


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Doris源码阅读与解析第8讲《查询优化器讲解》
《 Apache Doris 源码阅读与解析》系列直播活动旨在帮助 Apache Doris 社区的开发者或者有意向参与 Apache Doris 社区建设的小伙伴们,可以更快熟悉 Apache Doris 代码的组织结构和一些主要流程的实现原理以及代码位置,以便于各位小伙伴们能够快速上手,参与到开发工作中来。
《第八讲 —— 查询优化器详解》,这一讲我们将从查询优化器的基本概念出发,为大家介绍查询优化器的设计与实现:
- 查询优化器的设计原理
- Doris 目前的实现逻辑
- 小功能:如何添加一个 Rewrite 规则
展开查看详情
1 .Apache Doris 源码阅读与解析 第八讲:查询优化器详解 缪翎
2 .自我介绍 缪翎 • Apache Doris PPMC • 百度资深研发工程师 • github id :EmmyMiao87 • 个人博客:https://emmymiao87.github.io/
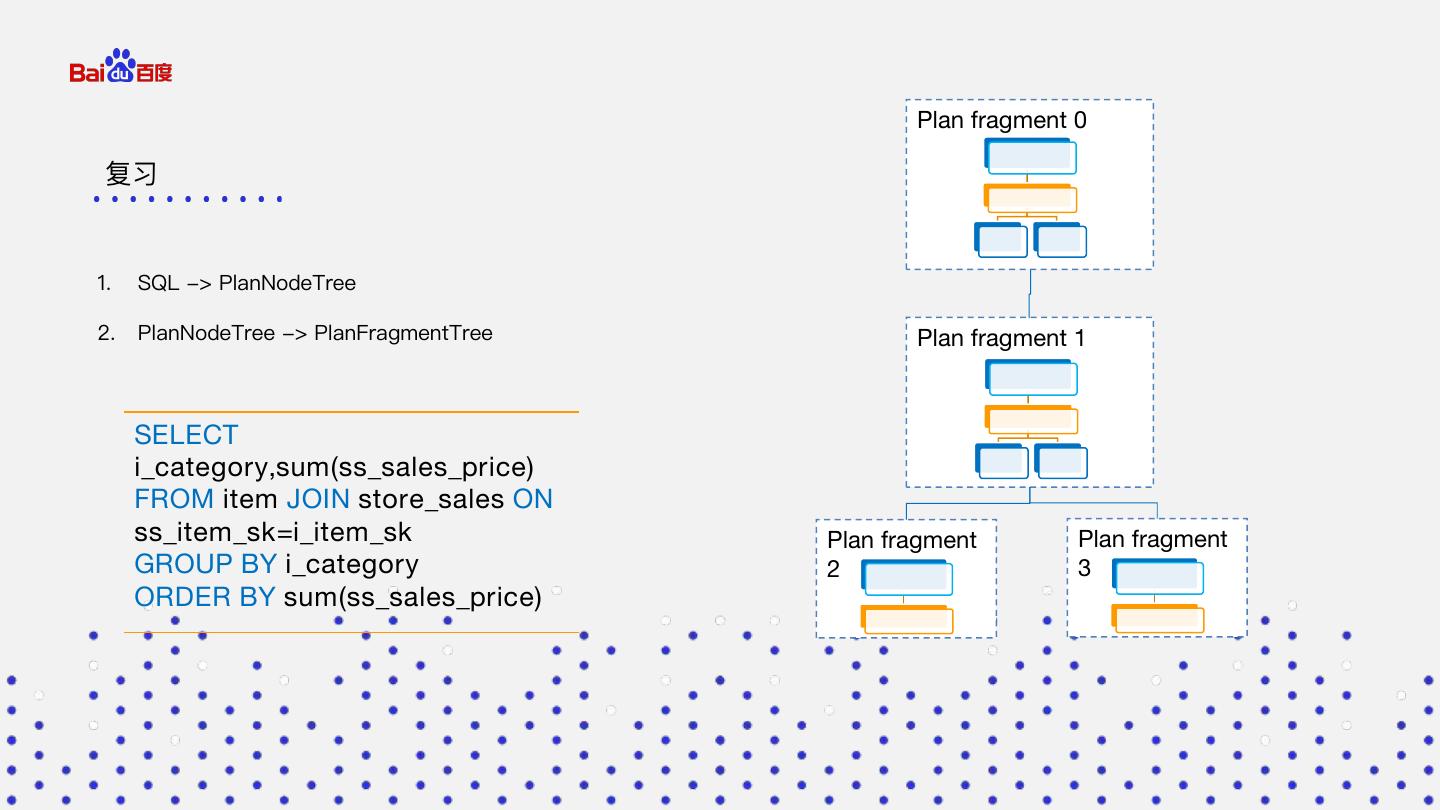
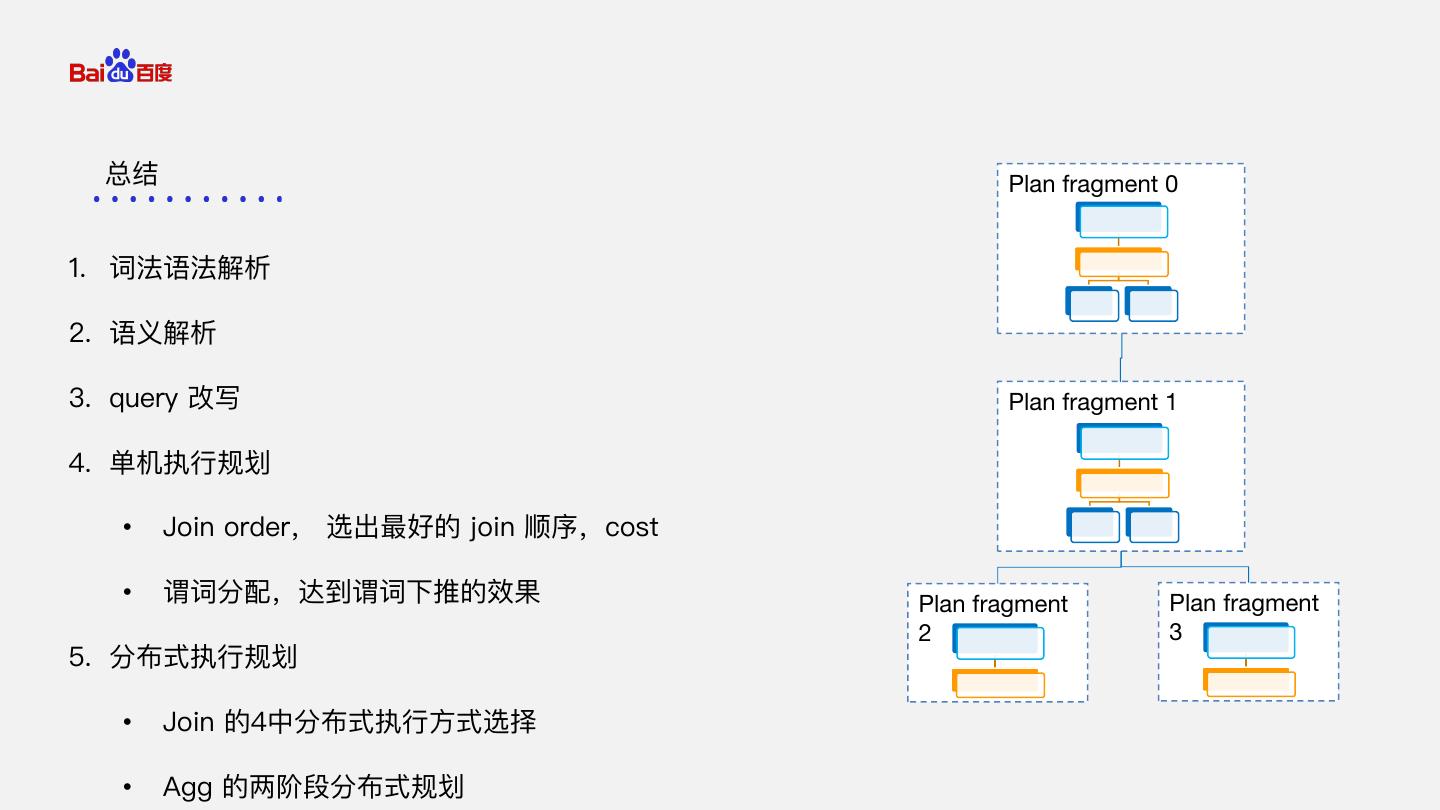
3 . Plan fragment 0 复习 1. SQL -> PlanNodeTree 2. PlanNodeTree -> PlanFragmentTree Plan fragment 1 SELECT i_category,sum(ss_sales_price) FROM item JOIN store_sales ON ss_item_sk=i_item_sk Plan fragment Plan fragment GROUP BY i_category 2 3 ORDER BY sum(ss_sales_price)
4 . Plan fragment 0 什么是查询优化器 Find Best Plan Plan fragment 1 SELECT i_category,sum(ss_sales_price) FROM item JOIN store_sales ON 优化器 ss_item_sk=i_item_sk GROUP BY i_category ORDER BY sum(ss_sales_price) Plan fragment Plan fragment 2 3
5 . 什么是查询优化器 SELECT Sum(l_extendedprice * ( 1 - SELECT Sum(l_extendedprice* (1 - l_discount )) AS revenue l_discount)) AS revenue FROM lineitem, FROM lineitem, part part WHERE ( p_partkey = l_partkey AND p_brand = 'Brand#11' ) WHERE p_partkey = l_partkey OR ( p_partkey = l_partkey AND p_brand in('Brand#11' , AND p_brand = 'Brand#21' ) 'Brand#21', 'Brand#32'); OR ( p_partkey = l_partkey AND p_brand = 'Brand#32' ); 执行时间:13 s 0.94 s
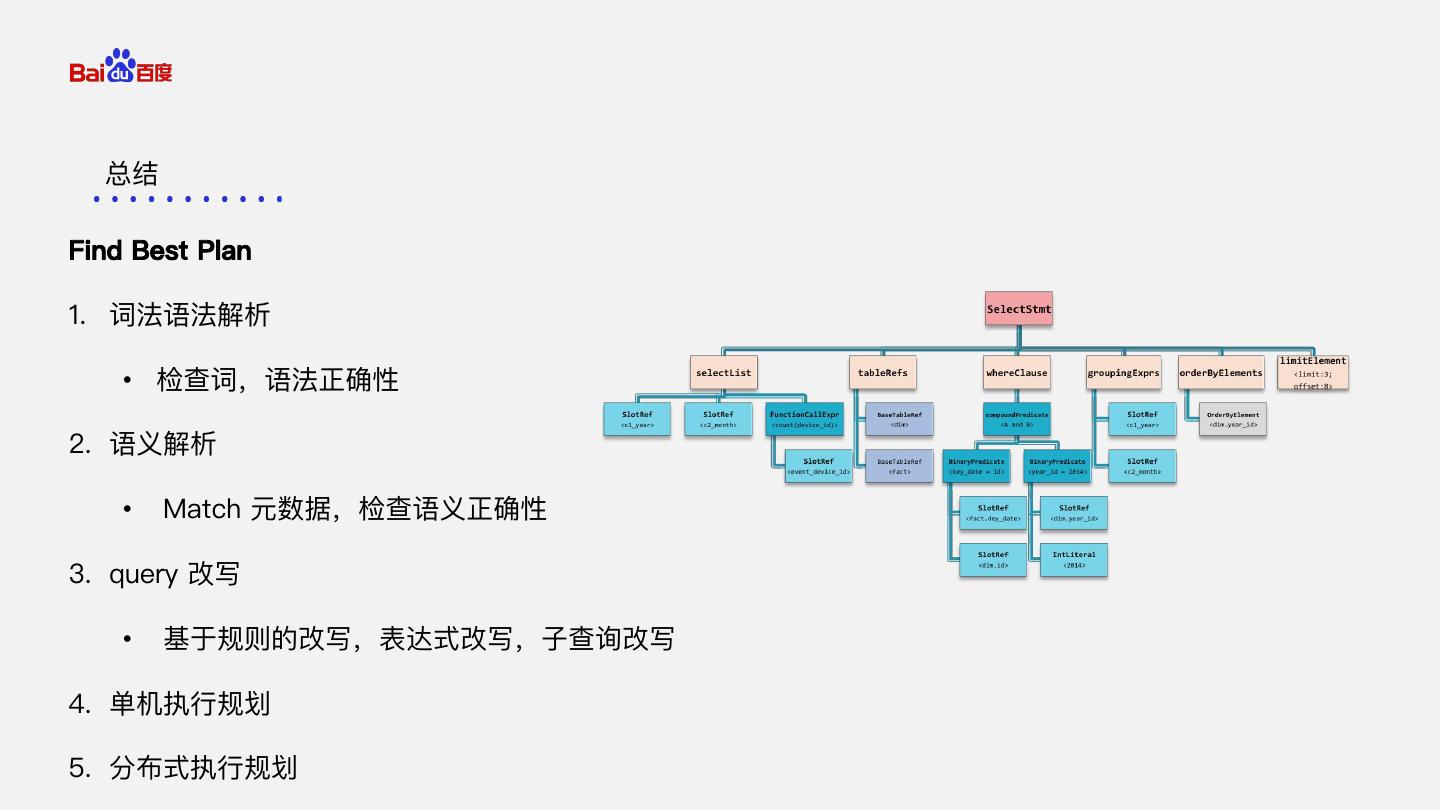
6 . 课程大纲 1. 词法语法解析 2. 语义解析 3. query 改写 4. 单机执行规划 5. 分布式执行规划
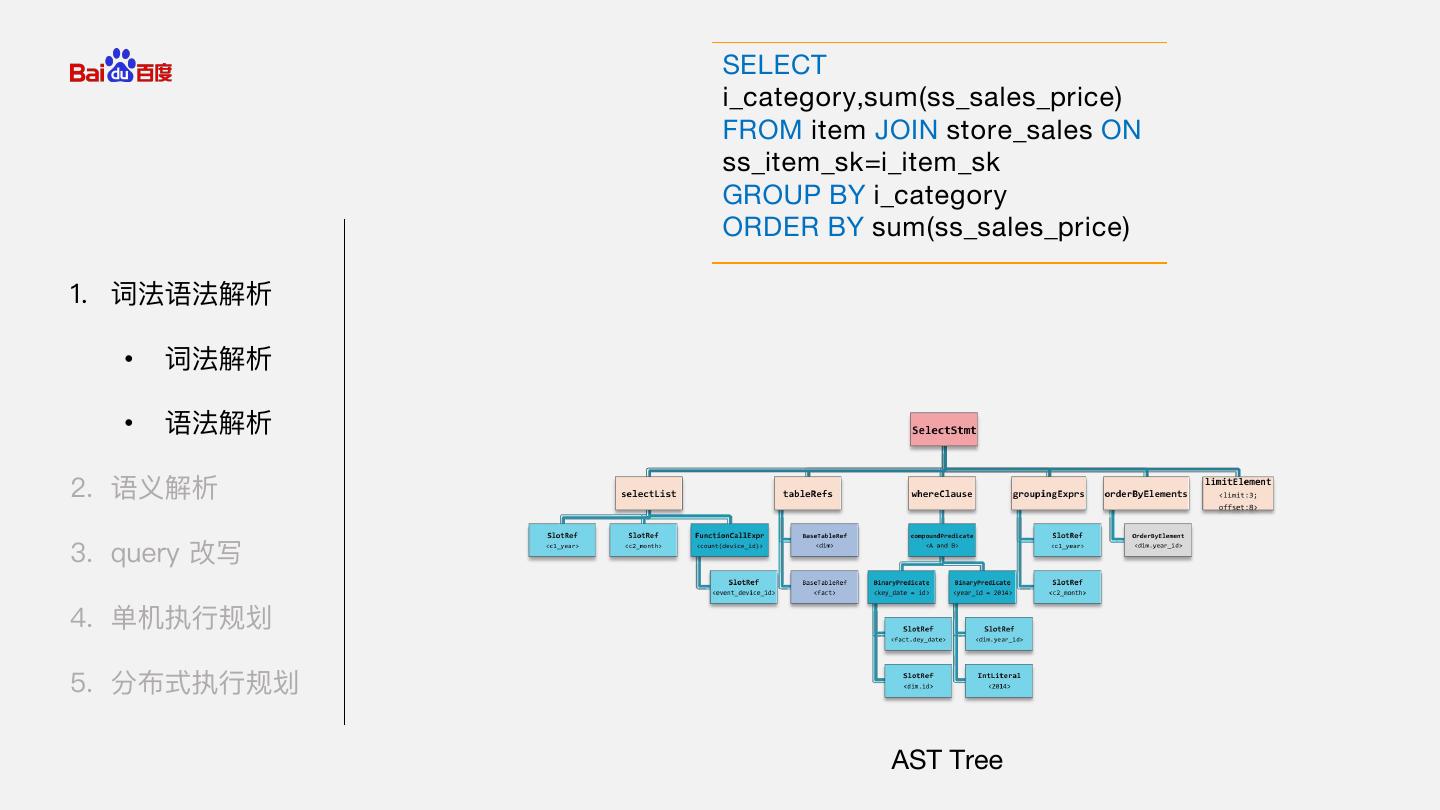
7 . SELECT i_category,sum(ss_sales_price) FROM item JOIN store_sales ON ss_item_sk=i_item_sk GROUP BY i_category ORDER BY sum(ss_sales_price) 1. 词法语法解析 • 词法解析 • 语法解析 2. 语义解析 3. query 改写 4. 单机执行规划 5. 分布式执行规划 AST Tree
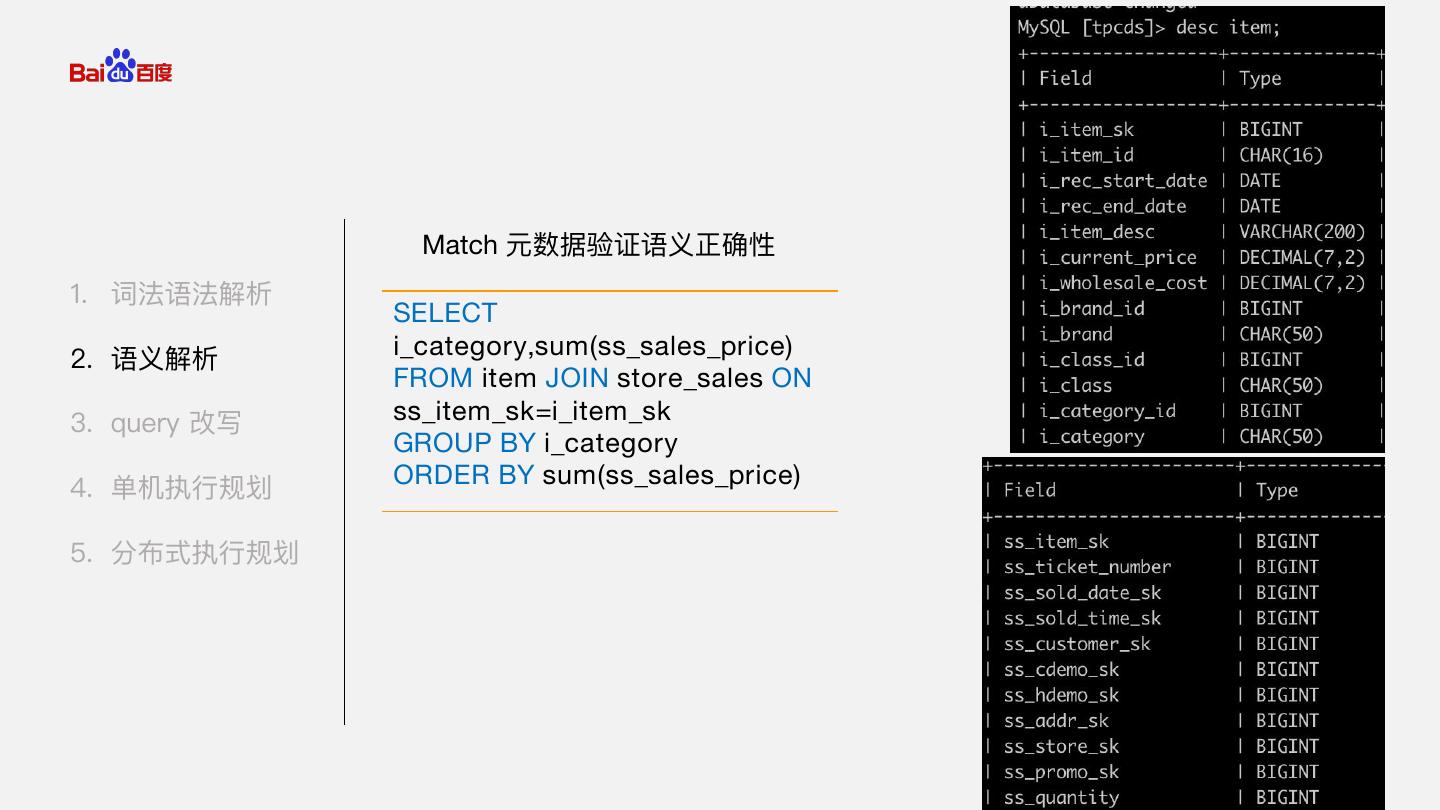
8 . Match 元数据验证语义正确性 1. 词法语法解析 SELECT 2. 语义解析 i_category,sum(ss_sales_price) FROM item JOIN store_sales ON 3. query 改写 ss_item_sk=i_item_sk GROUP BY i_category 4. 单机执行规划 ORDER BY sum(ss_sales_price) 5. 分布式执行规划
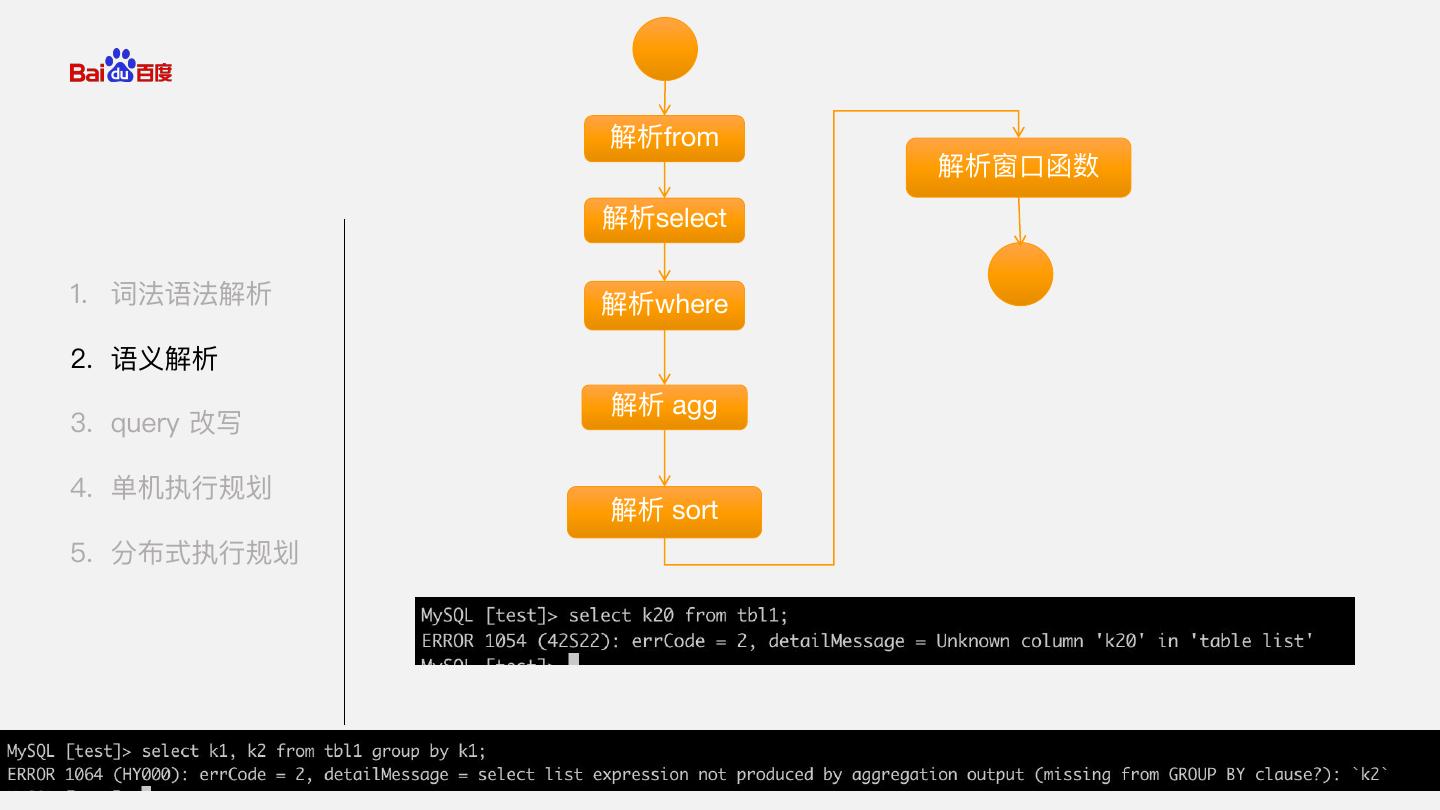
9 . 解析from 解析窗口函数 解析select 1. 词法语法解析 解析where 2. 语义解析 解析 agg 3. query 改写 4. 单机执行规划 解析 sort 5. 分布式执行规划
10 . c1=c2 and True c1=c2 Expr -> Rule.apply() -> NewExpr 1. 词法语法解析 2. 语义解析 3. query 改写 • 表达式改写 • 子查询 4. 单机执行规划 5. 分布式执行规划
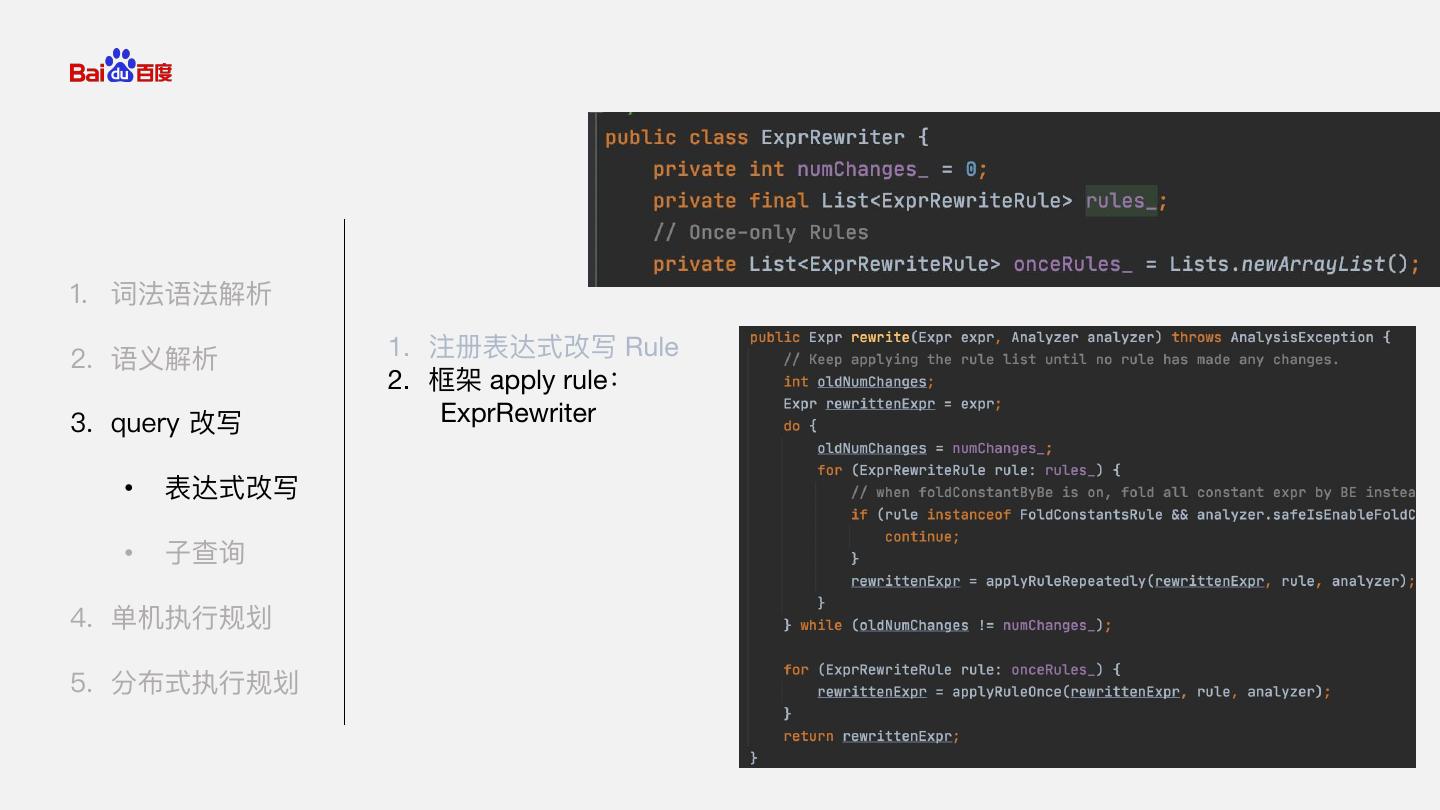
11 .1. 词法语法解析 1. 注册表达式改写 Rule 2. 语义解析 2. 框架 apply rule 3. query 改写 • 表达式改写 • 子查询 4. 单机执行规划 5. 分布式执行规划
12 .1. 词法语法解析 2. 语义解析 1. 注册表达式改写 Rule 2. 框架 apply rule: 3. query 改写 ExprRewriter • 表达式改写 • 子查询 4. 单机执行规划 5. 分布式执行规划
13 . SELECT * FROM tableA WHERE k1 in (SELECT k1 FROM tableB) 子查询解嵌套 SELECT * FROM tableA left semi join tableB on tableA.k1 = tableB.k1 1. 词法语法解析 2. 语义解析 3. query 改写 • 表达式改写 • 子查询 4. 单机执行规划 5. 分布式执行规划
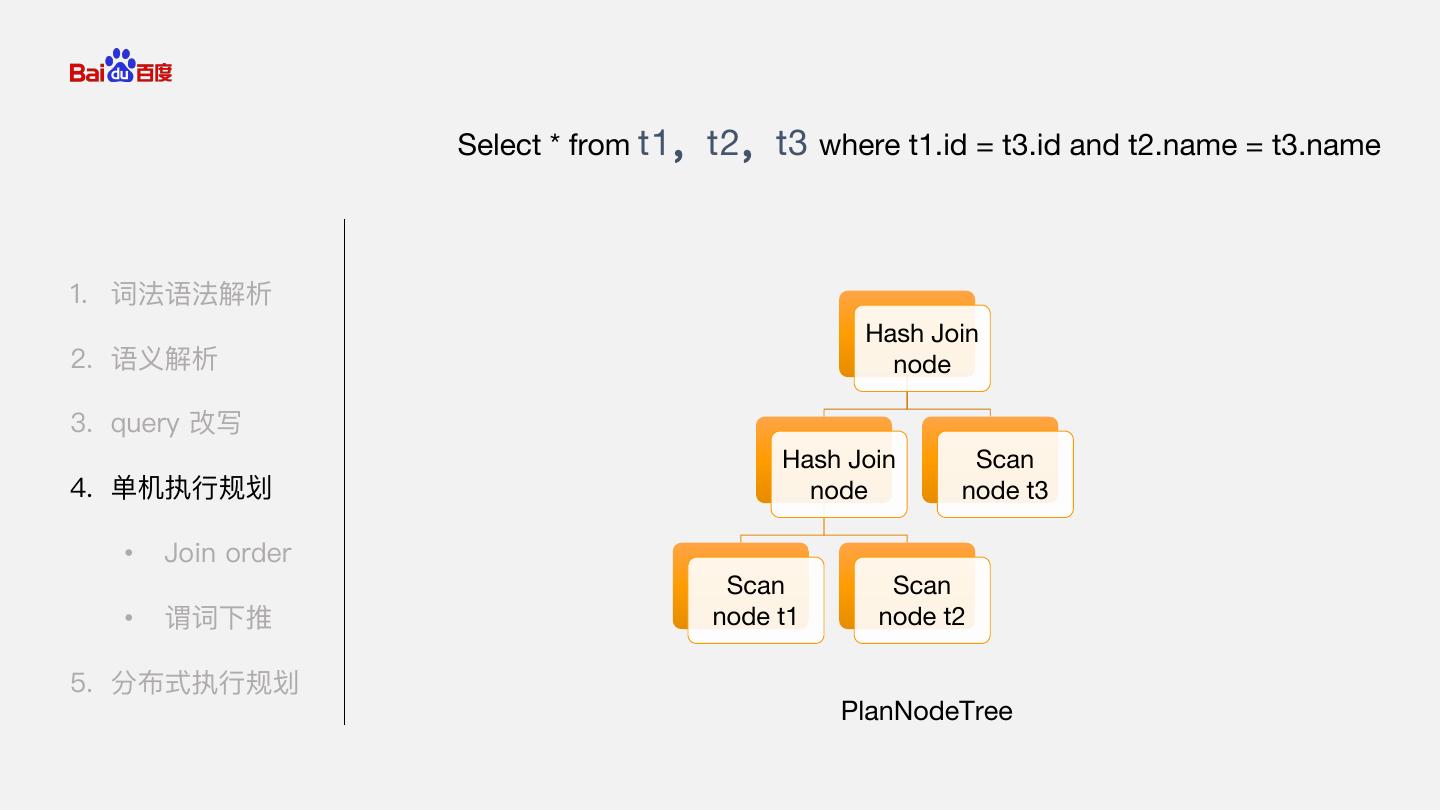
14 . Select * from t1,t2,t3 where t1.id = t3.id and t2.name = t3.name 1. 词法语法解析 Hash Join 2. 语义解析 node 3. query 改写 Hash Join Scan 4. 单机执行规划 node node t3 • Join order Scan Scan • 谓词下推 node t1 node t2 5. 分布式执行规划 PlanNodeTree
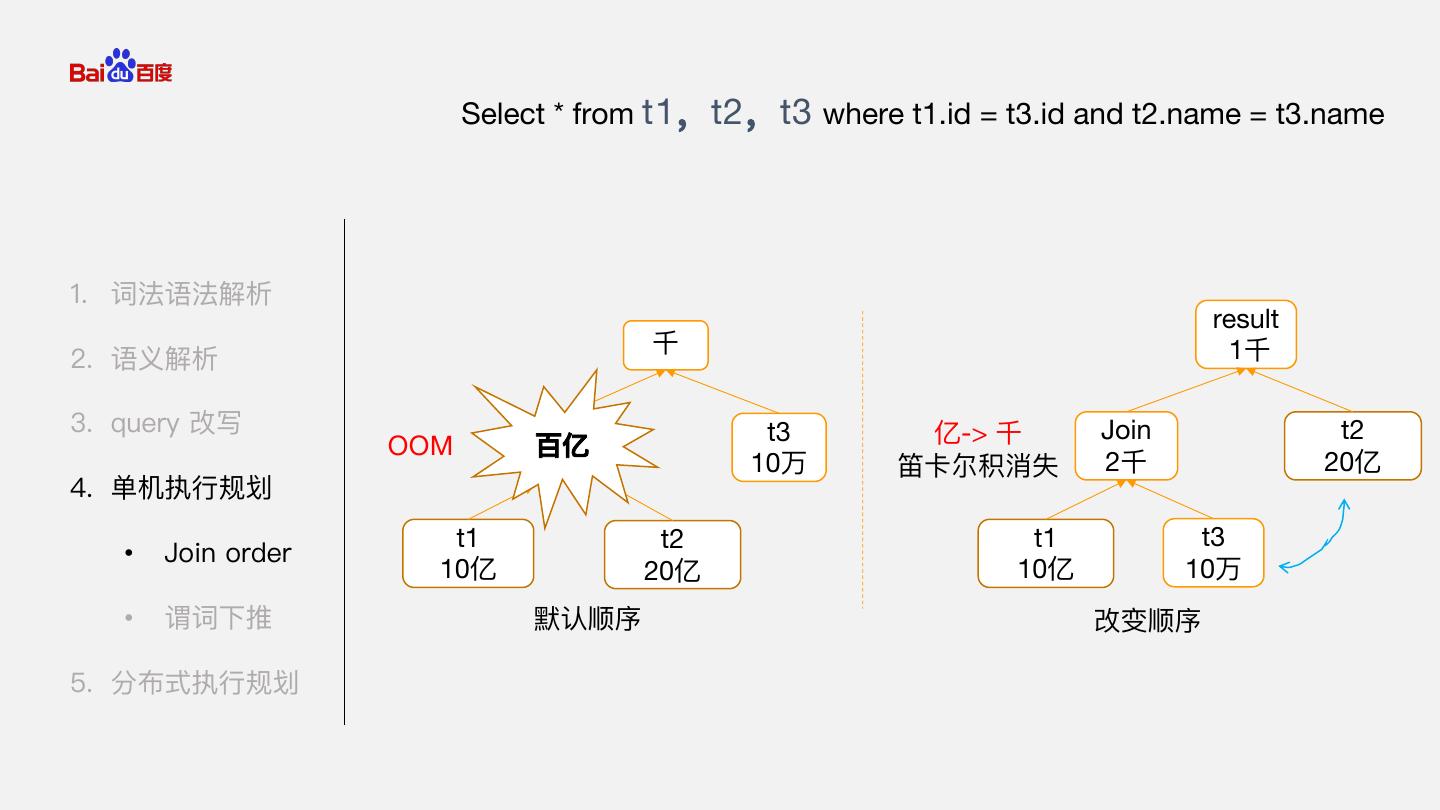
15 . Select * from t1,t2,t3 where t1.id = t3.id and t2.name = t3.name 1. 词法语法解析 result 千 1千 2. 语义解析 3. query 改写 t3 亿-> 千 Join t2 OOM 百亿 10万 笛卡尔积消失 2千 20亿 4. 单机执行规划 t1 t2 t1 t3 • Join order 10亿 20亿 10亿 10万 • 谓词下推 默认顺序 改变顺序 5. 分布式执行规划
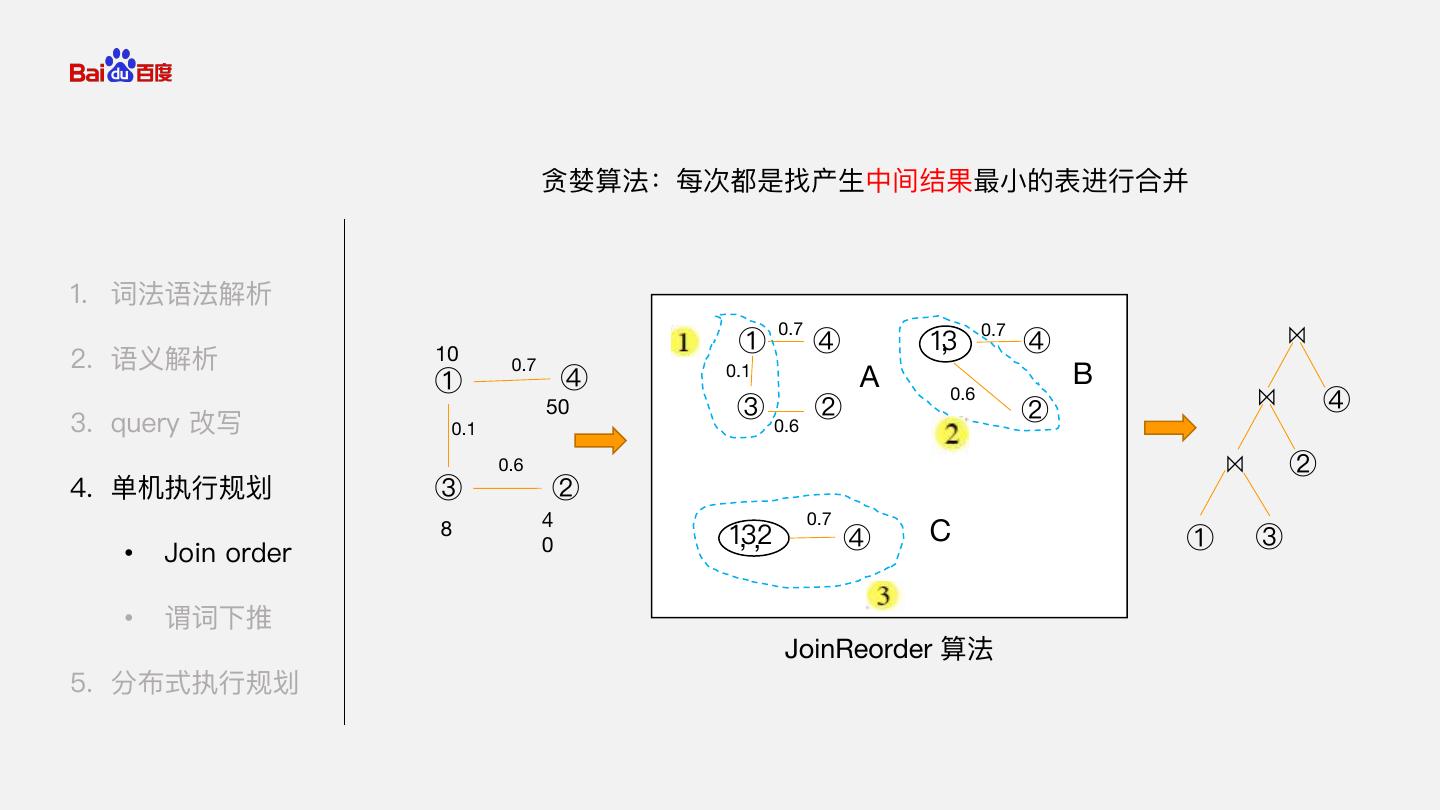
16 . 贪婪算法:每次都是找产生中间结果最小的表进行合并 1. 词法语法解析 ① 0.7 ④ , 13 0.7 ④ ⋈ 2. 语义解析 10 ① 0.7 ④ 0.1 A B 50 ③ ② 0.6 ⋈ ④ 3. query 改写 0.6 ② 0.1 0.6 ⋈ ② 4. 单机执行规划 ③ ② 4 0.7 8 0 132 ,, ④ C ① ③ • Join order • 谓词下推 JoinReorder 算法 5. 分布式执行规划
17 .1. 词法语法解析 2. 语义解析 1. Find Candidate 2. 比较 cost 3. query 改写 4. 单机执行规划 • Join order • 谓词下推 5. 分布式执行规划
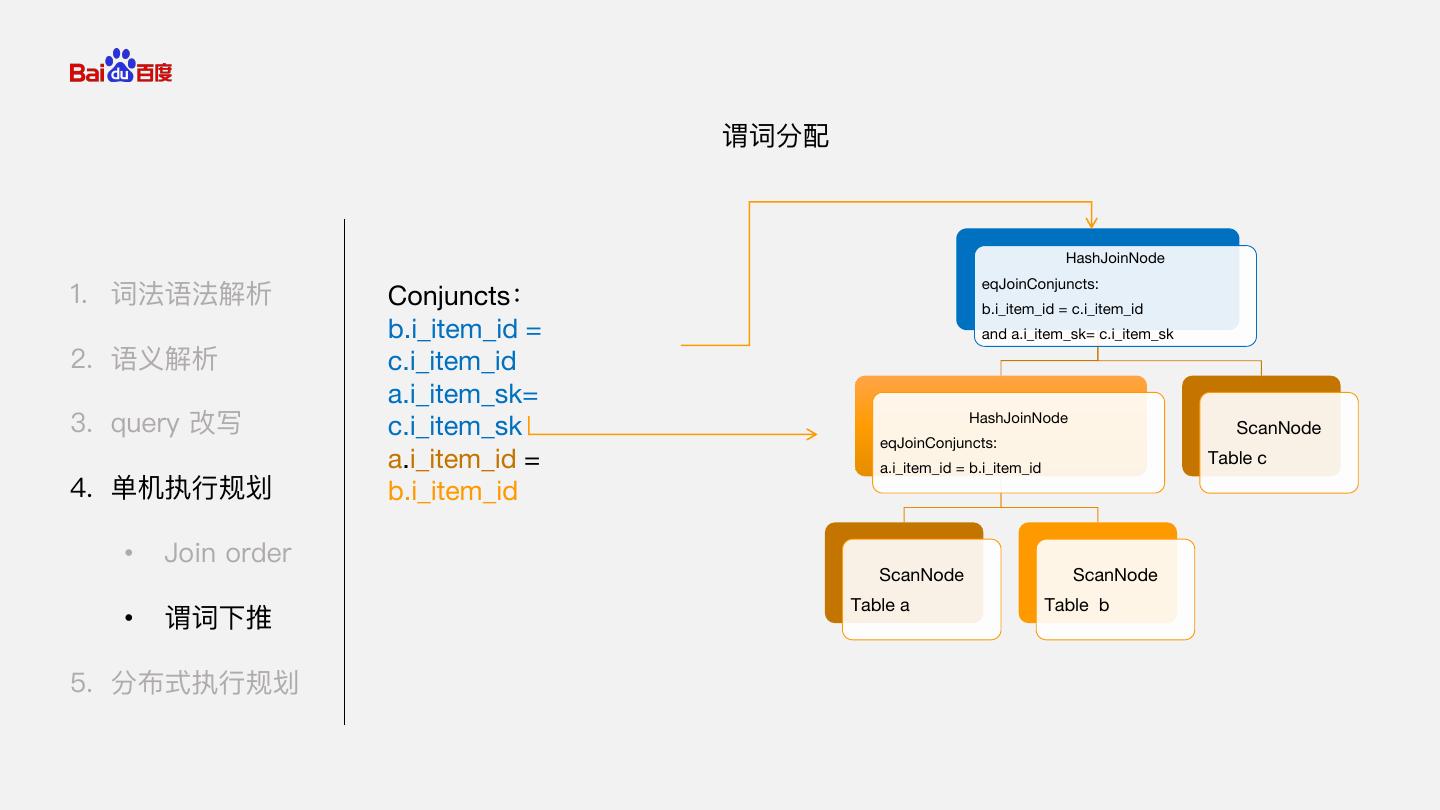
18 . 谓词分配 HashJoinNode eqJoinConjuncts: 1. 词法语法解析 Conjuncts: b.i_item_id = c.i_item_id b.i_item_id = and a.i_item_sk= c.i_item_sk 2. 语义解析 c.i_item_id a.i_item_sk= 3. query 改写 c.i_item_sk HashJoinNode eqJoinConjuncts: ScanNode a.i_item_id = a.i_item_id = b.i_item_id Table c 4. 单机执行规划 b.i_item_id • Join order ScanNode ScanNode Table a Table b • 谓词下推 5. 分布式执行规划
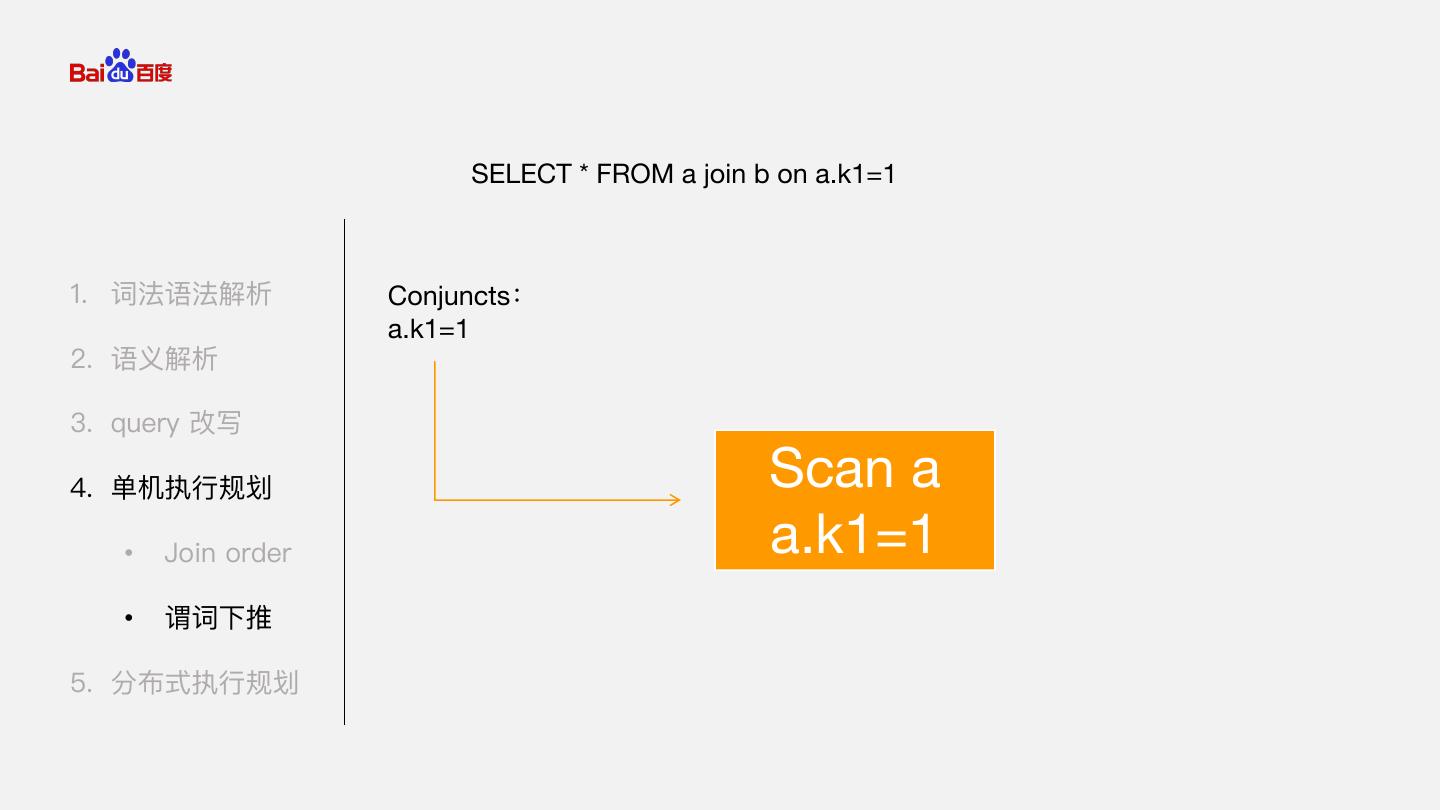
19 . SELECT * FROM a join b on a.k1=1 1. 词法语法解析 Conjuncts: a.k1=1 2. 语义解析 3. query 改写 4. 单机执行规划 • Join order Scan a • 谓词下推 5. 分布式执行规划
20 . SELECT * FROM a join b on a.k1=1 1. 词法语法解析 Conjuncts: a.k1=1 2. 语义解析 3. query 改写 4. 单机执行规划 Scan a • Join order a.k1=1 • 谓词下推 5. 分布式执行规划
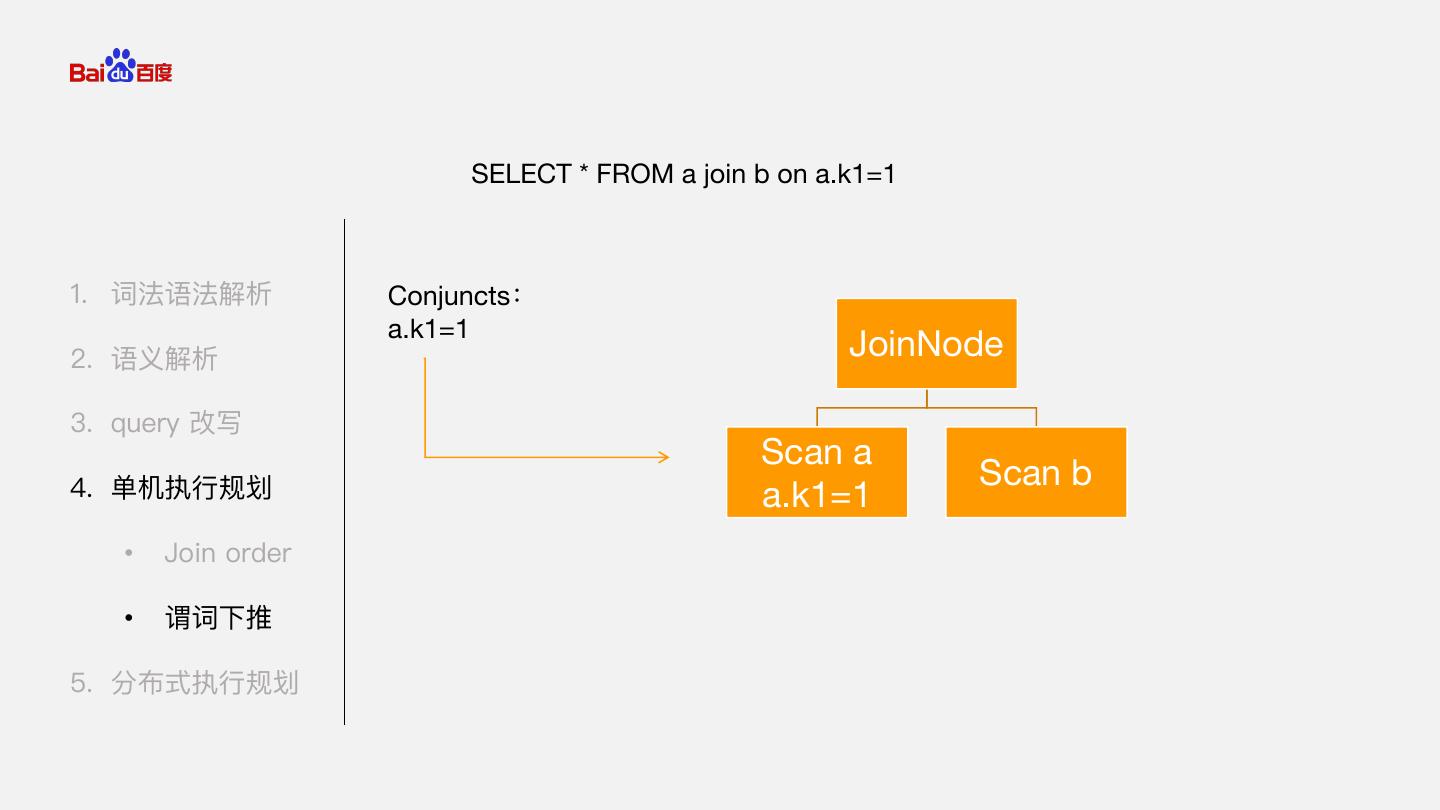
21 . SELECT * FROM a join b on a.k1=1 1. 词法语法解析 Conjuncts: a.k1=1 2. 语义解析 JoinNode 3. query 改写 Scan a Scan b 4. 单机执行规划 a.k1=1 • Join order • 谓词下推 5. 分布式执行规划
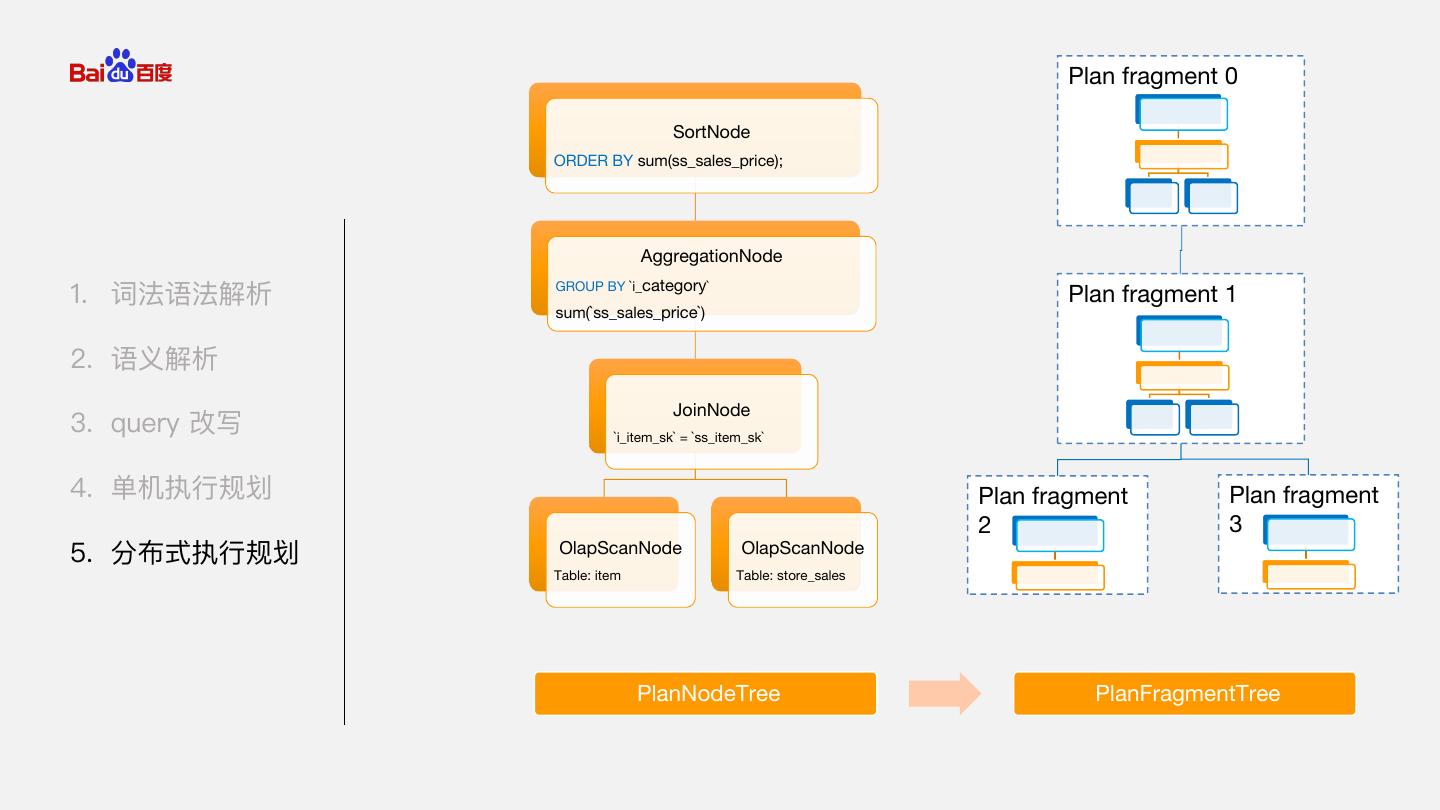
22 . Plan fragment 0 SortNode ORDER BY sum(ss_sales_price); AggregationNode GROUP BY `i_category` 1. 词法语法解析 Plan fragment 1 sum(`ss_sales_price`) 2. 语义解析 JoinNode 3. query 改写 `i_item_sk` = `ss_item_sk` 4. 单机执行规划 Plan fragment Plan fragment 2 3 5. 分布式执行规划 OlapScanNode OlapScanNode Table: item Table: store_sales PlanNodeTree PlanFragmentTree
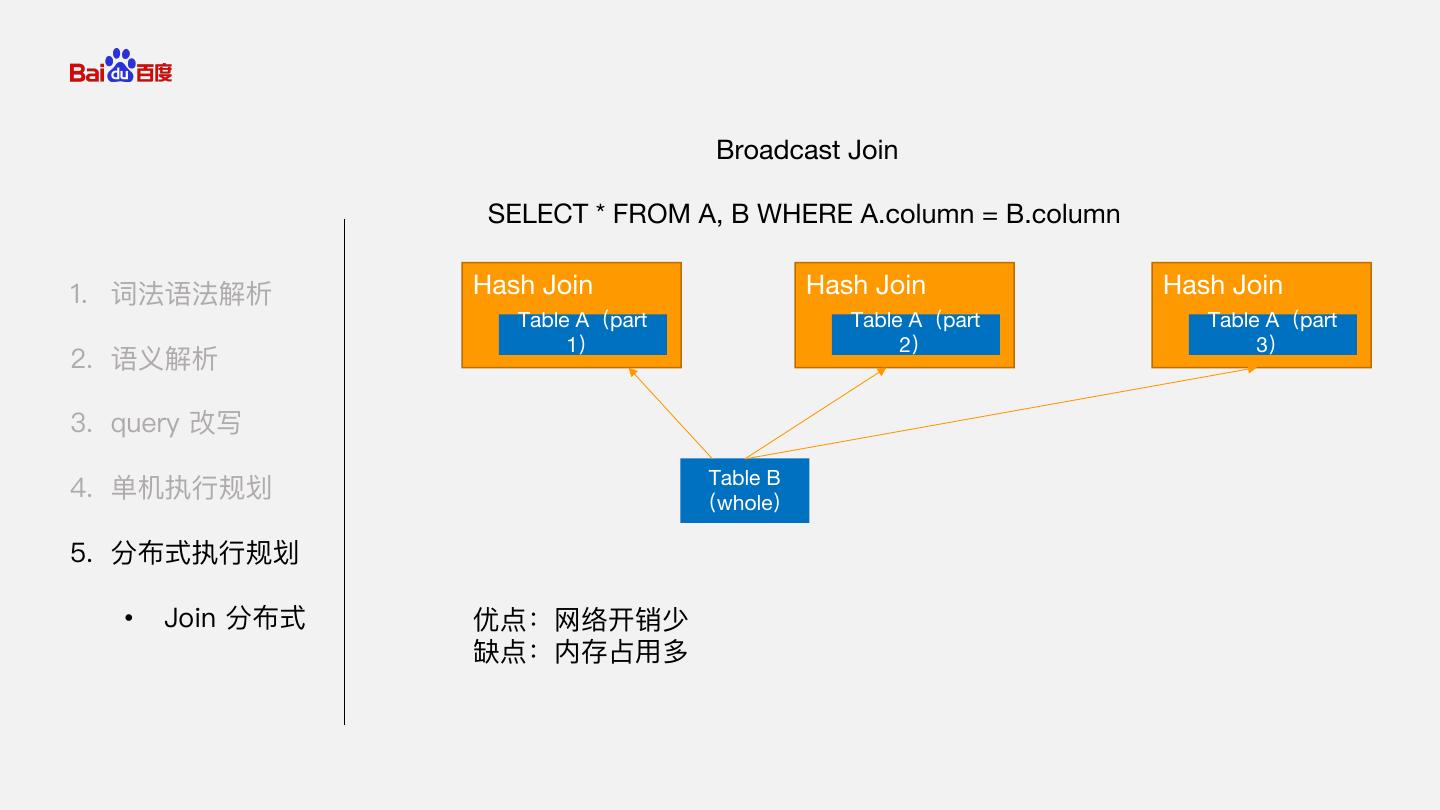
23 . Broadcast Join SELECT * FROM A, B WHERE A.column = B.column 1. 词法语法解析 Hash Join Hash Join Hash Join Table A(part Table A(part Table A(part 1) 2) 3) 2. 语义解析 3. query 改写 Table B 4. 单机执行规划 (whole) 5. 分布式执行规划 • Join 分布式 优点:网络开销少 缺点:内存占用多
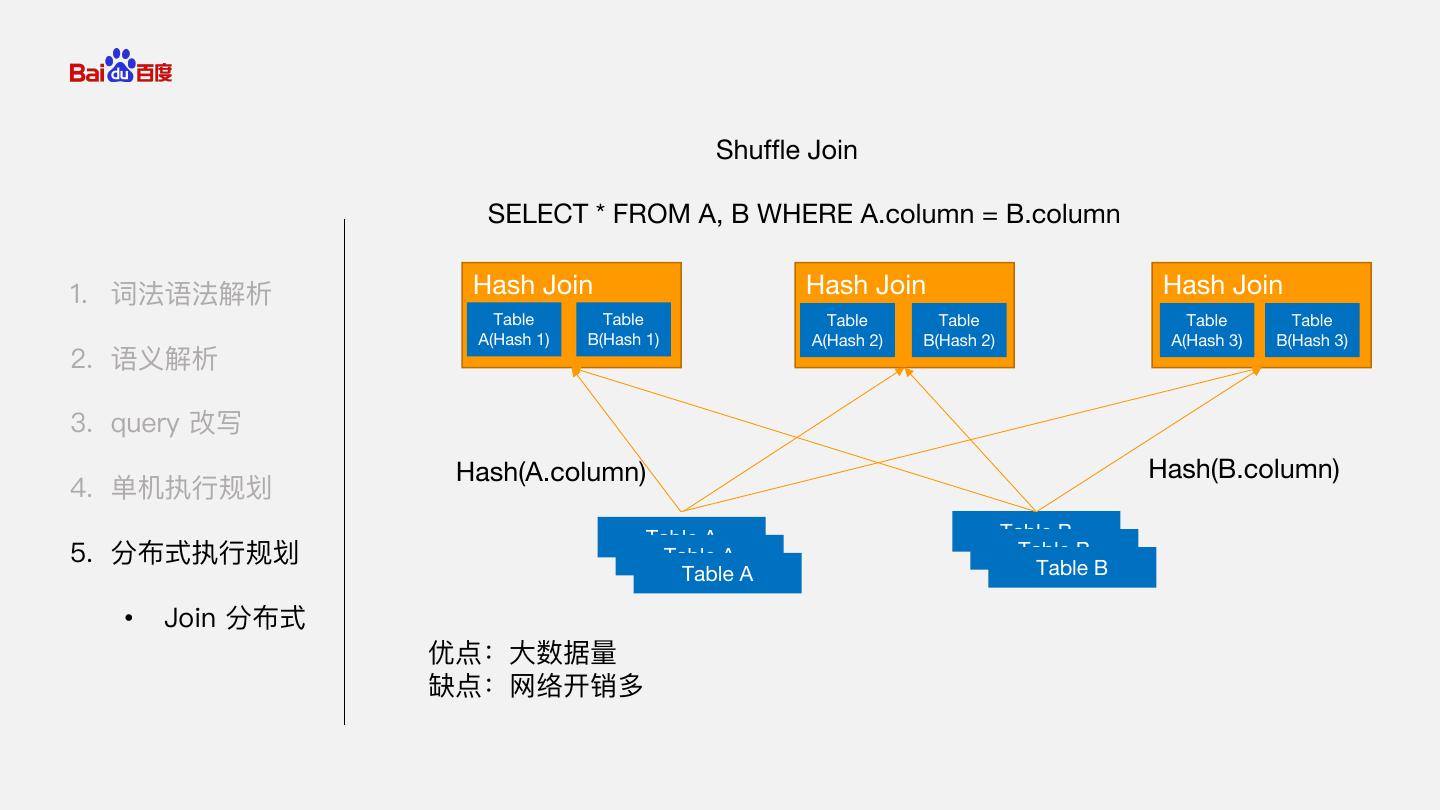
24 . Shuffle Join SELECT * FROM A, B WHERE A.column = B.column 1. 词法语法解析 Hash Join Hash Join Hash Join Table Table Table Table Table Table A(Hash 1) B(Hash 1) A(Hash 2) B(Hash 2) A(Hash 3) B(Hash 3) 2. 语义解析 3. query 改写 Hash(A.column) Hash(B.column) 4. 单机执行规划 Table A Table B 5. 分布式执行规划 Table A Table B Table A Table B • Join 分布式 优点:大数据量 缺点:网络开销多
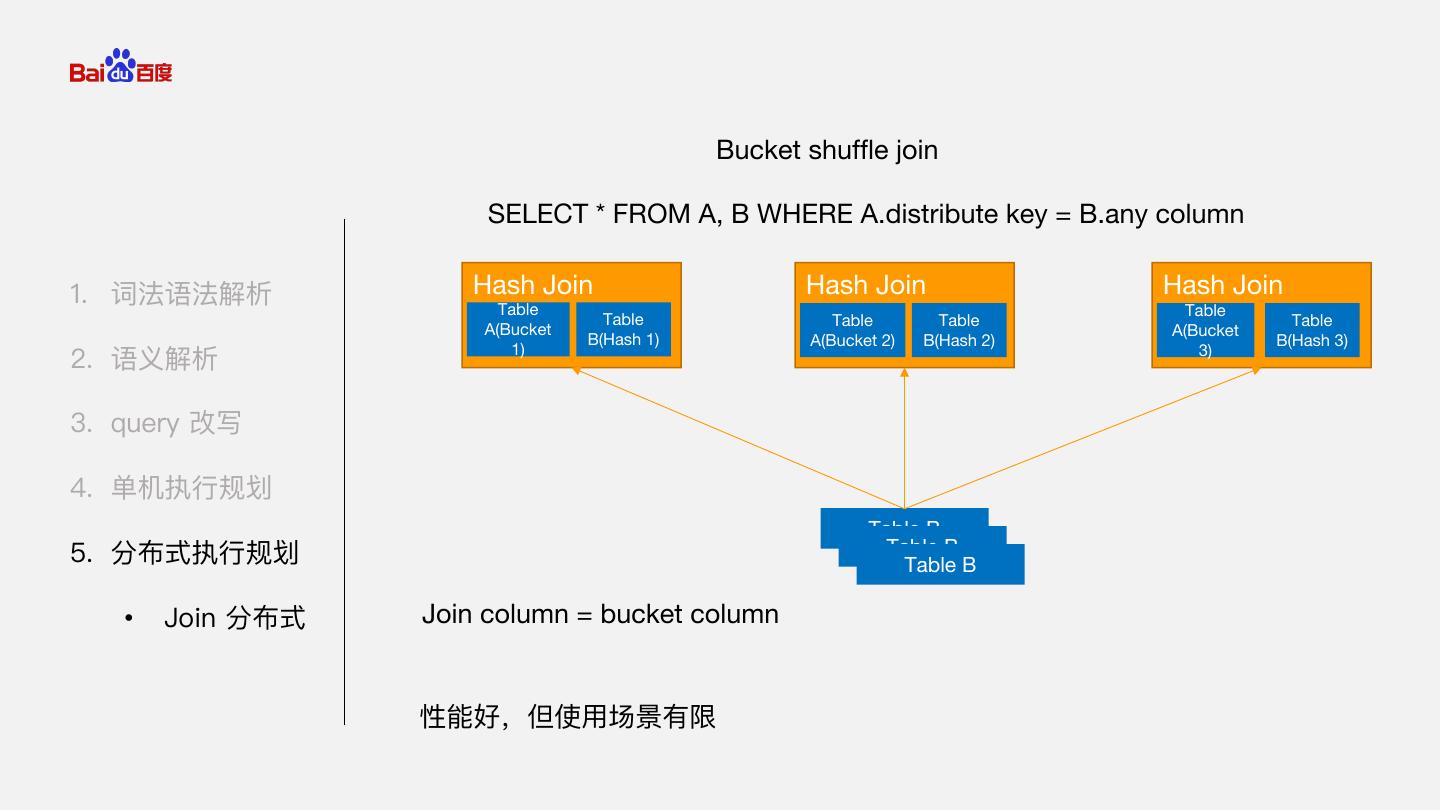
25 . Bucket shuffle join SELECT * FROM A, B WHERE A.distribute key = B.any column 1. 词法语法解析 Hash Join Hash Join Hash Join Table Table Table Table Table Table A(Bucket A(Bucket B(Hash 1) A(Bucket 2) B(Hash 2) B(Hash 3) 1) 3) 2. 语义解析 3. query 改写 4. 单机执行规划 Table B 5. 分布式执行规划 Table B Table B • Join 分布式 Join column = bucket column 性能好,但使用场景有限
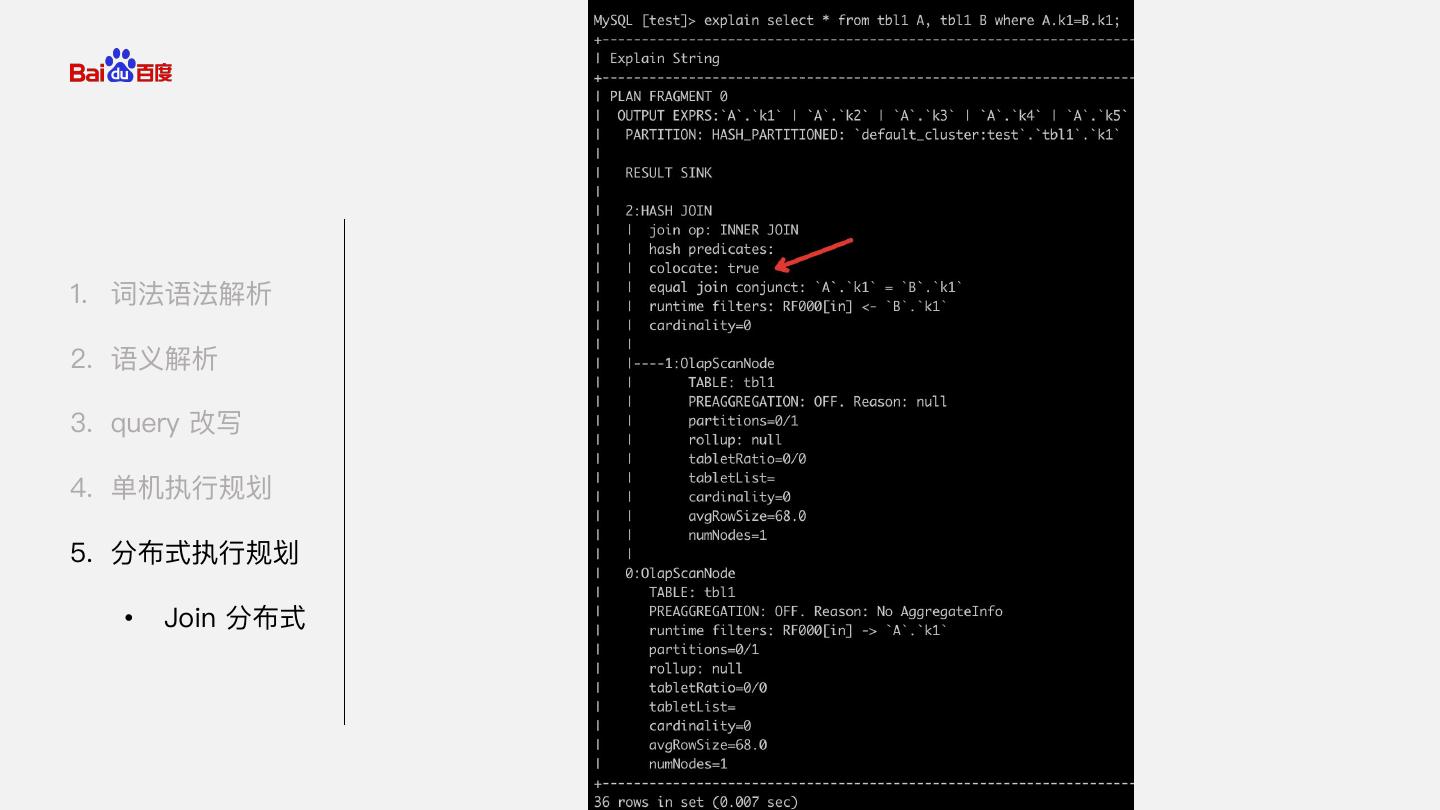
26 . Colocate join SELECT * FROM A, B WHERE A.colocate column = B.collocate column 1. 词法语法解析 2. 语义解析 Hash Join Hash Join Hash Join Table Table Table Table Table Table 3. query 改写 A(group1) B(group1) A(group2) B(group2) A(group3) B(group3) 4. 单机执行规划 5. 分布式执行规划 • Join 分布式 Colocate group : (TableA distribute key, TableB distribute key) 相同 HASH 值在相同 be 上。 性能最好,但使用场景有限
27 .1. 词法语法解析 2. 语义解析 3. query 改写 4. 单机执行规划 5. 分布式执行规划 • Join 分布式
28 .1. 词法语法解析 2. 语义解析 1. canColocate() 3. query 改写 2. canBucketShuffle() 3. Broadcast vs shuffle 4. 单机执行规划 5. 分布式执行规划 • Join 分布式
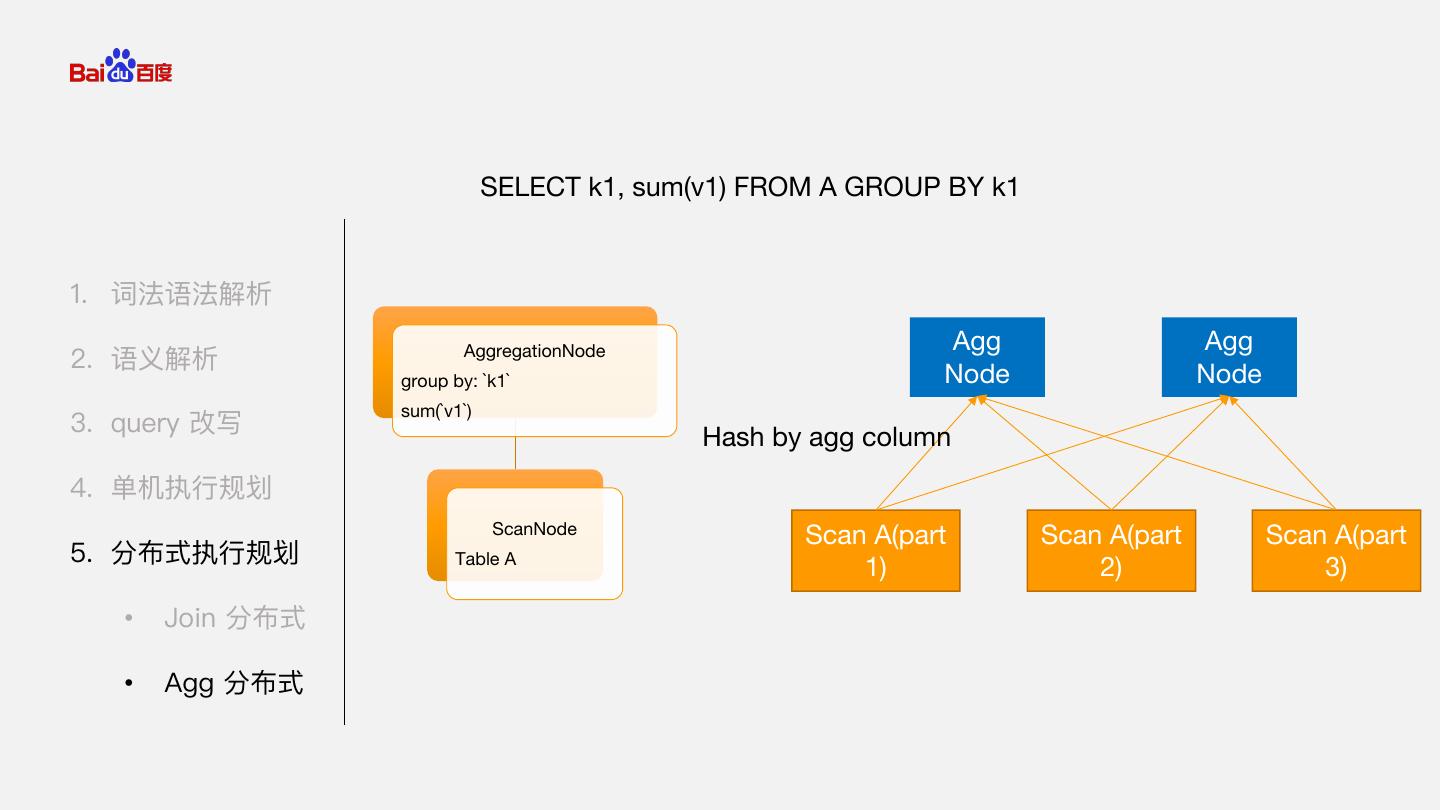
29 . SELECT k1, sum(v1) FROM A GROUP BY k1 1. 词法语法解析 AggregationNode Agg Agg 2. 语义解析 group by: `k1` Node Node sum(`v1`) 3. query 改写 Hash by agg column 4. 单机执行规划 ScanNode Scan A(part Scan A(part Scan A(part 5. 分布式执行规划 Table A 1) 2) 3) • Join 分布式 • Agg 分布式
3秒后跳转登录页面
去登陆

