

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Simplify and Scale Data Engineering Pipelines with Delta Lake
Simplify and Scale Data Engineering Pipelines with Delta Lake
Simplify and Scale Data Engineering Pipelines with Delta Lake
We’re always told to ‘Go for the Gold!,’ but how do we get there? This talk will walk you through the process of moving your data to the finish fine to get that gold metal! A common data engineering pipeline architecture uses tables that correspond to different quality levels, progressively adding structure to the data: data ingestion (‘Bronze’ tables), transformation/feature engineering (‘Silver’ tables), and machine learning training or prediction (‘Gold’ tables). Combined, we refer to these tables as a ‘multi-hop’ architecture. It allows data engineers to build a pipeline that begins with raw data as a ‘single source of truth’ from which everything flows. In this session, we will show how to build a scalable data engineering data pipeline using Delta Lake, so you can be the champion in your organization.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Simplify and Scale Data Engineering Pipelines with Delta Lake Amanda Moran, Databricks #UnifiedDataAnalytics #SparkAISummit
3 .Today’s Speaker ● Solutions Architect @ Databricks ● MS Computer Science, BS Biology ● Previously: HP, Teradata, DataStax, Esgyn ● PMC and Apache Committer on Apache Trafodion ● 5 Different Distributed Systems ● Course with Udacity on Data Engineering
4 .Agenda ● Data Engineers Nightmares and Dreams ● Data Lifecycle vs the Delta Lifecycle ● Transitioning Data Pipeline to Delta ● How Dreams Become True ● DEMO! ● How to use Delta
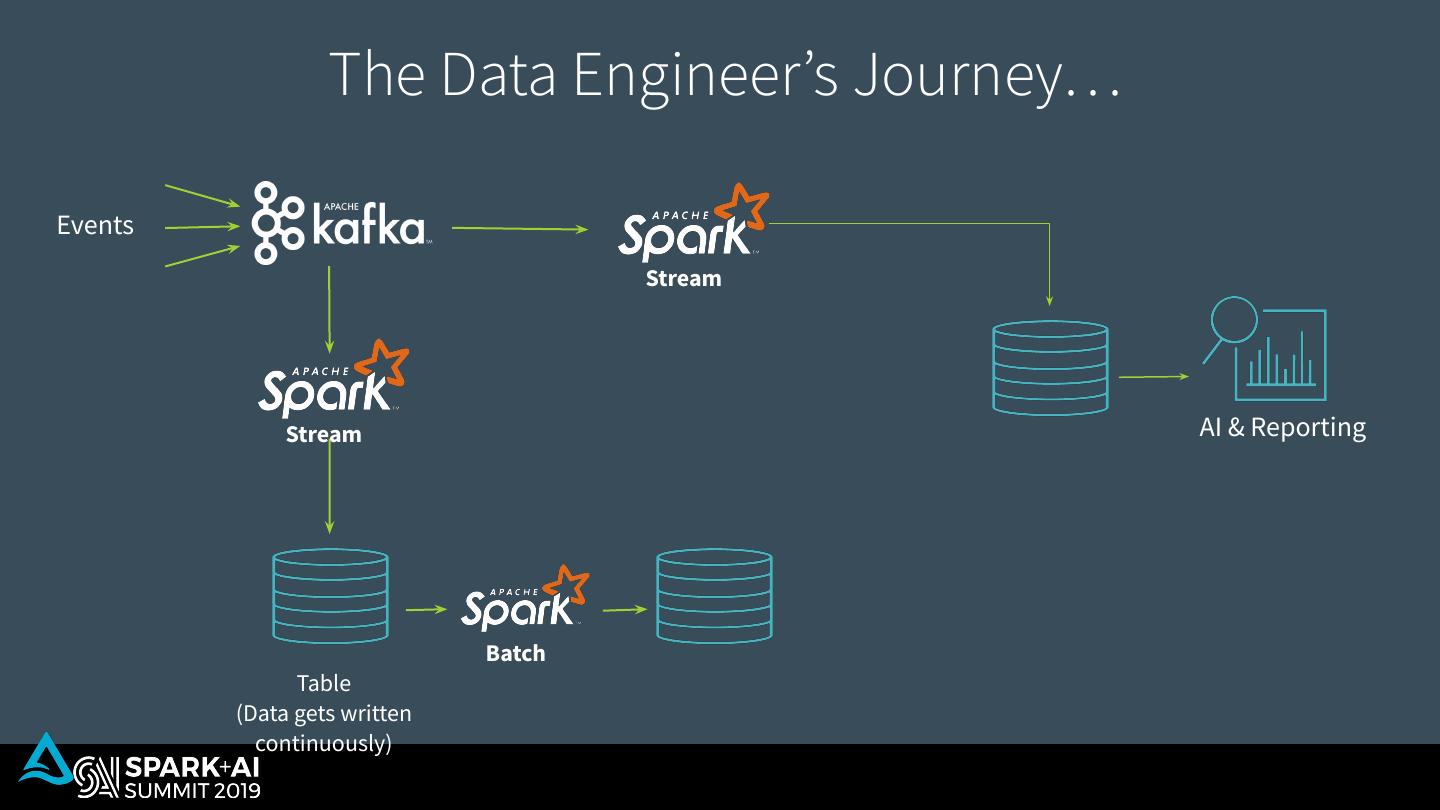
5 . The Data Engineer’s Journey… Events Stream Stream AI & Reporting Batch Table (Data gets written continuously)
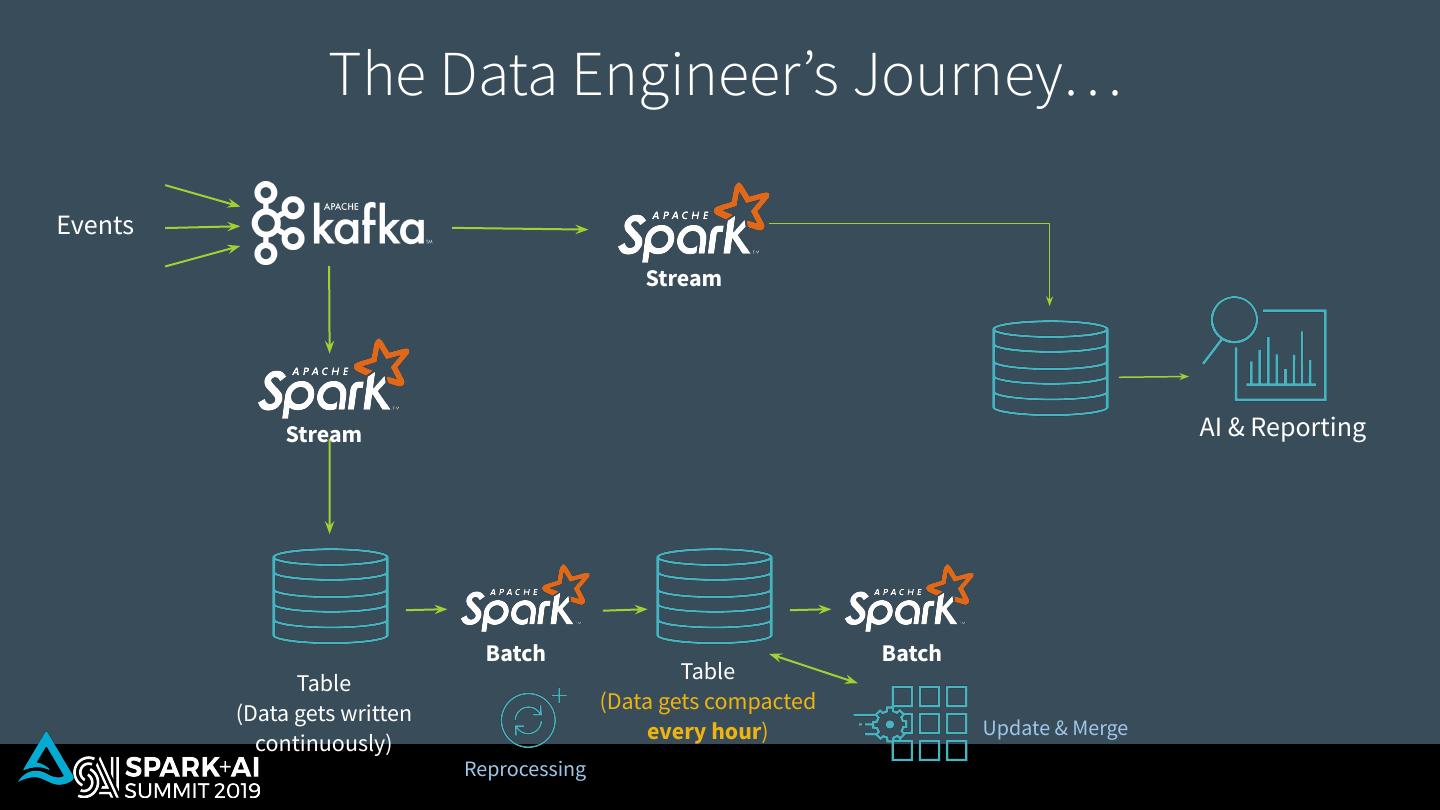
6 . The Data Engineer’s Journey… Events Stream Stream AI & Reporting Batch Batch Table Table (Data gets compacted (Data gets written every hour) Update & Merge continuously) Reprocessing
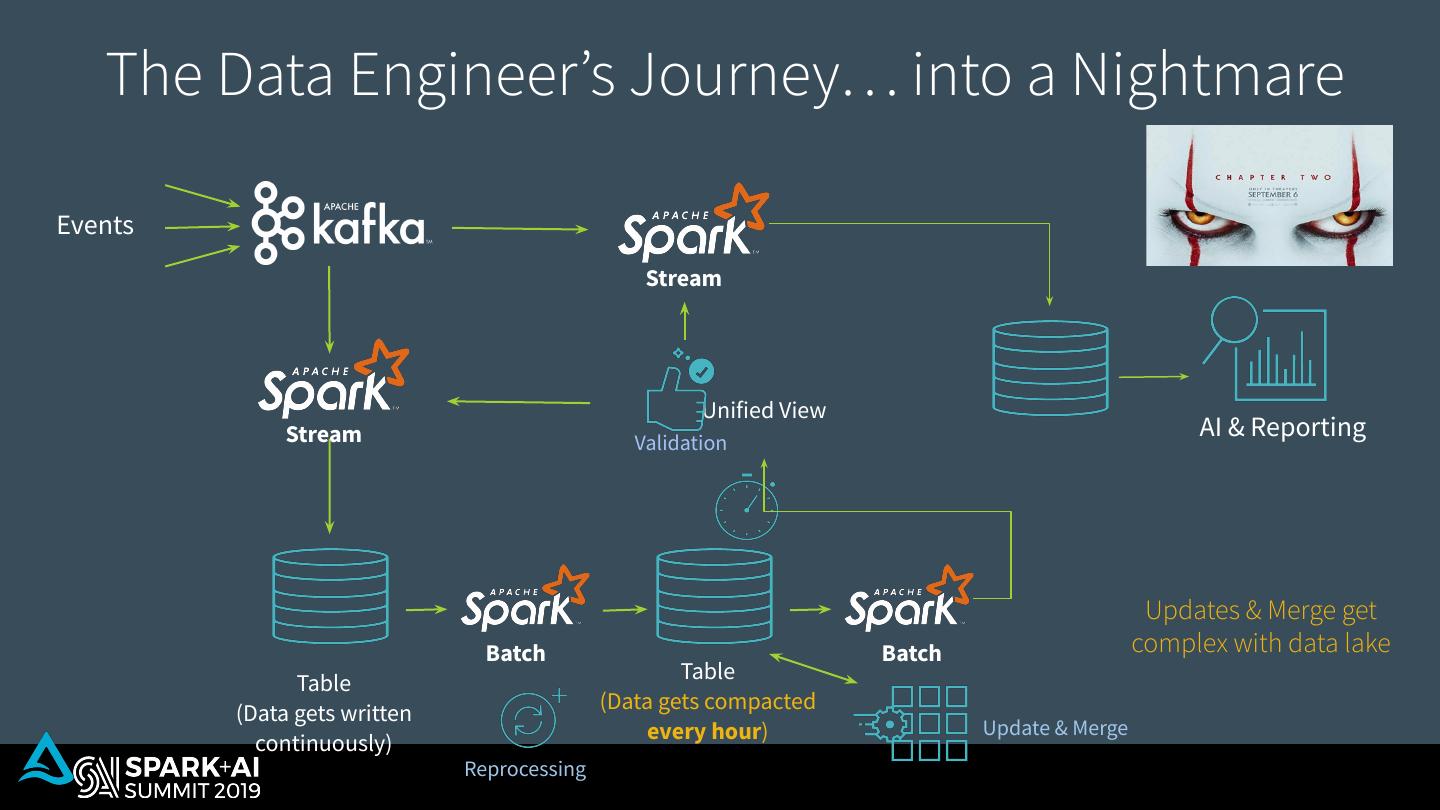
7 . The Data Engineer’s Journey… into a Nightmare Events Stream Unified View Stream AI & Reporting Validation Updates & Merge get Batch Batch complex with data lake Table Table (Data gets compacted (Data gets written every hour) Update & Merge continuously) Reprocessing
8 . The Data Engineer’s Journey… into a Nightmare Events Stream d ? p il fie e s i m AI & Reporting Stream s b Validation Unified View a n thi C Updates & Merge get Batch Batch complex with data lake Table Table (Data gets compacted (Data gets written every hour) Update & Merge continuously) Reprocessing
9 . A Data Engineer’s Dream... Process data continuously and incrementally as new data arrive in a cost efficient way without having to choose between batch or streaming Kinesis CSV, AI & Reporting JSON, TXT… Data Lake
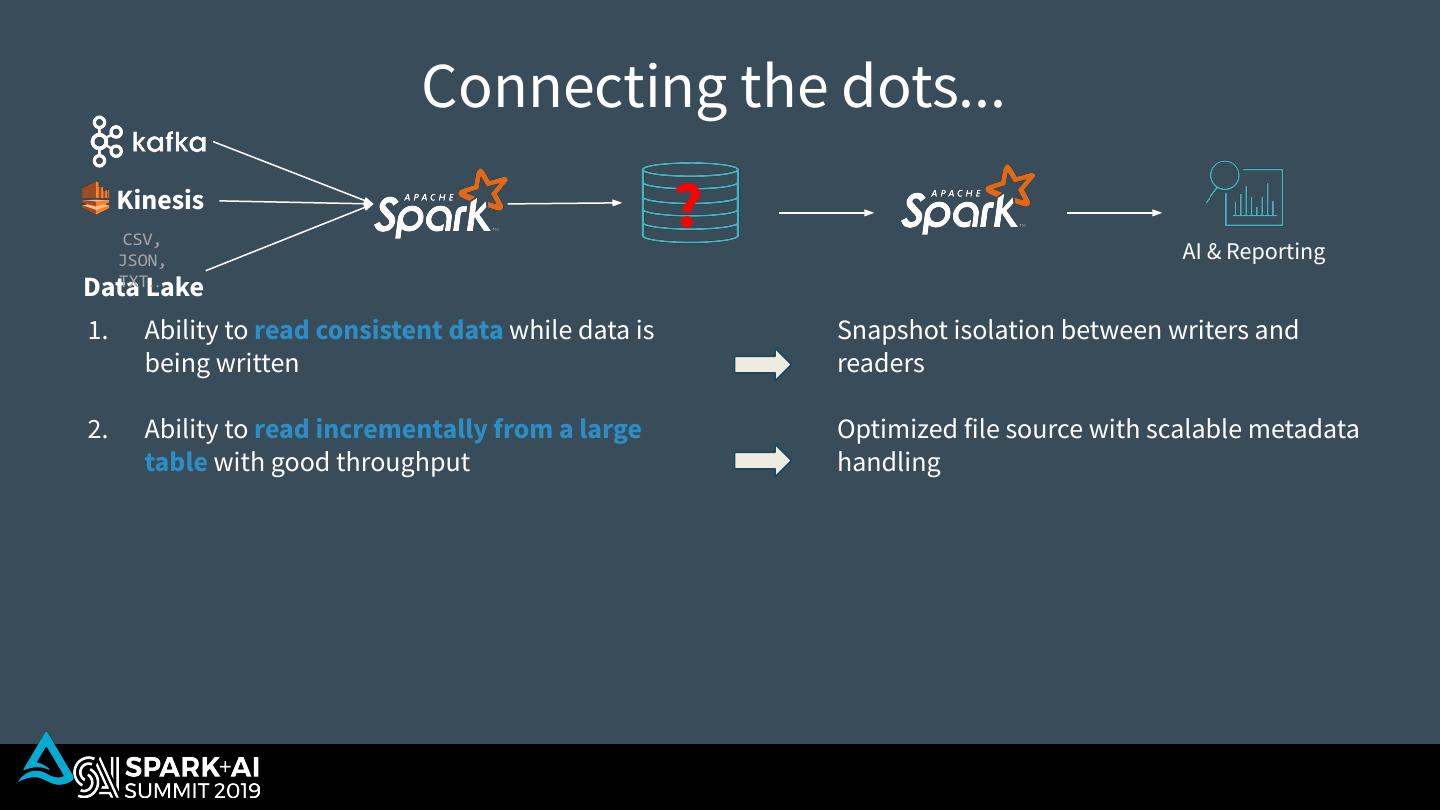
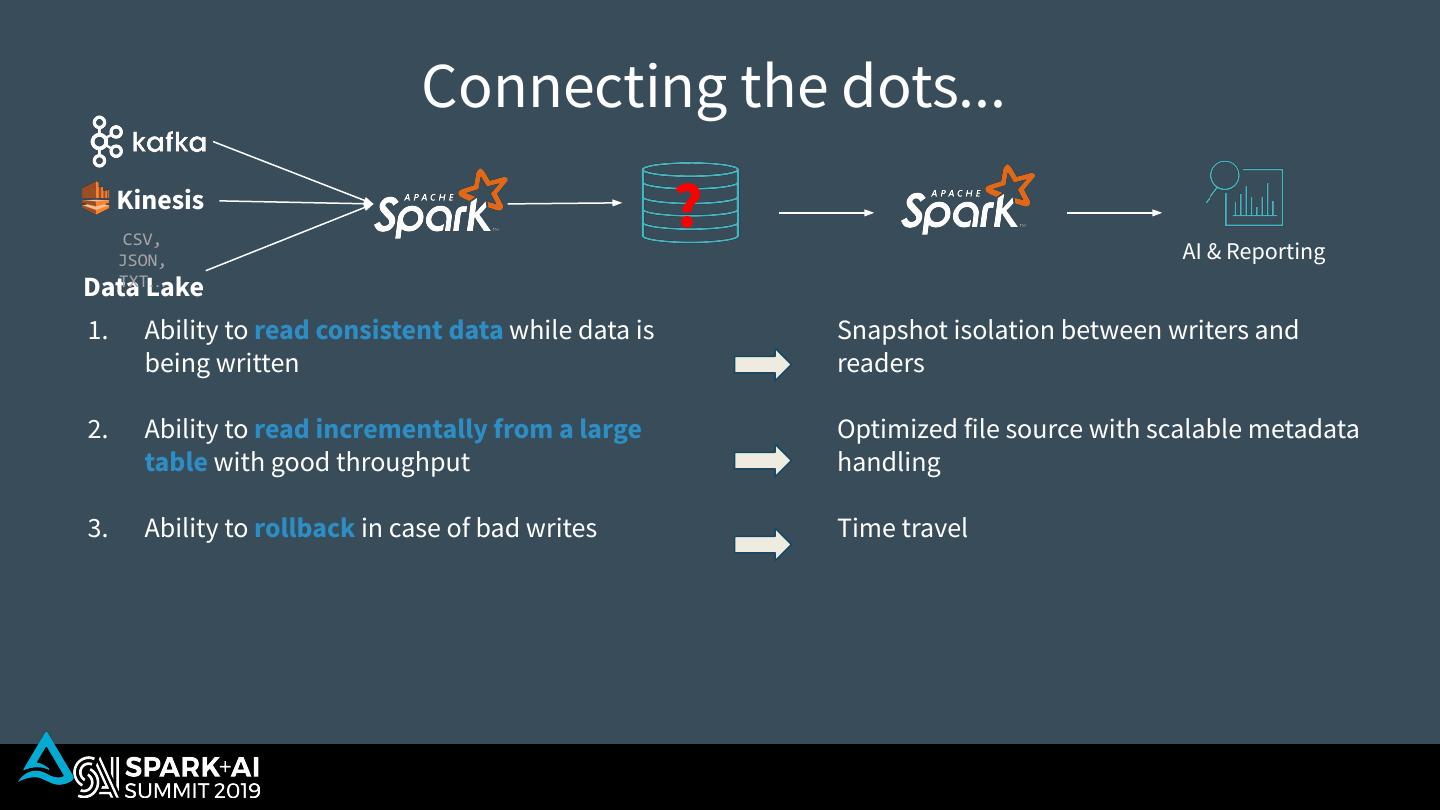
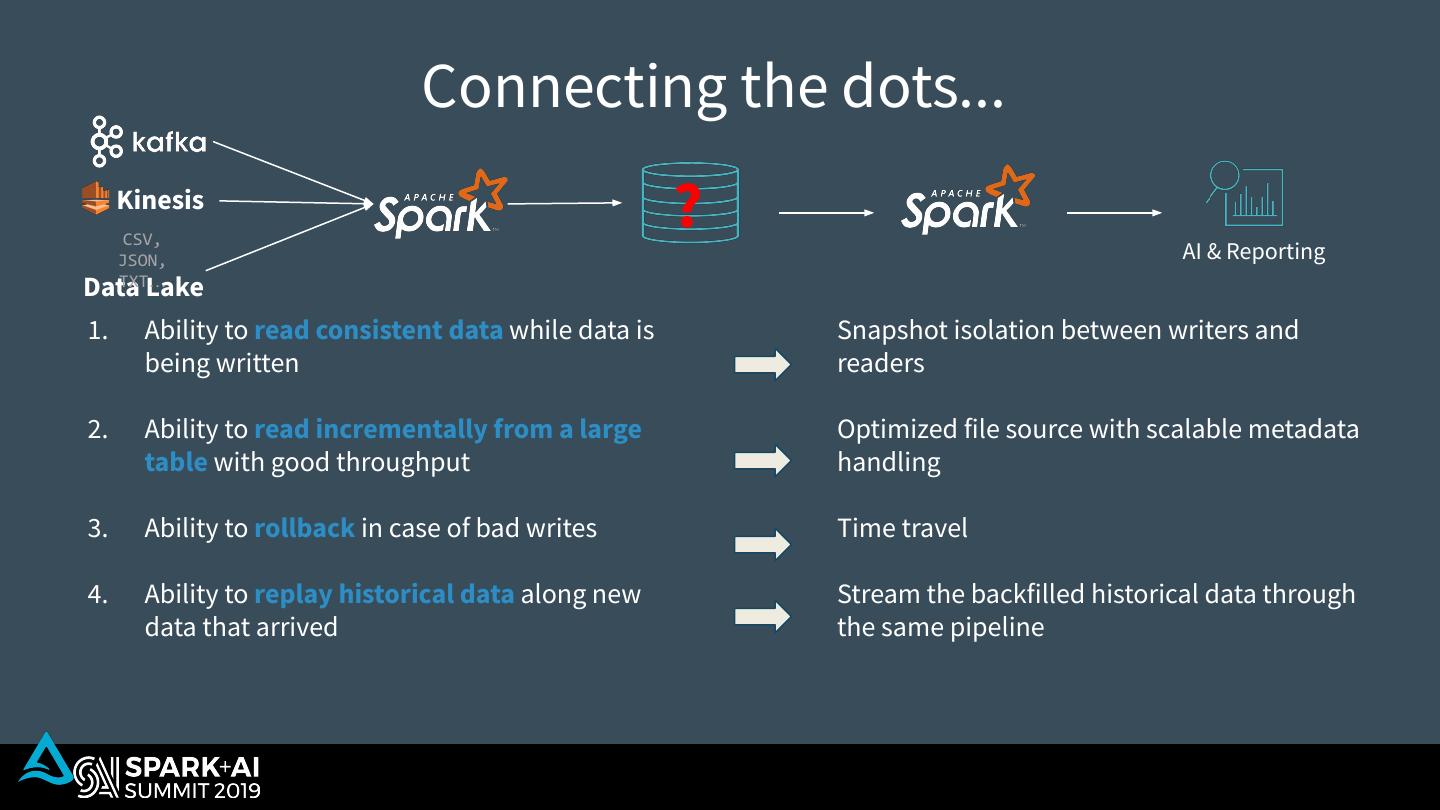
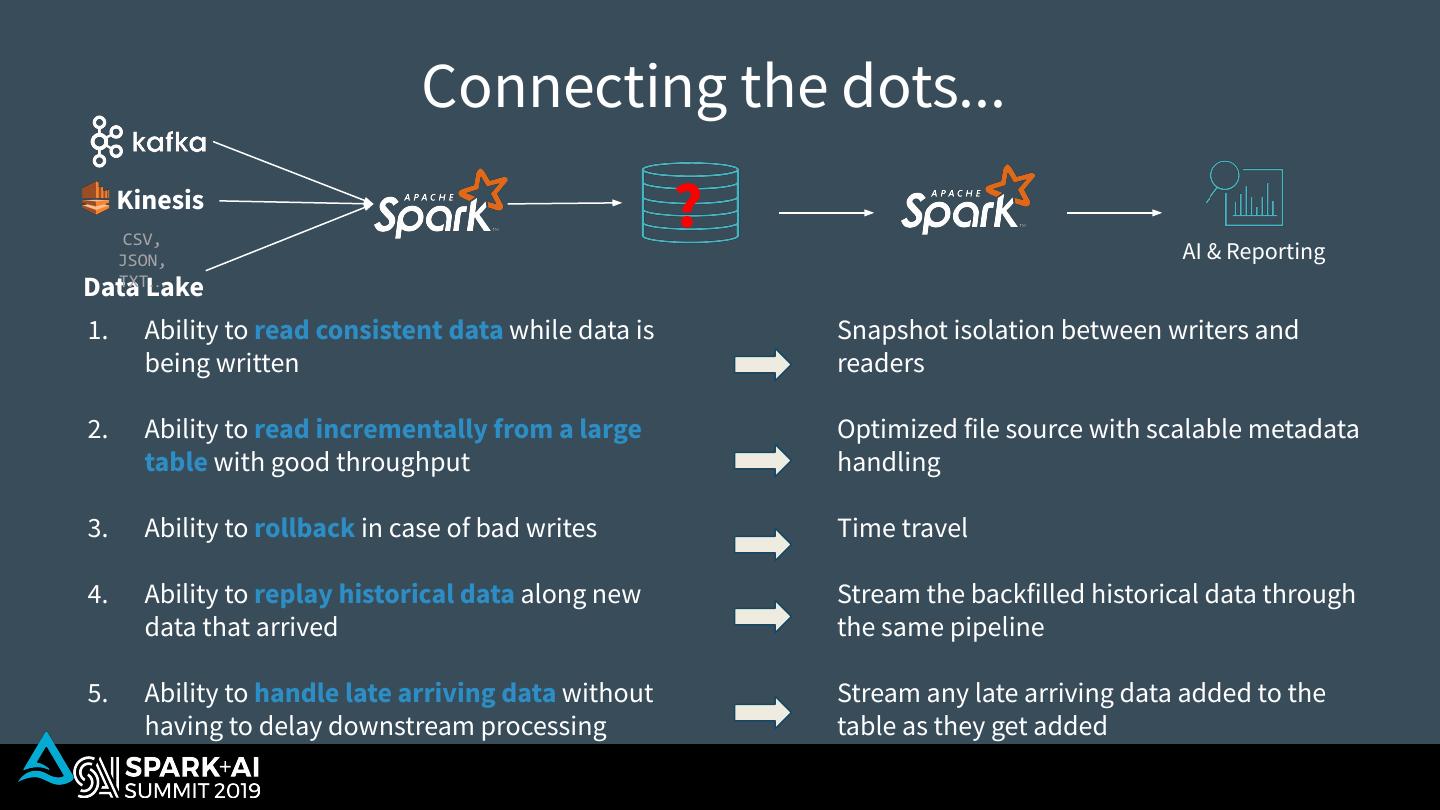
10 . What’s missing? Kinesis CSV, ? AI & Reporting JSON, TXT… Data Lake 1. Ability to read consistent data while data is being written 2. Ability to read incrementally from a large table with good throughput 3. Ability to rollback in case of bad writes 4. Ability to replay historical data along new data that arrived 5. Ability to handle late arriving data without having to delay downstream processing
11 . So… What is the answer? The + = Delta STRUCTURED STREAMING Architecture 1. Unify batch & streaming with a continuous data flow model 2. Infinite retention to replay/reprocess historical events as needed 3. Independent, elastic compute and storage to scale while balancing costs
12 .Let’s try it instead with
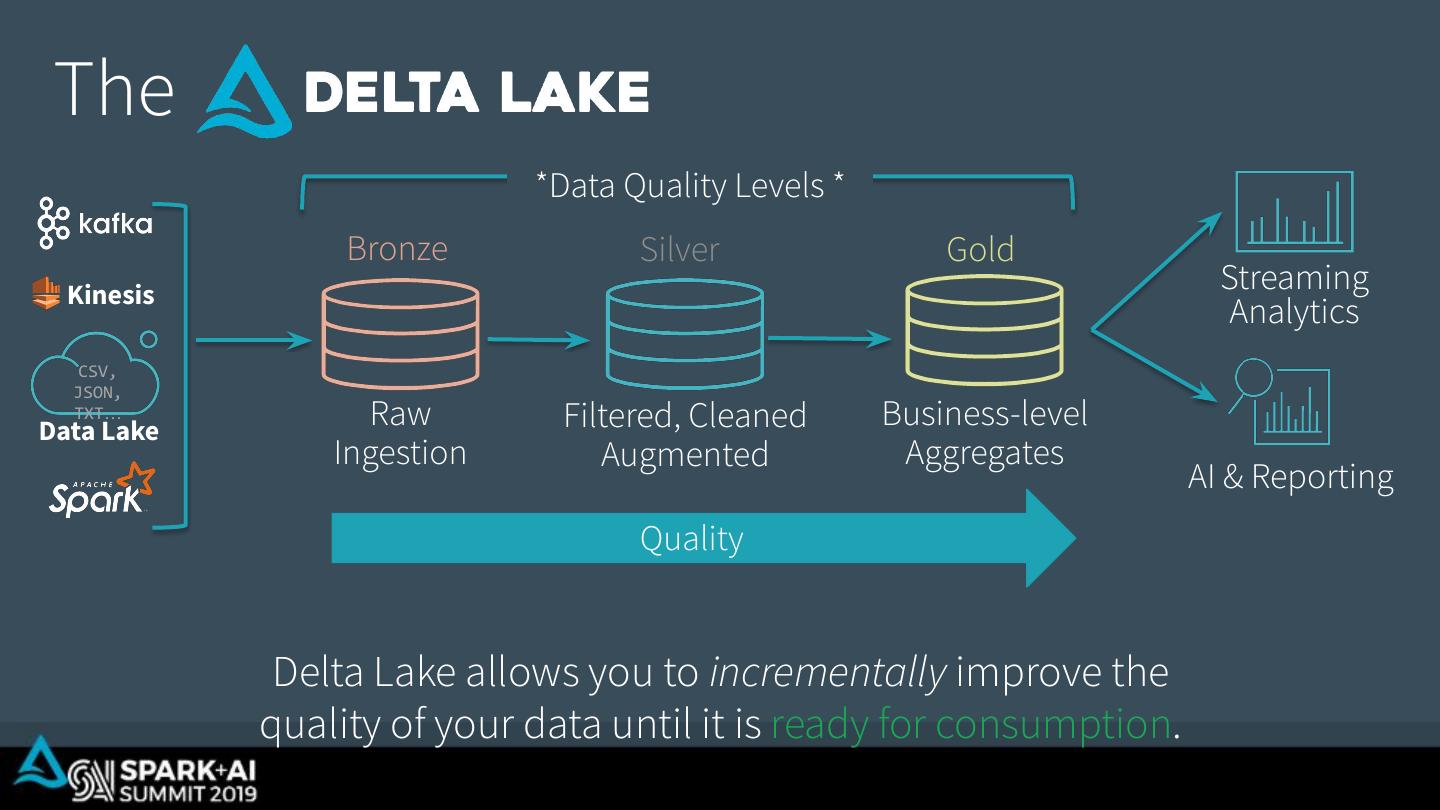
13 . The *Data Quality Levels * Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality Delta Lake allows you to incrementally improve the quality of your data until it is ready for consumption.
14 .What does this remind you of?
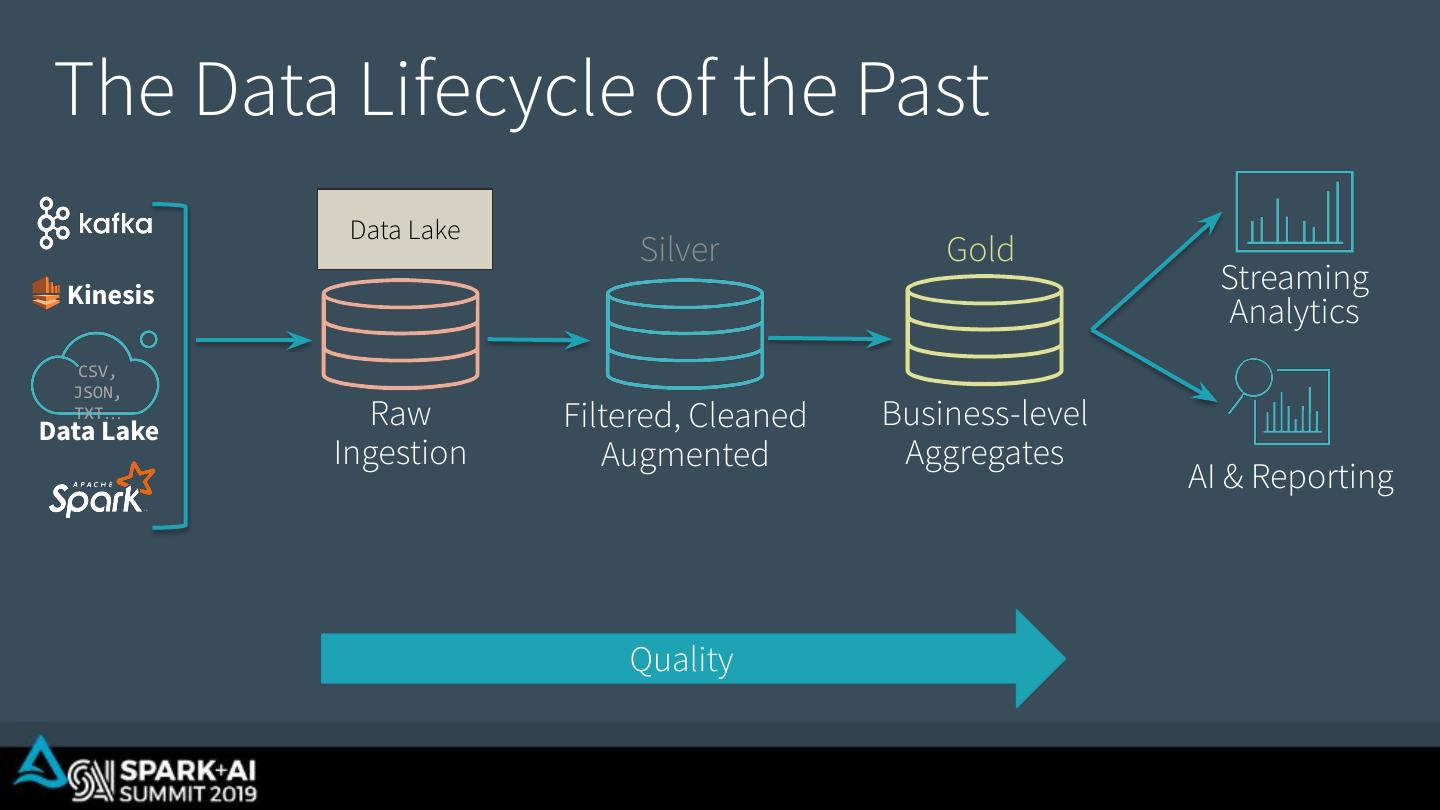
15 . The Data Lifecycle of the Past Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality
16 . The Data Lifecycle of the Past Data Lake Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality
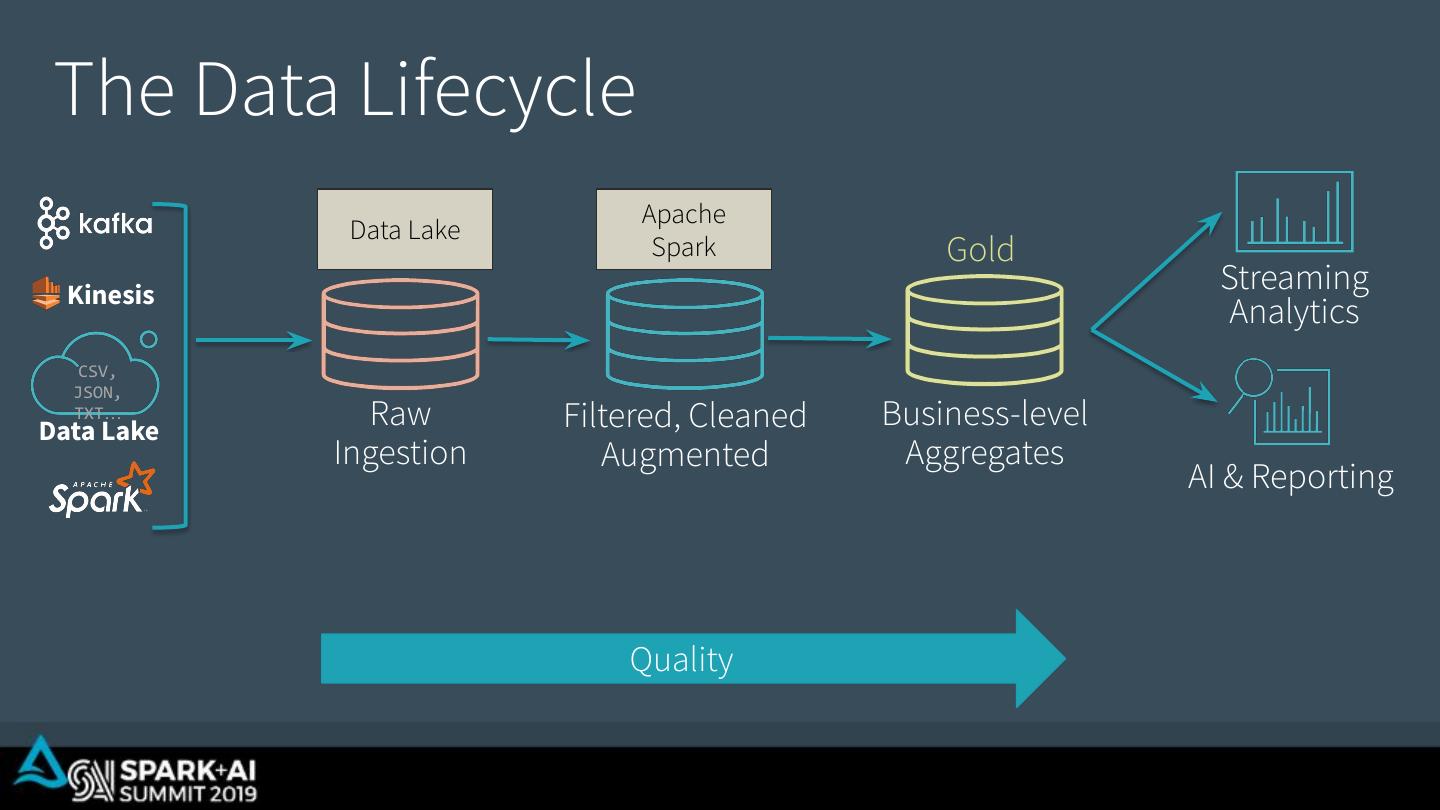
17 . The Data Lifecycle Apache Data Lake Bronze Silver Spark Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality
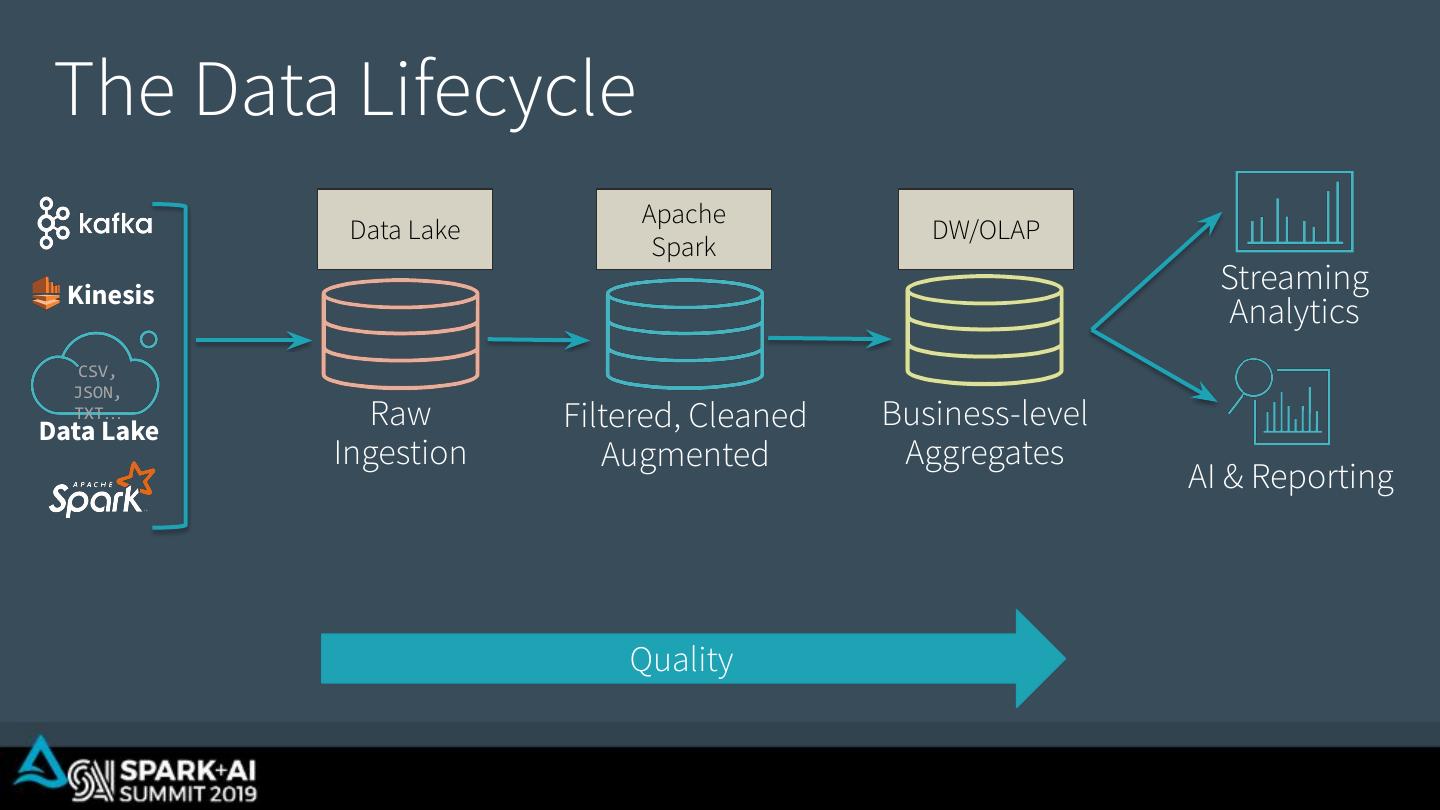
18 . The Data Lifecycle Apache Data Lake DW/OLAP Bronze Silver Spark Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality
19 .Transitioning from the Data Lifecycle to the Delta Lake Lifecycle
20 . The *Data Quality Levels * Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Quality Delta Lake allows you to incrementally improve the quality of your data until it is ready for consumption.
21 . The Bronze Silver Gold Kinesis Streaming �� Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting •Dumping ground for raw data •Often with long retention (years) •Avoid error-prone parsing
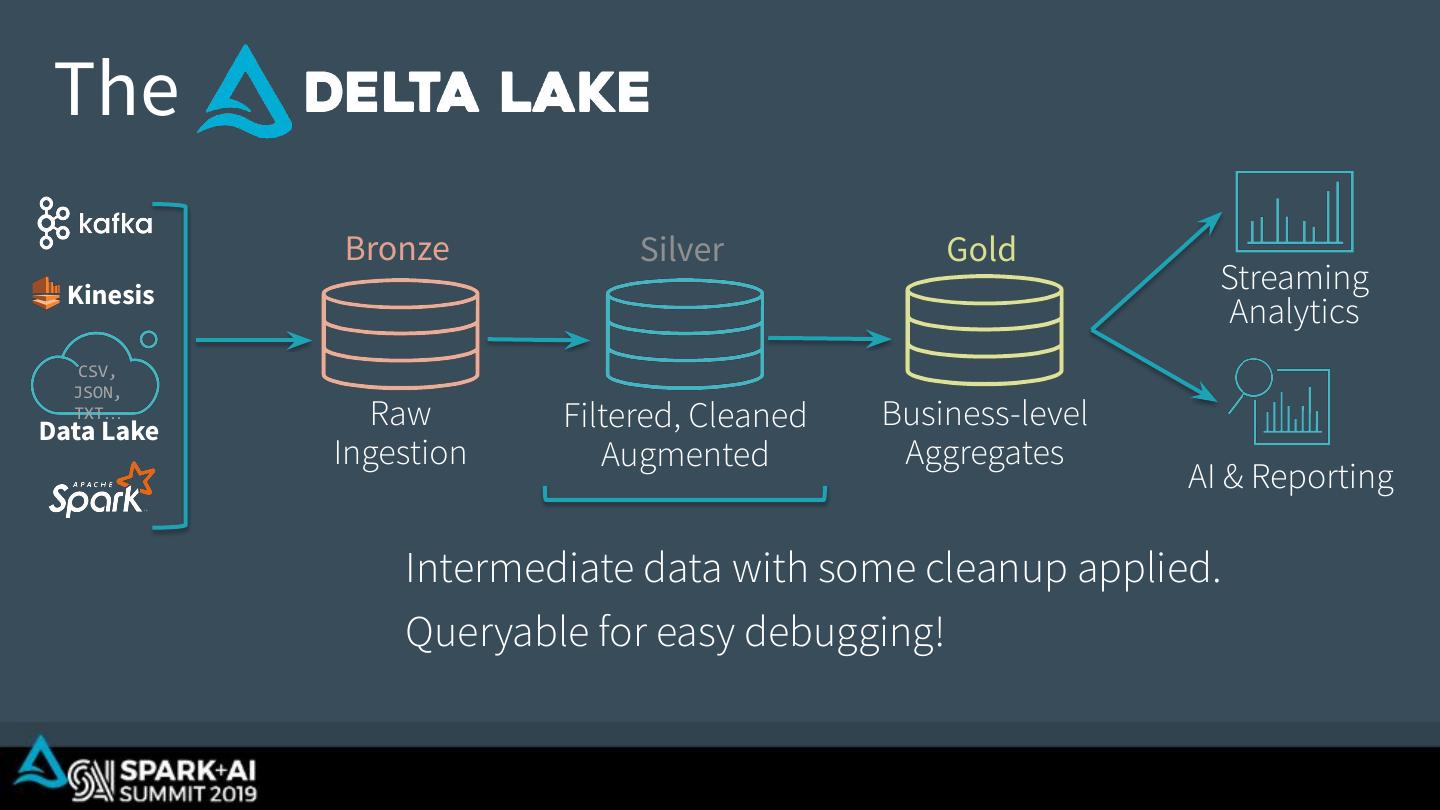
22 . The Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Intermediate data with some cleanup applied. Queryable for easy debugging!
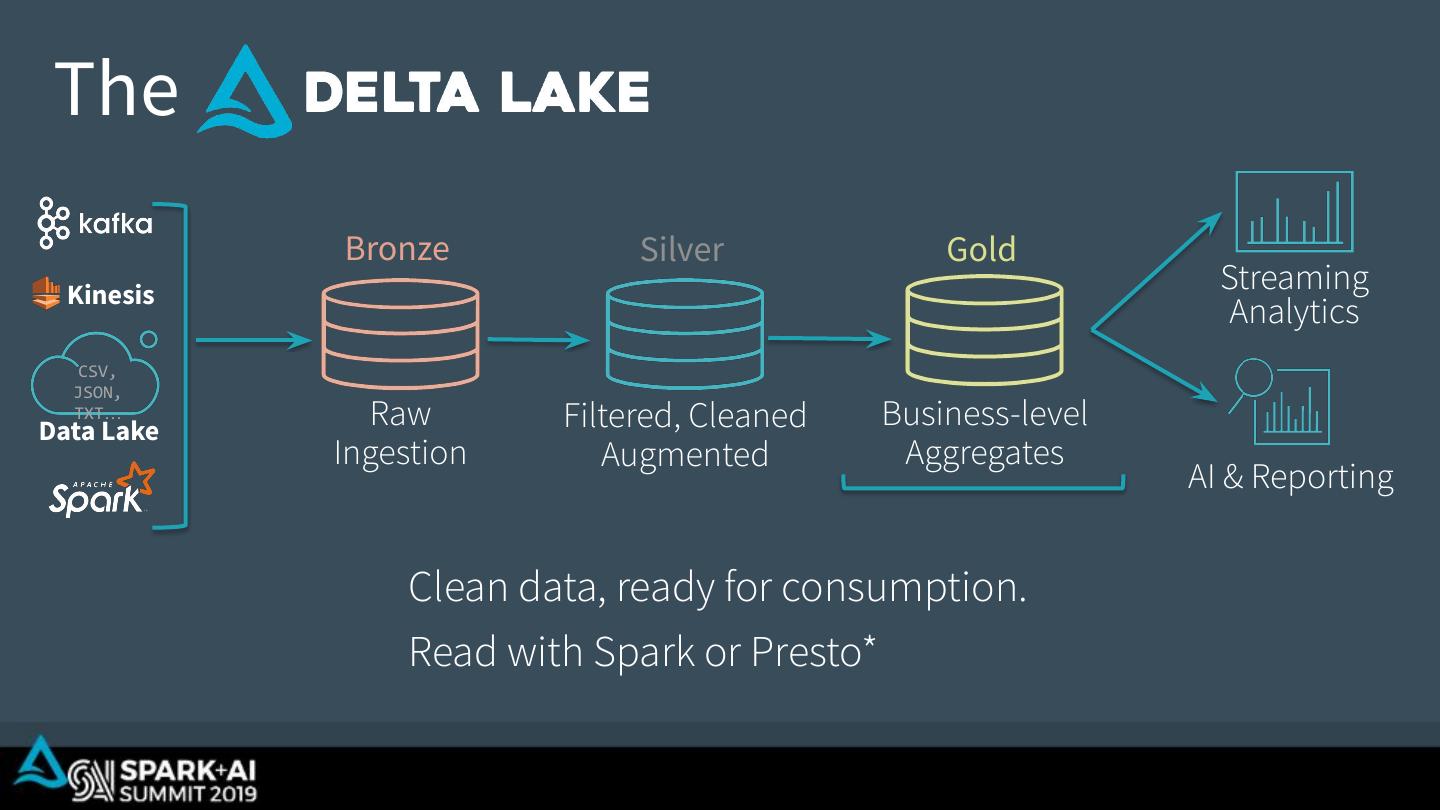
23 . The Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Clean data, ready for consumption. Read with Spark or Presto*
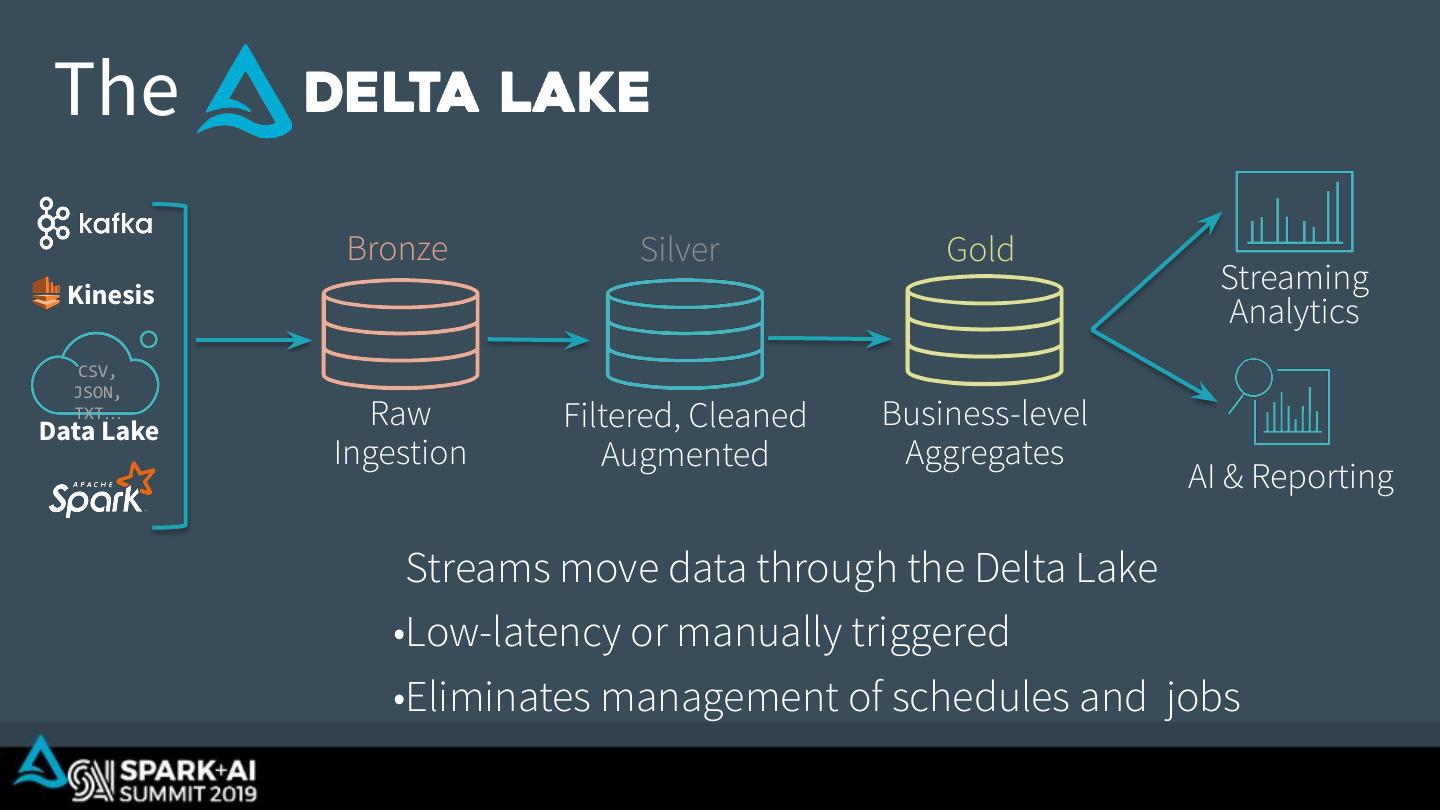
24 . The Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Streams move data through the Delta Lake •Low-latency or manually triggered •Eliminates management of schedules and jobs
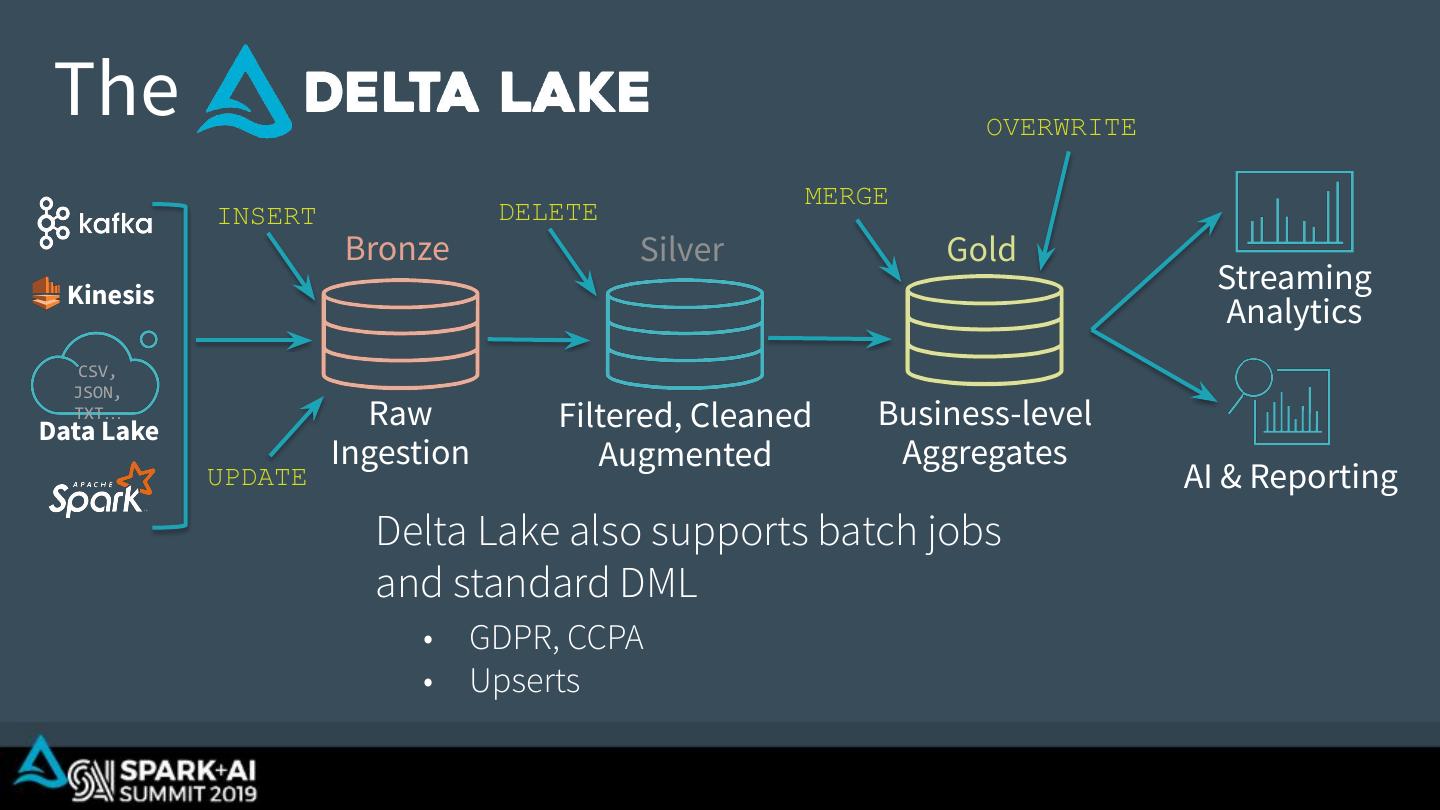
25 . The OVERWRITE MERGE INSERT DELETE Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates UPDATE AI & Reporting Delta Lake also supports batch jobs and standard DML • GDPR, CCPA • Upserts
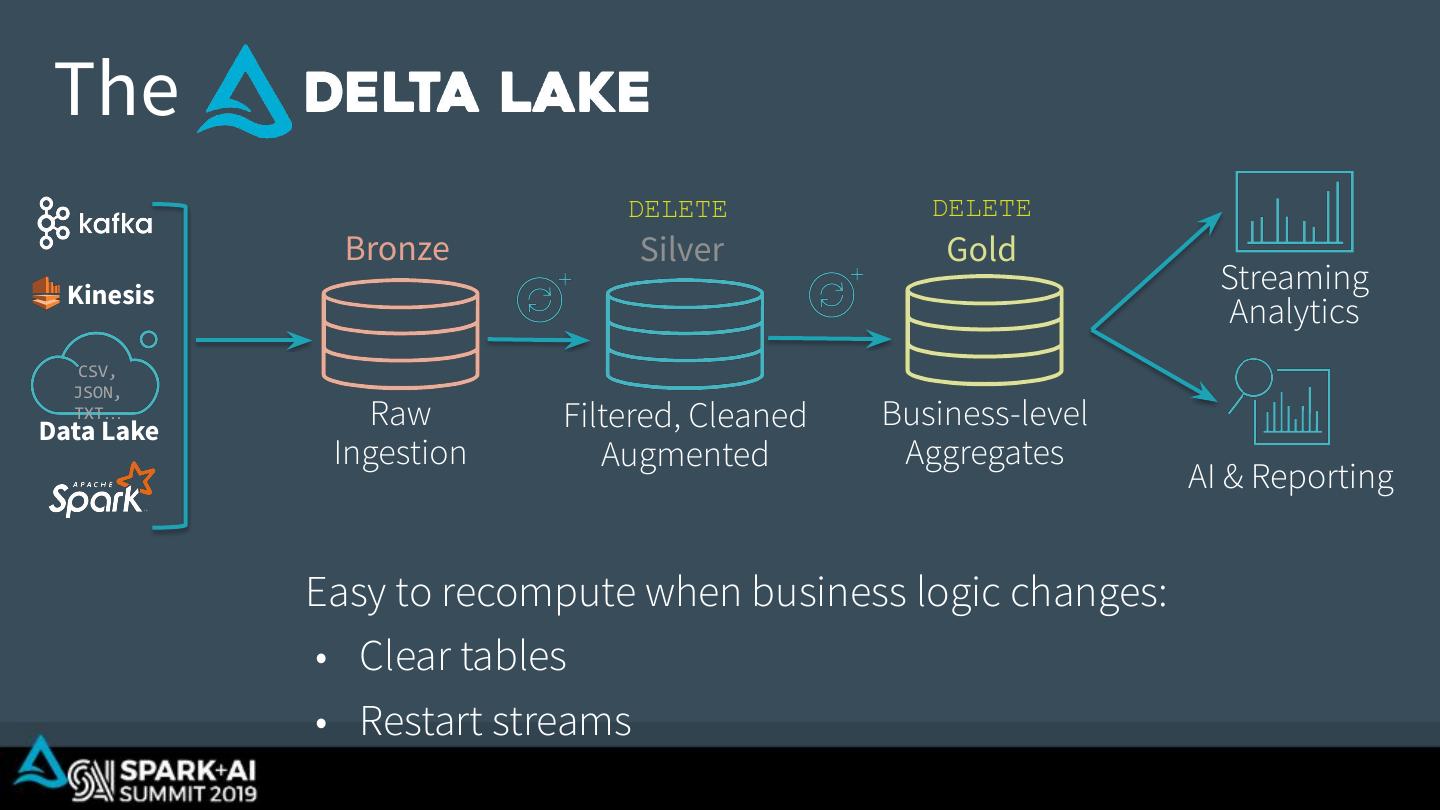
26 . The DELETE DELETE Bronze Silver Gold Kinesis Streaming Analytics CSV, JSON, TXT… Data Lake Raw Filtered, Cleaned Business-level Ingestion Augmented Aggregates AI & Reporting Easy to recompute when business logic changes: • Clear tables • Restart streams
27 .How the Dream Becomes True
28 .Demo Time
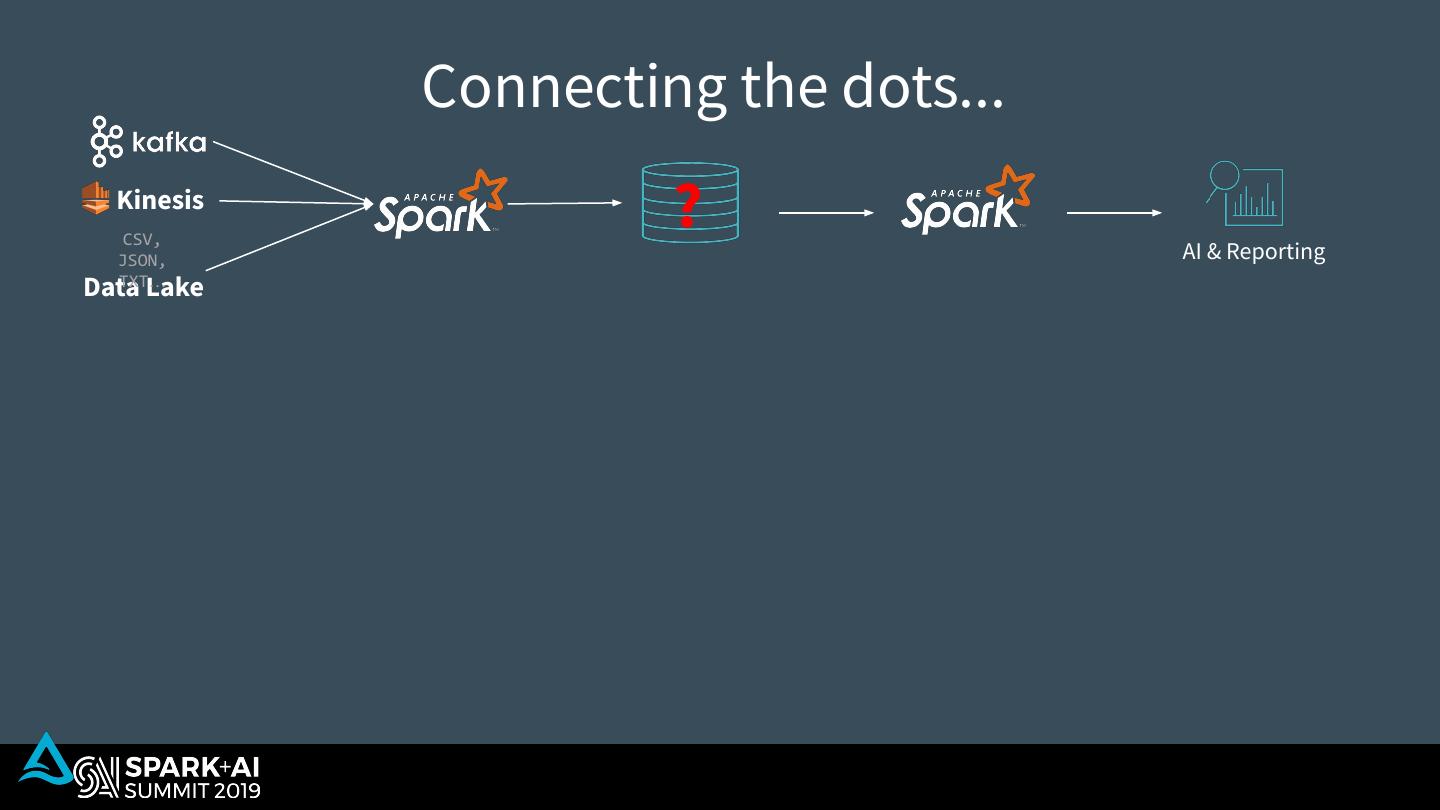
29 . Connecting the dots... Kinesis CSV, ? AI & Reporting JSON, TXT… Data Lake
3秒后跳转登录页面
去登陆

