展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Scaling Spark on
Kubernetes
Li Gao, Lyft
Rohit Menon, Lyft
#UnifiedAnalytics #SparkAISummit
�
3 .Introduction
Li Gao
Works in the Data Platform team at Lyft, currently leading the Compute Infra
initiatives including Spark on Kubernetes.
Previously at Salesforce, Fitbit, Groupon, and other startups.
Rohit Menon
Rohit Menon is a Software Engineer on the Data Platform team at Lyft. Rohit's
primary area of focus is building and scaling out the Spark and Hive Infrastructure
for ETL and Machine learning use cases.
Previously at EA, VMWare
#UnifiedAnalytics #SparkAISummit 3
�
4 .Agenda
● Introduction of Data Landscape at Lyft
● The challenges we face
● How Apache Spark on Kubernetes can help
● Remaining work
#UnifiedAnalytics #SparkAISummit 4
�
5 . Data Landscape
● Batch data Ingestion and ETL
● Data Streaming
● ML platforms
● Notebooks and BI tools
● Query and Visualization
● Operational Analytics
● Data Discovery & Lineage
● Workflow orchestration
● Cloud Platforms
#UnifiedAnalytics #SparkAISummit 5
�
6 .Evolving Batch Architecture
Vendor-based Hive on MR Hive on Tez + Spark on
Hadoop Vendor Presto Spark Adhoc Vendor GA
2016-2017 2017-2018 Mid 2018 Late 2018 Early 2019 Future
Spark on K8s Spark on K8s
Alpha Beta
6
�
7 .What batch compute is used for
AWS S3
AWS S3
Events Batch
Presto, Hive Client, and BI Tools
Compute Analysts
Ext Data Clusters
Ingest Pipelines
RDB/KV
HMS Engineers
Sys Events
Services
Scientists
7
�
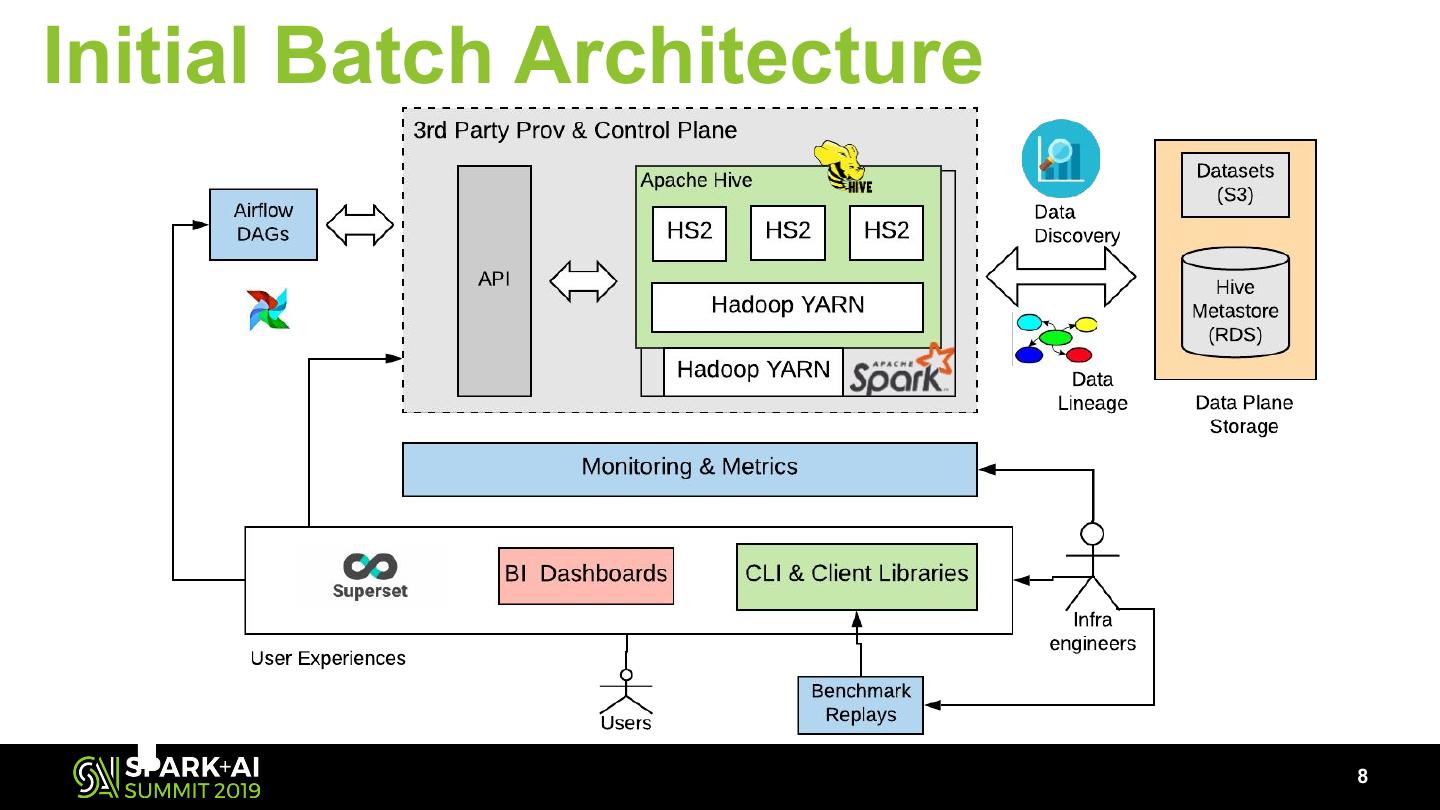
8 .Initial Batch Architecture
8
�
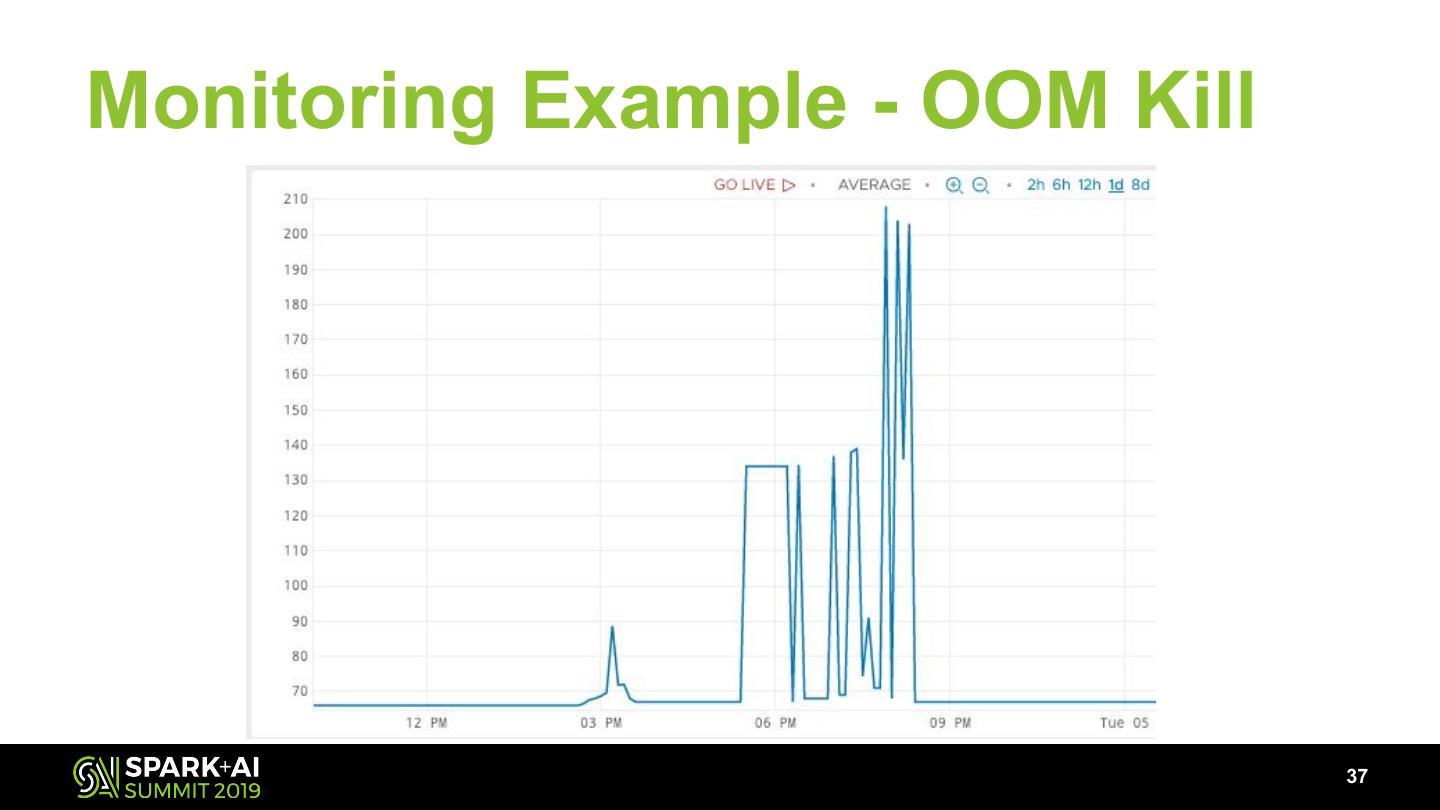
9 .Batch Compute Challenges
● 3rd Party vendor dependency limitations
● Data ETL expressed solely in SQL
● Complex logic expressed in Python that hard to adopt
in SQL
● Different dependencies and versions
● Resource load balancing for heterogeneous workloads
9
�
10 .3rd Party Vendor Limitations
● Proprietary patches
● Inconsistent bootstrap
● Release schedule
● Homogeneous environments
10
�
11 .Is SQL the complete solution?
11
�
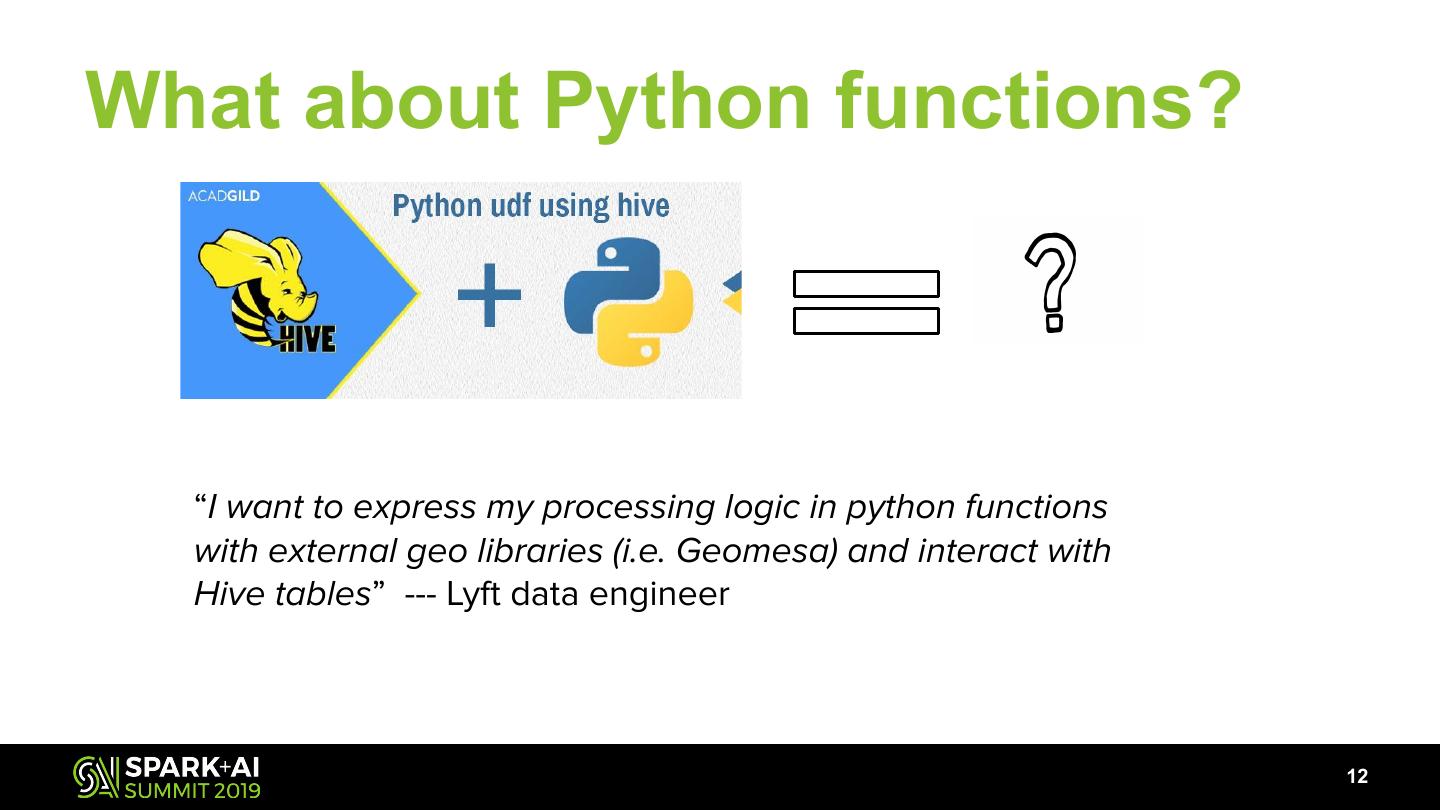
12 .What about Python functions?
“I want to express my processing logic in python functions
with external geo libraries (i.e. Geomesa) and interact with
Hive tables” --- Lyft data engineer
12
�
13 .How Spark can help?
Applications
APIs
Environments
Data Sources RDB/KV
and Data
Sinks
13
�
14 .What challenges remain?
● Per job custom dependencies
● Handling version requirements (Py3 v.s. Py2)
● Still need to run on shared clusters for cost efficiency
14
�
15 .What about dependencies?
RTree Libraries
Spatial Libraries
Data Codecs
15
�
16 .Different Spark or Hive versions?
● Legacy jobs that require Spark 2.2
● Newer Jobs require Spark 2.3 or Spark 2.4
● Hive 2.1 SQL and Hive 2.3
16
�
17 .How Kubernetes can help?
Pods Ingress
Multi-Tenancy Support
Pods Services
Service Mesh
Event driven &
Immutability
Declarative
Namespaces Operators &
Controllers
Community + CNCF
17
�
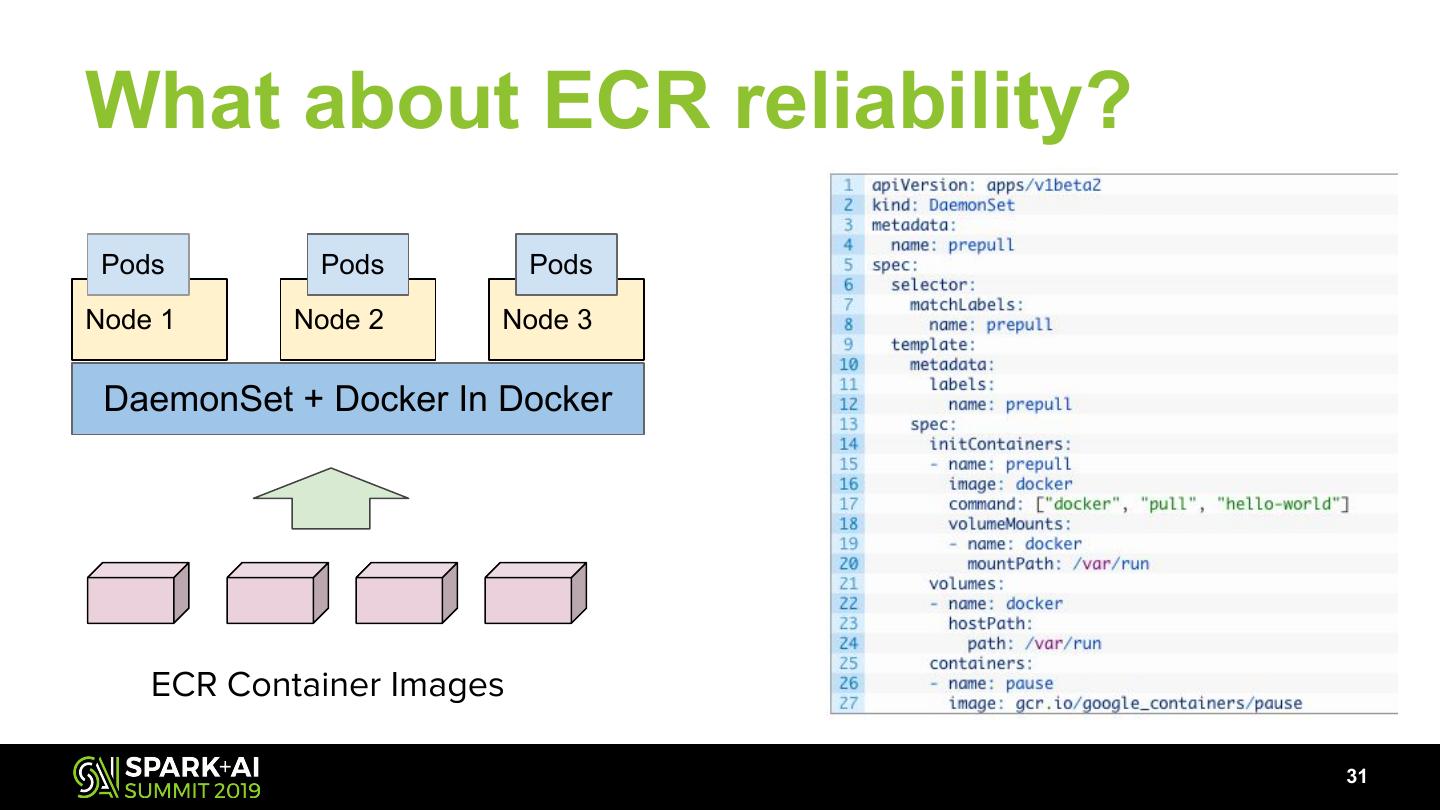
19 .What challenges still remain?
● Spark on k8s is still in its early days
● Single cluster scaling limit
● CRD and control plane update
● Pod churn and IP allocations throttling
● ECR container registry reliability
19
�
20 .Current scale
● 10s PB data lake
● (O) 100k batch jobs running daily
● ~ 1000s of EC2 nodes spanning multiple
clusters and AZs
● ~ 1000s of workflows running daily
20
�
21 . How Lyft scales Spark on K8s
# of Clusters # of Namespaces
# of Nodes
# of Pods
Pod Size
Pod Churn Rate
Affinity & Isolation
ECR Rate Limit
Job:Pod ratio IP Alloc Rate Limit QoS & Quota
21
�
22 .The Evolving Architecture
22
�
24 .HA in Cluster Pool
Cluster Pool A
Cluster 3
Cluster 1
Cluster 2
Cluster 4
● Cluster rotation within a cluster pool
● Automated provisioning of a new cluster and (manually) add into rotation
● Throttle at lower bound when rotation in progress
24
�
25 .Multiple Namespaces (Groups)
Role1 Role1 Role2
Pod Pod Pod Pod Pod Pod Pod Pod Pod
Namespace 1 Namespace 2 Namespace 3
Max Pod Size 1 Max Pod Size 2
Node A Node B Node C Node D
● Practical ~3K active pods per namespace observed
● Less preemption required when namespace isolated by quota
● Different namespaces can map different IAM roles and sidecar
configurations
25
�
26 .Pod Sharing
Shared Pods
Job
Controller Spark Driver Spark Exec Dep
Job 1 Pod Pods
Job 4
AWS
S3
Job 2 Driver Job 2 Exec
Pod Pods
Job 2
Dep
Job 3 Driver Job 3 Exec
Job 3 Pod Pods
Dep
Dedicate & Isolated Pods
26
�
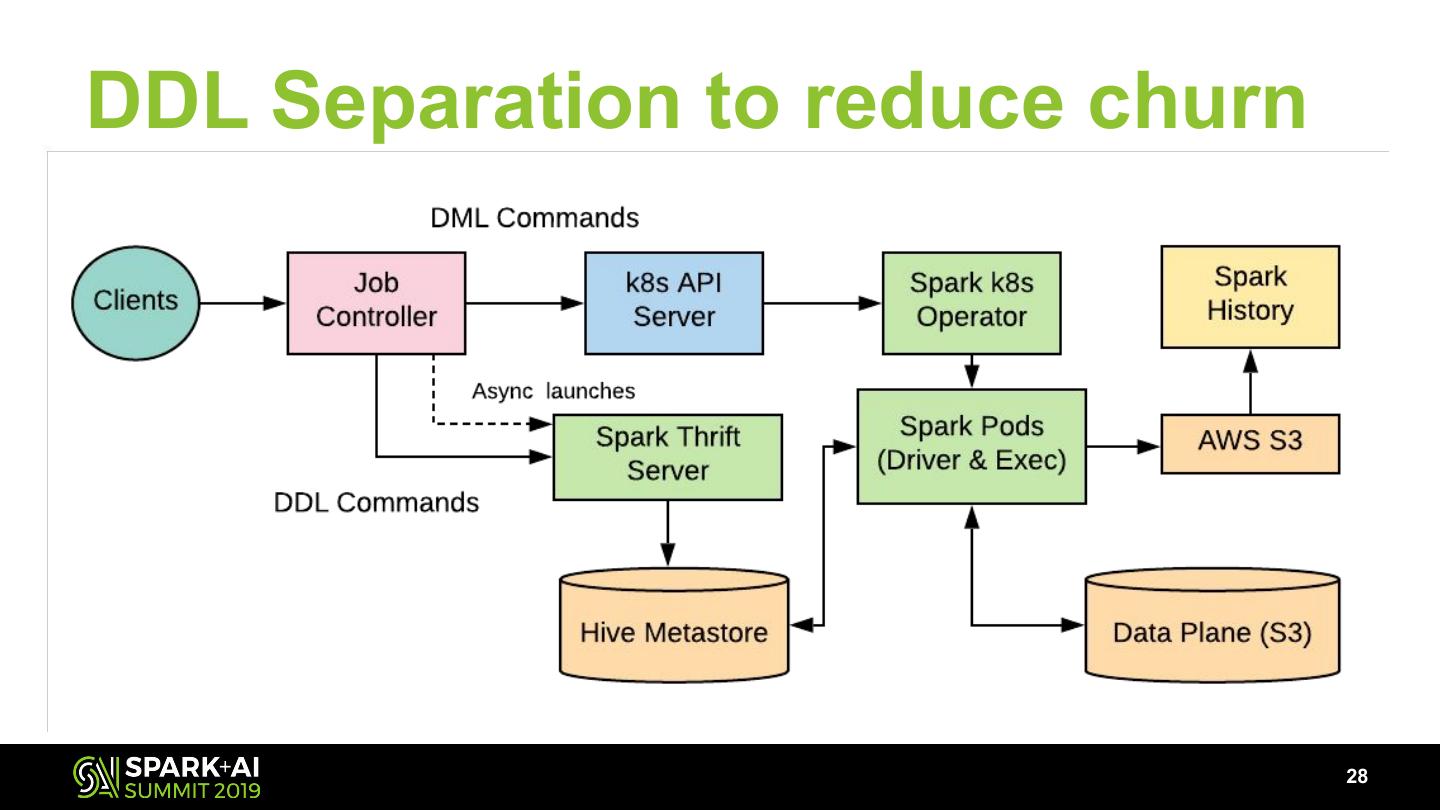
27 .Separate DML from DDL
27
�
28 .DDL Separation to reduce churn
28
�
29 . Pod Priority and Preemption (WIP)
Before
New Pod Req
● Priority base
D1 D2 E1 E2 E3 E4
preemption
● Driver pod has higher E5
priority than executor K8s Scheduler
pod
● Experimental
D1 D2 E5 E2 E3 E4 E1
https://github.com/kubernetes/kubernetes/issues/71486
After Evicted
https://github.com/kubernetes/enhancements/issues/564
29
�