展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .The Parquet Format and
Performance Optimization
Opportunities
Boudewijn Braams
Software Engineer - Databricks
#UnifiedDataAnalytics #SparkAISummit
�
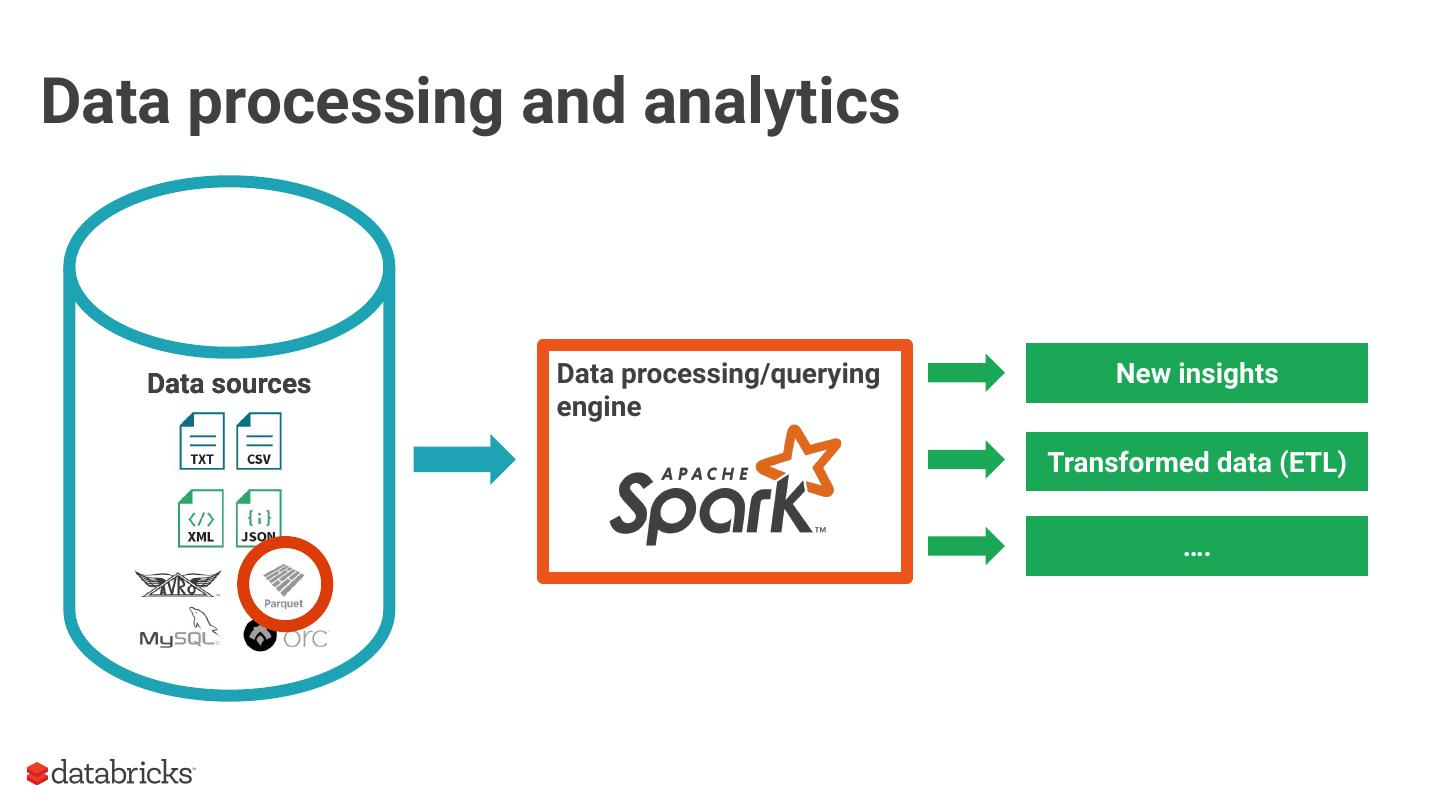
3 .Data processing and analytics
Data sources Data processing/querying New insights
engine
Transformed data (ETL)
….
�
4 .Overview
● Data storage models
● The Parquet format
● Optimization opportunities
�
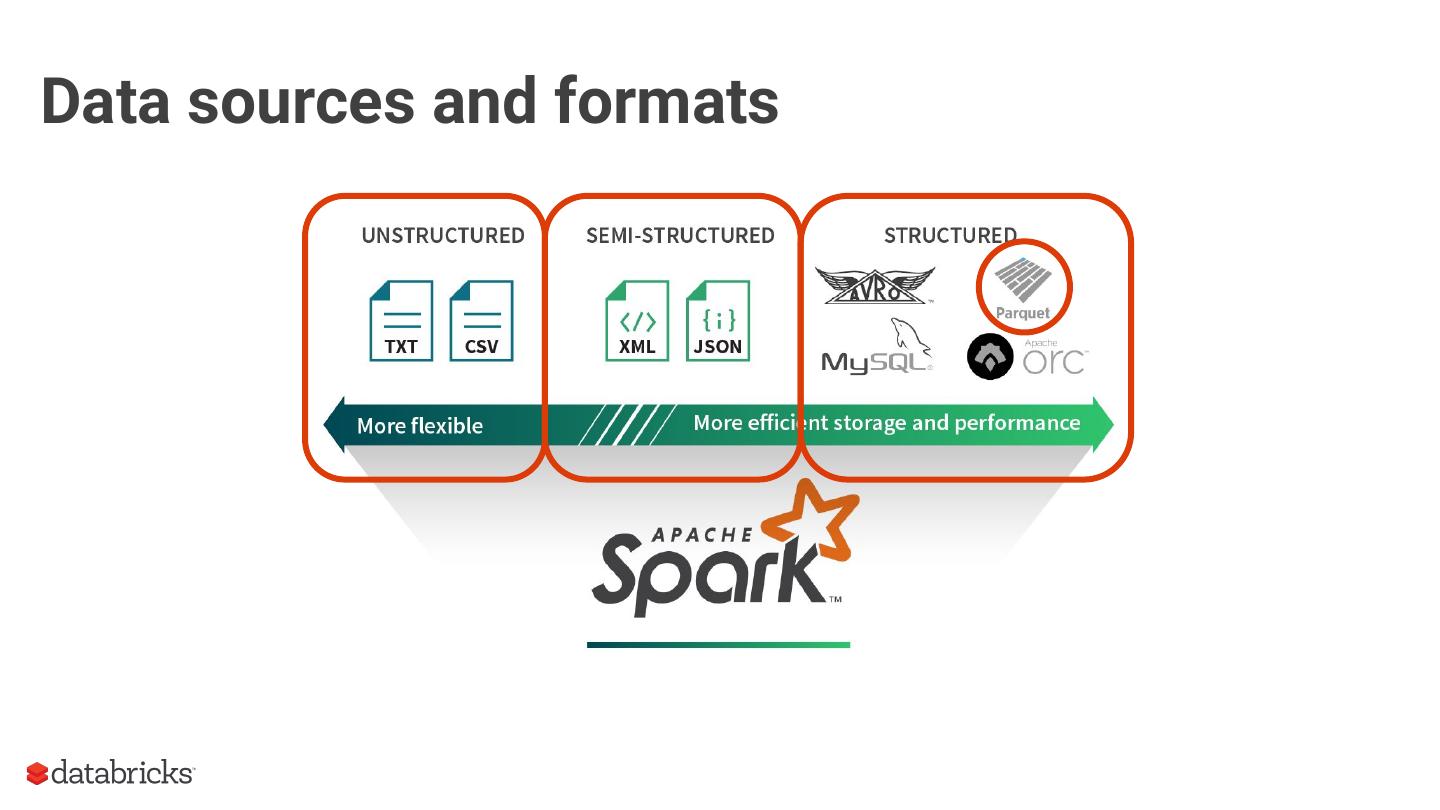
5 .Data sources and formats
�
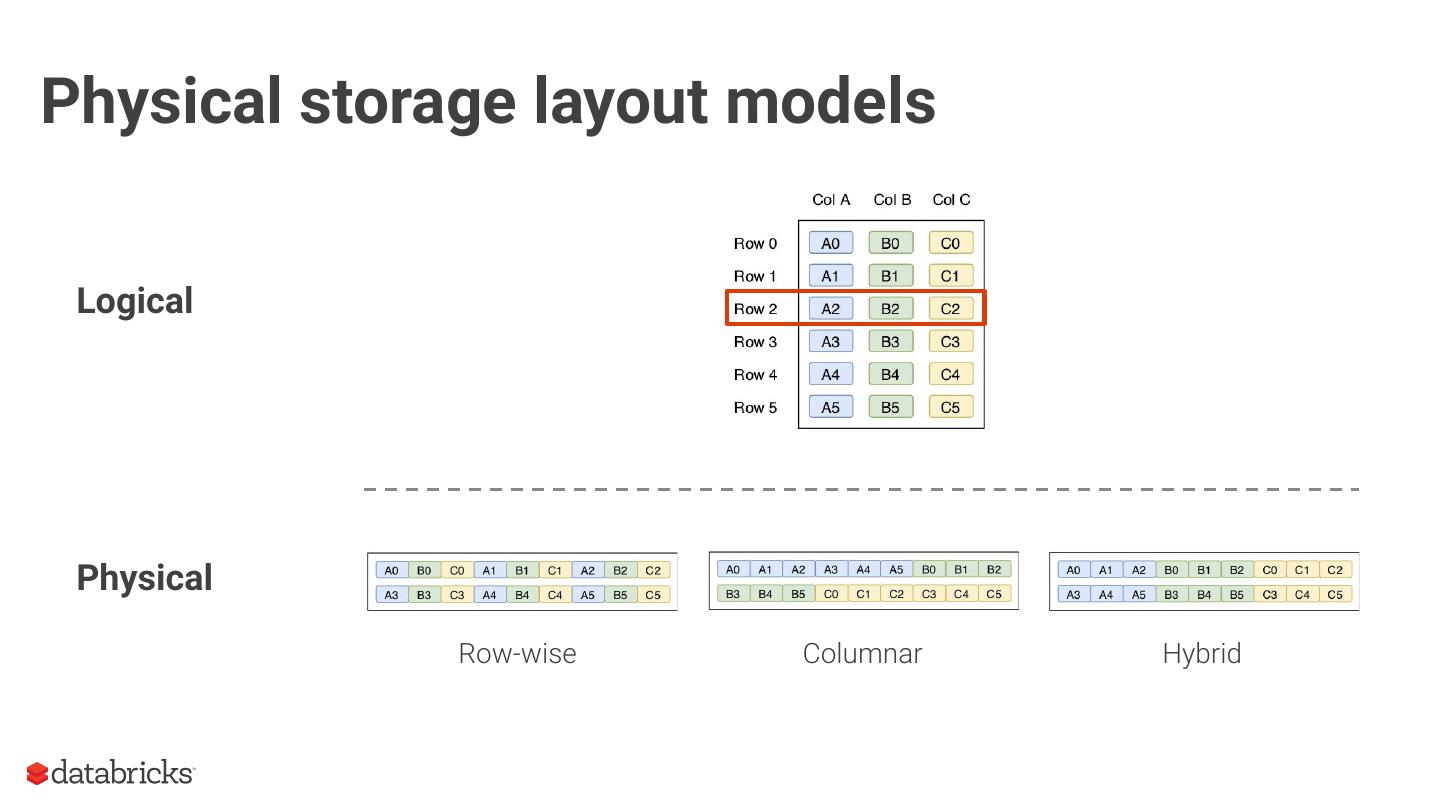
6 .Physical storage layout models
Logical
Physical
Row-wise Columnar Hybrid
�
7 .Different workloads
● OLTP
○ Online transaction processing
○ Lots of small operations involving whole rows
● OLAP
○ Online analytical processing
○ Few large operations involving subset of all columns
● Assumption: I/O is expensive (memory, disk, network..)
�
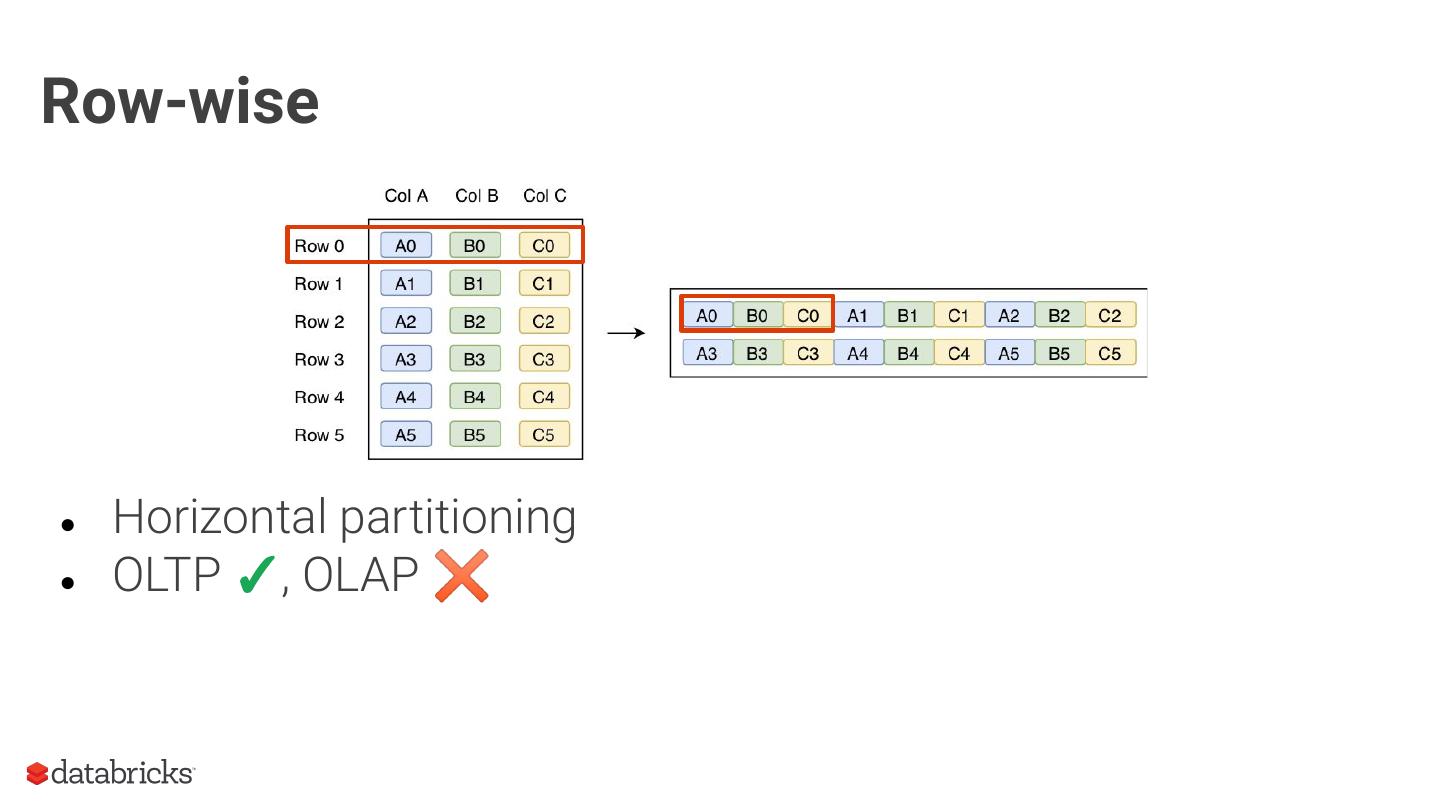
8 .Row-wise
● Horizontal partitioning
● OLTP ✓, OLAP ✖
�
9 .Columnar
● Vertical partitioning
● OLTP ✖, OLAP ✓
○ Free projection pushdown
○ Compression opportunities
�
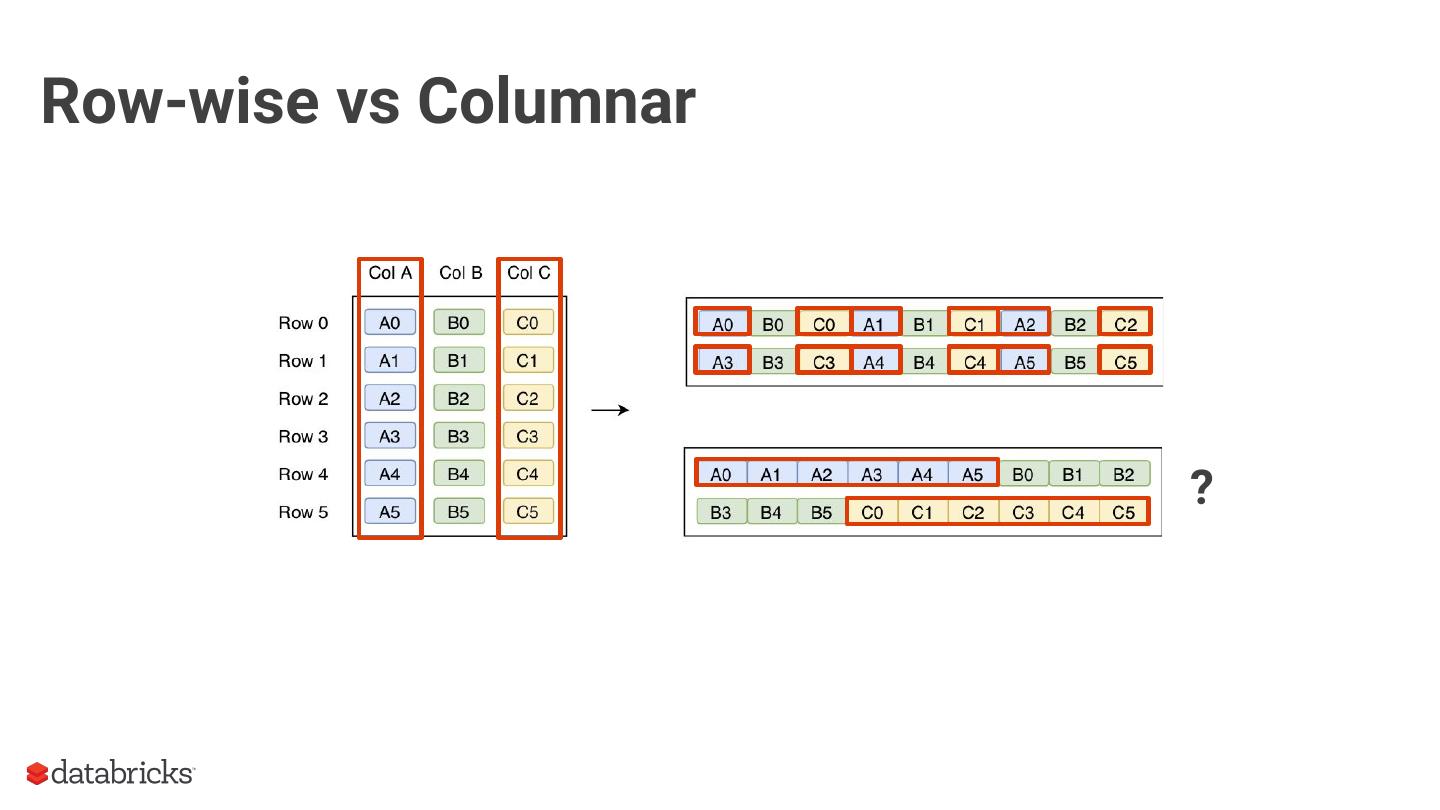
10 .Row-wise vs Columnar
?
�
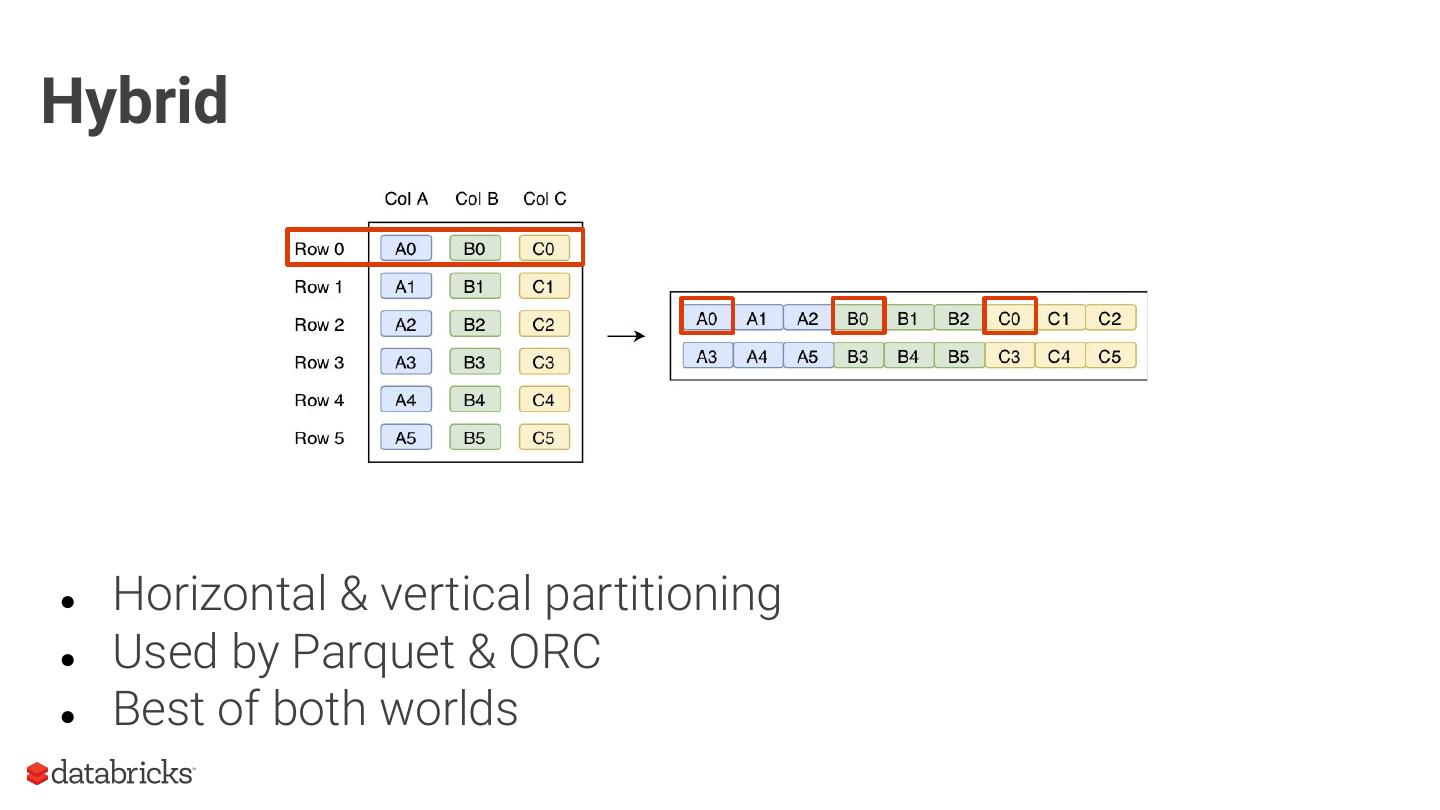
11 .Hybrid
● Horizontal & vertical partitioning
● Used by Parquet & ORC
● Best of both worlds
�
12 .Apache Parquet
● Initial effort by Twitter & Cloudera
● Open source storage format
○ Hybrid storage model (PAX)
● Widely used in Spark/Hadoop ecosystem
● One of the primary formats used by Databricks customers
�
13 .Parquet: files
● On disk usually not a single file
● Logical file is defined by a root directory
○ Root dir contains one or multiple files
./example_parquet_file/
./example_parquet_file/part-00000-87439b68-7536-44a2-9eaa-1b40a236163d-c000.snappy.parquet
./example_parquet_file/part-00001-ae3c183b-d89d-4005-a3c0-c7df9a8e1f94-c000.snappy.parquet
○ or contains sub-directory structure with files in leaf directories
./example_parquet_file/
./example_parquet_file/country=Netherlands/
./example_parquet_file/country=Netherlands/part-00000-...-475b15e2874d.c000.snappy.parquet
./example_parquet_file/country=Netherlands/part-00001-...-c7df9a8e1f94.c000.snappy.parquet
�
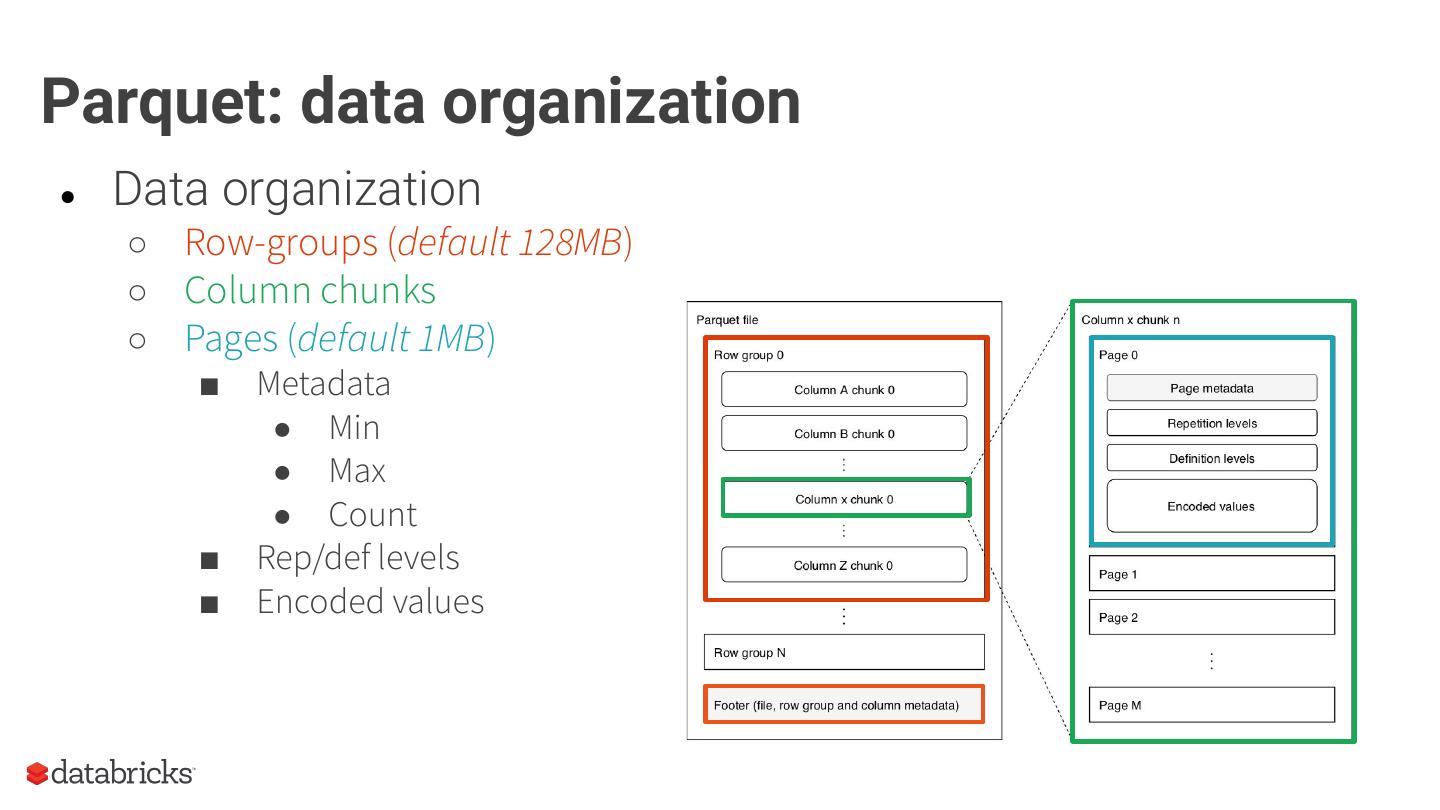
14 .Parquet: data organization
● Data organization
○ Row-groups (default 128MB)
○ Column chunks
○ Pages (default 1MB)
■ Metadata
● Min
● Max
● Count
■ Rep/def levels
■ Encoded values
�
15 .Parquet: encoding schemes
● PLAIN
○ Fixed-width: back-to-back
○ Non fixed-width: length prefixed
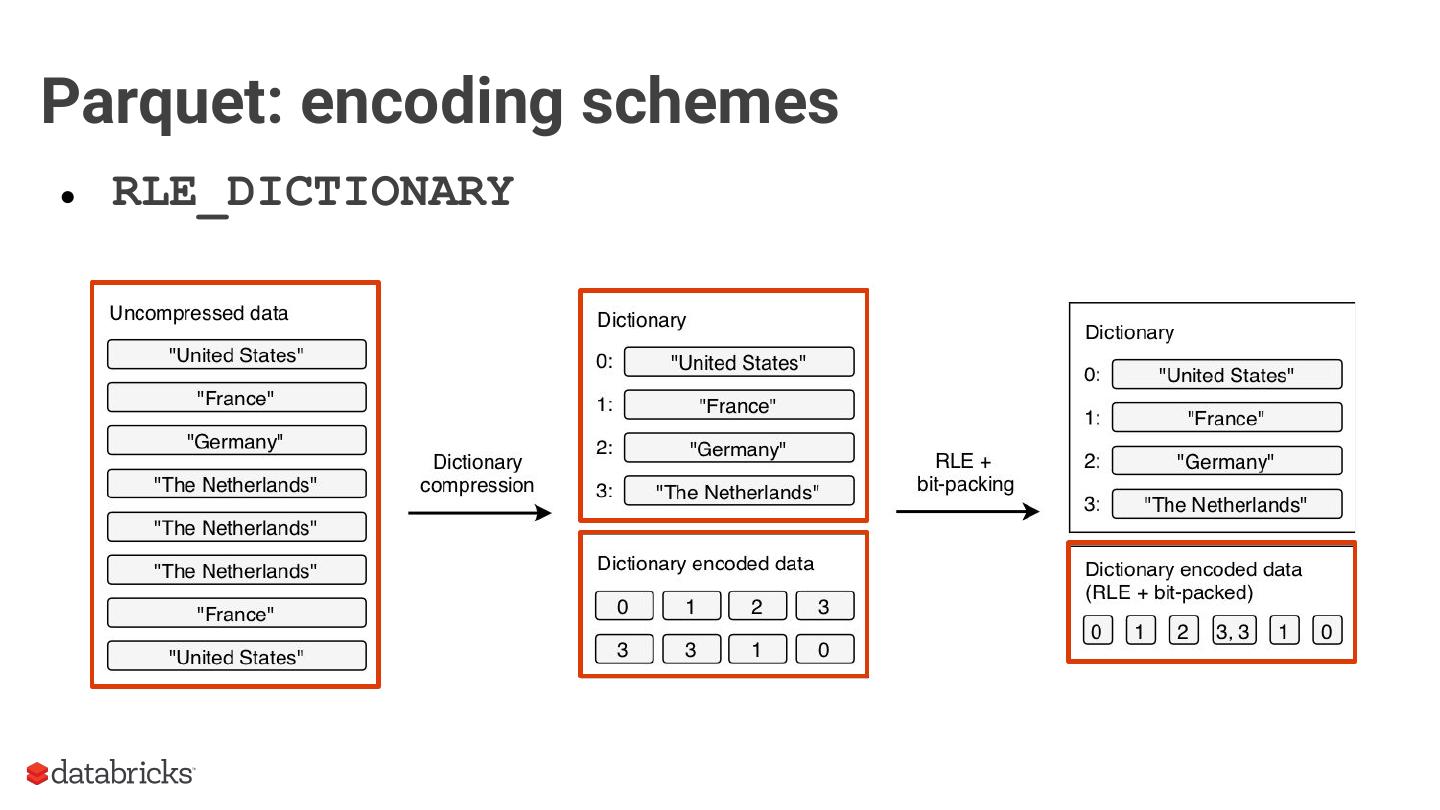
● RLE_DICTIONARY
○ Run-length encoding + bit-packing + dictionary compression
○ Assumes duplicate and repeated values
�
16 .Parquet: encoding schemes
● RLE_DICTIONARY
�
17 .Optimization: dictionary encoding
● Smaller files means less I/O
● Note: single dictionary per column chunk, size limit
Dictionary too big?
Automatic fallback to PLAIN...
�
18 .Optimization: dictionary encoding
● Increase max dictionary size
parquet.dictionary.page.size
● Decrease row-group size
parquet.block.size
�
19 .Optimization: dictionary encoding
● Inspect Parquet files using parquet-tools
�
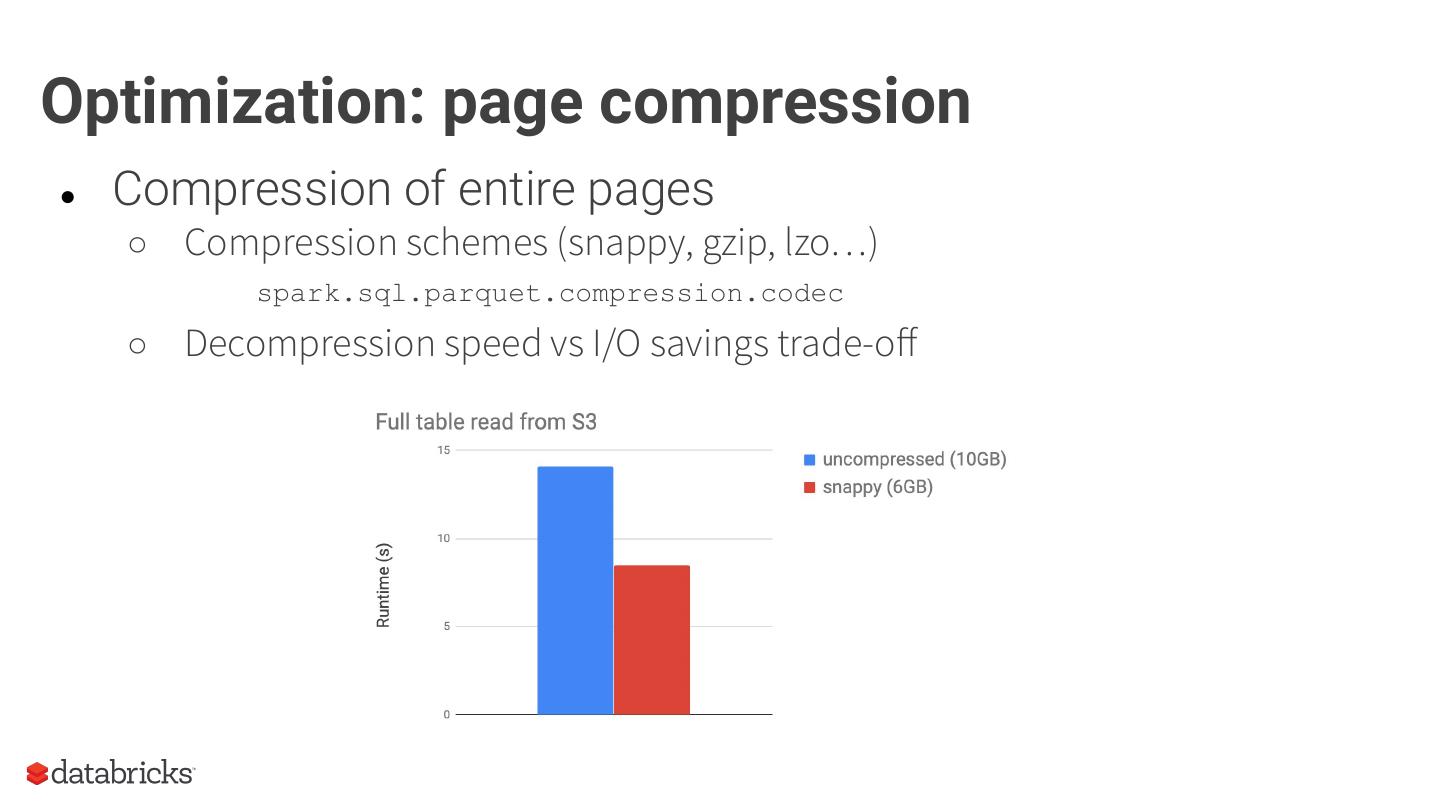
20 .Optimization: page compression
● Compression of entire pages
○ Compression schemes (snappy, gzip, lzo…)
spark.sql.parquet.compression.codec
○ Decompression speed vs I/O savings trade-off
�
21 .Optimization: predicate pushdown
SELECT * FROM table WHERE x > 5
Row-group 0: x: [min: 0, max: 9]
Row-group 1: x: [min: 3, max: 7]
Row-group 2: x: [min: 1, max: 4]
…
● Leverage min/max statistics
spark.sql.parquet.filterPushdown
�
22 .Optimization: predicate pushdown
● Doesn’t work well on unsorted data
○ Large value range within row-group, low min, high max
○ What to do? Pre-sort data on predicate columns
● Use typed predicates
○ Match predicate and column type, don’t rely on casting/conversions
○ Example: use actual longs in predicate instead of ints for long columns
�
23 .Optimization: predicate pushdown
SELECT * FROM table WHERE x = 5
Row-group 0: x: [min: 0, max: 9]
Row-group 1: x: [min: 3, max: 7]
Row-group 2: x: [min: 1, max: 4]
…
● Dictionary filtering!
parquet.filter.dictionary.enabled
�
24 .Optimization: partitioning
● Embed predicates in directory structure
df.write.partitionBy(“date”).parquet(...)
./example_parquet_file/date=2019-10-15/...
./example_parquet_file/date=2019-10-16/...
part-00000-...-475b15e2874d.c000.snappy.parquet
./example_parquet_file/date=2019-10-17/
…
�
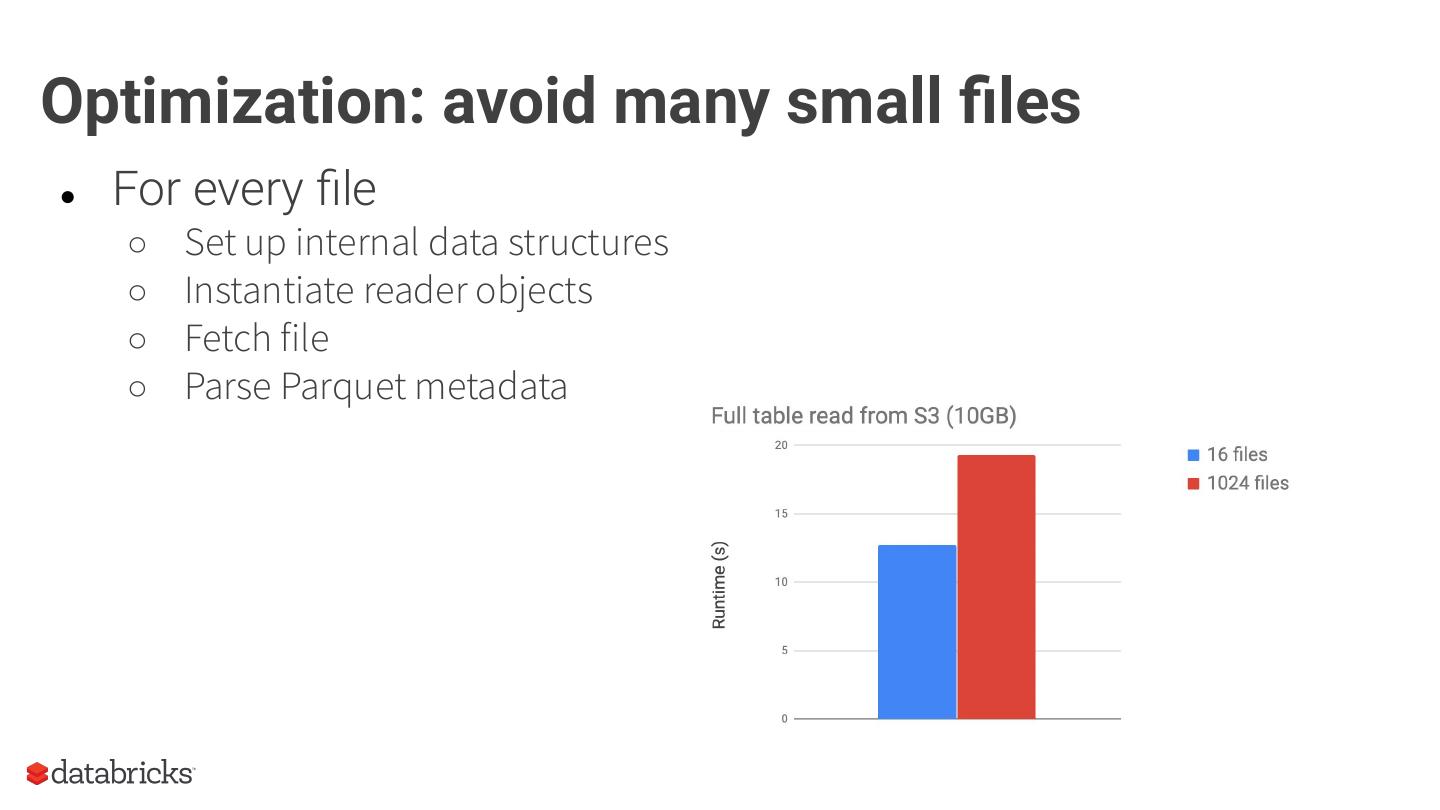
25 .Optimization: avoid many small files
● For every file
○ Set up internal data structures
○ Instantiate reader objects
○ Fetch file
○ Parse Parquet metadata
�
26 .Optimization: avoid many small files
● Manual compaction
df.repartition(numPartitions).write.parquet(...)
or
df.coalesce(numPartitions).write.parquet(...)
● Watch out for incremental workload output!
�
27 .Optimization: avoid few huge files
● Also avoid having huge files!
● SELECT count(*) on 250GB dataset
○ 250 partitions (~1GB each)
■ 5 mins
○ 1 huge partition (250GB)
■ 1 hour
● Footer processing not optimized for speed...
�
28 .Optimization: avoid many small files
● Manual repartitioning
○ Can we automate this optimization?
○ What about concurrent access?
● We need isolation of operations (i.e. ACID transactions)
● Is there anything for Spark and Parquet that we can use?
�
29 .Optimization: Delta Lake
● Open-source storage layer on top of Parquet in Spark
○ ACID transactions
○ Time travel (versioning via WAL)
○ ...
● Automated repartitioning (Databricks)
○ (Auto-) OPTIMIZE
○ Additional file-level skipping stats
■ Metadata stored in Parquet format, scalable
○ Z-ORDER clustering
�