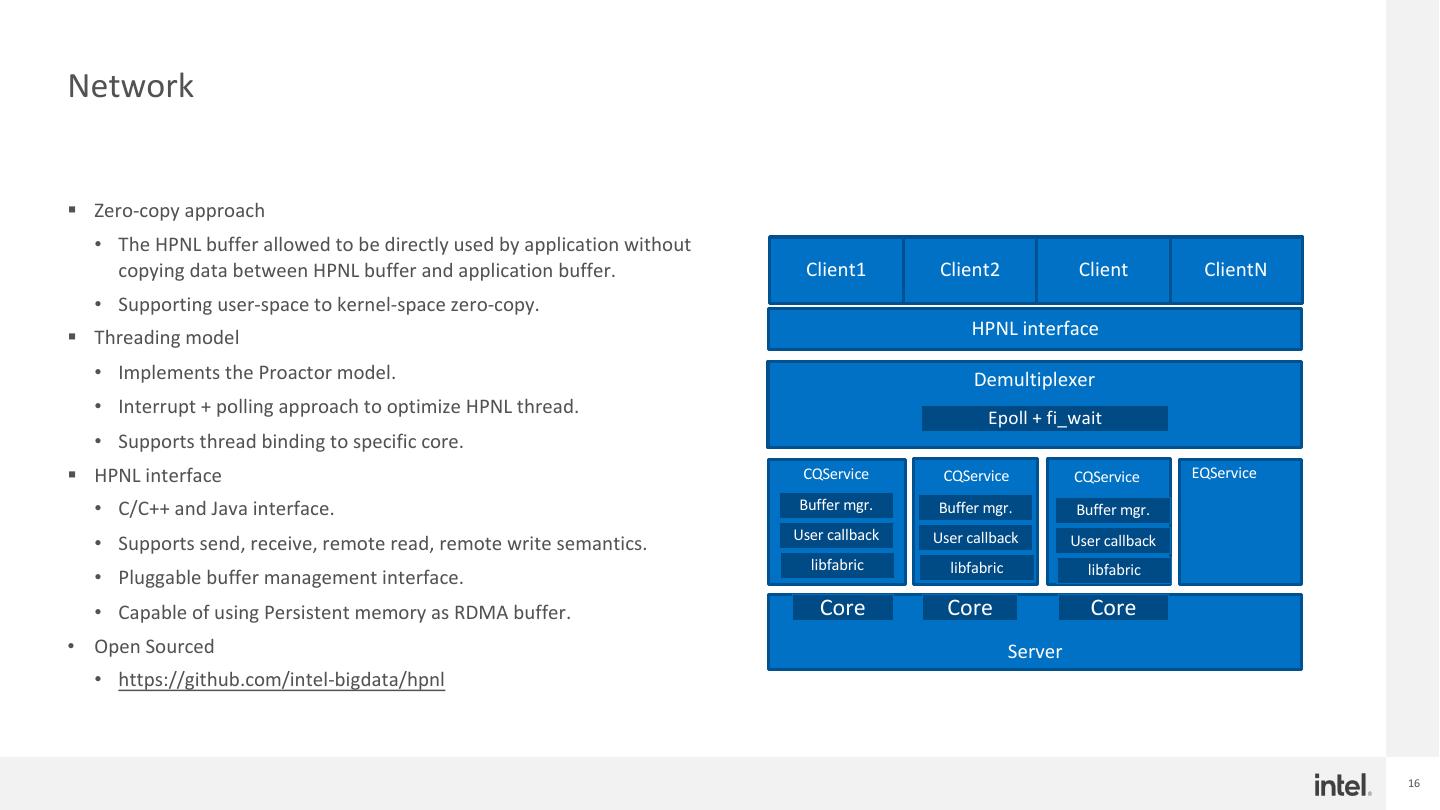
16 .Network § Zero-copy approach • The HPNL buffer allowed to be directly used by application without copying data between HPNL buffer and application buffer. Client1 Client2 Client ClientN • Supporting user-space to kernel-space zero-copy. § Threading model HPNL interface • Implements the Proactor model. Demultiplexer • Interrupt + polling approach to optimize HPNL thread. Epoll + fi_wait • Supports thread binding to specific core. § HPNL interface CQService CQService CQService EQService • C/C++ and Java interface. Buffer mgr. Buffer mgr. Buffer mgr. User callback User callback • Supports send, receive, remote read, remote write semantics. User callback libfabric libfabric libfabric • Pluggable buffer management interface. • Capable of using Persistent memory as RDMA buffer. Core Core Core • Open Sourced Server • https://github.com/intel-bigdata/hpnl 16
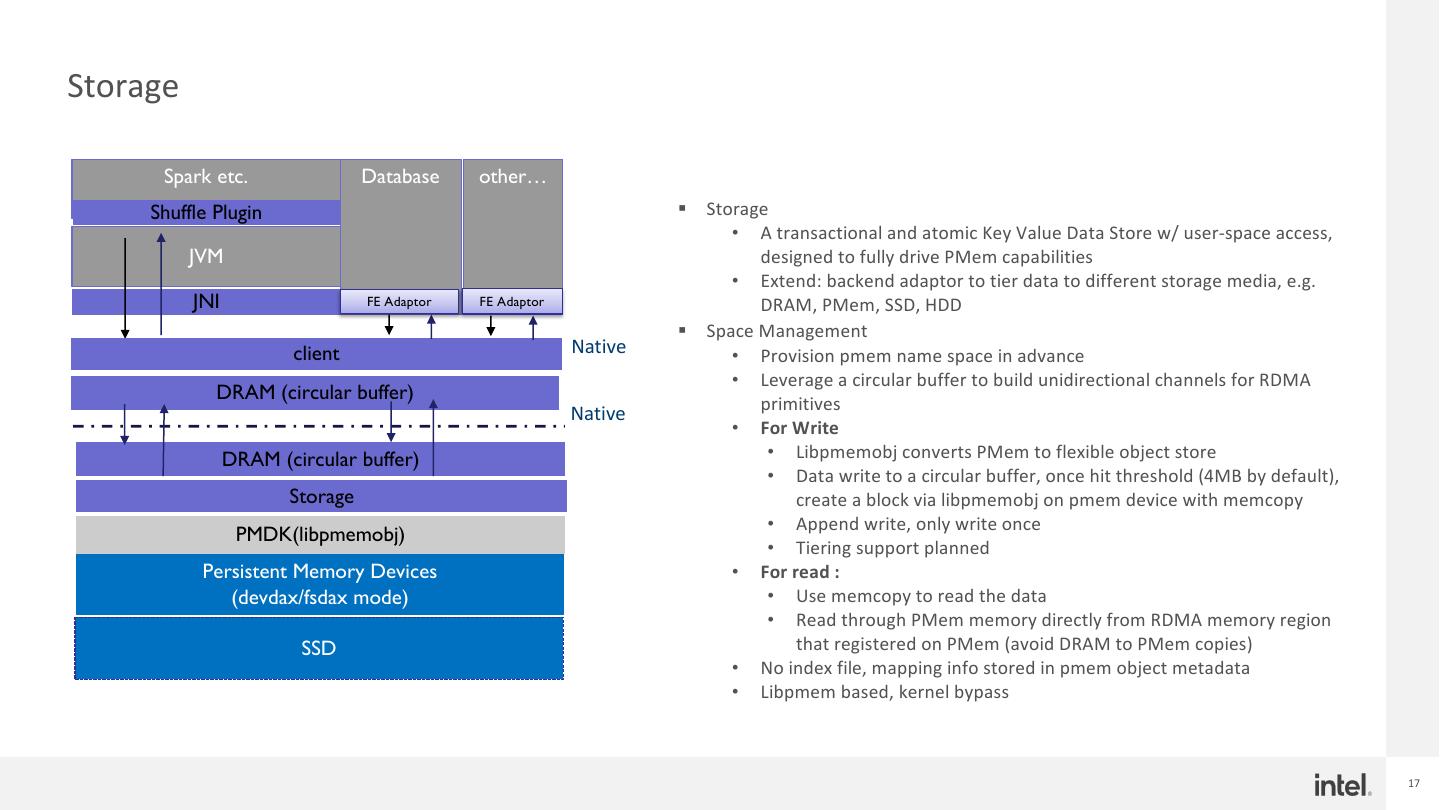
17 .Storage Spark etc. Database other… Shuffle Plugin § Storage • A transactional and atomic Key Value Data Store w/ user-space access, JVM designed to fully drive PMem capabilities • Extend: backend adaptor to tier data to different storage media, e.g. JNI FE Adaptor FE Adaptor DRAM, PMem, SSD, HDD § Space Management client Native • Provision pmem name space in advance • Leverage a circular buffer to build unidirectional channels for RDMA DRAM (circular buffer) primitives Native • For Write DRAM (circular buffer) • Libpmemobj converts PMem to flexible object store • Data write to a circular buffer, once hit threshold (4MB by default), Storage create a block via libpmemobj on pmem device with memcopy • Append write, only write once PMDK(libpmemobj) • Tiering support planned Persistent Memory Devices • For read : (devdax/fsdax mode) • Use memcopy to read the data • Read through PMem memory directly from RDMA memory region SSD that registered on PMem (avoid DRAM to PMem copies) • No index file, mapping info stored in pmem object metadata • Libpmem based, kernel bypass 17
18 .Data layout CircularBuffer Client RmaBufferR Read_m Write_ buffer bits egister utex mutex Request Request TaskExecutor Request … RDMA RECV READ ACK CircularBuffer indexmap buffer … Key PMemoid (addr) PUT RecvWorker ReadWorker FinalizeWorker Allocateandwrite PMem PMem Base Pool Bytes_writ Head Tail rwlock en Block Block_hdr data Block Block_hdr data entry Next Pre addr size … entry Next Pre addr size 18
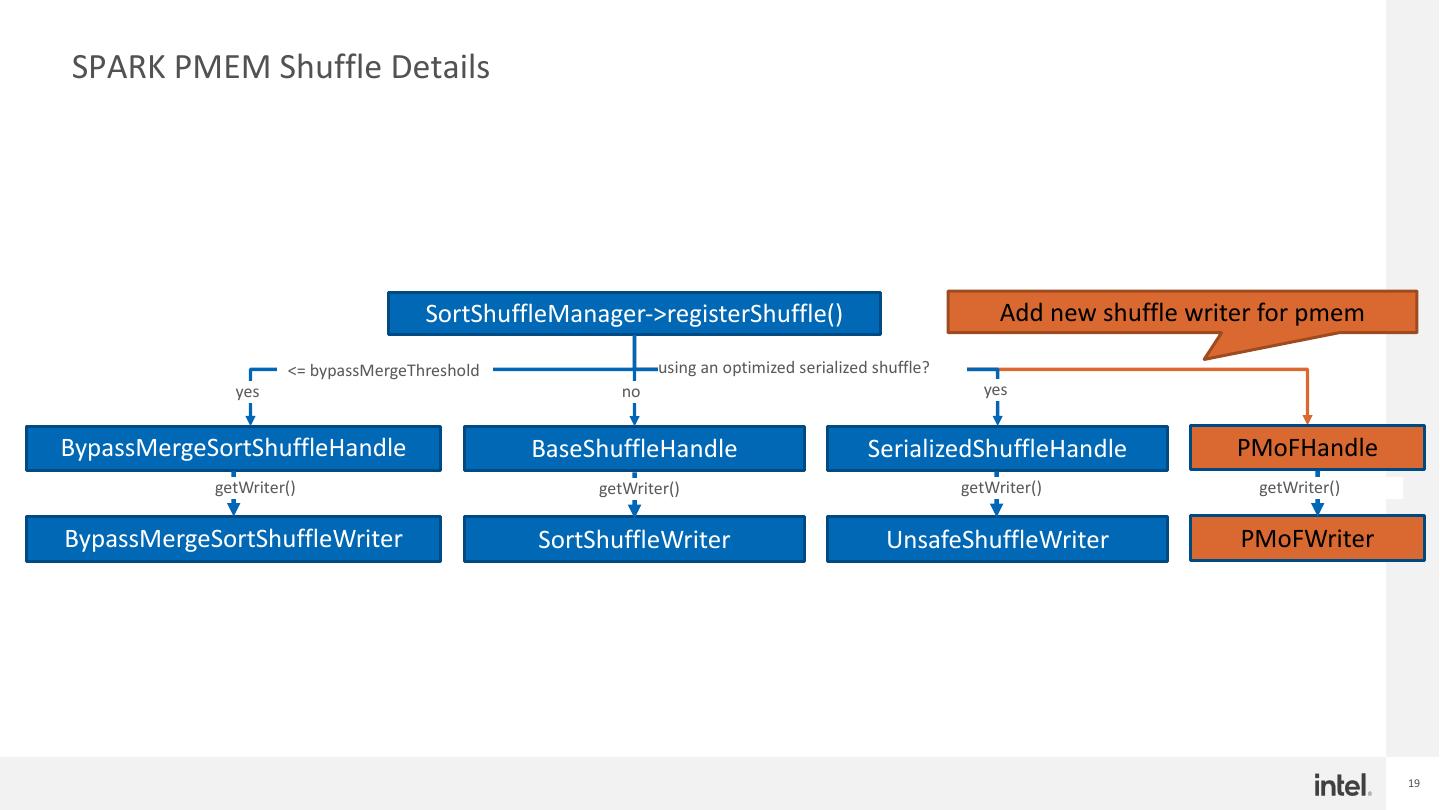
19 .SPARK PMEM Shuffle Details SortShuffleManager->registerShuffle() Add new shuffle writer for pmem <= bypassMergeThreshold using an optimized serialized shuffle? yes no yes BypassMergeSortShuffleHandle BaseShuffleHandle SerializedShuffleHandle PMoFHandle getWriter() getWriter() getWriter() getWriter() BypassMergeSortShuffleWriter SortShuffleWriter UnsafeShuffleWriter PMoFWriter 19
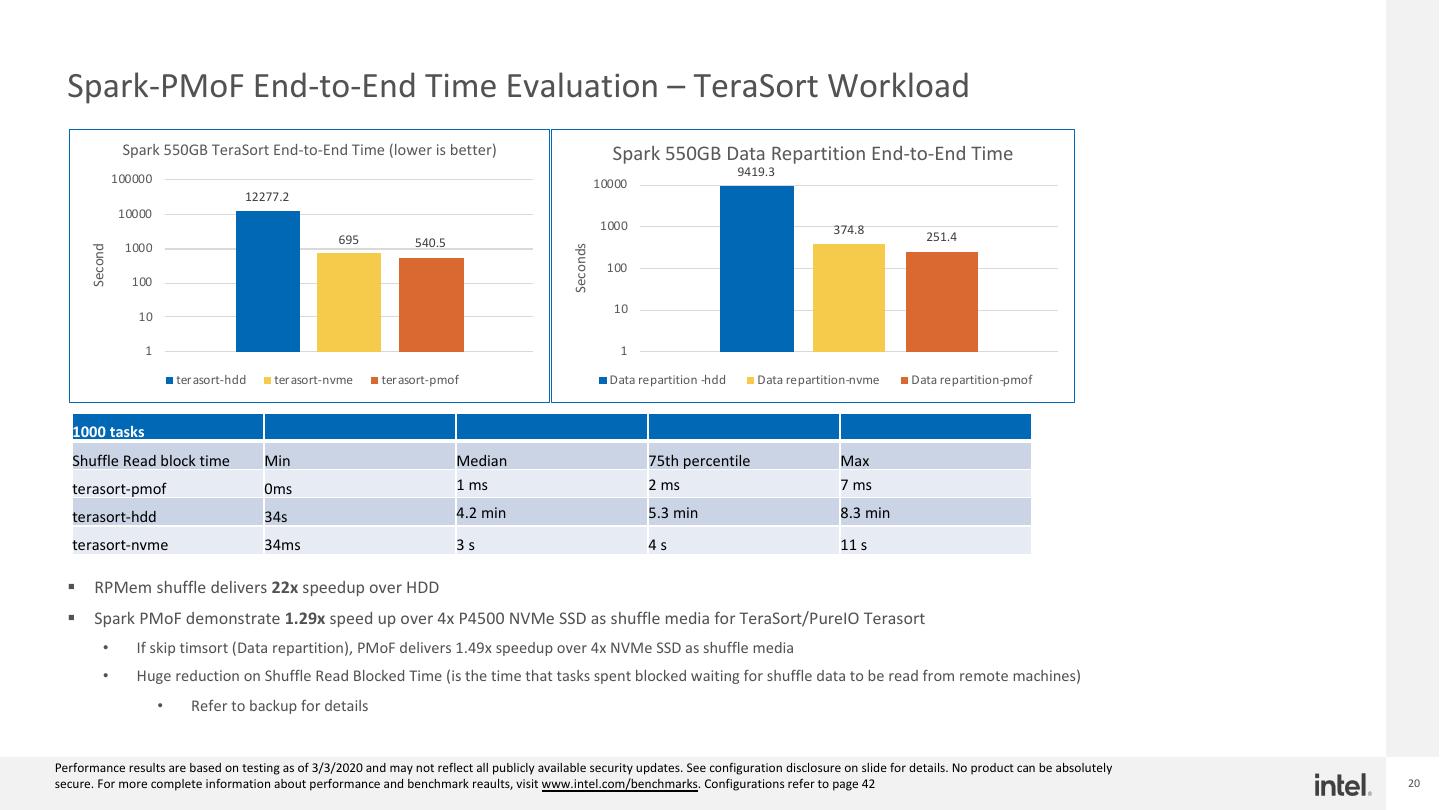
20 . Spark-PMoF End-to-End Time Evaluation – TeraSort Workload Spark 550GB TeraSort End-to-End Time (lower is better) Spark 550GB Data Repartition End-to-End Time 9419.3 100000 10000 12277.2 10000 1000 374.8 695 540.5 251.4 1000 Seconds Second 100 100 10 10 1 1 terasort-hdd terasort-nvme terasort-pmof Data repartition -hdd Data repartition-nvme Data repartition-pmof 1000 tasks Shuffle Read block time Min Median 75th percentile Max terasort-pmof 0ms 1 ms 2 ms 7 ms terasort-hdd 34s 4.2 min 5.3 min 8.3 min terasort-nvme 34ms 3s 4s 11 s § RPMem shuffle delivers 22x speedup over HDD § Spark PMoF demonstrate 1.29x speed up over 4x P4500 NVMe SSD as shuffle media for TeraSort/PureIO Terasort • If skip timsort (Data repartition), PMoF delivers 1.49x speedup over 4x NVMe SSD as shuffle media • Huge reduction on Shuffle Read Blocked Time (is the time that tasks spent blocked waiting for shuffle data to be read from remote machines) • Refer to backup for details Performance results are based on testing as of 3/3/2020 and may not reflect all publicly available security updates. See configuration disclosure on slide for details. No product can be absolutely secure. For more complete information about performance and benchmark reaults, visit www.intel.com/benchmarks. Configurations refer to page 42 20
21 . Shuffle disk details HDD NVMe PMem HDD shuffle write BW (single HDD) 80000 60000 40000 20000 0 1001 1101 1201 1301 1401 1501 1601 1701 1801 1 101 201 301 401 501 601 701 801 901 rkB/s wk B/s • HDD shuffle: ~25MB/s, HDD is the bottleneck (small random I/O ~100KB for write, ~200KB for read ), throttled by await & util% • NVMe shuffle: Peak Shuffle Read BW: 150MB/s+ for single NVMe, ~500MB/s for single node • PMem shuffle: average 749MB/s, Peak 4GB/s 21
22 . Profiling Data for TeraSort (Spark-PMoF vs Vanilla Spark on NVMe) CPU utilization Network bandwidth Disk bandwidth Memory Vanilla Spark on NVMe Spark-PMoF 22
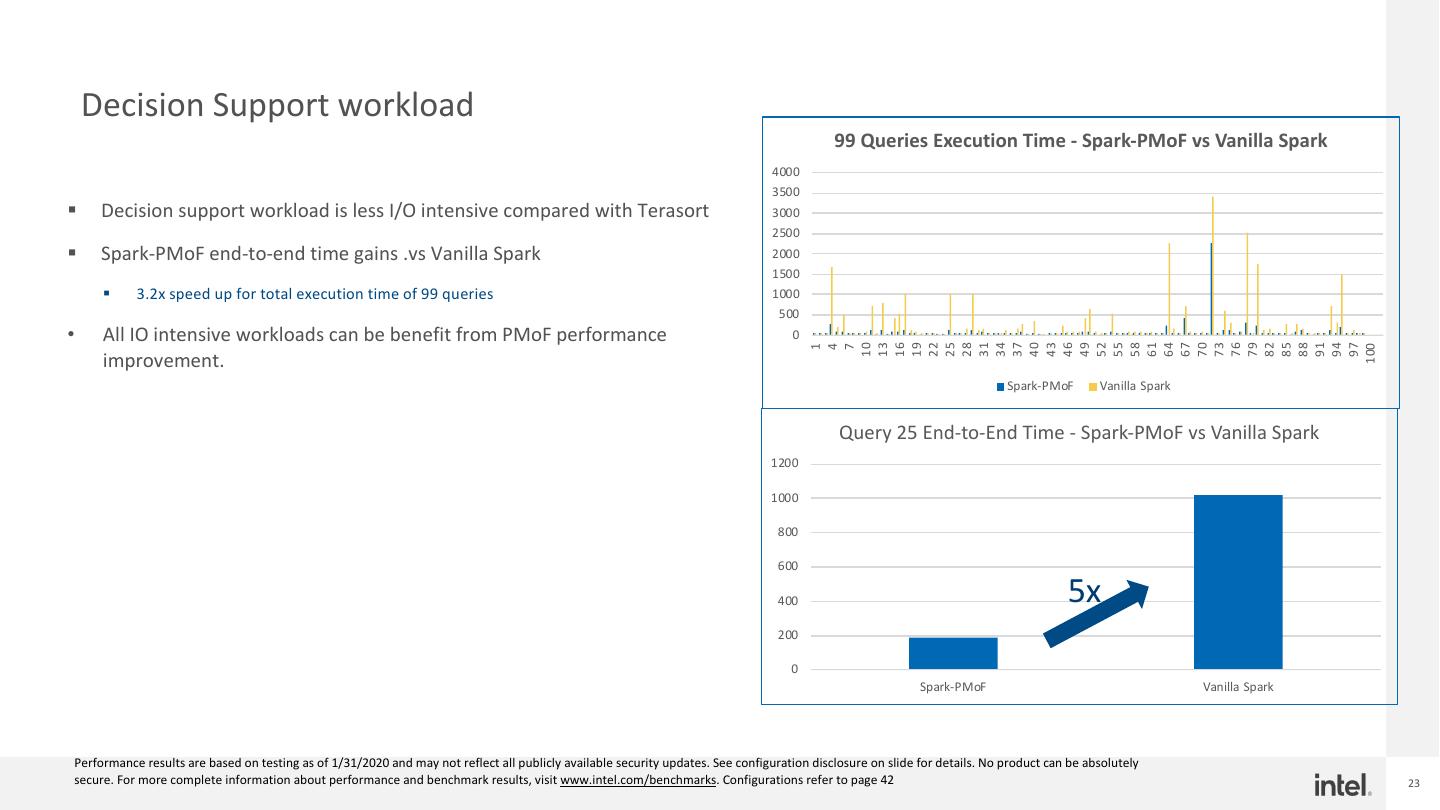
23 . Decision Support workload 99 Queries Execution Time - Spark-PMoF vs Vanilla Spark 4000 3500 § Decision support workload is less I/O intensive compared with Terasort 3000 2500 § Spark-PMoF end-to-end time gains .vs Vanilla Spark 2000 1500 § 3.2x speed up for total execution time of 99 queries 1000 500 • All IO intensive workloads can be benefit from PMoF performance 0 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 1 4 7 100 improvement. Spark-PMoF Vanilla Spark Query 25 End-to-End Time - Spark-PMoF vs Vanilla Spark 1200 1000 800 600 400 5x 200 0 Spark-PMoF Vanilla Spark Performance results are based on testing as of 1/31/2020 and may not reflect all publicly available security updates. See configuration disclosure on slide for details. No product can be absolutely secure. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Configurations refer to page 42 23
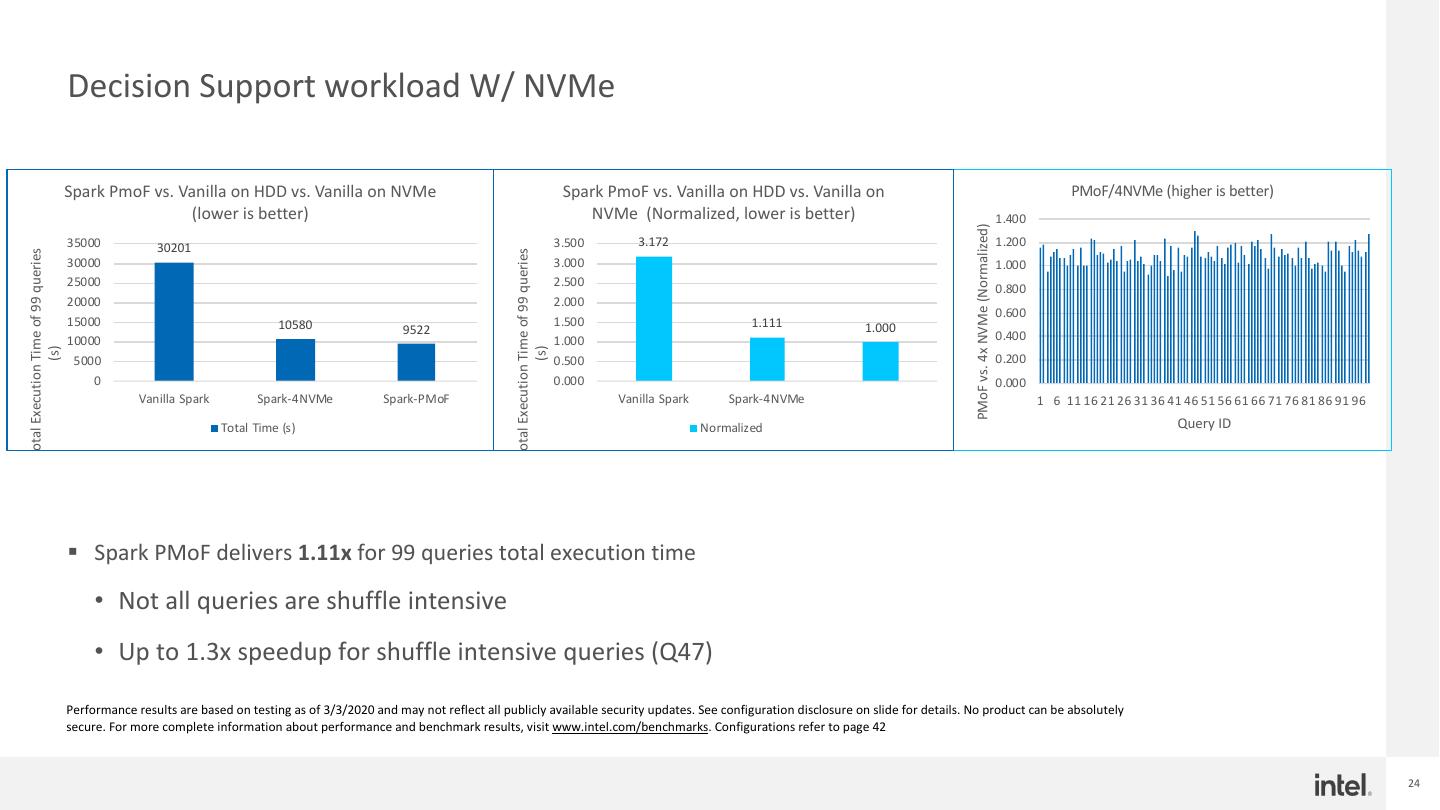
24 . Decision Support workload W/ NVMe Spark PmoF vs. Vanilla on HDD vs. Vanilla on NVMe Spark PmoF vs. Vanilla on HDD vs. Vanilla on PMoF/4NVMe (higher is better) (lower is better) NVMe (Normalized, lower is better) 1.400 PMoF vs. 4x NVMe (Normalized) 35000 30201 3.500 3.172 1.200 Total Execution Time of 99 queries Total Execution Time of 99 queries 30000 3.000 1.000 25000 2.500 0.800 20000 2.000 0.600 15000 10580 1.500 1.111 1.000 9522 0.400 10000 1.000 (s) (s) 5000 0.500 0.200 0 0.000 0.000 Vanilla Spark Spark-4NVMe Spark-PMoF Vanilla Spark Spark-4NVMe 1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86 91 96 Total Time (s) Normalized Query ID § Spark PMoF delivers 1.11x for 99 queries total execution time • Not all queries are shuffle intensive • Up to 1.3x speedup for shuffle intensive queries (Q47) Performance results are based on testing as of 3/3/2020 and may not reflect all publicly available security updates. See configuration disclosure on slide for details. No product can be absolutely secure. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Configurations refer to page 42 24
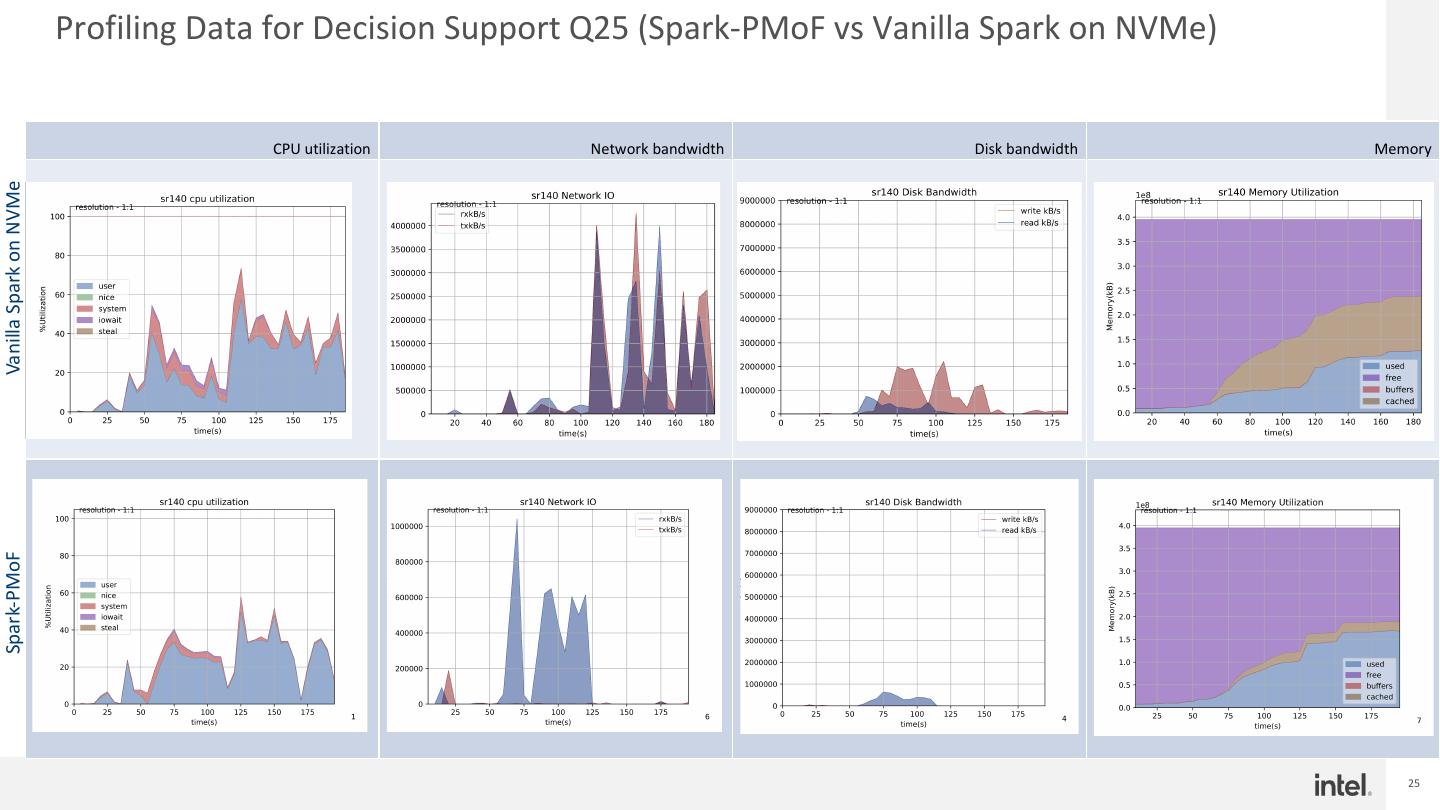
25 . Profiling Data for Decision Support Q25 (Spark-PMoF vs Vanilla Spark on NVMe) CPU utilization Network bandwidth Disk bandwidth Memory Vanilla Spark on NVMe Spark-PMoF 25
26 .Extending to fully Disaggregated Shuffle solution § Remote Persistent Memory for read demonstrated good results, but what’s more? § In real production environment, there are more challenges • Disaggregated, diskless environment • Scale shuffle/compute independently • CPU/Memory unbalanced issue • Some jobs lasts for long time, stage recompute cost is intolerable in case of shuffle failure § Elastic Deployment with compute and storage disaggregation requires independent shuffle solution • Decouple shuffle I/O from a specific network/storage is capable of delivering dedicated SLA for critical applications • Fault tolerant in case on shuffle failure, no need for recompute • Offload spill as well, reduced compute memory resource requirements • Balanced resource utilization • Leverage state-of-art storage medium as storage media • To provide high performance, high endurance storage backend § Drive the intention to build a RPMem based, fully disaggregated shuffle solution! 26
27 .RPMP Architecture § Remote Persistent Memory Pool: SQL K/V Transactions Streaming Machine Learning § A persistent memory based distributed storage system § An RDMA powered network library and an innovative approach to use persistent Compute memory as both shuffle media as well as RDMA memory region to reduce additional Spark Flink Presto memory copies and context switches. shuffle data cache § Target as high-performance storage & ephemeral data storage Storage Ephemeral Data § Features RPMP Data Lake § High Performance Storage powered by modern HW like PMem and RDMA w/ user- DRAM PMem SSD Object Block File level I/O access § Rich API: Provides memory-like allocate/free/read/write APIs on pooled PMem resources § Pluggable modules: A modular architecture makes it can be plugged into in memory database, Apache Spark (shuffle) & Cache etc. § Heterogeneous tiered storage backend § Benefits § Improved scalability of analytics and AI workloads by disaggregating ephemeral data from compute node to a high-performance distributed storage, e.g., Spark shuffle § Improved performance with high speed persistent memory and low latency RDMA network § Improved reliability by providing a manageable and highly available disaggregated storage supports ephemeral data replication and fault-tolerant, e.g. shuffle data to avoid recompute. 27
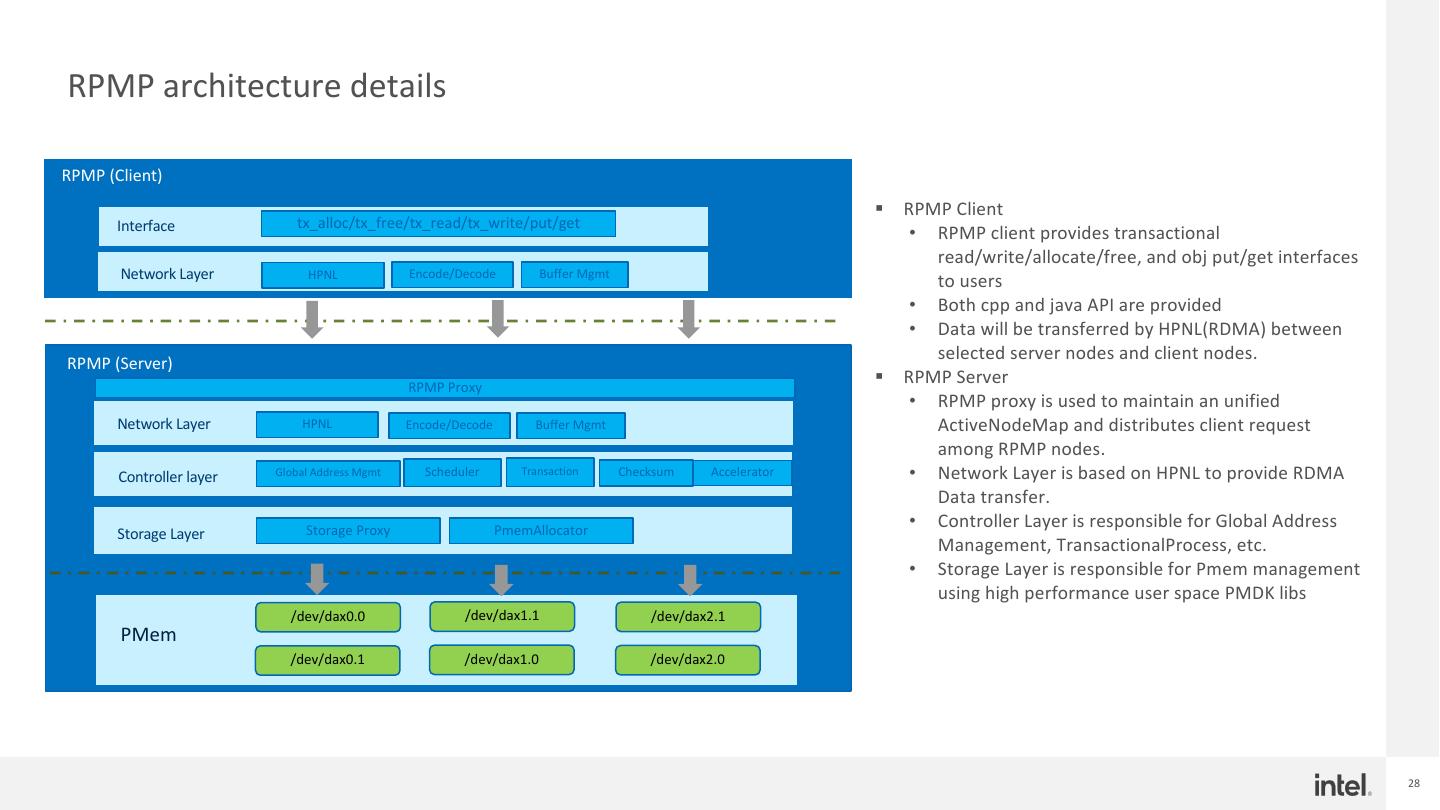
28 .RPMP architecture details RPMP (Client) § RPMP Client Interface tx_alloc/tx_free/tx_read/tx_write/put/get • RPMP client provides transactional read/write/allocate/free, and obj put/get interfaces Network Layer HPNL Encode/Decode Buffer Mgmt to users • Both cpp and java API are provided • Data will be transferred by HPNL(RDMA) between RPMP (Server) selected server nodes and client nodes. RPMP Proxy § RPMP Server • RPMP proxy is used to maintain an unified Network Layer HPNL Encode/Decode Buffer Mgmt ActiveNodeMap and distributes client request among RPMP nodes. Controller layer Global Address Mgmt Scheduler Transaction Checksum Accelerator • Network Layer is based on HPNL to provide RDMA Data transfer. Storage Proxy PmemAllocator • Controller Layer is responsible for Global Address Storage Layer Management, TransactionalProcess, etc. • Storage Layer is responsible for Pmem management using high performance user space PMDK libs /dev/dax0.0 /dev/dax1.1 /dev/dax2.1 PMem /dev/dax0.1 /dev/dax1.0 /dev/dax2.0 28
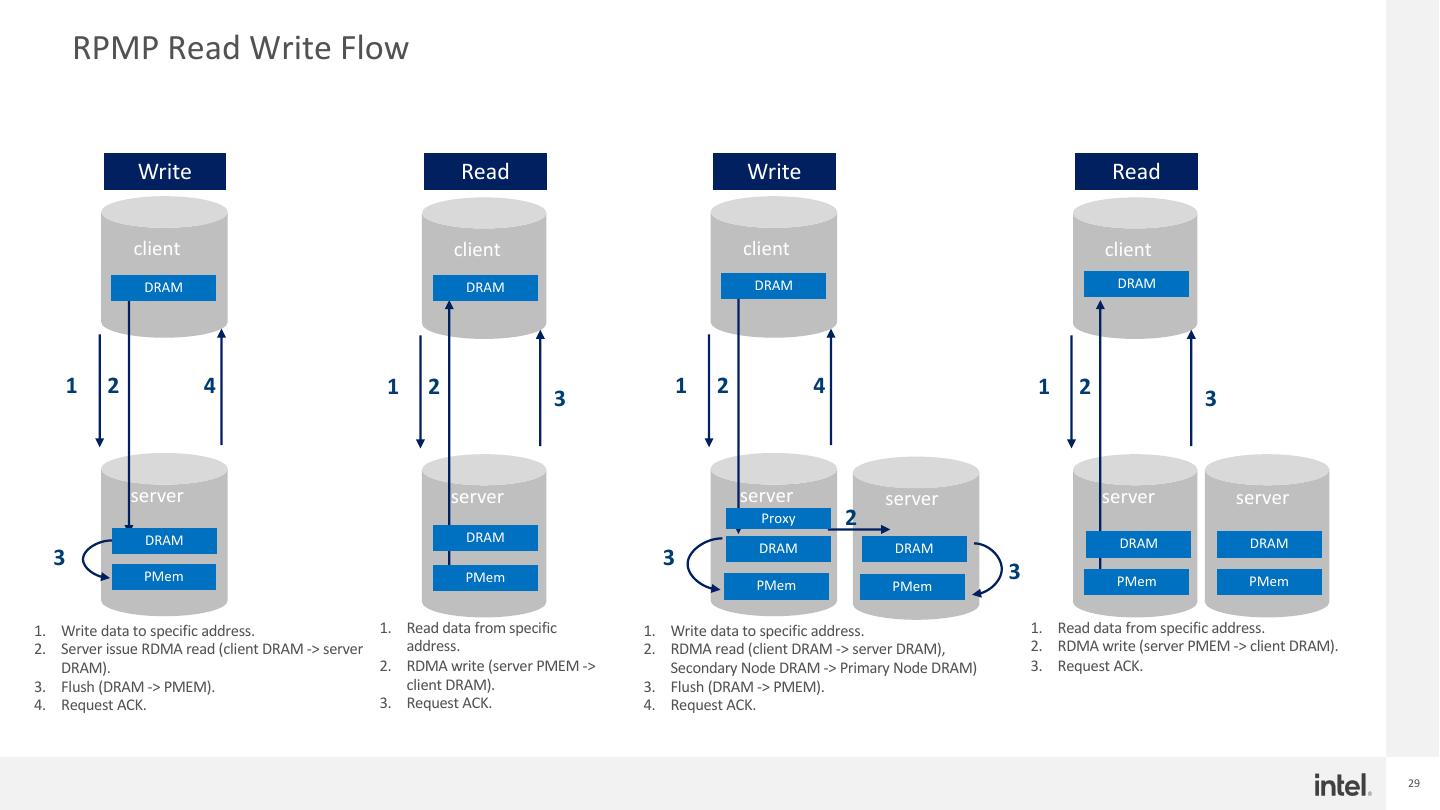
29 . RPMP Read Write Flow Write Read Write Read client client client client DRAM DRAM DRAM DRAM 1 2 4 1 2 1 2 4 1 2 3 3 server server server server server server Proxy 2 DRAM DRAM DRAM DRAM DRAM DRAM 3 3 PMem PMem PMem PMem 3 PMem PMem 1. Write data to specific address. 1. Read data from specific 1. Write data to specific address. 1. Read data from specific address. 2. Server issue RDMA read (client DRAM -> server address. 2. RDMA read (client DRAM -> server DRAM), 2. RDMA write (server PMEM -> client DRAM). DRAM). 2. RDMA write (server PMEM -> Secondary Node DRAM -> Primary Node DRAM) 3. Request ACK. 3. Flush (DRAM -> PMEM). client DRAM). 3. Flush (DRAM -> PMEM). 4. Request ACK. 3. Request ACK. 4. Request ACK. 29
3秒后跳转登录页面
去登陆

