




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
技术大咖带你探秘Cassandra 4.0 数据库
在本次活动中,我们的嘉宾将分享他们对于Cassandra 4.0中以下内容的理解:
审核日志 (Audit Logging)
零拷贝串流 (Zero-copy streaming)
Netty节点间通信 (Netty Internode messaging)
虚拟表 (Virtual Table)
增量式修复 (Incremental Repair)
临时副本 (Transient replication)
回放测试,查询日志 (Replay Testing (FQL))
模糊测试和基于属性的测试 (Fuzz Testing and Property based testing)
Cassandra-diff工具
你可以为4.0发布做什么贡献
展开查看详情
1 .Apache Cassandra 4.0 新特性介绍 蔡⼀凡
2 .Cassandra 4.0-beta1已经发布了 🎉
3 .571项代码变更! 截⽌4.0-beta1 https://github.com/apache/cassandra/blob/trunk/CHANGES.txt
4 .主要内容 • 审核⽇志 (Audit logging) • 零拷⻉串流(Zero-copy streaming) • Netty节点间通信(Netty internode messaging) • 虚拟表(Virtual table) • 增量式修复(Incremental repair) • 临时副本(Transient replication)
5 .审核⽇志(Audit logging) CASSANDRA-12151 • 记录所有数据库事件 • ⾼性能 • 有助于企业的合规管理 • 回放测试(Replay testing)
6 .零拷⻉串流(Zero-copy streaming) 数据串流在Cassandra的场景 • 启动(bootstrap) • 数据修复 • Nodetool rebuild • 增加/替换/移除节点 • 修改节点令牌(token)
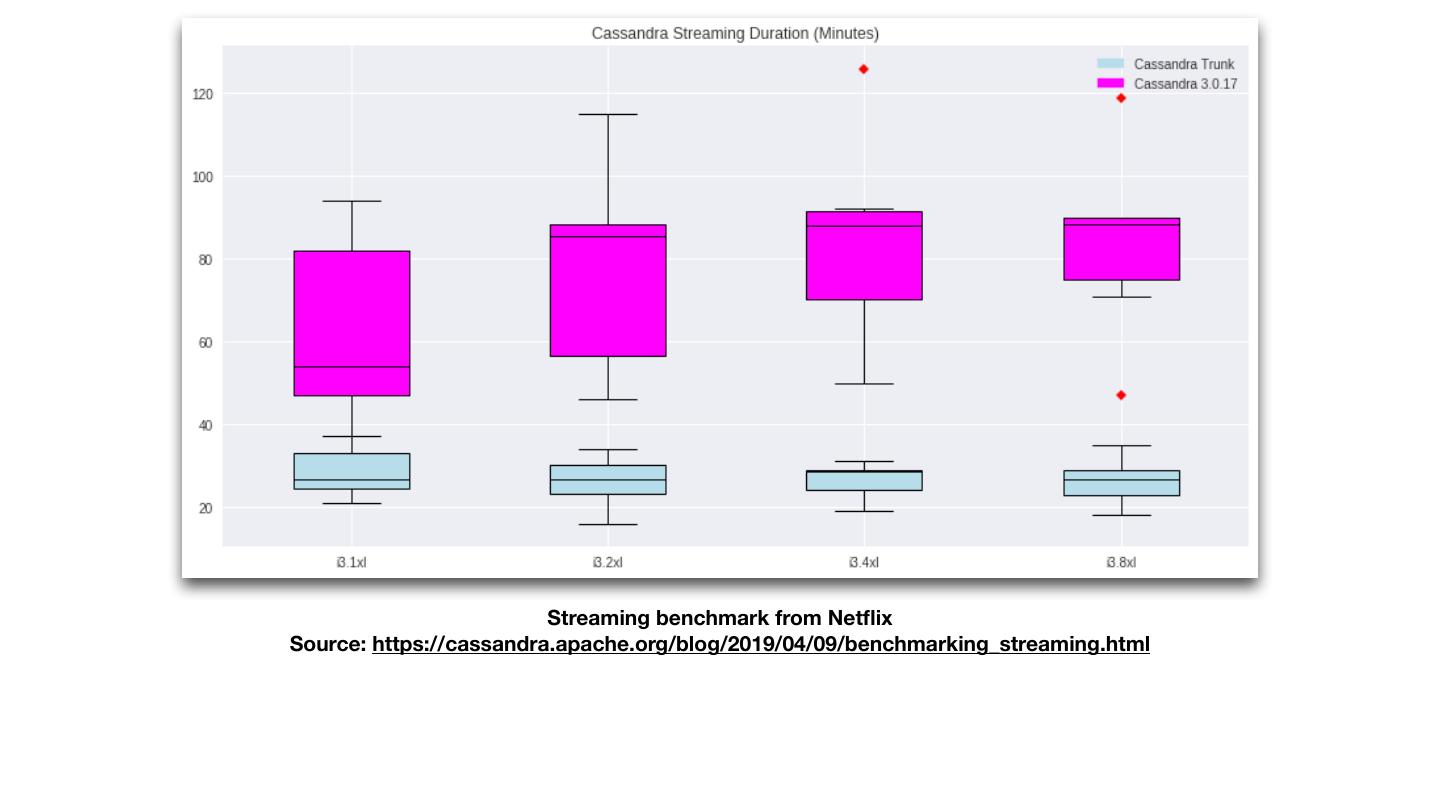
7 . Streaming benchmark from Netflix Source: https://cassandra.apache.org/blog/2019/04/09/benchmarking_streaming.html
8 .零拷⻉串流(Zero-copy streaming) CASSANDRA-14556 • ⼤幅提⾼串流速度(~5倍) • I/O Bound(磁盘,⽹卡) • ⼤幅缩短平均恢复时间 • 降低运维成本
9 .Netty节点间通信(Netty internode messaging) CASSANDRA-15066 • ⾮阻塞I/O,不再按节点分配线程 • 延迟更低(平均值减少40%,p99减少60%) • 吞吐量更⾼(~2x) • 内存占⽤更少 • 节点间加密通信扩展性更⾼(~4x)
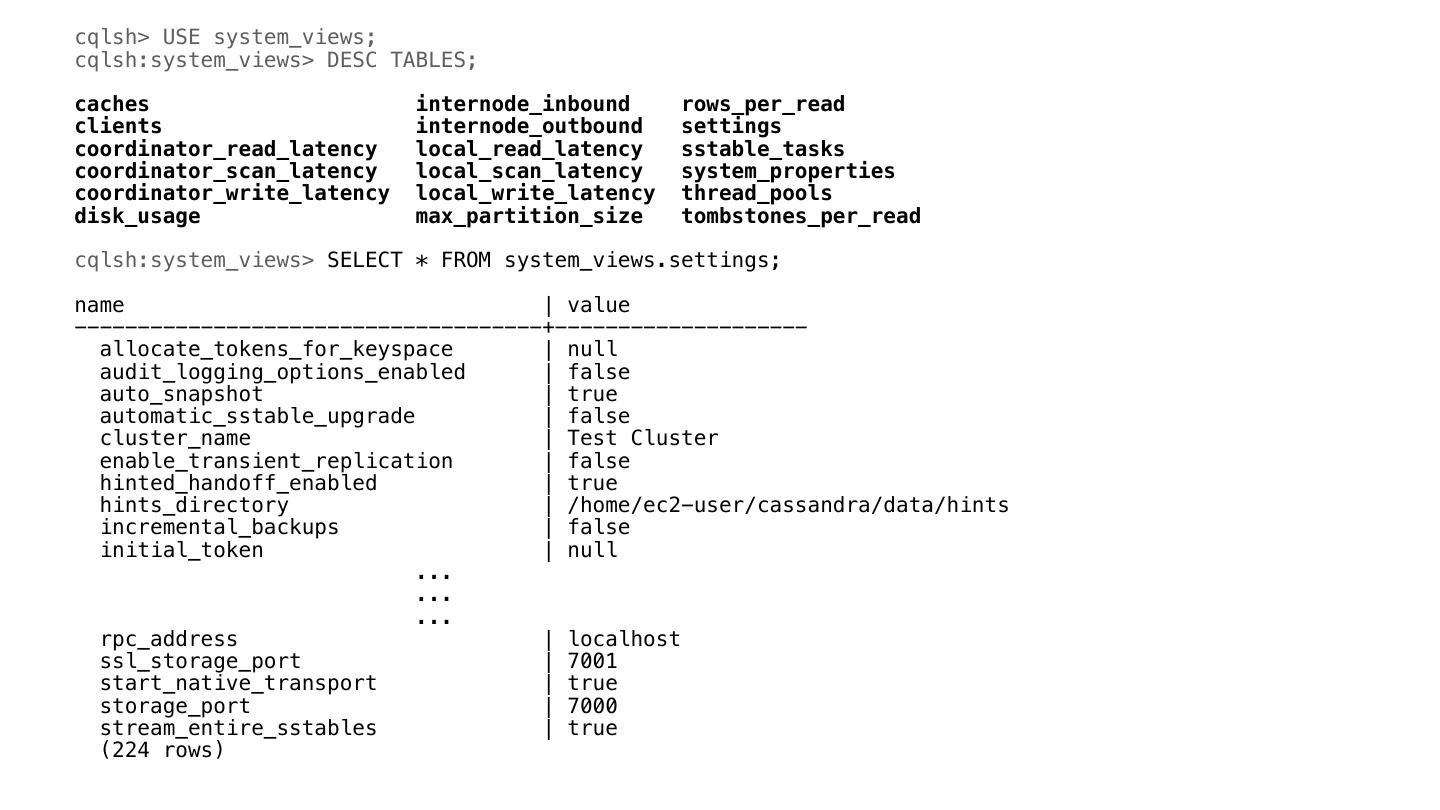
10 .虚拟表(Virtual tables) CASSANDRA-7622 • 基于API实现,⽽不是数据 • 每个节点所特有 • 通过CQL来查询Cassandra系统状态及配置 • No JMX
11 .cqlsh> USE system_views; cqlsh:system_views> DESC TABLES; caches internode_inbound rows_per_read clients internode_outbound settings coordinator_read_latency local_read_latency sstable_tasks coordinator_scan_latency local_scan_latency system_properties coordinator_write_latency local_write_latency thread_pools disk_usage max_partition_size tombstones_per_read cqlsh:system_views> SELECT * FROM system_views.settings; name | value -------------------------------------+-------------------- allocate_tokens_for_keyspace | null audit_logging_options_enabled | false auto_snapshot | true automatic_sstable_upgrade | false cluster_name | Test Cluster enable_transient_replication | false hinted_handoff_enabled | true hints_directory | /home/ec2-user/cassandra/data/hints incremental_backups | false initial_token | null ... ... ... rpc_address | localhost ssl_storage_port | 7001 start_native_transport | true storage_port | 7000 stream_entire_sstables | true (224 rows)
12 .增量式修复(Incremental repair) CASSANDRA-9143 • 只修复未修复过的数据 • 分摊修复的时间和I/O成本 • 4.0修复了“增量式修复”功能
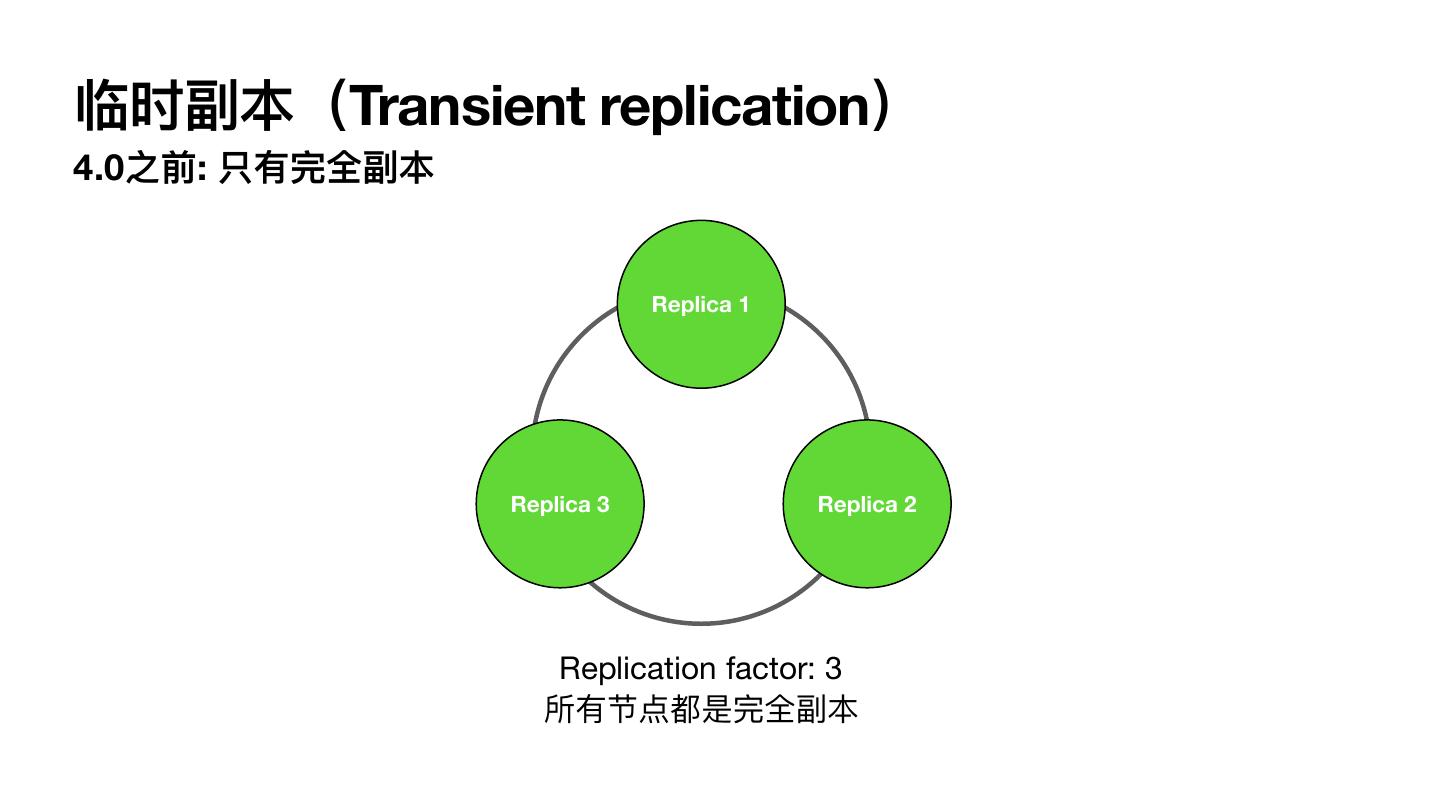
13 .临时副本(Transient replication) 4.0之前: 只有完全副本 Replica 1 Replica 3 Replica 2 Replication factor: 3 所有节点都是完全副本
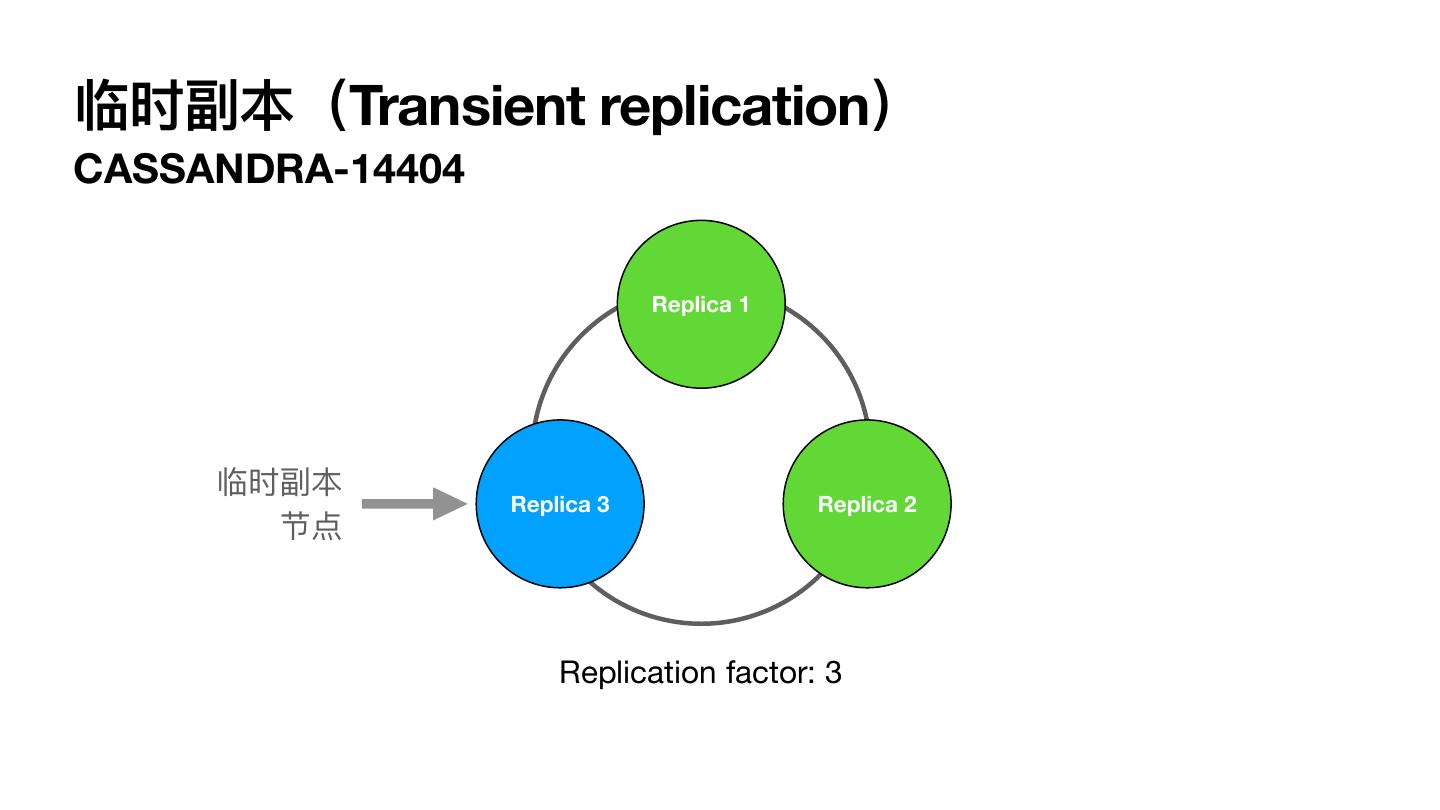
14 .临时副本(Transient replication) CASSANDRA-14404 Replica 1 临时副本 Replica 3 Replica 2 节点 Replication factor: 3
15 .临时副本(Transient replication) 影响 • 最多减少33%的存储,如果RF=3 • 临时副本节点使⽤更少的CPU和I/O • 保留持久性的保证
16 . Cassandra 4.0 史上最稳定版本 带来更快的串流,可靠的运作以及企业级的安全与可观察性
17 .Cassandra社区是怎么测试4.0的 曹海荣
18 .自我介绍 - 2006年起就参与的开源软件的开发 - 2010年~2013年曾在北京领导过VMWare beijing的研发团队 - 2014年加入DataStax,领导后端工程师团队基于Apache Cassandra, Spark, Solr 和 TinkerPop的大数据平台(DSE)
19 .Cassandra 数据库准确性测试架构 1. 夜照恢复 2. 匿名化Schema 3. 分别加载数据到源集群 和目标集群 4. 运行Cassandra-diff 来 比较两个集群的数据
20 . Anonymize schema (匿名schema) 源Schema 匿名化Schema CREATE KEYSPACE cassandradiff WITH replication = CREATE KEYSPACE IF NOT EXISTS ks_0 WITH {'class': 'SimpleStrategy', 'replication_factor': '1'} AND replication = {'class': 'SimpleStrategy', durable_writes = true; 'replication_factor': '1'} AND durable_writes = true; CREATE TABLE cassandradiff.job_status ( CREATE TABLE IF NOT EXISTS ks_0.tbl_0 ( job_id uuid,· col_4 uuid, bucket int, col_5 int, qualified_table_name text, col_2 text, completed counter, col_3 counter, PRIMARY KEY ((job_id, bucket), qualified_table_name) PRIMARY KEY ((col_4, col_5), col_2) ) WITH CLUSTERING ORDER BY (qualified_table_name ) WITH CLUSTERING ORDER BY (col_2 ASC) ASC)
21 .加载数据 - NoSQL Bench 为什么使用NoSQLBench来加载数据? - 开源NoSQL 测试工具 https://github.com/nosqlbench/nosqlbench - 决定性(Deterministic) 生成数据来确保多次生成的数据是一致的。 - 基于匿名Schema生成随机数据
22 .NoSQL Bench 例子 bindings: name_2: Add(1) -> int name_3: HashedLineToString('data/variable_words.txt') blocks: - tags: $java -jar nb.jar start driver=cql workload=myks_nb tags=phase:schema phase: schema statements: - create-keyspace: | CREATE KEYSPACE if not exists name_0 WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true; tags: name: create-keyspace - create-table : | CREATE TABLE if not exists name_0.name_1 ( name_2 int PRIMARY KEY, name_3 text ) WITH …….. tags: name: create-table $ java -jar ../nb/nb.jar run driver=cql workload=myks_nb tags=phase:main cycles=1000000 - tags: phase: main type: write statements: - insert-main: | insert into <<keyspace:name_0>>.<<table:name_1>> (name_2, name_3) values ({name_2}, {name_3}) using timestamp {cell_timestamp} idempotent: true tags: name: insert-main params: instrument: TEMPLATE(instrument-writes,TEMPLATE(instrument,false))
23 .FQL - Replay Testing (回放测试) FQL (Full Query Log 所有查询日志): - Cassandra 4.0的新功能 - 用来记录集群内所有CQL命令 - 主要用来调试,性能测试 - 审核日志(Audit log)就是基于FQL开发的 - 只记录成功的命令: Single or Batch. - 启用FQL对集群性能的影响非常小 (BinLog 格式 + 高性能Chronicle Queue) - 更多信息 - https://issues.apache.org/jira/browse/CASSANDRA-13983 - https://cassandra.apache.org/doc/latest/new/fqllogging.html
24 .FQL - Replay Testing (回放测试) $nodetool enablefullquerylog --path /tmp/cassfql root@4ee861862dbd:/tmp/cassfql# ls -l total 3116 Or cassandra.yaml full_query_logging_options: -rw-r--r-- 1 cassandra cassandra 83886080 Aug 5 19:37 20200805-19.cq4 -rw-r--r-- 1 cassandra cassandra 65536 Aug 5 19:13 directory-listing.cq4t $ fqltool replay --keyspace name_0 --results /tmp/cassfql-replay --target 172.17.0.2 ./ root@4ee861862dbd:/tmp/cassfql# fqltool replay --keyspace name_0 --results /tmp/cassfql-replay --target 172.17.0.2 ./ INFO [main] 2020-08-07 19:22:06,933 QueryProcessor.java:106 - Initialized prepared statement caches with 0 MB INFO [main] 2020-08-07 19:22:06,964 Cluster.java:267 - DataStax Java driver 3.9.0 for Apache Cassandra INFO [main] 2020-08-07 19:22:06,969 GuavaCompatibility.java:185 - Detected Guava >= 19 in the classpath, using modern compatibility layer INFO [main] 2020-08-07 19:22:06,989 Native.java:113 - Could not load JNR C Library, native system calls through this library will not be available (set this logger level to DEBUG to see the full stack trace). INFO [main] 2020-08-07 19:22:06,990 Clock.java:60 - Using java.lang.System clock to generate timestamps. INFO [main] 2020-08-07 19:22:07,112 NettyUtil.java:84 - Detected shaded Netty classes in the classpath; native epoll transport will not work properly, defaulting to NIO. INFO [main] 2020-08-07 19:22:07,549 DCAwareRoundRobinPolicy.java:110 - Using data-center name 'datacenter1' for DCAwareRoundRobinPolicy (if this is incorrect, please provide the correct datacenter name with DCAwareRoundRobinPolicy constructor) INFO [main] 2020-08-07 19:22:07,551 Cluster.java:1782 - New Cassandra host /172.17.0.2:9042 added ERROR [pool-2-thread-1] 2020-08-07 19:22:07,669 ResultHandler.java:65 - Query FQLQuery{queryStartTime=1596654826029, protocolVersion=4, queryState='org.apache.cassandra.service.QueryState@2b87581'}: Query: [SELECT * FROM system.peers_v2], valuecount : 0 against 172.17.0.2 failure: unconfigured table peers_v2 ………………………………. INFO [main] 2020-08-07 19:22:13,069 QueryReplayer.java:147 - 5000 queries, rate = 891.80 INFO [main] 2020-08-07 19:22:16,867 QueryReplayer.java:147 - 10000 queries, rate = 891.80
25 .FQL - Replay Testing (回放测试) Type: single-query Query start time: 1596654826638 Protocol version: 4 Generated timestamp:-9223372036854775808 Generated nowInSeconds:-2147483648 Query: CREATE TABLE if not exists name_0.name_1 ( name_2 int PRIMARY KEY, $fqltool dump /tmp/cassfql name_3 text ) WITH compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND default_time_to_live = 0 AND gc_grace_seconds = 864000 AND memtable_flush_period_in_ms = 0; Type: single-query Query start time: 1596654826328 Protocol version: 4 Generated timestamp:-9223372036854775808 Generated nowInSeconds:1596654826 Query: select cluster_name from system.local where key = 'local' Type: single-query Values: Query start time: 1596654853093 Protocol version: 4 Generated timestamp:-9223372036854775808 Type: single-query Generated nowInSeconds:1596654853 Query start time: 1596654826343 Query: insert into name_0.name_1 (name_2, name_3) values (?, ?) using Protocol version: 4 timestamp ? Generated timestamp:-9223372036854775808 Generated nowInSeconds:-2147483648 Values: Query: CREATE KEYSPACE if not exists name_0 WITH replication = 00000000 00 00 00 01 ···· {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = 00000000 63 6F 68 65 73 69 6F 6E cohesion true; ----- 00000000 00 00 00 00 00 00 00 00 ········ Values: -----
26 .Cassandra-diff ● 加载同样的数据到两个不同版本或者不同配置的C*集群,然后用Cassandra-diff 来比较两个集群的数据来确保数据库的准确性。 ● 具体实现是把整个集群的Token切分,然后分配给Spark worker来比较每个 token的数据。 ● More: https://github.com/apache/cassandra-diff/
27 . # List of keyspace.tables to diff keyspace_tables: - name_0.name_1 # This is how many parts we split the full token range in. Cassandra-diff # Each of these splits is then compared between the clusters splits: 10000 # Number of buckets - splits / buckets should be under 100k to avoid wide partitions when storing the metadata buckets: 100 $spark-submit --verbose --files diff-job-config.yaml --class org.apache.cassandra.diff.DiffJob # global rate limit - this is how many q/s you think the target clusters can handle cassandra-diff/spark-uberjar/target/spark-uberjar-0.2-SNAPSHOT.jar diff-job-config.yaml rate_limit: 10000 # optional job id - if restarting a job, set the correct job_id here to avoid re-diffing old splits # job_id: 4e2c6c6b-bed7-4c4e-bd4c-28bef89c3cef # Fetch size to use for the query fetching the tokens in the cluster 20/08/07 13:28:15 INFO Differ: Creating Differ for Split [-1935063453332132602, -1933218778924761648] token_scan_fetch_size: 1000 20/08/07 13:28:15 INFO RangeComparator: Comparing range # Fetch size to use for the queries fetching the rows of each partition [4853338365792981798,4855183040200352752] partition_read_fetch_size: 1000 20/08/07 13:28:15 INFO JobMetadataDb: Finishing range [4853338365792981798, 4855183040200352752] for table KeyspaceTablePair{keyspace=name_0, table=name_1} read_timeout_millis: 10000 20/08/07 13:28:15 INFO Differ: Diffing Split [-1935063453332132602, -1933218778924761648] for tables reverse_read_probability: 0.5 {KeyspaceTablePair{keyspace=name_0, table=name_1}=TaskStatus{lastToken=null, stats=Matched consistency_level: ALL Partitions - 0, Mismatched Partitions - 0, Partition Errors - 0, Partitions Only In Source - 0, Partitions Only In metadata_options: Target - 0, Skipped Partitions - 0, Matched Rows - 0, Matched Values - 0, Mismatched Values - 0 }} keyspace: cassandradiff ……….. replication: "{'class':'SimpleStrategy', 'replication_factor':'1'}" 20/08/07 13:28:15 INFO JobMetadataDb: Finishing range [-1935063453332132602, -1933218778924761648] ttl: 31536000 for table KeyspaceTablePair{keyspace=name_0, table=name_1} should_init: true ………... cluster_config: 20/08/07 13:28:15 INFO Executor: Finished task 31.0 in stage 0.0 (TID 31). 1212 bytes result sent to driver source: 20/08/07 13:28:15 INFO TaskSetManager: Finished task 31.0 in stage 0.0 (TID 31) in 5981 ms on 10.0.0.13 impl: "org.apache.cassandra.diff.ContactPointsClusterProvider" (executor driver) (31/32) name: "local_test_1" 20/08/07 13:28:15 INFO Executor: Finished task 29.0 in stage 0.0 (TID 29). 1212 bytes result sent to driver contact_points: "127.0.0.1" ………... port: "9042" 20/08/07 13:28:15 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished dc: "datacenter1" 20/08/07 13:28:15 INFO DAGScheduler: Job 0 finished: reduce at DiffJob.java:179, took 22.345949 s target: 20/08/07 13:28:15 INFO JobMetadataDb: Finalizing job status impl: "org.apache.cassandra.diff.ContactPointsClusterProvider" 20/08/07 13:28:15 INFO JobMetadataDb: Marking job 91a64f2b-8be6-428b-83ef-c9121e34cf8a as not running name: "local_test_2" 20/08/07 13:28:15 INFO DiffJob: FINISHED: {KeyspaceTablePair{keyspace=name_0, contact_points: "127.0.0.1" table=name_1}=Matched Partitions - 9, Mismatched Partitions - 0, Partition Errors - 0, Partitions Only In port: "9044" Source - 0, Partitions Only In Target - 0, Skipped Partitions - 0, Matched Rows - 9, Matched Values - 18, dc: "datacenter1" Mismatched Values - 0 } metadata: 20/08/07 13:28:17 INFO DiffCluster: Closing cluster SOURCE impl: "org.apache.cassandra.diff.ContactPointsClusterProvider" 20/08/07 13:28:17 INFO DiffCluster: Closing cluster TARGET name: "local_test" contact_points: "127.0.0.1" port: "9042" dc: "datacenter1"
28 .Property based testing (PBT) ● 单元测试(Unit Test),或称为 Example Based Test,我们需要手动构建入参,再检查结果,来测 试程序对于边界条件的健壮性。 ● 相对于UT 面向用例不同,PBT 考虑的是这个问题本质的属性是什么,通过对属性的深入理解,提 出到达解集的不同路径来进行验证。 ● PBT 将一个测试分成了三个步骤: ○ 输入策略:我们不再需要手写一个个的 输入数据,而是只需要定制 输入的策略, PBT 的框架会自 动的根据策略生成足 够大的 测试数据集 ○ 结果检查: 结果检查是需要费心去考虑的,因为你没法预知测试集的输入,你也就没法 预先写好测试集的输出, 所以 PBT 逼迫你去深入的理解 逻辑需求,并精心构造出不同的解 题路径,来对结果进行验证。 ○ 错误收敛: 因为 PBT 会自动生成大量的 输入参数,所以自然也会生成众多的 结果,而为了开发人员更方便的找到具有典型 意义的异常数据, PBT 的框架会自 动的对错误集进行收敛,生成尽可能小的异常参数集。 ● 例如:加法的属性。 Detecting Corruption is a Property (发现数据损害是一个属性): Checksum可以发现数据被损 ● More: ○ https://github.com/quicktheories/QuickTheories ○ https://cassandra.apache.org/blog/2018/10/17/finding_bugs_with_property_based_testing.html
29 .如何参与到Cassandra社区中 ● 参与到社区中: ○ Cassandra mailing list ○ ASF Slack ○ 具体请参: https://cassandra.apache.org/community/ ● 参与到项目中: ○ 回答用户问题 ○ 测试 ○ Review代码 ○ 提交补丁 ○ 参与开发新功能 (CEP) ■ https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=95652201 ○ JIRA https://issues.apache.org/jira/projects/CASSANDRA/summary
3秒后跳转登录页面
去登陆

