Stream processing - choosing the right tool for the job
分享
点赞
6
收藏
2
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
Due to the increasing interest in real-time processing, many stream processing frameworks were developed. However, no clear guidelines have been established for choosing a framework for a specific use case. In this talk, two different scenarios are taken and the audience is guided through the thought process and questions that one should ask oneself when choosing the right tool. The stream processing frameworks that will be discussed are Spark Streaming, Structured Streaming, Flink and Kafka Streams.
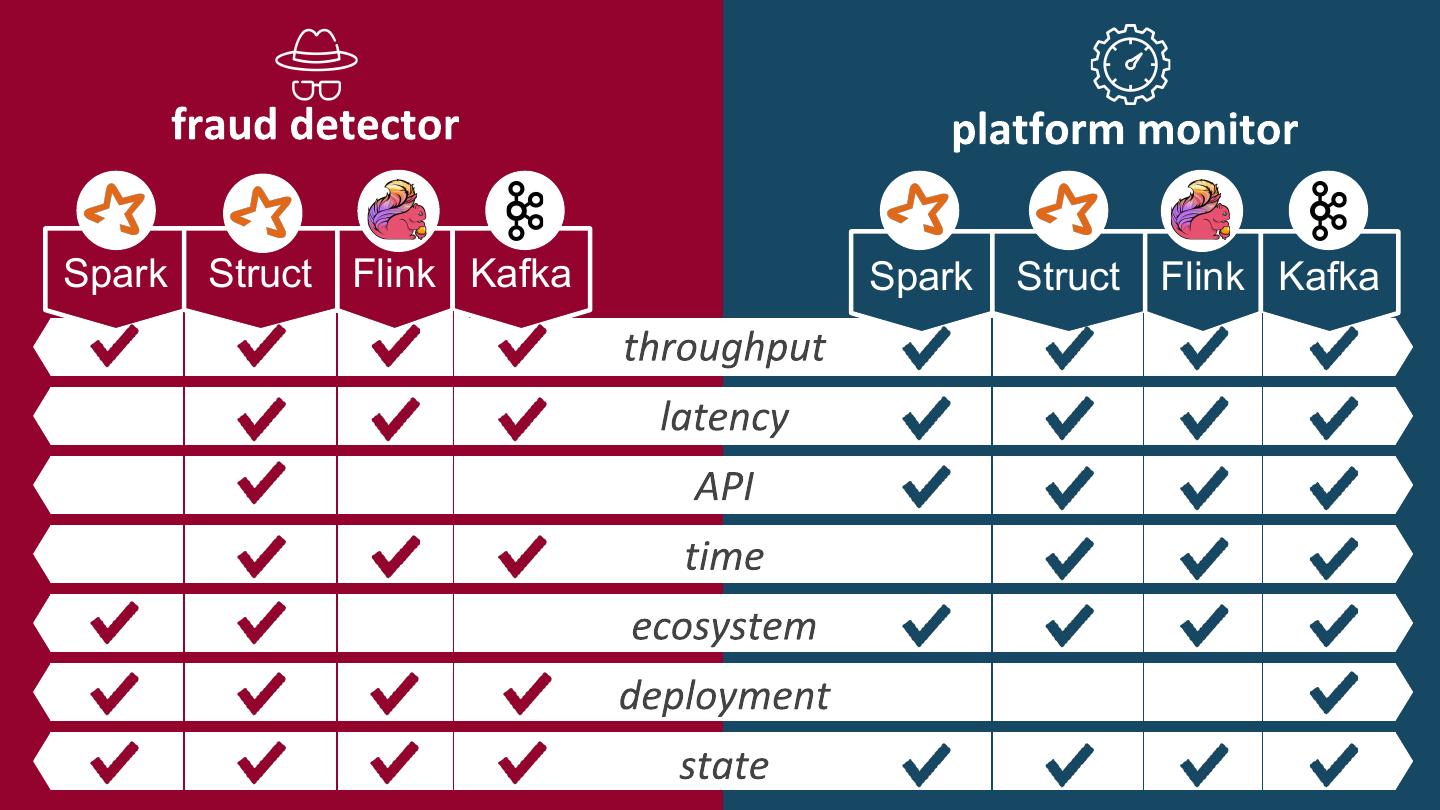
The main questions are:
How much data does it need to process? (throughput)
Does it need to be fast? (latency)
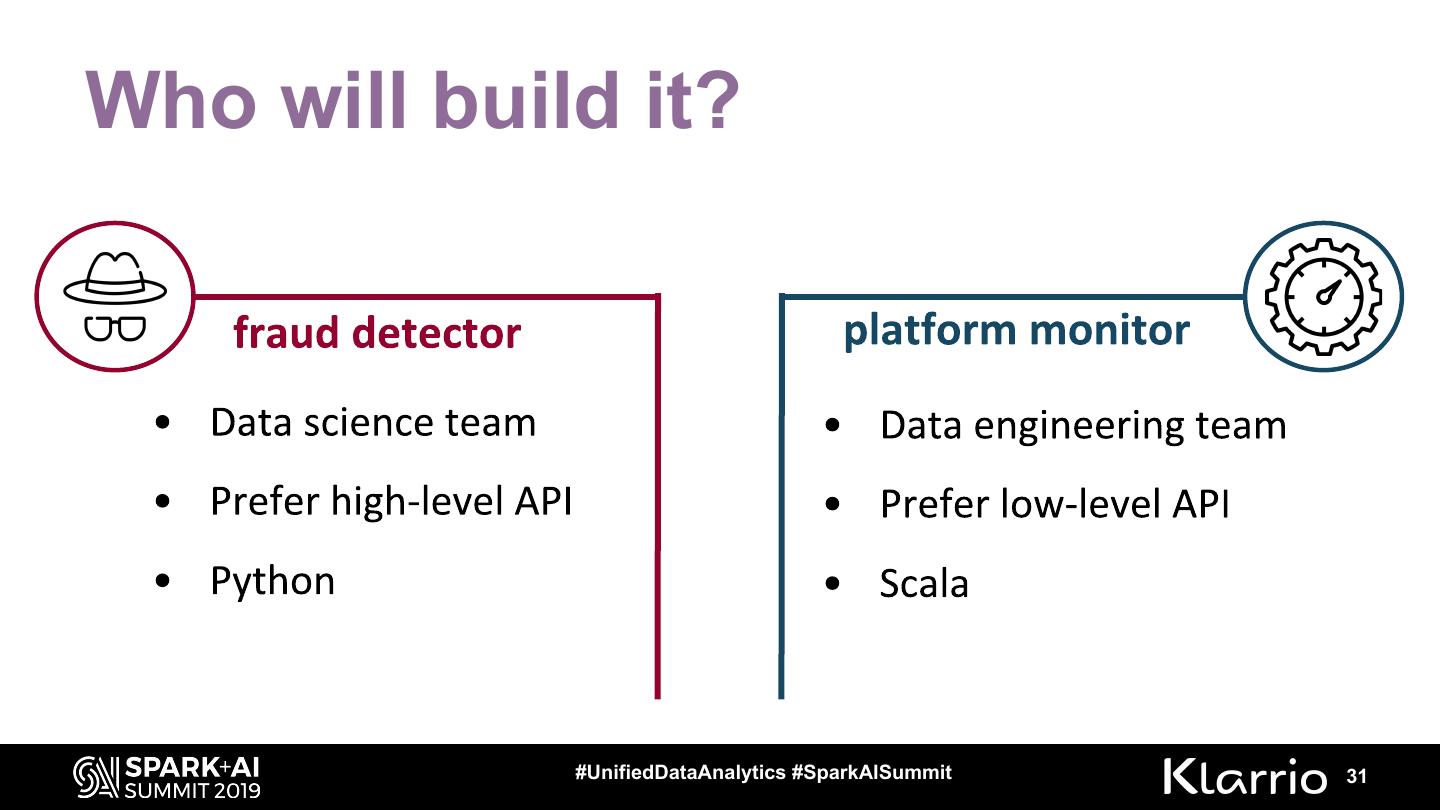
Who will build it? (supported languages, level of API, SQL capabilities, built-in windowing and joining functionalities, etc)
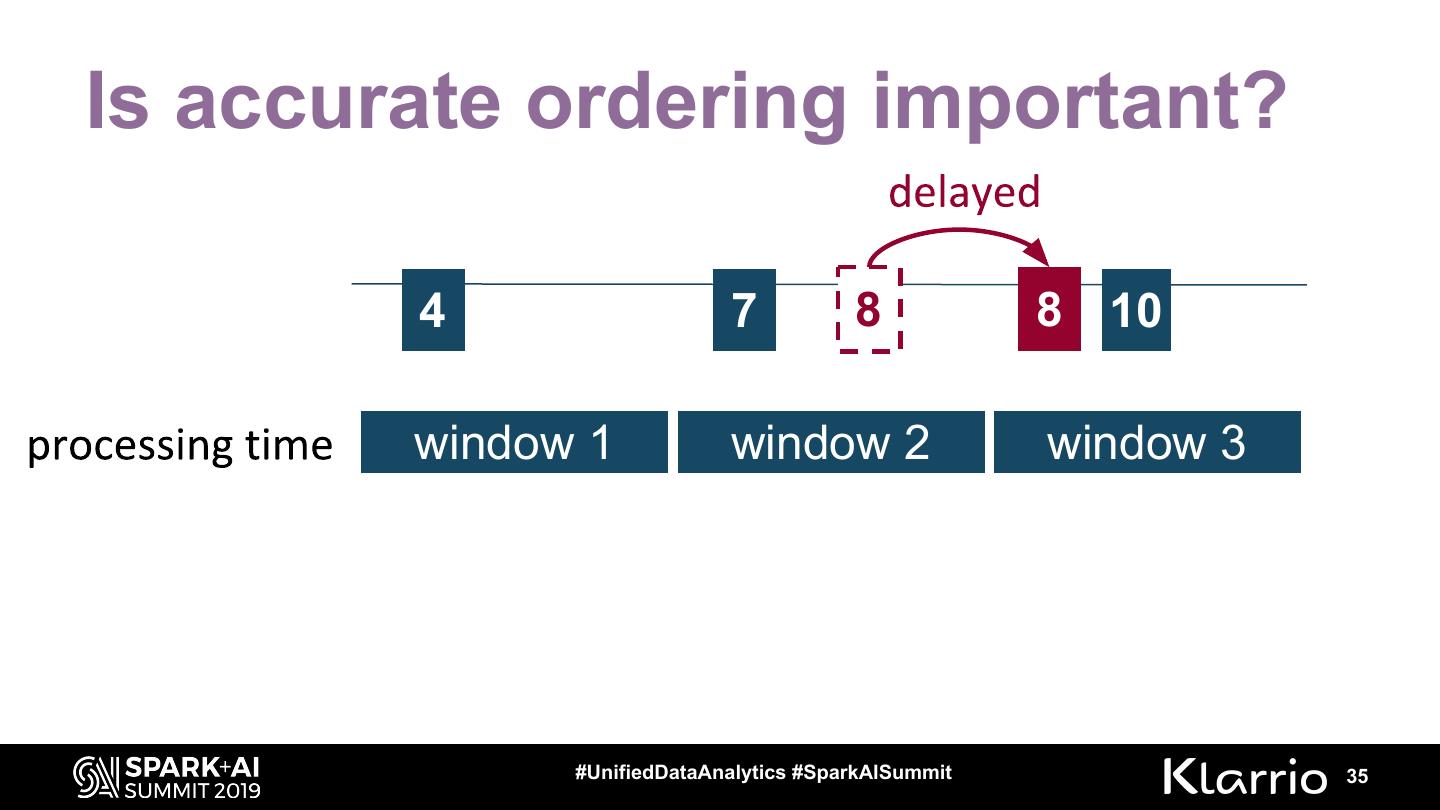
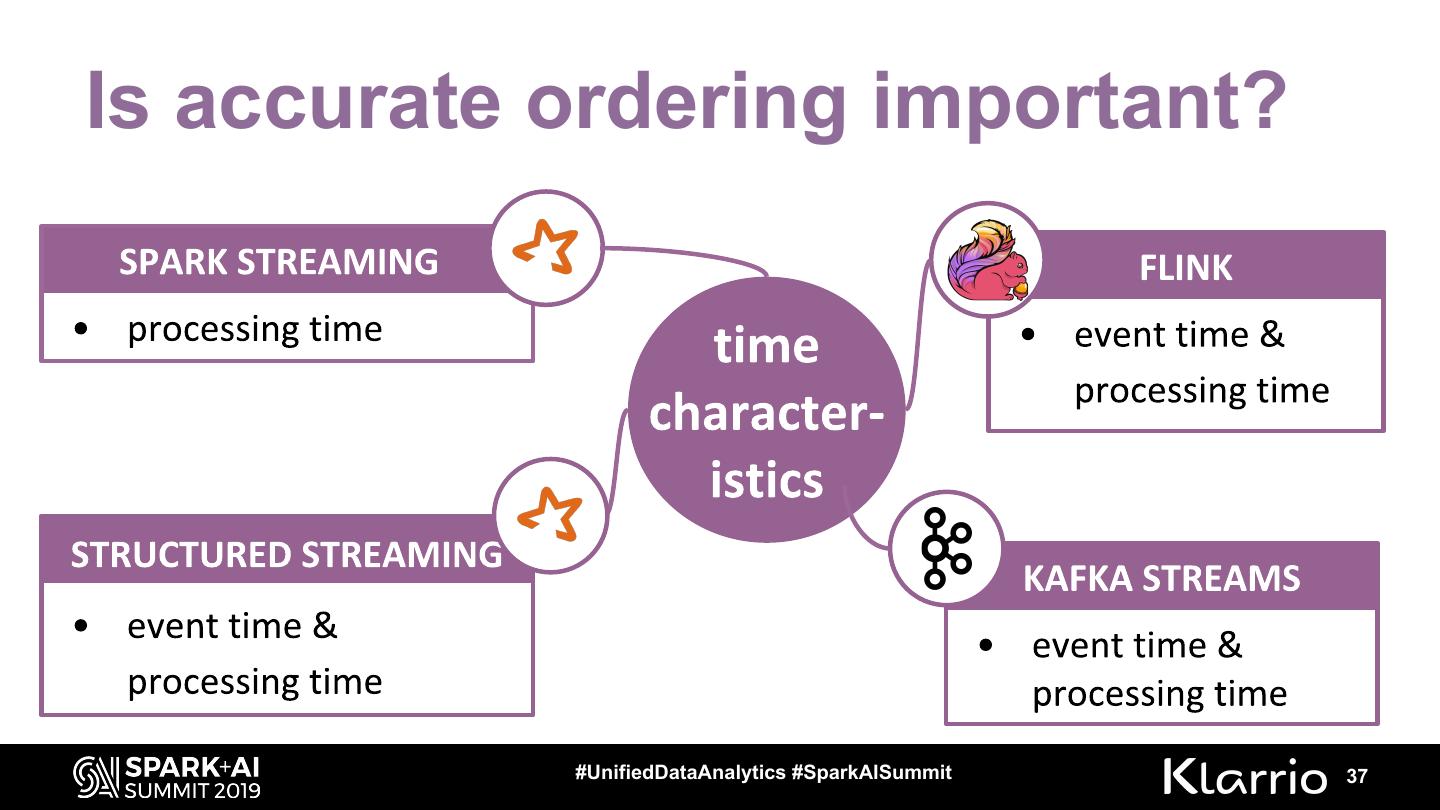
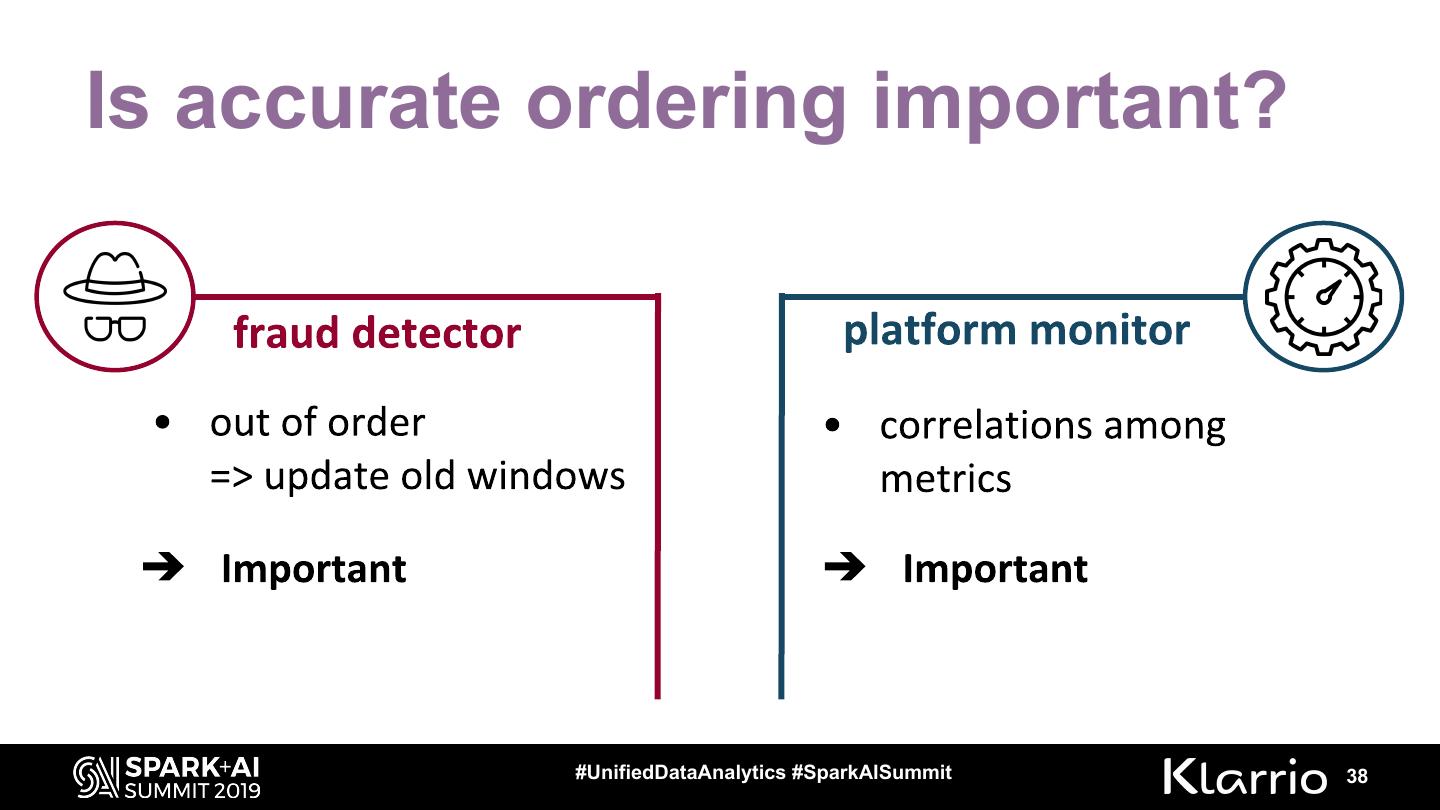
Is accurate ordering important? (event time vs. processing time)
Is there a batch component? (integration of batch API)
How do we want it to run? (deployment options: standalone, YARN, mesos, …)
How much state do we have? (state store options) – What if a message gets lost? (message delivery guarantees, checkpointing).
For each of these questions, we look at how each framework tackles this and what the main differences are. The content is based on the PhD research of Giselle van Dongen in benchmarking stream processing frameworks in several scenarios using latency, throughput and resource utilization.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Stream processing:
choosing the right tool for
the job
Giselle van Dongen,
#UnifiedDataAnalytics #SparkAISummit
�
3 . ●
●
○
○
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Context
…
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Context
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Context
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Disclaimer
a.k.a I will not pick a stream processing framework for you
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Commonalities
●
●
●
●
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Imagine...
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .#UnifiedDataAnalytics #SparkAISummit 10
�
11 .#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Do we need stream processing?
…
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Do we need stream processing?
…
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .#UnifiedDataAnalytics #SparkAISummit 14
�
15 .#UnifiedDataAnalytics #SparkAISummit 15
�
16 .#UnifiedDataAnalytics #SparkAISummit 16
�
17 .How much data?
➔
➔
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .How much data?
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Spark Struct Flink Kafka Spark Struct Flink Kafka
�
20 .#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Does it need to be fast?
➔ ➔
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .Does it need to be fast?
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Does it need to be fast?
●
…
●
●
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .Event-driven
https://www.cakesolutions.net/teamblogs/comparison-of-apache-stream-processing-frameworks-part-1
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .Micro-batching
https://www.cakesolutions.net/teamblogs/comparison-of-apache-stream-processing-frameworks-part-1
#UnifiedDataAnalytics #SparkAISummit 25
�
26 .Does it need to be fast?
●
➔
➔
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Spark Struct Flink Kafka Spark Struct Flink Kafka
�
28 .#UnifiedDataAnalytics #SparkAISummit 28
�
29 . Performance
Advanced features
Deployment & Internals
#UnifiedDataAnalytics #SparkAISummit 29
�