展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Working with Complex
Types in DataFrames:
Optics to the Rescue
Alfonso Roa, Habla Computing
#UnifiedDataAnalytics #SparkAISummit
�
3 .Who am I
Alfonso Roa
● Scala 👍
● Spark 👍
● Functional Programing 👍
● Open source (what i can) 👍
● Big data 👍
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Where I work
info@hablapps.com
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Agenda
(Live code session)
• The problem working with complex types
• How to solve it in a no Spark world
• How to solve it in a Spark world
• …
• Profits
5
�
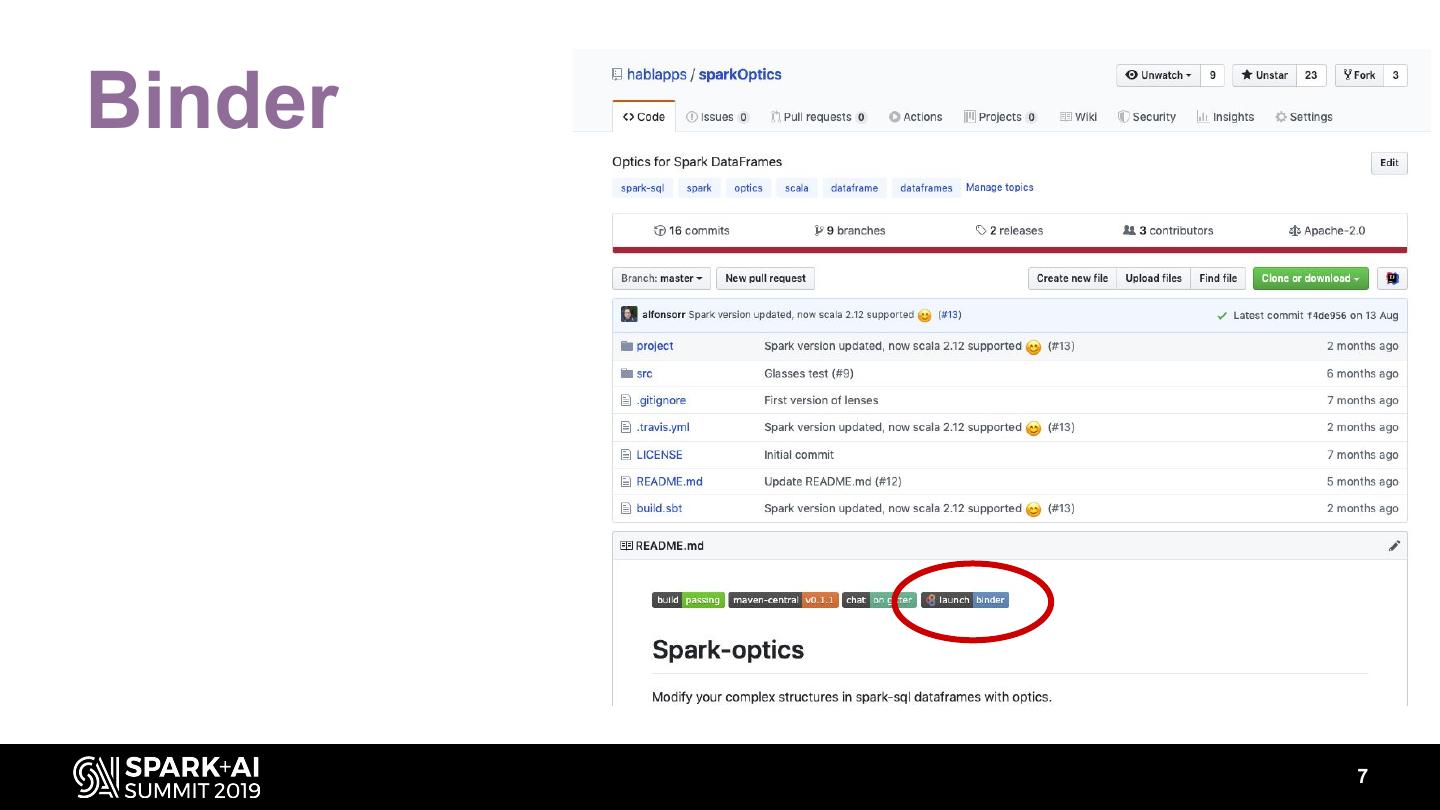
6 .Notebook used
Spark optics
https://github.com/hablapps/sparkOptics
#UnifiedDataAnalytics #SparkAISummit 6
�
8 .Complex types are complex
case class Street(number: Int, name: String)
case class Address(city: String, street: Street)
case class Company(name: String, address: Address)
case class Employee(name: String, company: Company)
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Our example for the talk
val employee =
Employee("john",
Company("awesome inc",
Address("london",
Street(23, "high street")
)))
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .How we see it in DF’s
+----+--------------------+
|name| company|
+----+--------------------+
|john|[awesome inc, [lo...|
+----+--------------------+
import sparkSession.implicits._ root
val df = List(employee).toDF |-- name: string (nullable = true)
|-- company: struct (nullable = true)
df.show
| |-- name: string (nullable = true)
df.printSchema | |-- address: struct (nullable = true)
| | |-- city: string (nullable = true)
| | |-- street: struct (nullable = true)
| | | |-- number: integer (nullable = false)
| | | |-- name: string (nullable = true)
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .Changes in DF
val employeeNameChanged = df.select(
concat(df("name"),lit("!!!")).as("name")
,
df("company")
)
employeeNameChanged.show +-------+--------------------+
employeeNameChanged.printSchema | name| company|
+-------+--------------------+
|john!!!|[awesome inc, [lo...|
+-------+--------------------+
root
|-- name: string (nullable = true)
|-- company: struct (nullable = true)
| ...
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Changes in complex structs
val companyNameChanged = df.select(
df("name"),
struct(
concat(df("company.name"),lit("!!!")).as("name"),
df("company.address")
).as("company")
)
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Even more complex structs
df.select(df("name"),struct(
df("company.name").as("name"),
struct(
df("company.address.city").as("city"),
struct(
df("company.address.street.number").as("number"),
upper(df("company.address.street.name")).as("name")
).as("street")
).as("address")
).as("company"))
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .How this is made with case class
Employee(
"john!!!",
employee.copy(name = employee.name+"!!!") Company("awesome inc", Address("london", Street(23,
"high street")))
)
employee.copy(company =
Employee(
employee.company.copy(name = "john",
employee.company.name+"!!!") Company("awesome inc!!!", Address("london",
) Street(23, "high street")))
)
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .Immutability is hard
Very similar...
BUT WE HAVE OPTICS!
Monocle
Scala optics library
https://julien-truffaut.github.io/Monocle/
#UnifiedDataAnalytics #SparkAISummit 15
�
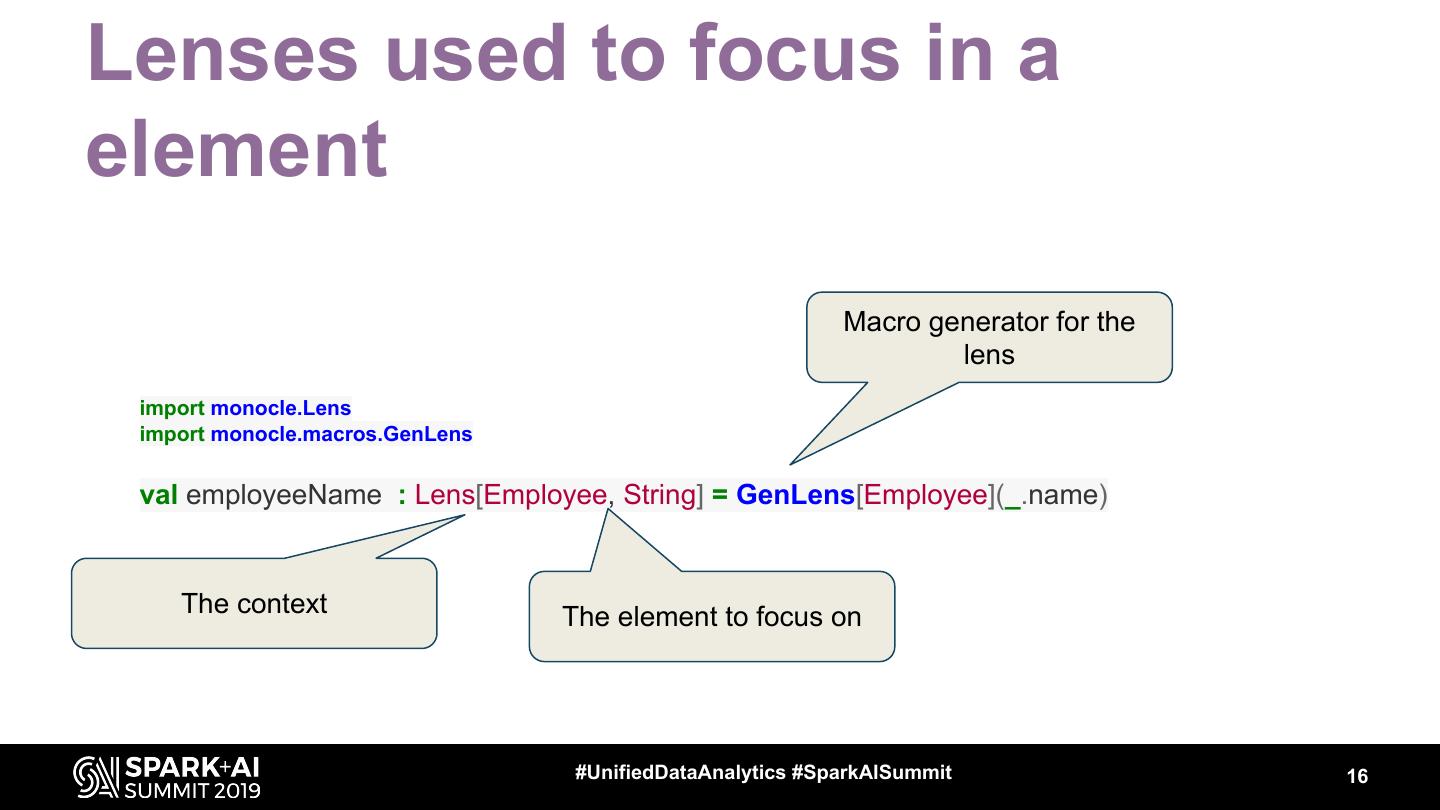
16 .Lenses used to focus in a
element
Macro generator for the
lens
import monocle.Lens
import monocle.macros.GenLens
val employeeName : Lens[Employee, String] = GenLens[Employee](_.name)
The context The element to focus on
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Lenses used to focus in a
element
employeeName.get(employee) returns "john"
Employee(
val f: Employee => Employee = "James",
employeeName.set(“James”) Company("awesome inc", Address("london",
f(employee) Street(23, "high street")))
)
Employee(
val f: Employee => Employee = "john!!!",
employeeName.modify(a => a + “!!!”) Company("awesome inc", Address("london",
f(employee) Street(23, "high street")))
)
#UnifiedDataAnalytics #SparkAISummit 17
�
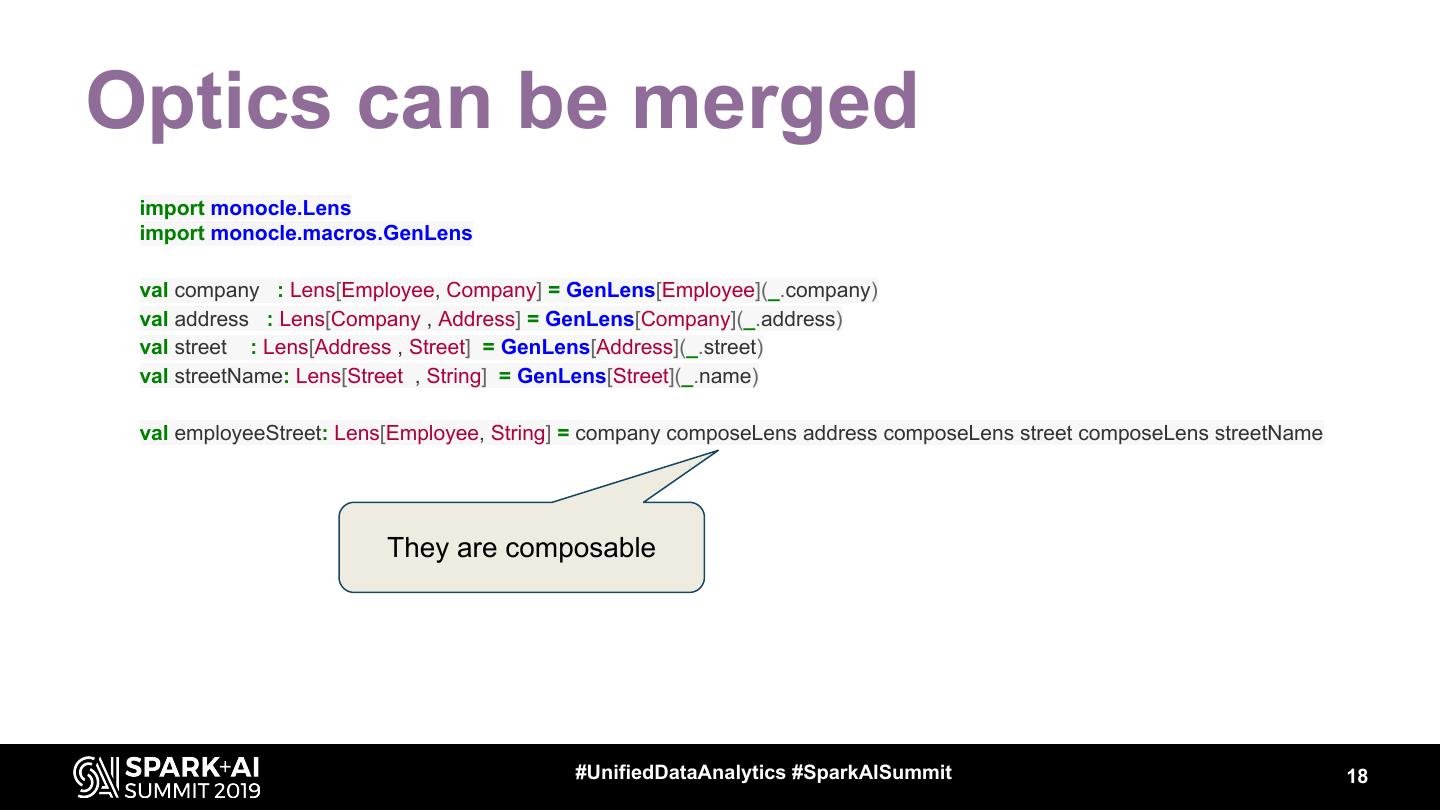
18 .Optics can be merged
import monocle.Lens
import monocle.macros.GenLens
val company : Lens[Employee, Company] = GenLens[Employee](_.company)
val address : Lens[Company , Address] = GenLens[Company](_.address)
val street : Lens[Address , Street] = GenLens[Address](_.street)
val streetName: Lens[Street , String] = GenLens[Street](_.name)
val employeeStreet: Lens[Employee, String] = company composeLens address composeLens street composeLens streetName
They are composable
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Functionality
val streetChanger:Employee => Employee = employeeStreet.modify(_ + "!!!")
streetChanger(employee)
Employee(
"john",
Company("awesome inc", Address("london", Street(23, "high street!!!")))
)
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .How lucky they are
So easy
Wish there was something
like this for spark dataframes…
Spark optics!
https://github.com/hablapps/sparkOptics
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Similar to typed optics
import org.hablapps.sparkOptics.Lens
import org.hablapps.sparkOptics.syntax._
val lens = Lens("name")(df.schema)
The element to focus on The context
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .Same methods, included modify
val lens = Lens("name")(df.schema)
val column: Column = lens.get(df)
val transformedDF = df.select(lens.modify(c =>
concat(c,lit("!!!"))):_*)
transformedDF.printSchema
transformedDF.as[Employee].head
(Column => Column) => Array[Columns]
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Same methods, included modify
root
|-- name: string (nullable = true)
|-- company: struct (nullable = false)
| |-- name: string (nullable = true)
| |-- address: struct (nullable = false)
| | |-- city: string (nullable = true)
| | |-- street: struct (nullable = false)
| | | |-- number: integer (nullable = true)
| | | |-- name: string (nullable = true)
Employee(
"john!!!",
Company("awesome inc", Address("london", Street(23, "high street")))
)
23
�
24 .Creating the lenses
But not as easy as the Typed optics to get the
context in inner elements. Get the schema of the inner
element
import org.apache.spark.sql.types.StructType
val companyL: Lens = Lens("company")(df.schema)
val companySchema = df.schema.fields.find(_.name == "company").get.dataType.asInstanceOf[StructType]
val addressL = Lens("address")(companySchema)
val addressSchema = companySchema.fields.find(_.name == "address").get.dataType.asInstanceOf[StructType]
val streetL = Lens("street")(addressSchema)
val streetSchema = addressSchema.fields.find(_.name == "street").get.dataType.asInstanceOf[StructType]
val streetNameL = Lens("name")(streetSchema)
And again and again… 😔
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .Composable
But they are still composable
val employeeCompanyStreetName =
companyL composeLens addressL composeLens streetL composeLens streetNameL
val modifiedDF = df.select(employeeCompanyStreetName.set(lit("new street
name")):_*)
modifiedDF.as[Employee].head
Employee(
"john",
Company("awesome inc", Address("london", Street(23, "new street name")))
)
#UnifiedDataAnalytics #SparkAISummit 25
�
26 .Creating easier lenses
Intro the proto lens, a lens without context (yet)
val companyL: Lens = Lens("company")(df.schema)
Checks that the schema of companyL has
the address element, or it will throw an error
val addressProtolens: ProtoLens = Lens("address")
val composedLens: Lens = companyL composeProtoLens addressProtolens
val composedLens: ProtoLens = Lens("a") composeProtoLens Lens("b")
No schema in any element?
Still a valid protolens
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Sugar in composition
Similar syntax to spark sql
val sweetLens = Lens("company.address.street.name")(df.schema)
val sourLens = Lens("company")(df.schema) composeProtoLens
Lens("address") composeProtoLens
Lens("street") composeProtoLens
Lens("name")
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .Comparation
val flashLens = Lens("company.address.street.name")(df.schema)
val modifiedDF = df.select(flashLens.modify(upper):_*)
Much better than
val mDF = df.select(df("name"),struct(
df("company.name").as("name"),
struct(
df("company.address.city").as("city"),
struct(
df("company.address.street.number").as("number"),
upper(df("company.address.street.name")).as("name")
).as("street")
).as("address")
).as("company"))
And lenses function are reusable
#UnifiedDataAnalytics #SparkAISummit 28
�
29 .Extra functionality
Schema changing functions
#UnifiedDataAnalytics #SparkAISummit 29
�