展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Title of Your Presentation
Stream, Stream, Stream
Goes Here
Different Streaming methods with Spark and Kafka
Your Name,Nielsen
Itai Yaffe, Your Organization
#UnifiedDataAnalytics #SparkAISummit
#UnifiedDataAnalytics #SparkAISummit
�
3 .Introduction
Itai Yaffe
● Tech Lead, Big Data group
● Dealing with Big Data
challenges since 2012
�
4 .Introduction - part 2 (or: “your turn…”)
● Data engineers? Data architects? Something else?
● Working with Spark? Planning to?
● Working Kafka? Planning to?
�
5 .Agenda
Nielsen Marketing Cloud (NMC)
○ About
○ High-level architecture
Data flow - past and present
Spark Streaming
○ ”Stateless” and ”stateful” use-cases
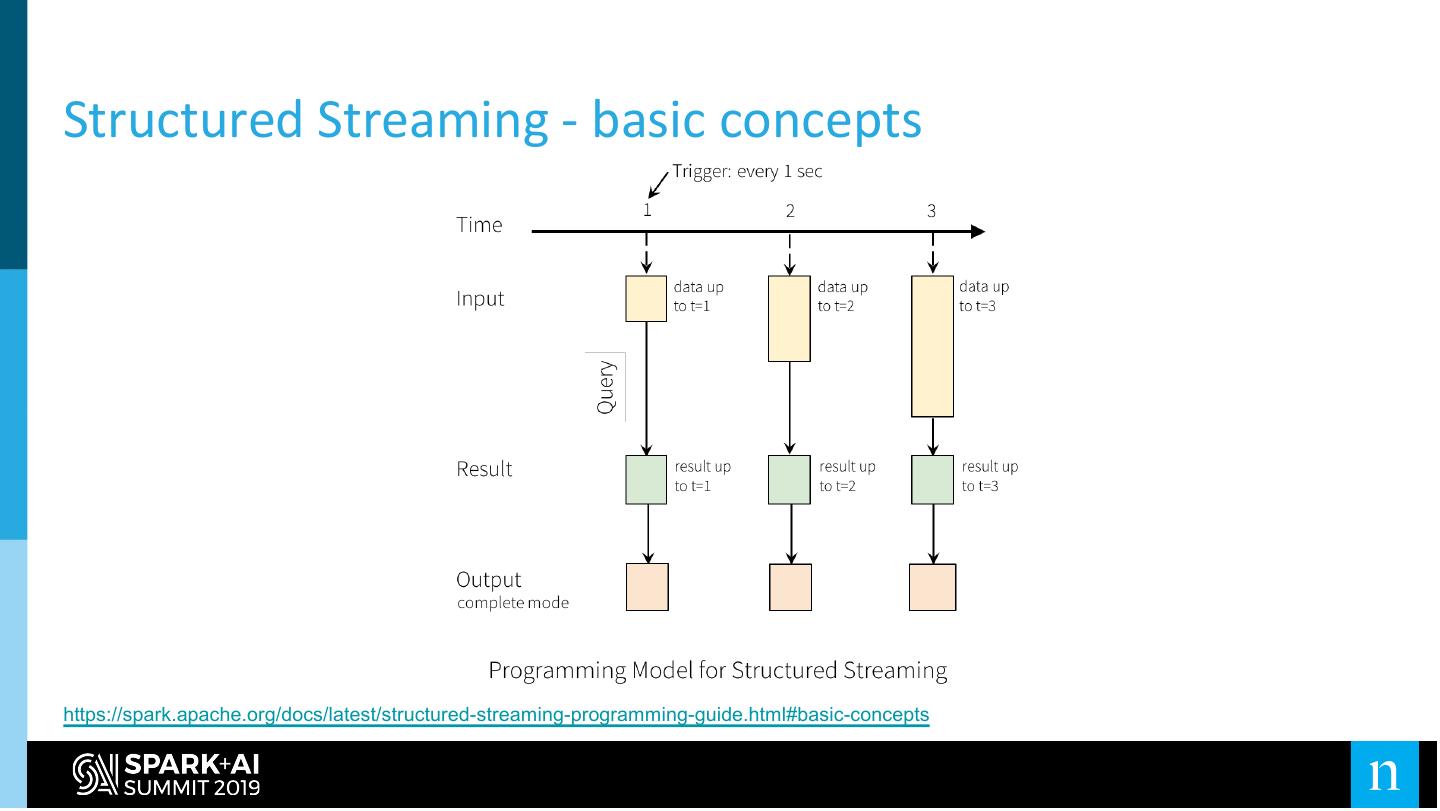
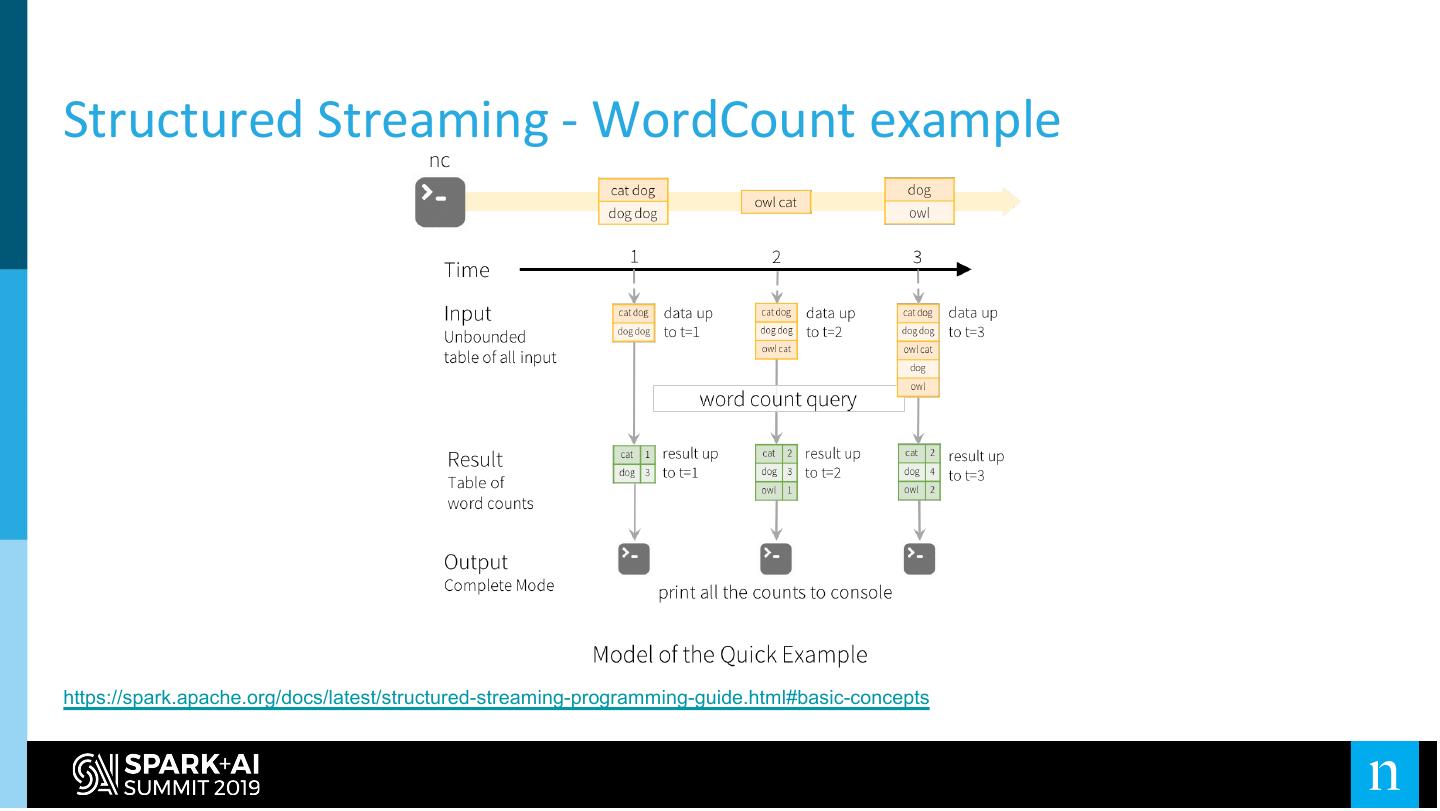
Spark Structured Streaming
”Streaming” over our Data Lake
�
6 .Nielsen Marketing Cloud (NMC)
● eXelate was acquired by Nielsen on March 2015
● A Data company
● Machine learning models for insights
● Targeting
● Business decisions
�
7 .Nielsen Marketing Cloud - questions we try to answer
1. How many unique users of a certain profile can we reach?
E.g campaign for young women who love tech
2. How many impressions a campaign received?
�
8 .Nielsen Marketing Cloud - high-level architecture
�
9 .Data flow in the old days...
OLAP
In-DB aggregation
�
10 .Data flow in the old days… What’s wrong with that?
● CSV-related issues, e.g:
○ Truncated lines in input files
○ Can’t enforce schema
● Scale-related issues, e.g:
○ Had to “manually” scale the processes
�
11 .That's one small step for [a] man… (2014)
OLAP
In-DB aggregation
“Apache Spark is the Taylor Swift of big data software" (Derrick Harris, Fortune.com, 2015)
�
12 .Why just a small step?
● Solved the scaling issues
● Still faced the CSV-related issues
�
13 .Data flow - the modern way
+
Photography Copyright: NBC
�
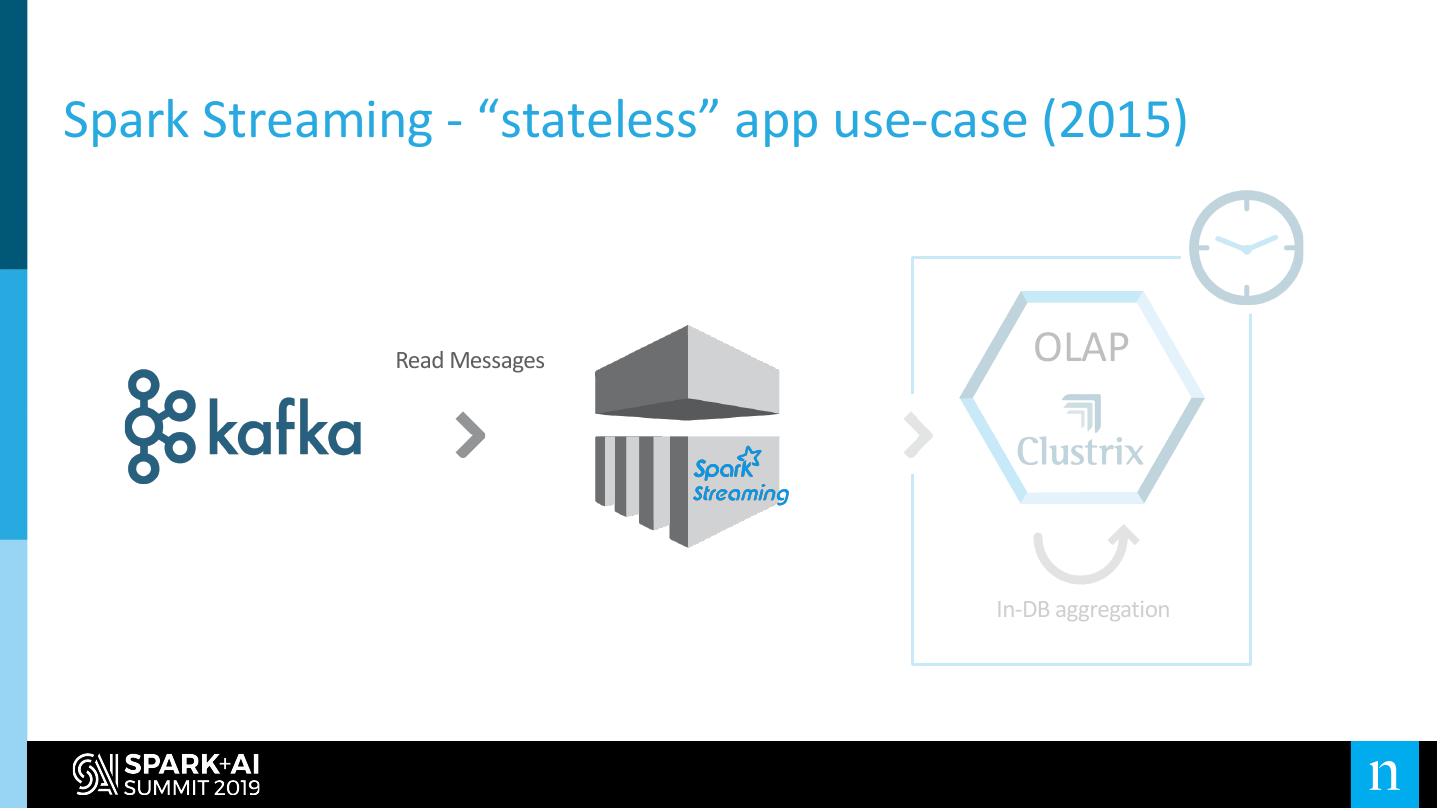
14 .Spark Streaming - “stateless” app use-case (2015)
Read Messages OLAP
In-DB aggregation
�
15 .The need for stateful streaming
Fast forward a few months...
● New requirements were being raised
● Specific use-case :
○ To take the load off of the operational DB (used both as OLTP and OLAP), we wanted to move most of
the aggregative operations to our Spark Streaming app
�
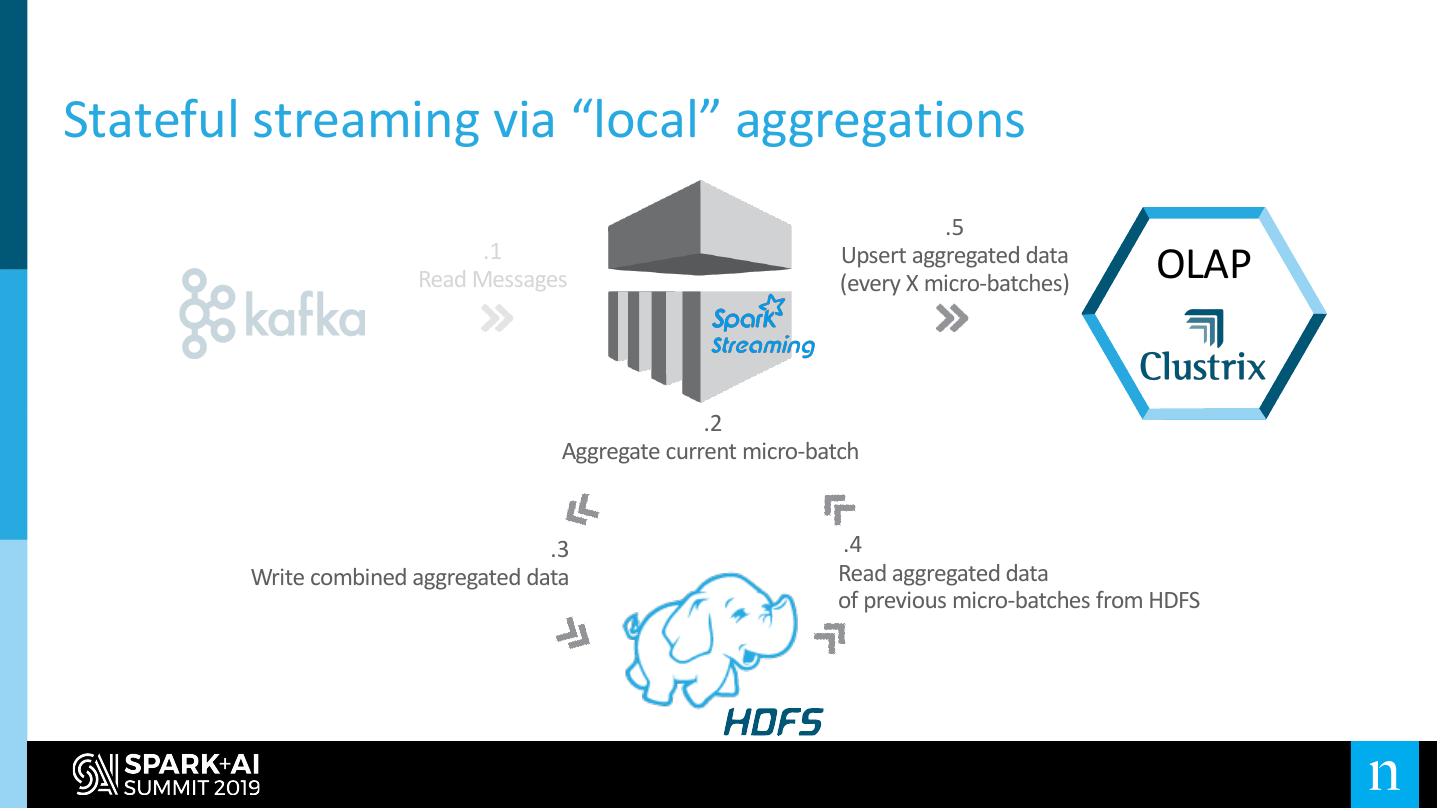
16 .Stateful streaming via “local” aggregations
.5
.1
Read Messages
Upsert aggregated data
(every X micro-batches)
OLAP
.2
Aggregate current micro-batch
.3 .4
Write combined aggregated data Read aggregated data
of previous micro-batches from HDFS
�
17 .Stateful streaming via “local” aggregations
● Required us to manage the state on our own
● Error-prone
○ E.g what if my cluster is terminated and data on HDFS is lost?
● Complicates the code
○ Mixed input sources for the same app (Kafka + files)
● Possible performance impact
○ Might cause the Kafka consumer to lag
�
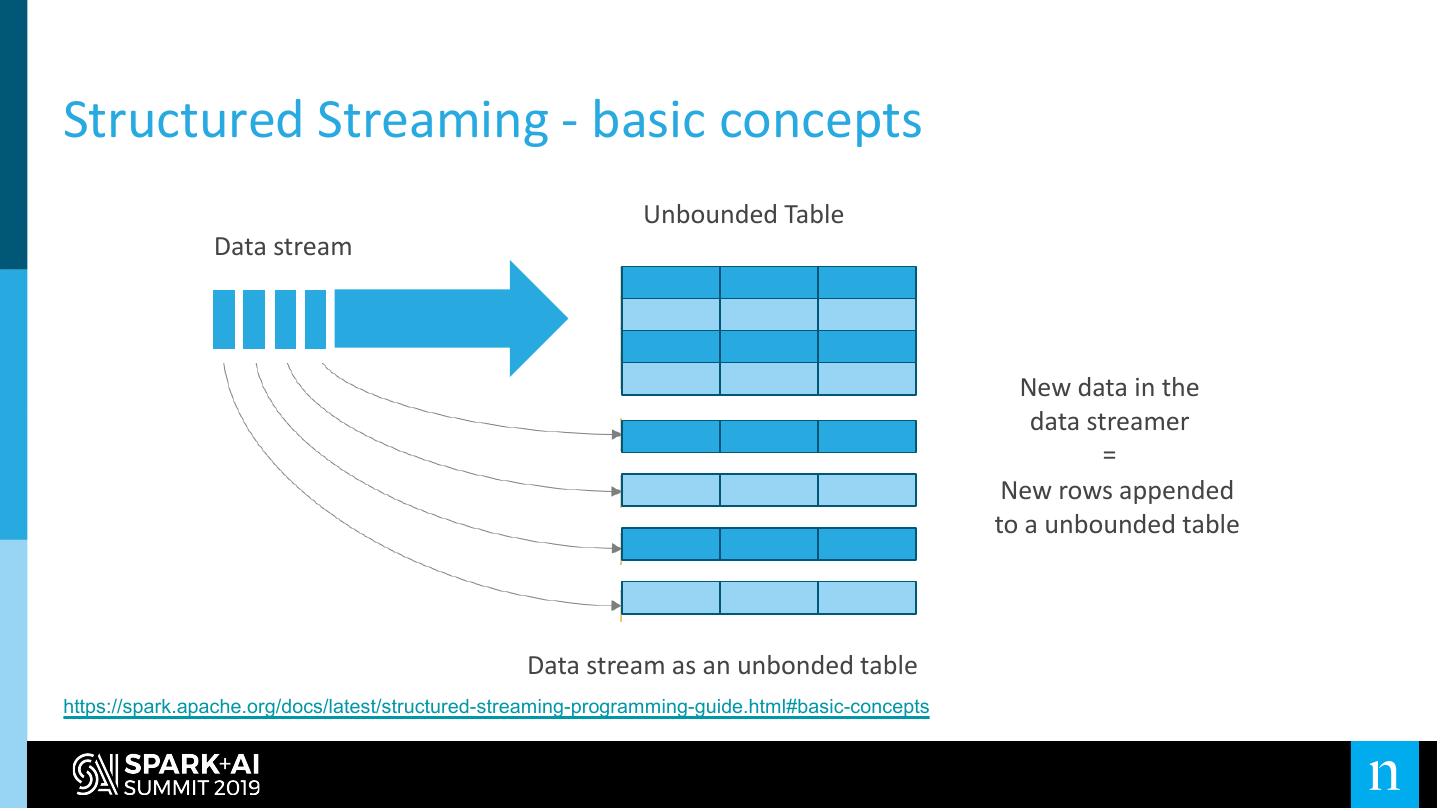
18 .Structured Streaming - to the rescue?
Spark 2.0 introduced Structured Streaming
● Enables running continuous, incremental processes
○ Basically manages the state for you
● Built on Spark SQL
○ DataFrame/Dataset API
○ Catalyst Optimizer
● Many other features
● Was in ALPHA mode in 2.0 and 2.1
Structured Streaming
�
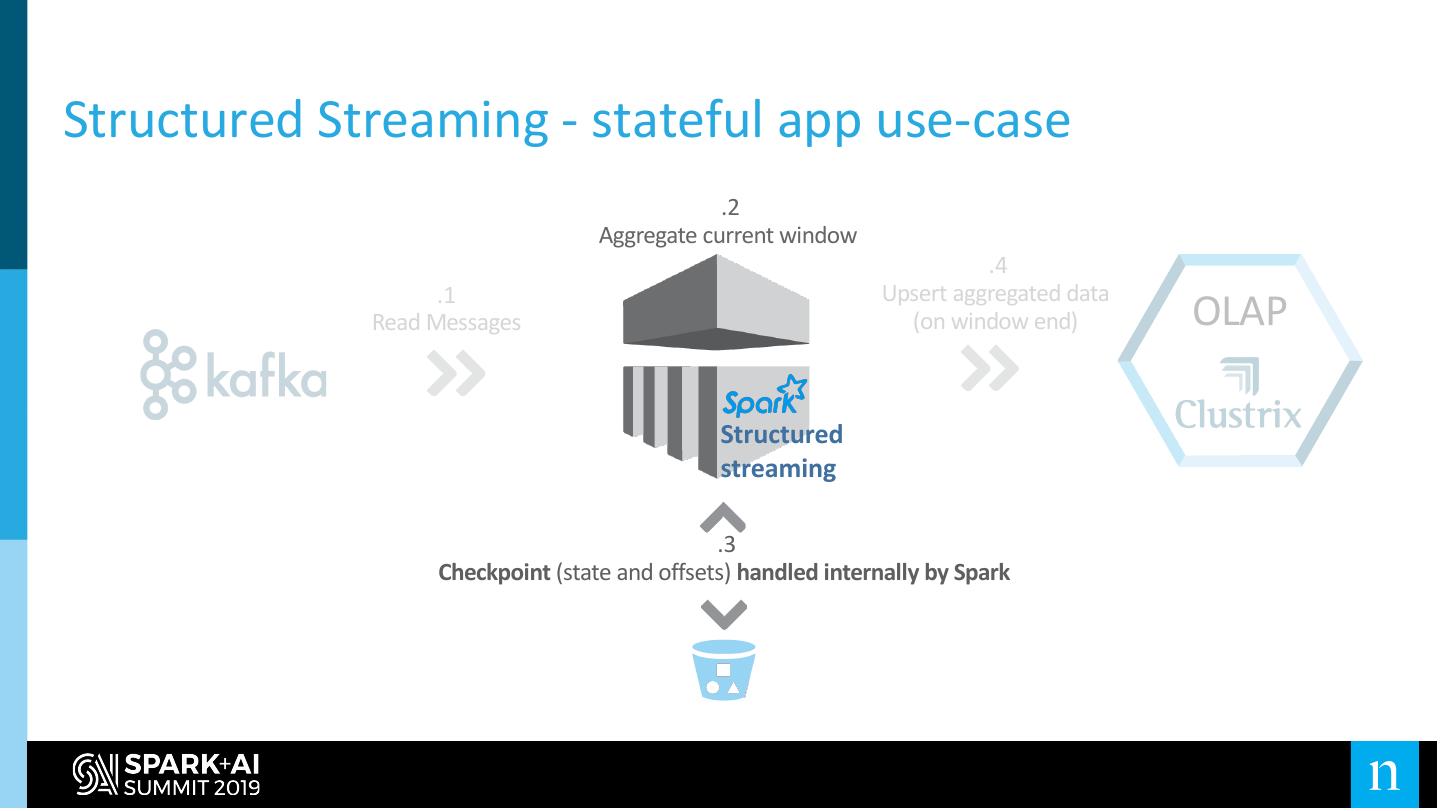
19 .Structured Streaming - stateful app use-case
.2
Aggregate current window
.4
.1 Upsert aggregated data
Read Messages (on window end) OLAP
Structured
streaming
.3
Checkpoint (state and offsets) handled internally by Spark
�
20 .Structured Streaming - known issues & tips
● 3 major issues we had in 2.1.0 (solved in 2.1.1) :
○ https://issues.apache.org/jira/browse/SPARK-19517
○ https://issues.apache.org/jira/browse/SPARK-19677
○ https://issues.apache.org/jira/browse/SPARK-19407
● Checkpointing to S3 wasn’t straight-forward
○ Tried using EMRFS consistent view
■ Worked for stateless apps
■ Encountered sporadic issues for stateful apps
�
21 .Structured Streaming - strengths and weaknesses (IMO)
● Strengths include:
○ Running incremental, continuous processing
○ Increased performance (e.g via Catalyst SQL optimizer)
○ Massive efforts are invested in it
● Weaknesses were mostly related to maturity
�
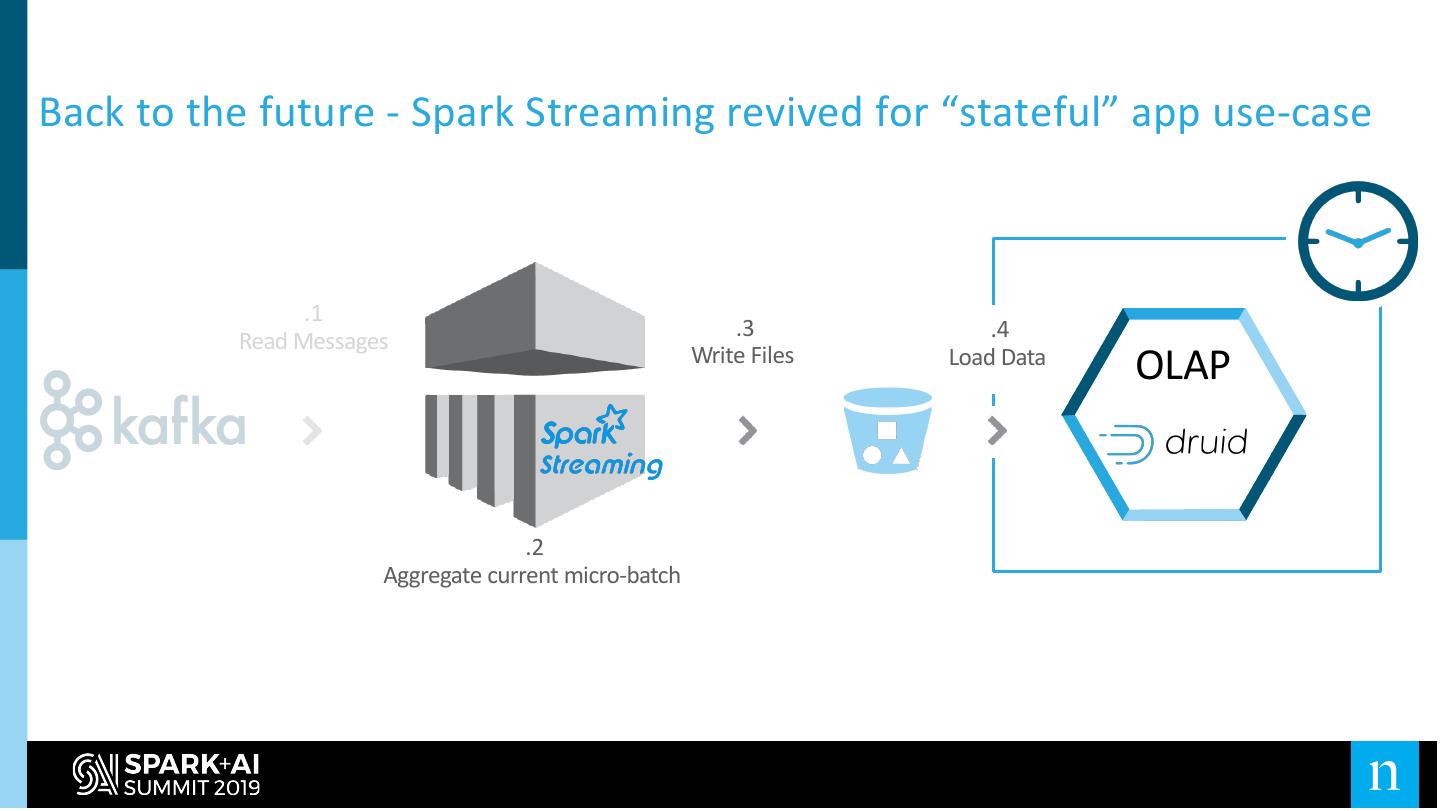
22 .Back to the future - Spark Streaming revived for “stateful” app use-case
.1
.3 .4
Read Messages
Write Files Load Data
OLAP
.2
Aggregate current micro-batch
�
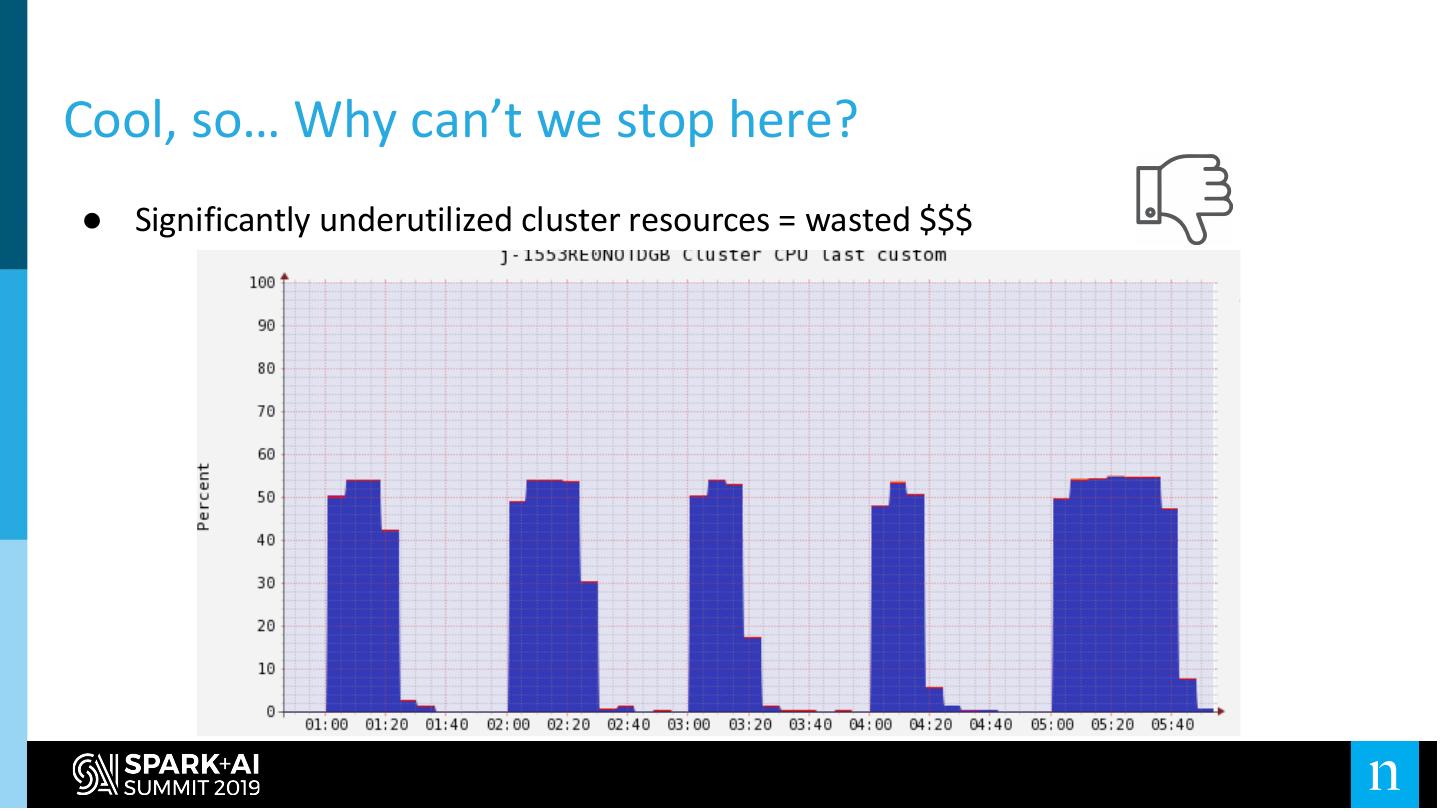
23 .Cool, so… Why can’t we stop here?
● Significantly underutilized cluster resources = wasted $$$
�
24 .Cool, so… Why can’t we stop here? (cont.)
● Extreme load of Kafka brokers’ disks
○ Each micro-batch needs to read ~300M messages, Kafka can’t store it all in memory
● ConcurrentModificationException when using Spark Streaming + Kafka 0.10 integration
○ Forced us to use 1 core per executor to avoid it
○ https://issues.apache.org/jira/browse/SPARK-19185 supposedly solved in 2.4.0 (possibly solving
https://issues.apache.org/jira/browse/SPARK-22562 as well)
● We wish we could run it even less frequently
○ Remember - longer micro-batches result in a better aggregation ratio
�
25 .Introducing RDR
RDR (or Raw Data Repository) is our Data Lake
● Kafka topic messages are stored on S3 in Parquet format
partitioned by date (date=2019-10-17)
● RDR Loaders - stateless Spark Streaming applications
● Applications can read data from RDR for various use-cases
○ E.g analyzing data of the last 1 day or 30 days
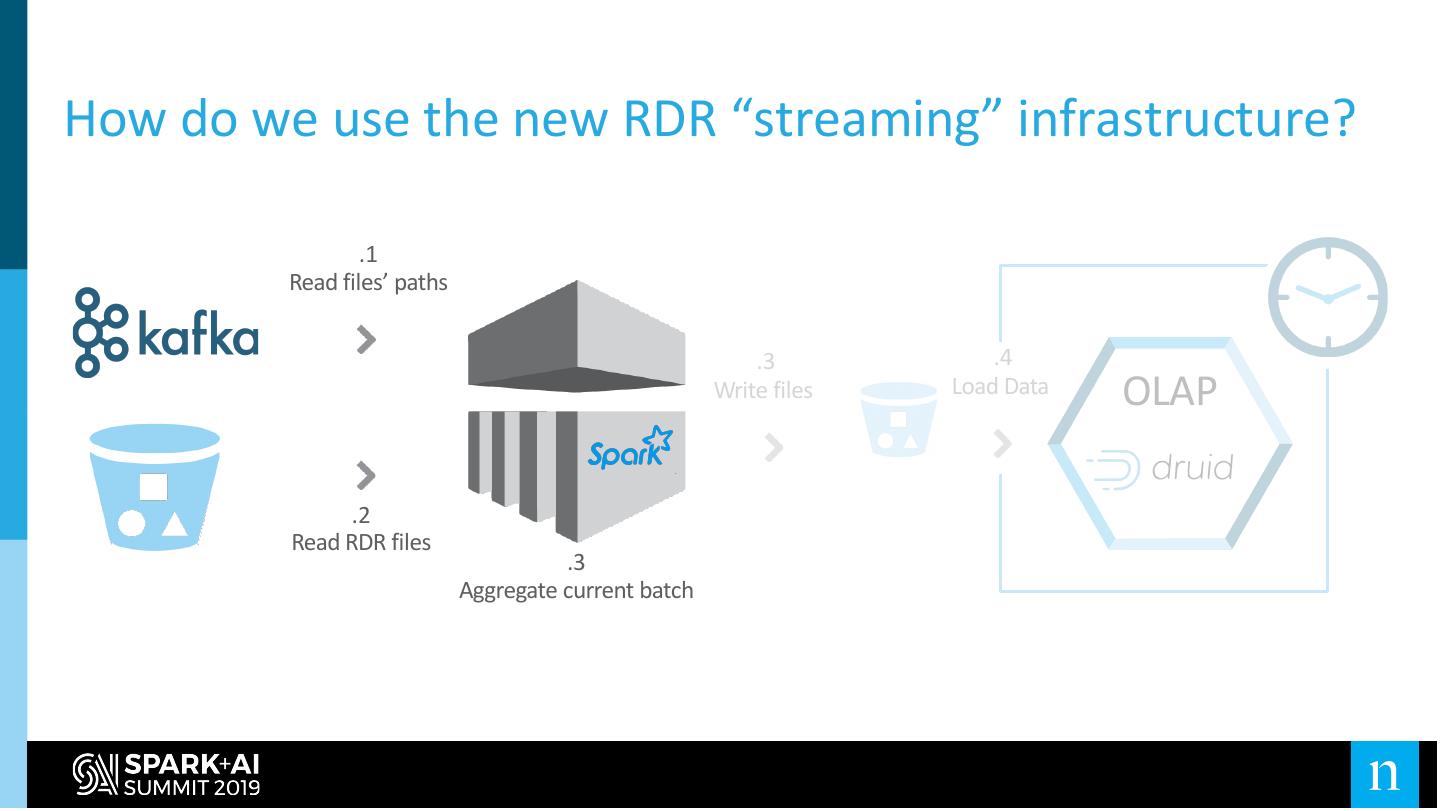
Can we leverage our Data Lake and use it as the data source (instead of Kafka)?
�
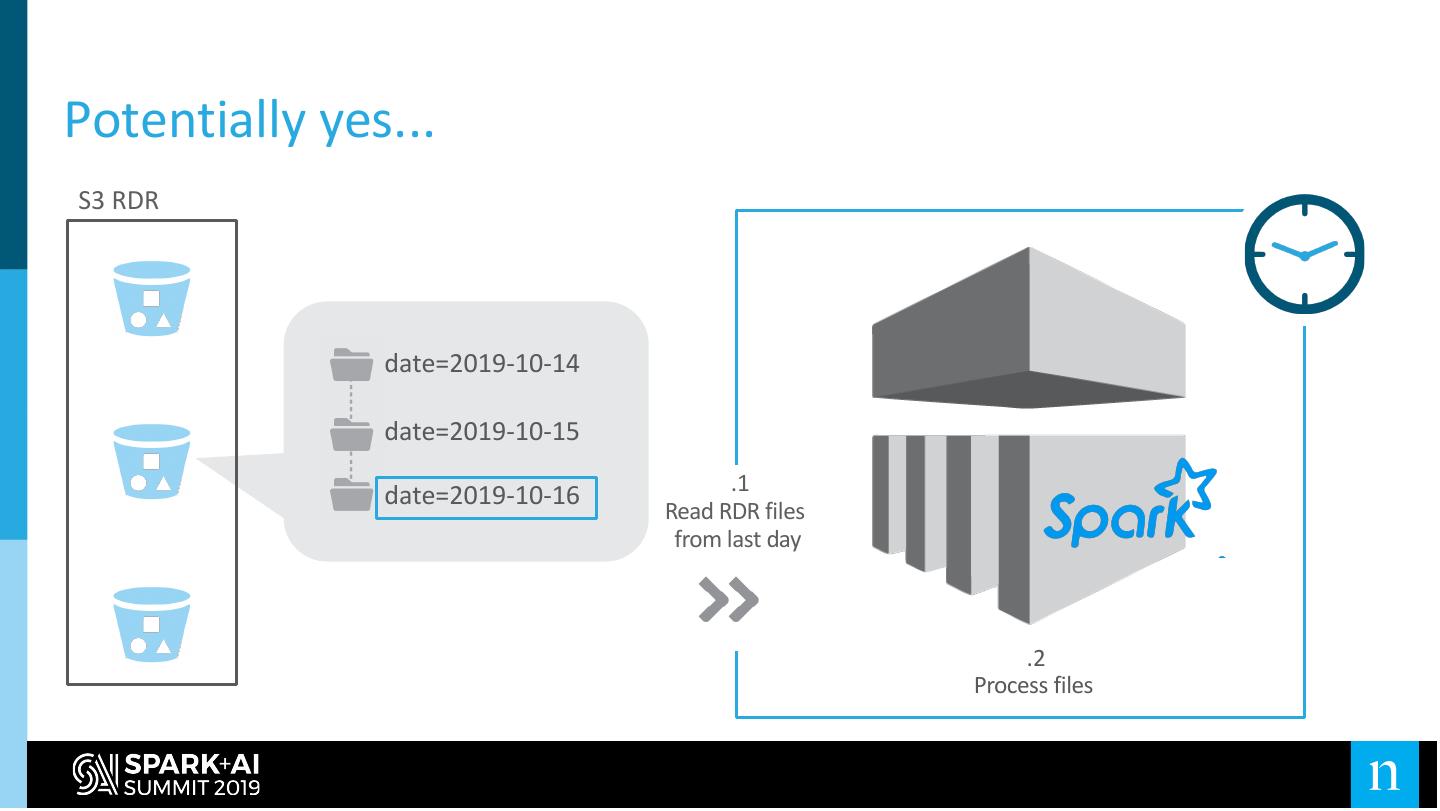
26 .Potentially yes...
S3 RDR
date=2019-10-14
date=2019-10-15
.1
date=2019-10-16
Read RDR files
from last day
.2
Process files
�
27 .... but
● This ignores late arriving events
�
28 .Enter “streaming” over RDR
+ +
�
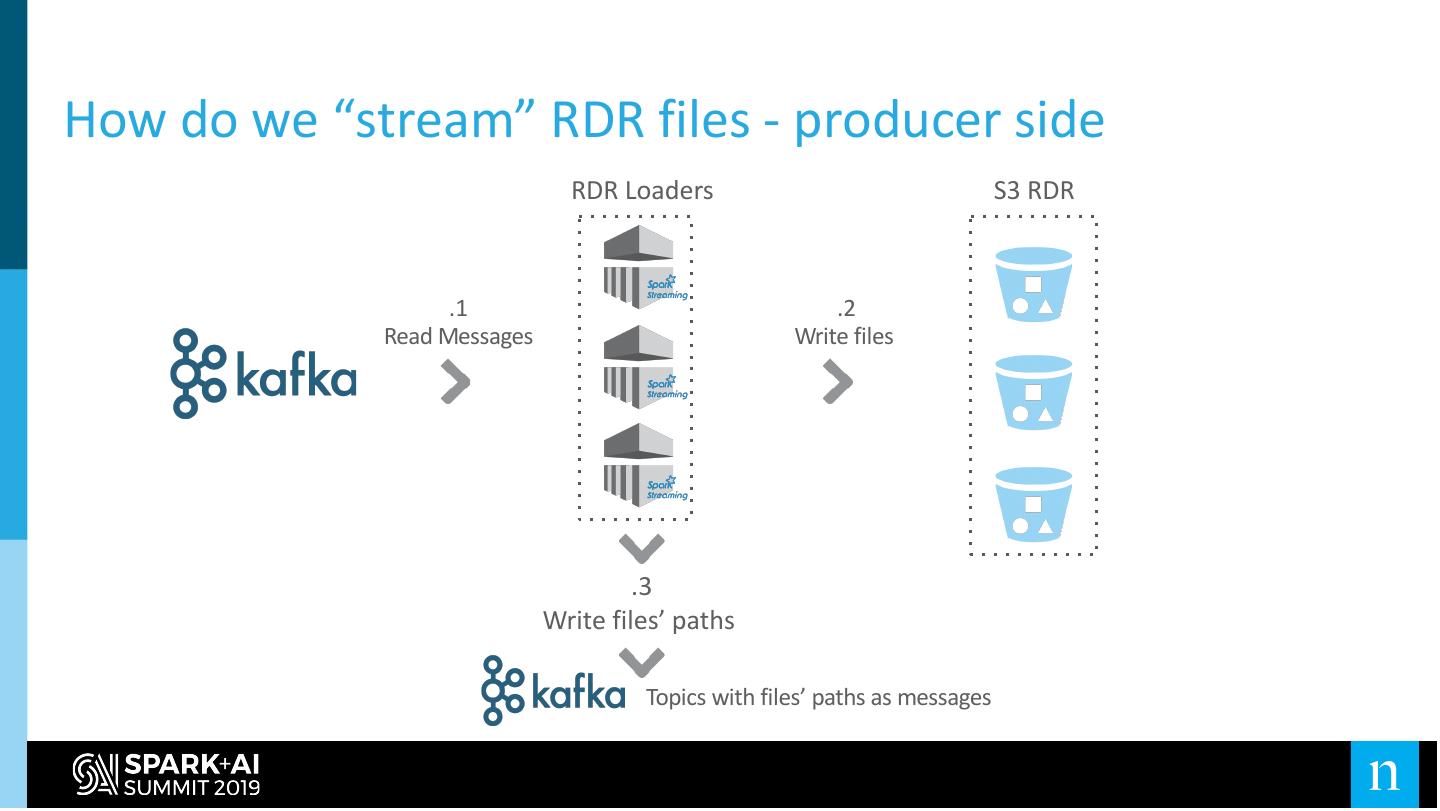
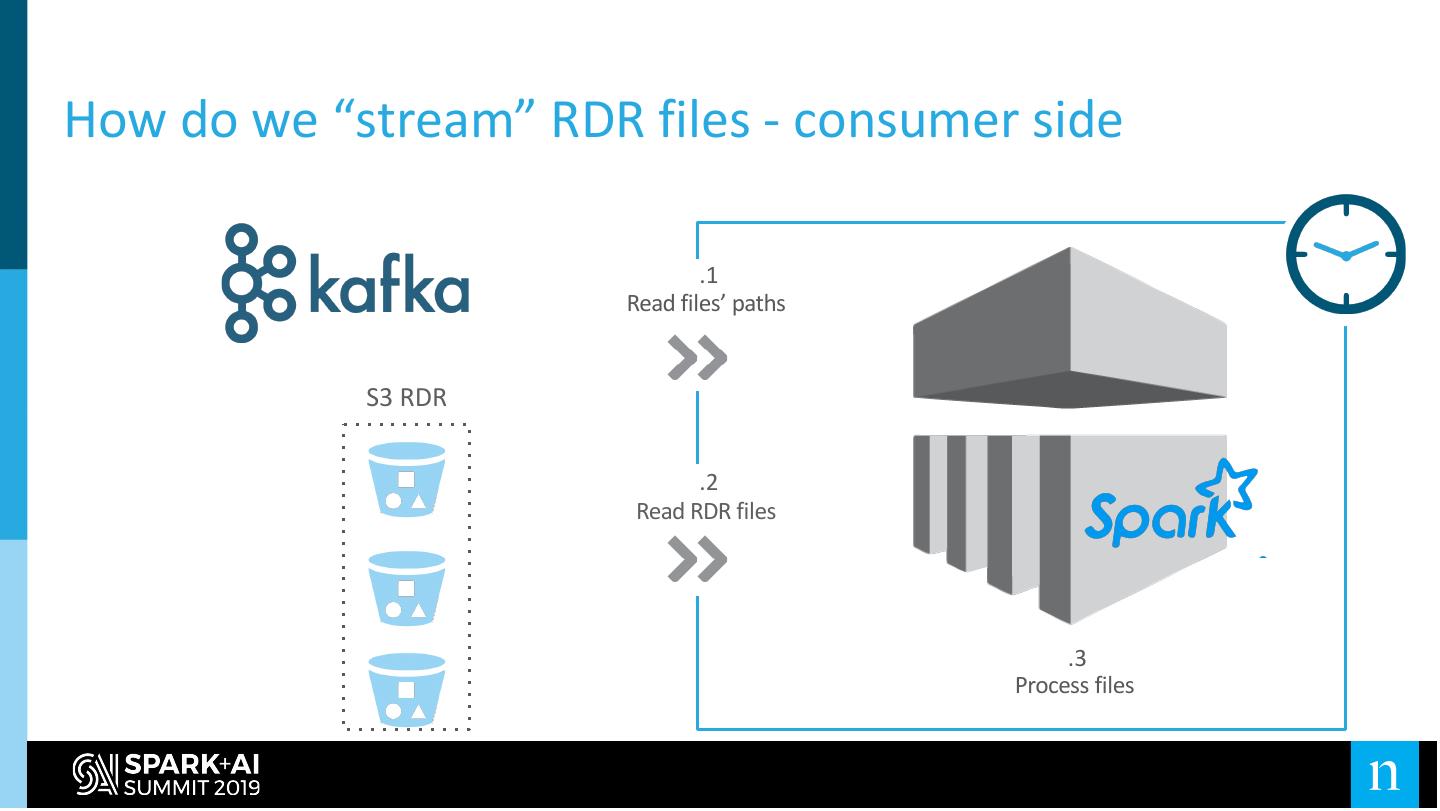
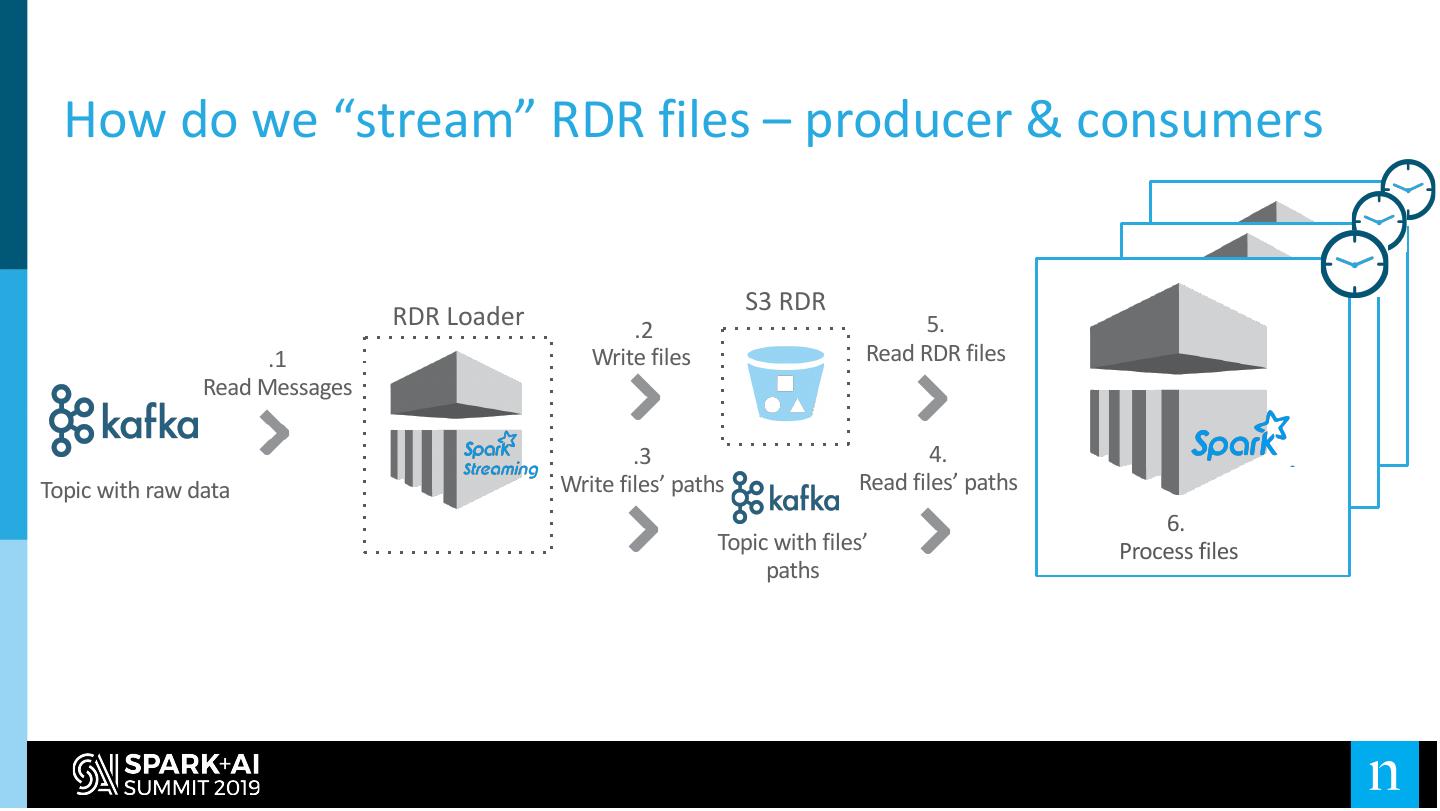
29 .How do we “stream” RDR files - producer side
RDR Loaders S3 RDR
.1 .2
Read Messages Write files
.3
Write files’ paths
Topics with files’ paths as messages
�