

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark3上的Rapids加速器

沈国一-英伟达Spark上海团队开发经理
展开查看详情
1 .1
2 .使用RAPIDS加速 APACHE SPARK 3.0
3 .AGENDA 使用Rapids加速Apache Spark 3.0 工作原理 GPU加速时的SHUFFLE 性能测试 3
4 . 使用RAPIDS加速 APACHE SPARK 3.0 4
5 . 结合NVIDIA GPU的SPARK 3.0 无代码修改,加速数据处理 更快的执行时间 简化从分析到AI 降低基础架构费用 加速数据准备 端到端的流水线 用更少的硬件更快地完成工作 快速的进入下个处理阶段 从ETL到训练,再到呈现 节省在内部或云端的部署 专注于最重要的活动 对Spark和ML/DL框架的统一 以少做多 5
6 . 为什么要迁移到SPARK 3.0? 性能上的提升 Spark 2.x – CPU ONLY! ❏ 自适应查询执行(Adaptive Query Execution) Data Preparation Model Training ❏ 动态分区裁剪(Dynamic Partition Pruning) XGBoost | TensorFlow | Spark PyTorch 对GPU的支持 GPUs are key to both CPU Powered Cluster GPU Powered Cluster Spark Orchestrated Data ❑ GPU作为可调度资源用于加速处理 Sources GPUs lower TCO Shared Storage ❑ RDD[ColumnarBatch] vs RDD[InternalRow] ETL和DL的整合 Spark 3.x + GPUS ❏ 新的Spark平台特点 和一些开源库 (Horvod, XGBoost4J)更好 Data Preparation Model Training 的支持ML/DL框架 Spark XGBoost | TensorFlow | PyTorch GPU Powered Cluster Data Spark Orchestrated Sources
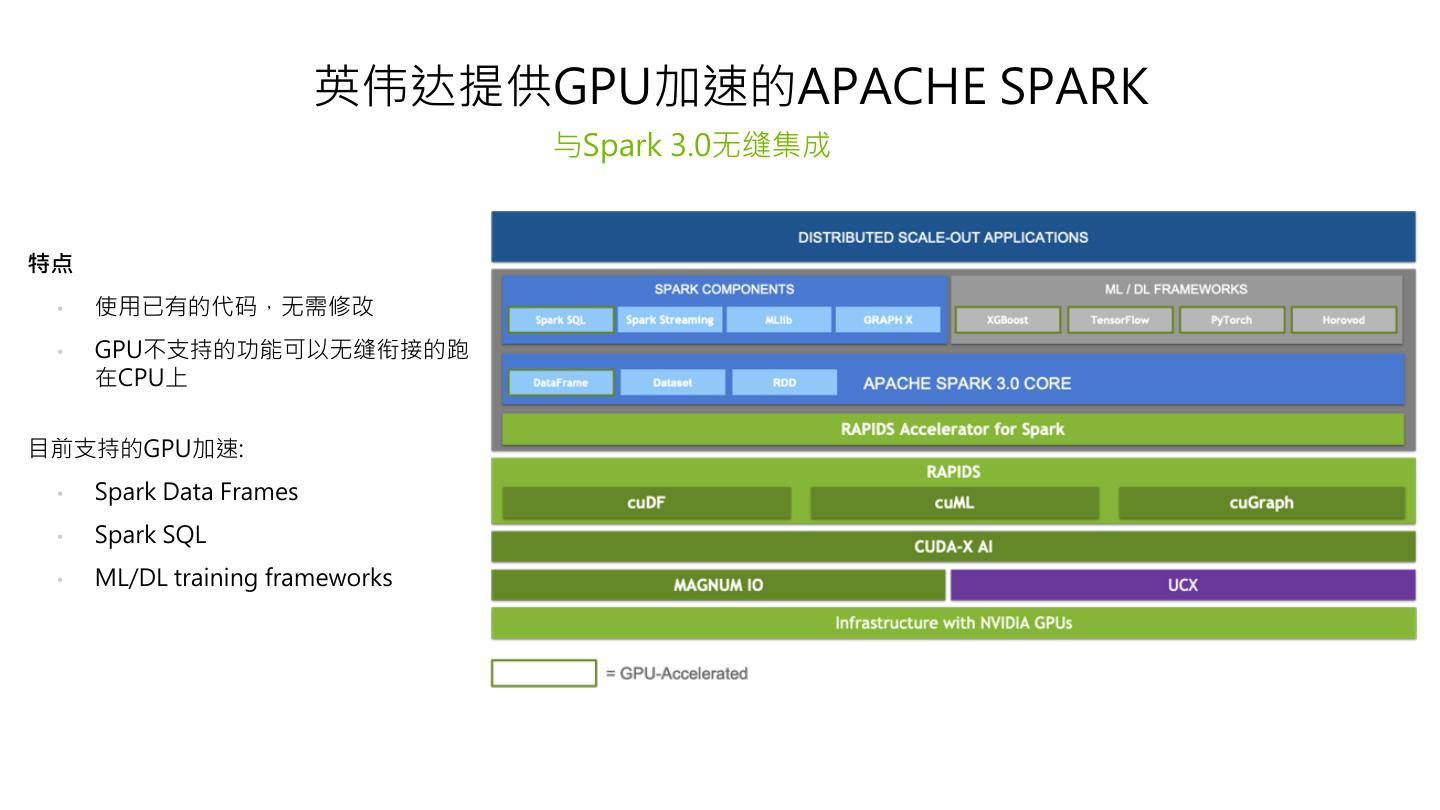
7 . 英伟达提供GPU加速的APACHE SPARK 与Spark 3.0无缝集成 特点 • 使用已有的代码,无需修改 • GPU不支持的功能可以无缝衔接的跑 在CPU上 目前支持的GPU加速: • Spark Data Frames • Spark SQL • ML/DL training frameworks 7
8 . RAPIDS ACCELERATOR ECOSYSTEM MOMENTUM Apache Spark 3.0 Databricks Google Cloud Cloudera CDP Azure Synapse Community Machine Dataproc Analytics Release Learning Runtime Available Available Available Available Available Now Now Now in July'21 Now 8
9 .工作原理 9
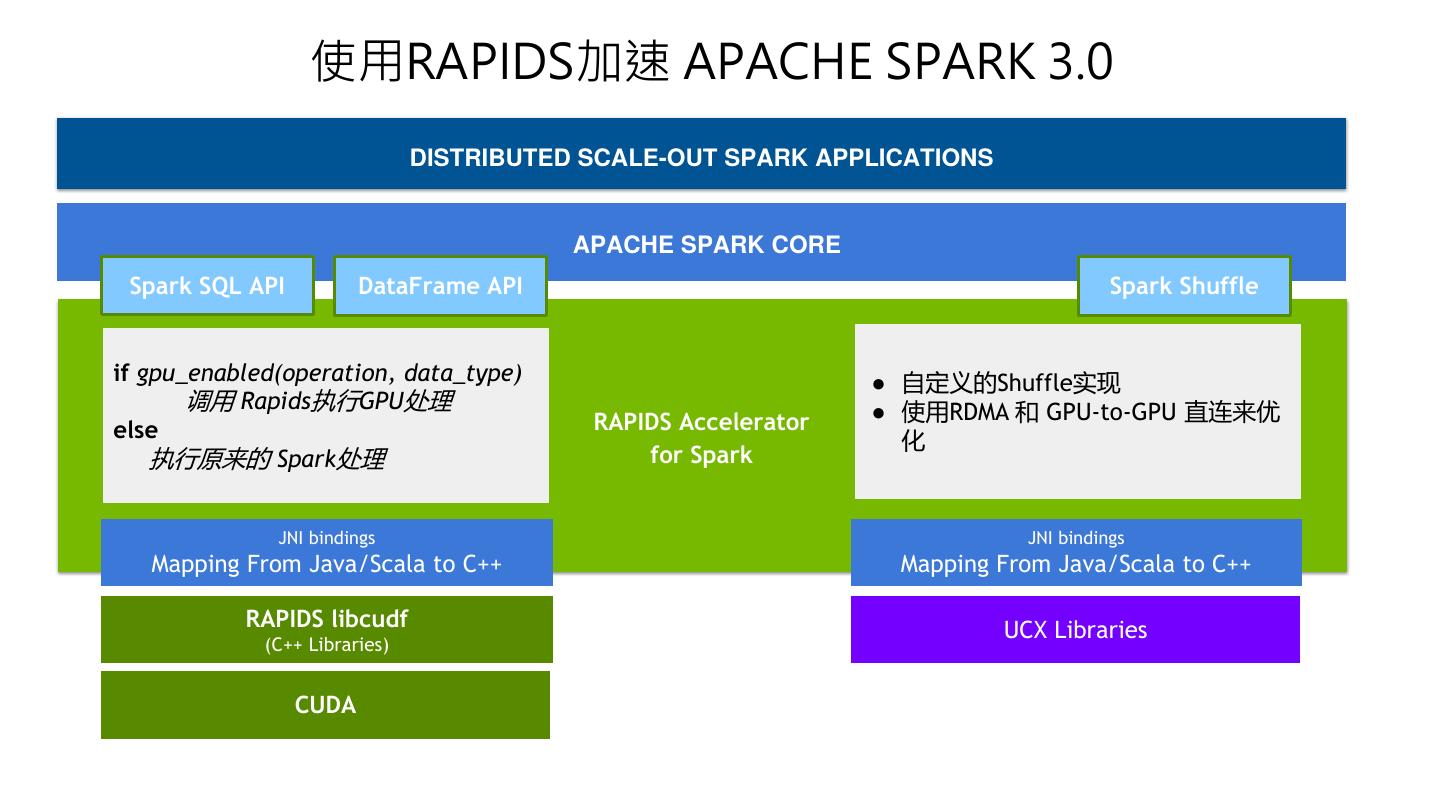
10 . 使用RAPIDS加速 APACHE SPARK 3.0 DISTRIBUTED SCALE-OUT SPARK APPLICATIONS APACHE SPARK CORE Spark SQL API DataFrame API Spark Shuffle if gpu_enabled(operation, data_type) ● 自定义的Shuffle实现 调用 Rapids执行GPU处理 ● 使用RDMA 和 GPU-to-GPU 直连来优 else RAPIDS Accelerator 化 执行原来的 Spark处理 for Spark JNI bindings JNI bindings Mapping From Java/Scala to C++ Mapping From Java/Scala to C++ RAPIDS libcudf UCX Libraries (C++ Libraries) CUDA
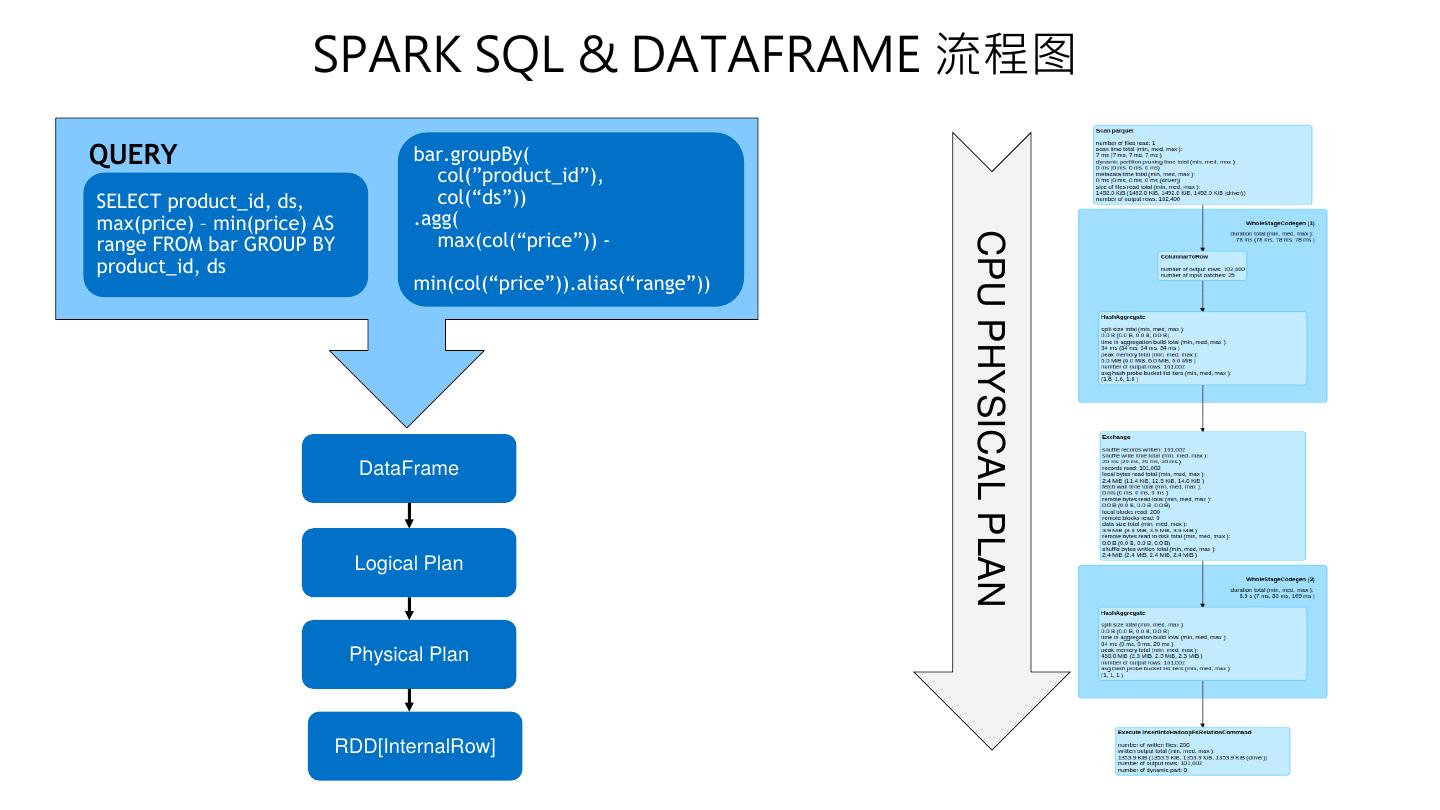
11 . SPARK SQL & DATAFRAME 流程图 QUERY bar.groupBy( col(”product_id”), SELECT product_id, ds, col(“ds”)) max(price) – min(price) AS .agg( max(col(“price”)) - CPU PHYSICAL PLAN range FROM bar GROUP BY product_id, ds min(col(“price”)).alias(“range”)) DataFrame Logical Plan Physical Plan RDD[InternalRow]
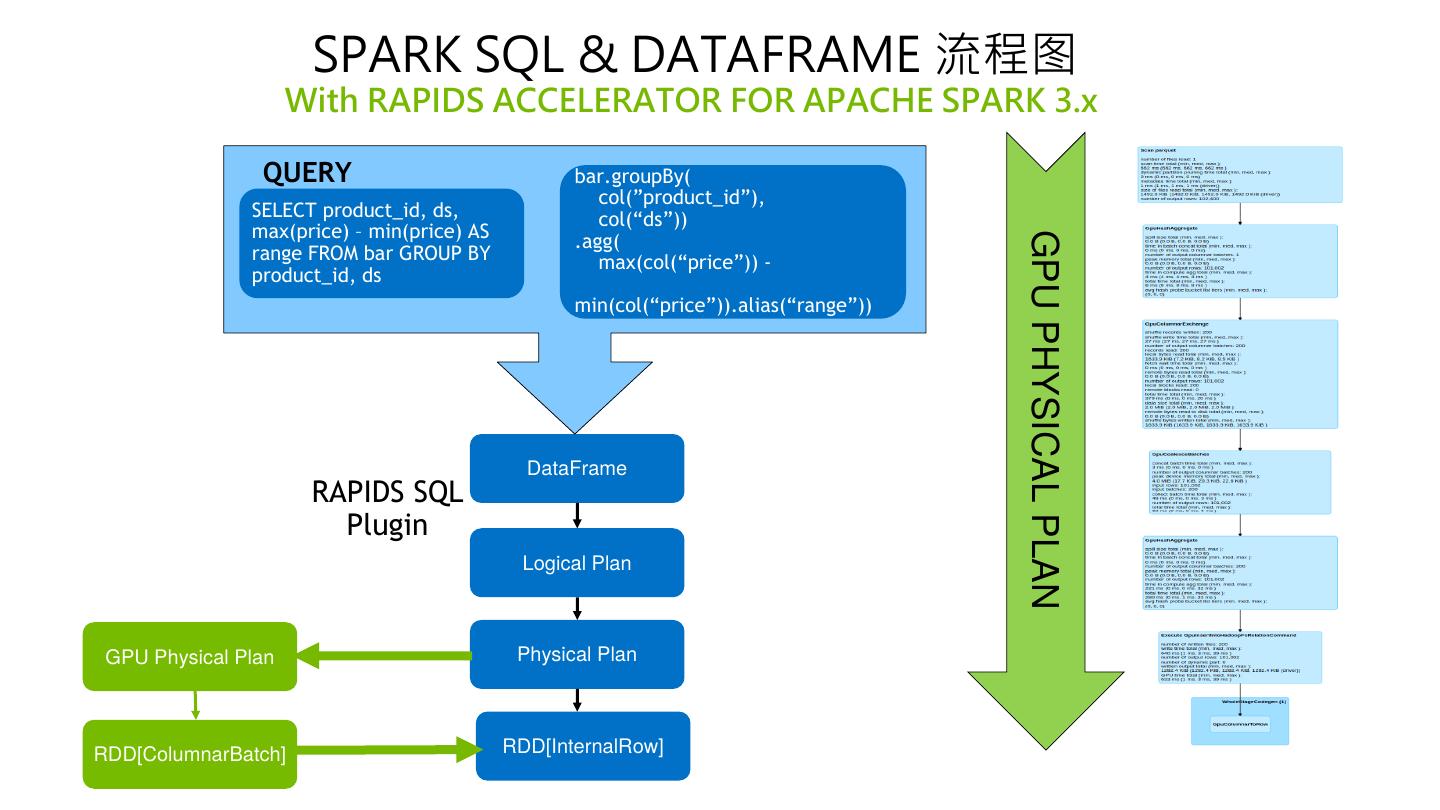
12 . SPARK SQL & DATAFRAME 流程图 With RAPIDS ACCELERATOR FOR APACHE SPARK 3.x QUERY bar.groupBy( col(”product_id”), SELECT product_id, ds, col(“ds”)) max(price) – min(price) AS .agg( GPU PHYSICAL PLAN range FROM bar GROUP BY max(col(“price”)) - product_id, ds min(col(“price”)).alias(“range”)) DataFrame RAPIDS SQL Plugin Logical Plan GPU Physical Plan Physical Plan RDD[ColumnarBatch] RDD[InternalRow]
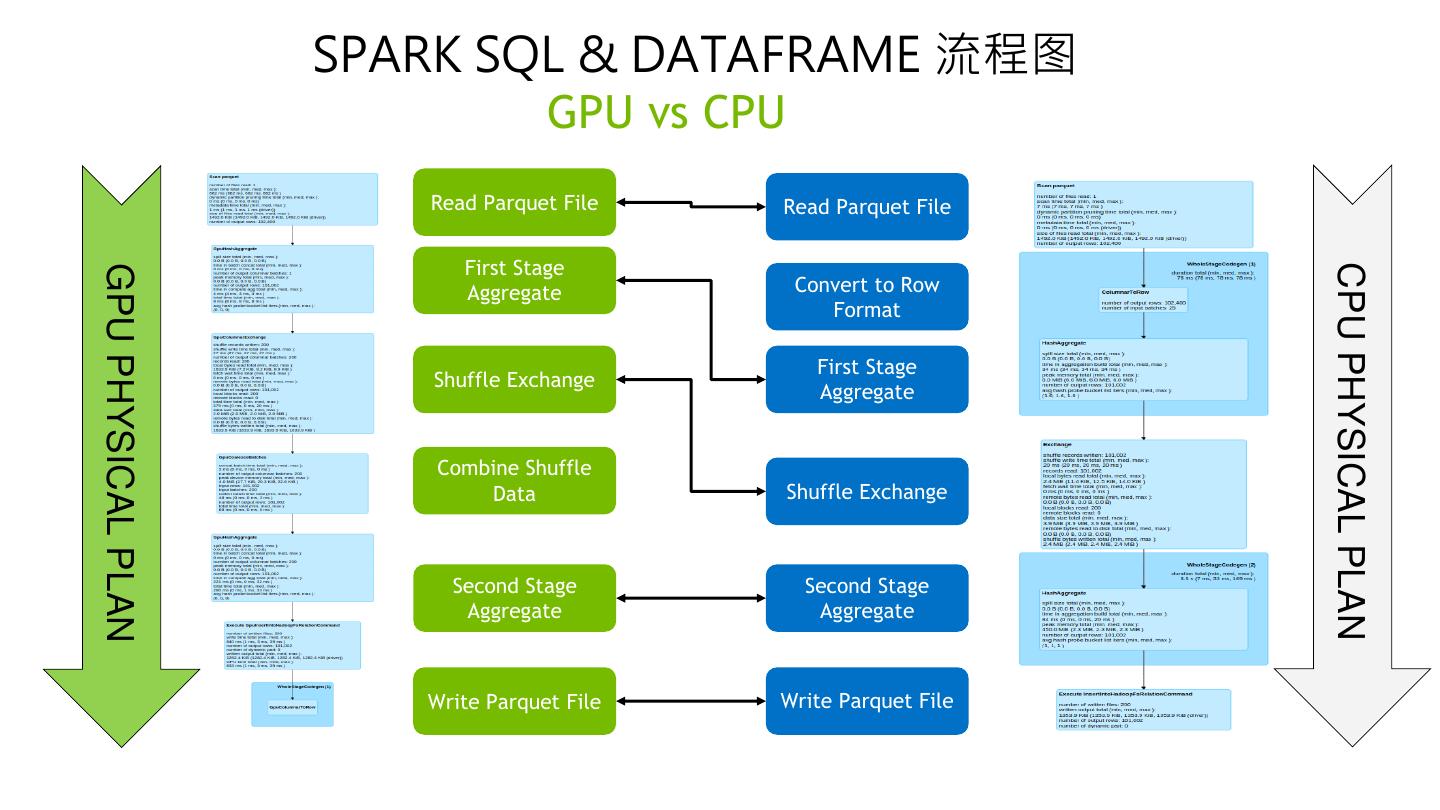
13 . SPARK SQL & DATAFRAME 流程图 GPU vs CPU Read Parquet File Read Parquet File First Stage CPU PHYSICAL PLAN GPU PHYSICAL PLAN Aggregate Convert to Row Format First Stage Shuffle Exchange Aggregate Combine Shuffle Data Shuffle Exchange Second Stage Second Stage Aggregate Aggregate Write Parquet File Write Parquet File
14 . 适合GPU的场合 高散列度 数据的joins 高散列度数据的aggregates 高散列度数据的sort Window operations (特别是大型 windows) 复杂计算 数据编码 (创建 Parquet 和 ORC 文件,读取 CSV) 14
15 .GPU加速时的SHUFFLE 15
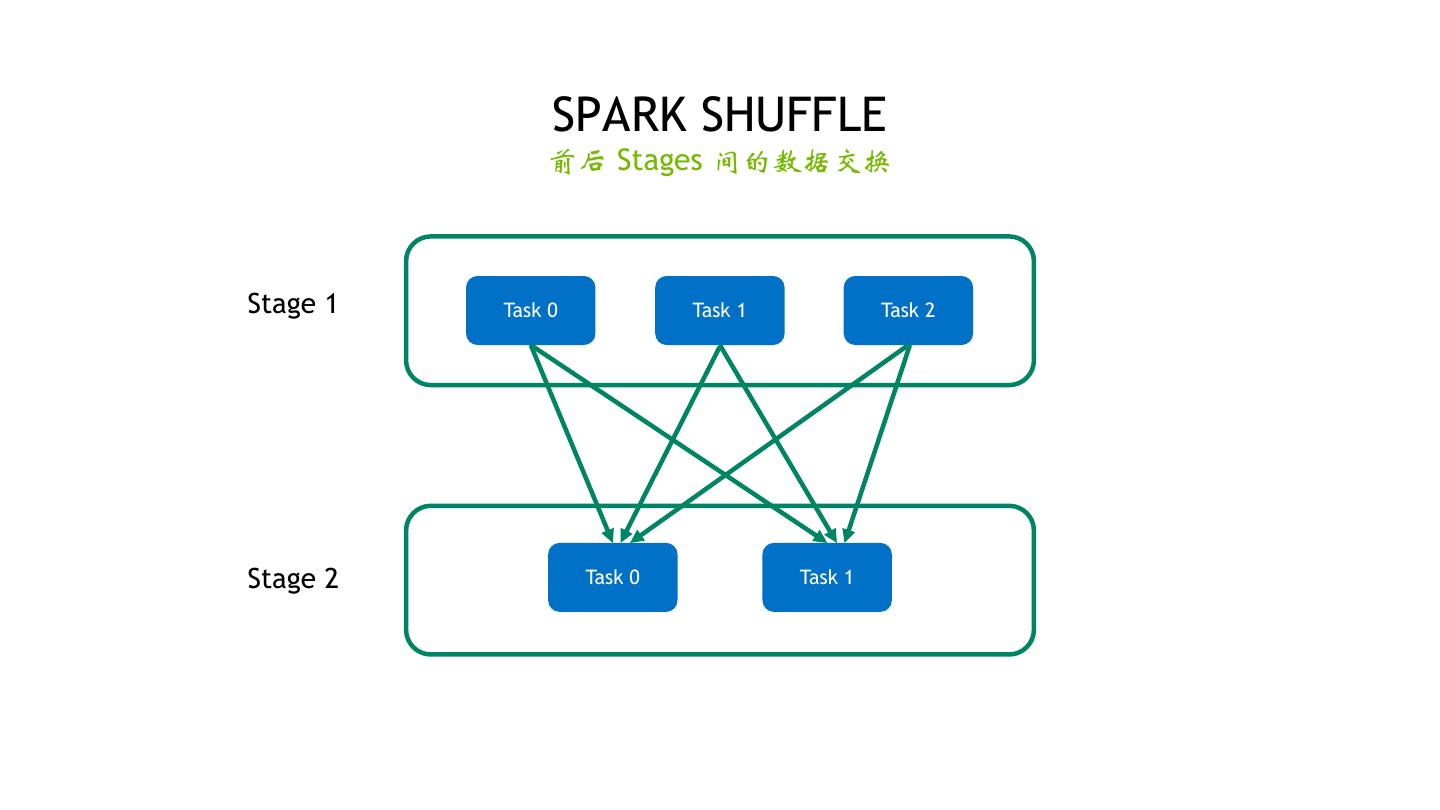
16 . SPARK SHUFFLE 前后 Stages 间的数据交换 Stage 1 Task 0 Task 1 Task 2 Stage 2 Task 0 Task 1 16
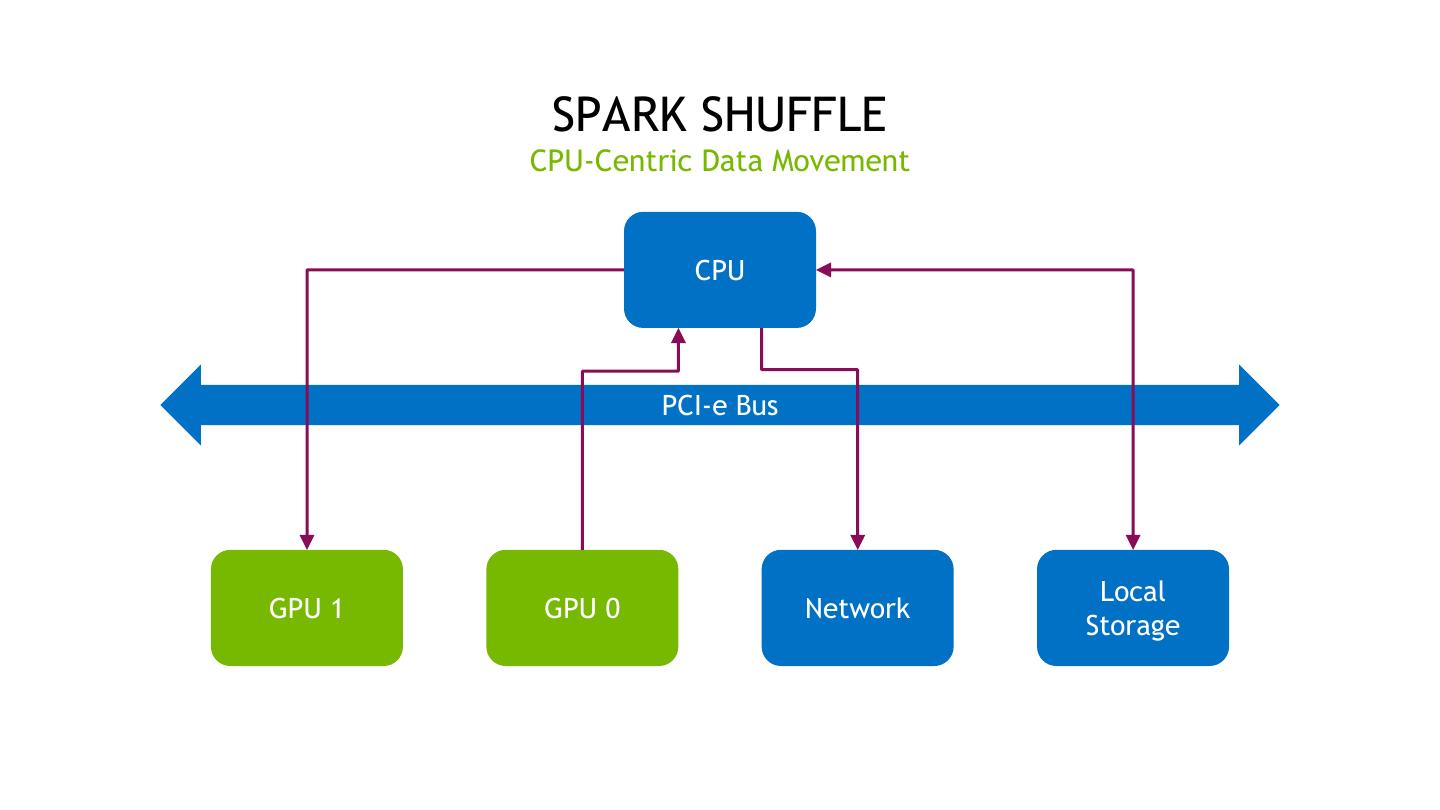
17 . SPARK SHUFFLE CPU-Centric Data Movement CPU PCI-e Bus Local GPU 1 GPU 0 Network Storage 17
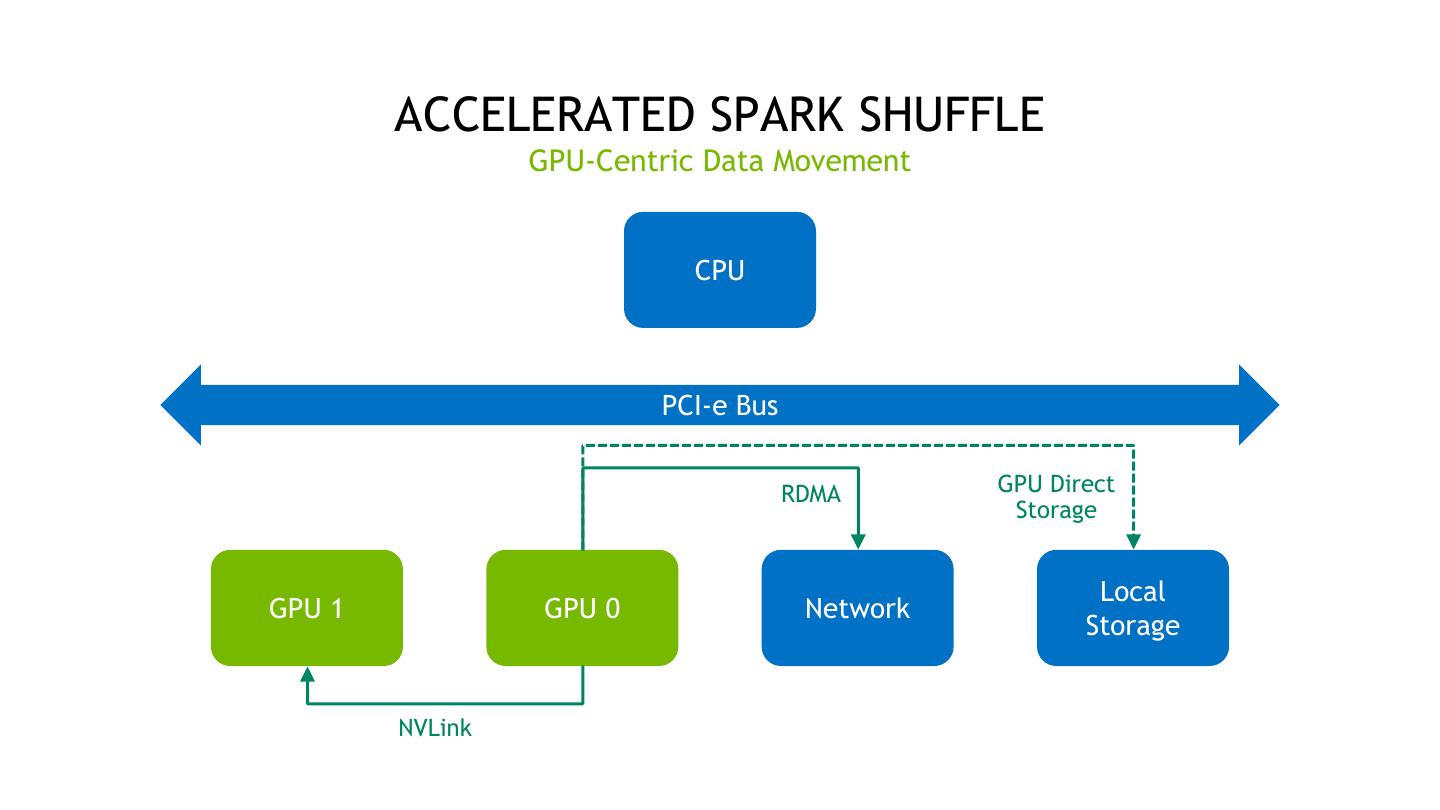
18 . ACCELERATED SPARK SHUFFLE GPU-Centric Data Movement CPU PCI-e Bus RDMA GPU Direct Storage Local GPU 1 GPU 0 Network Storage NVLink 18
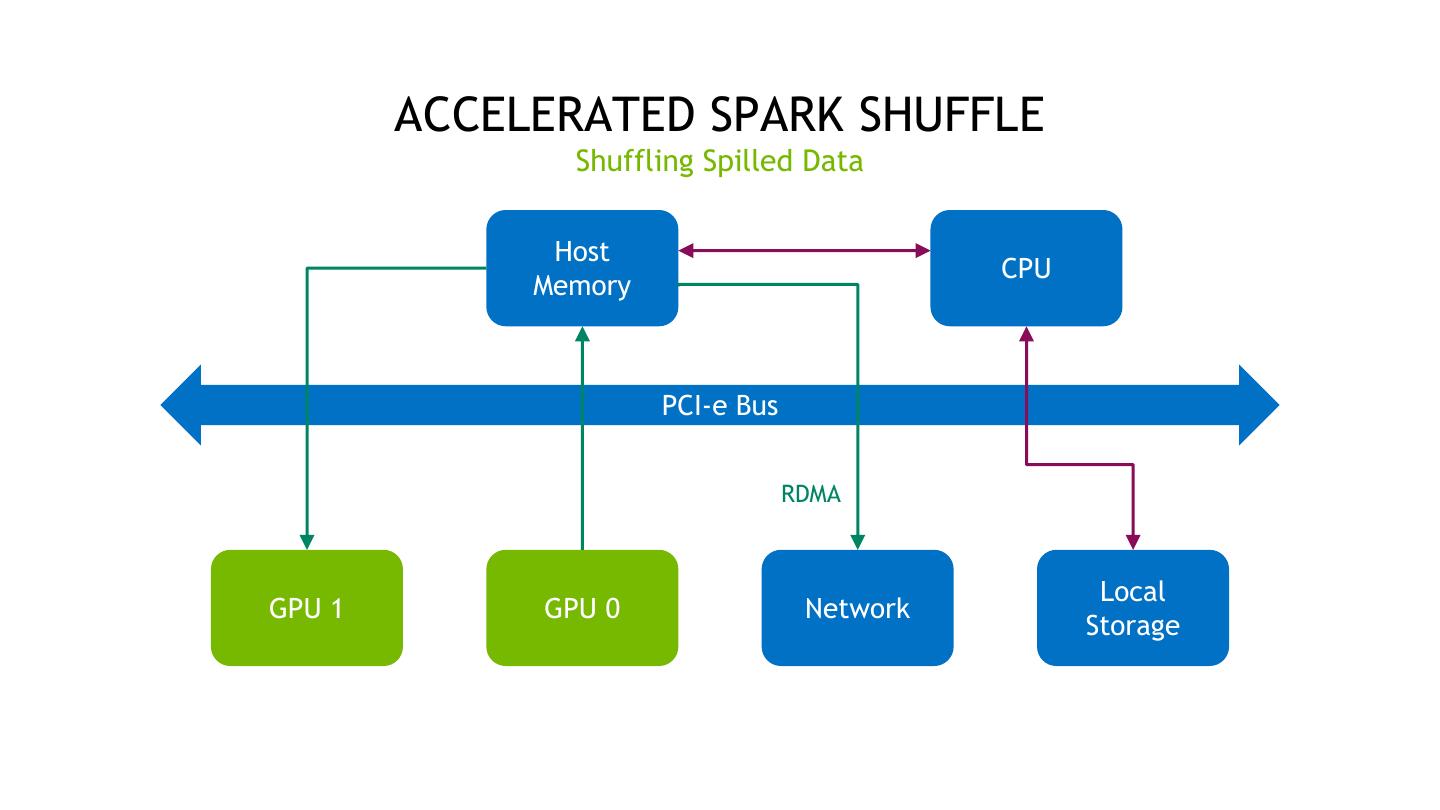
19 . ACCELERATED SPARK SHUFFLE Shuffling Spilled Data Host CPU Memory PCI-e Bus RDMA Local GPU 1 GPU 0 Network Storage 19
20 .加速SHUFFLE后的对比 Inventory Pricing Query* 250 228 Query Duration In Seconds 200 150 100 50 45 8.4 0 CPU GPU GPU+UCX *This is part of NVIDIA Decision Support (NDS) benchmark that is derived from the TPC-DS benchmark and is used for internal performance testing. Results from NDS are not comparable to TPC-DS
21 .性能测试 21
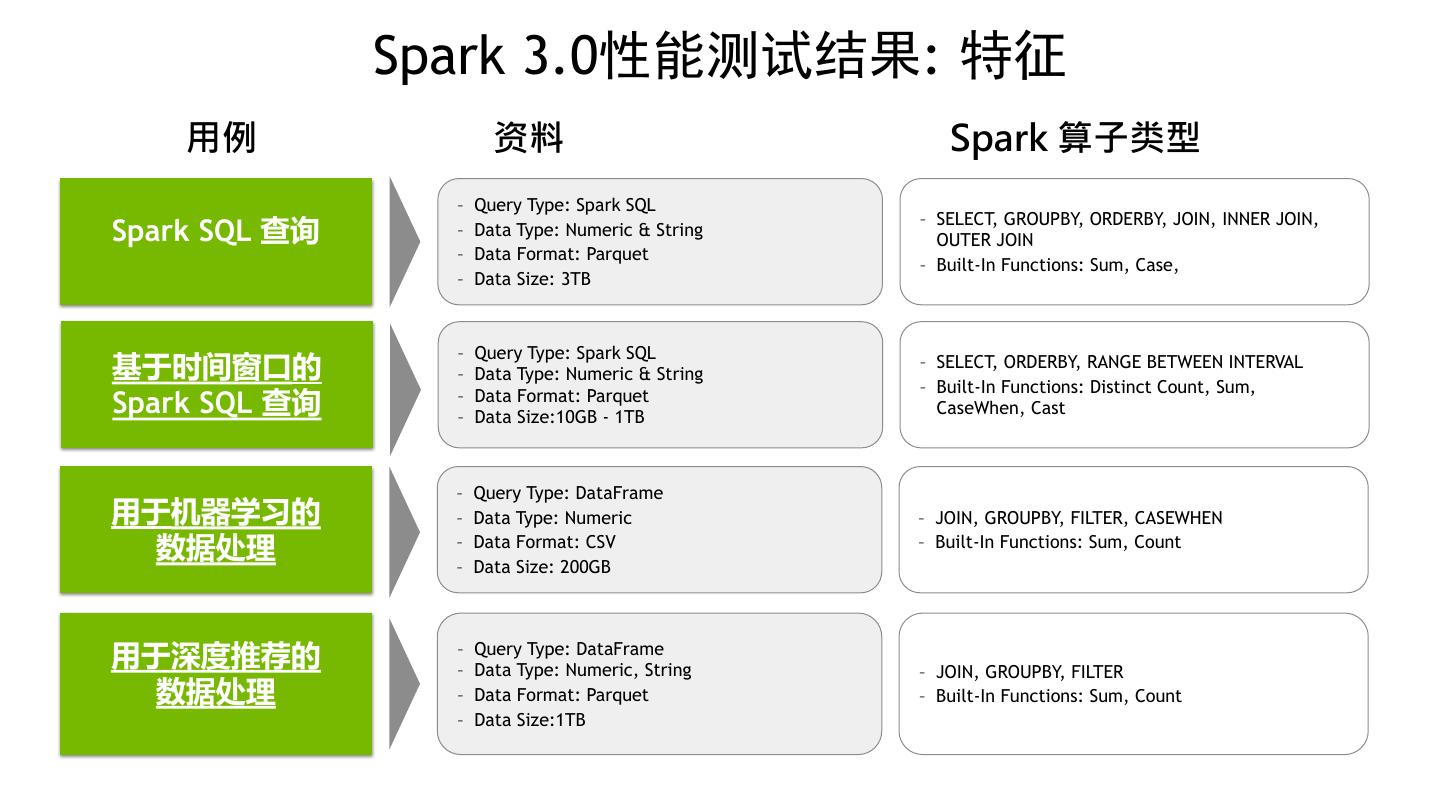
22 . Spark 3.0性能测试结果: 特征 用例 资料 Spark 算子类型 – Query Type: Spark SQL – SELECT, GROUPBY, ORDERBY, JOIN, INNER JOIN, Spark SQL 查询 – Data Type: Numeric & String OUTER JOIN – Data Format: Parquet – Built-In Functions: Sum, Case, – Data Size: 3TB – Query Type: Spark SQL 基于时间窗口的 – Data Type: Numeric & String – SELECT, ORDERBY, RANGE BETWEEN INTERVAL – Built-In Functions: Distinct Count, Sum, Spark SQL 查询 – – Data Format: Parquet Data Size:10GB - 1TB CaseWhen, Cast – Query Type: DataFrame 用于机器学习的 – Data Type: Numeric – JOIN, GROUPBY, FILTER, CASEWHEN 数据处理 – – Data Format: CSV Data Size: 200GB – Built-In Functions: Sum, Count 用于深度推荐的 – – Query Type: DataFrame Data Type: Numeric, String – JOIN, GROUPBY, FILTER 数据处理 – Data Format: Parquet – Built-In Functions: Sum, Count – Data Size:1TB
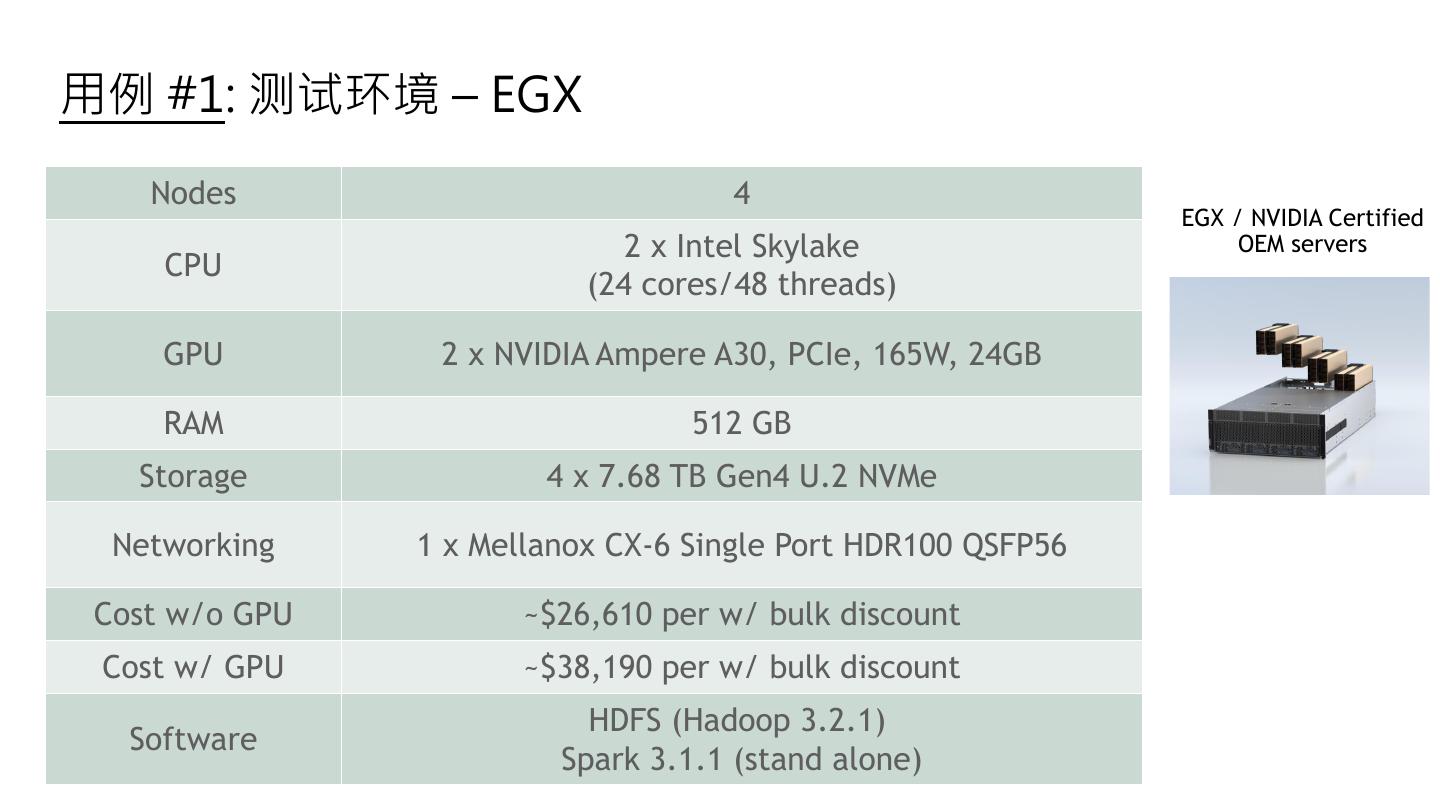
23 .用例 #1: 测试环境 – EGX Nodes 4 EGX / NVIDIA Certified 2 x Intel Skylake OEM servers CPU (24 cores/48 threads) GPU 2 x NVIDIA Ampere A30, PCIe, 165W, 24GB RAM 512 GB Storage 4 x 7.68 TB Gen4 U.2 NVMe Networking 1 x Mellanox CX-6 Single Port HDR100 QSFP56 Cost w/o GPU ~$26,610 per w/ bulk discount Cost w/ GPU ~$38,190 per w/ bulk discount HDFS (Hadoop 3.2.1) Software Spark 3.1.1 (stand alone) 24
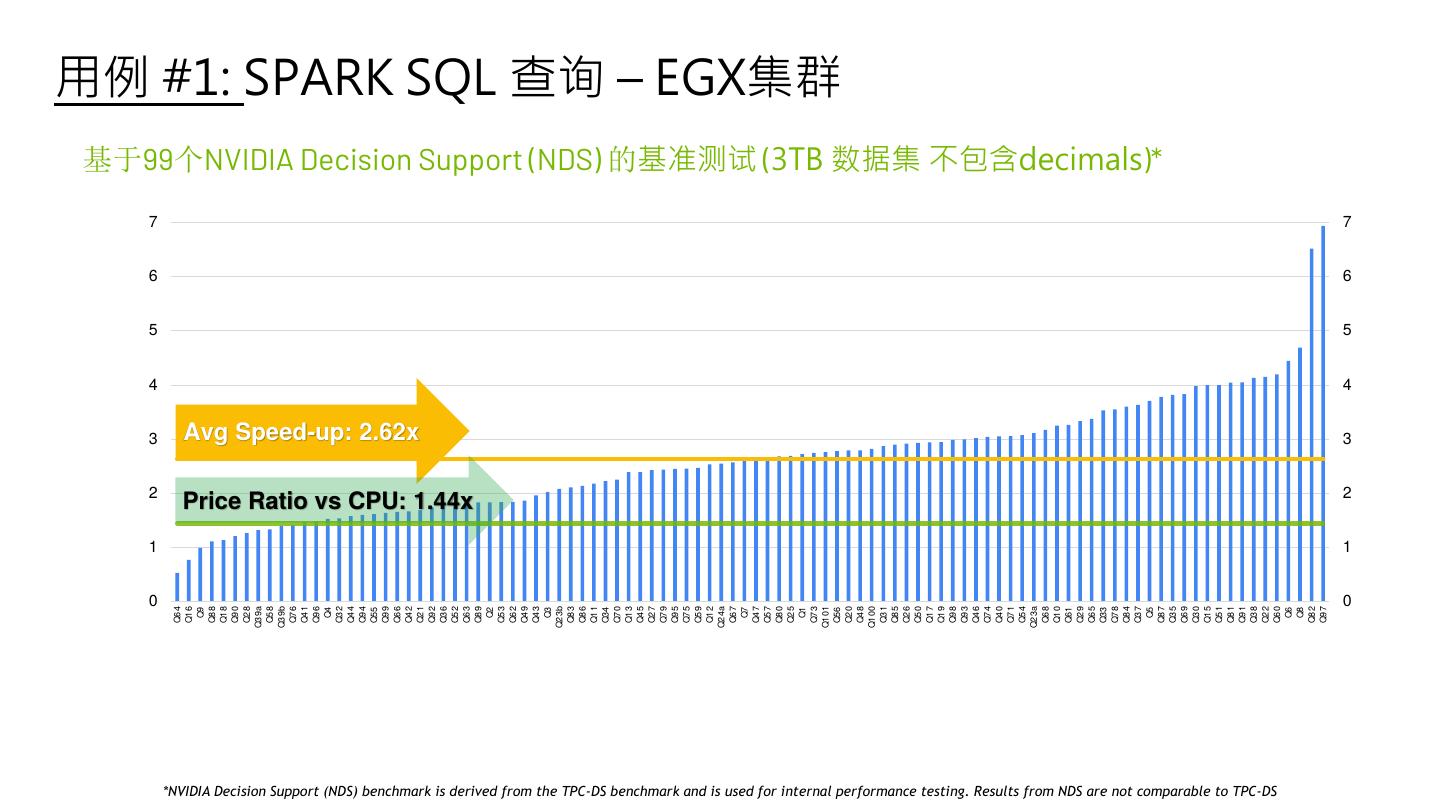
24 .用例 #1: SPARK SQL 查询 – EGX集群 基于99个NVIDIA Decision Support (NDS) 的基准测试 (3TB 数据集 不包含decimals)* 7 7 6 6 5 5 4 4 3 Avg Speed-up: 2.62x 3 2 2 Price Ratio vs CPU: 1.44x 1 1 0 0 Q39a Q39b Q23b Q24a Q101 Q100 Q23a Q64 Q16 Q9 Q88 Q18 Q90 Q28 Q58 Q76 Q41 Q96 Q4 Q32 Q44 Q94 Q55 Q99 Q66 Q42 Q21 Q92 Q36 Q52 Q63 Q89 Q2 Q53 Q62 Q49 Q43 Q3 Q83 Q86 Q11 Q34 Q70 Q13 Q45 Q27 Q79 Q95 Q75 Q59 Q12 Q67 Q7 Q47 Q57 Q80 Q25 Q1 Q73 Q56 Q20 Q48 Q31 Q85 Q26 Q50 Q17 Q19 Q98 Q93 Q46 Q74 Q40 Q71 Q54 Q68 Q10 Q61 Q29 Q65 Q33 Q78 Q84 Q37 Q5 Q87 Q35 Q69 Q30 Q15 Q51 Q81 Q91 Q38 Q22 Q60 Q8 Q6 Q82 Q97 *NVIDIA Decision Support (NDS) benchmark is derived from the TPC-DS benchmark and is used for internal performance testing. Results from NDS are not comparable to TPC-DS
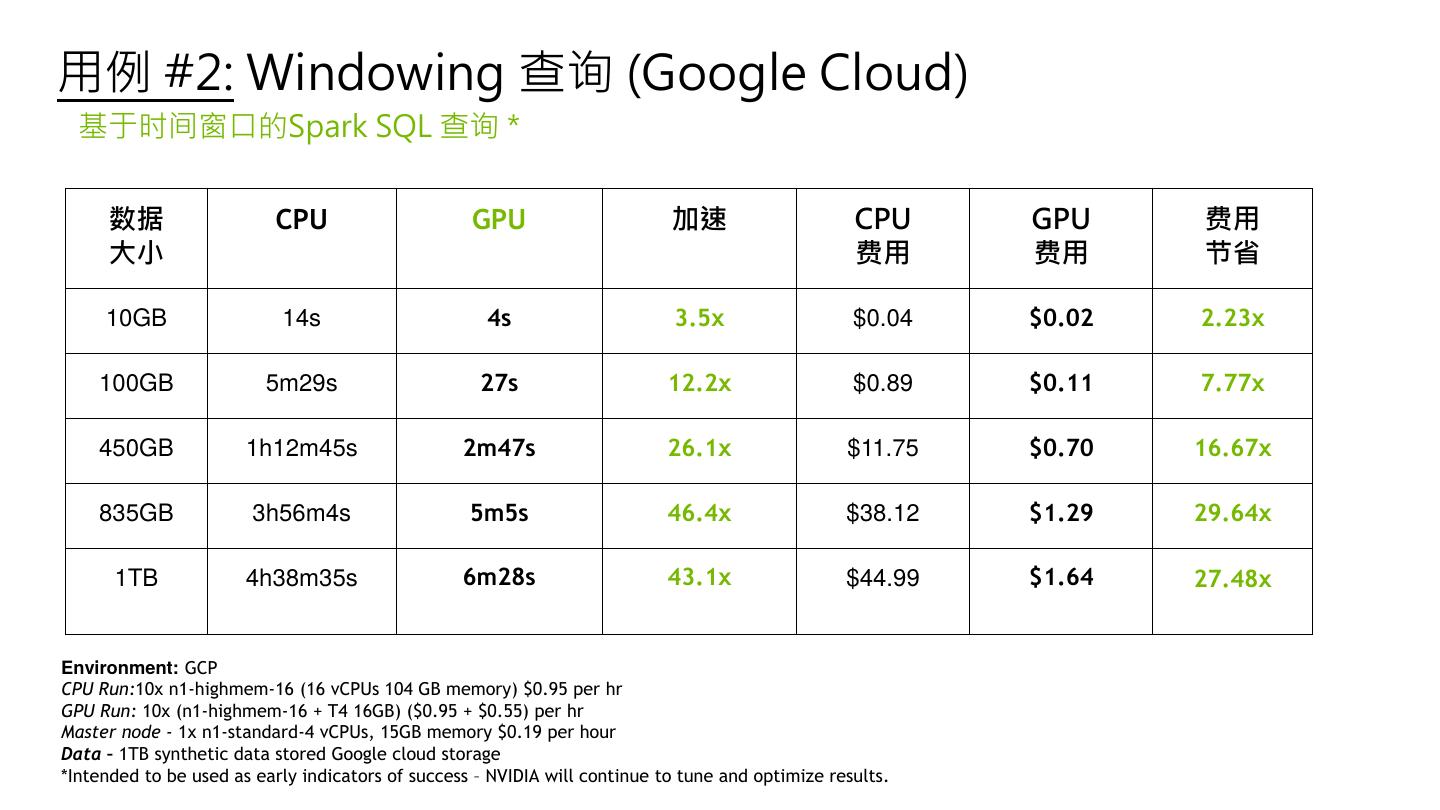
25 . 用例 #2: Windowing 查询 (Google Cloud) 基于时间窗口的Spark SQL 查询 * 数据 CPU GPU 加速 CPU GPU 费用 大小 费用 费用 节省 10GB 14s 4s 3.5x $0.04 $0.02 2.23x 100GB 5m29s 27s 12.2x $0.89 $0.11 7.77x 450GB 1h12m45s 2m47s 26.1x $11.75 $0.70 16.67x 835GB 3h56m4s 5m5s 46.4x $38.12 $1.29 29.64x 1TB 4h38m35s 6m28s 43.1x $44.99 $1.64 27.48x Environment: GCP CPU Run:10x n1-highmem-16 (16 vCPUs 104 GB memory) $0.95 per hr GPU Run: 10x (n1-highmem-16 + T4 16GB) ($0.95 + $0.55) per hr Master node - 1x n1-standard-4 vCPUs, 15GB memory $0.19 per hour Data – 1TB synthetic data stored Google cloud storage *Intended NVIDIA toDO CONFIDENTIAL. beNOT used as early indicators of success – NVIDIA will continue to tune and optimize results. DISTRIBUTE.
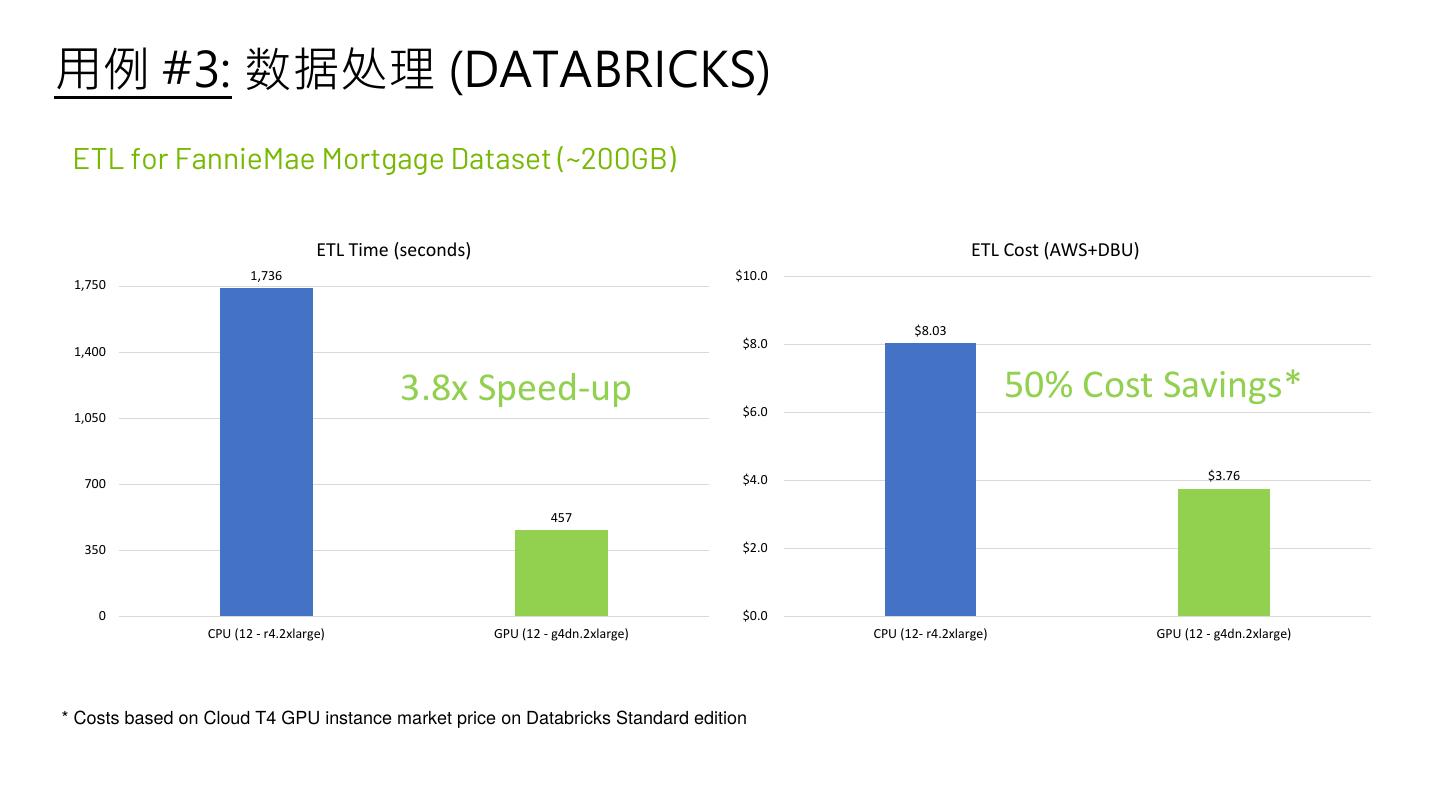
26 .用例 #3: 数据处理 (DATABRICKS) ETL for FannieMae Mortgage Dataset (~200GB) ETL Time (seconds) ETL Cost (AWS+DBU) 1,736 $10.0 1,750 $8.03 $8.0 1,400 3.8x Speed-up $6.0 50% Cost Savings* 1,050 $4.0 $3.76 700 457 350 $2.0 0 $0.0 CPU (12 - r4.2xlarge) GPU (12 - g4dn.2xlarge) CPU (12- r4.2xlarge) GPU (12 - g4dn.2xlarge) * Costs based on Cloud T4 GPU instance market price on Databricks Standard edition
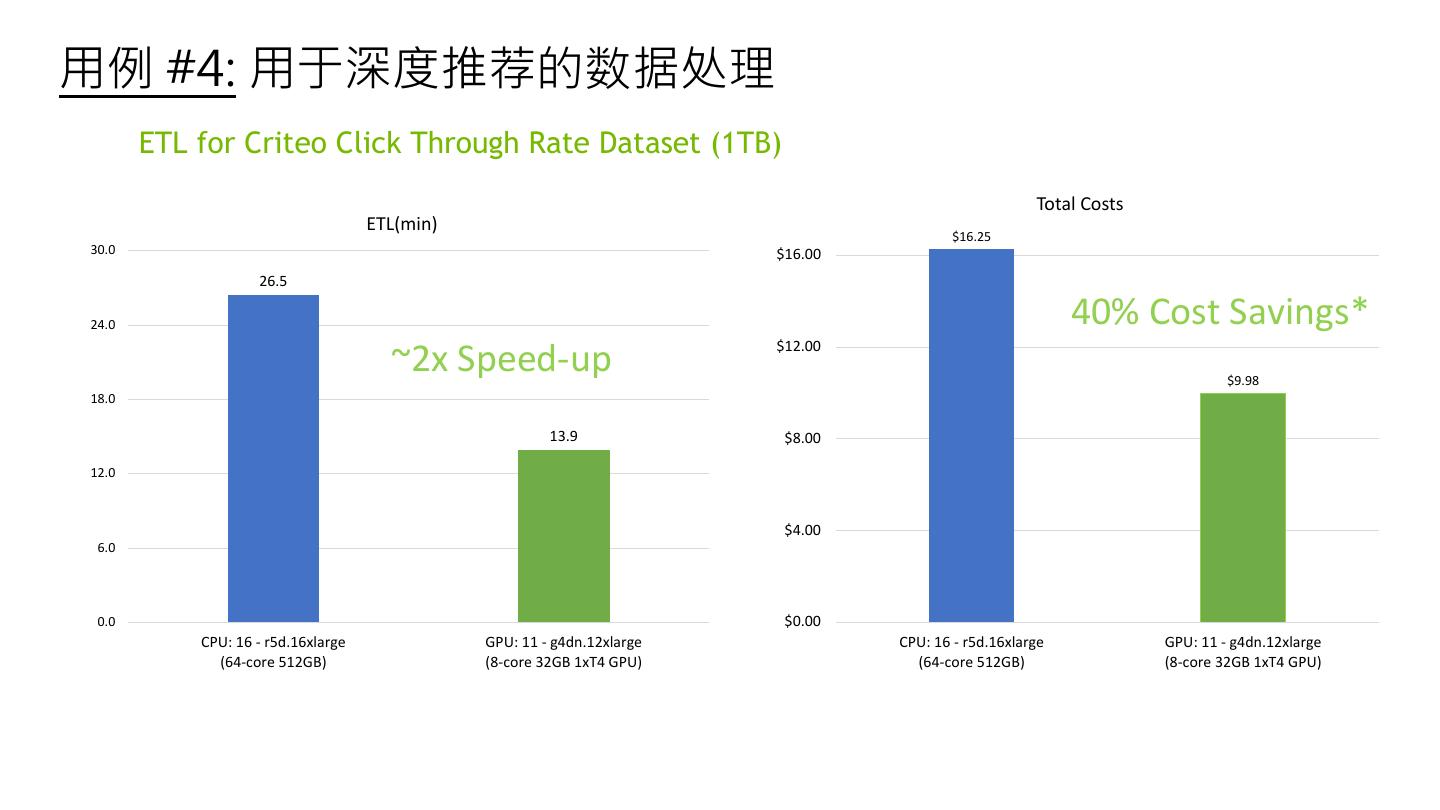
27 .用例 #4: 用于深度推荐的数据处理 ETL for Criteo Click Through Rate Dataset (1TB) Total Costs ETL(min) $16.25 30.0 $16.00 26.5 24.0 40% Cost Savings* $12.00 ~2x Speed-up $9.98 18.0 13.9 $8.00 12.0 $4.00 6.0 0.0 $0.00 CPU: 16 - r5d.16xlarge GPU: 11 - g4dn.12xlarge CPU: 16 - r5d.16xlarge GPU: 11 - g4dn.12xlarge (64-core 512GB) (8-core 32GB 1xT4 GPU) (64-core 512GB) (8-core 32GB 1xT4 GPU)
28 . 了解更多信息 Github仓库:https://github.com/NVIDIA/spark-rapids 文档主页:https://nvidia.github.io/spark-rapids/ 预览 Spark 3.0 GPU Features 电子书: 29
29 .欢迎加入 30
3秒后跳转登录页面
去登陆

