展开查看详情
1 .Understanding Query Plans
and Spark UIs
Xiao Li @ gatorsmile
Spark + AI Summit @ SF | April 2019
1
�
2 .About Me
• Engineering Manager at Databricks
• Apache Spark Committer and PMC Member
• Previously, IBM Master Inventor
• Spark, Database Replication, Information Integration
• Ph.D. in University of Florida
• Github: gatorsmile
�
3 . Databricks Customers Across Industries
Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology
Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
�
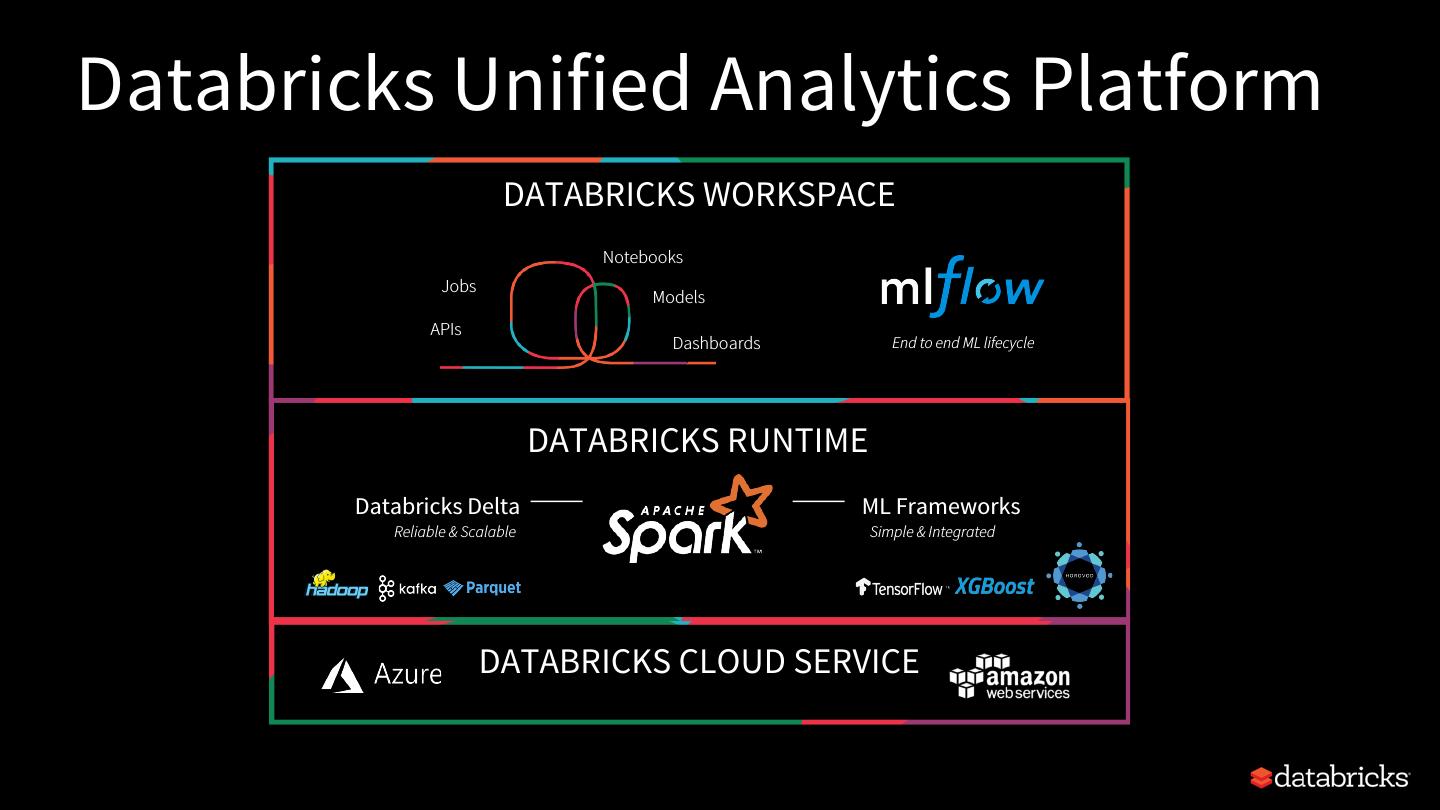
4 .Databricks Unified Analytics Platform
DATABRICKS WORKSPACE
Notebooks
Jobs
Models
APIs
Dashboards End to end ML lifecycle
DATABRICKS RUNTIME
Databricks Delta ML Frameworks
Reliable & Scalable Simple & Integrated
DATABRICKS CLOUD SERVICE
�
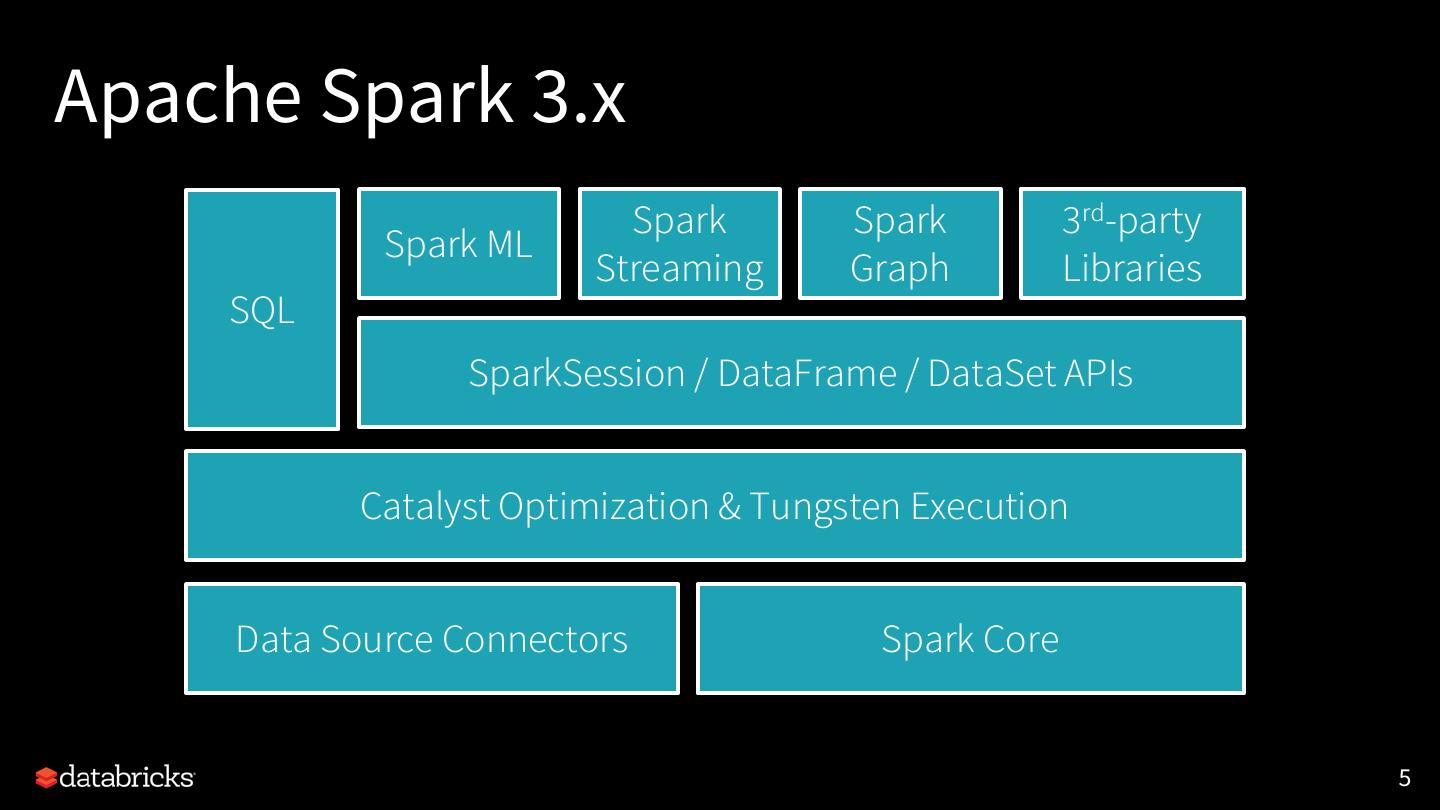
5 .Apache Spark 3.x
Spark Spark 3rd-party
Spark ML
Streaming Graph Libraries
SQL
SparkSession / DataFrame / DataSet APIs
Catalyst Optimization & Tungsten Execution
Data Source Connectors Spark Core
5
�
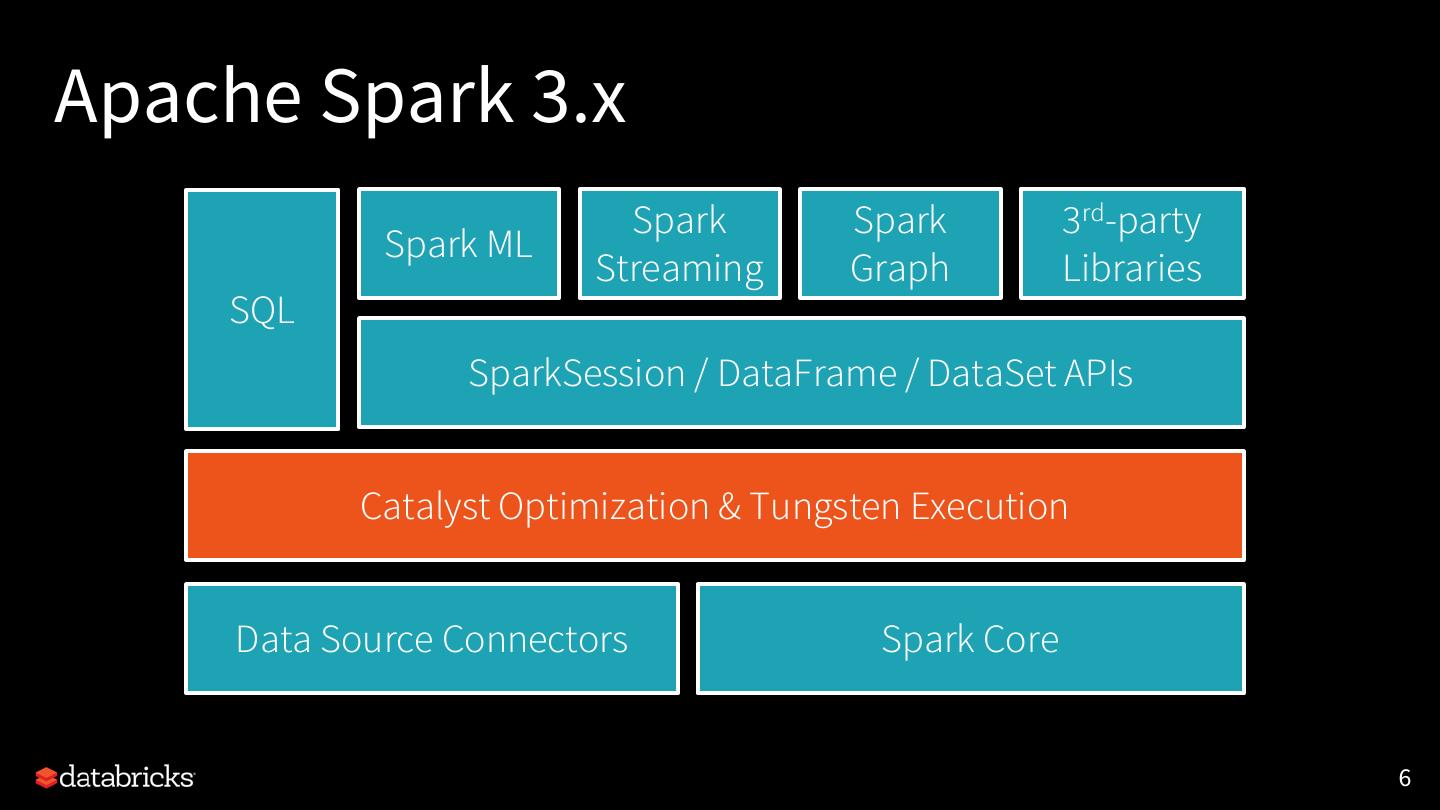
6 .Apache Spark 3.x
Spark Spark 3rd-party
Spark ML
Streaming Graph Libraries
SQL
SparkSession / DataFrame / DataSet APIs
Catalyst Optimization & Tungsten Execution
Data Source Connectors Spark Core
6
�
7 .From declarative queries to RDDs
Cypher
7
�
8 .Maximize Performance
8
�
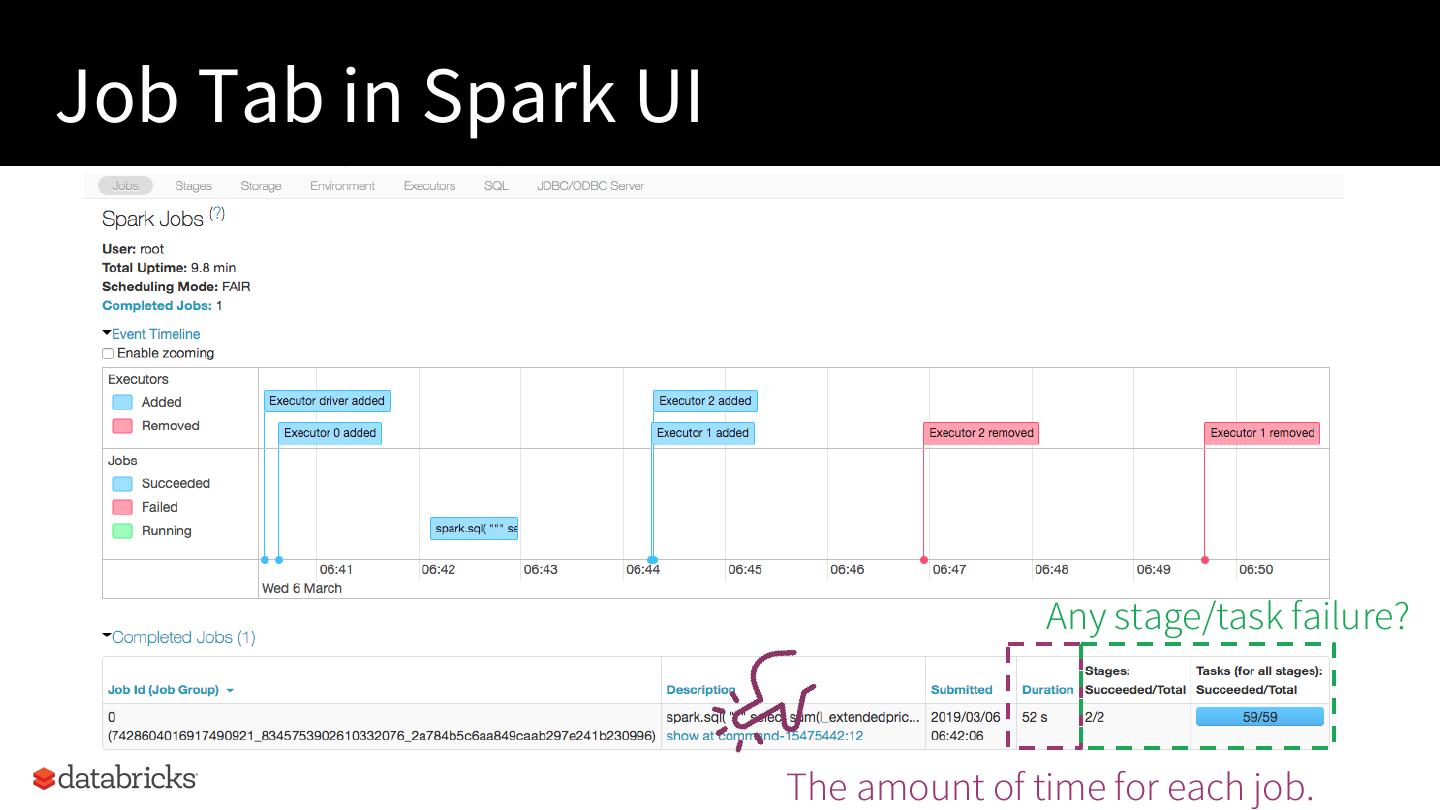
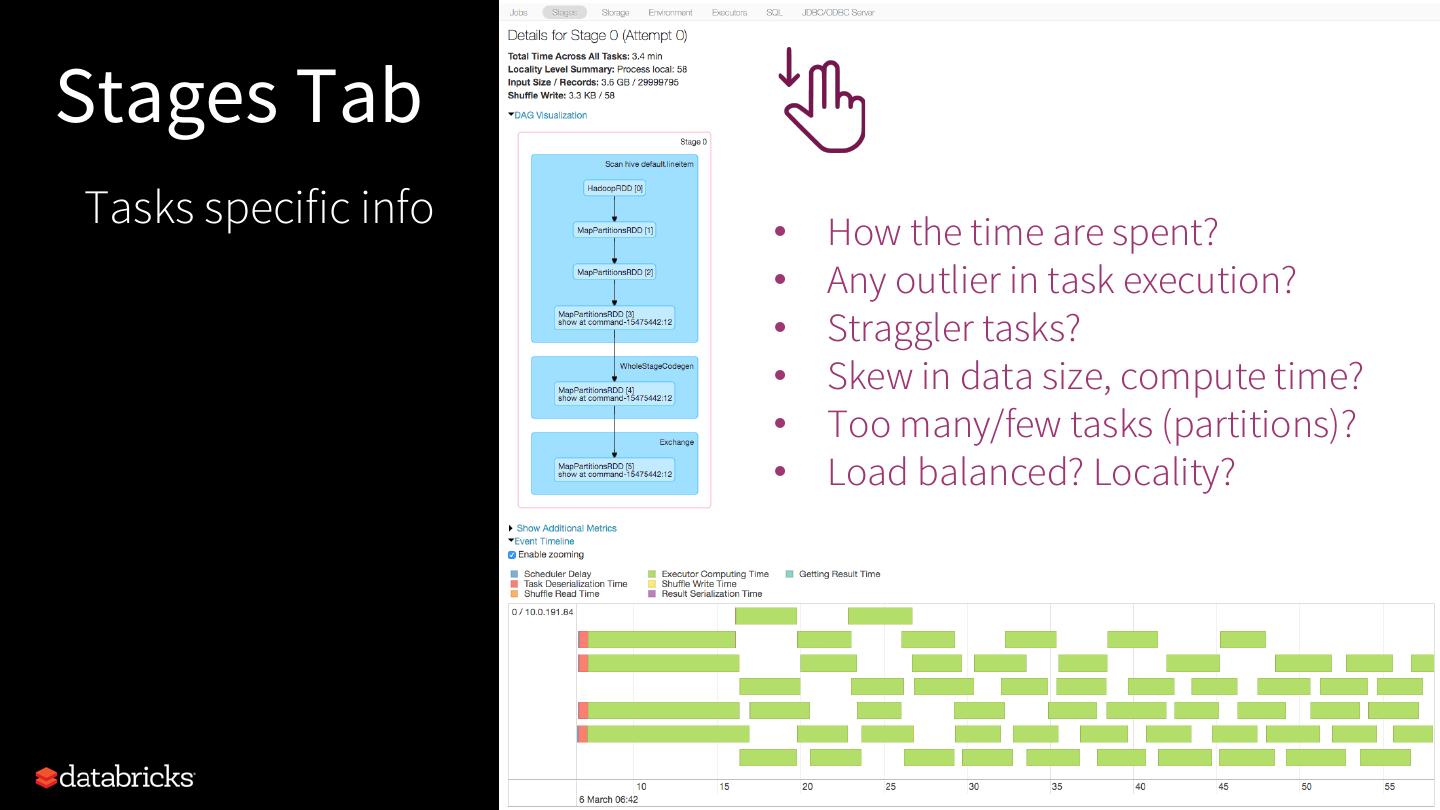
9 . Read Plan.
Interpret Plan.
Tune Plan.
Track Execution.
9
�
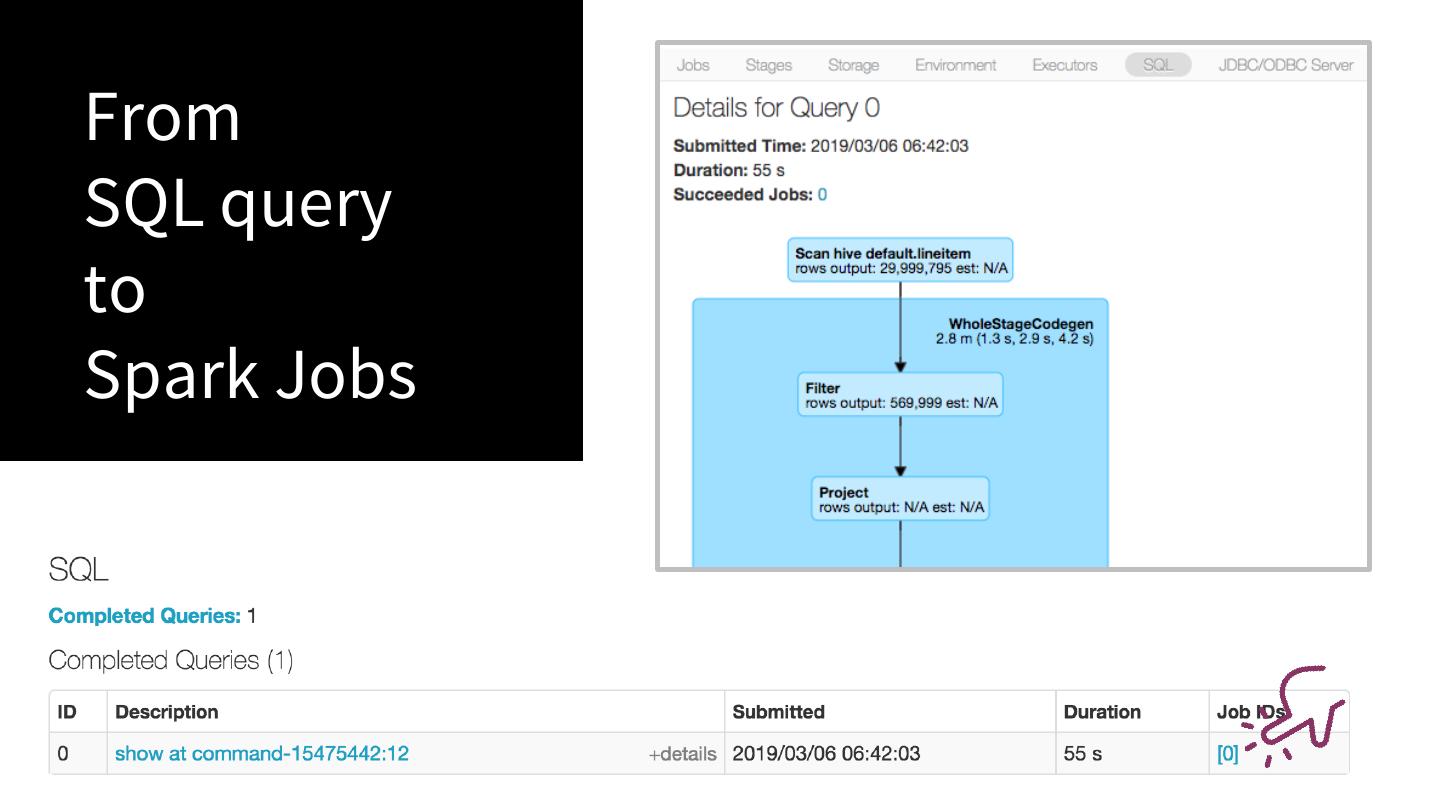
10 .Read Plans from
SQL Tab in either
Spark UI or Spark
History Server
10
�
11 .Read Plans from
SQL Tab in either
Spark UI or Spark
History Server
Spark 3.0: Show the actual SQL statement? [SPARK-27045]
11
�
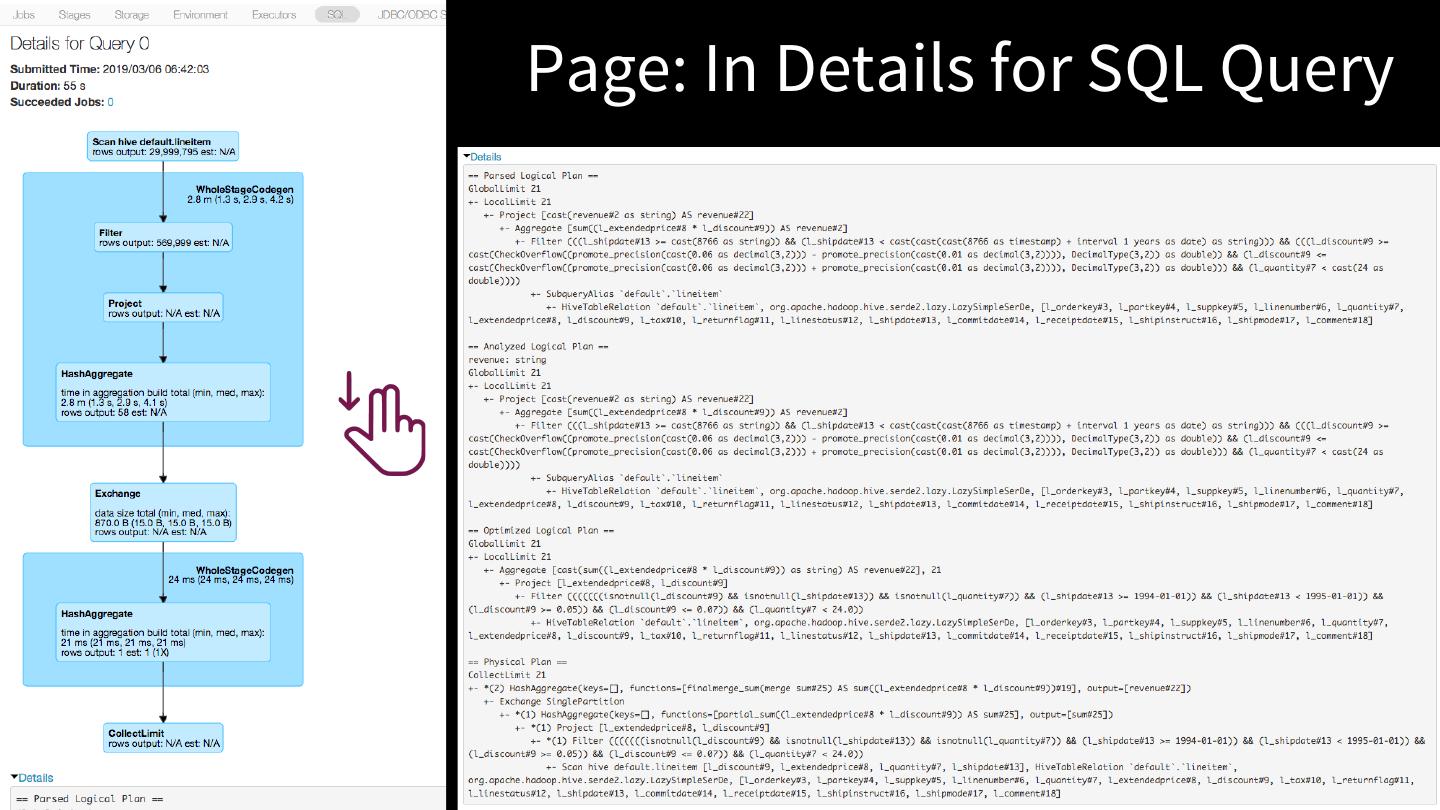
12 .Page: In Details for SQL Query
12
�
13 . Parsed
Plan
Analyzed
Plan
Optimized
Plan
Physical
Plan
13
�
14 .Understand and Tune Plans
14
�
15 .Different Results!!!
15
�
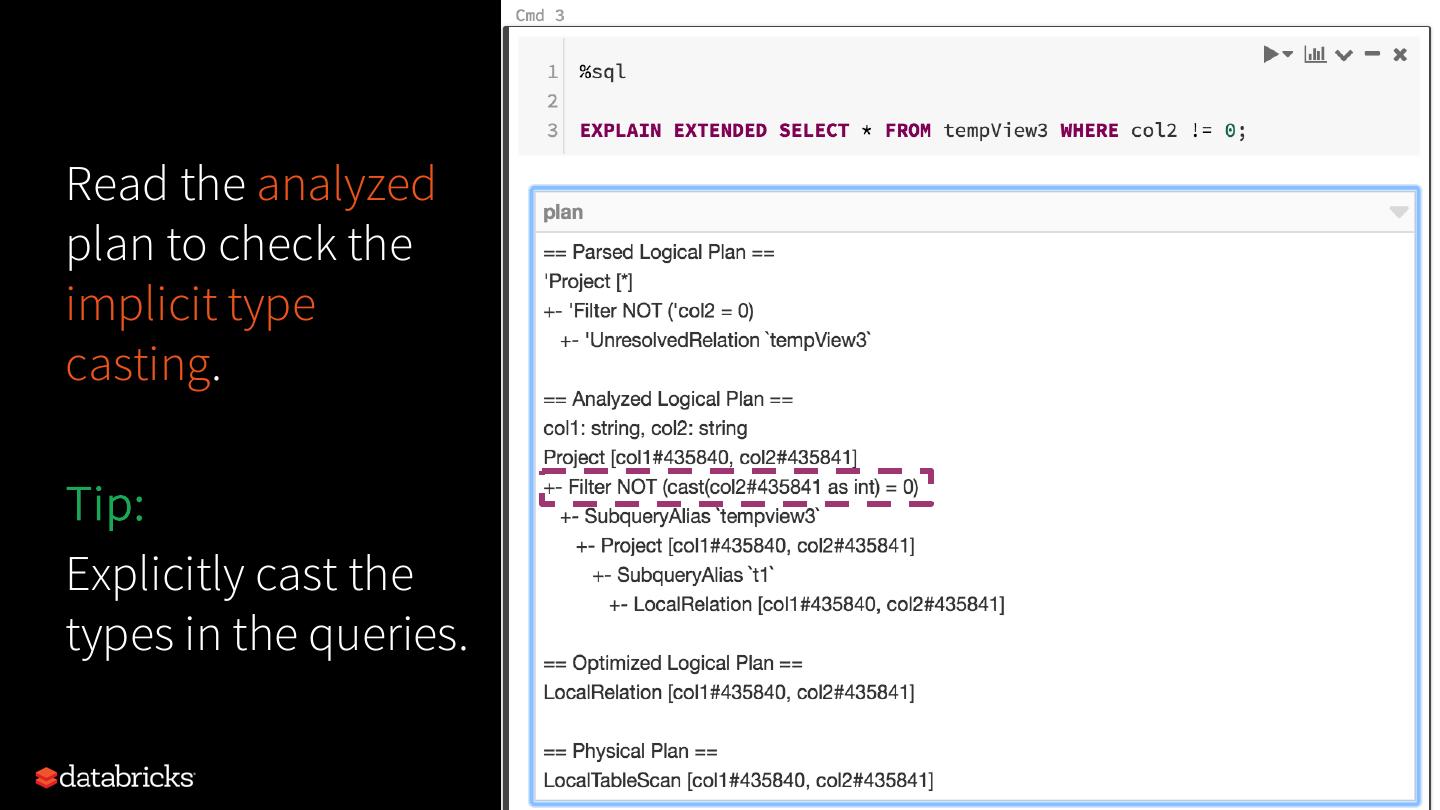
16 .Read the analyzed
plan to check the
implicit type
casting.
Tip:
Explicitly cast the
types in the queries.
16
�
17 .Read the analyzed
plan to check the
implicit type
casting.
Tip:
Explicitly cast the
types in the queries.
17
�
18 .Create Hive Tables
Syntax to create a Hive Serde table
18
�
19 .Read Tables
Hive serde reader
�
20 . Native
reader/writer
performs faster
than Hive serde
reader/writer
filter pushdown
20
�
21 .Create Native Tables
Syntax to create a Spark native ORC table
Tip:
Create native
data source
tables for better
performance
and stability.
21
�
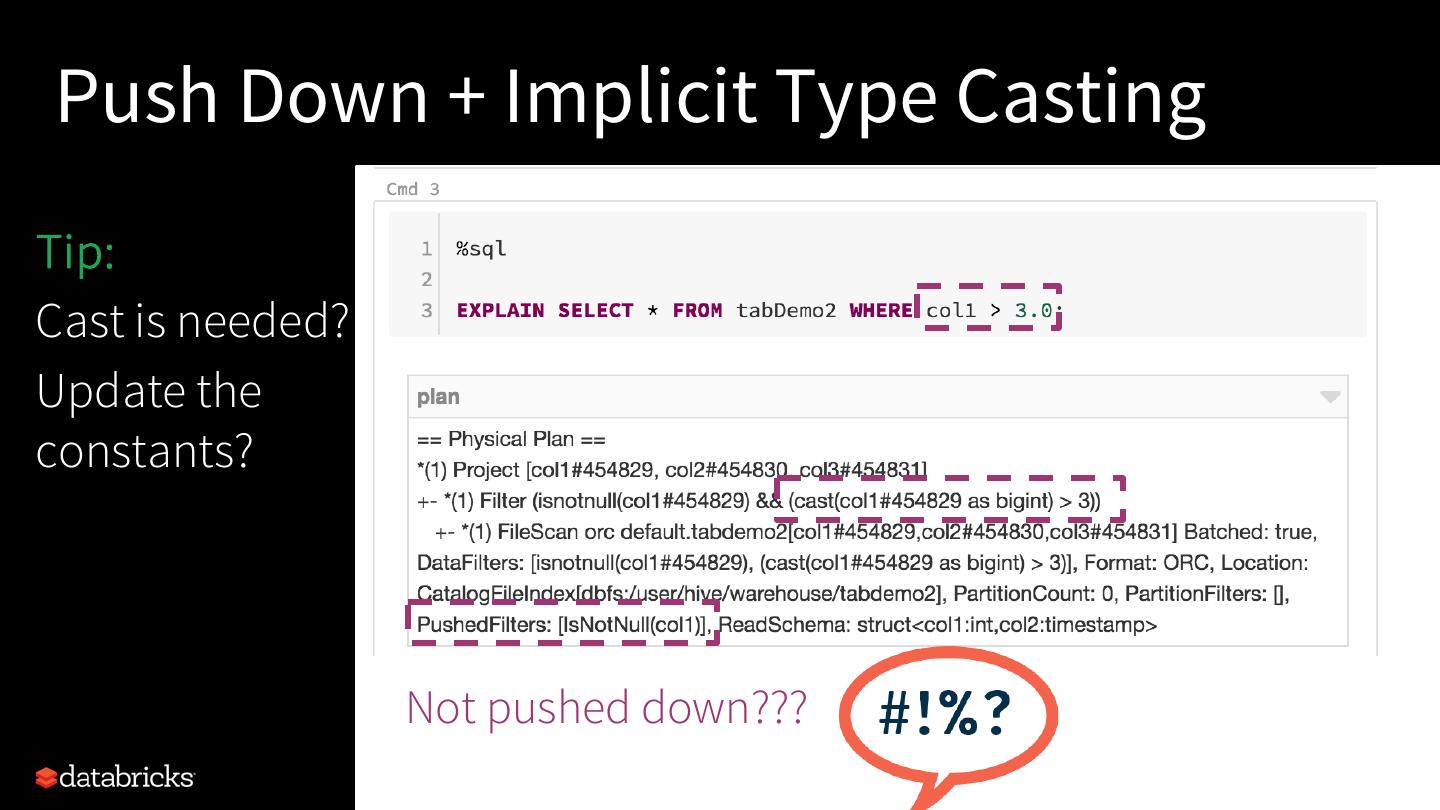
22 .Push Down + Implicit Type Casting
Tip:
Cast is needed?
Update the
constants?
Not pushed down???
22
�
23 .Nested Schema Pruning
Not pruned??? 23
�
24 .Nested Schema Pruning
24
�
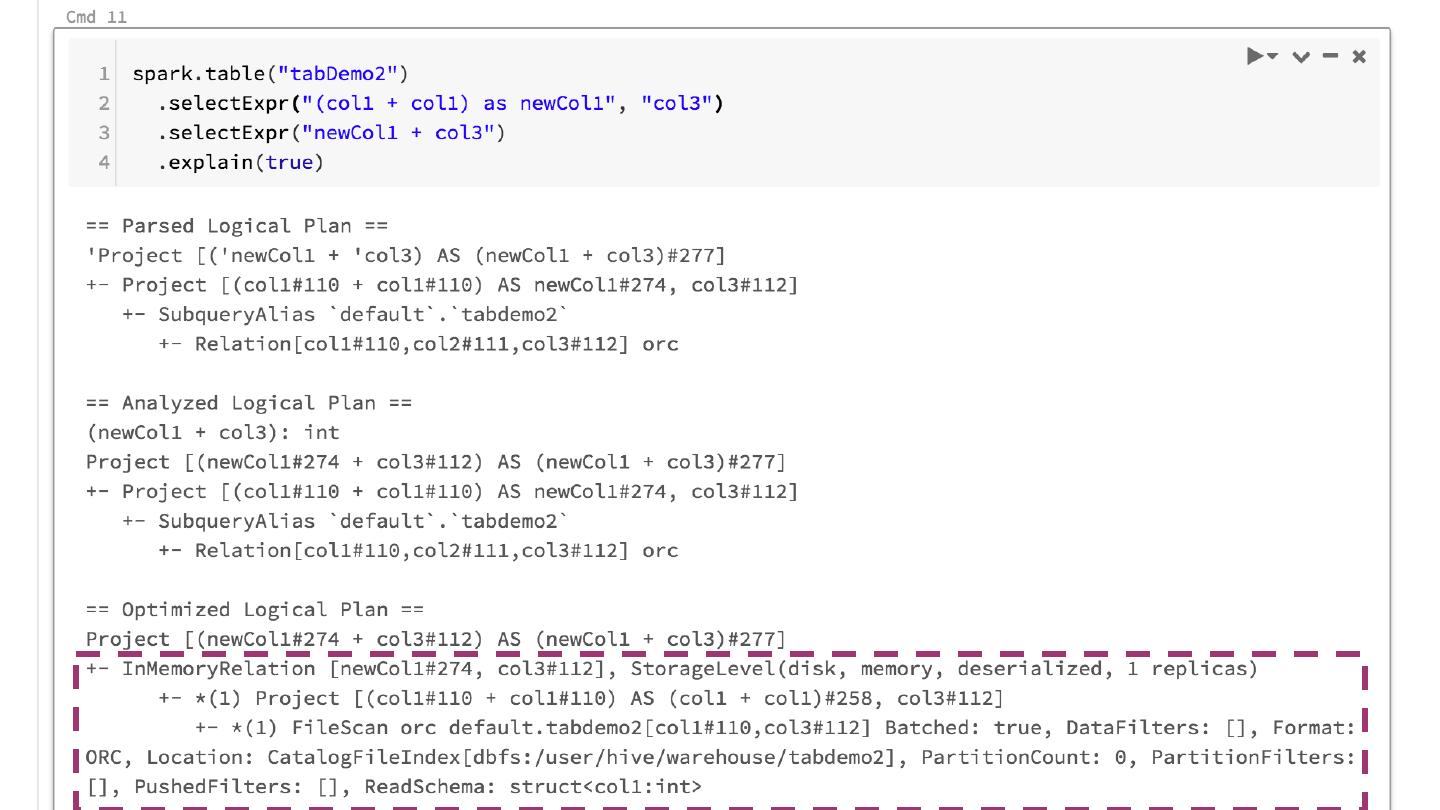
25 .Collapse Projects
Call UDF three times!!!
25
�
27 .Cross-session SQL Cache
• If a query is cached in the one session, the new
queries in all the sessions might be impacted.
• Check your query plan!
27
�
29 .Join Hints in Spark 3.0
• BROADCAST
• Broadcast Hash/Nested-loop Join
• MERGE
• Shuffle Sort Merge Join
• SHUFFLE_HASH
• Shuffle Hash Join
• SHUFFLE_REPLICATE_NL
• Shuffle-and-Replicate Nested Loop Join
29
�