展开查看详情
1 .基于 Spark 和 TensorFlow
的机器学习实践
吴威
阿里云高级技术专家
江宇
阿里云技术专家
�
2 . 01 EMR E-Learning平台
Contents
目录
02 TensorFlow on Spark
�
4 . 大数据和 AI
大数据 AI 大数据与 AI
ETL
Data Warehouse BI 通过数据来获取经验构建模型,广泛的用于日常生活 大数据以及计算能力的提升
批处理与实时处理,多维分析 如自然语言处理、推荐系统、计算机视觉等 AI突飞猛进的发展
数据湖
�
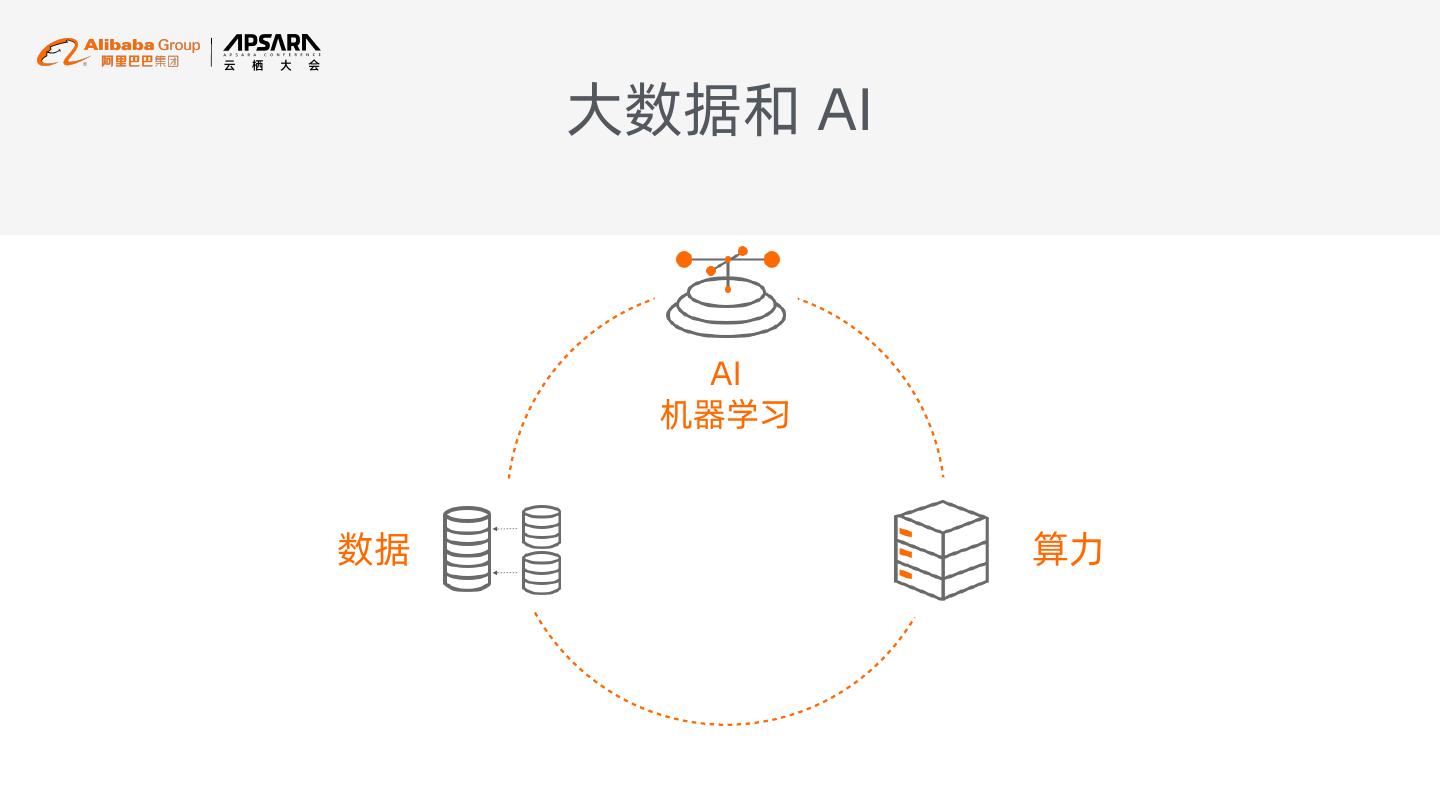
5 . 大数据和 AI
AI
机器学习
数据 算力
�
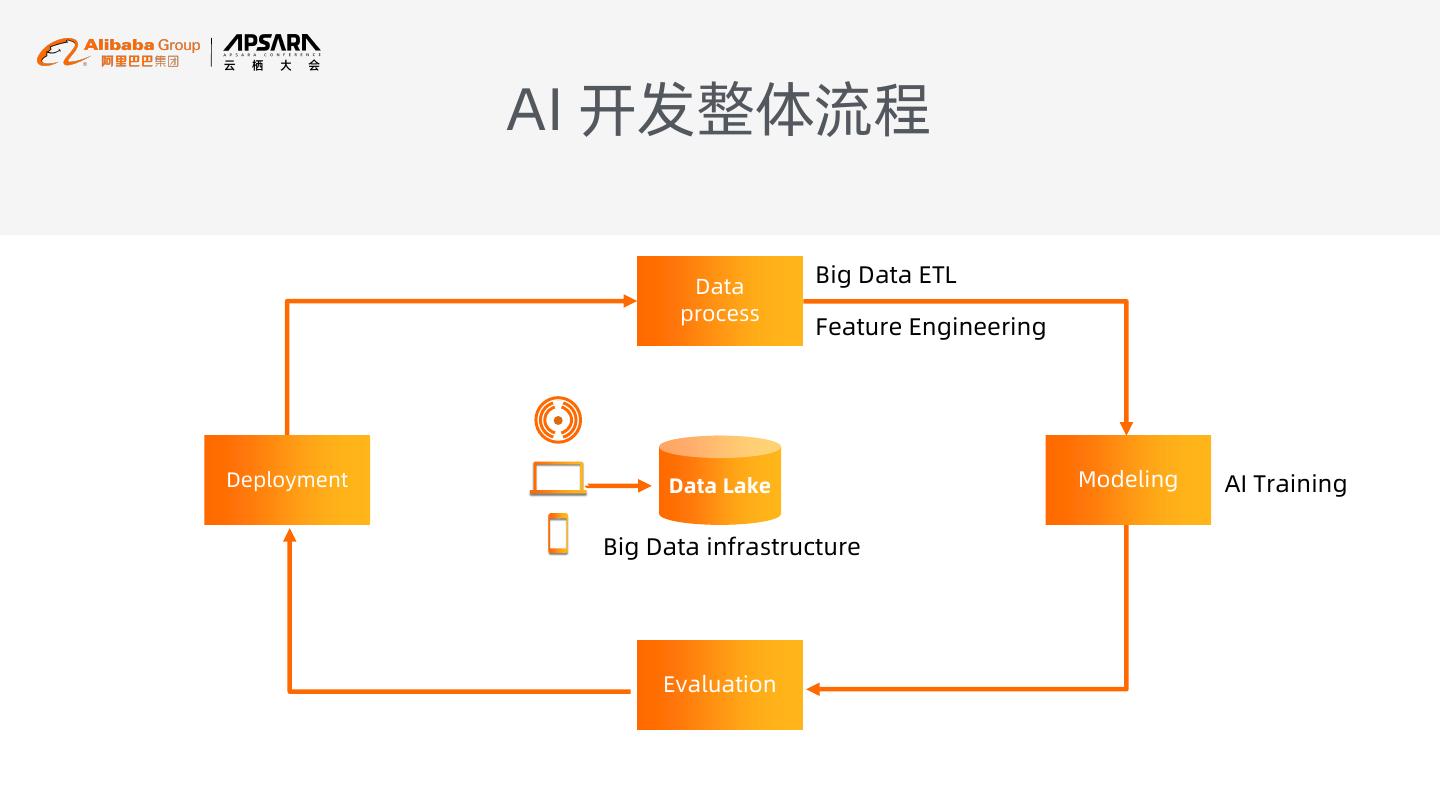
6 . AI 开发整体流程
Data
Big Data ETL
process
Feature Engineering
Deployment Data Lake Modeling AI Training
Big Data infrastructure
Evaluation
�
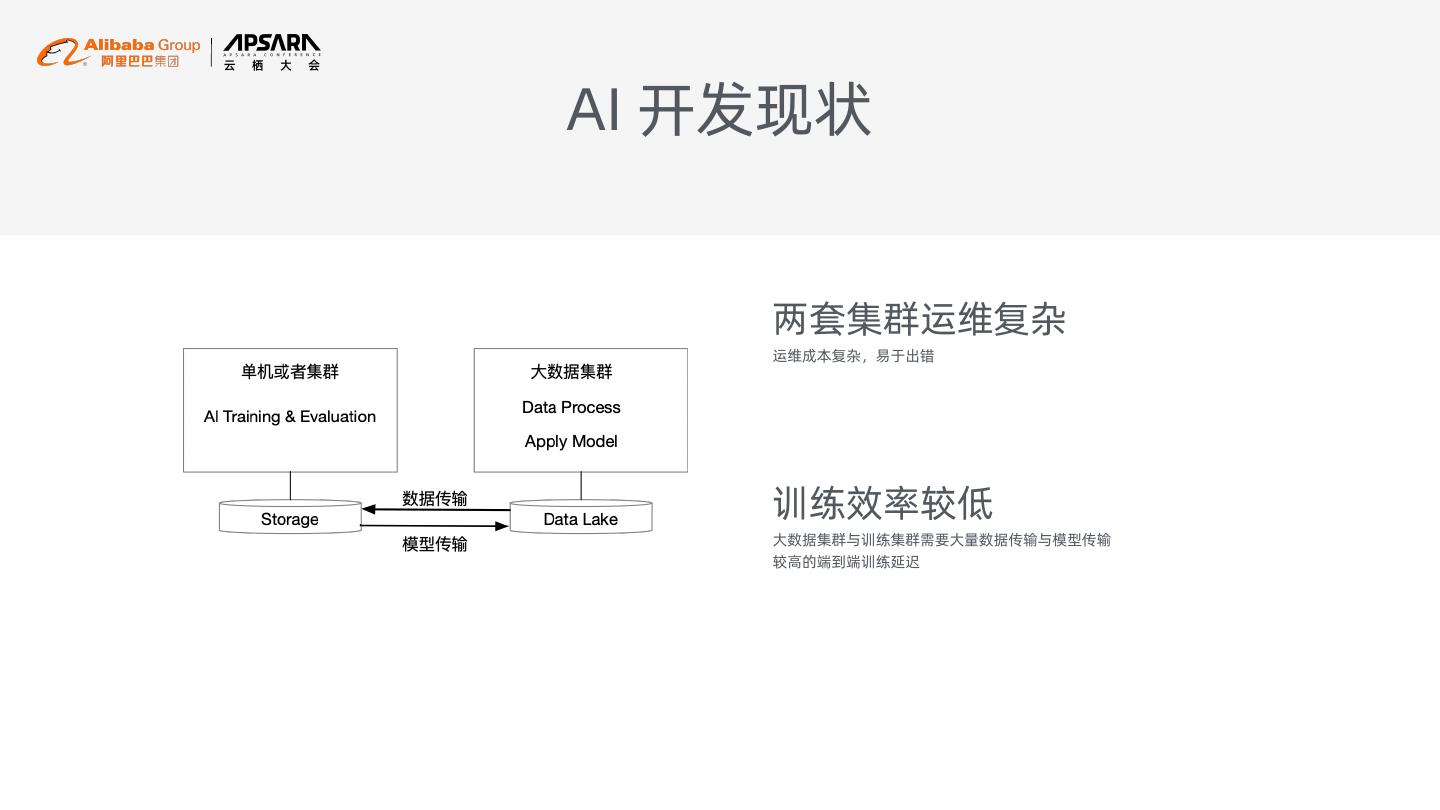
7 .AI 开发现状
两套集群运维复杂
运维成本复杂,易于出错
训练效率较低
大数据集群与训练集群需要大量数据传输与模型传输
较高的端到端训练延迟
�
8 . EMR 统一的数据平台
Feature AI Batch
Data Access Data Analysis Notebook 计算与分析
Engineering Training Streaming
E-Learning
PAI TensorFlow on
Analytics Zoo Presto Impala
Spark
Spark Spark Storm 计算引擎
Spark SQL PySpark GraphX Hive
Streaming MLlib
Spark Core (Jindo Spark) MapReduce Flink
资源调度
YARN Kubernetes ZooKeeper 资源协调
Kafka Flume 数据接入层 HDFS JindoFS / OSS 存储系统 (Data Lake)
ECS CPU Servers ECS GPU Servers 基础资源
�
9 . E-Learning 平台特性
统一的资源管理与调度 多框架的支持
CPU, Mem, GPU 多种深度学习框架的支持 TensorFlow, MXNet, Caffe
高资源利用率,更细粒度的资源分配 阿里巴巴 PAI TensorFlow的支持
支持YARN,Kubernetes资源调度框架
Spark通用的数据处理框架 Spark + 深度学习框架
Data Source API 方便读取各类数据源 Spark和深度学习框架高效数据传输
MLlib pipeline 广泛的用于特征工程 Spark资源调度模型支持分布式深度学习训练
资源监控与报警 易用性
EMR APM系统提供完善的应用程序与集群监控 Jupyter notebook 以及Python 多环境部署支持
多种报警方式 端到端机器学习训练流程
�
10 . E-Learning 集成 PAI TensorFlow
PAI TensorFlow PAI TensorFlow
对深度学习的优化 对大规模稀疏场景的优化
Hierarchal RIngAllReduce 动态弹性伸缩
基于自动分组的梯度融合 GRPC++,提高通信吞吐
梯度压缩 动态数据分发
快速容错
�
11 .TensorFlow on Spark
02
�
12 . TensorFlow on Spark设计目标
• 方便的与现有的Spark 数据处理流程结合
• 用户现有TensorFlow程序不需要改动就可以迁移
• 支持TensorFlow的所有功能
• 支持高效的数据传输,加速从特征工程到训练时间
• PAI TensorFlow 底层的通信优化及大量的算法组件
• 快速支持各种框架接入 MXNet, Caffe
�
13 . TensorFlow on Spark架构
ZooKeeper
Service Registry
Spark Executor Spark Executor
TensorFlow Ps Driver TensorFlow Worker Driver
Spark Executor Spark Executor Spark Executor Spark Executor
TensorFlow Ps Task TensorFlow Ps Task TensorFlow Worker Task TensorFlow Worker Task
PAI TensorFlow Runtime PAI TensorFlow Runtime PAI TensorFlow Runtime PAI TensorFlow Runtime
控制流
数据流
Data Lake
�
14 . 数据交互
Spark Executor
JVM Python Worker
Spark PythonRDD Pandas PAI TensorFlow
DataFrame Object Apache DataFrame Runtime
Arrow
Spark Executor
JVM Python Worker
Spark PythonRDD Pandas PAI TensorFlow
DataFrame Object Apache DataFrame Runtime
Arrow
�
15 . 容错机制
Barrier Barrier
Horovod Workers
• TensorFlow Checkpoints 定期写入Data Lake
• PS 和 Worker 任务之间存在daemon进程,监控对应任务运行情况
• MPI任务通过Spark Barrier Execution 重启所有task,重新配置所有环境变量
• TF任务负责读取最近的Checkpoint
Checkpoint
�
16 . 功能和易用性
• 部署环境多样
支持指定conda,打包python运行时virtual env
支持指定docker
• TensorFlow 架构支持 E-Learning
支持分布式TensorFlow原生PS架构
支持分布式Horovod MPI架构
TensorFlow Horovod Keras MXNet
• TensorFlow API支持
支持分布式TensorFlow Estimator高阶API EMR Spark (Jindo)
支持分布式TensorFlow Session 低阶API
• 快速支持各种框架接入
根据客户需求加入新的AI框架,如MXNet
�
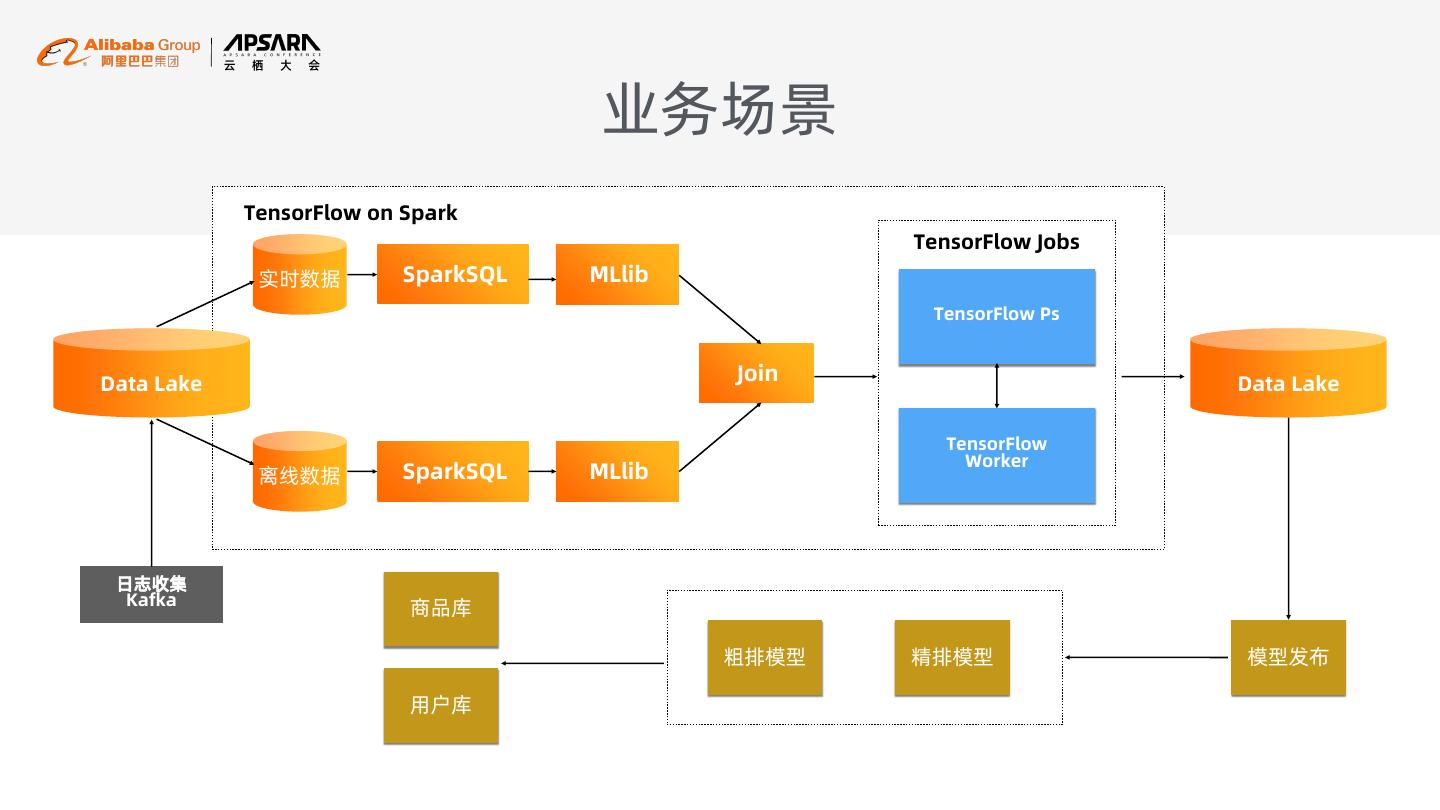
17 . 业务场景
TensorFlow on Spark
TensorFlow Jobs
实时数据 SparkSQL MLlib
TensorFlow Ps
Data Lake
Join Data Lake
TensorFlow
Worker
离线数据 SparkSQL MLlib
日志收集
Kafka
商品库
粗排模型 精排模型 模型发布
用户库
�
18 . API与提交方式
"""
this class should be implement by user
pre_train method: user implement this method to do Feature Engineer or Data Loading
shutdown method: user implement this method to do cleanup
train method: user implement this method to do tensorflow training
"""
class dl_base(object):
@staticmethod
def pre_train(env):
raise NotImplementedError('subclass must override pre_train()!')
@staticmethod
def shutdown():
pass
@staticmethod
def train(dataframe, env):
raise NotImplementedError('subclass must override train()!')
pl_submit -conf ~/submit.yaml -c ~/tf_fm_on_spark.py
�
19 . 推荐系统 FM 样例代码
特征工程 训练
https://github.com/aliyun/aliyun-emapreduce-demo/tree/master-2/src/main/python/deeplearning
�
20 . 总结
• EMR E-Learning 平台将大数据处理、深度学习、机器学习、数据湖、GPUs功能特性紧密的结合,提供一站式大数据与
机器学习平台
• TensorFlow on Spark 提供了高效的数据交互流程以及完备的机器学习训练流程,将Spark与TensorFlow结合,借助
PAI TensorFlow,助力用户加速训练
• E-Learning平台成功案例
CPU集群规模 GPU集群规模
1000+ 100+
�