展开查看详情
1 . Evgeny Shapiro, Varant Zanoyan / Oct 2019 / Airbnb
Zipline: Declarative
Feature Engineering
�
2 . 1. The machine learning workflow
2. The feature engineering problem
3. Zipline as a solution
4. Implementation
Agenda
5. Results
6. Q&A
�
3 . THE MACHINE
LEARNING WORKFLOW
IN PRODUCTION
�
4 . ● Goal: Make a prediction about the world given
incomplete data
● Labels: Prediction Target
● Features: known information to learn from
Machine Learning ● Training output: model weights/parameters
● Serving: online feature
● Assumption: Training and serving distribution is
the same (consistency)
�
5 . ● Goal: Make a prediction about the world given
incomplete data
● Labels: Prediction Target
● Features: known information to learn from
Machine Learning ● Training output: model weights/parameters
● Serving: online feature
● Assumption: Training and serving distribution
is the same (consistency)
�
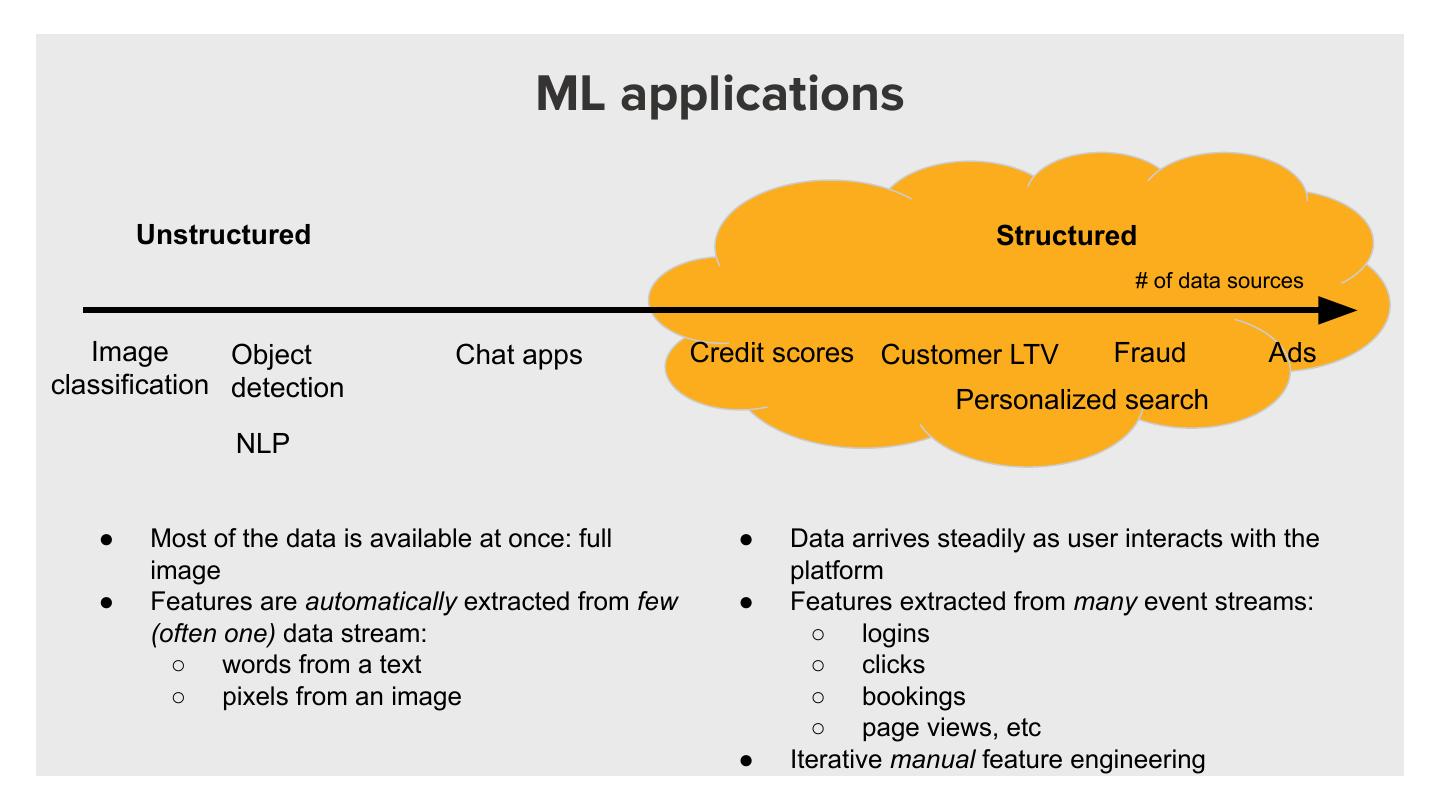
6 . ML applications
Unstructured Structured
# of data sources
Image Object Chat apps Credit scores Customer LTV Fraud Ads
classification detection
Personalized search
NLP
● Most of the data is available at once: full ● Data arrives steadily as user interacts with the
image platform
● Features are automatically extracted from few ● Features extracted from many event streams:
(often one) data stream: ○ logins
○ words from a text ○ clicks
○ pixels from an image ○ bookings
○ page views, etc
● Iterative manual feature engineering
�
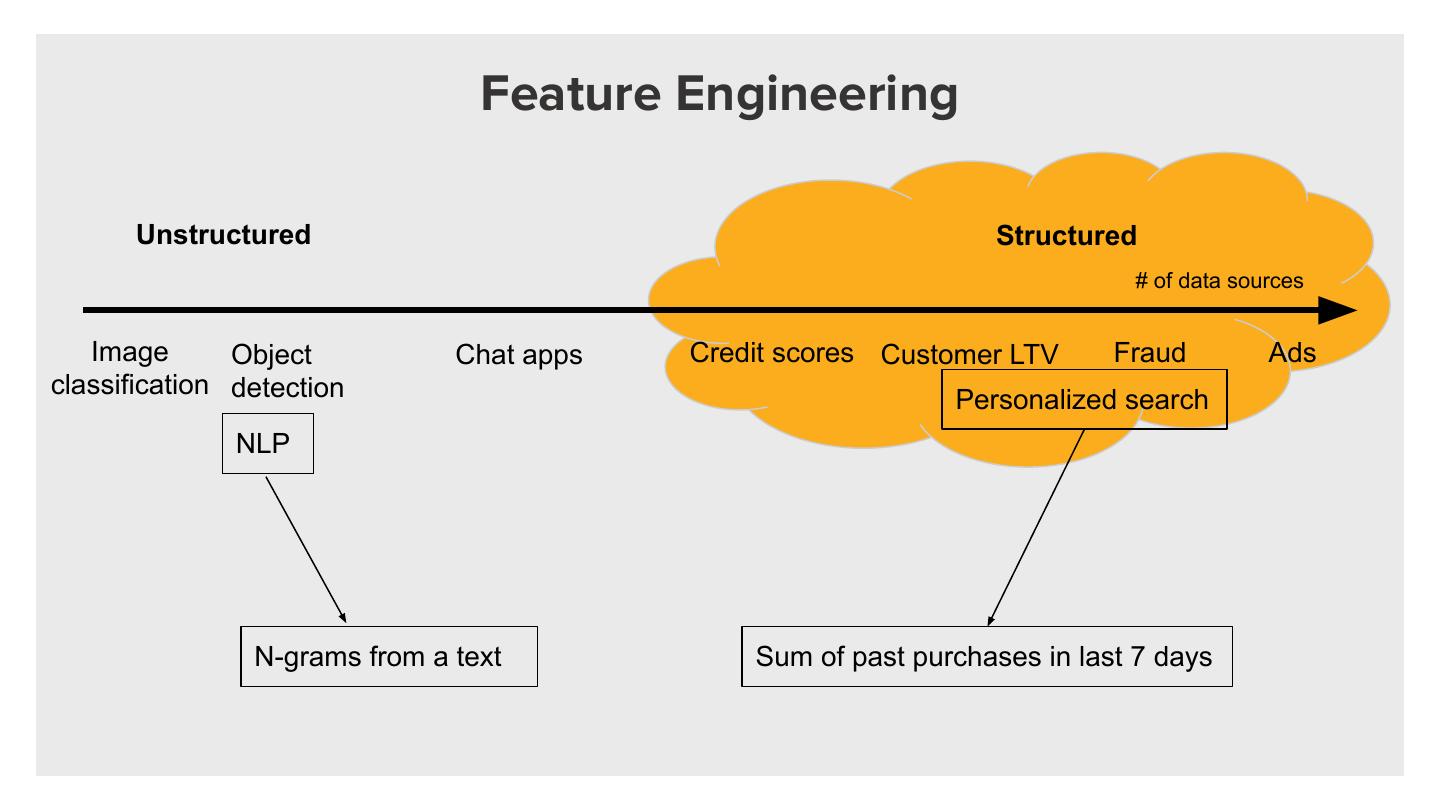
7 . Feature Engineering
Unstructured Structured
# of data sources
Image Object Chat apps Credit scores Customer LTV Fraud Ads
classification detection
Personalized search
NLP
N-grams from a text Sum of past purchases in last 7 days
�
8 . ● Offline Batch (email marketing)
○ Does not require serving feature in
production
○ Online/Offline consistency is not a problem
Offline Batch vs
Online Real-time ● Online Real-time (personalized search)
○ Does require serving feature in production
○ Online/Offline consistency is a problem
�
9 . Feature engineering
For the structured online
use case
�
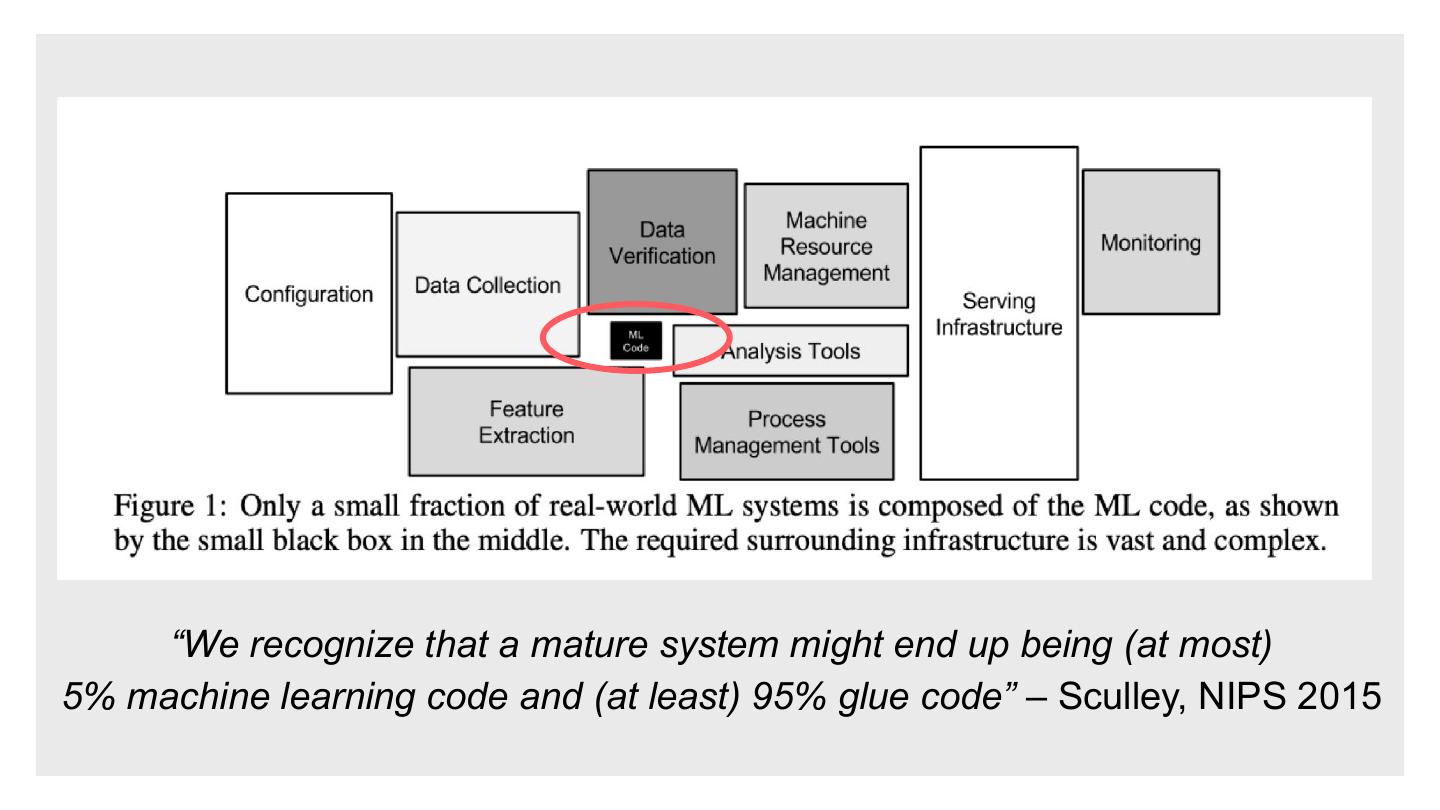
10 . “We recognize that a mature system might end up being (at most)
5% machine learning code and (at least) 95% glue code” – Sculley, NIPS 2015
�
11 . ML Models
Feature values Training data set
User behavior & business processes
F1 0 5 7 4 7
F2 3 2 4 3
Product
Pred P1
Problem
Label L L
Time
�
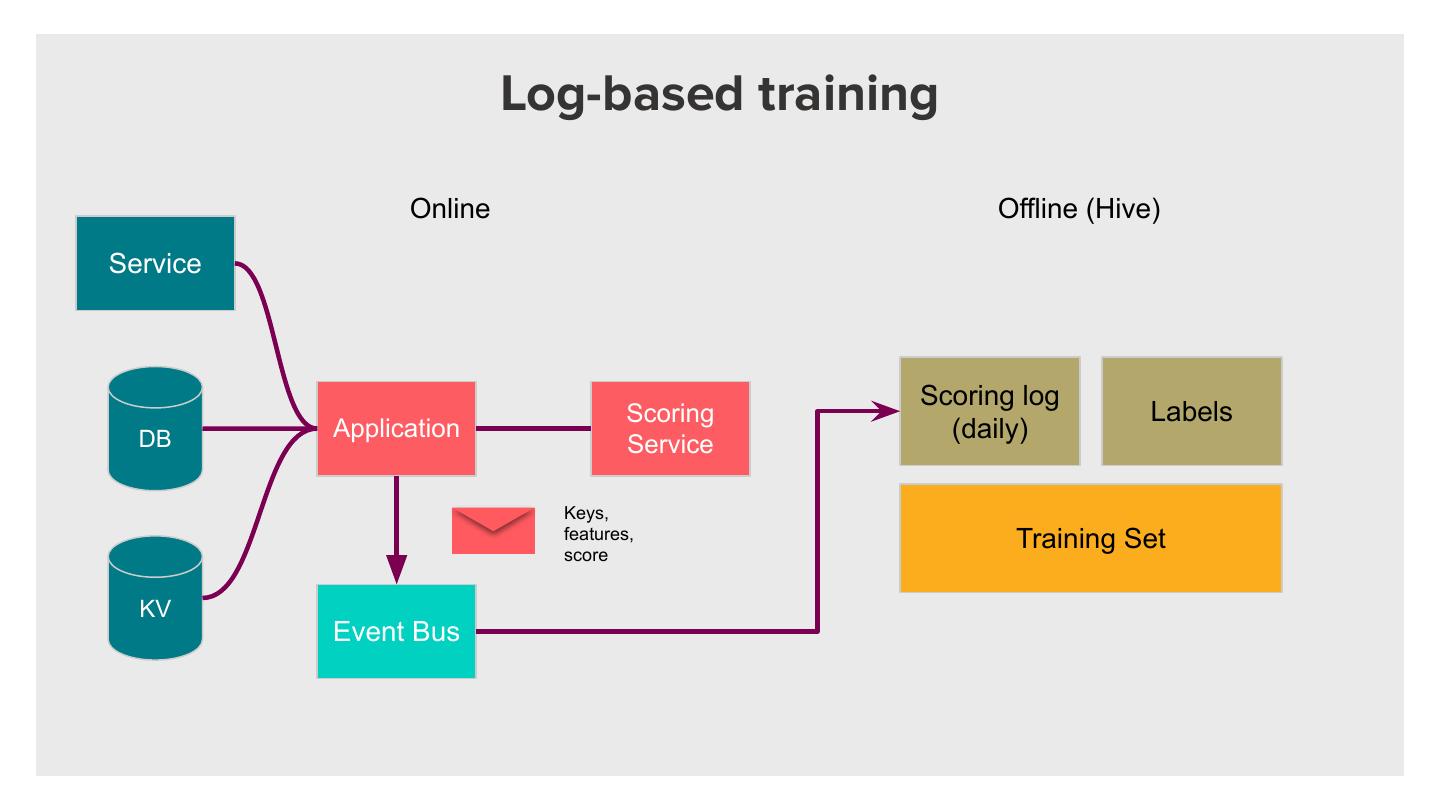
12 . Log-based training
Online Offline (Hive)
Service
Scoring log
Scoring Labels
DB Application (daily)
Service
Keys,
features, Training Set
score
KV
Event Bus
�
13 . ● Easy to implement
● Any production-available data point can be used
Log-based training for training and scoring
is great † ● Log can be used for audit and debug purposes
● Consistency is guaranteed
† May capture accidental data distribution shifts, requires upfront implementation of new features in production, may slow
down feature iteration cycle, prevents feature sharing between models, increases product experimentation cycle, severely
limits your ability to react to incidents, fixing production issues might degrade model performance, may decrease sleep
time during on-call rotations. Consult with your architect before taking log-based training approach.
�
14 . ● Sharing features is hard
● Testing new features requires production
implementation
The Fine Print up
close ● May capture accidental data shifts (bugs,
downed services)
● Slows down the iteration cycle
● Limits agility in reacting to production incidents
�
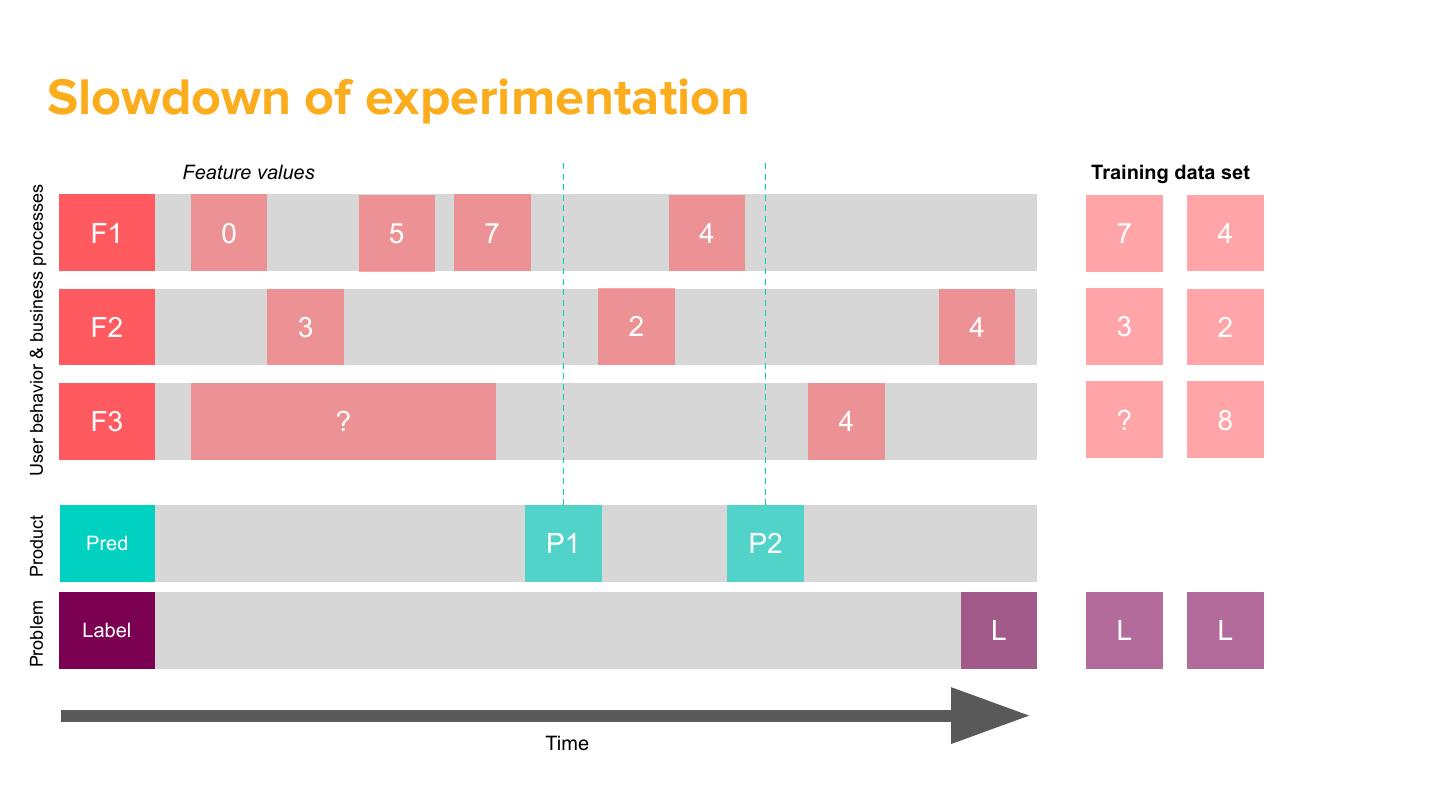
15 . Slowdown of experimentation
Feature values Training data set
User behavior & business processes
F1 0 5 7 4 7 4
F2 3 2 4 3 2
F3 ? 4 ? 8
Product
Pred P1 P2
Problem
Label L L L
Time
�
16 . ● Some models are time-dependent (seasonality)
● For some problems label maturity is on the order
of months
Why is that a
problem? ● Production incidents lead to dirty data in training
● Labels are scarce and expensive to acquire
→ Months-long iteration cycles
→ Hard to maintain models in production
→ Cannot address shifts in data quickly
�
17 . ● Backfill features
○ Quick!
● Single feature definition for production and
What do we want? training
● Automatic pipelines for training and scoring
�
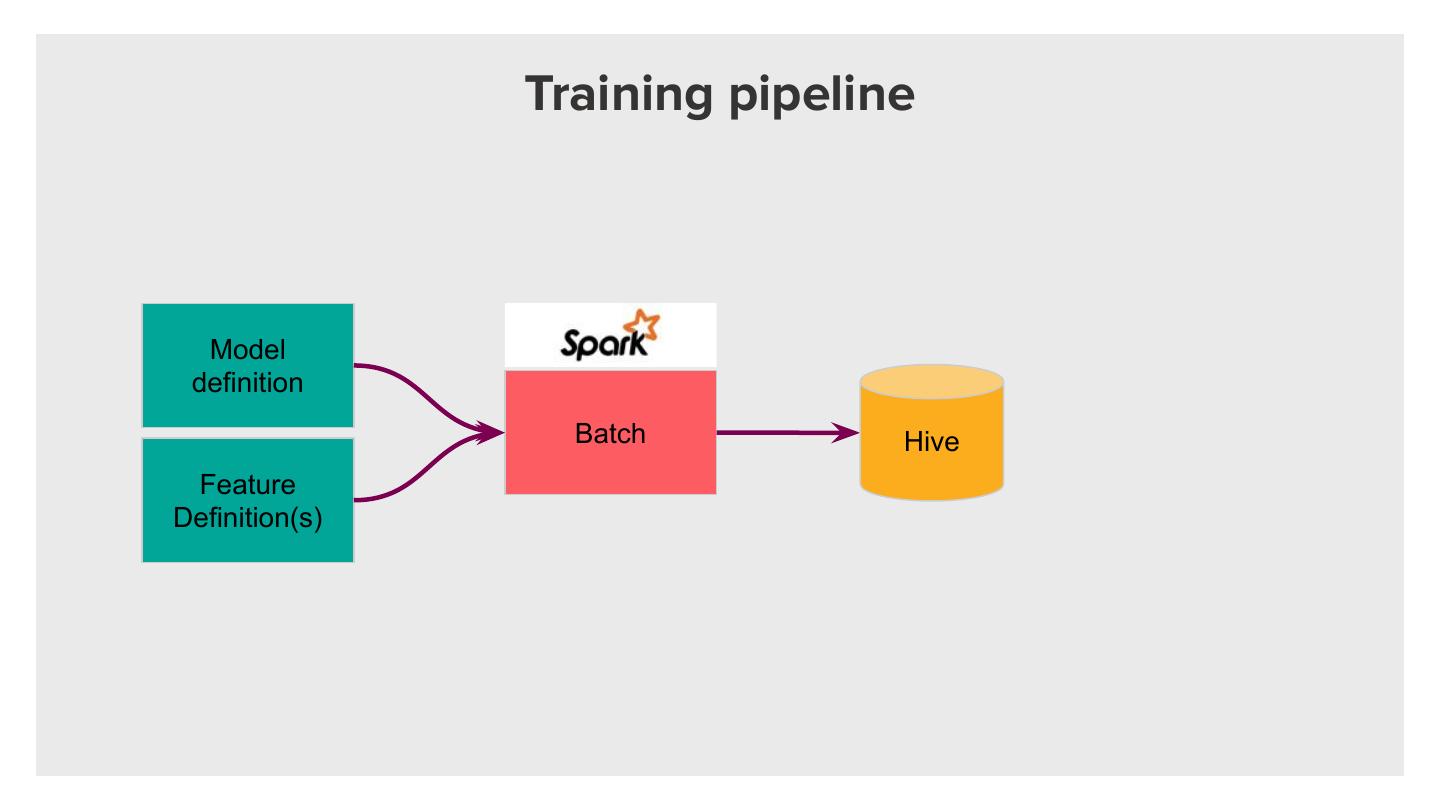
19 . Zipline: feature management system
Fast Backfills - Data Warehouse
Training Model
Pipeline Training Set
Feature
Definition Consistency
Serving Online Scoring
Pipeline Vector
Low Latency Serving - Online Environment
�
21 .Training Set API
The time at which we
made the prediction,
also the time at which
we would log the feature
�
23 . If you missed it...
Training set = f(features,
keys, timestamps)
�
25 . ● Complex features:
○ Only worth it if the gain is huge
○ Require complex computations
○ Harder to interpret
○ Harder to maintain
Feature philosophy
● Simple features:
○ Easier to maintain
○ Faster to compute
○ Cumulatively provide huge gain for the
model
�
26 . ● Sum, Count
● Min, Max
● First, Last
Supported ● Last N
operations
● Statistical moments
● Approx unique count
● Approx percentile
● Bloom filters
+ time windows for all operations!
�
27 . ● Commutative: a ⊕ b = b ⊕ a
● Associative: (a ⊕ b) ⊕ c = a ⊕ (b ⊕ c)
Operation
● Additional optimizations:
requirements
○ Reversible: a ⊕ ? = c
● Must be O(1) in compute ⇒ must be O(1) in space
�
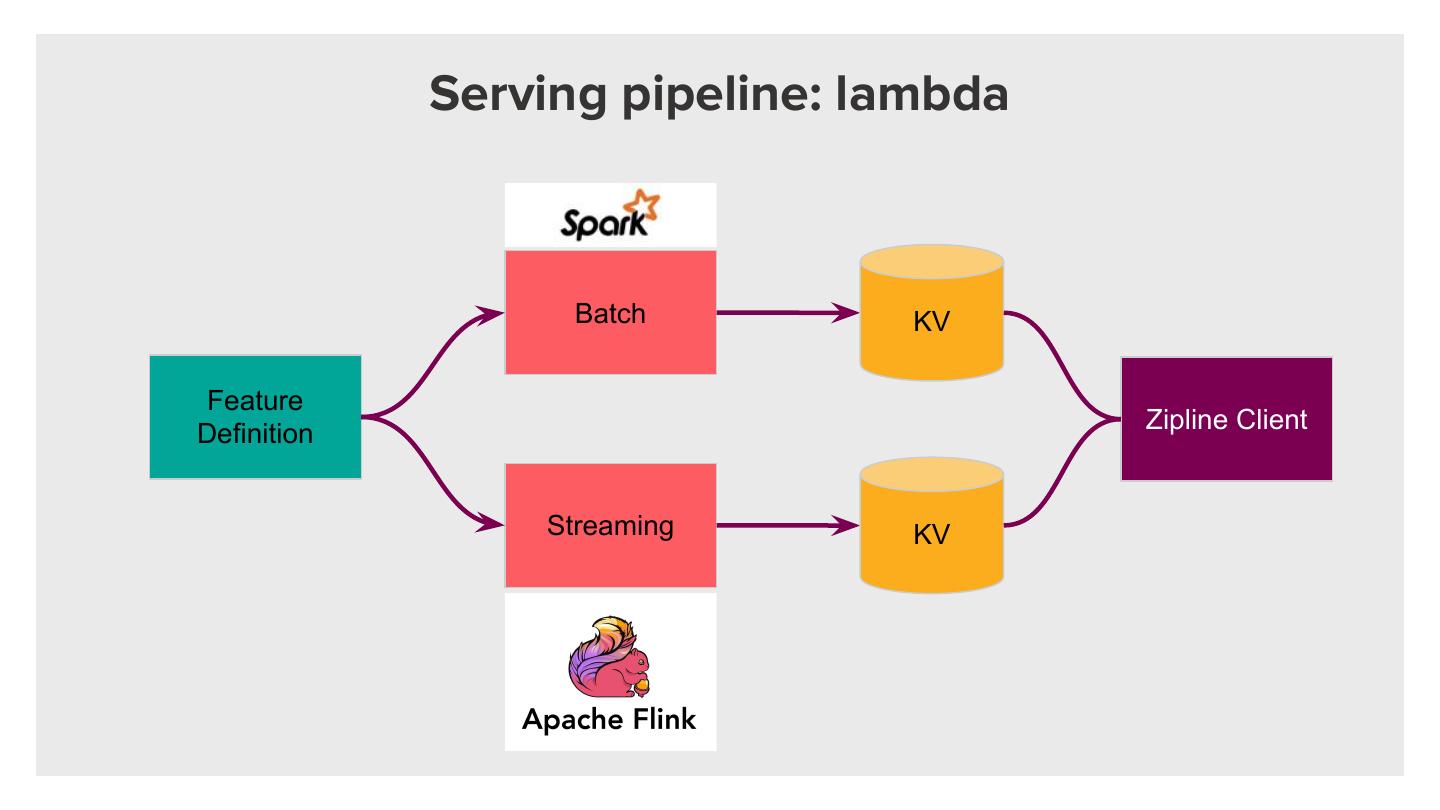
28 . Serving pipeline: lambda
Batch KV
Feature
Zipline Client
Definition
Streaming KV
�
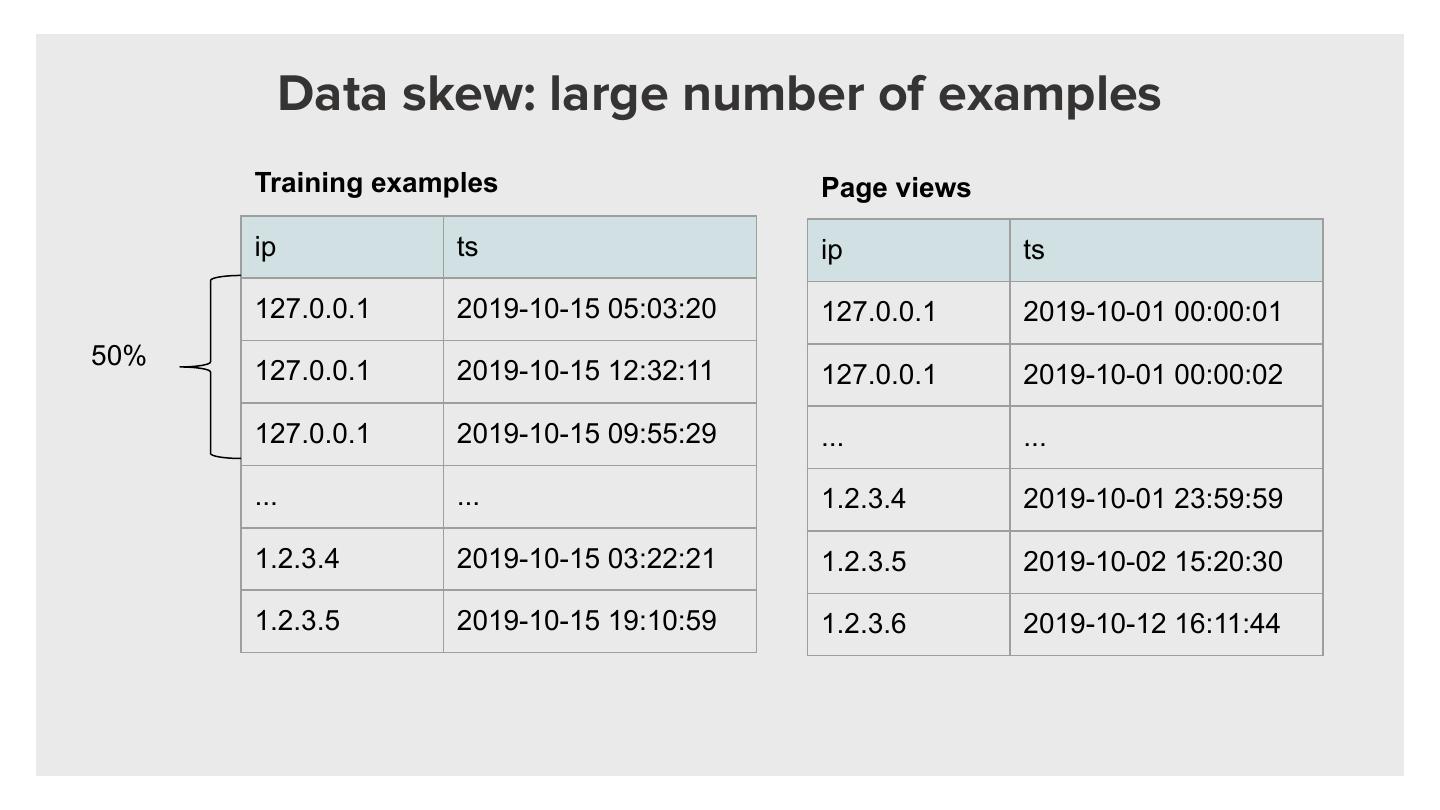
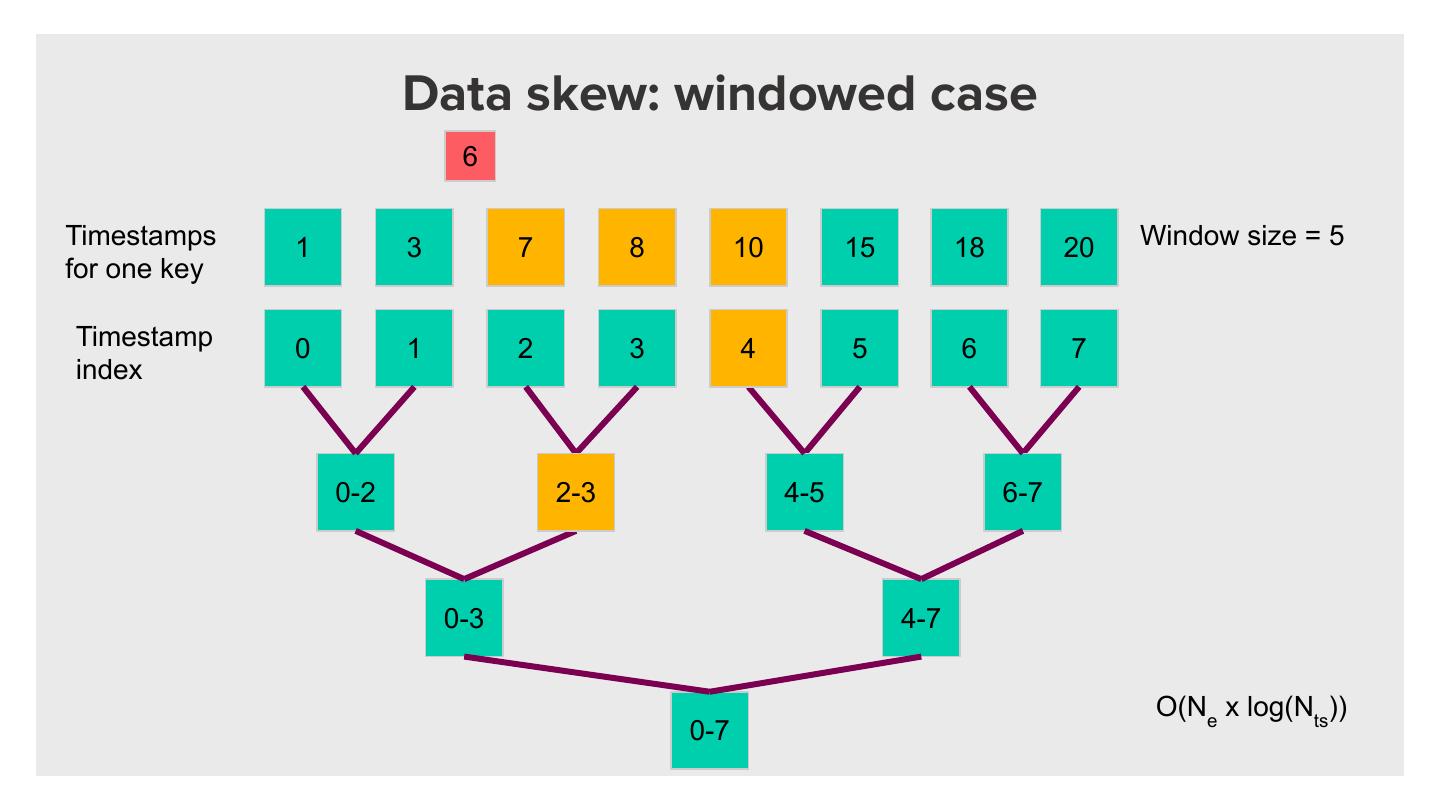
29 . Data skew: large number of events
Page views
user ts
1 2019-10-01 00:00:01
1 2019-10-01 00:00:02
50%
... ...
1 2019-10-01 23:59:59
2 2019-10-02 15:20:30
3 2019-10-12 16:11:44
Use aggregateByKey to ensure data is locally combined on the first stage before
sent final merge
�