展开查看详情
1 .Scaling Apache Spark at
Facebook
Sameer Agarwal & Ankit Agarwal
Spark Summit | San Francisco | 24 th April 2019
�
2 .About Us
Sameer Agarwal
- Software Engineer at Facebook (Data Warehouse Team)
- Apache Spark Committer (Spark Core/SQL)
- Previously at Databricks and UC Berkeley
Ankit Agarwal
- Production Engineering Manager at Facebook (Data Warehouse Team)
- Data Infrastructure Team at Facebook since 2012
- Previously worked on the search team at Yahoo!
�
3 .Agenda
1. Spark at Facebook
2. Hardware Trends: A tale of two bottlenecks
3. Evolving the Core Engine
- History Based Tuning
- Join Optimizations
4. Our Users and their Use-cases
5. The Road Ahead
�
4 .Agenda
1. Spark at Facebook
2. Hardware Trends: A tale of two bottlenecks
3. Evolving the Core Engine
- History Based Tuning
- Join Optimizations
4. Our Users and their Use-cases
5. The Road Ahead
�
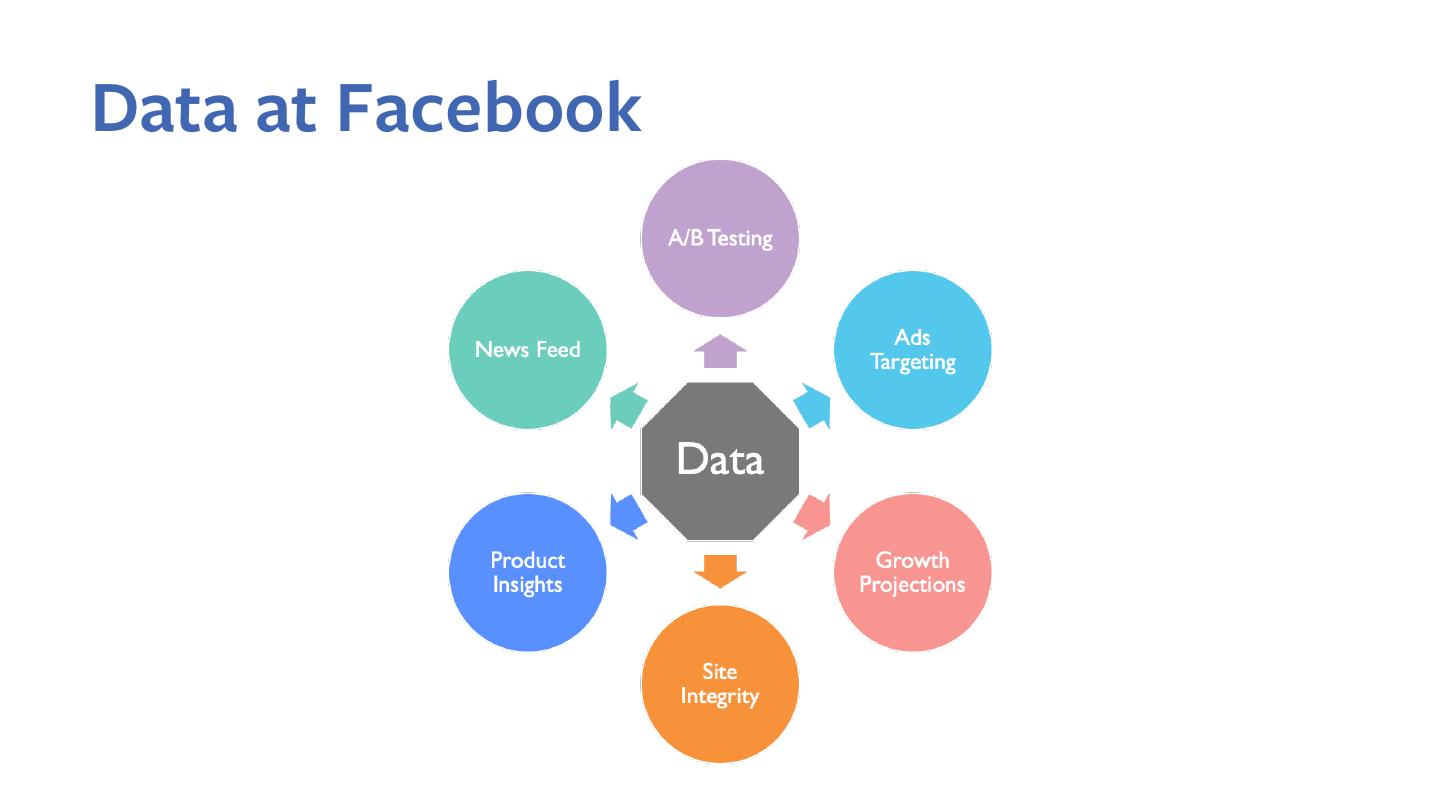
6 .2.7 Billion MAU
2 Billion DAU
Source: Facebook Q4 2018 earnings call transcript
�
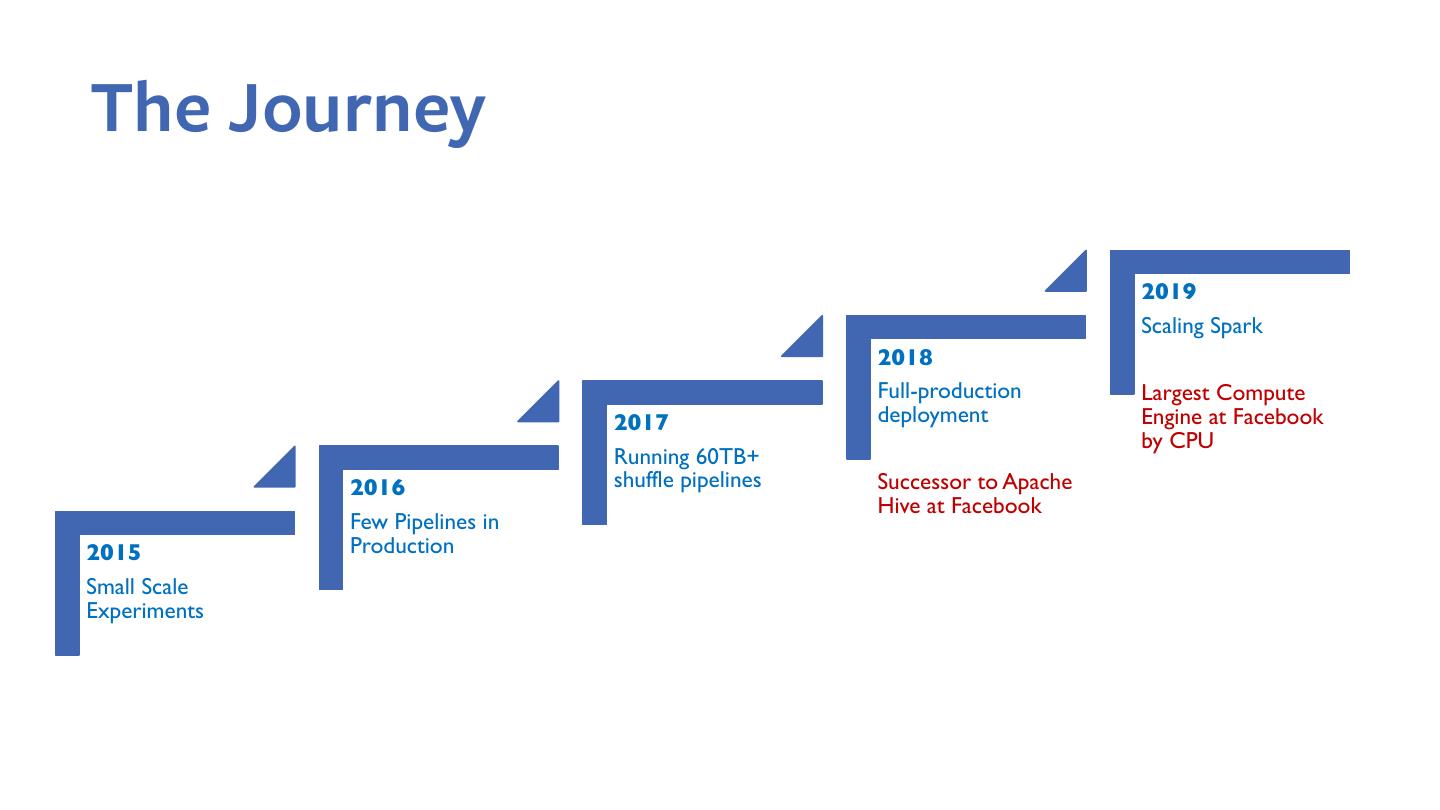
7 .The Journey
2019
Scaling Spark
2018
Full-production Largest Compute
2017 deployment Engine at Facebook
by CPU
Running 60TB+
2016 shuffle pipelines Successor to Apache
Hive at Facebook
Few Pipelines in
2015 Production
Small Scale
Experiments
�
8 .Agenda
1. Spark at Facebook
2. Hardware Trends: A tale of two bottlenecks
3. Evolving the Core Engine
- History Based Tuning
- Join Optimizations
4. Our Users and their Use-cases
5. The Road Ahead
�
9 .Hardware Trends
CPU, DRAM, and Disk
�
10 .Hardware Trends
CPU, DRAM, and Disk
1. The industry is optimizing for
throughput by adding more cores
2. To optimize performance/watt,
next generation processors will have
more cores that run at lower
frequency
�
11 .Hardware Trends
CPU, DRAM, and Disk
1. The price of DRAM continued to rise
throughout 2016-2018 and has
started fluctuating this year
2. Need to reduce our over-
dependence on DRAM
�
12 .Hardware Trends
CPU, DRAM, and Disk
1. Disk sizes continue to increase
but the number of random
accesses per second aren’t
increasing
2. IOPS becomes a bottleneck
�
13 .What does this mean for Spark?
1. Optimize Spark for increasing core-memory ratio
2. Run Spark on disaggregated compute/storage clusters
- Use server types optimized for compute and storage
- Scale/upgrade clusters independently over time depending
on whether CPU or IOPS was a bottleneck
3. Scale extremely diverse workloads (SQL, ML etc.) on Spark
over clusters of tens of thousands of heterogenous
machines
�
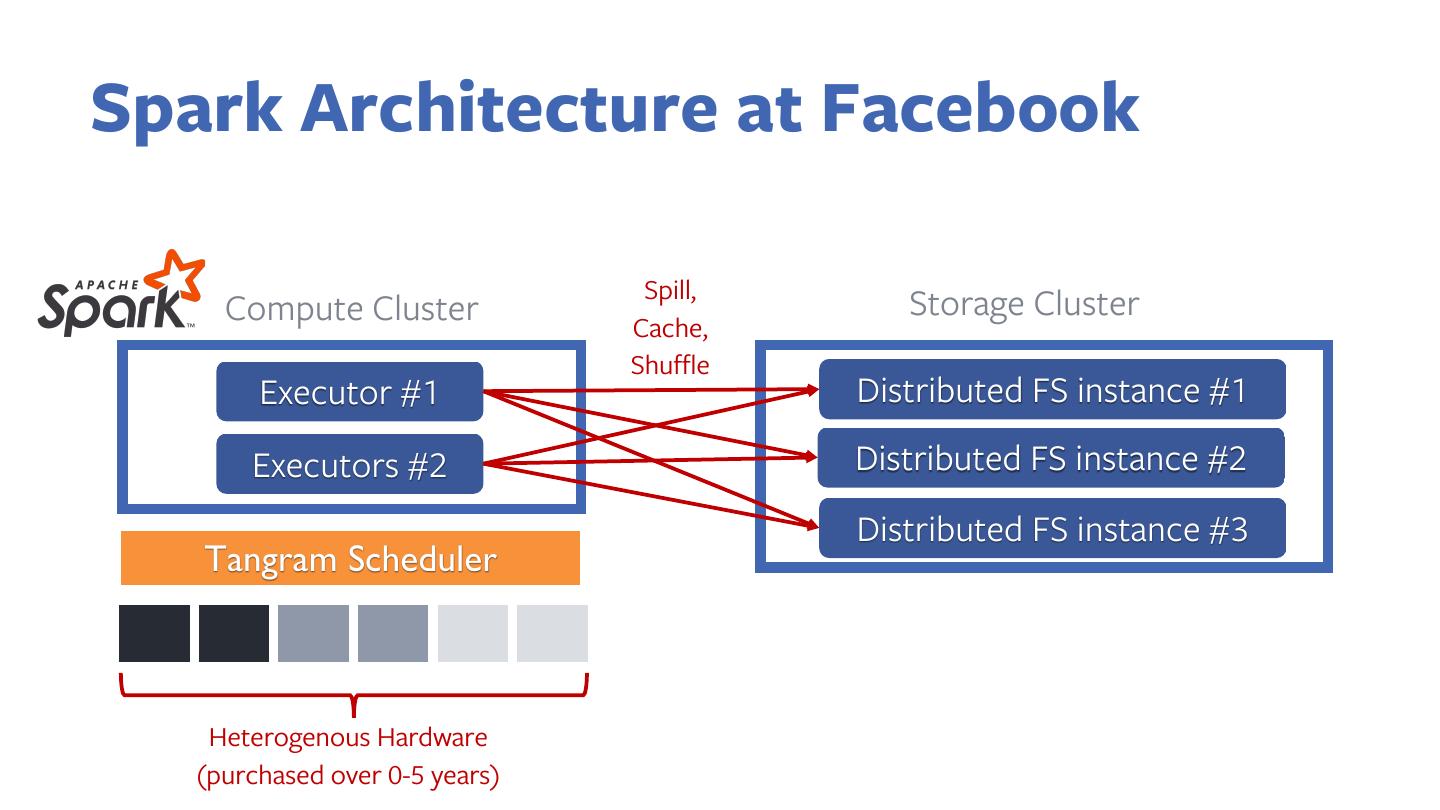
14 .Spark Architecture at Facebook
Compute Cluster Storage Cluster
Executor #1 Distributed FS instance #1
Executors #2 Distributed FS instance #2
Distributed FS instance #3
�
15 .Spark Architecture at Facebook
Spill,
Compute Cluster Storage Cluster
Cache,
Shuffle
Executor #1 Distributed FS instance #1
Executors #2 Distributed FS instance #2
Distributed FS instance #3
�
16 .Spark Architecture at Facebook
Spill,
Compute Cluster Storage Cluster
Cache,
Shuffle
Executor #1 Distributed FS instance #1
Executors #2 Distributed FS instance #2
Distributed FS instance #3
Tangram Scheduler
Heterogenous Hardware
(purchased over 0-5 years)
�
17 .Spark Architecture at Facebook
Spill,
Compute
Brian Cho andCluster
Dmitry Borovsky, Cosco: An Efficient Storage Cluster Shuffle Service
Facebook-Scale
Cache,
Shuffle Today at 4:30PM (Developer Track)
Executor #1 Distributed FS instance #1
Executors #2 Distributed FS instance #2
Rui Jian and Hao Lin, Tangram: Distributed Scheduling for Spark at Facebook
Distributed FS instance #3
Tangram Scheduler Tomorrow at 11:50AM (Developer Track)
Heterogenous Hardware
(purchased over 0-5 years)
�
18 .Agenda
1. Spark at Facebook
2. Hardware Trends: A tale of two bottlenecks
3. Evolving the Core Engine
Contributed 100+
- History Based Tuning patches upstream
- Join Optimizations
4. Our Users and their Use-cases
5. The Road Ahead
�
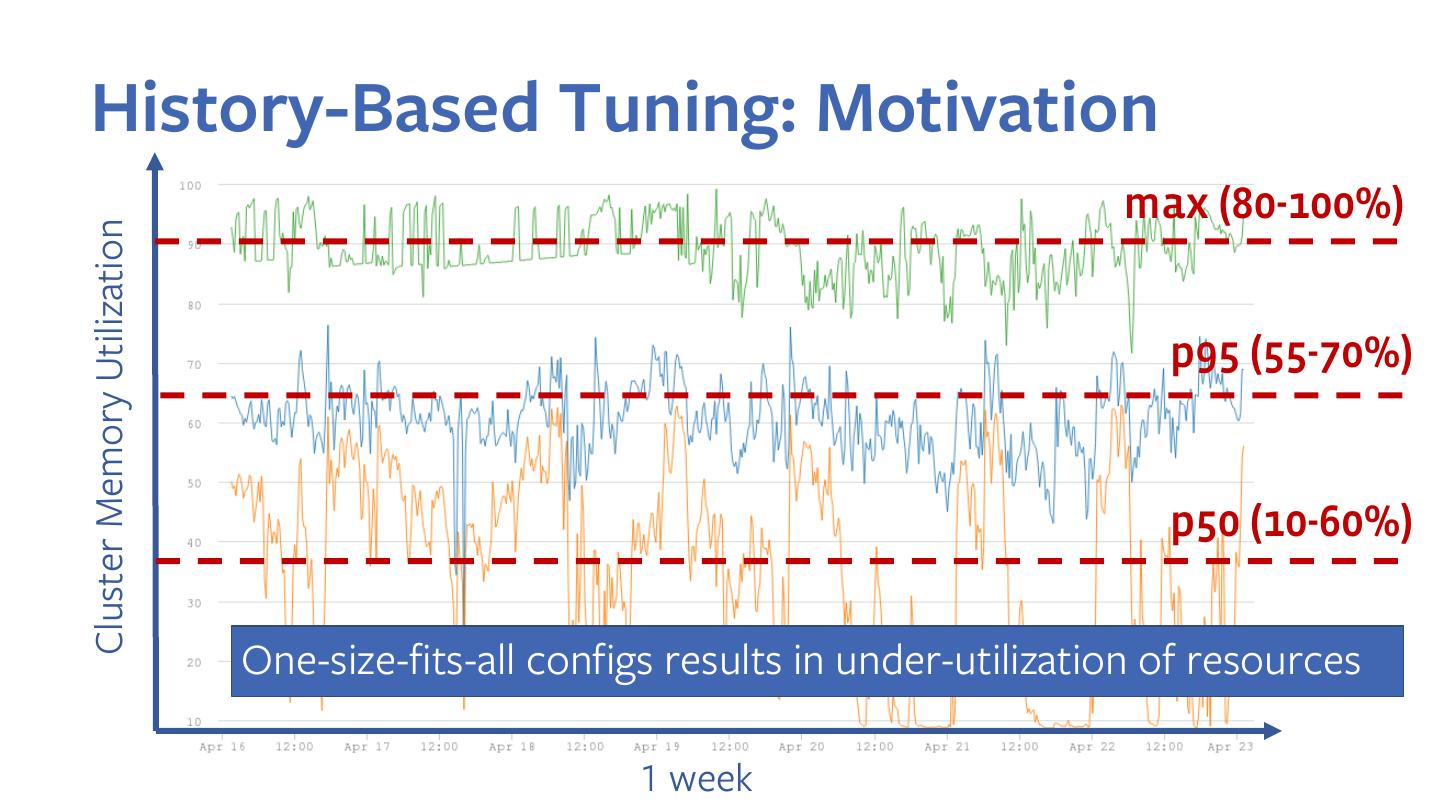
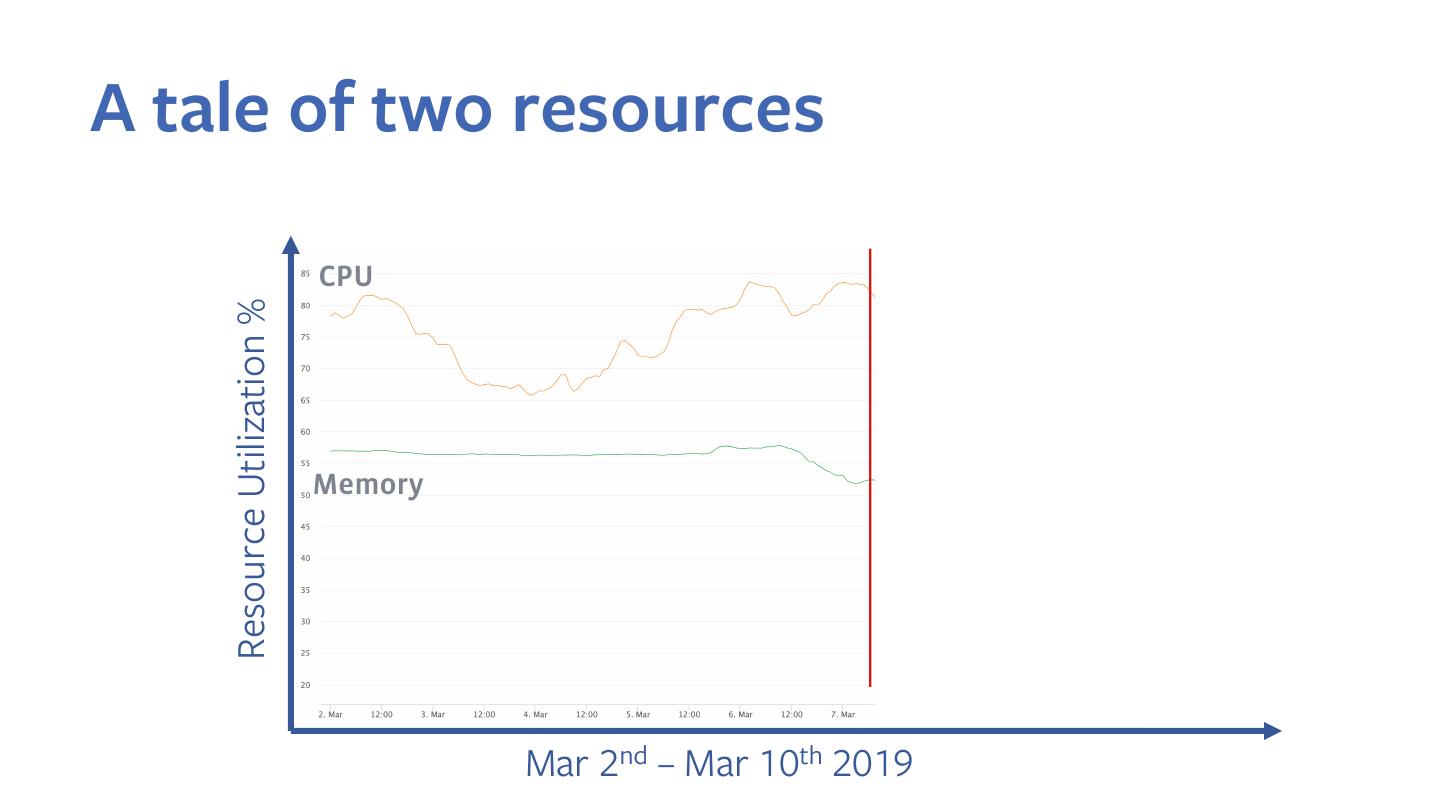
19 .History-Based Tuning: Motivation
max (80-100%)
Cluster Memory Utilization
p95 (55-70%)
p50 (10-60%)
1 week
�
20 .History-Based Tuning: Motivation
max (80-100%)
Cluster Memory Utilization
p95 (55-70%)
p50 (10-60%)
One-size-fits-all configs results in under-utilization of resources
1 week
�
21 .History-Based Tuning: Motivation
Percentage of Spark Tasks (CDF)
75% of Spark tasks use less than
600 MB of peak execution memory
Peak Execution Memory Bytes
�
22 .History-Based Tuning: Motivation
Percentage of Spark Tasks (CDF)
75% of Spark tasks use less than
600 MB of peak execution memory
Individual resource requirements for each Spark task has a huge variance
Peak Execution Memory Bytes
�
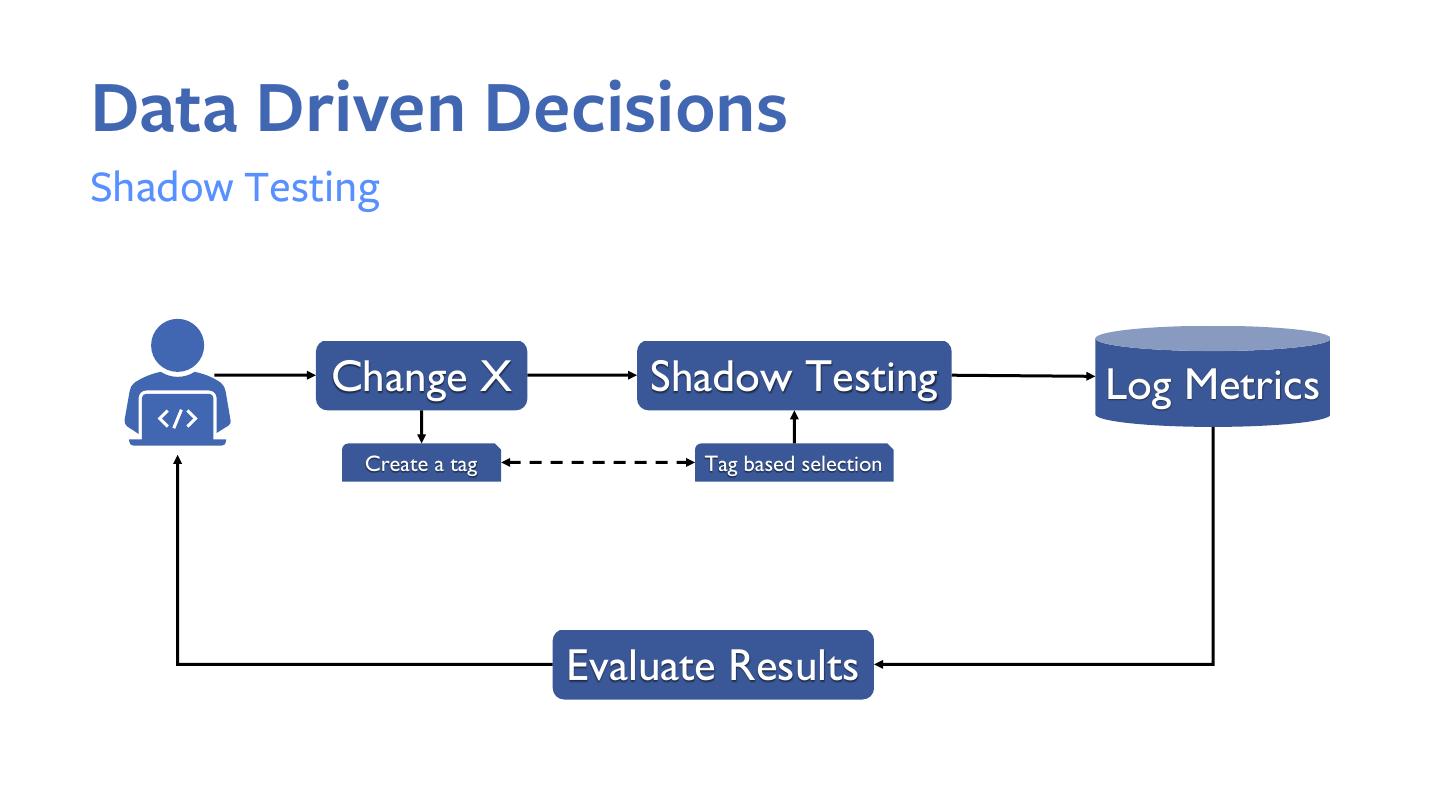
23 . History-Based Tuning
1. Need to tune Spark on a per-job or a per-stage basis
2. Leverage historical characteristics of the job to tune resources:
• Peak executor memory and spill sizes to tune executor off-heap
memory
• Shuffle size to optionally not insert partial aggregates in the query plan
• Predicting the number of shuffle partitions (job level and stage level)
�
24 .History-Based Tuning
InsertIntoHiveTable [partitions: ds,country]
+- *Project [cast(key as int) AS key, value]
Query Plan
+- *HiveTableScan (db.test) [col: key,value] [part: ds]
Template
New
Query
�
25 .History-Based Tuning
Query Plan Regressions/Failures
Template since past N days Apply
Conservative
Defaults
Apply
Config
New Historical No Regressions/Failures Overrides
Query Job Runs since past N days
Config
Override
Rules
�
26 .Joins in Spark
1. Broadcast Join: Broadcast small table to all nodes, stream
the larger table; skew resistant
2. Shuffle-Hash Join: Shuffle both tables, create a hashmap
with smaller table and stream the larger table
3. Sort-Merge Join: Shuffle and sort both tables, buffer one
side and stream the other side
�
27 .Sort-Merge-Bucket (SMB) Join
1. Bucketing is a way to shuffle (and optionally sort) output data
based on certain columns of table
2. Ideal for write-once, read-many datasets
3. Variant of Sort Merge Join in Spark; overrides
outputPartitioning and outputOrdering for
HiveTableScanExec and stitches partitioning/ ordering
metadata throughout the query plan
SPARK-19256
�
28 .Dynamic Join
A hybrid join algorithm where-in each task starts off by
executing a shuffle-hash join. In the process of execution,
should the hash table exceed a certain size (and OOM),
it automatically reconstructs/sorts the iterators and falls
back to a sort merge join
SPARK- 21505
�
29 .Skew Join
A hybrid join algorithm that processes skewed keys via a
broadcast join and non-skewed keys via a shuffle-hash
or sort-merge join
SELECT /*+ SKEWED_ON(a.userid='10001') */ a.userid
FROM table_A a INNER JOIN table_B b
ON a.userid = b.userid
�