


































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark Structured Streaming with Delta
本次分享分别从Structured Streaming与Delta Lake的设计原理和目标出发,解析如何通过有机结合二者构建稳定易用的流式计算引擎,并对最新发布的Delta Lake 0.6.0版本新功能做重点介绍。
展开查看详情
1 .Spark Structured Streaming with Delta Yuanjian Li May 15th 2020 for Spark Meetup China@示说网
2 .Agenda Part 1: 20 min • Introduction to Structured Streaming • Introduction to Databricks Delta Part 2: 15 min • Key features and improvements in Delta Lake 0.6.0 • Demo Part 3: ● Q&A
3 .Typical Data Pipeline Architecture Dev Tools & CI/CD Storage Source Visualization, reporting, exploration & ML Oracle Compute Workflow & Orchestration
4 .What is streaming? 4
5 .What is streaming? Batch is doing everything at once on a regular basis Streaming is doing it incrementally as new data enters the system Stream/batch processing engines and bounded/unbounded datasets How to process in one run? Batch processing engine Stream processing engine Bounded dataset big batch row by row / mini-batch Unbounded dataset N/A (multiple runs) row by row / mini-batch 5
6 .Another way to think about streaming data stream unbounded input table new data in the data stream = new rows appended to a unbounded table 6
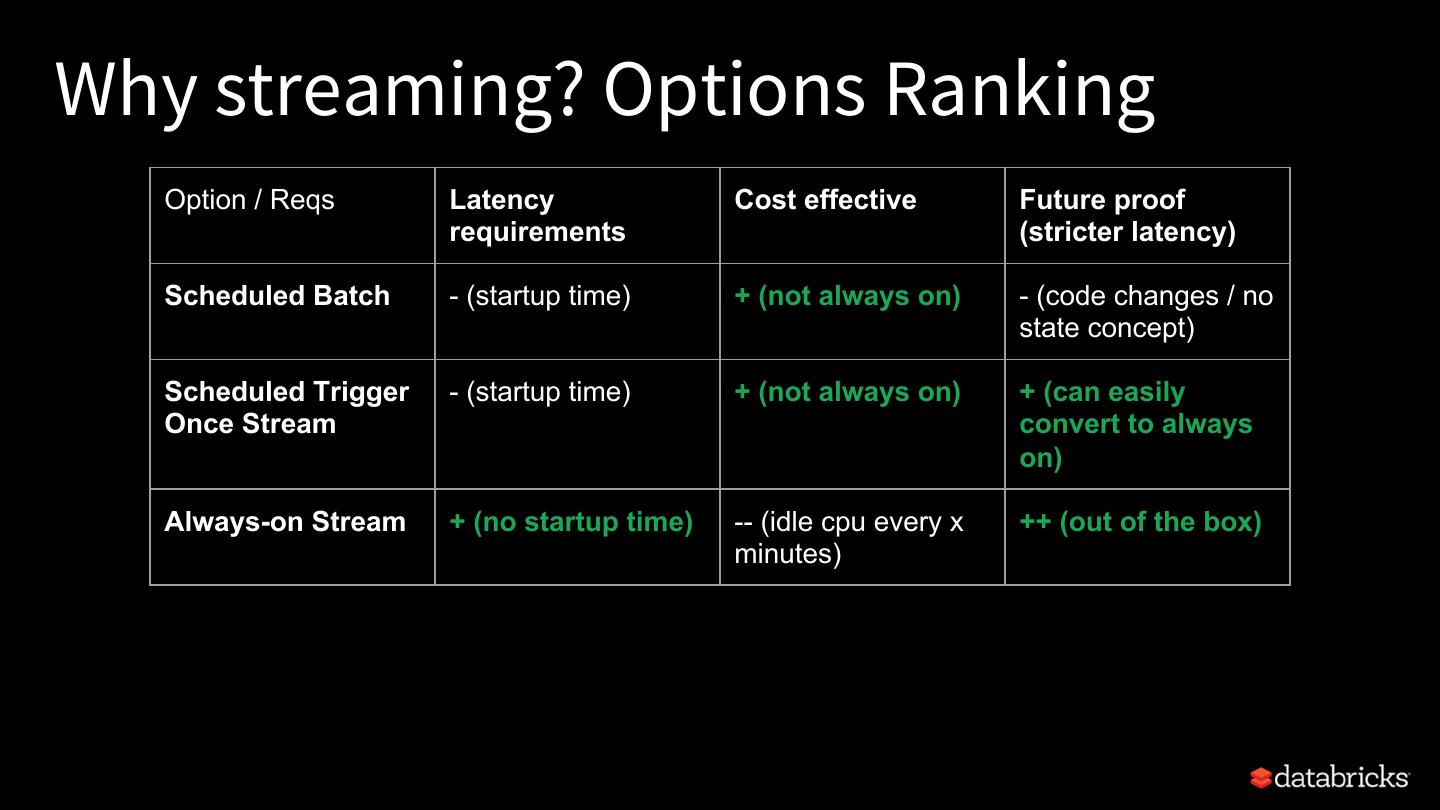
7 .Why streaming? Options Ranking Option / Reqs Latency Cost effective Future proof requirements (stricter latency) Scheduled Batch - (startup time) + (not always on) - (code changes / no state concept) Scheduled Trigger - (startup time) + (not always on) + (can easily Once Stream convert to always on) Always-on Stream + (no startup time) -- (idle cpu every x ++ (out of the box) minutes)
8 .Stream processing engine requirements Correctness is required to get on parity with batch: – need exactly-once delivery guarantee (at-least-once/at- most-once delivery guarantees are not enough) – cannot cut corners using approximation (lambda architecture) – need to be able to deal with out of order events (late data) We then need tools for reasoning about time to get beyond batch
9 .Reasoning about time: Time domains • Event time vs. processing time – Event Time: time at which the event (record in the data) actually occurred. – Processing time: time at which a record is actually processed. – important in every use case processing unbounded data in whatever order (otherwise no guarantee on correctness)
10 .Time Domain Skew When batch processing: • Processing time per definition much later (e.g. an hour or day) than event time • Data assumed to be complete (or settle for incompleteness) When stream processing: • Processing time >= event time but often close (e.g. seconds, minutes) • Challenge when processing time >>> event time (late data): not able to conclude anything easily, how long to wait for the data to be complete?
11 .DStreams vs Structured Streaming DStreams STRUCTURED STREAMING • RDD based • DataFrame/Dataset based • Low level • Supports event time processing • lacks event time processing (strictly • Clean API and semantics processing time based) • leverage basically everything from • Poor support in Databricks DataFrame API, as a stream • Hacked into Spark • First class citizen in Spark • First class citizen in Databricks • “Your DataFrame, but streaming” 11
12 .Structured Streaming High-level streaming API built on Spark SQL engine Runs the same computation as batch queries in Datasets/DataFrames Event time, windowing, sessions, sources & sinks End-to-end exactly once semantics Unifies streaming, interactive and batch queries Aggregate data in a stream, then serve using JDBC Add, remove, change queries at runtime Build and apply ML models Rich ecosystem of data sources and sinks 12
13 .Structured Streaming Design Goal You should write simple queries & Spark should continuously update the answer 13
14 .
15 .
16 .
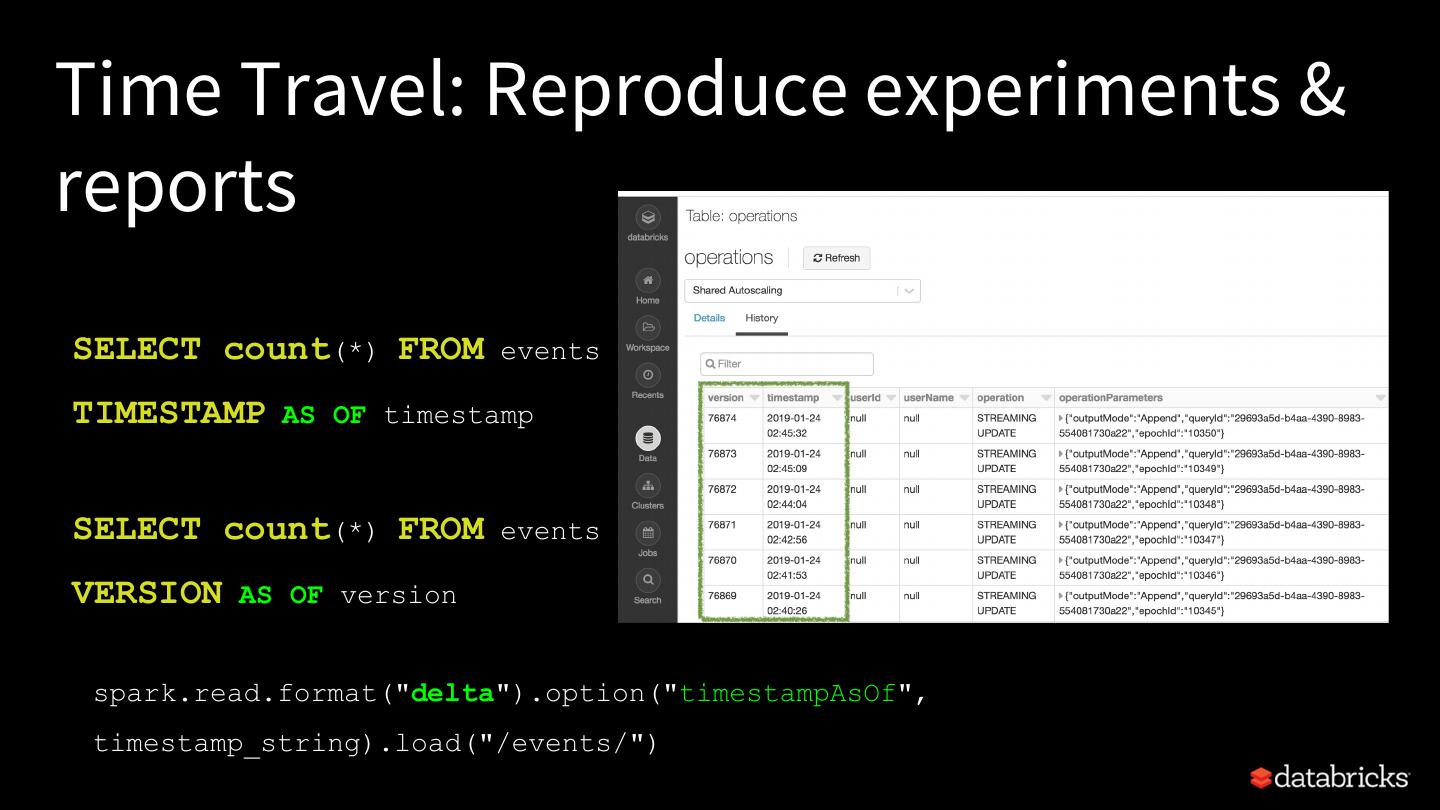
17 .
18 .
19 .But we didn’t get everything right in
20 .1. Data Reliability Challenges with Spark Failed production jobs leave data in corrupt ✗ state requiring tedious recovery Lack of schema enforcement creates inconsistent and low quality data Lack of consistency makes it almost impossible to mix appends ands reads, batch and streaming
21 .2. Performance Challenges with Spark Too many small or very big files - more time opening & closing files rather than reading contents (worse with streaming) Partitioning aka “poor man’s indexing”- breaks down if you picked the wrong fields or when data has many dimensions, high cardinality columns No caching - cloud storage throughput is low (S3 is 20- 50MB/s/core vs 300MB/s/core for local SSDs)
22 . Databricks Delta Next-generation unified analytics engine Databricks Delta ● Co-designed compute & storage ● Compatible with Spark API’s Versioned Parquet Files Transactional Log Indexes & Stats ● Built on open standards (Parquet) Built on top of your cloud blob storage
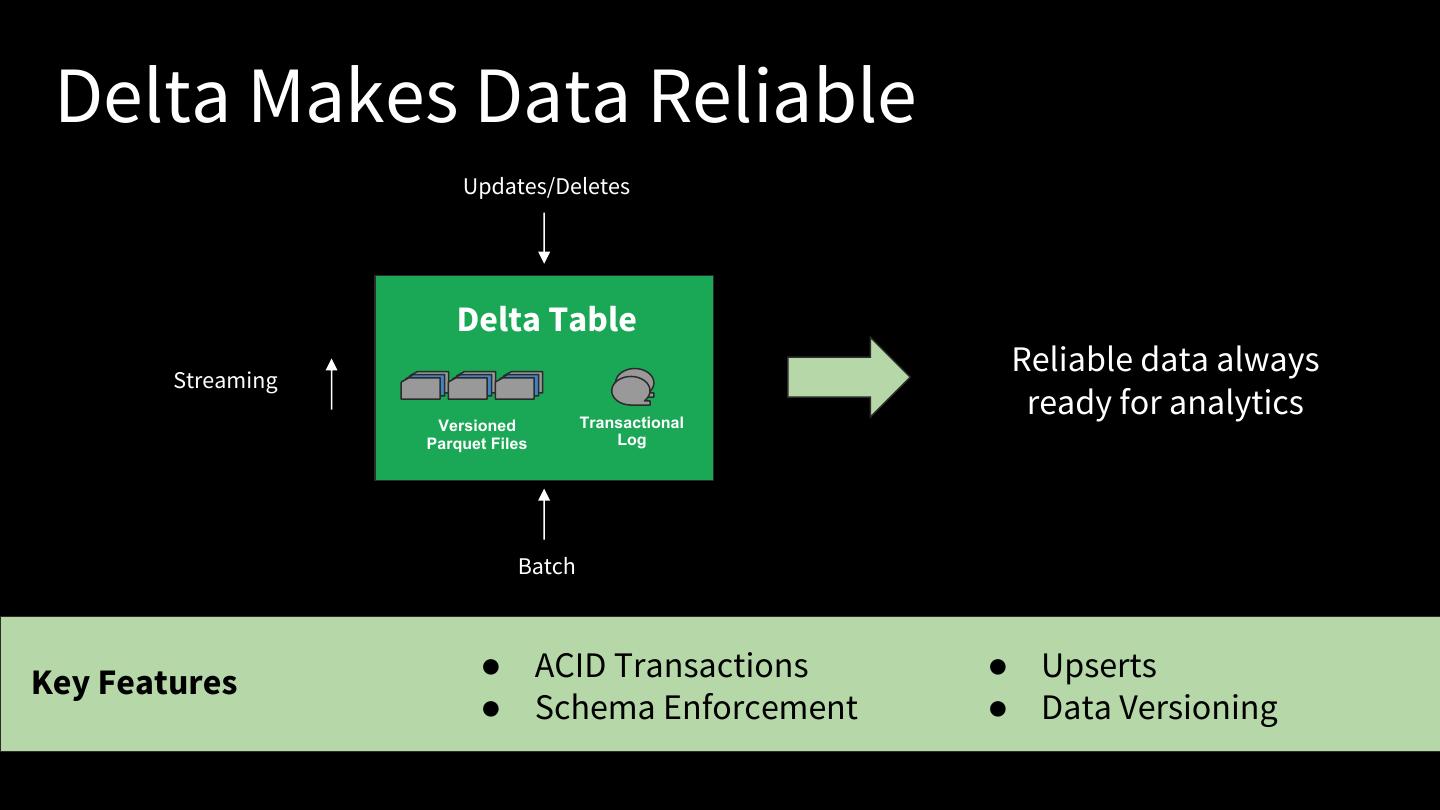
23 . Delta Makes Data Reliable Updates/Deletes Delta Table Streaming Reliable data always Versioned Transactional ready for analytics Parquet Files Log Batch Key Features ● ACID Transactions ● Upserts ● Schema Enforcement ● Data Versioning
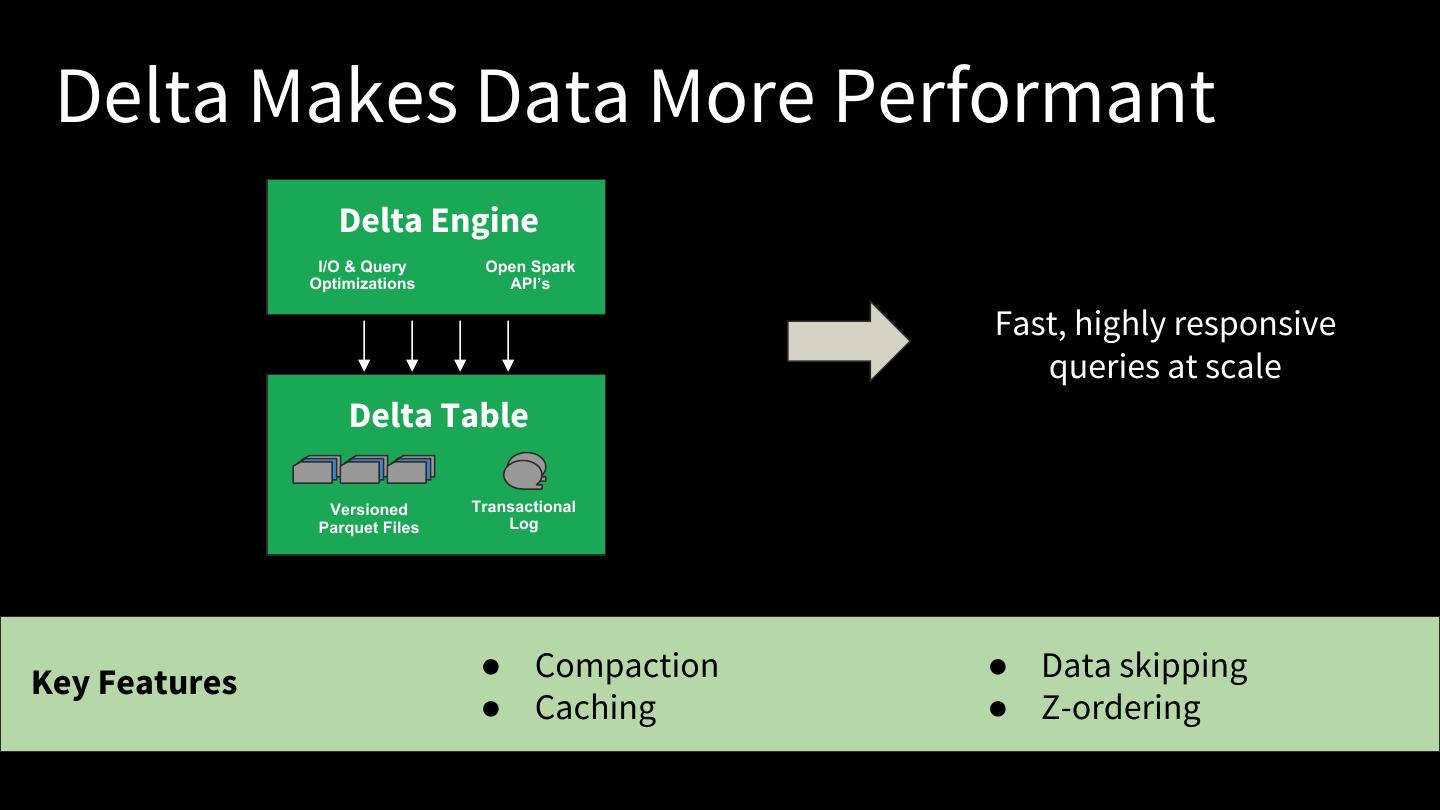
24 . Delta Makes Data More Performant Delta Engine I/O & Query Open Spark Optimizations API’s Fast, highly responsive queries at scale Delta Table Versioned Transactional Parquet Files Log Key Features ● Compaction ● Data skipping ● Caching ● Z-ordering
25 . Delta unifies batch and streaming Key Features
26 .Get Started with Delta using Spark APIs Instead of parquet... … simply say delta CREATE TABLE ... CREATE TABLE ... USING parquet USING delta ... … dataframe dataframe .write .write .format("parquet") .format("delta") .save("/data") .save("/data")
27 .Migrating your Spark jobs to Delta Step 1: Convert Parquet to Delta Tables CONVERT TO DELTA parquet.`path/to/table` [NO STATISTICS] [PARTITIONED BY (col_name1 col_type1, col_name2 col_type2, ...)] Step 2: Optimize Layout for Fast Queries OPTIMIZE events WHERE date >= current_timestamp() - INTERVAL 1 day ZORDER BY (eventType)
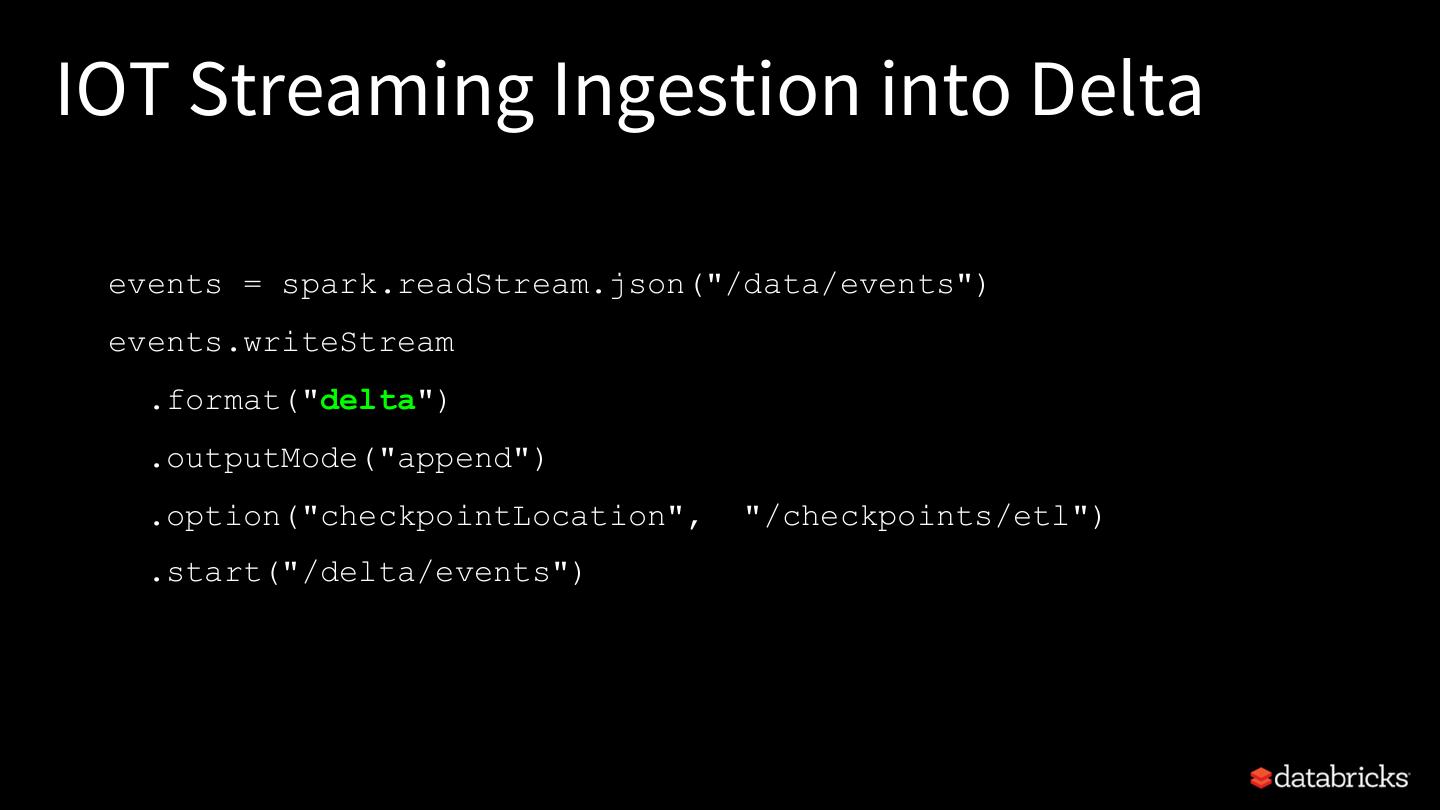
28 .IOT Streaming Ingestion into Delta events = spark.readStream.json("/data/events") events.writeStream .format("delta") .outputMode("append") .option("checkpointLocation", "/checkpoints/etl") .start("/delta/events")
29 .Fine grained updates into Delta MERGE INTO customers -- Delta table USING updates ON customers.customerId = source.customerId WHEN MATCHED THEN UPDATE SET address = updates.address WHEN NOT MATCHED THEN INSERT (customerId, address) VALUES (updates.customerId, updates.address)
3秒后跳转登录页面
去登陆

