



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark SQL Bucketing at Facebook
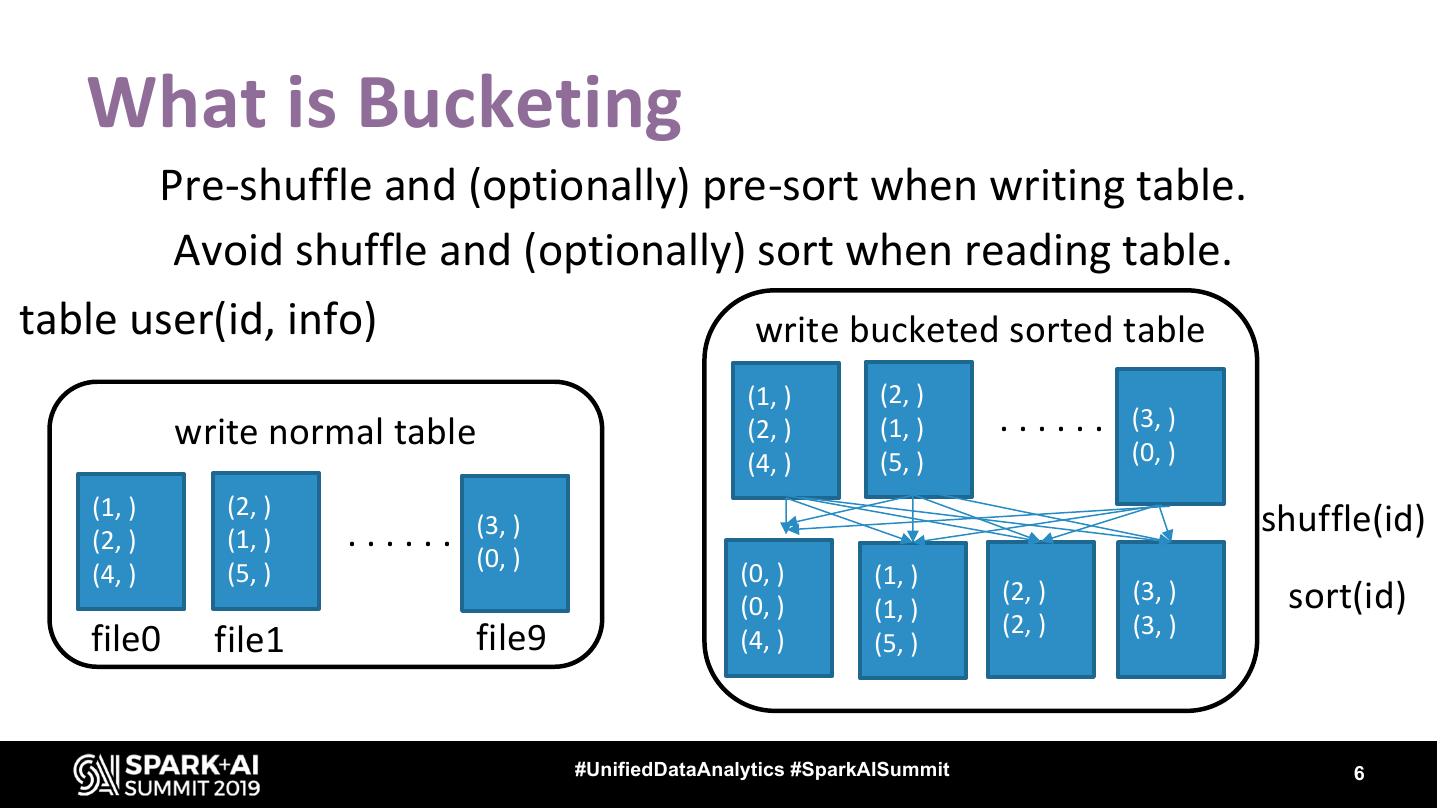
Bucketing is a popular data partitioning technique to pre-shuffle and (optionally) pre-sort data during writes. This is ideal for a variety of write-once and read-many datasets at Facebook, where Spark can automatically avoid expensive shuffles/sorts (when the underlying data is joined/aggregated on its bucketed keys) resulting in substantial savings in both CPU and IO.
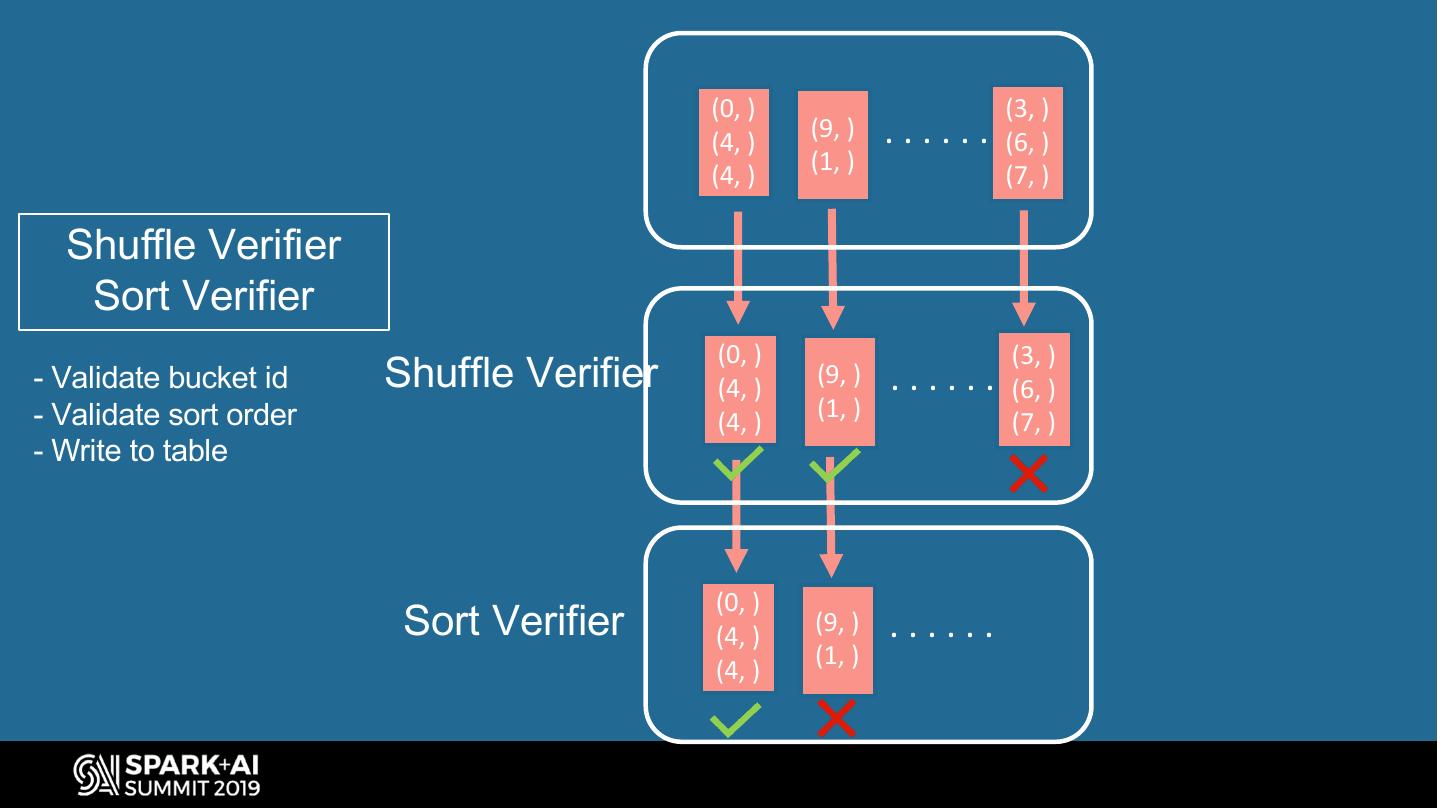
Over the last year, we’ve added a series of optimizations in Apache Spark as a means towards achieving feature parity with Hive and Spark. These include avoiding shuffle/sort when joining/aggregating/inserting on tables with mismatching buckets, allowing user to skip shuffle/sort when writing to bucketed tables, adding data validators before writing bucketed data, among many others. As a direct consequence of these efforts, we’ve witnessed over 10x growth (spanning 40% of total compute) in queries that read one or more bucketed tables across the entire data warehouse at Facebook.
In this talk, we’ll take a deep dive into the internals of bucketing support in SparkSQL, describe use-cases where bucketing is useful, touch upon some of the on-going work to automatically suggest bucketing tables based on query column lineage, and summarize the lessons learned from developing bucketing support in Spark at Facebook over the last 2 years
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Spark SQL Bucketing at Facebook Cheng Su, Facebook #UnifiedDataAnalytics #SparkAISummit
3 .About me Cheng Su • Software Engineer at Facebook (Data Infrastructure Organization) • Working in Spark team • Previously worked in Hive/Corona team #UnifiedDataAnalytics #SparkAISummit 3
4 .Agenda • Spark at Facebook • What is Bucketing • Spark Bucketing Optimizations (JIRA: SPARK-19256) • Bucketing Compatability across SQL Engines • The Road Ahead #UnifiedDataAnalytics #SparkAISummit 4
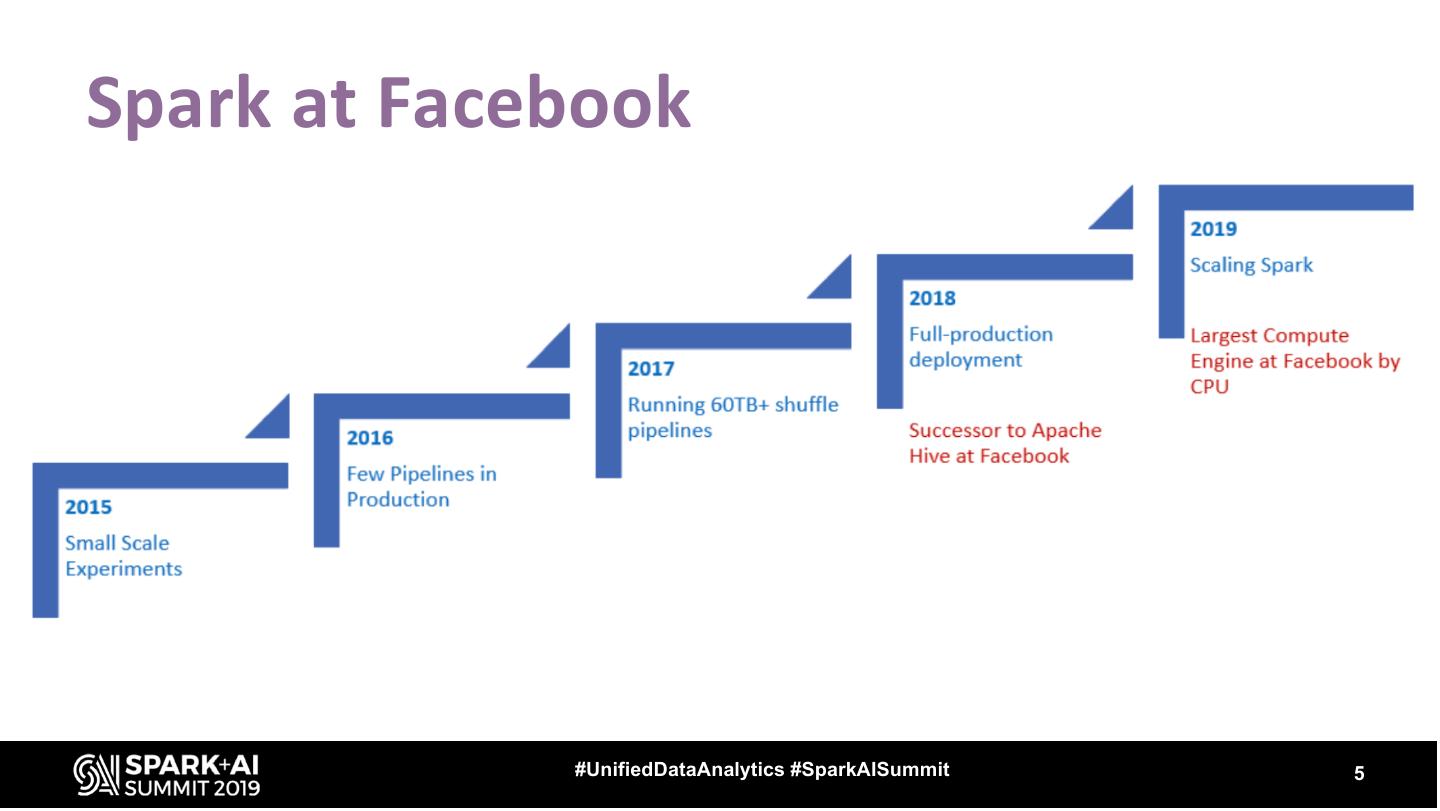
5 .Spark at Facebook #UnifiedDataAnalytics #SparkAISummit 5
6 . What is Bucketing Pre-shuffle and (optionally) pre-sort when writing table. Avoid shuffle and (optionally) sort when reading table. table user(id, info) write bucketed sorted table (1, ) (2, ) write normal table (2, ) (1, ) ...... (3, ) (4, ) (5, ) (0, ) (1, ) (2, ) (2, ) (1, ) ...... (3, ) shuffle(id) (0, ) (4, ) (5, ) (0, ) (1, ) (0, ) (1, ) (2, ) (3, ) sort(id) (2, ) (3, ) file0 file1 file9 (4, ) (5, ) #UnifiedDataAnalytics #SparkAISummit 6
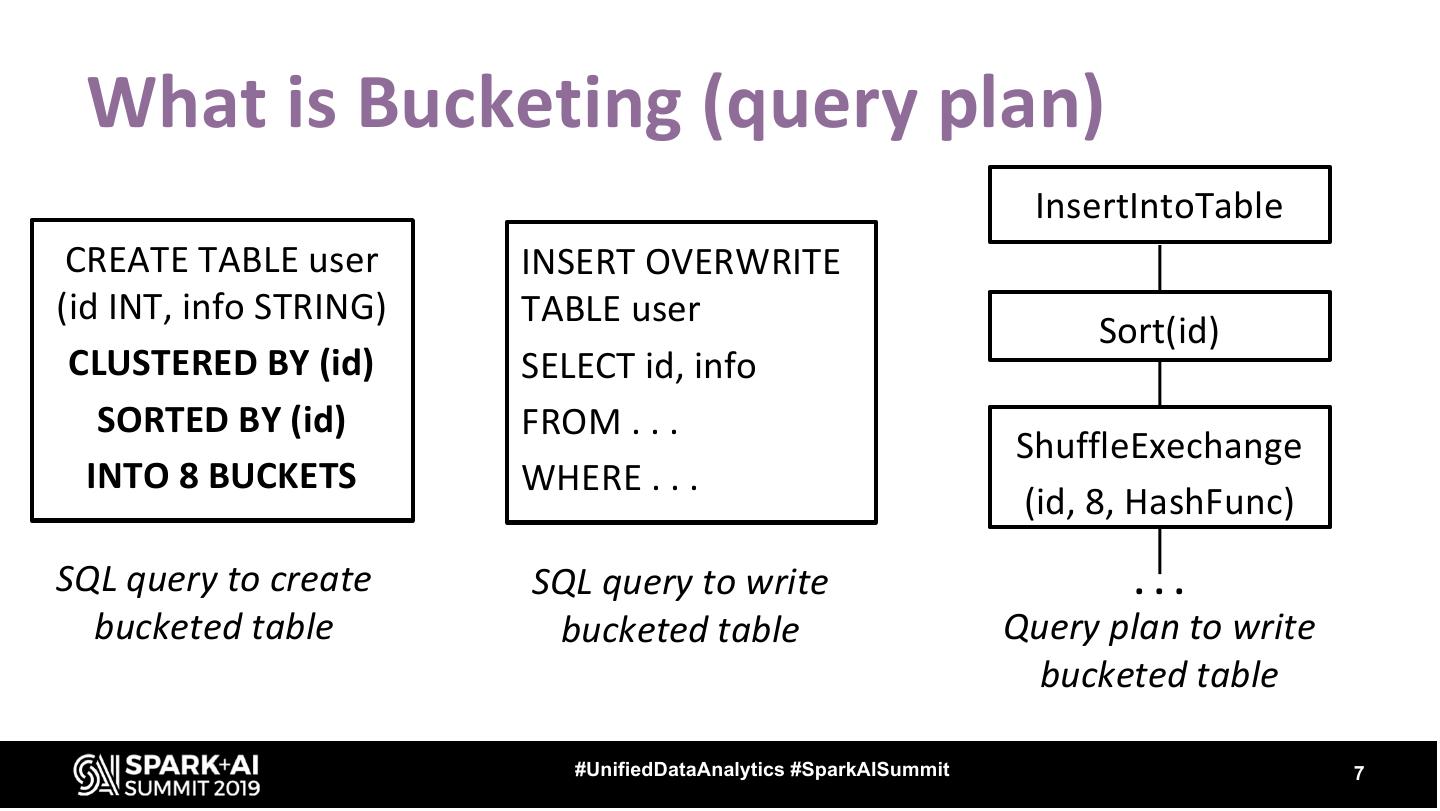
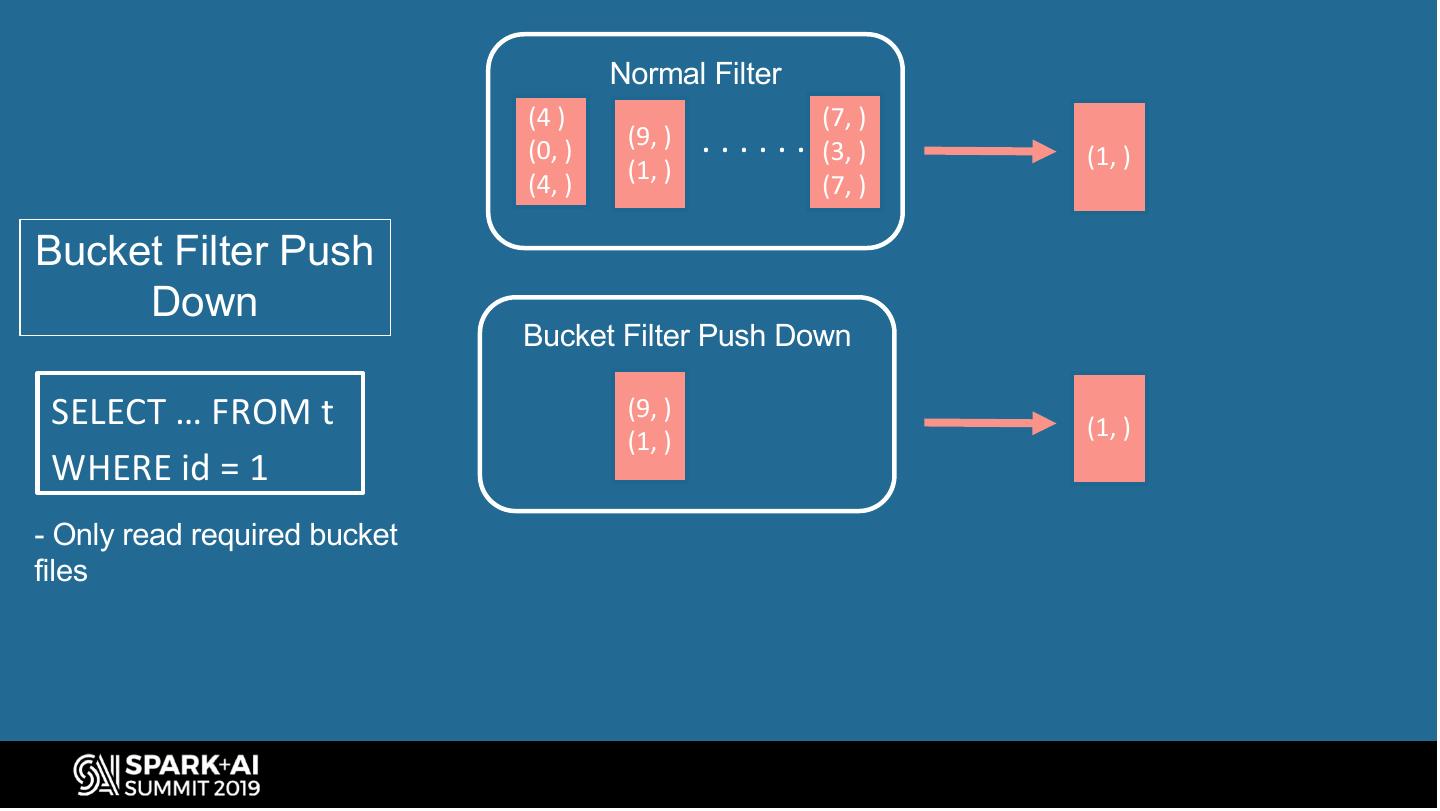
7 . What is Bucketing (query plan) InsertIntoTable CREATE TABLE user INSERT OVERWRITE (id INT, info STRING) TABLE user Sort(id) CLUSTERED BY (id) SELECT id, info SORTED BY (id) FROM . . . ShuffleExechange INTO 8 BUCKETS WHERE . . . (id, 8, HashFunc) SQL query to create SQL query to write ... bucketed table bucketed table Query plan to write bucketed table #UnifiedDataAnalytics #SparkAISummit 7
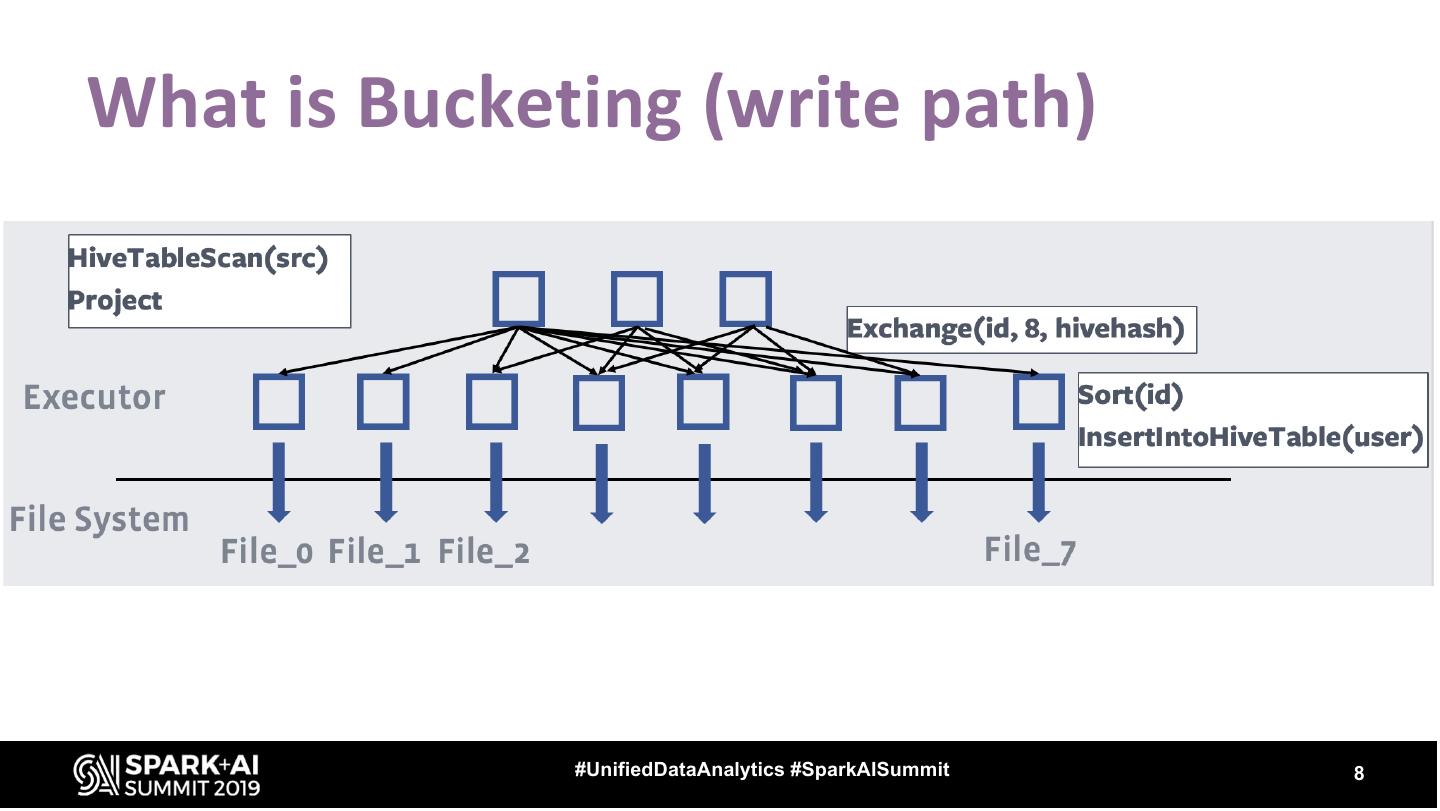
8 .What is Bucketing (write path) #UnifiedDataAnalytics #SparkAISummit 8
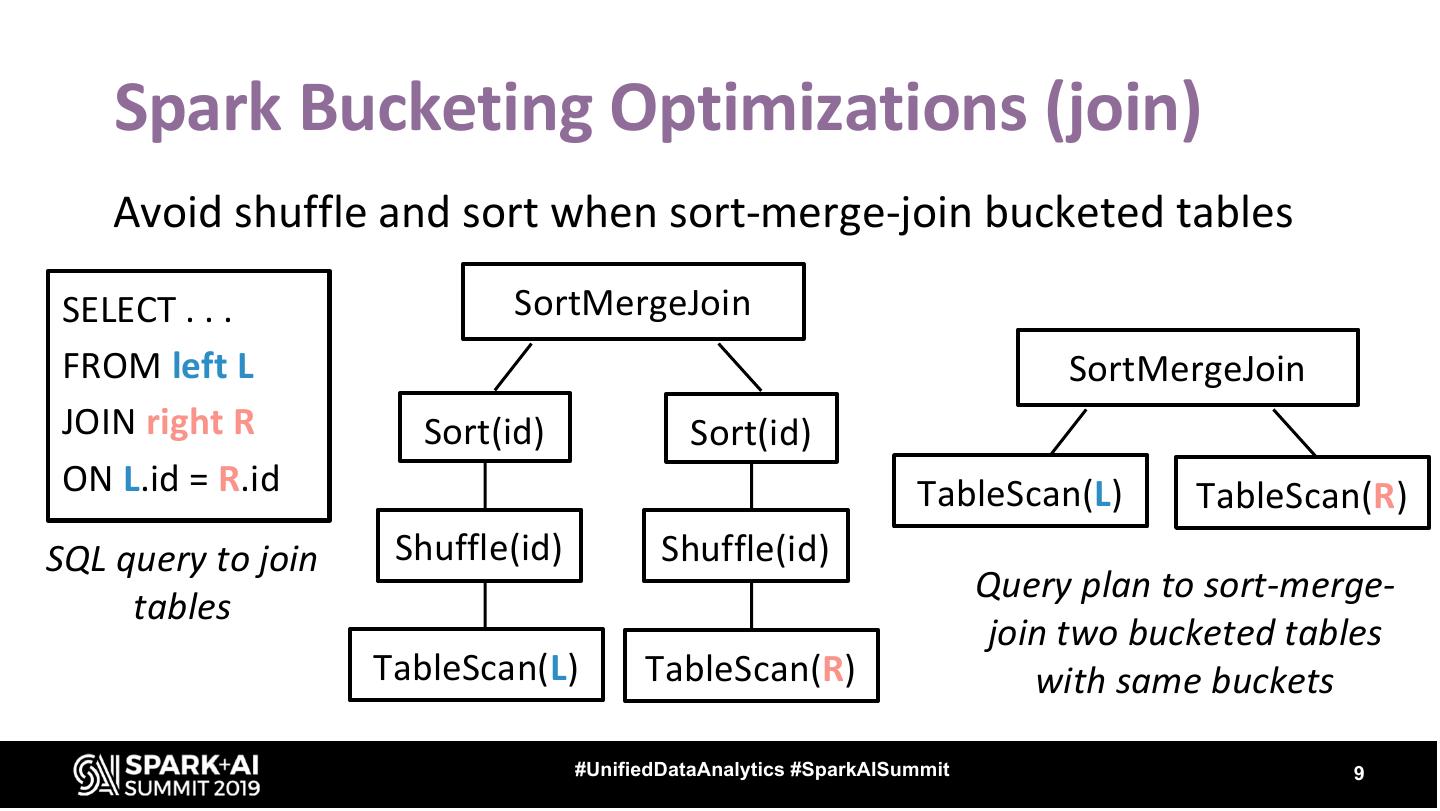
9 . Spark Bucketing Optimizations (join) Avoid shuffle and sort when sort-merge-join bucketed tables SELECT . . . SortMergeJoin FROM left L SortMergeJoin JOIN right R Sort(id) Sort(id) ON L.id = R.id TableScan(L) TableScan(R) SQL query to join Shuffle(id) Shuffle(id) Query plan to sort-merge- tables join two bucketed tables TableScan(L) TableScan(R) with same buckets #UnifiedDataAnalytics #SparkAISummit 9
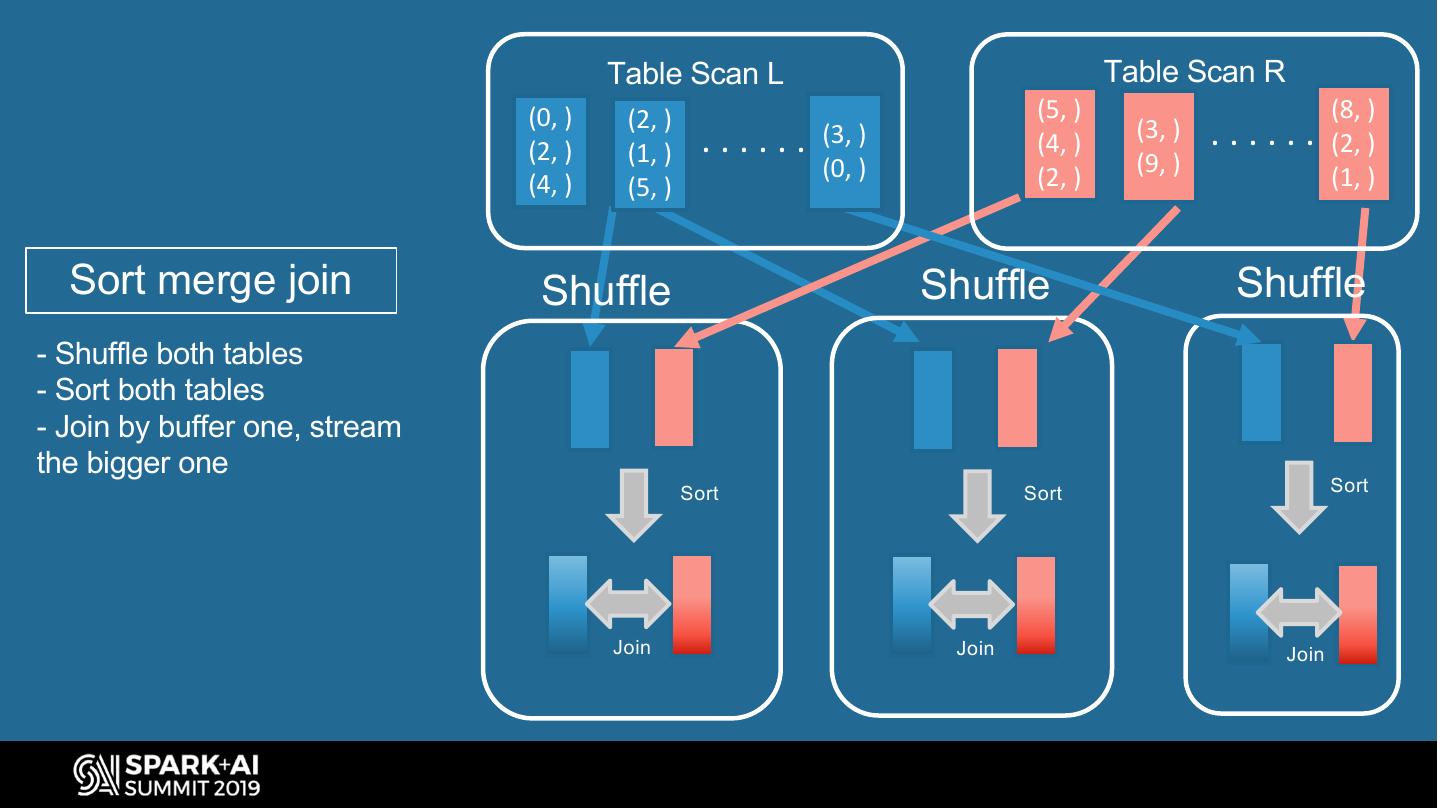
10 . Table Scan L Table Scan R (0, ) (2, ) (5, ) (8, ) (2, ) (1, ) ...... (3, ) (4, ) (3, ) ...... (2, ) (0, ) (9, ) (4, ) (5, ) (2, ) (1, ) Sort merge join Shuffle Shuffle Shuffle - Shuffle both tables - Sort both tables - Join by buffer one, stream the bigger one Sort Sort Sort Join Join Join
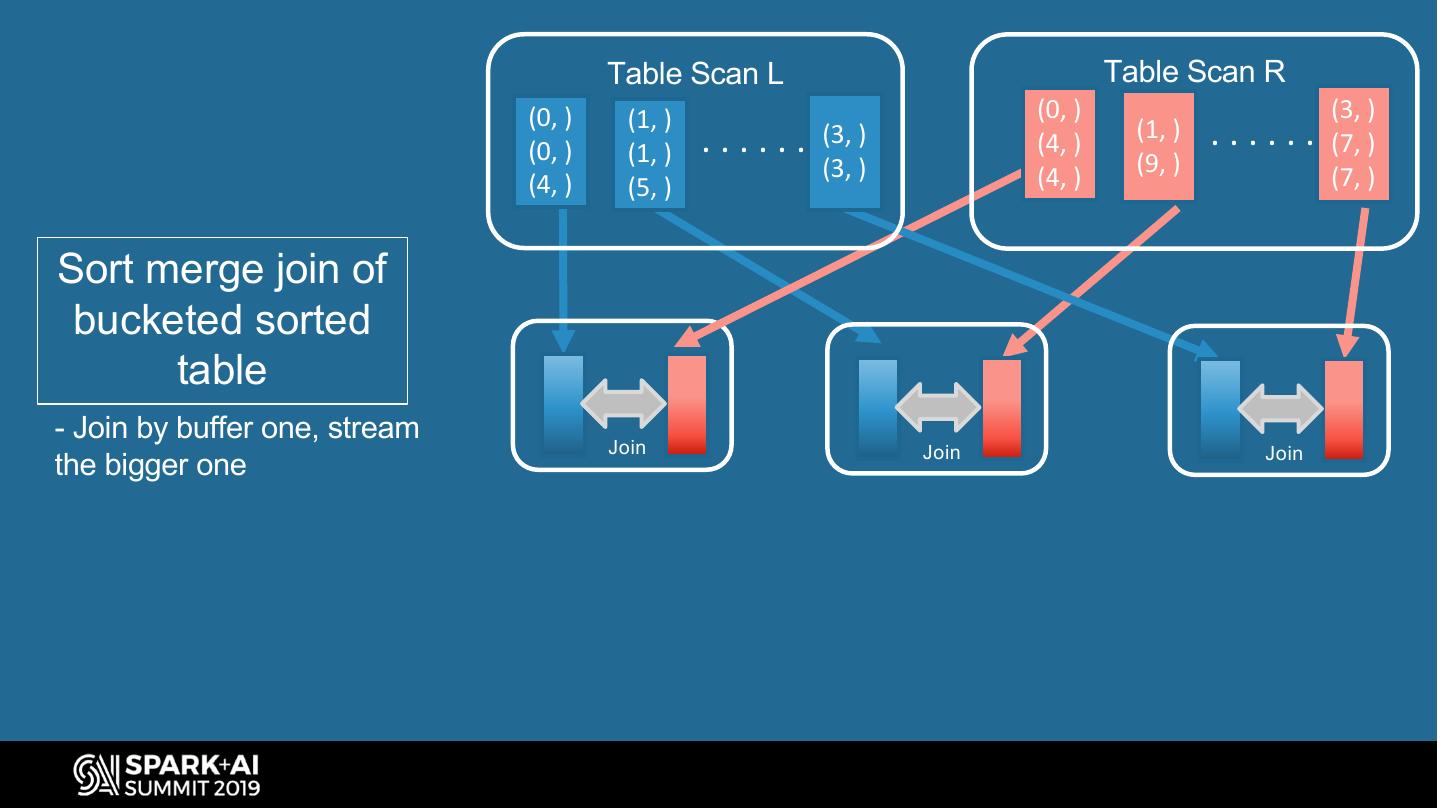
11 . Table Scan L Table Scan R (0, ) (1, ) (0, ) (3, ) (0, ) (1, ) ...... (3, ) (4, ) (1, ) ...... (7, ) (3, ) (9, ) (4, ) (5, ) (4, ) (7, ) Sort merge join of bucketed sorted table - Join by buffer one, stream Join Join Join the bigger one
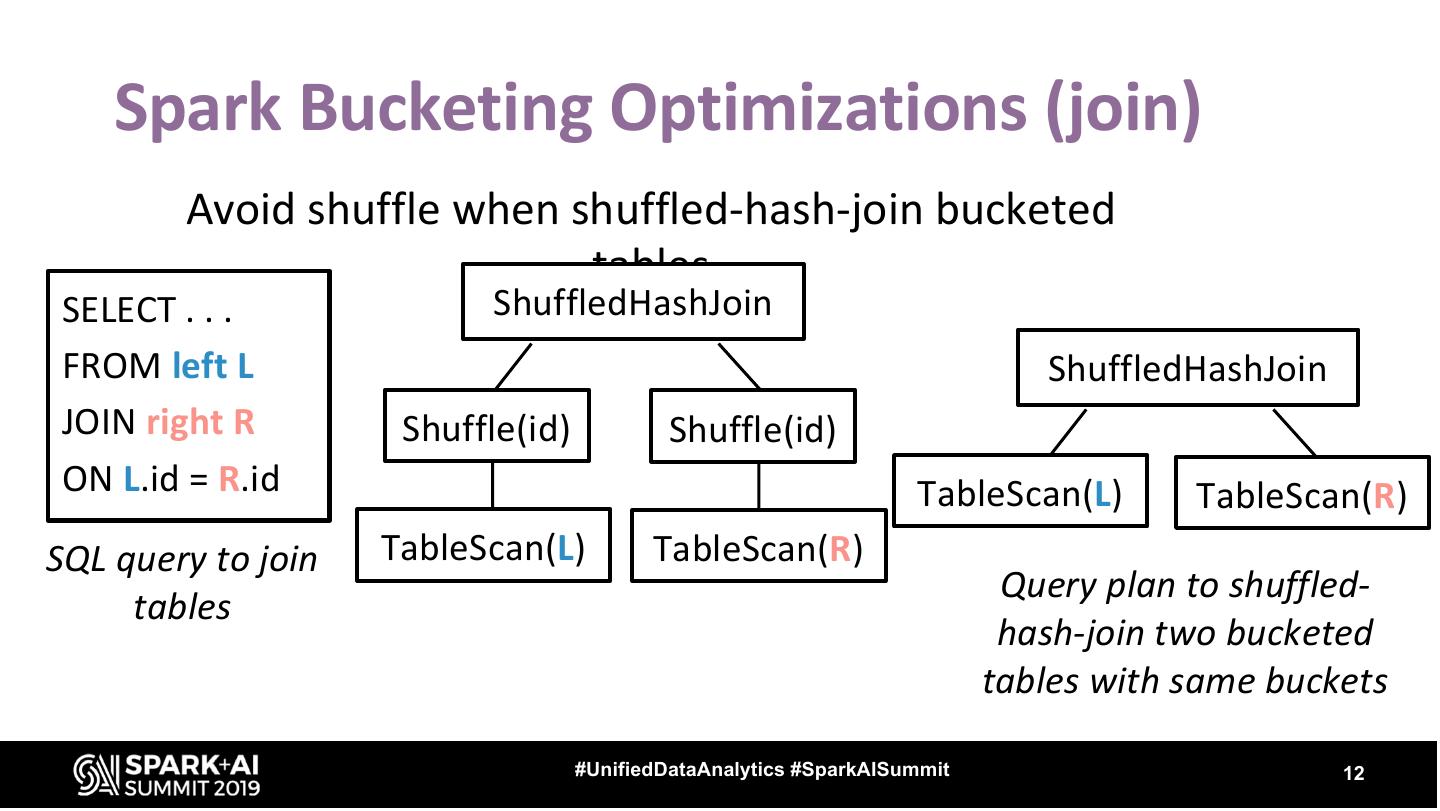
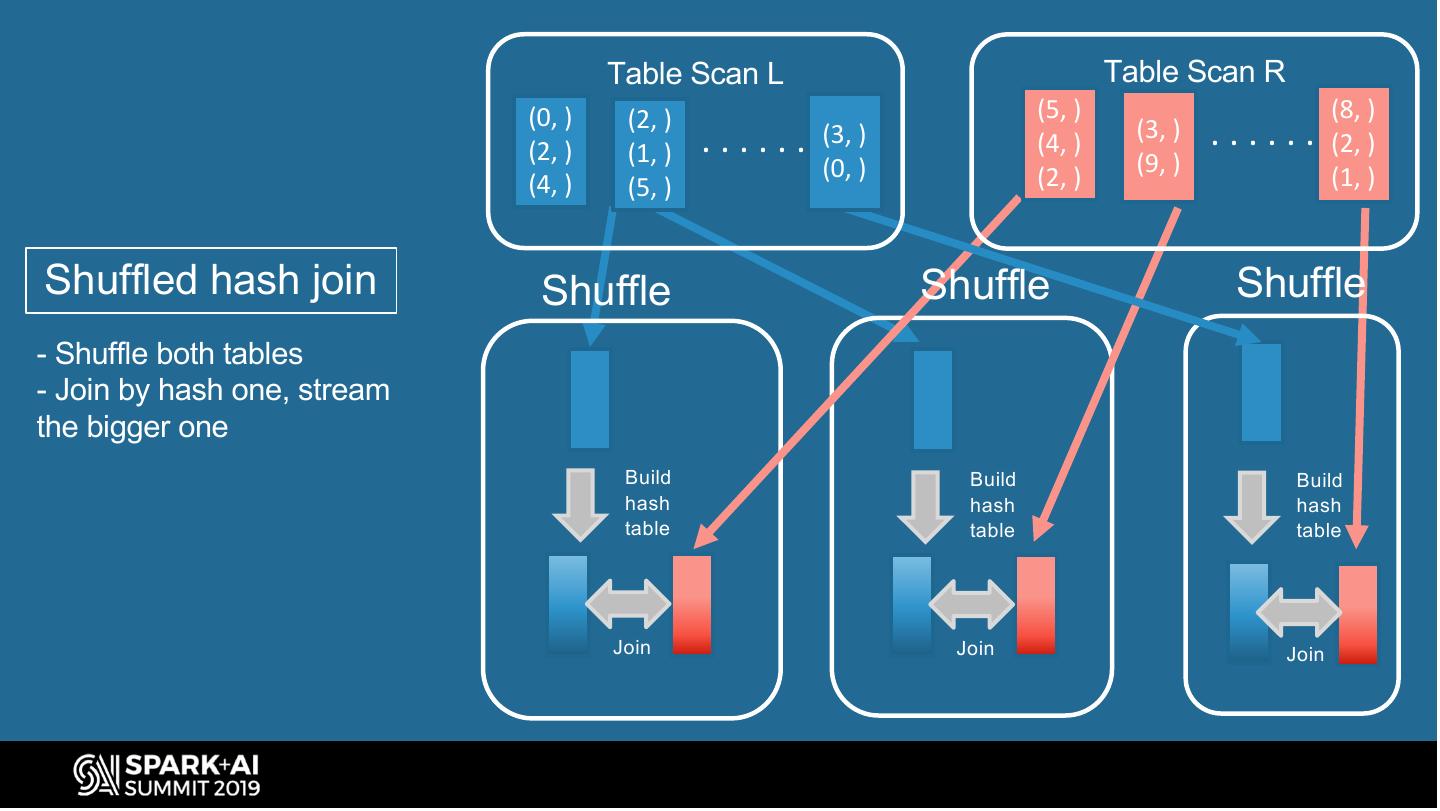
12 . Spark Bucketing Optimizations (join) Avoid shuffle when shuffled-hash-join bucketed tables SELECT . . . ShuffledHashJoin FROM left L ShuffledHashJoin JOIN right R Shuffle(id) Shuffle(id) ON L.id = R.id TableScan(L) TableScan(R) SQL query to join TableScan(L) TableScan(R) Query plan to shuffled- tables hash-join two bucketed tables with same buckets #UnifiedDataAnalytics #SparkAISummit 12
13 . Table Scan L Table Scan R (0, ) (2, ) (5, ) (8, ) (2, ) (1, ) ...... (3, ) (4, ) (3, ) ...... (2, ) (0, ) (9, ) (4, ) (5, ) (2, ) (1, ) Shuffled hash join Shuffle Shuffle Shuffle - Shuffle both tables - Join by hash one, stream the bigger one Build Build Build hash hash hash table table table Join Join Join
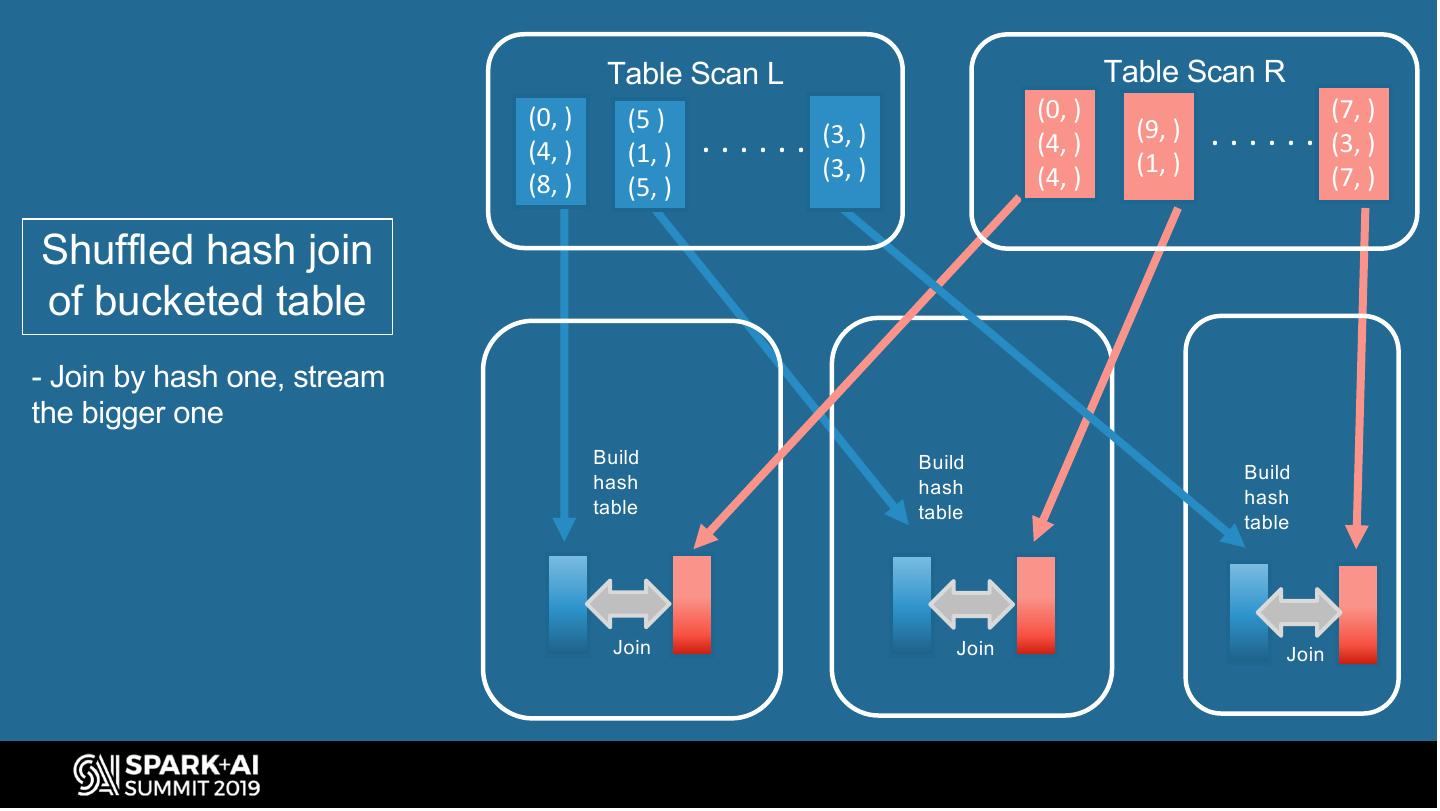
14 . Table Scan L Table Scan R (0, ) (5 ) (0, ) (7, ) (4, ) (1, ) ...... (3, ) (4, ) (9, ) ...... (3, ) (3, ) (1, ) (8, ) (5, ) (4, ) (7, ) Shuffled hash join of bucketed table - Join by hash one, stream the bigger one Build Build Build hash hash table hash table table Join Join Join
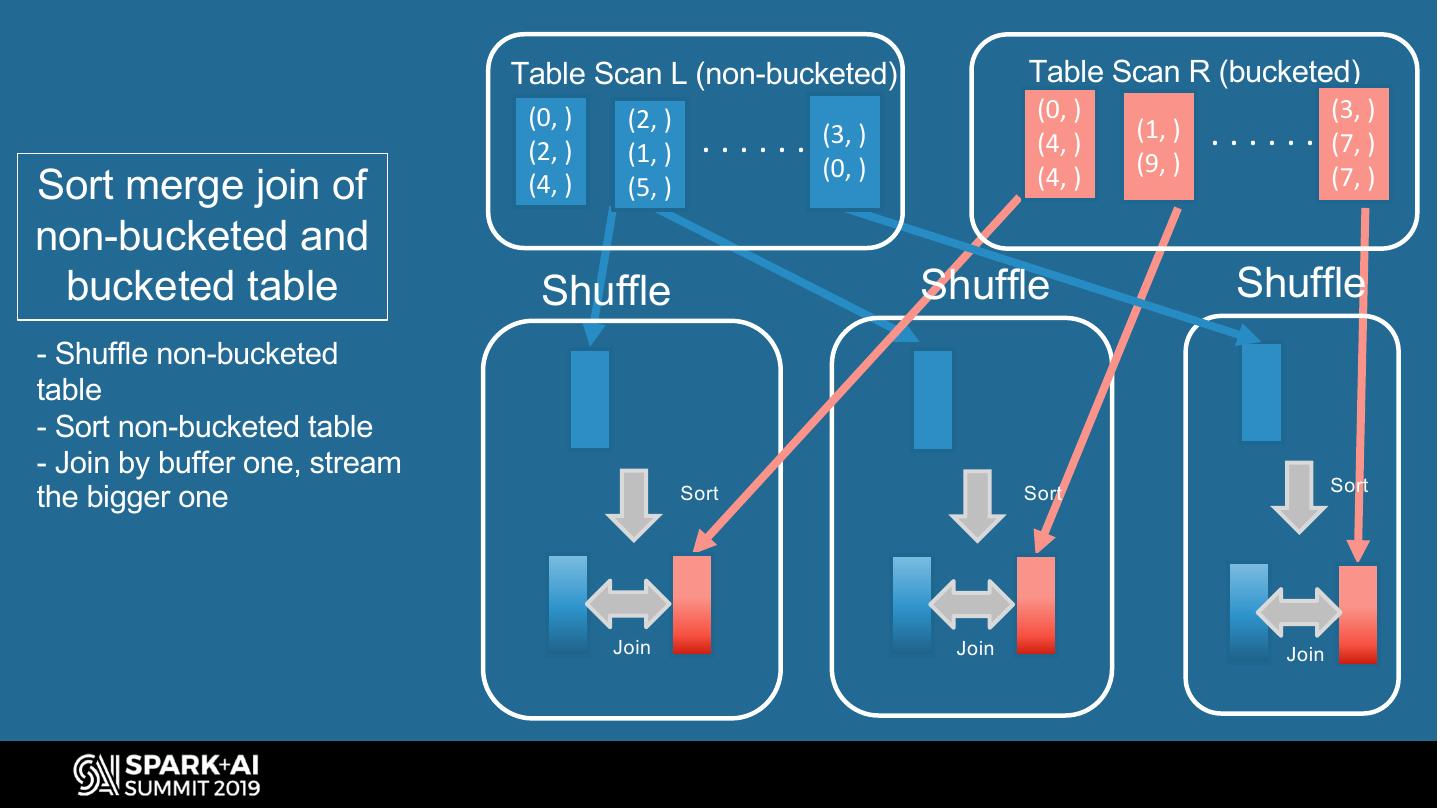
15 . Spark Bucketing Optimizations (join) Avoid shuffle and sort when joining non-bucketed, and bucketed table SELECT . . . SortMergeJoin FROM left L JOIN right R Sort(id) TableScan(R) Query plan to sort-merge-join ON L.id = R.id non-bucketed table (L) with SQL query to join Shuffle(id) bucketed table (R) tables TableScan(L) #UnifiedDataAnalytics #SparkAISummit 15
16 . Table Scan L (non-bucketed) Table Scan R (bucketed) (0, ) (2, ) (0, ) (3, ) (2, ) (1, ) ...... (3, ) (4, ) (1, ) ...... (7, ) (0, ) (9, ) Sort merge join of (4, ) (5, ) (4, ) (7, ) non-bucketed and bucketed table Shuffle Shuffle Shuffle - Shuffle non-bucketed table - Sort non-bucketed table - Join by buffer one, stream Sort the bigger one Sort Sort Join Join Join
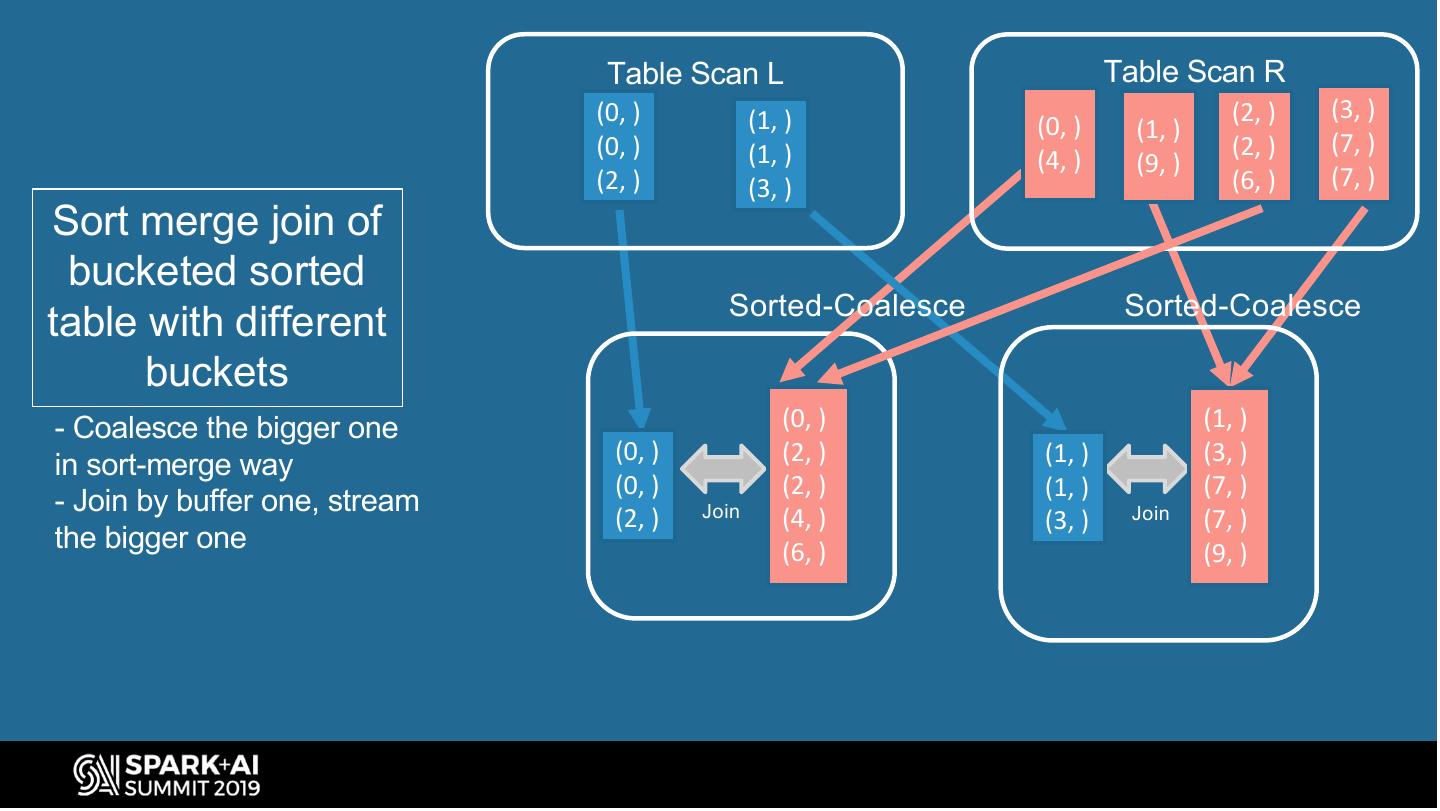
17 . Spark Bucketing Optimizations (join) Avoid shuffle and sort when joining bucketed tables with different buckets SortedCoalesceExec SELECT . . . SortMergeJoin (physical plan operator FROM left L inherits child ordering ) JOIN right R TableScan(L) SortedCoalesce(4) ON L.id = R.id SortedCoalescedRDD SQL query to join TableScan(R) (extends CoalescedRDD tables to read children RDDs in Query plan to join 4-buckets-table sort-merge-way) (L) with 16-buckets-table (R) (priority-queue) #UnifiedDataAnalytics #SparkAISummit 17
18 . Table Scan L Table Scan R (0, ) (1, ) (2, ) (3, ) (0, ) (1, ) (0, ) (1, ) (2, ) (7, ) (4, ) (9, ) (2, ) (3, ) (6, ) (7, ) Sort merge join of bucketed sorted Sorted-Coalesce Sorted-Coalesce table with different buckets - Coalesce the bigger one (0, ) (1, ) (0, ) (2, ) (1, ) (3, ) in sort-merge way (0, ) (2, ) (1, ) (7, ) - Join by buffer one, stream Join (2, ) (4, ) (3, ) Join (7, ) the bigger one (6, ) (9, )
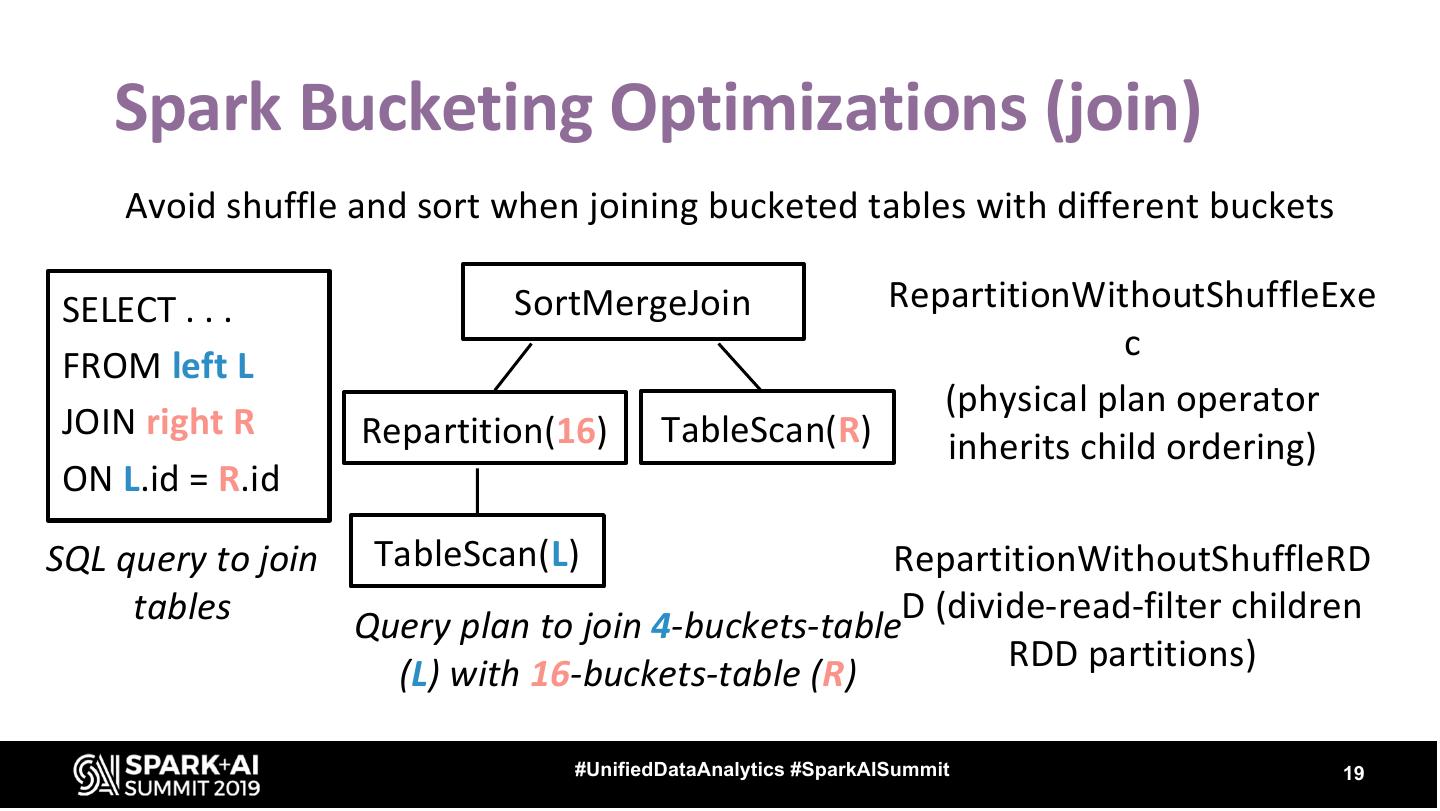
19 . Spark Bucketing Optimizations (join) Avoid shuffle and sort when joining bucketed tables with different buckets SELECT . . . SortMergeJoin RepartitionWithoutShuffleExe c FROM left L (physical plan operator JOIN right R Repartition(16) TableScan(R) inherits child ordering) ON L.id = R.id SQL query to join TableScan(L) RepartitionWithoutShuffleRD tables Query plan to join 4-buckets-tableD (divide-read-filter children (L) with 16-buckets-table (R) RDD partitions) #UnifiedDataAnalytics #SparkAISummit 19
20 . Table Scan L Table Scan R (0, ) (1, ) (2, ) (3, ) (0, ) (1, ) (0, ) (1, ) (2, ) (7, ) (4, ) (9, ) (2, ) (3, ) (6, ) (7, ) Divide Divide Divide Divide (0, ) (0, ) (1, ) (1, ) (2, ) (3, ) (0, ) Join (4, ) (1, ) (9, ) (2, ) (2, ) (3, ) (7, ) Join Join Join (6, ) (7, ) Sort merge join of - Divide (repartition-w/o- bucketed sorted shuffle) the smaller one - Join by buffer one, stream table with different the bigger one buckets
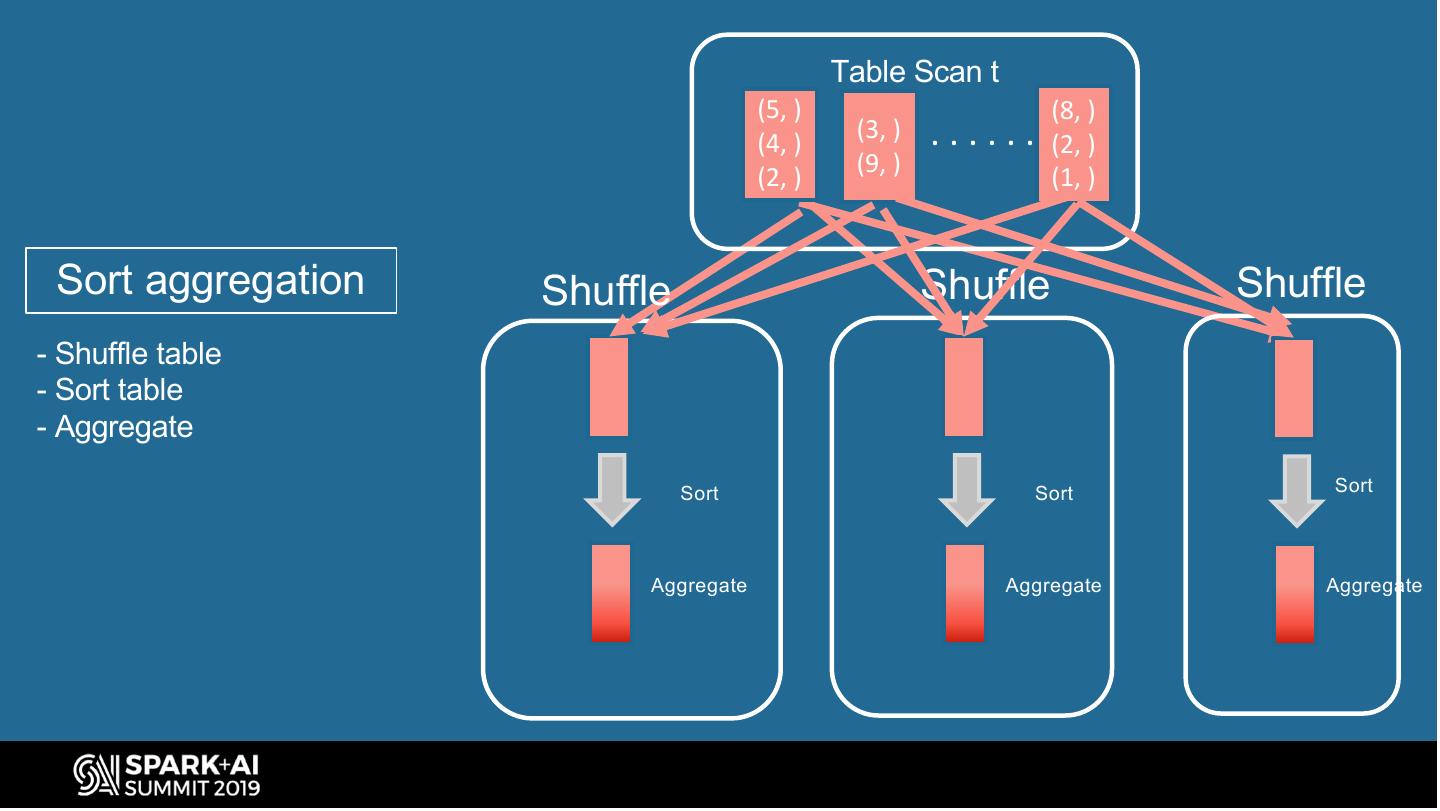
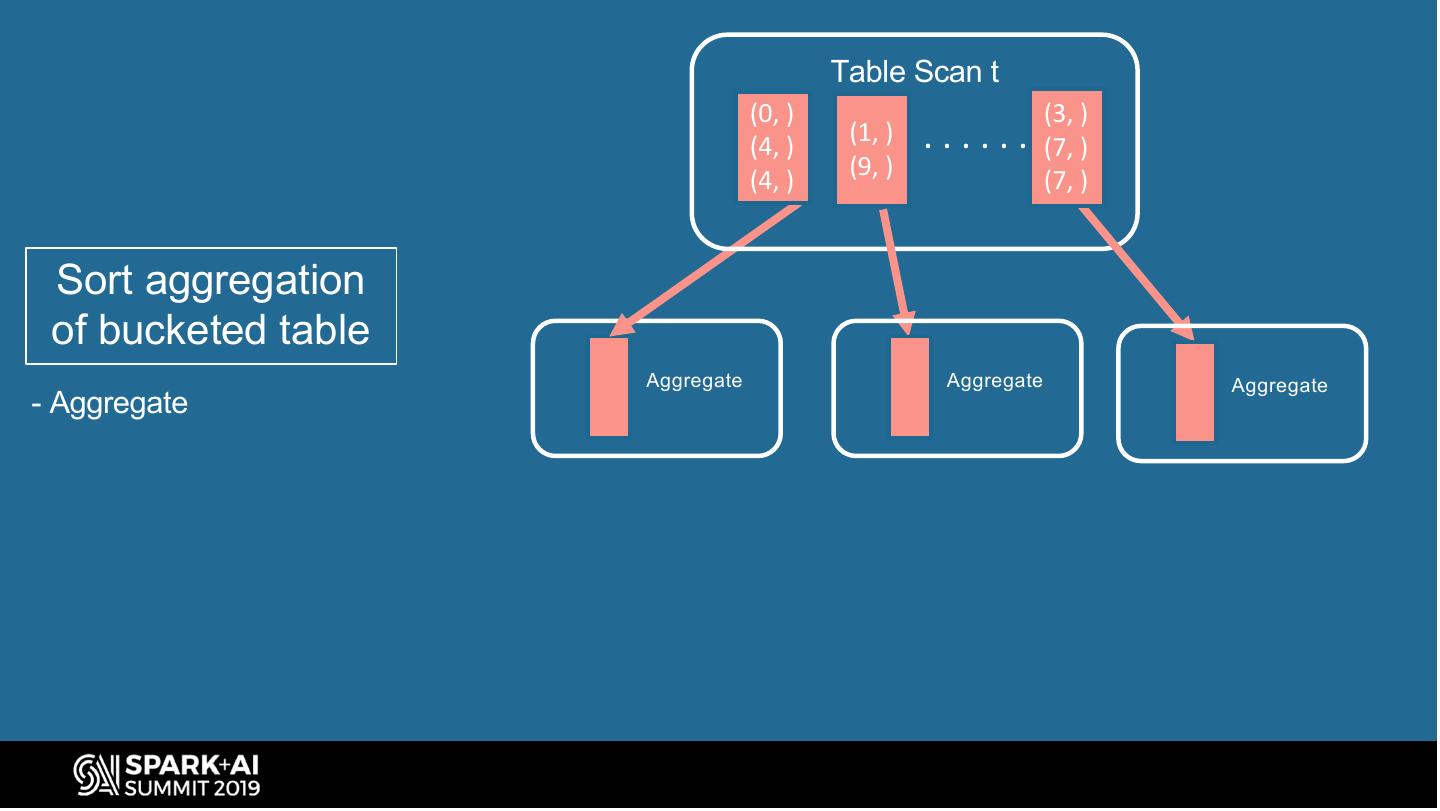
21 . Spark Bucketing Optimizations (group-by) Avoid shuffle and sort when sort-aggregate bucketed tables SortAggregate SortAggregate SELECT . . . FROM t Sort(id) TableScan(t) GROUP BY id Shuffle(id) Query plan to sort- SQL query to group- aggregate bucketed table by table TableScan(t) #UnifiedDataAnalytics #SparkAISummit 21
22 . Table Scan t (5, ) (8, ) (4, ) (3, ) ...... (2, ) (9, ) (2, ) (1, ) Sort aggregation Shuffle Shuffle Shuffle - Shuffle table - Sort table - Aggregate Sort Sort Sort Aggregate Aggregate Aggregate
23 . Table Scan t (0, ) (3, ) (4, ) (1, ) ...... (7, ) (9, ) (4, ) (7, ) Sort aggregation of bucketed table Aggregate Aggregate Aggregate - Aggregate
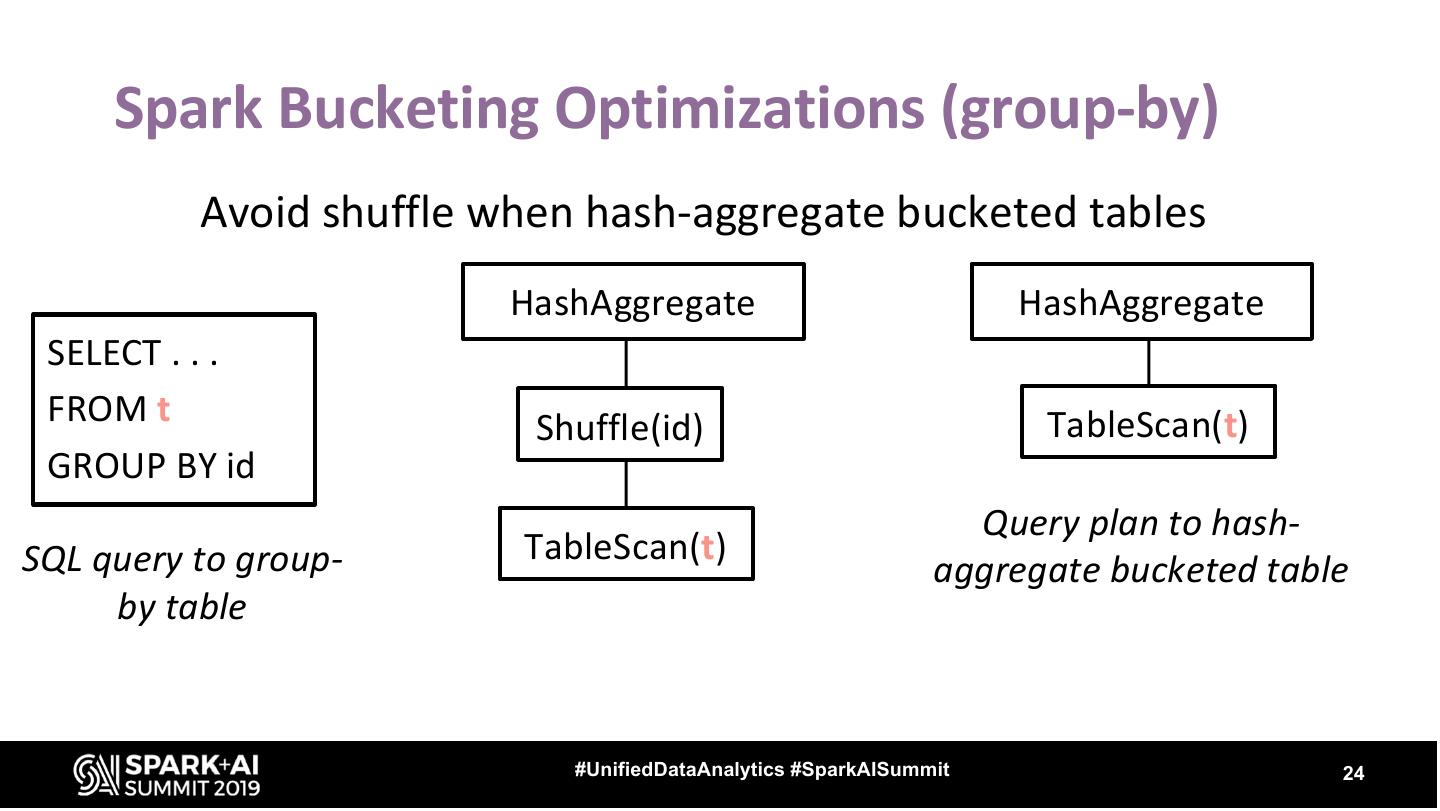
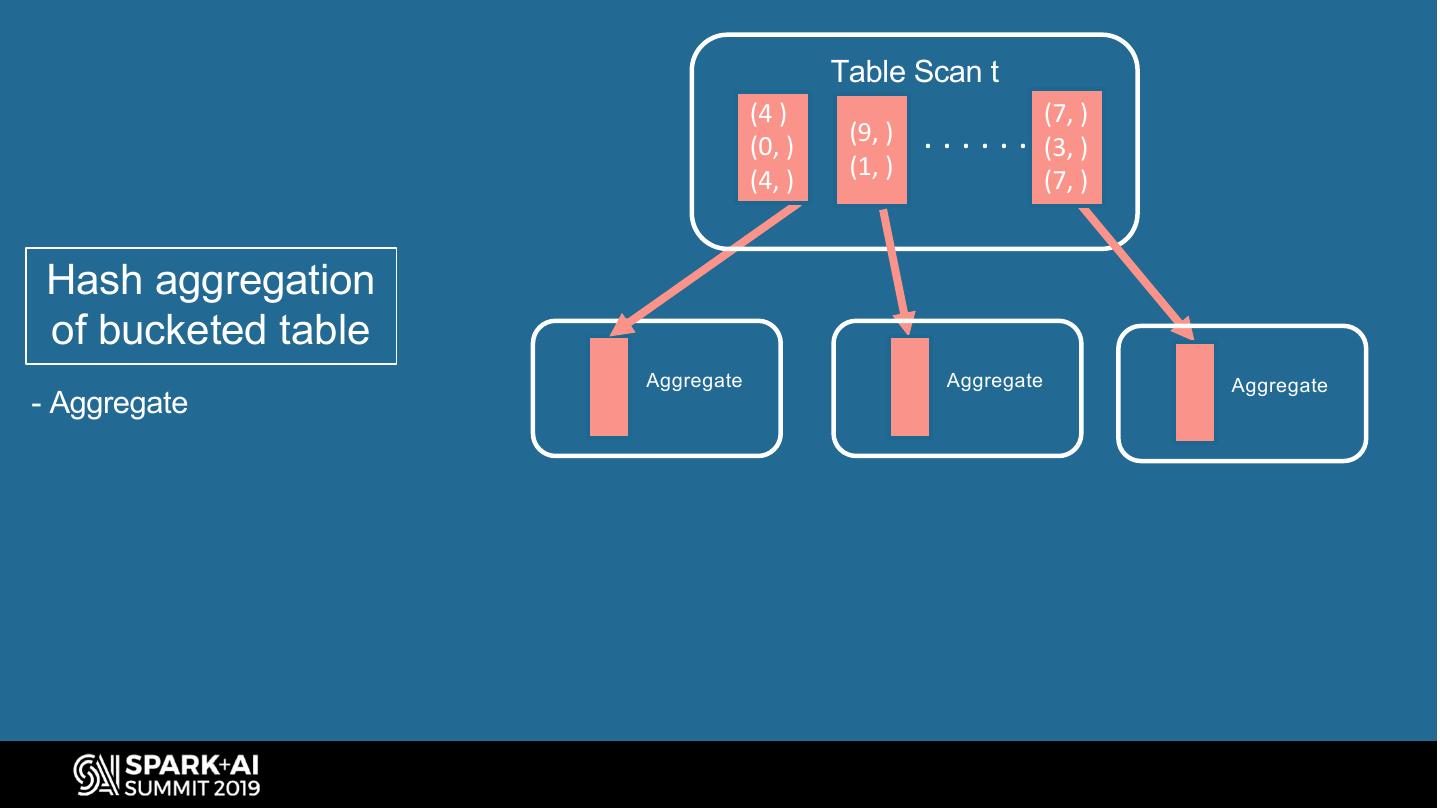
24 . Spark Bucketing Optimizations (group-by) Avoid shuffle when hash-aggregate bucketed tables HashAggregate HashAggregate SELECT . . . FROM t Shuffle(id) TableScan(t) GROUP BY id Query plan to hash- SQL query to group- TableScan(t) aggregate bucketed table by table #UnifiedDataAnalytics #SparkAISummit 24
25 . Table Scan t (5, ) (8, ) (4, ) (3, ) ...... (2, ) (9, ) (2, ) (1, ) Hash aggregation Shuffle Shuffle Shuffle - Shuffle table - Aggregate Aggregate Aggregate Aggregate
26 . Table Scan t (4 ) (7, ) (0, ) (9, ) ...... (3, ) (1, ) (4, ) (7, ) Hash aggregation of bucketed table Aggregate Aggregate Aggregate - Aggregate
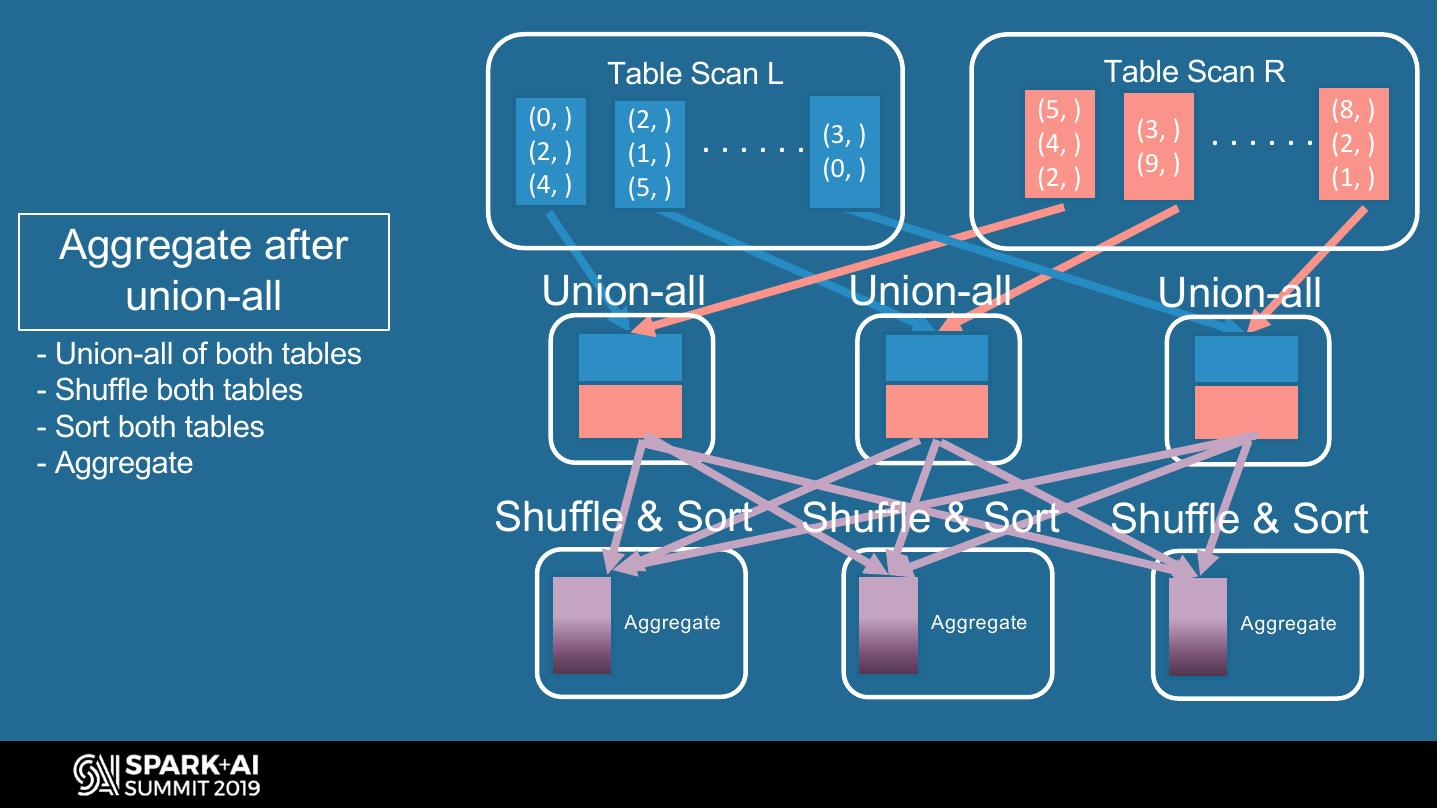
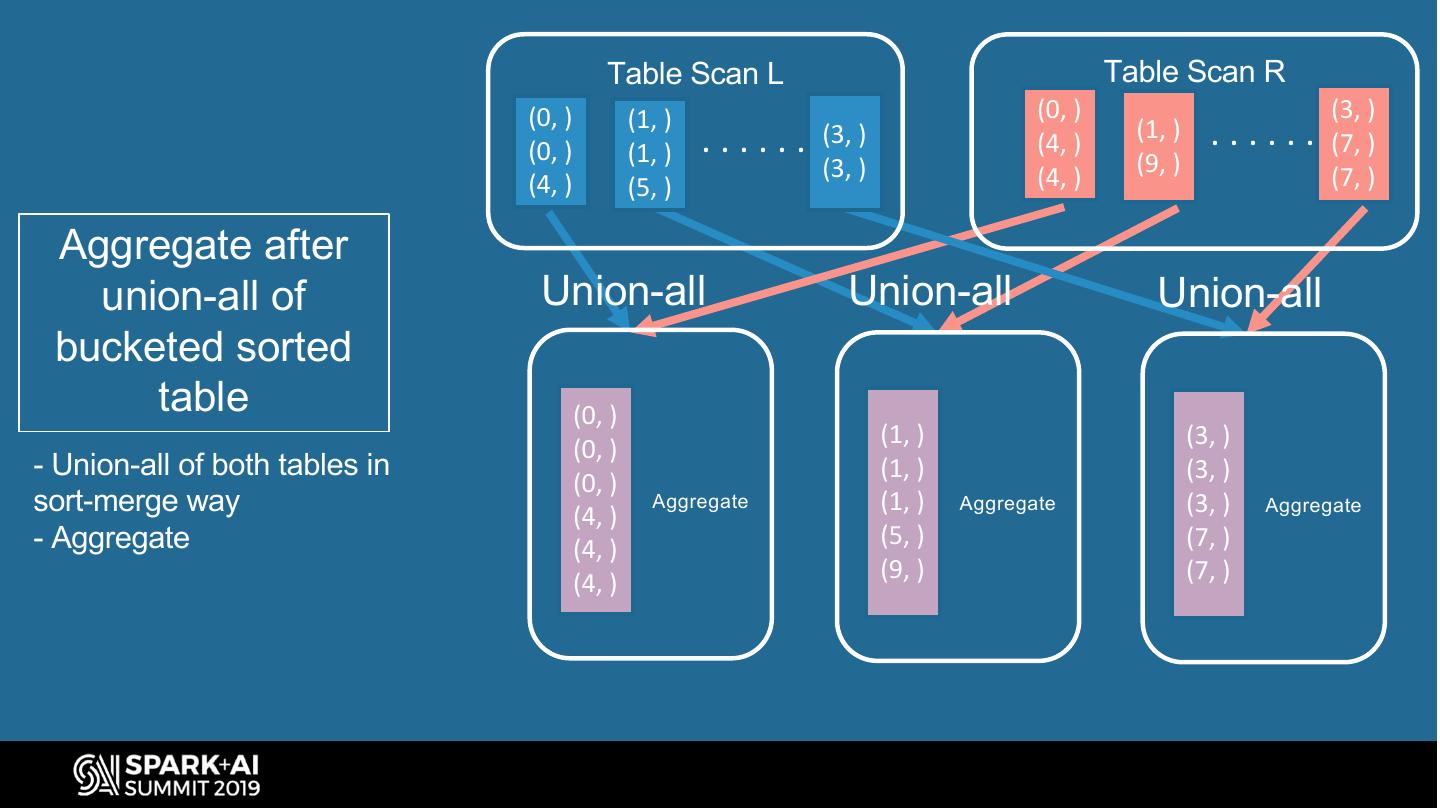
27 . Spark Bucketing Optimizations (union all) Avoid shuffle and sort when join/group-by on union-all of bucketed tables SELECT . . . SortAggregate FROM ( SELECT … FROM L Change UnionExec to Union produce UNION ALL SortedCoalescedRDD SELECT … FROM R instead of CoalescedRDD ) TableScan(L) TableScan(R) GROUP BY id Query plan to hash- SQL query to group-by aggregate union-all of on union-all of tables bucketed tables #UnifiedDataAnalytics #SparkAISummit 27
28 . Table Scan L Table Scan R (0, ) (2, ) (5, ) (8, ) (2, ) (1, ) ...... (3, ) (4, ) (3, ) ...... (2, ) (0, ) (9, ) (4, ) (5, ) (2, ) (1, ) Aggregate after union-all Union-all Union-all Union-all - Union-all of both tables - Shuffle both tables - Sort both tables - Aggregate Shuffle & Sort Shuffle & Sort Shuffle & Sort Aggregate Aggregate Aggregate
29 . Table Scan L Table Scan R (0, ) (1, ) (0, ) (3, ) (0, ) (1, ) ...... (3, ) (4, ) (1, ) ...... (7, ) (3, ) (9, ) (4, ) (5, ) (4, ) (7, ) Aggregate after union-all of Union-all Union-all Union-all bucketed sorted table (0, ) (1, ) (3, ) (0, ) - Union-all of both tables in (1, ) (3, ) (0, ) sort-merge way (4, ) Aggregate (1, ) Aggregate (3, ) Aggregate - Aggregate (5, ) (7, ) (4, ) (9, ) (7, ) (4, )
3秒后跳转登录页面
去登陆

