《 Apache Doris 源码阅读与解析——第五讲:数据是如何被读取的》
分享
点赞
37
收藏
13
下载 173
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
《 Apache Doris 源码阅读与解析》系列直播活动旨在帮助 Apache Doris 社区的开发者或者有意向参与 Apache Doris 社区建设的小伙伴们,可以更快熟悉 Apache Doris 代码的组织结构和一些主要流程的实现原理以及代码位置,以便于各位小伙伴们能够快速上手,参与到开发工作中来。
本期内容为《第五讲:数据是如何被读取的》
这一讲我们将从扫描节点出发,介绍数据是如何从最底层的文件被读取到查询层处理的:
介绍读取逻辑的层级结构以及每一层的作用
Page Cache 的原理和作用
展开查看详情
1 .Apache Doris 源码阅读与解析
第五讲:数据的读取流程
李昊鹏
�
2 .课程介绍
• Doris数据读取的逻辑流程
• Reader -> RowsetReader -> SegmentIterator 的读取流程
• Page的读取与Page Cache
�
4 .基础概念
• Tablet
• Rowset
• Segment
• Page
�
5 . 读取数据的查询计划
• desc select * from baseall;
�
9 .Reader
• TupleReader
• _direct_next_row
• _agg_key_next_row
• _unique_key_next_row
�
12 .CollectIterator的接口
• 归并排序(堆排序)
• 依托与下层多Segment的有序性
• Key相等时,比较Rowset的版本
�
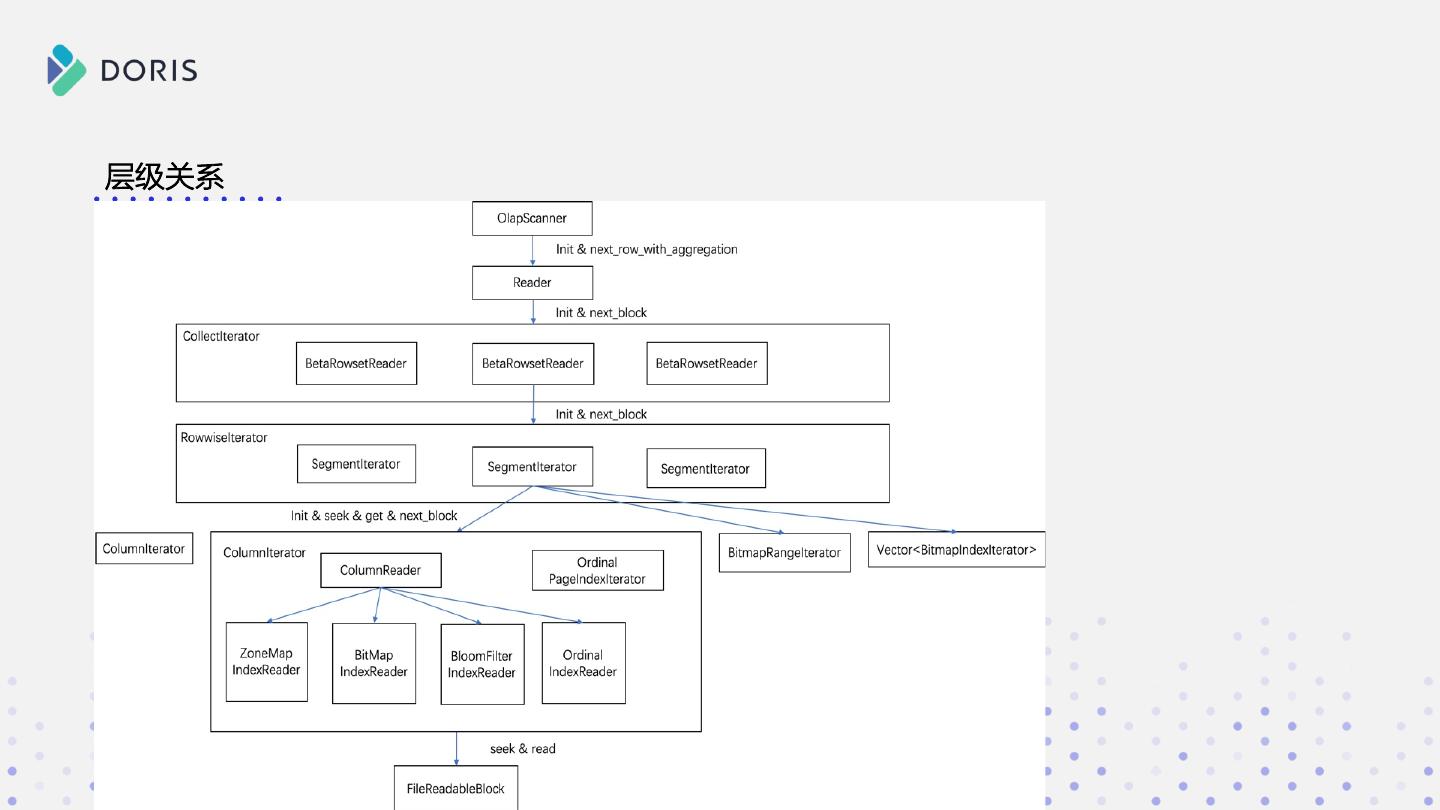
14 .RowwiseIterator
• AutoIncreamentIterator:自增的迭代器
• EmptySegmentIterator:空的迭代器
• SegmentIterator:实际读取Segment数据的迭代器
• MergeIterator:进行归并排序的迭代器,它的孩子通常为多个
SegmentIterator,来确保多Segment读取的有序性
• UnionIterator:仅用于Dup Key表,不排序,直接返回数据
�
15 .MergeInterator与UnionIterator
它们都是在SegmentIterator之上进行的逻辑封装,
实际数据读取的逻辑在SegmentIteratror之中
�
16 .SegmentIterator读取流程
Segment索引过滤查询条件
基于KeyRange确认要读取行
Page索引过滤查询条件
读取存在查询条件的列过滤
延迟物化
读取剩余不带查询条件的列
�
21 .Page索引过滤查询条件
• ZoneMap索引
• BitMap索引
• BloomFilter索引
�
23 .基于KeyRange读取存在查询条件的列并过滤
�
25 . 03
Page的读取与PageCache
�
26 .Page的结构
• 类型:IndexPage/DataPage/DictionaryPage/ShortKeyPage
• 定位:Footer中存储,Offset,Size确定唯一Page
• 压缩:LZ4,LZ4f, Snappy, Zlib
�
27 .PageCache
• 定位:Page的缓存池,可以缓存IndexPage/DataPage
• 策略:LRUCache
• 优点:减少磁盘I/O,CPU解压缩的开销
• 默认配置:
• storage_page_cache_limit: 20%
• index_page_cache_percentage: 10%
• disable_storage_page_cache: false
�
28 .Page的读取流程
Page是否存在
返回Page
Cache中
读取文件
解压缩
写入Cache
�
29 .Cache存储
• CacheKey:文件名 + Offset
• 内存结构:双向链表
• 引用计数的CacheHandle
• Cache优先级:NORMAL/DURABLE
• 配置表为“in_memmory”属性时,PageCache自动切换DURABLE
• LRU进行淘汰时,优先淘汰NORMAL属性的PageCache
�