展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Updates from Project Hydrogen: Unifying
State-of-the-Art AI and Big Data in Apache Spark
Xingbo Jiang, Databricks
#UnifiedDataAnalytics #SparkAISummit
�
3 .About Me
• Software Engineer at
• Committer of Apache Spark
Xingbo Jiang (Github: jiangxb1987)
�
4 .About Project Hydrogen
Announced last June, Project Hydrogen is a major Spark initiative
to unify state-of-the-art AI and big data workloads.
Barrier Optimized Accelerator
Execution Data Aware
Mode Exchange Scheduling
4
�
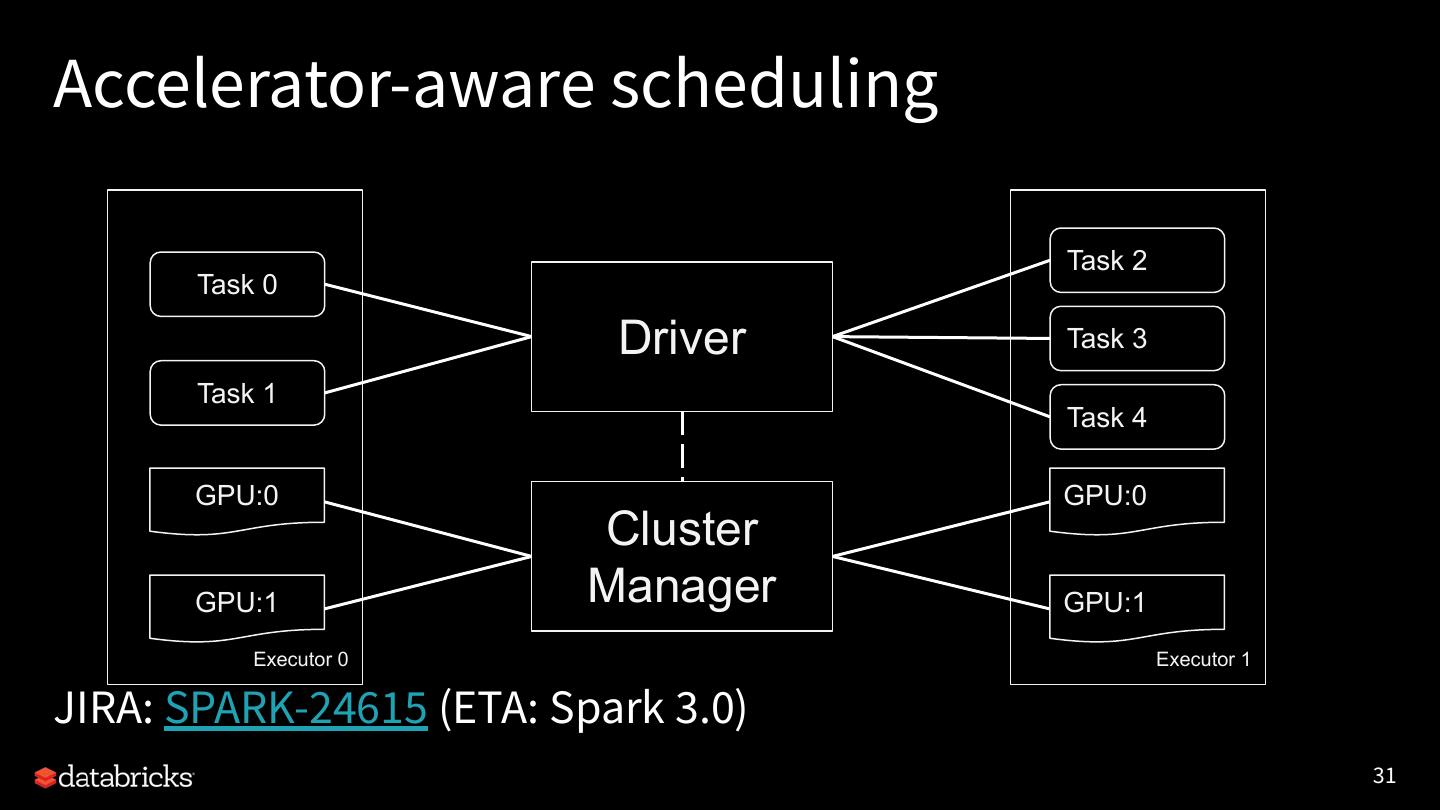
6 . Apache Spark:
The First Unified Analytics Engine
Runtime
Delta
Spark Core Engine
Big Data Processing Machine Learning
ETL + SQL +Streaming MLlib + SparkR
6
�
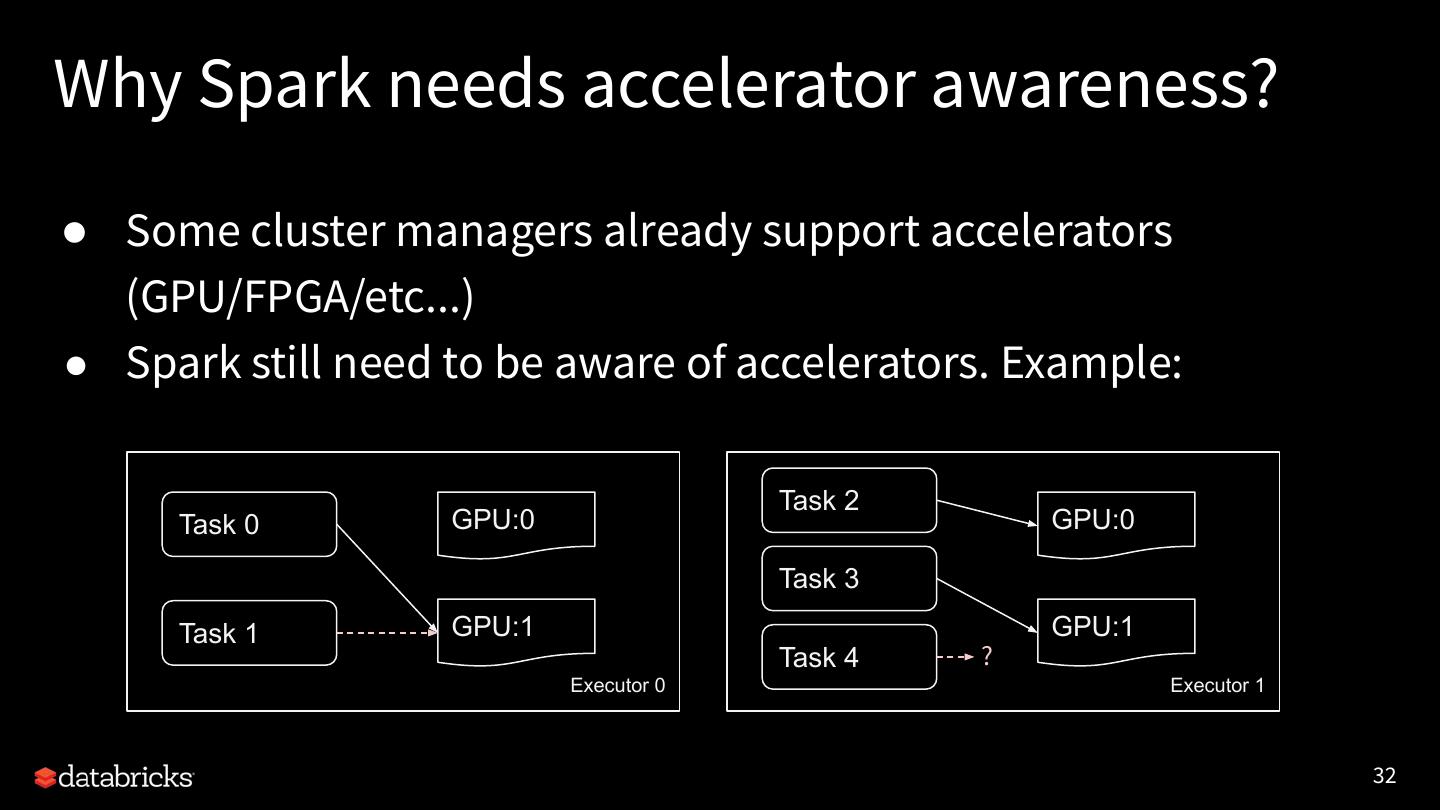
7 .AI is re-shaping the world
Huge disruptive innovations are affecting most enterprises on the planet
Healthcare and Genomics Fraud Prevention Digital Personalization Internet of Things
and many more...
7
�
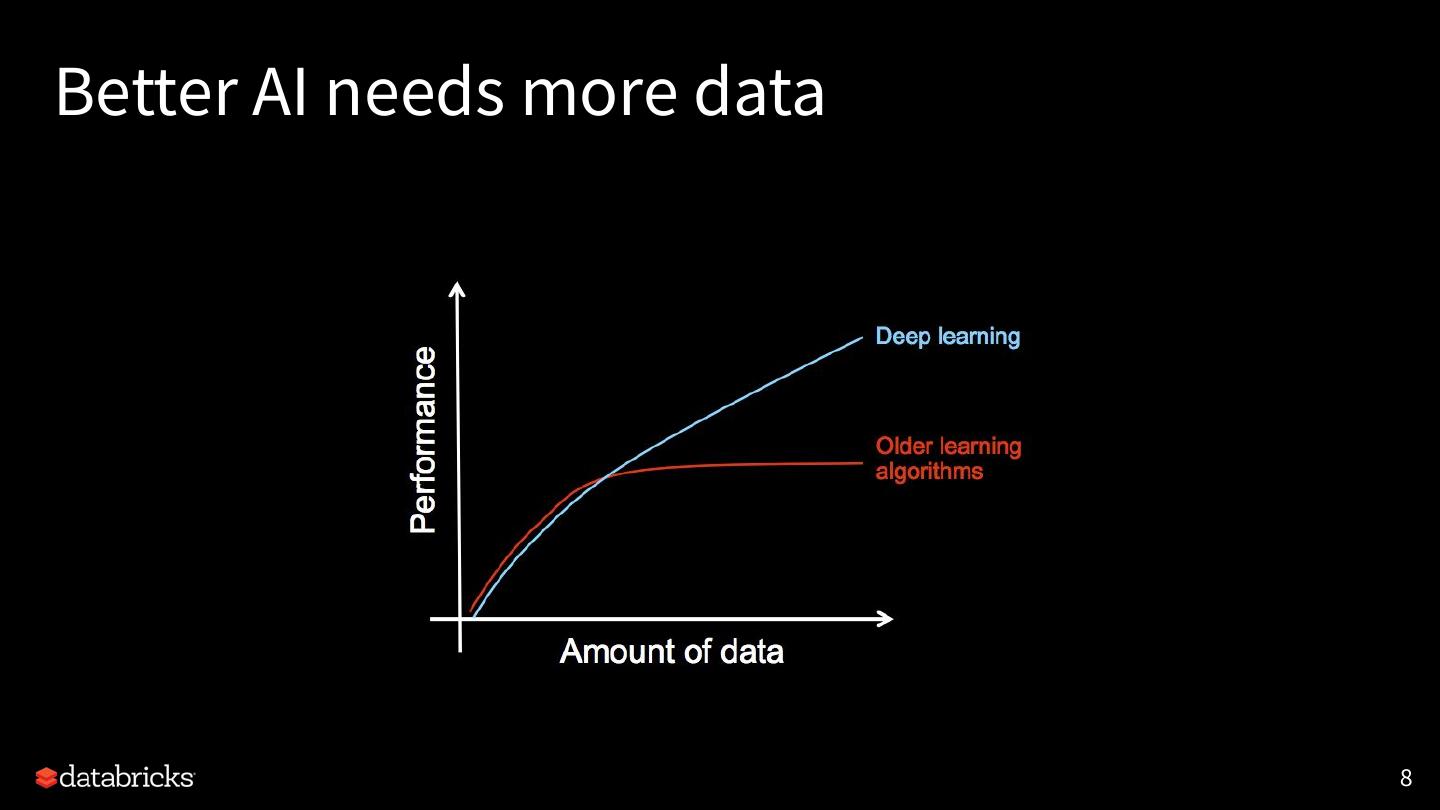
8 .Better AI needs more data
8
�
9 .The cross... ??
Continuous Horovod
Processing
Distributed
Pandas UDF TensorFlow
Structured Streaming tf.data
tf.transform
Keras
TF XLA
AI/ML
Project Tungsten TensorFlow
TensorFrames
ML Pipelines API Caffe/PyTorch/MXNet
TensorFlowOnSpark
GraphLab
50+ Data Sources xgboost
CaffeOnSpark
scikit-learn
DataFrame-based APIs
LIBLINEAR glmnet
Python/Java/R interfaces
Map/Reduce RDD pandas/numpy/scipy R
9
�
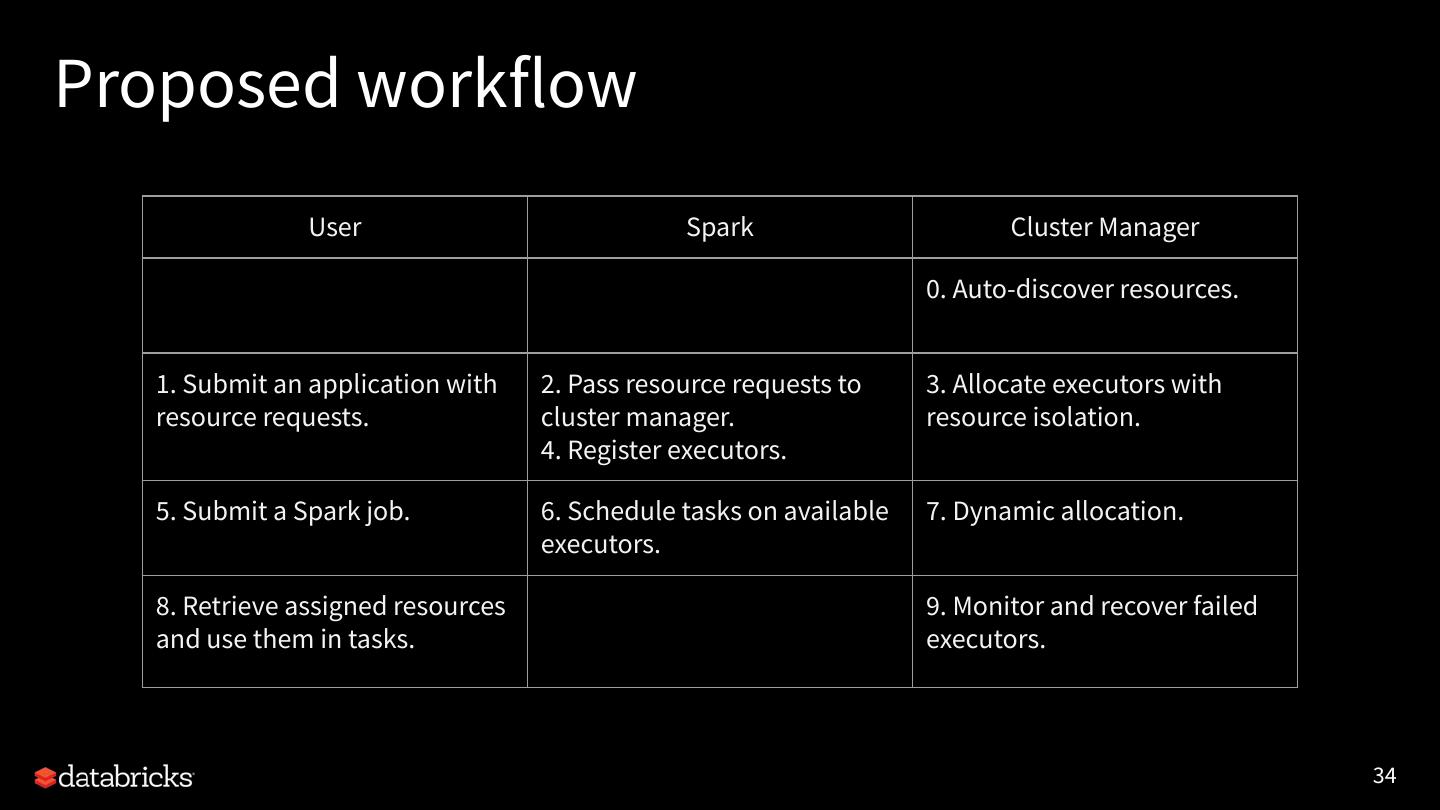
10 .Why Project Hydrogen?
10
�
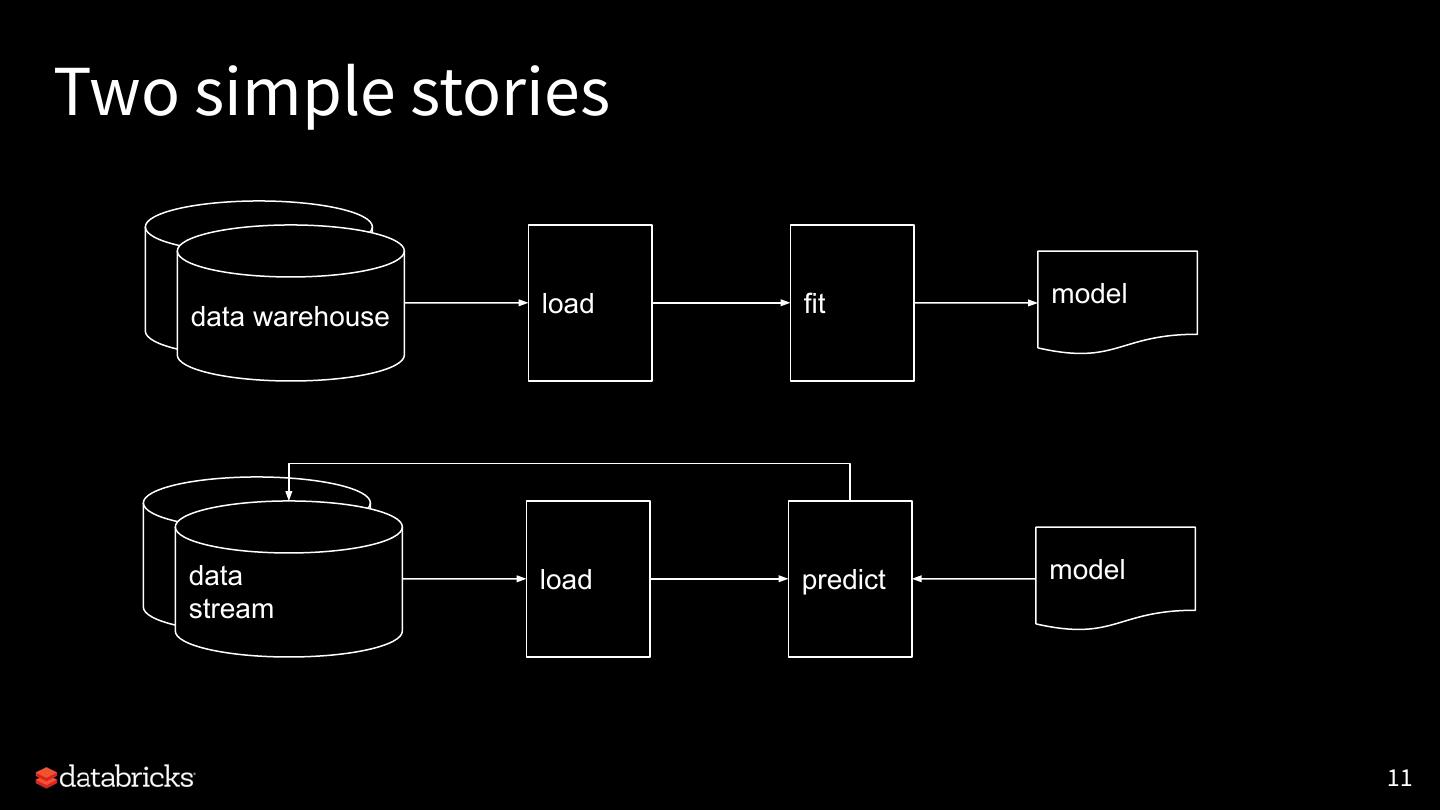
11 .Two simple stories
load fit model
data warehouse
data load predict model
stream
11
�
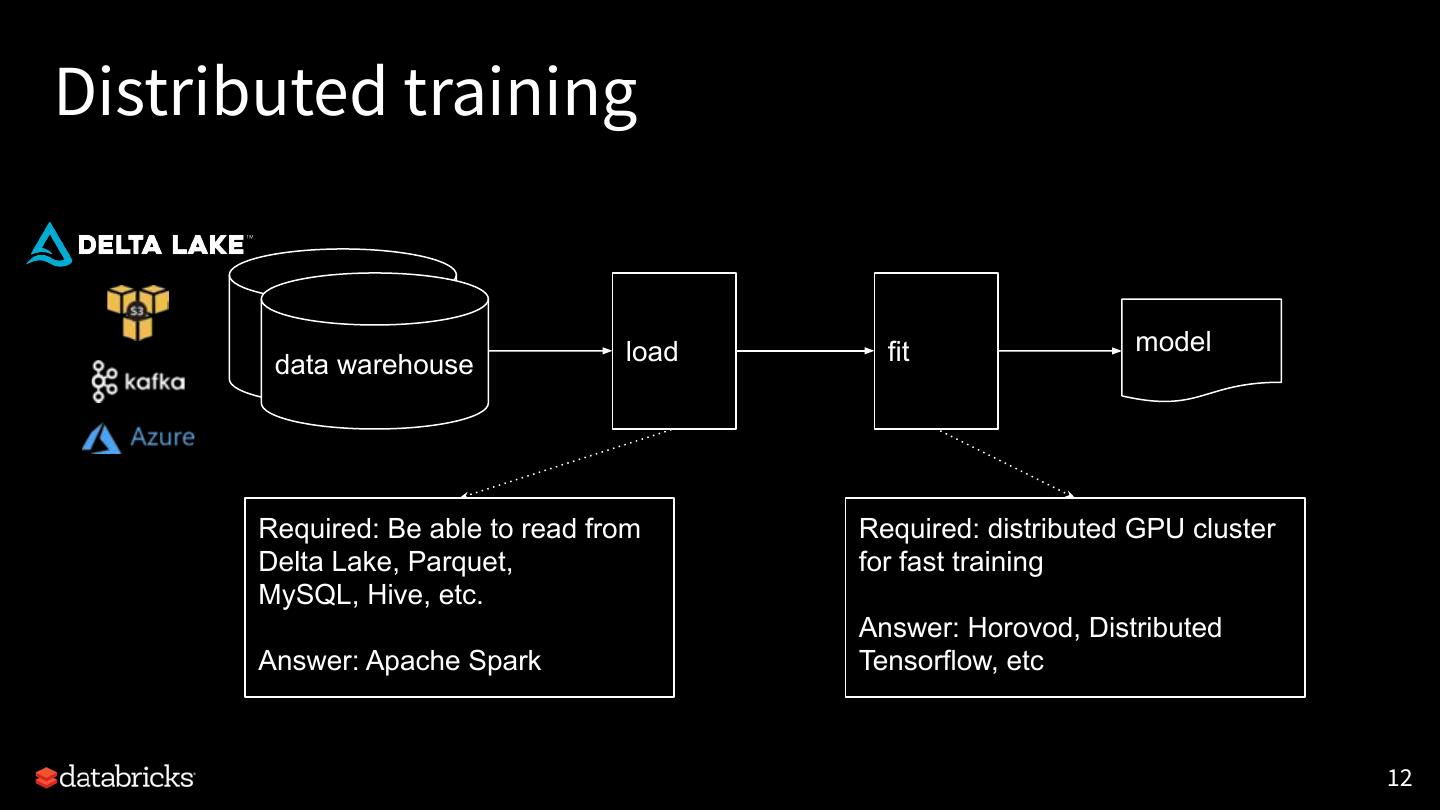
12 .Distributed training
load fit model
data warehouse
Required: Be able to read from Required: distributed GPU cluster
Delta Lake, Parquet, for fast training
MySQL, Hive, etc.
Answer: Horovod, Distributed
Answer: Apache Spark Tensorflow, etc
12
�
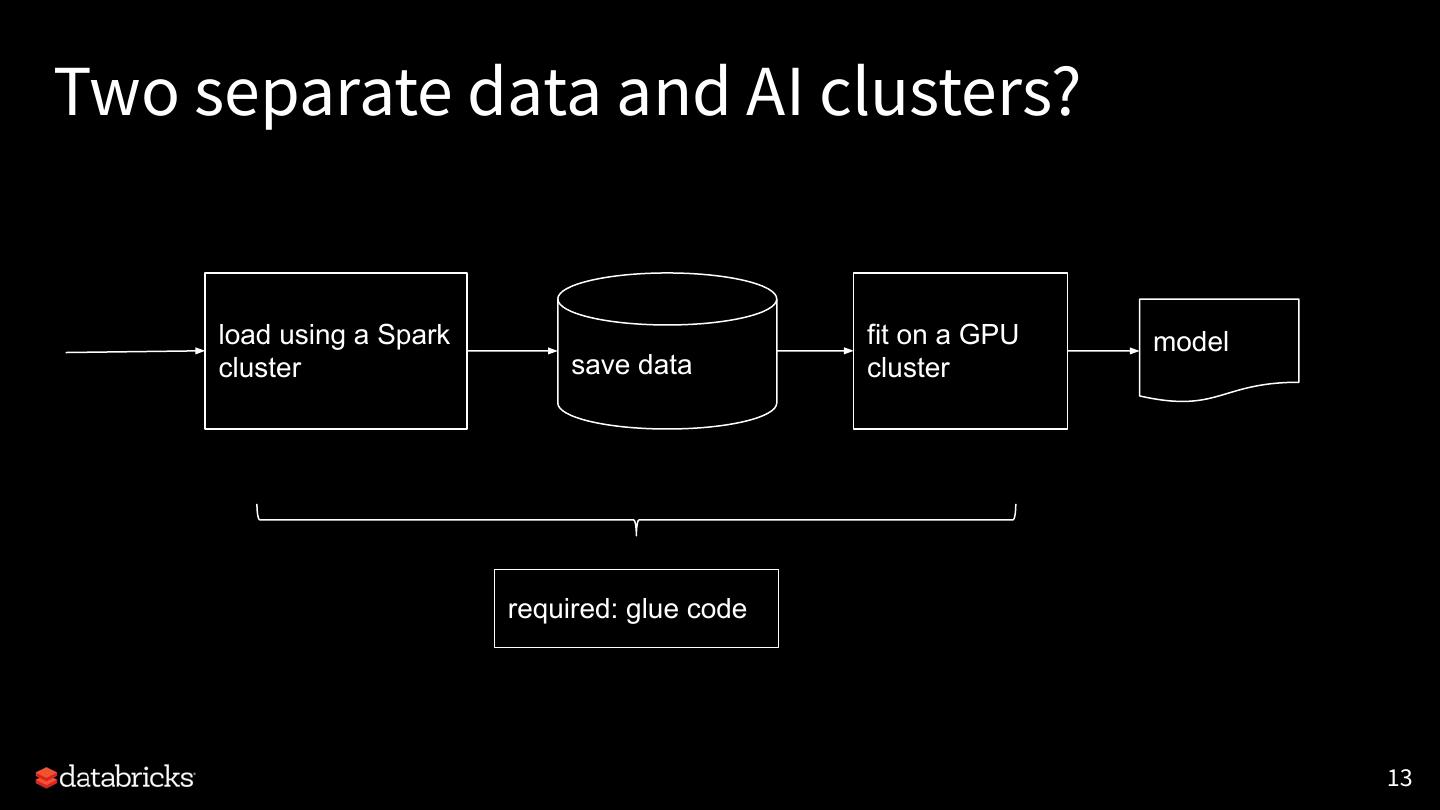
13 .Two separate data and AI clusters?
load using a Spark fit on a GPU model
cluster save data cluster
required: glue code
13
�
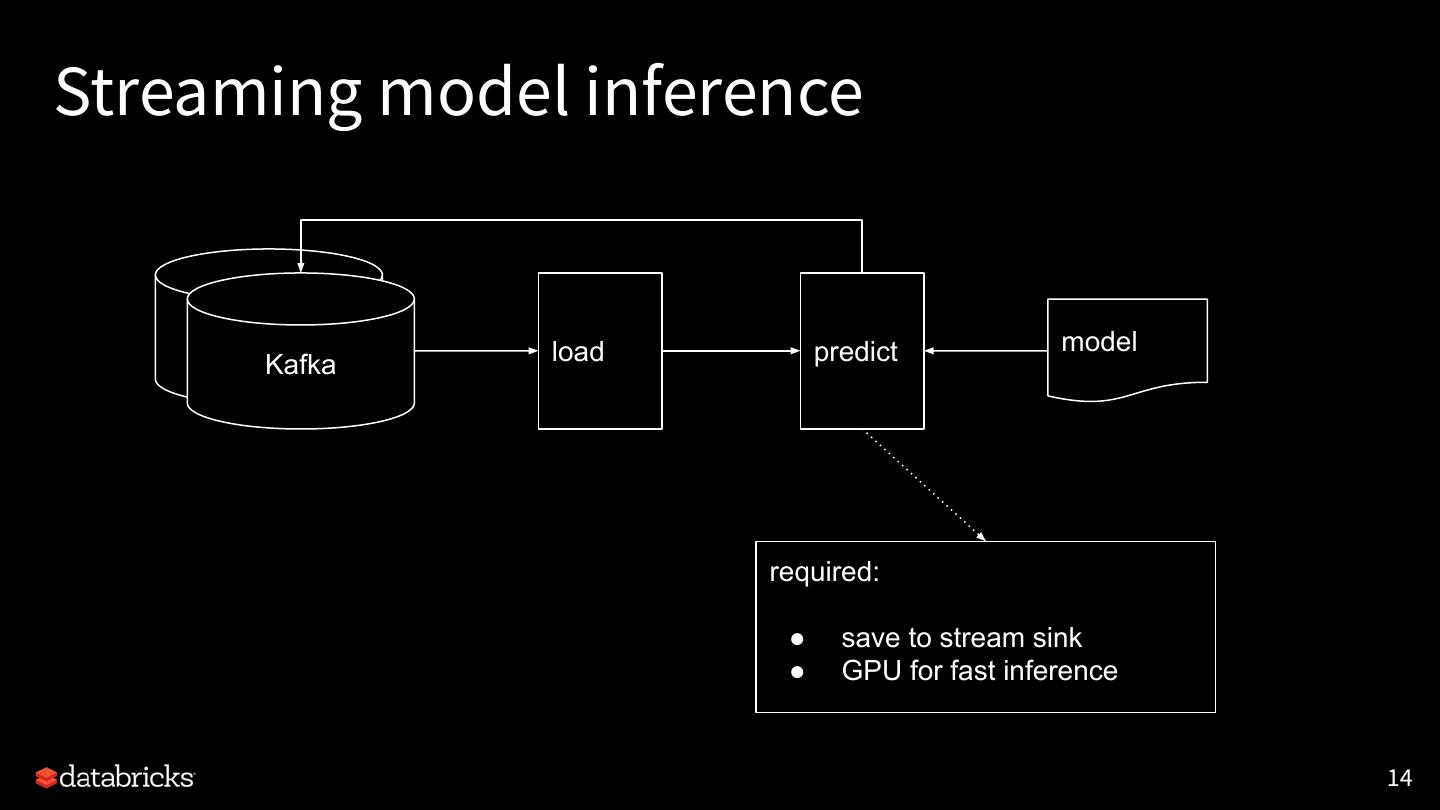
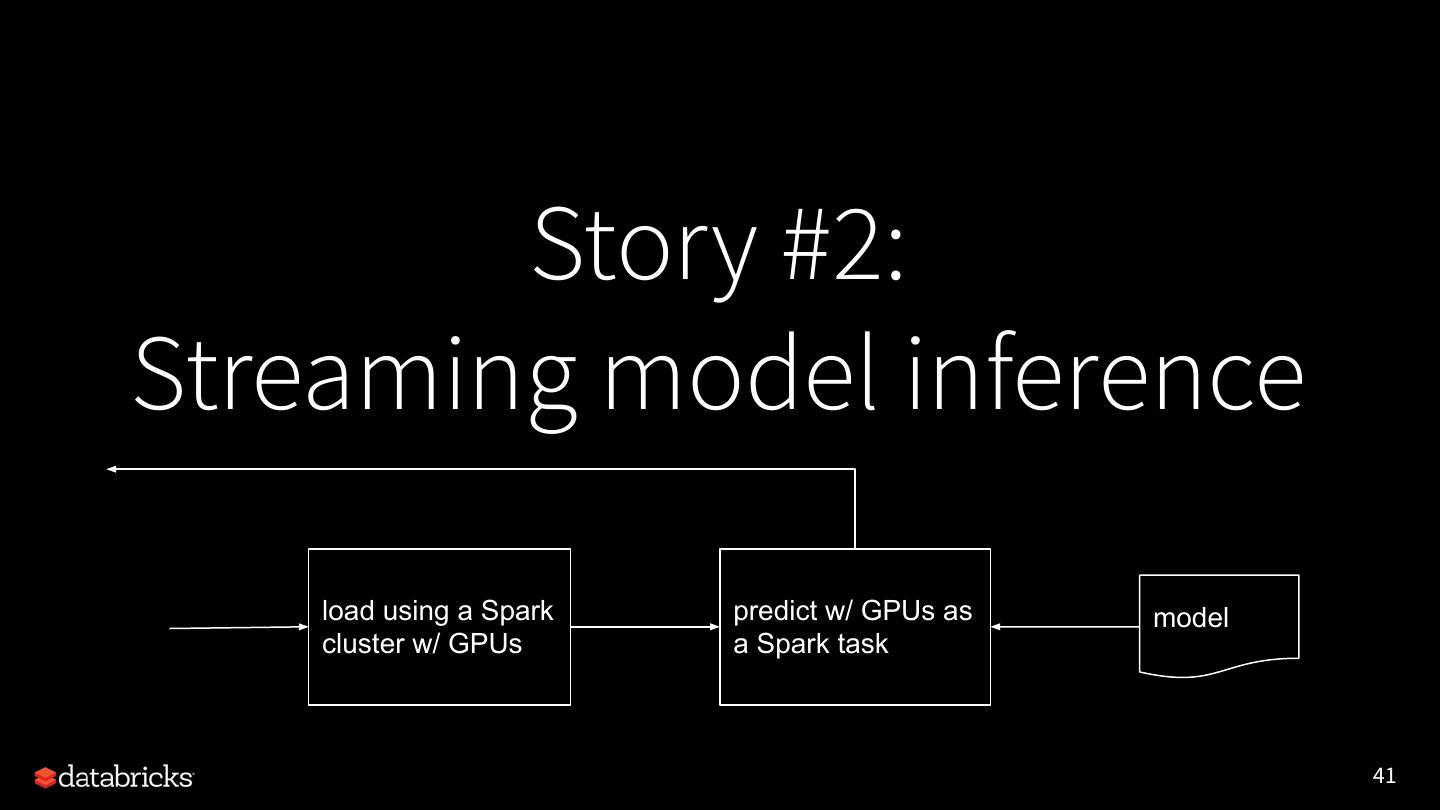
14 .Streaming model inference
load predict model
Kafka
required:
● save to stream sink
● GPU for fast inference
14
�
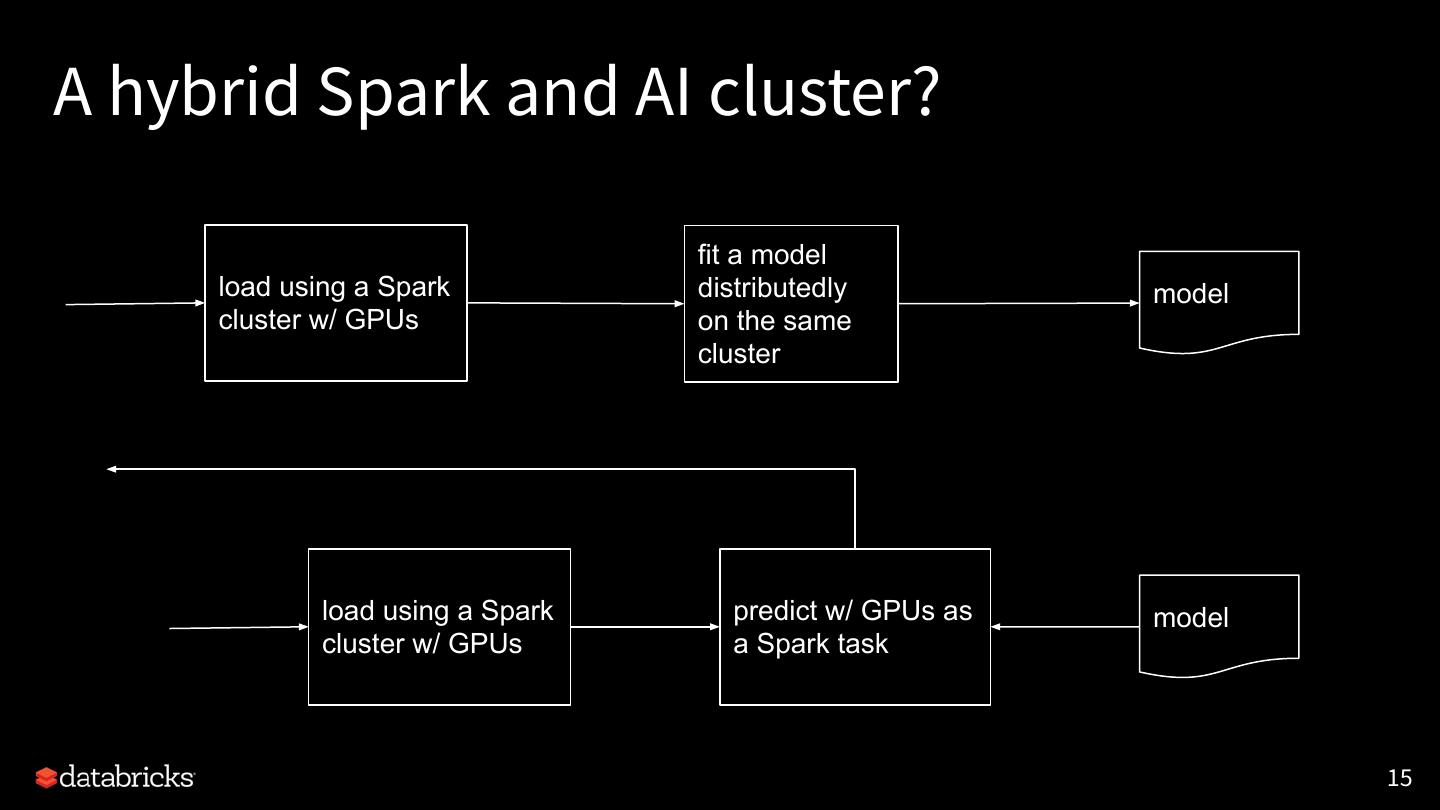
15 .A hybrid Spark and AI cluster?
fit a model
load using a Spark distributedly model
cluster w/ GPUs on the same
cluster
load using a Spark predict w/ GPUs as model
cluster w/ GPUs a Spark task
15
�
16 .Unfortunately, it doesn’t work out of the box.
See a previous demo.
�
17 .Project Hydrogen to fill the major gaps
Barrier Optimized Accelerator
Execution Data Aware
Mode Exchange Scheduling
17
�
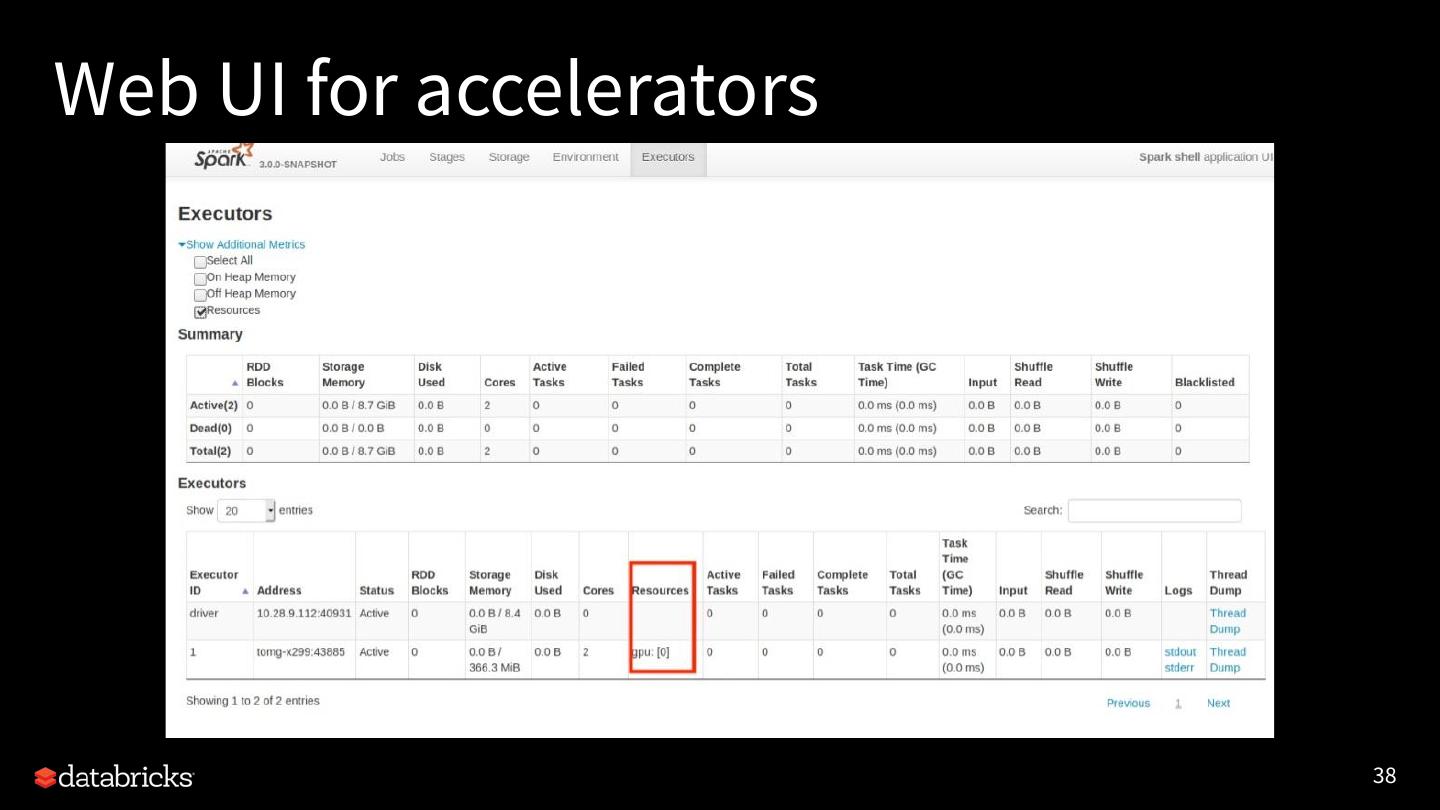
18 .Updates from Project Hydrogen
● Available features
● Future Improvement
● How to utilize
18
�
19 . Story #1:
Distributed training
fit a model
load using a Spark distributedly model
cluster w/ GPUs on the same
cluster
19
�
20 .Project Hydrogen: barrier execution mode
Barrier Optimized Accelerator
Execution Data Aware
Mode Exchange Scheduling
20
�
21 .Different execution models
Task 1
Spark (MapReduce)
Task 2
Tasks are independent of each other
Task 3
Embarrassingly parallel & massively scalable
Task 1
Distributed training
Complete coordination among tasks
Optimized for communication
Task 2 Task 3
21
�
22 .Barrier execution mode
• All tasks start together
• Sufficient info to run a hybrid distributed job
• Cancel and restart all tasks on failure
JIRA: SPARK-24374 (Spark 2.4)
22
�
23 .API: RDD.barrier()
RDD.barrier() tells Spark to launch the tasks together.
rdd.barrier().mapPartitions { iter =>
val context = BarrierTaskContext.get()
...
}
23
�
24 .API: context.barrier()
context.barrier() places a global barrier and waits until all tasks in
this stage hit this barrier.
val context = BarrierTaskContext.get()
… // preparation
context.barrier()
24
�
25 .API: context.getTaskInfos()
context.getTaskInfos() returns info about all tasks in this stage.
if (context.partitionId == 0) {
val addrs = context.getTaskInfos().map(_.address)
... // start a hybrid training job, e.g., via MPI
}
context.barrier() // wait until training finishes
25
�
26 .Barrier mode integration
26
�
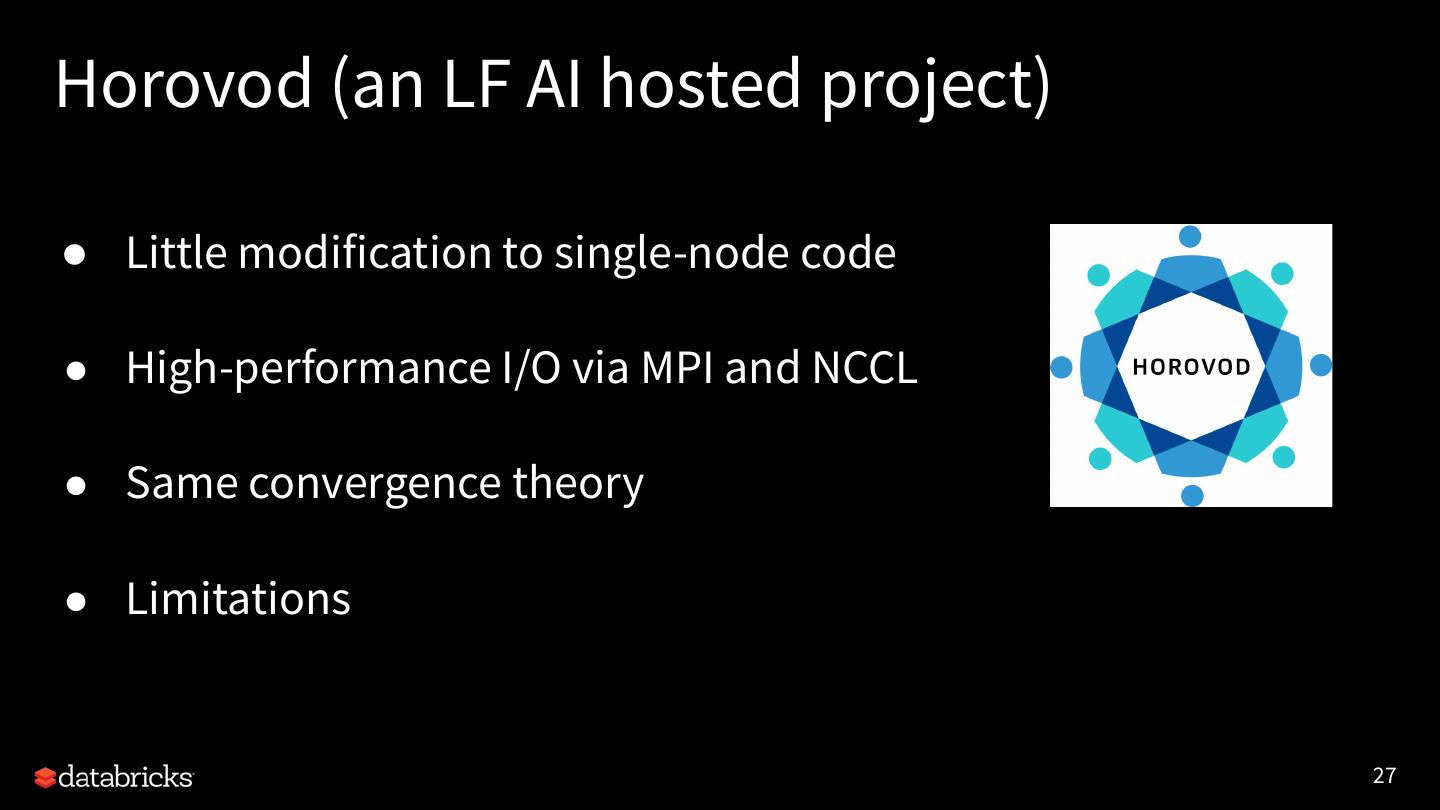
27 .Horovod (an LF AI hosted project)
● Little modification to single-node code
● High-performance I/O via MPI and NCCL
● Same convergence theory
● Limitations
27
�
28 .Hydrogen integration with Horovod
● HorovodRunner with Databricks Runtime 5.0 ML has released
● Runs Horovod under barrier execution mode
● Hides details from users
def train_hvd():
hvd.init()
… # train using Horovod
HorovodRunner(np=2).run(train_hvd)
28
�
29 .Implementation of HorovodRunner
Integrating Horovod with barrier mode is straightforward:
● Pickle and broadcast the train function.
○ Inspect code and warn users about potential issues.
● Launch a Spark job in barrier execution mode.
● In the first executor, use worker addresses to launch the Horovod MPI job.
● Terminate Horovod if the Spark job got cancelled.
○ Hint: PR_SET_PDEATHSIG
Limitation:
● Tailored for Databricks Runtime ML
○ Horovod built with TensorFlow/PyTorch, SSH, OpenMPI, NCCL, etc.
○ Spark 2.4, GPU cluster configuration, etc.
29
�