


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Successful AI_ML Projects with End-to-End Cloud Data Engineering
Successful AI_ML Projects with End-to-End Cloud Data Engineering
Successful AI_ML Projects with End-to-End Cloud Data Engineering
Trusted, high-quality data and efficient use of data engineers’ time are critical success factors for AI/ML projects. Enterprise data is complex—it comes from several sources, in a variety of formats, and at varied speeds. For your machine learning projects on Apache Spark, you need a holistic approach to data engineering: finding & discovering, ingesting & integrating, server-less processing at scale, and data governance. Stop by this session for an overview on how to set up AI/ML projects for success while Informatica takes the heavy lifting out of your data engineering.
展开查看详情
1 .Successful AI/ML Projects with End-to-End Cloud Data Engineering Louis Polycarpou ` Technical Director Cloud, Data Engineering, and Data Integration
2 .AI/ML Projects in the Enterprise Today Only 1% of AI/ML projects are successful *Source: Databricks research 2018 2 © Informatica. Proprietary and Confidential.
3 .Why are AI/ML Projects so difficult? • Data Scientists spend 80% of their time in preparing data.. only 20% on modeling • Data challenges – data is coming in at high volume, high velocity from a variety of sources • Enterprise data can not be provisioned if it lacks governance or is hidden • Lost productivity in repetitive data pipelines to move and prepare data • Data Engineers spend too much time capacity planning of Big Data processing End-to-End Data Engineering holds the Key! 3 © Informatica. Proprietary and Confidential.
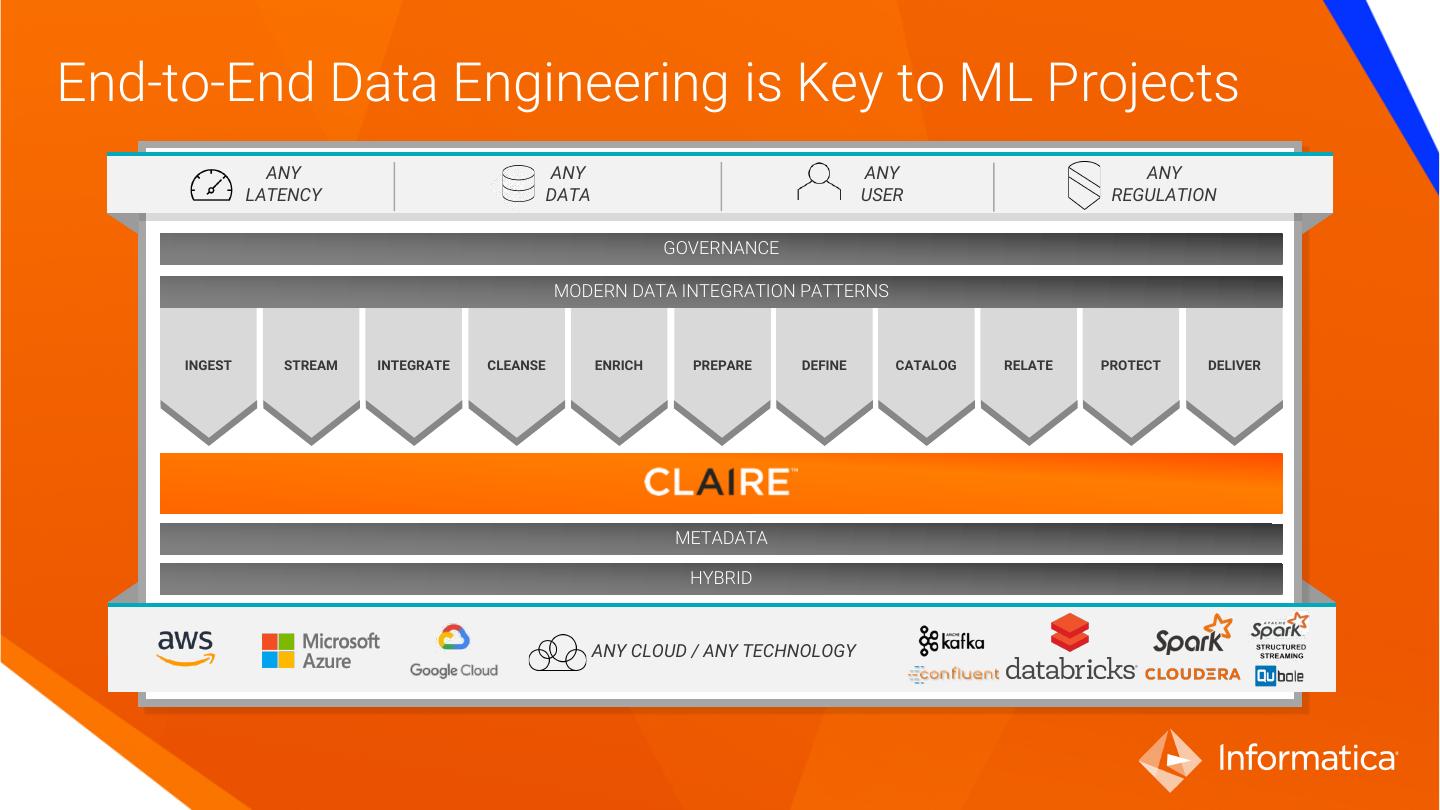
4 .End-to-End Data Engineering is Key to ML Projects ANY ANY ANY ANY LATENCY DATA USER REGULATION GOVERNANCE MODERN DATA INTEGRATION PATTERNS INGEST STREAM INTEGRATE CLEANSE ENRICH PREPARE DEFINE CATALOG RELATE PROTECT DELIVER METADATA HYBRID ANY CLOUD / ANY TECHNOLOGY
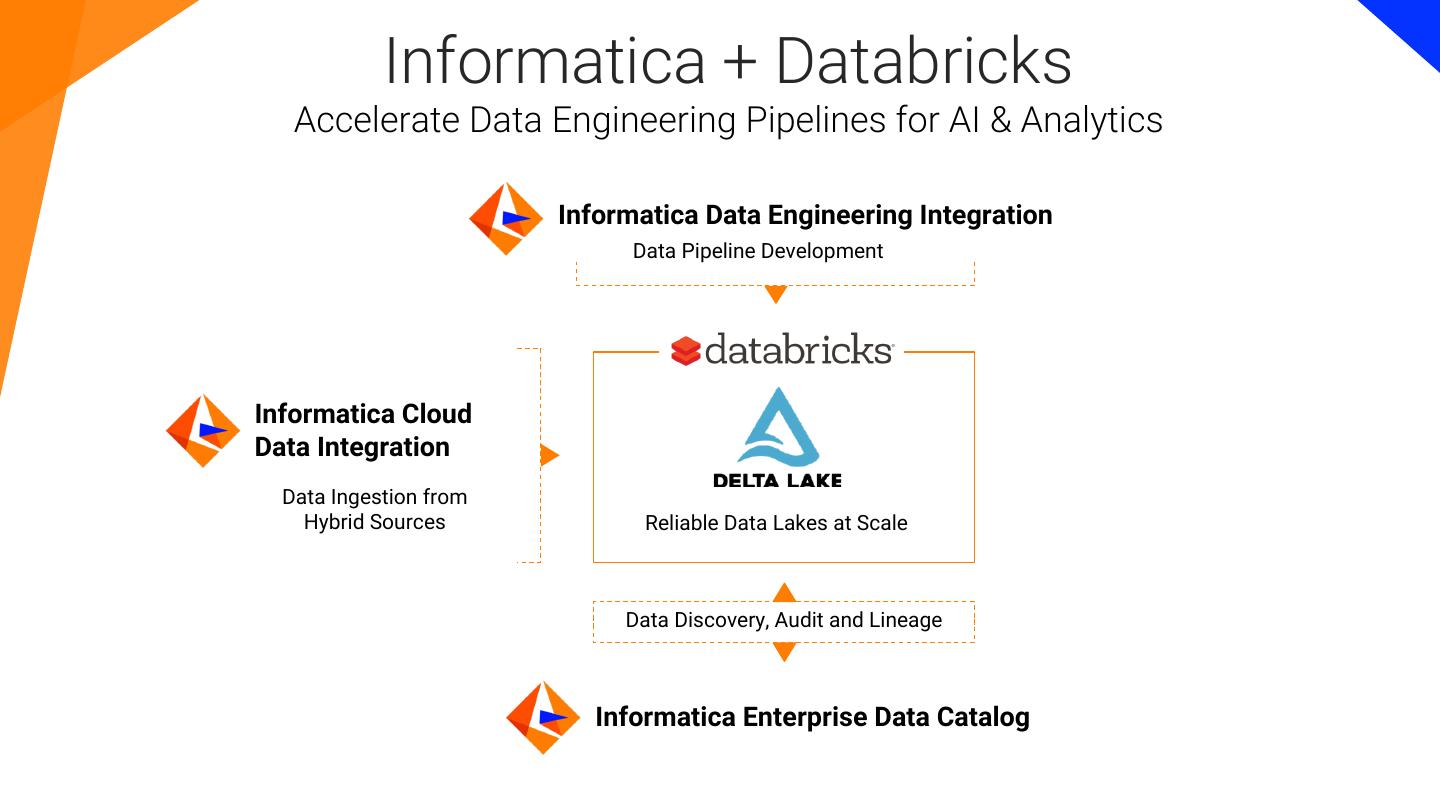
5 . Informatica + Databricks Accelerate Data Engineering Pipelines for AI & Analytics Informatica Data Engineering Integration Data Pipeline Development Informatica Cloud Data Integration Data Ingestion from Hybrid Sources Reliable Data Lakes at Scale Data Discovery, Audit and Lineage Informatica Enterprise Data Catalog
6 .Informatica Enterprise Data Catalog • Comprehensive discovery of data assets for accurate machine learning models • Easily find and discover trusted data for building machine learning models • Explore holistic data relationships • End-to-End data lineage through the analytics process • Integrated Business Glossary • Crowd-sourced curation of data assets • Machine-learning-based semantic inference and recommendations 6 © Informatica. Proprietary and Confidential.
7 .Informatica Data Engineering Portfolio Data Engineering Integration Data Engineering Streaming Data Engineering Quality Data Engineering Masking (DEI) (DES) (DEQ) (DEM) Intelligently manage Govern all your data on Spark De-identify, de-sensitize, and data pipelines for faster Turn volumes of streaming and in cloud and other anonymize sensitive data from insights. Data ingestion and IoT data into trusted insights environments to ensure it’s unauthorized access for app processing trusted and relevant users, BI, and AI & analytics The industry’s most comprehensive data engineering solution for multi-cloud & hybrid environments in Spark “true” serverless mode 7 © Informatica. Proprietary and Confidential.
8 .No Code, No Ops, No Limits On Data
9 .No Code: Leverage the Power of Easy-to-Use Interface DEI Mapping Spark Code package main.scala import org.apache.spark.sql.DataFrame import org.apache.spark.SparkContext import org.apache.spark.sql.functions.sum import org.apache.spark.sql.functions.udf /** * Query 3 * */ class Q03 extends TpchQuery { override def execute(sc: SparkContext, schemaProvider: TpchSchemaProvider): DataFrame = { // this is used to implicitly convert an RDD to a DataFrame. val sqlContext = new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._ import schemaProvider._ val decrease = udf { (x: Double, y: Double) => x * (1 - y) } val fcust = customer.filter($"c_mktsegment" === "BUILDING") val forders = order.filter($"o_orderdate" < "1995-03-15") val flineitems = lineitem.filter($"l_shipdate" > "1995-03-15") SQL Query fcust.join(forders, $"c_custkey" === forders("o_custkey")) .select($"o_orderkey", $"o_orderdate", $"o_shippriority") select l_orderkey, sum(l_extendedprice * (1 - .join(flineitems, $"o_orderkey" === flineitems("l_orderkey")) l_discount)) as revenue, o_orderdate, o_shippriority .select($"l_orderkey", from CUSTOMER, ORDERS, LINEITEM where decrease($"l_extendedprice", $"l_discount").as("volume"), $"o_orderdate", $"o_shippriority") c_mktsegment = 'AUTOMOBILE' and c_custkey = .groupBy($"l_orderkey", $"o_orderdate", $"o_shippriority") o_custkey and l_orderkey = o_orderkey and .agg(sum($"volume").as("revenue")) o_orderdate < date '1995-03-13' and l_shipdate > date .sort($"revenue".desc, $"o_orderdate") '1995-03-13' group by l_orderkey, o_orderdate, .limit(10) } o_shippriority order by revenue desc, o_orderdate limit } 10; Future proof your investments, design once 9 and run on best-of-breed engine © Informatica. Proprietary and Confidential.
10 .No Code: Schema Drift Handling Handle complex structure and its changes for both batch and streaming data 10 © Informatica. Proprietary and Confidential.
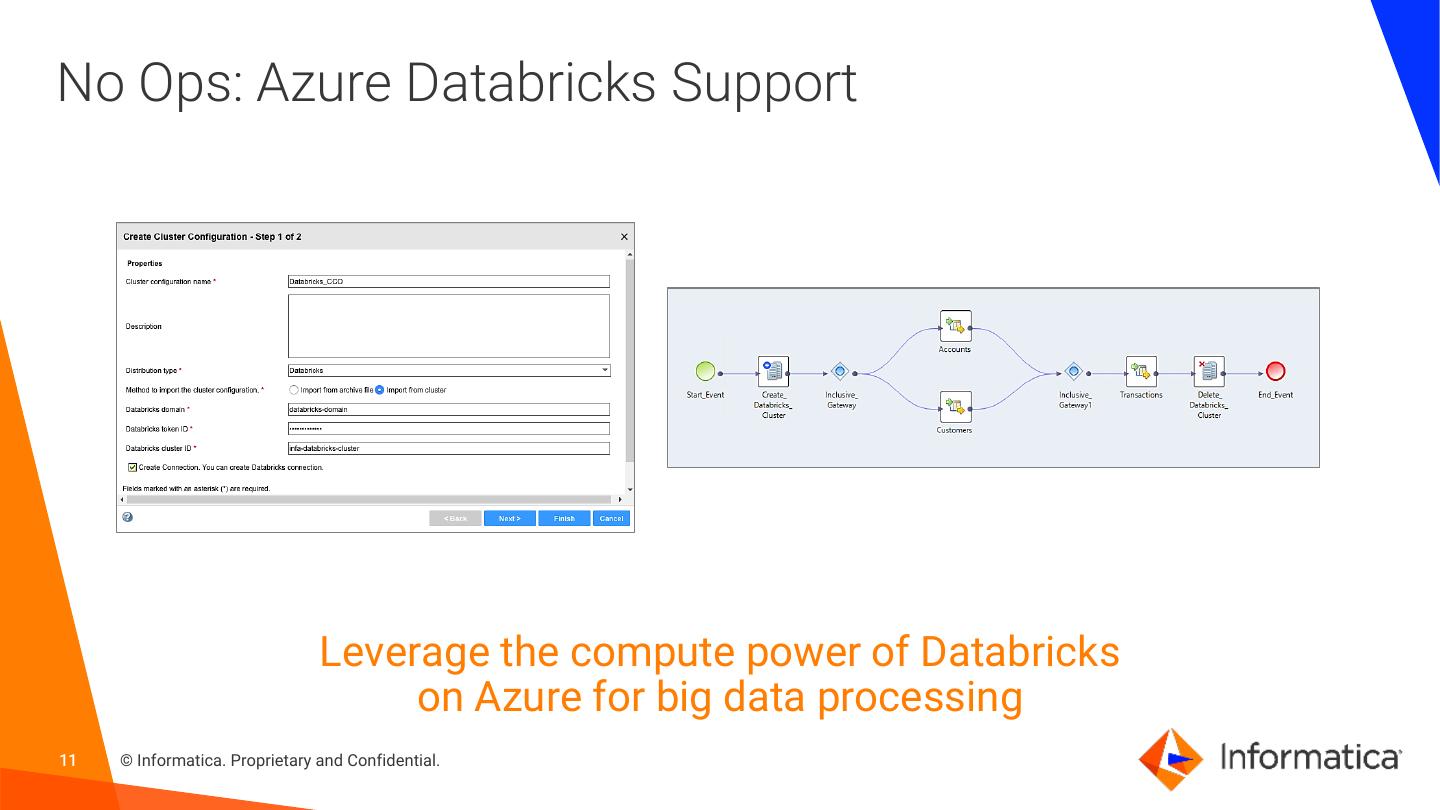
11 .No Ops: Azure Databricks Support Leverage the compute power of Databricks on Azure for big data processing 11 © Informatica. Proprietary and Confidential.
12 .No Ops: Advanced Spark Support Take advantage of latest innovation, performance, and scaling benefits 12 © Informatica. Proprietary and Confidential.
13 .No Ops: Operational Insights Deliver predictive operational insights about your data engineering environments 13 © Informatica. Proprietary and Confidential.
14 .No Limits on Data: Ingest Any Data in Real-time & Batch Mass ingestion of streaming/ IoT data, files, and databases 14 © Informatica. Proprietary and Confidential.
15 .No Limits on Data: High-Speed Mass Ingestion Rely on easy to use, fast, and scalable approach—no hand-coding 15 © Informatica. Proprietary and Confidential.
16 .No Limits on Data: Spark Structured Streaming Support Handle streaming data based on event time instead of processing time 16 © Informatica. Proprietary and Confidential.
17 .Cloud-Ready Reference Architecture Informatica + Azure Databricks ACQUIRE INGEST PREPARE CATALOG SECURE GOVERN ACCESS CONSUME CATALOG SEARCH PARSE MATCH LINEAGE RECOMMENDATIONS WEBLOGS DEVICE DATA Storage ADLS / blob Azure Databricks Storage ADLS / blob SQL Data RELATIONAL BLOB BLOB Warehouse 17 © Informatica. Proprietary and Confidential.
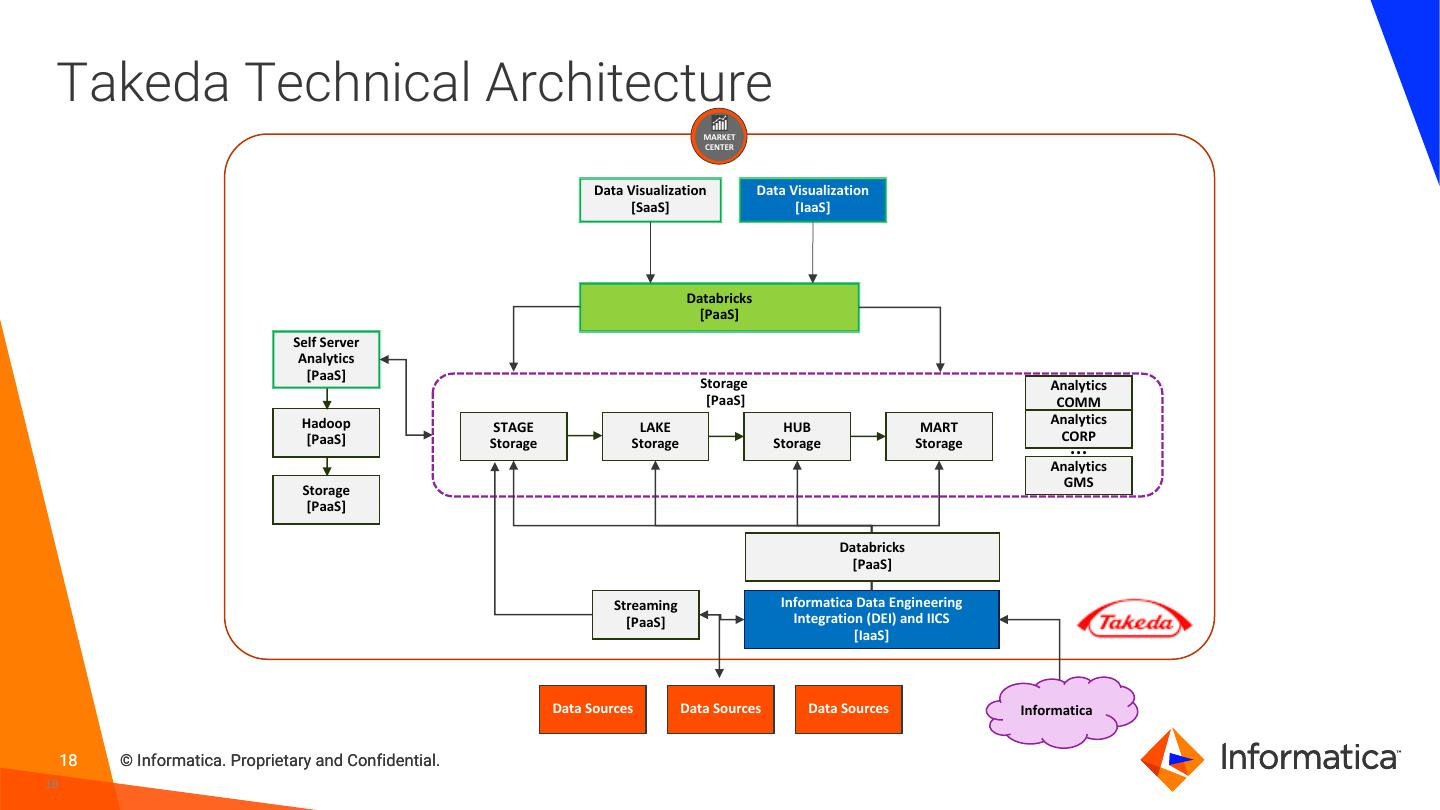
18 . Takeda Technical Architecture MARKET CENTER Data Visualization Data Visualization [SaaS] [IaaS] Databricks [PaaS] Self Server Analytics [PaaS] Storage Analytics [PaaS] COMM Hadoop Analytics STAGE LAKE HUB MART CORP [PaaS] Storage Storage Storage Storage … Analytics GMS Storage [PaaS] Databricks [PaaS] Streaming Informatica Data Engineering [PaaS] Integration (DEI) and IICS [IaaS] Data Sources Data Sources Data Sources Informatica 18 © Informatica. Proprietary and Confidential. 18
19 .Critical Success Factors of your AI/ML Projects 1 Find & discover data across all enterprise systems Accelerate movement of data to Databricks 2 3 Prepare & enrich the data before you start modeling Increase productivity with no-code UI for data engineering 4 5 Go serverless by processing data pipelines on Databricks 19 © Informatica. Proprietary and Confidential.
20 .Learn More 1. Stop by the Informatica booth #90 for a custom demo 2. Hear more about AI-Powered Streaming Analytics for Real-Time Customer Experience – Tomorrow 11:00am Room: E102 3. Visit http://www.informatica.com/databricks 4. Sign up for Hands-on Workshops on Serverless Cloud Data Lakes 20 © Informatica. Proprietary and Confidential.
21 .Thank You! Louis Polycarpou ` Technical Director Cloud, Data Engineering, and Data Integration
3秒后跳转登录页面
去登陆

