展开查看详情
1 . Scaling Data Analytics
Workloads on Databricks
Spark + AI Summit, Amsterdam
Chris Stevens and Bogdan Ghit
October 17, 2019
1
�
2 .Chris Stevens Bogdan Ghit
• Software Engineer @ Databricks - Serverless Team • Software Engineer @ Databricks - BI Team
• Spent ~10 years doing kernel development • PhD in datacenter scheduling @ TU Delft
2
�
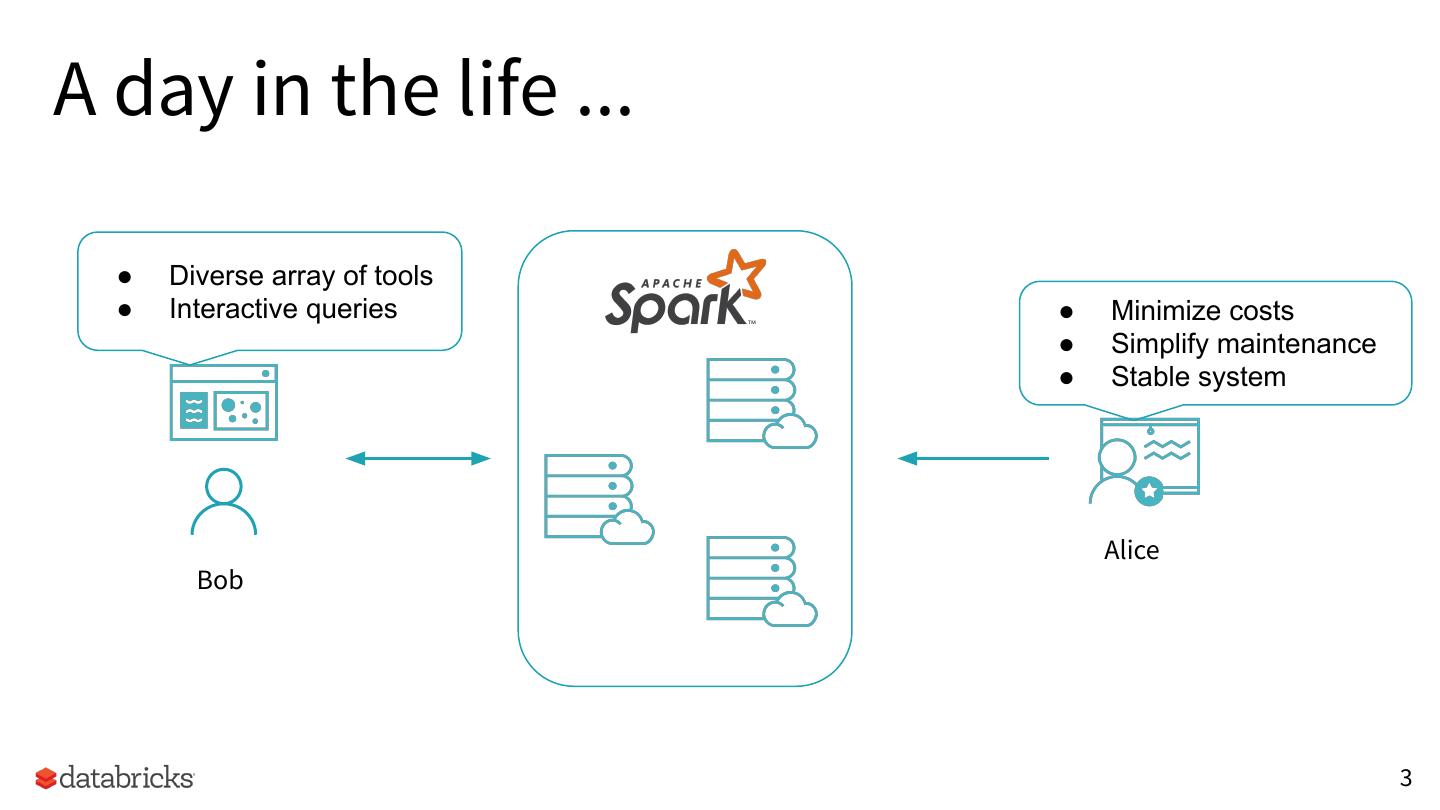
3 .A day in the life ...
● Diverse array of tools
● Interactive queries ● Minimize costs
● Simplify maintenance
● Stable system
Alice
Alice
Bob
Bob
3
�
4 .Reality ...
Alice
Alice
Bob
4
�
5 .This Talk
Control Plane
Resource management
Connectors
Provisioning 5
�
6 .BI Connectors
Control Plane
6
�
7 .Tableau on Databricks
Client machine Shard Databricks Runtime
Webapp Thrift
Proxy layer
BI tools ODBC/JDBC to/from Spark ODBC/JDBC Spark
driver clusters server
7
�
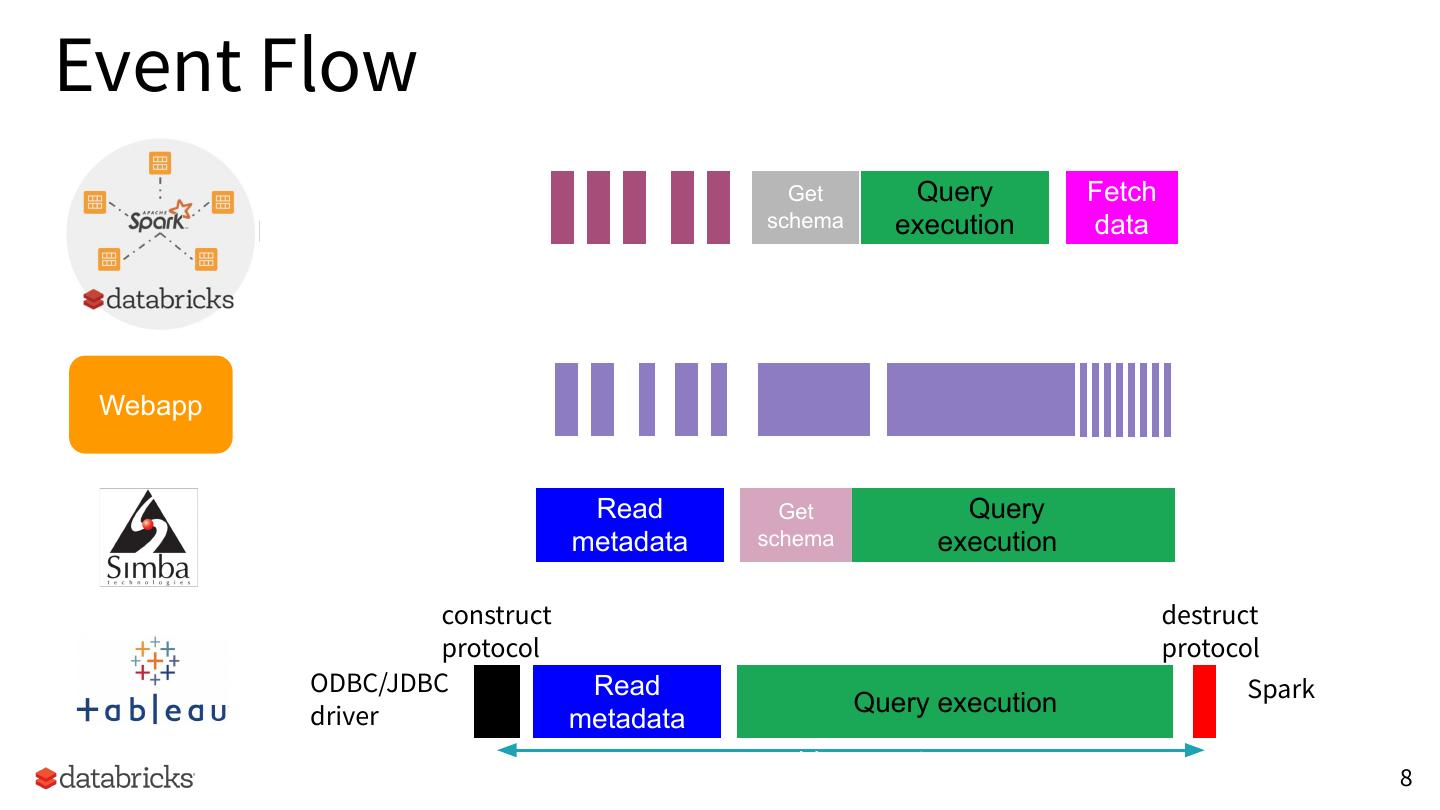
8 .Event Flow
Get Query Fetch
schema execution data
Webapp
Read Get Query
metadata schema execution
construct destruct
protocol protocol
BI tools ODBC/JDBC Read ODBC/JDBC Spark
driver Query execution
server
metadata
Tableau session
8
�
9 .Behind the Scenes
Login to Tableau
First cold run of Multiple warm runs of
a TPC-DS query a TPC-DS query
9
�
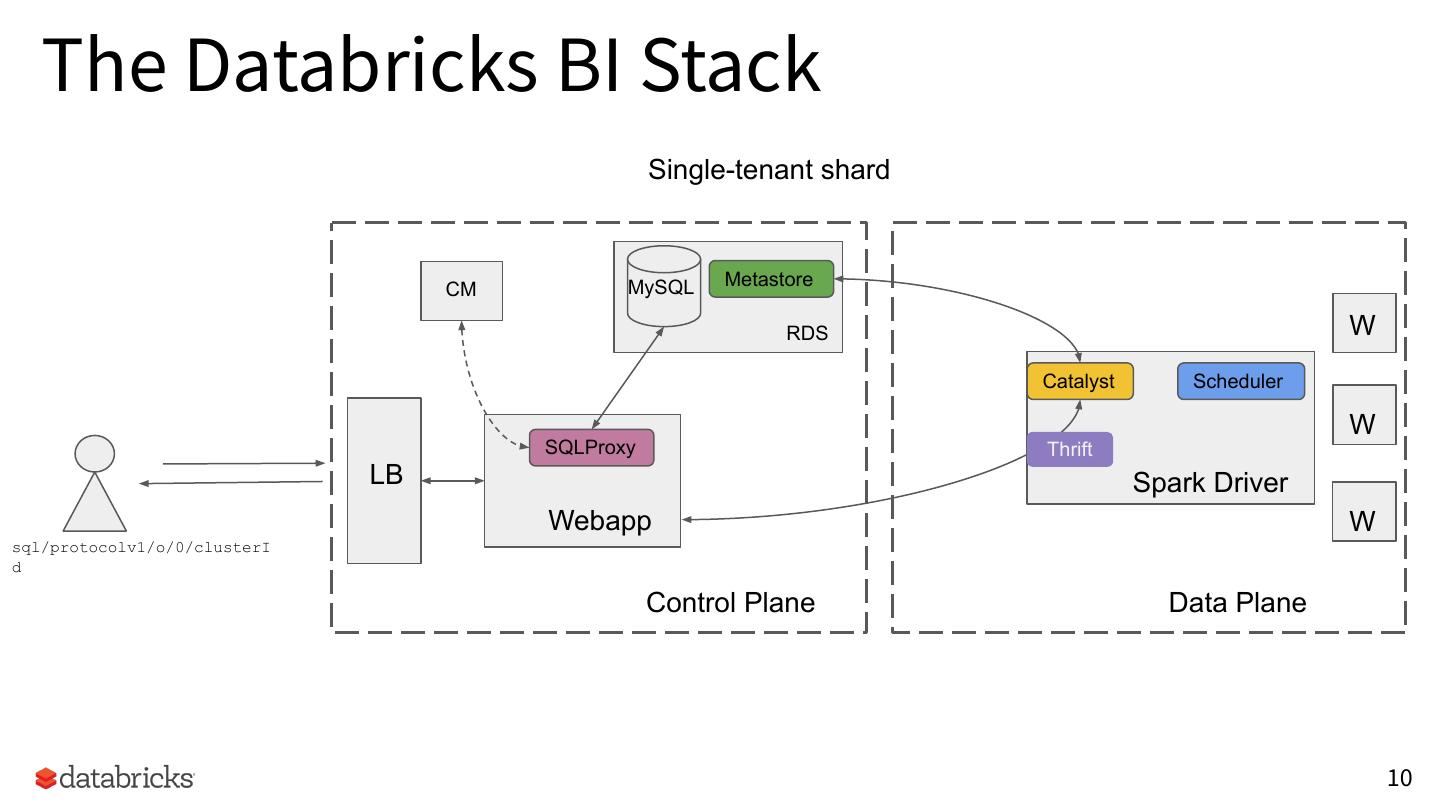
10 . The Databricks BI Stack
Single-tenant shard
MySQL Metastore
CM
RDS W
Catalyst Scheduler
W
SQLProxy Thrift
LB Spark Driver
Webapp W
sql/protocolv1/o/0/clusterI
d
Control Plane Data Plane
10
�
11 .Tableau Connector SDK
Plugin Connector connectionBuilder SQL Dialect
Custom Dialog File
Manifest File
connectionProperties
connectionMatcher
connectionRequired
Connection Resolver Connection String
11
�
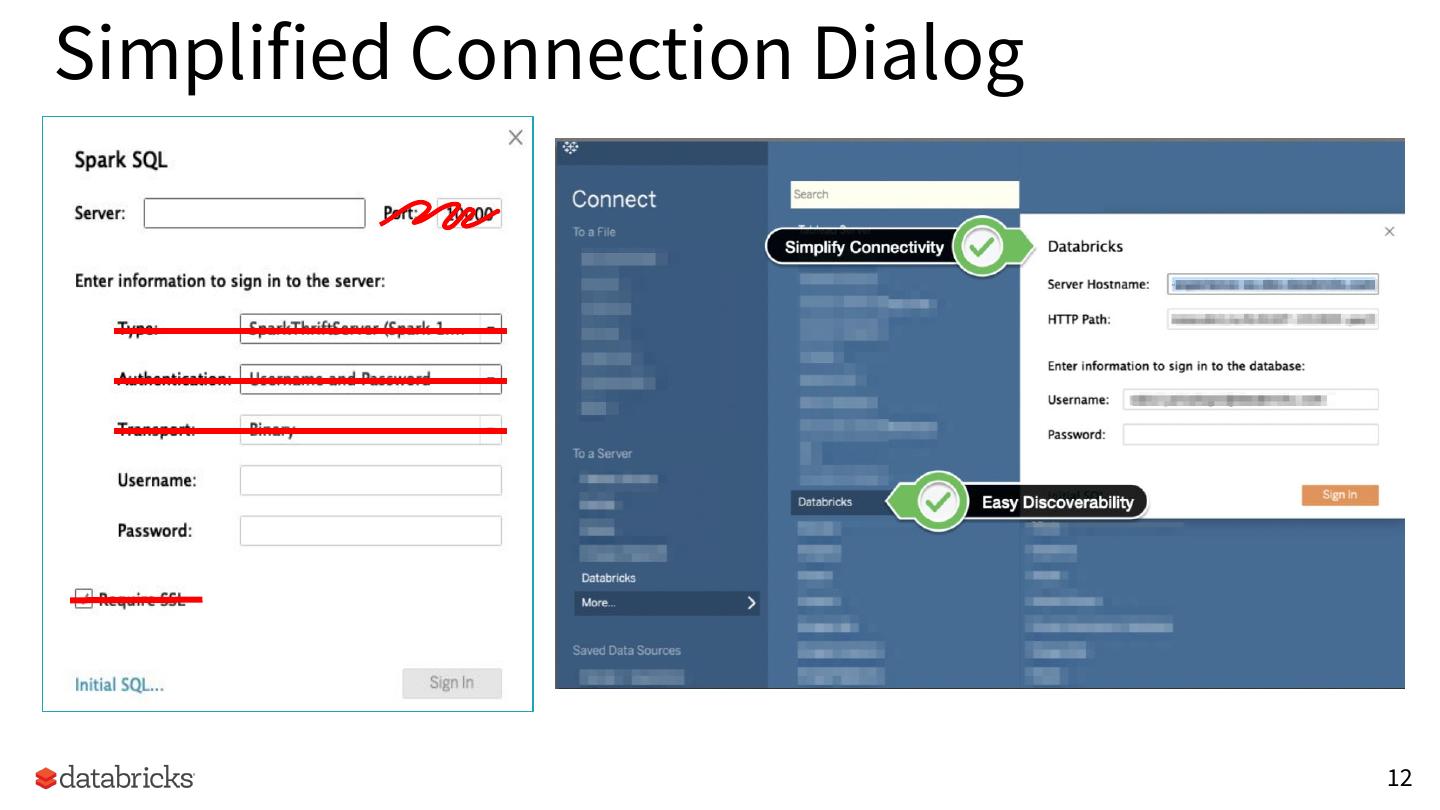
12 .Simplified Connection Dialog
12
�
13 .Controlling the Dialect
<function group='string' name='SPLIT' return-type='str'>
<formula> CASE
WHEN (%1 IS NULL) THEN
CAST(NULL AS STRING) Missing operators: IN_SET, ATAN, CHAR, RSPLIT
WHEN NOT (%3 IS NULL) THEN
COALESCE( Hive dialect wraps DATENAME in COALESCE operators
(CASE WHEN %3 > 0 THEN SPLIT(%1, '%2')[%3-1]
ELSE SPLIT(
REVERSE(%1),
Strategy to determine if two values are distinct
REVERSE('%2'))[ABS(%3)-1] END), '')
ELSE NULL END
The datasource supports booleans natively
</formula>
<argument type='str' />
<argument type='localstr' /> CASE-WHEN statements should be of boolean type
<argument type='localint' />
</function>
Achieved 100% compliance with TDVT standard testing
13
�
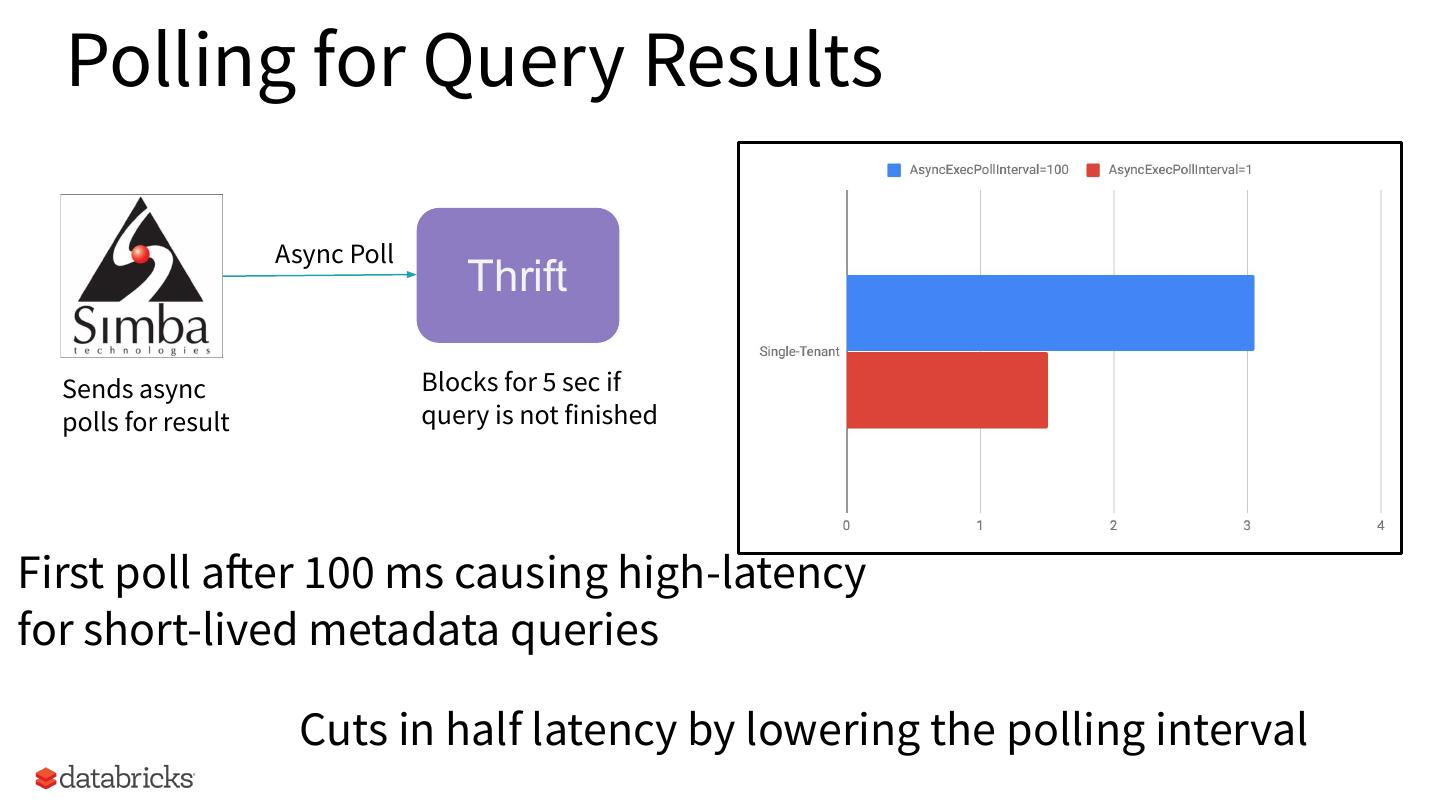
14 . Polling for Query Results
Async Poll
Thrift
Sends async Blocks for 5 sec if
polls for result query is not finished
First poll after 100 ms causing high-latency
for short-lived metadata queries
Cuts in half latency by lowering the polling interval
�
15 .Metadata Queries are Expensive
SHOW SCHEMAS
SHOW TABLES
DESC table
DESC table
Thrift
Each query triggers 6 round-trips from Tableau to Thrift
We optimize the sequence of metadata queries by retrieving
all needed metadata in one go
�
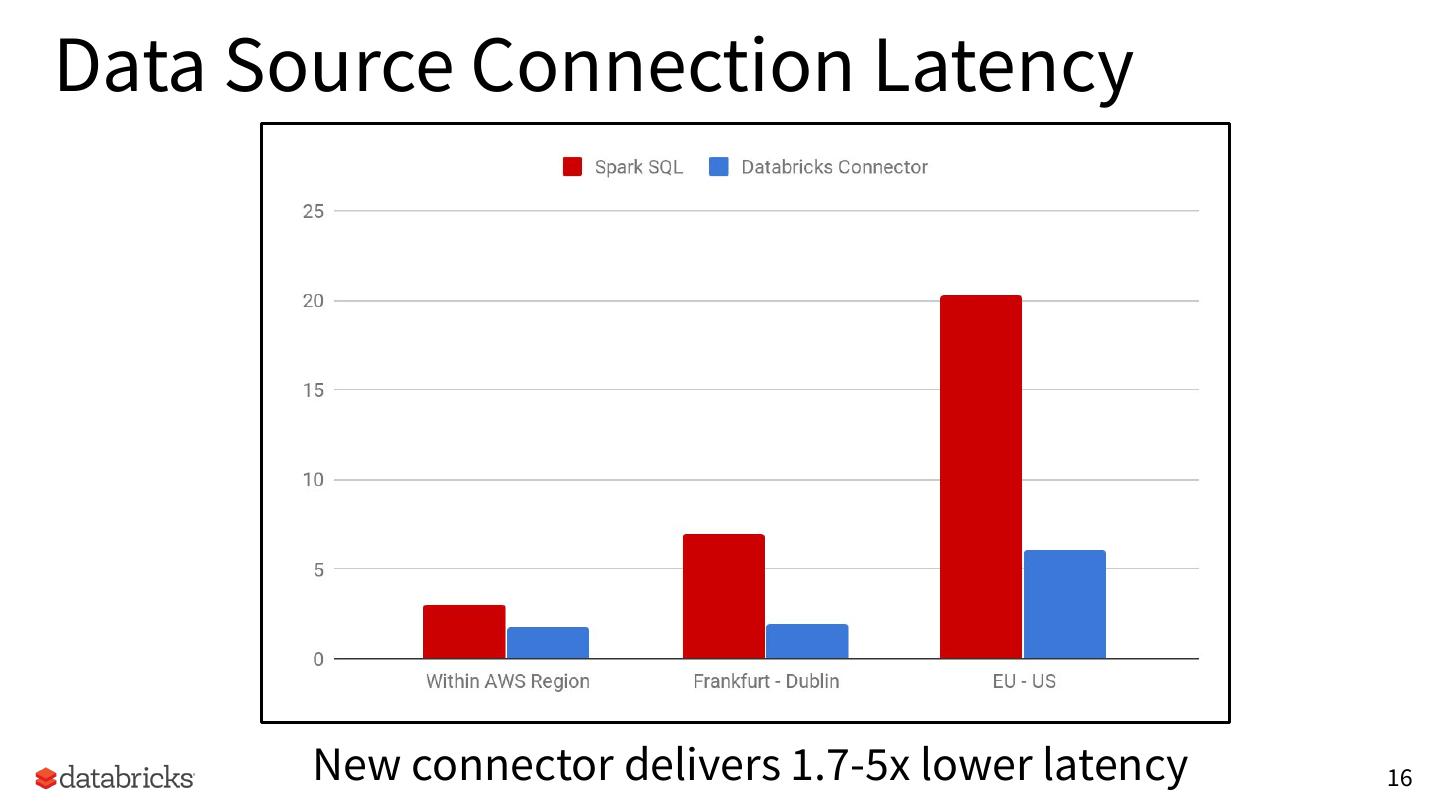
16 .Data Source Connection Latency
New connector delivers 1.7-5x lower latency 16
�
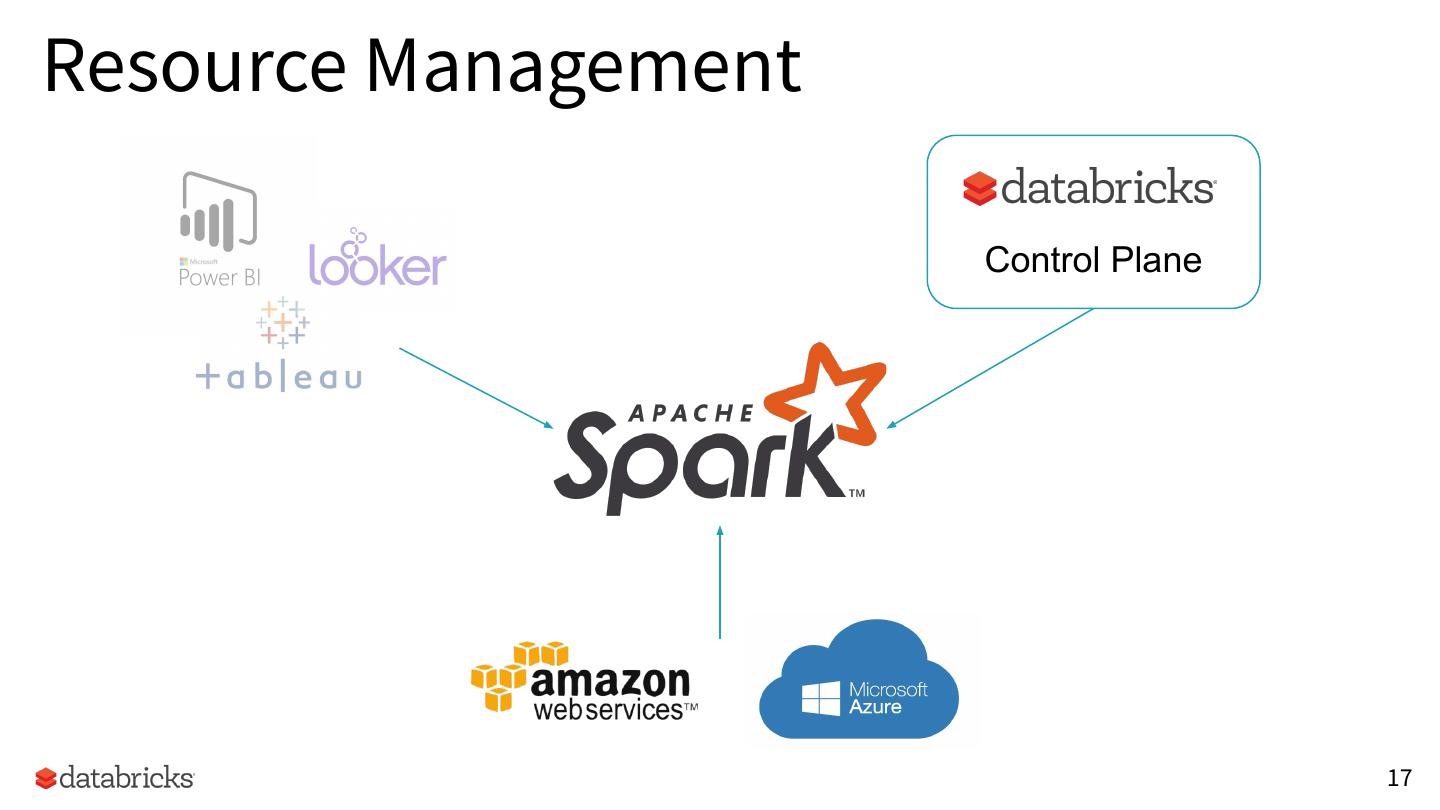
17 .Resource Management
Control Plane
17
�
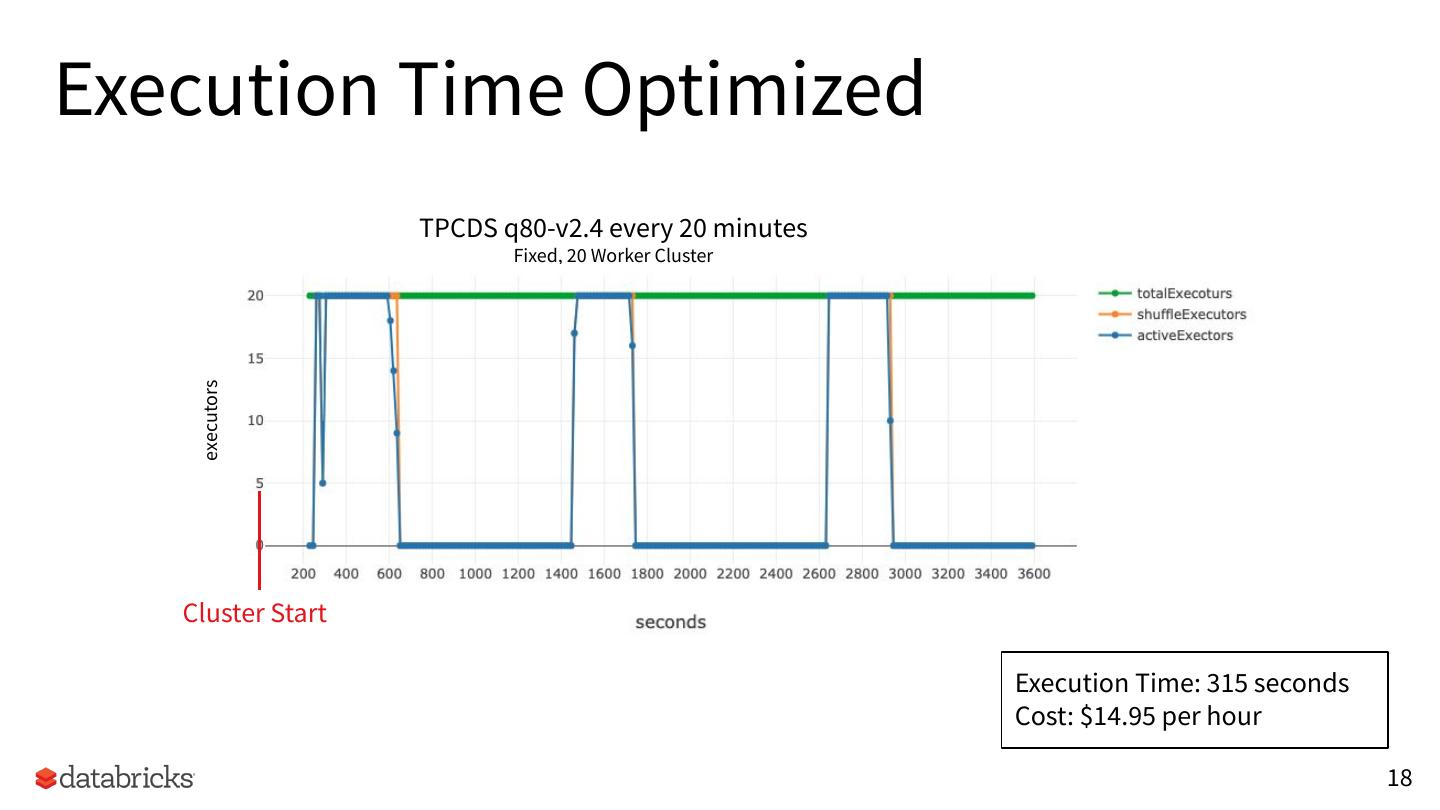
18 .Execution Time Optimized
TPCDS q80-v2.4 every 20 minutes
Fixed, 20 Worker Cluster
executors
Cluster Start
Execution Time: 315 seconds
Cost: $14.95 per hour
18
�
19 .Cost Optimized
TPCDS q80-v2.4 every 20 minutes
Auto-terminating, 20 Worker Cluster
executors
Cluster Starts
Execution Time: 613 seconds
Cost: $7.66 per hour
19
�
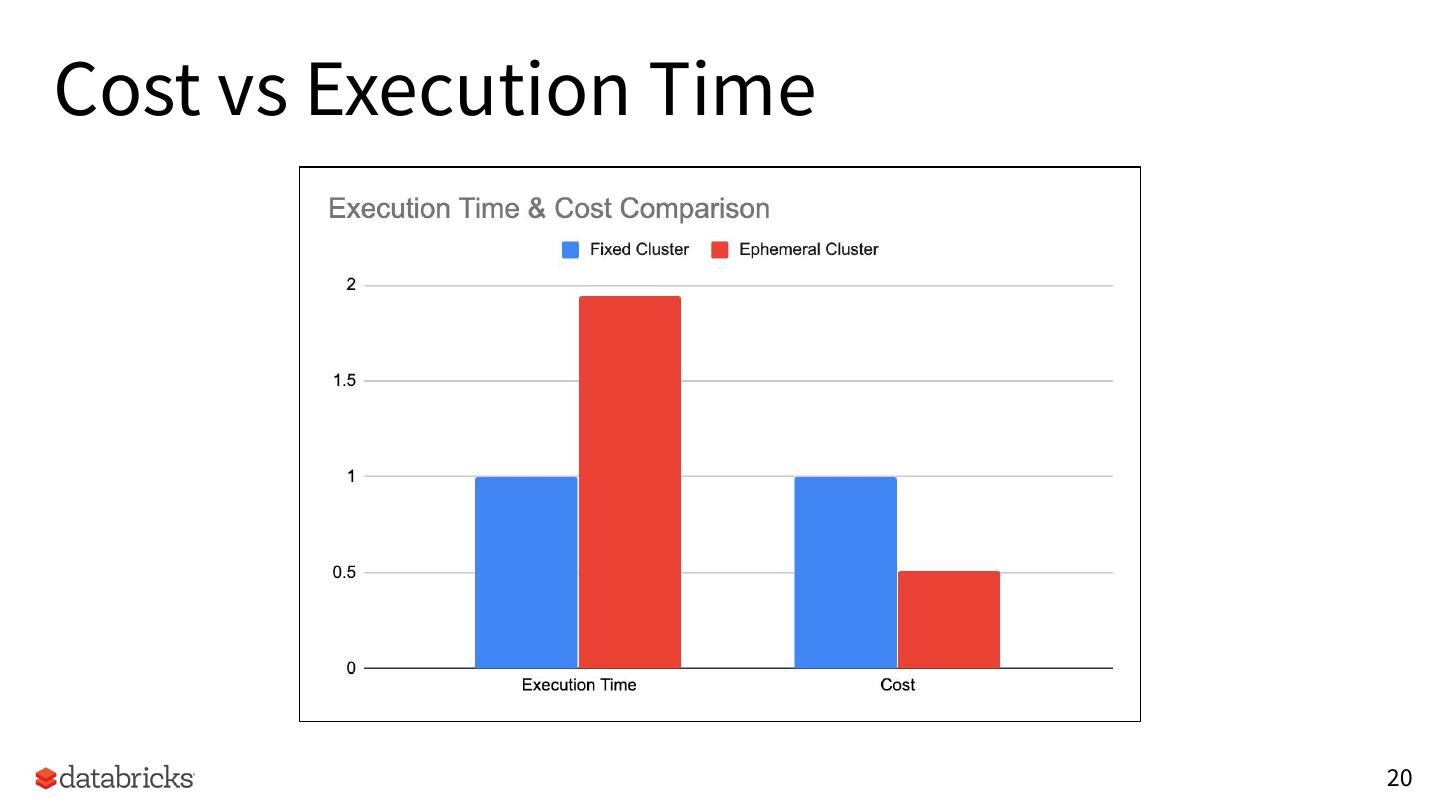
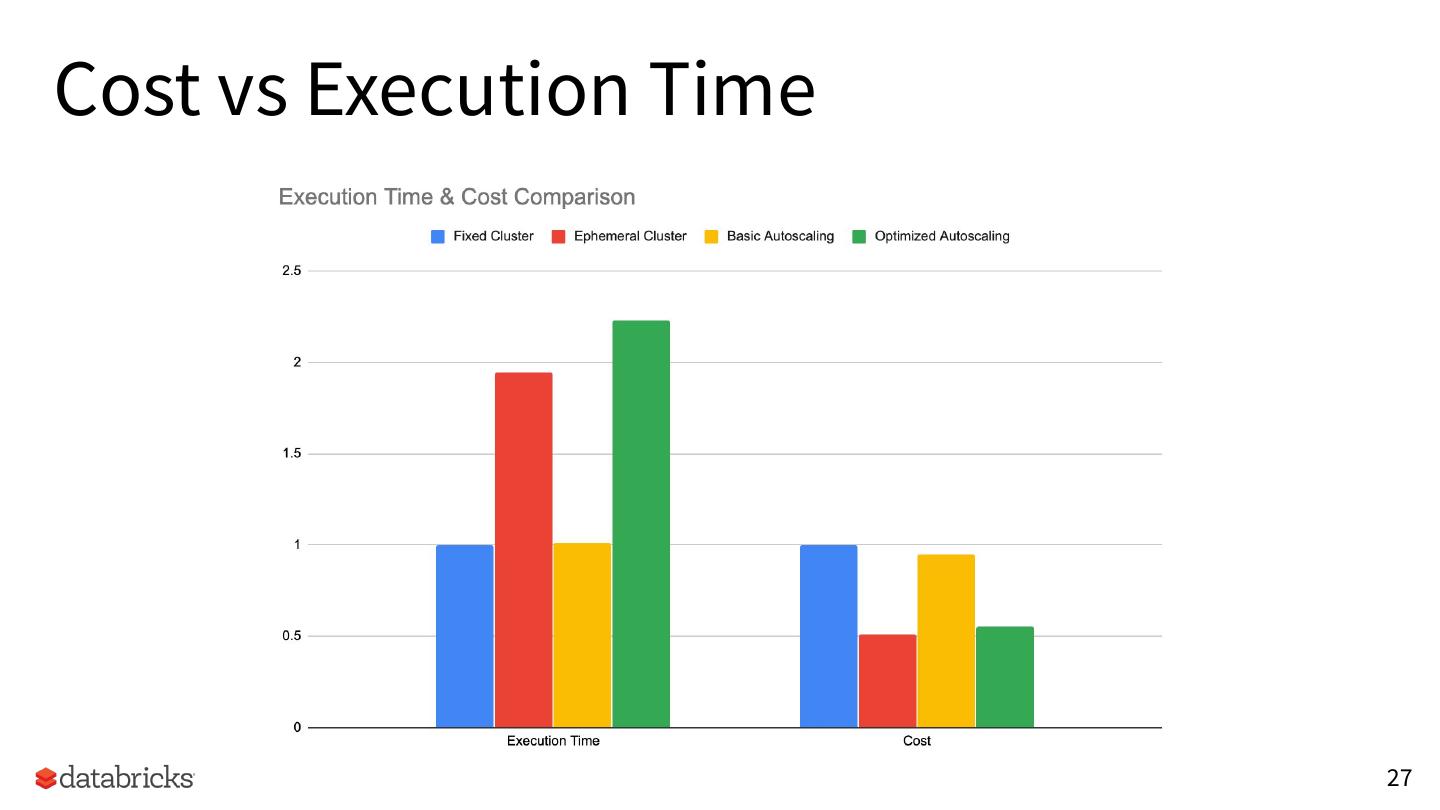
20 .Cost vs Execution Time
20
�
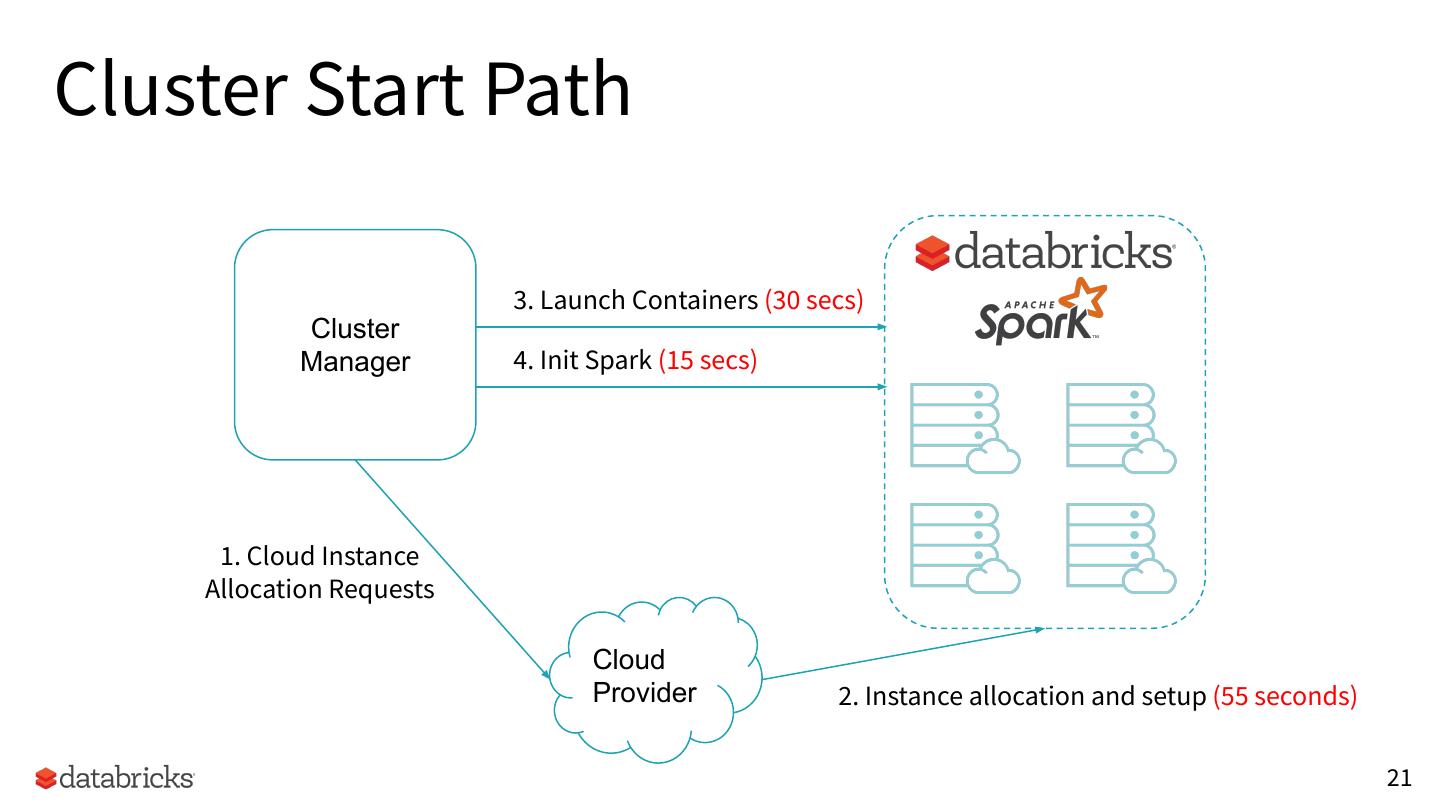
21 .Cluster Start Path
3. Launch Containers (30 secs)
Cluster
Manager 4. Init Spark (15 secs)
1. Cloud Instance
Allocation Requests
Cloud
Provider 2. Instance allocation and setup (55 seconds)
21
�
22 .Node Start Time
● Up to 55 seconds to acquire an
instance from the cloud provider and
initialize it.
● Up to 30 seconds to launch a
container (includes downloading
DBR)
● ~15 seconds to start master/worker
● Median for cluster starts is 2 mins
and 22 seconds.
22
�
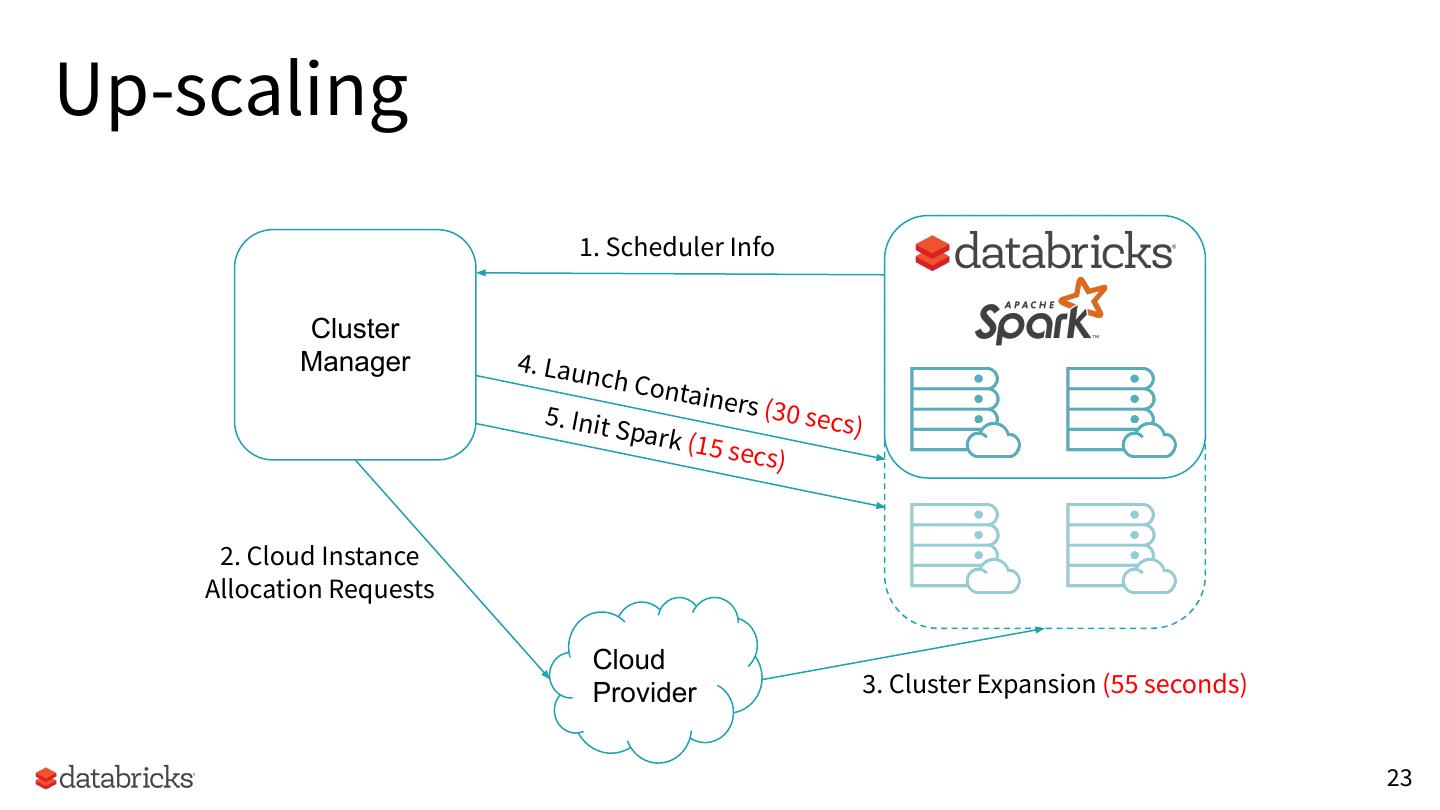
23 .Up-scaling
1. Scheduler Info
Cluster
Manager 4. Laun
ch Con
tainers
5. Init S (30 sec
park (1 s)
5 secs)
2. Cloud Instance
Allocation Requests
Cloud
Provider 3. Cluster Expansion (55 seconds)
23
�
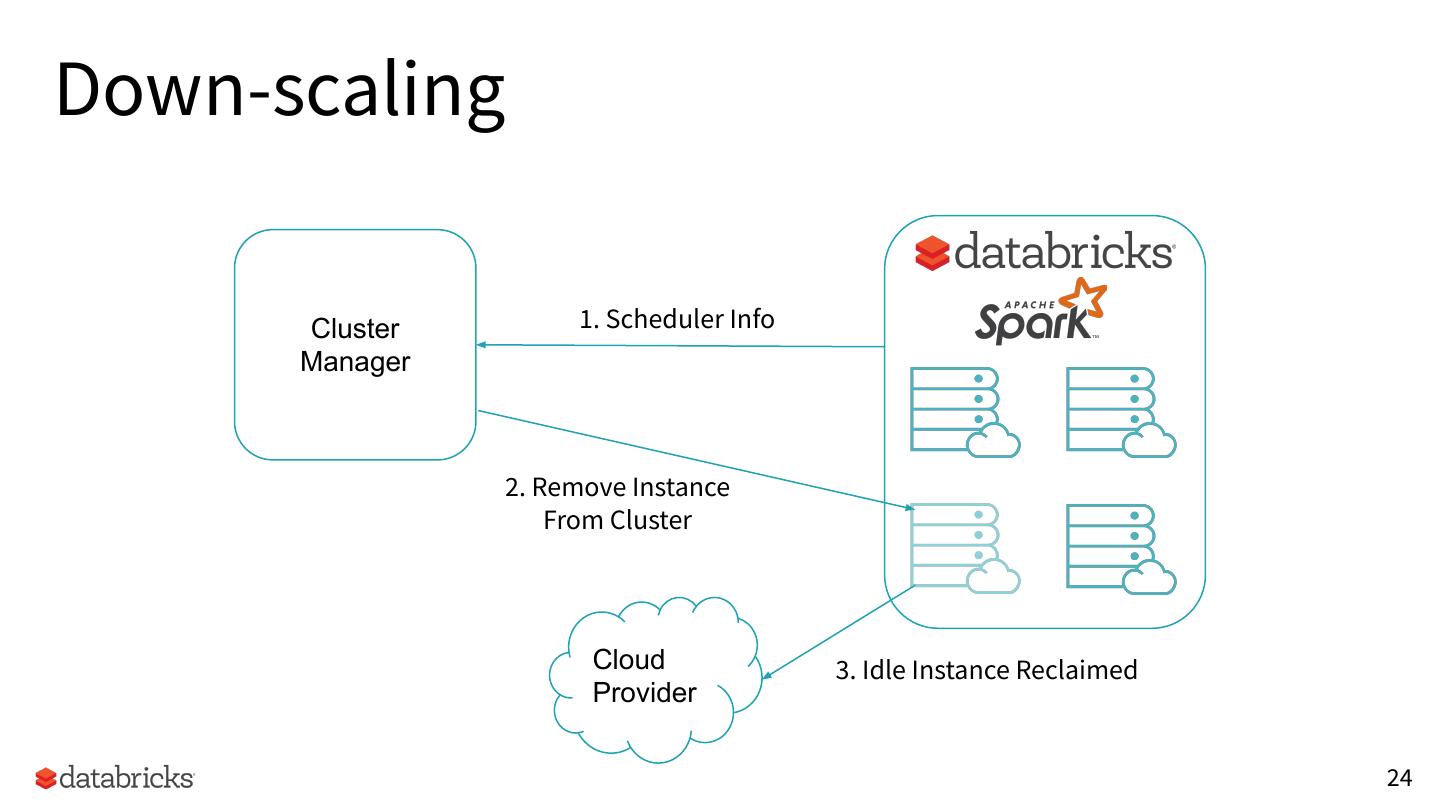
24 .Down-scaling
Cluster 1. Scheduler Info
Manager
2. Remove Instance
From Cluster
Cloud 3. Idle Instance Reclaimed
Provider
24
�
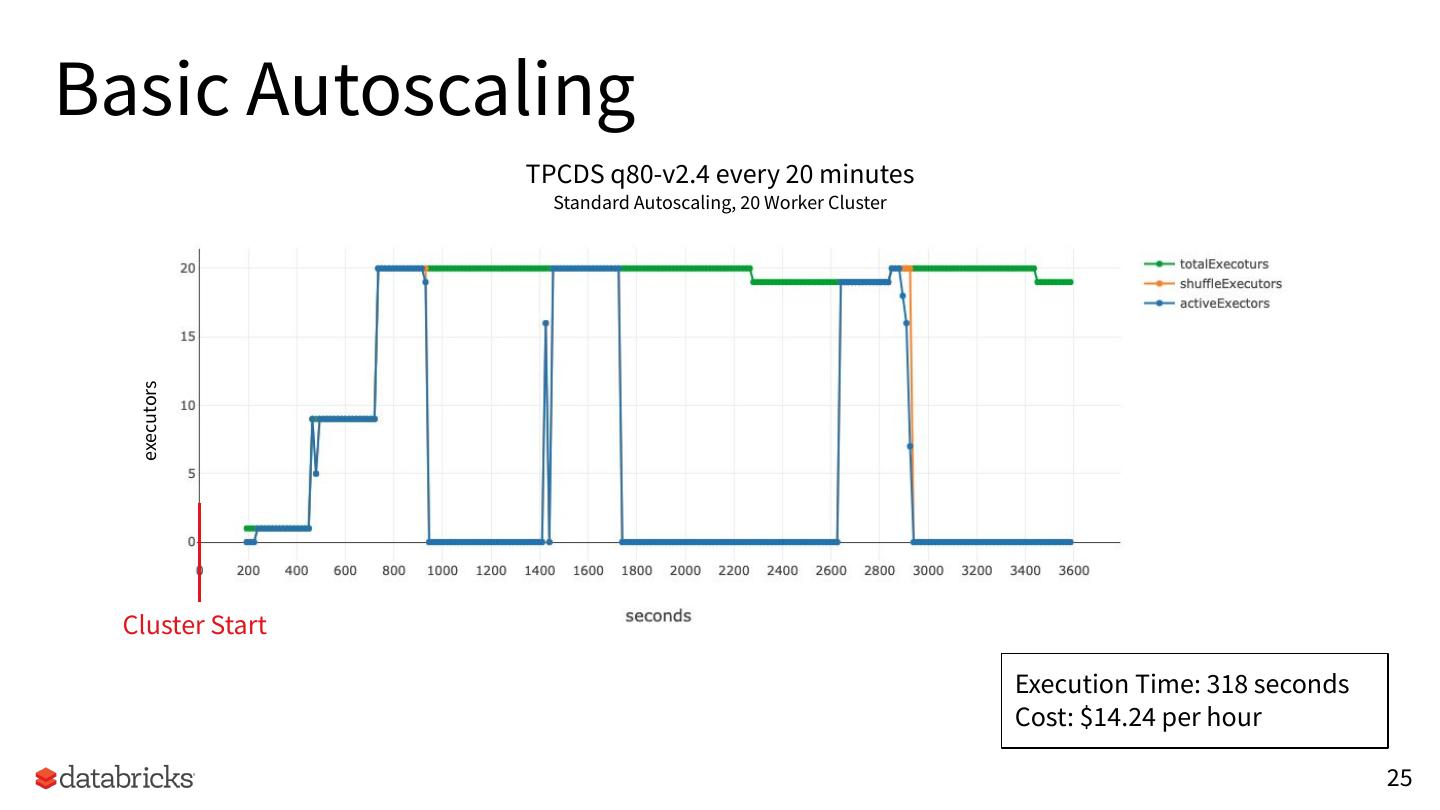
25 .Basic Autoscaling
TPCDS q80-v2.4 every 20 minutes
Standard Autoscaling, 20 Worker Cluster
executors
executors
Cluster Start
Execution Time: 318 seconds
Cost: $14.24 per hour
25
�
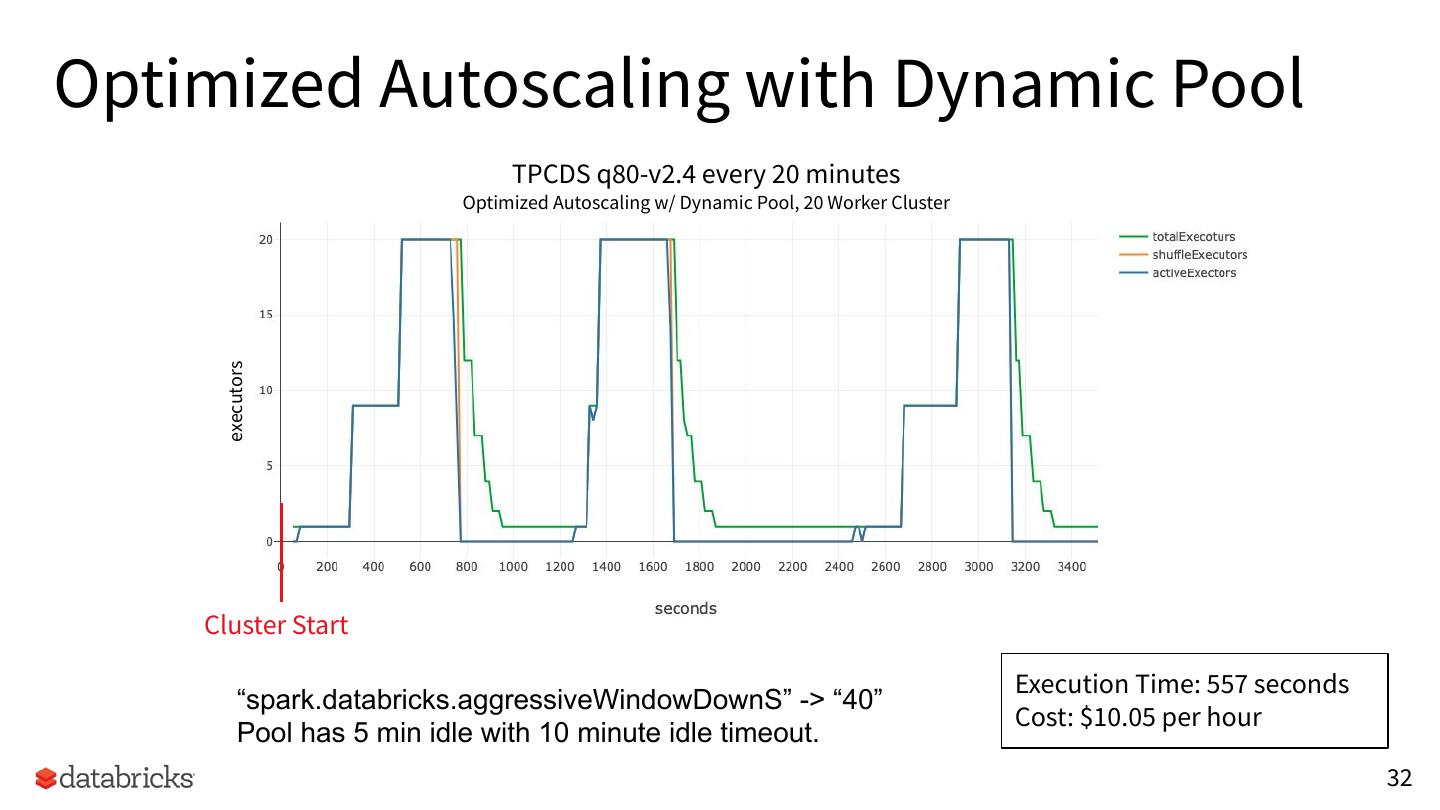
26 .Optimized Autoscaling
TPCDS q80-v2.4 every 20 minutes
executors Optimized Autoscaling, 20 Worker Cluster
Cluster Start
Execution Time: 703 seconds
“spark.databricks.aggressiveWindowDownS” -> “40”
Cost: $7.27 per hour
26
�
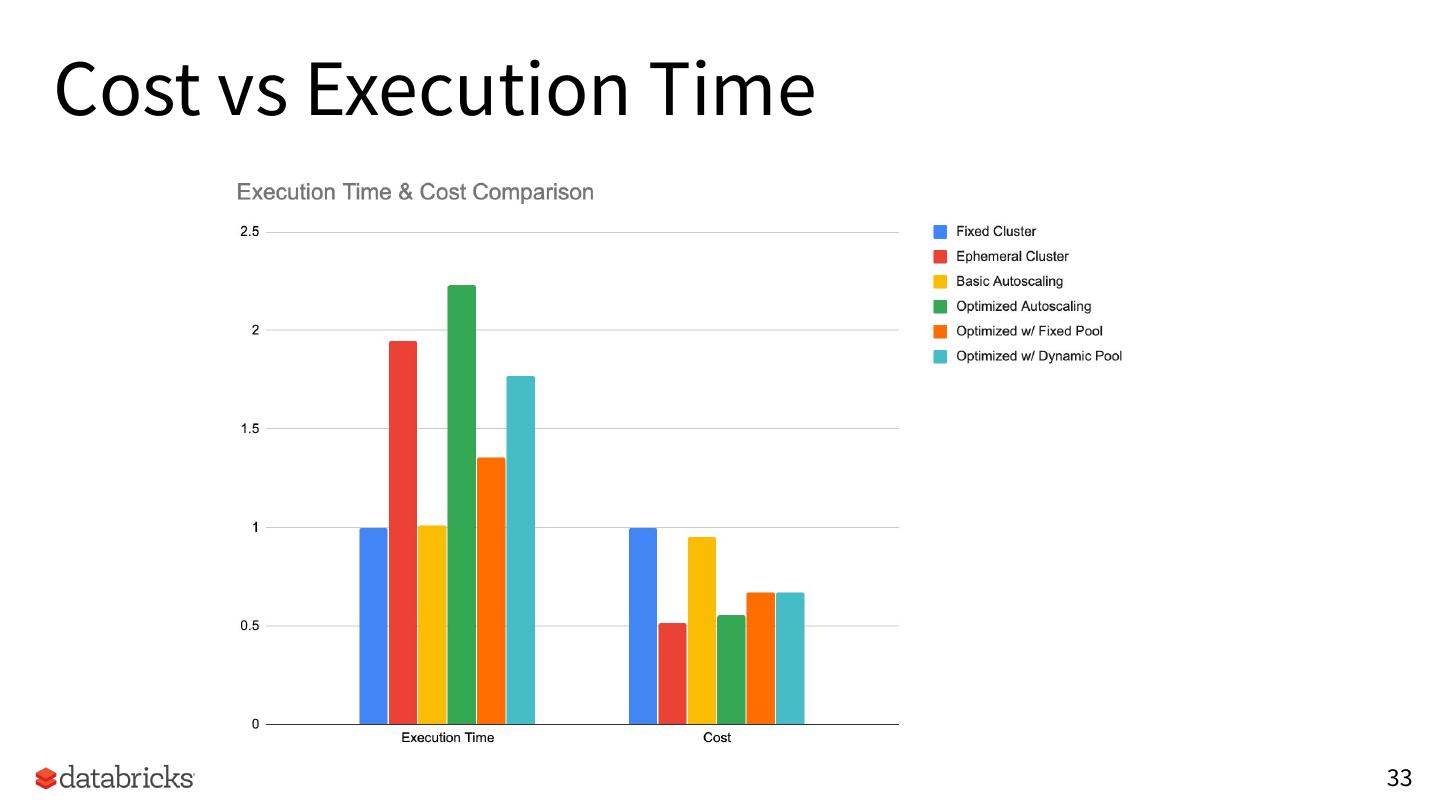
27 .Cost vs Execution Time
27
�
28 .Up-scaling with Instance Pools
Cluster 1. Scheduler Info
Manager
5. Launch Containers and
2. Pool Instance start Spark (25 secs)
Allocation Requests
4. Cluster Expansion (~7ms)
3. Pool Instance Allocation Idle Instances
Pool Manager
Cloud Instance Cloud
Allocation Requests Provider Pool Expansion (55 seconds)
(background) (background)
28
�
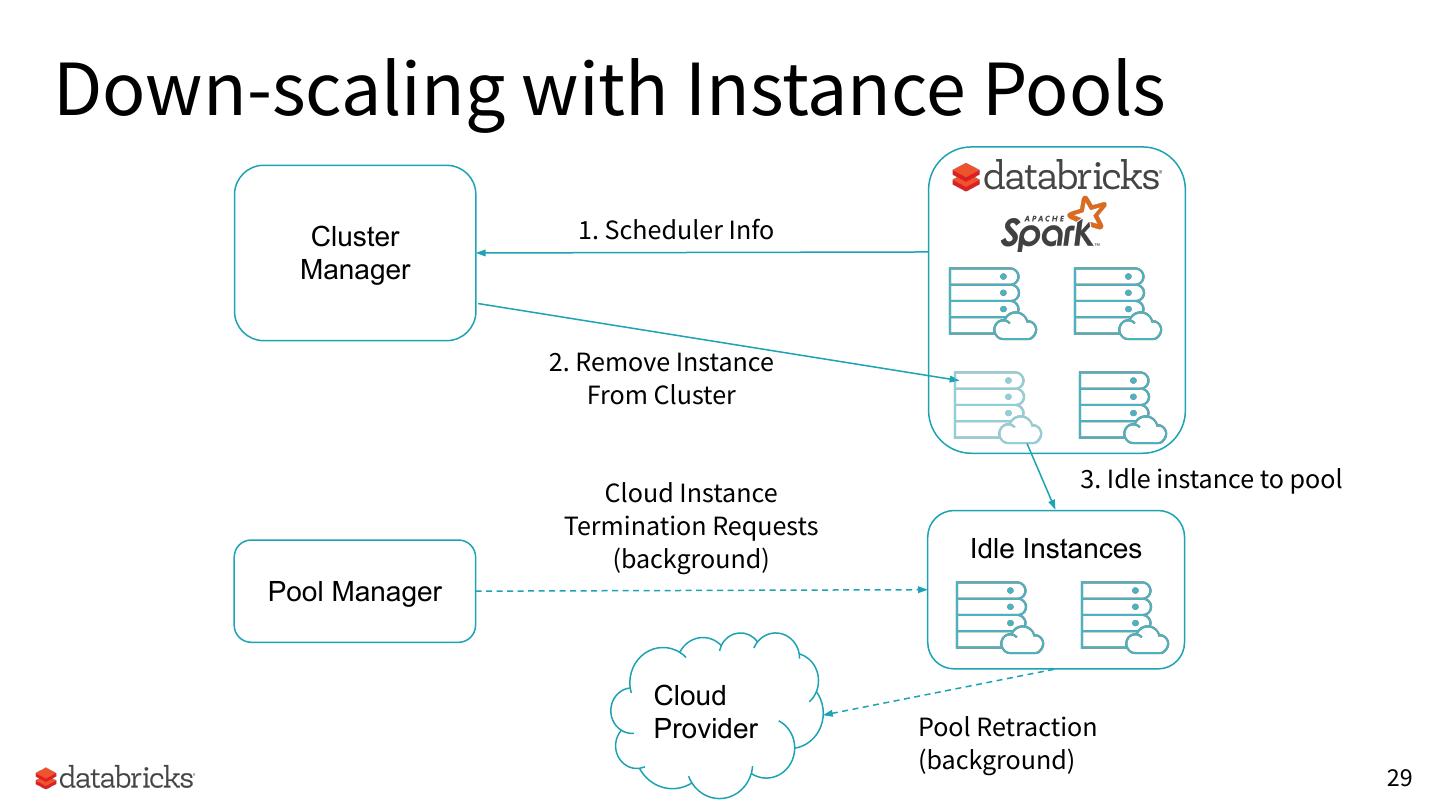
29 .Down-scaling with Instance Pools
Cluster 1. Scheduler Info
Manager
2. Remove Instance
From Cluster
Cloud Instance 3. Idle instance to pool
Termination Requests
(background) Idle Instances
Pool Manager
Cloud
Provider Pool Retraction
(background)
29
�