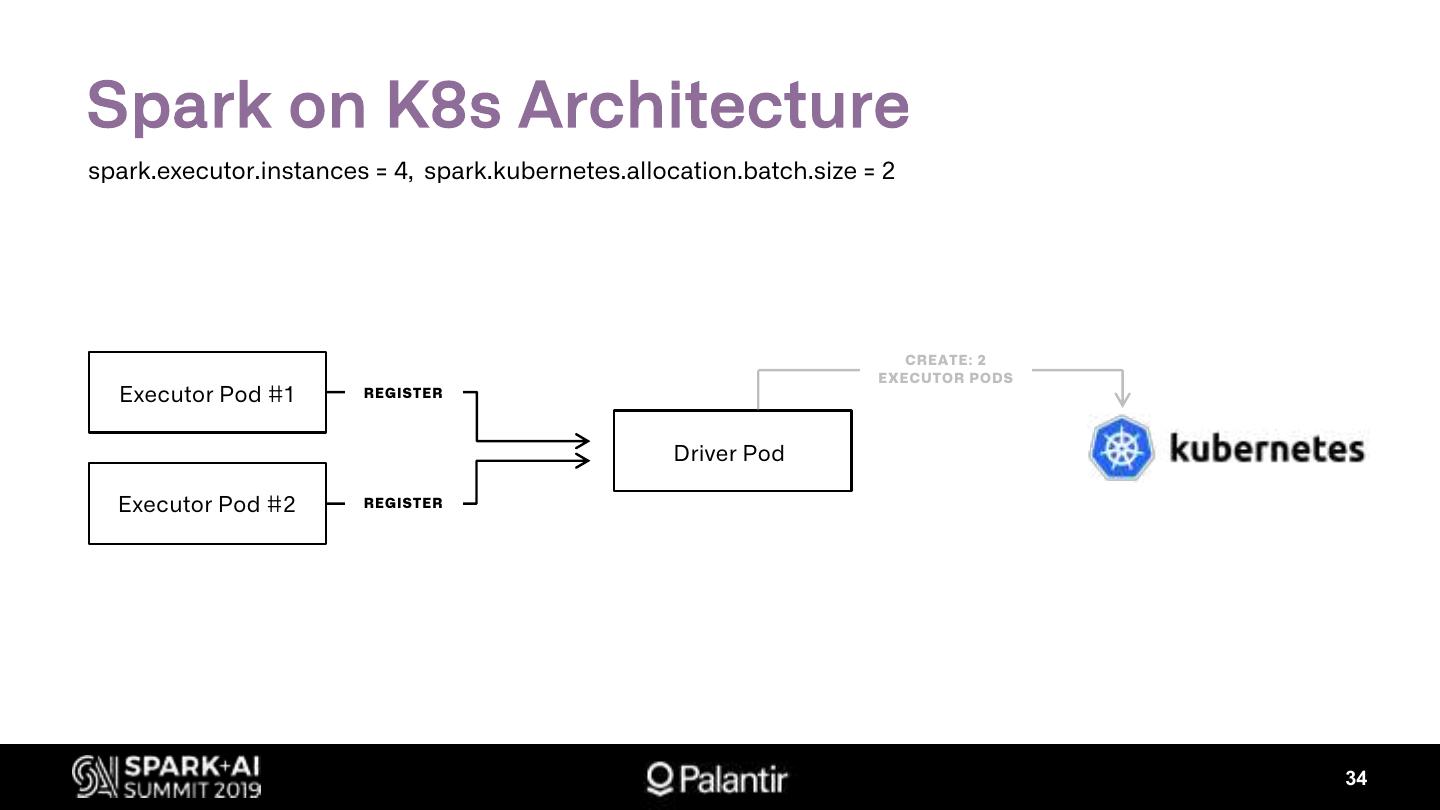
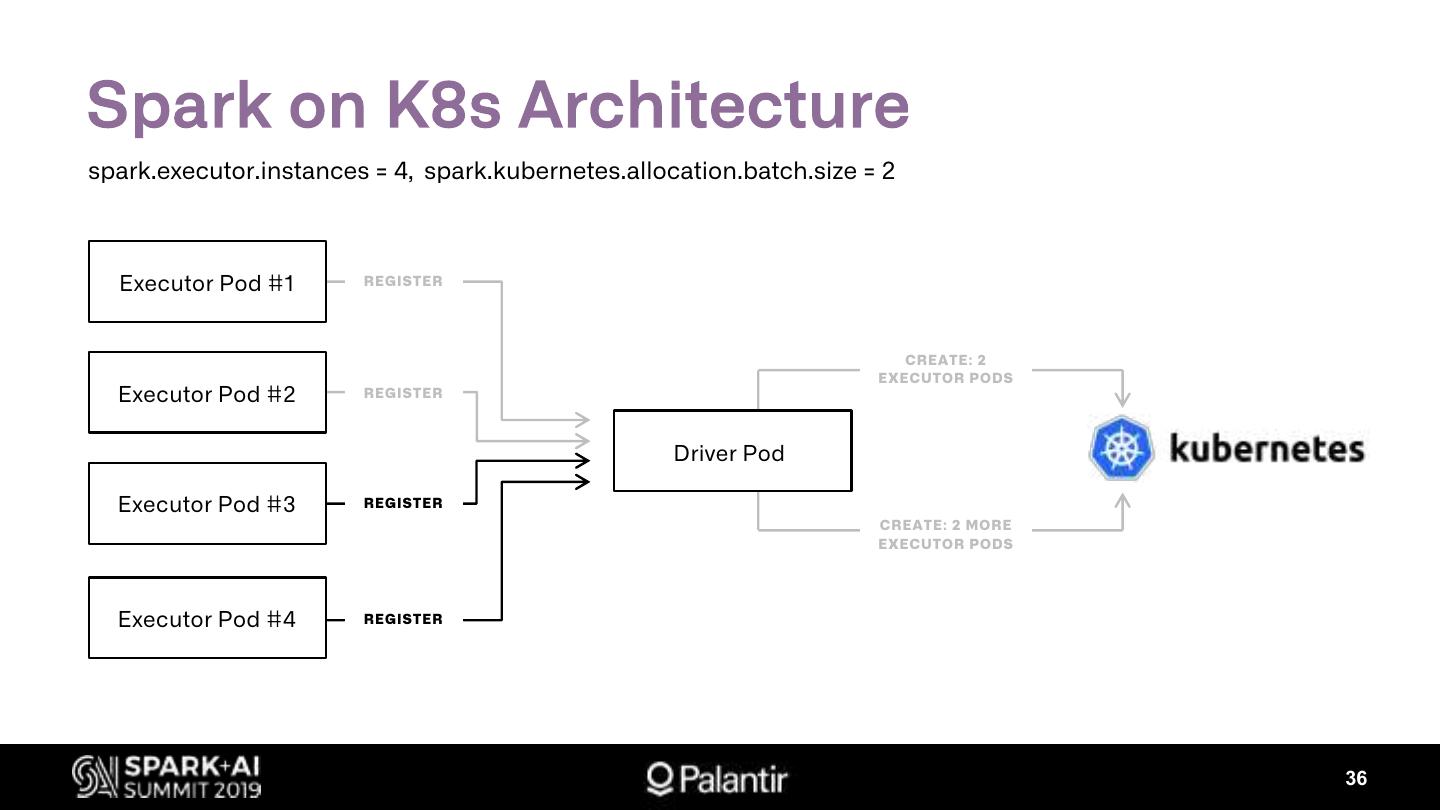
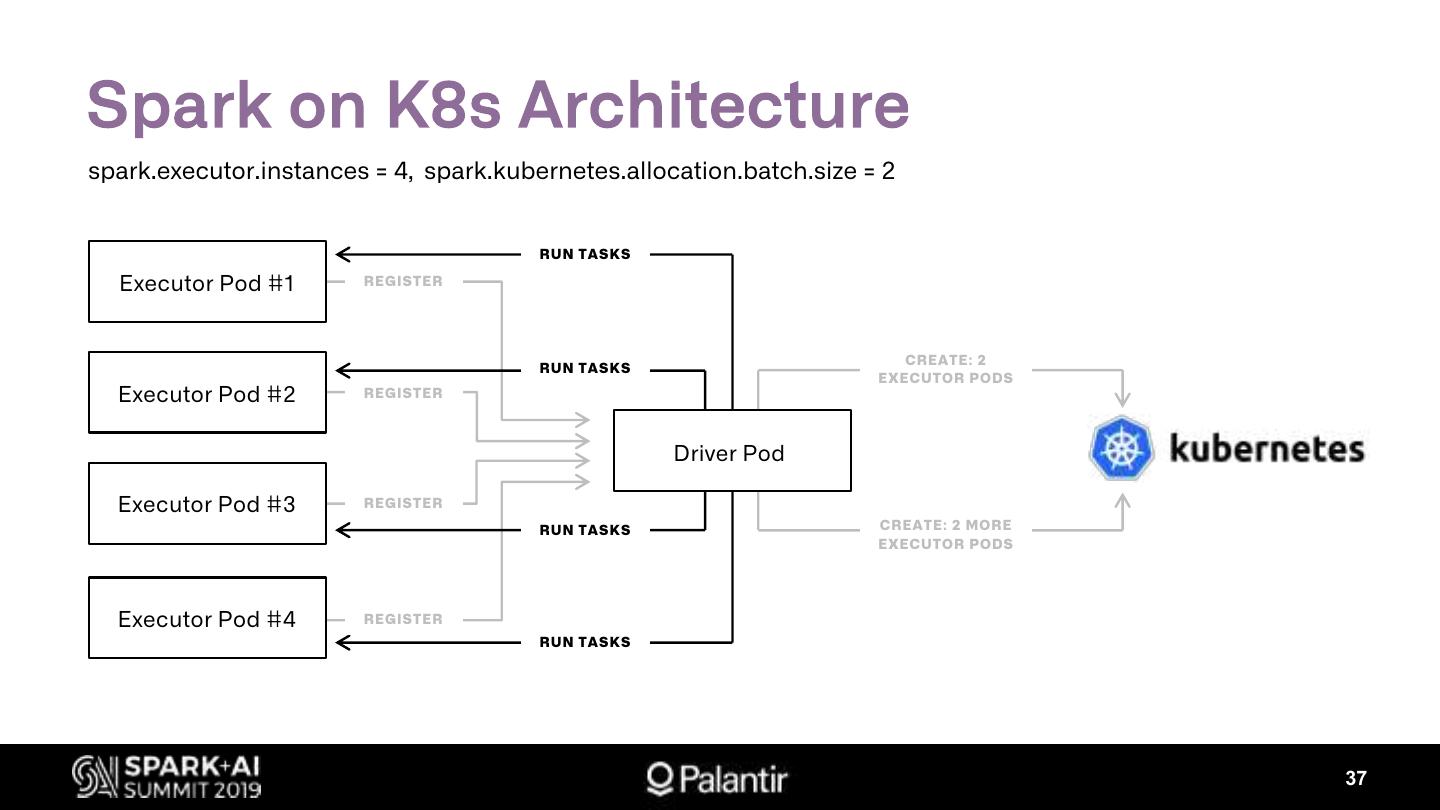
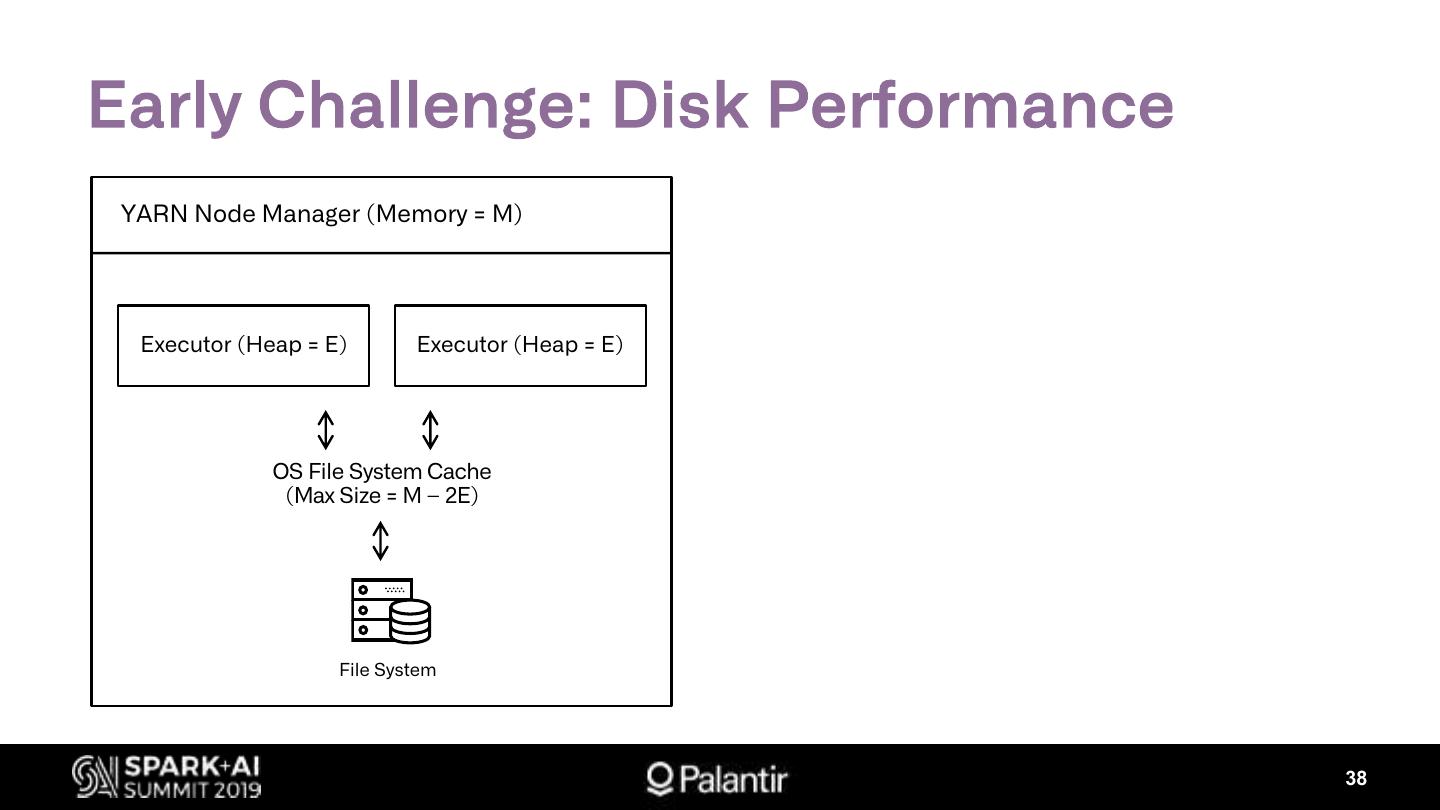
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Reliable Performance at Scale
with Spark on Kubernetes
Will Manning + Matt Cheah, Palantir Technologies
#UnifiedDataAnalytics #SparkAISummit
�
3 .About us
Will Manning 2013 Joined Palantir
2015 First production adopter of
YARN & Parquet
2016 Helped form our Data Flows
& Analytics product groups
Responsible for Engineering
and Architecture for Compute
(including Spark)
3
�
4 .About us
Matt Cheah 2014 Joined Palantir
Migrated Spark cluster management
from standalone to YARN, and later
from YARN to Kubernetes
2018 Spark committer / open source
Spark developer
4
�
5 .Agenda
1. A (Very) Quick Primer on Palantir
2. Why We Moved from YARN
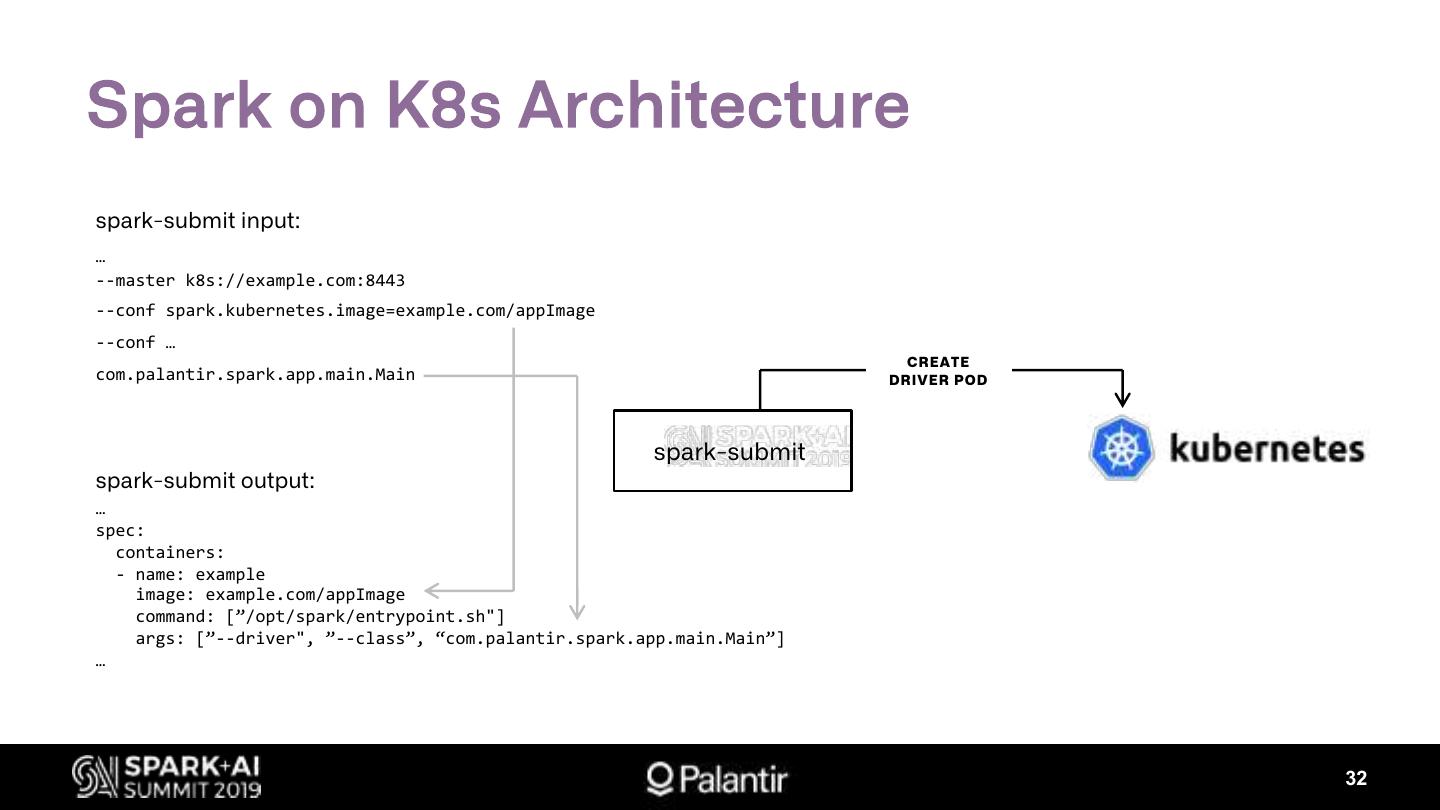
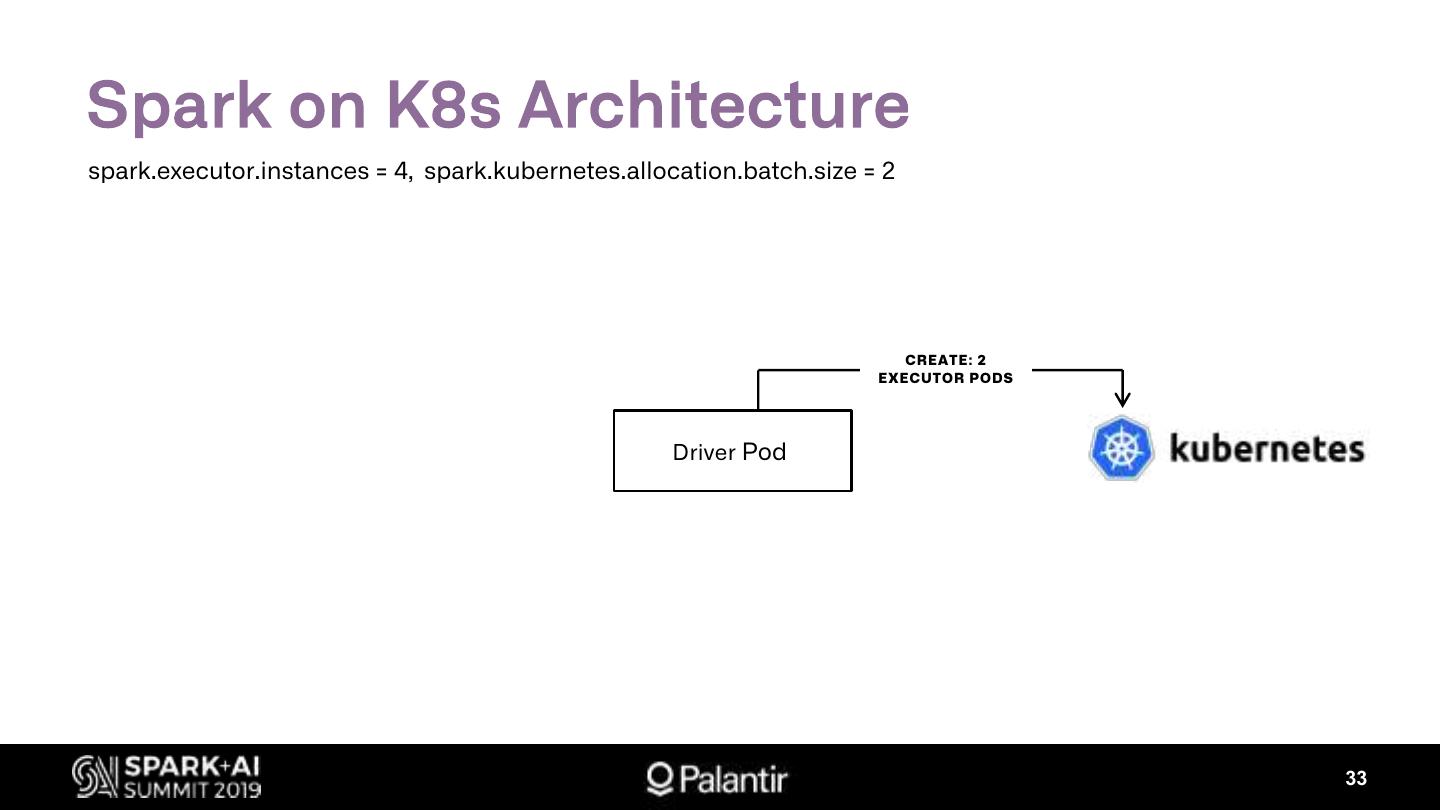
3. Spark on Kubernetes
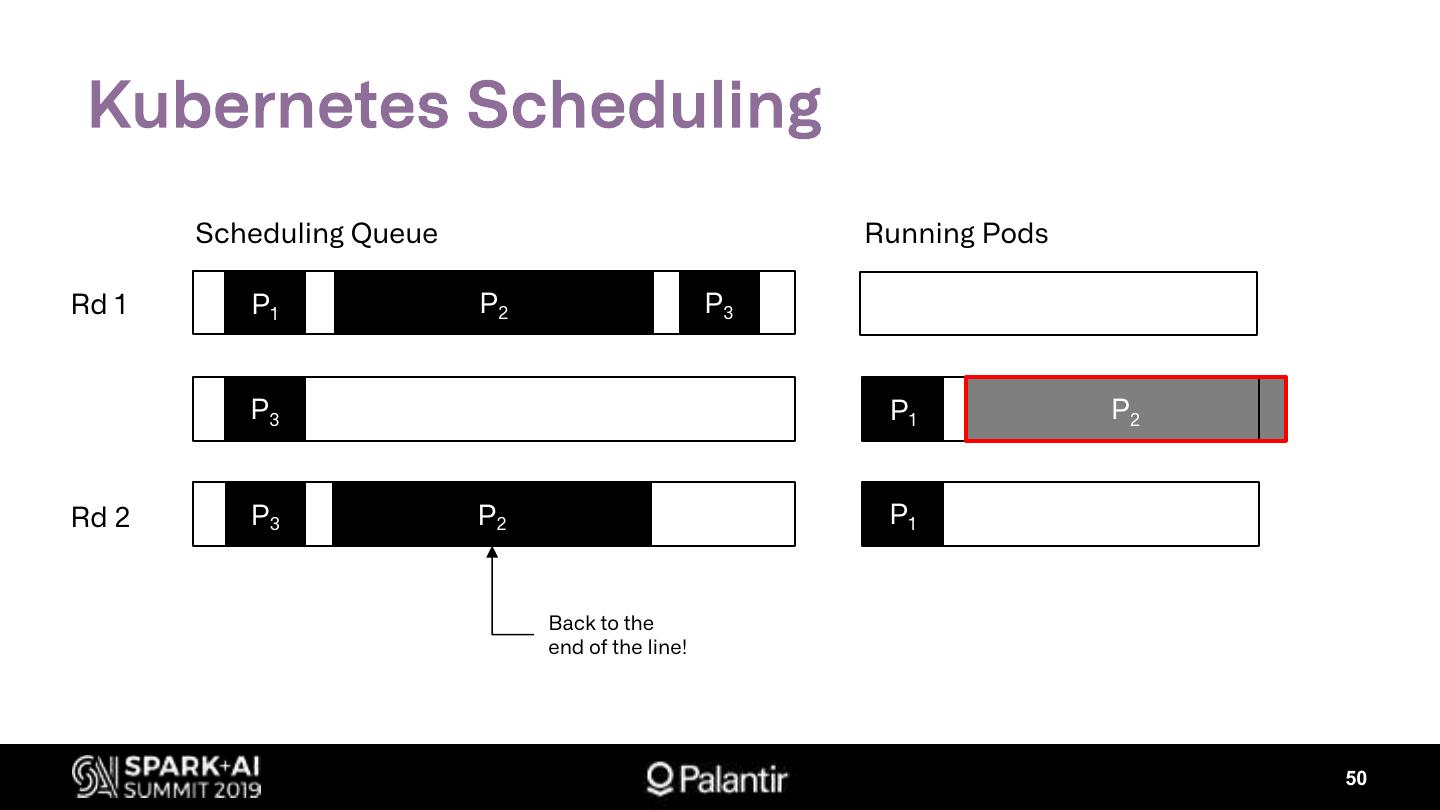
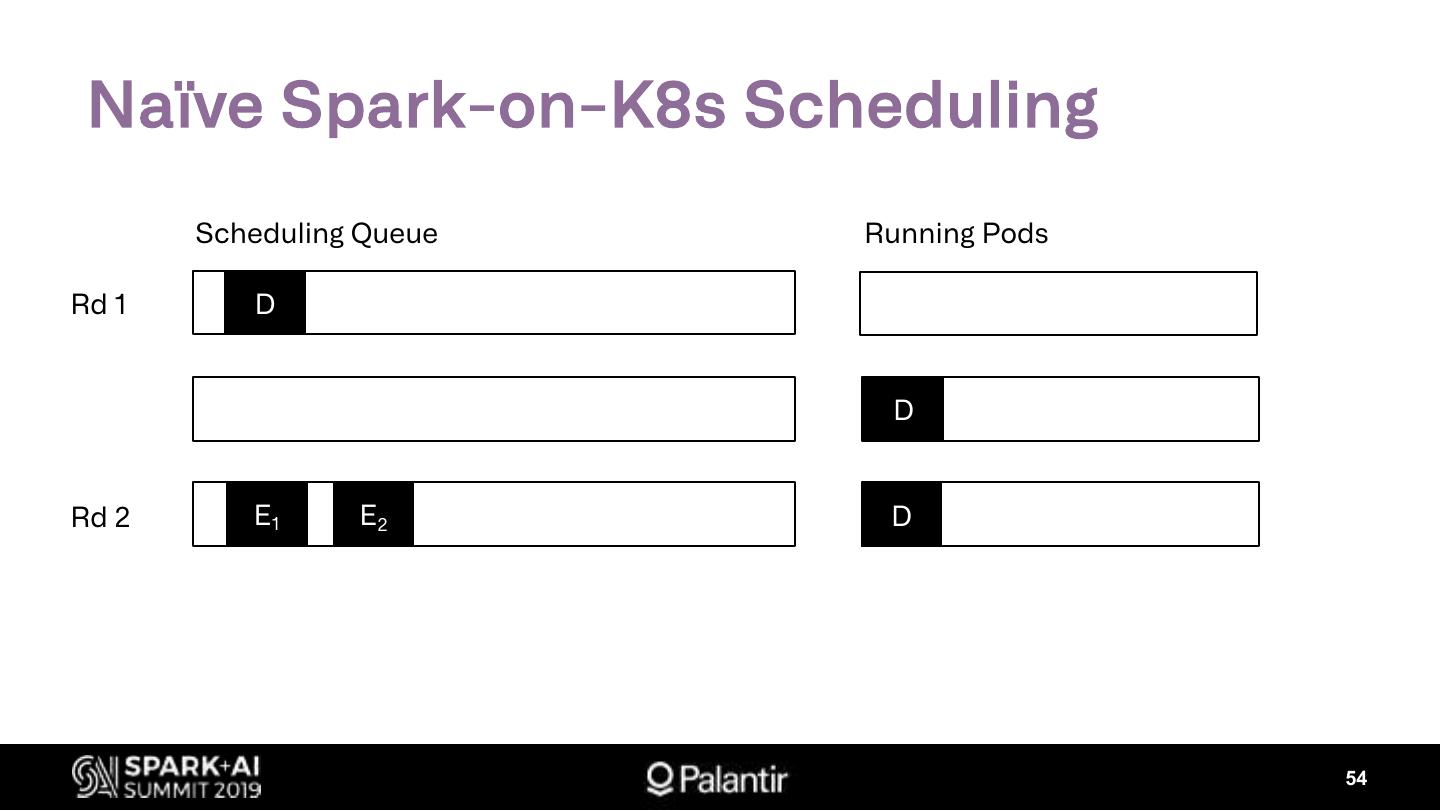
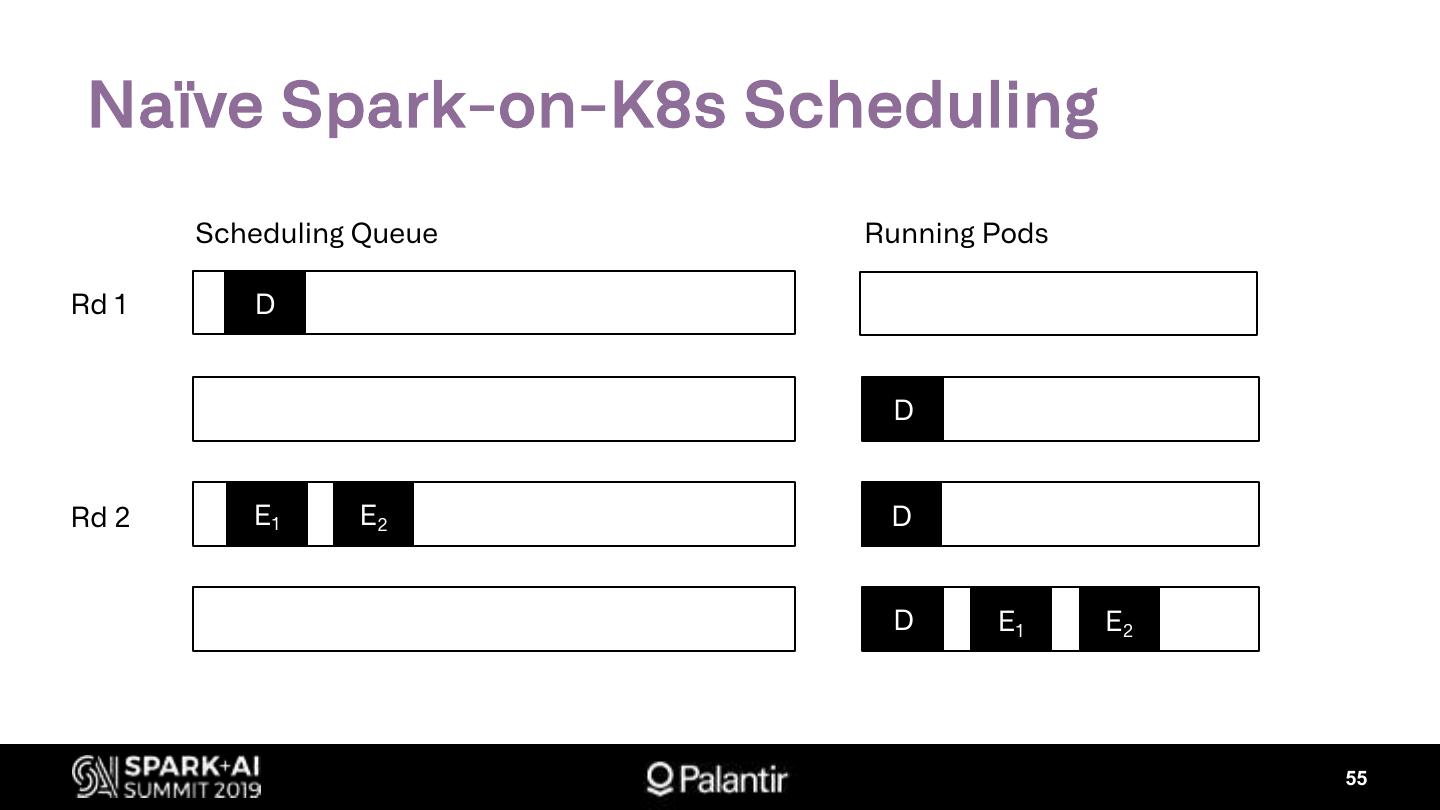
4. Key Production Challenges
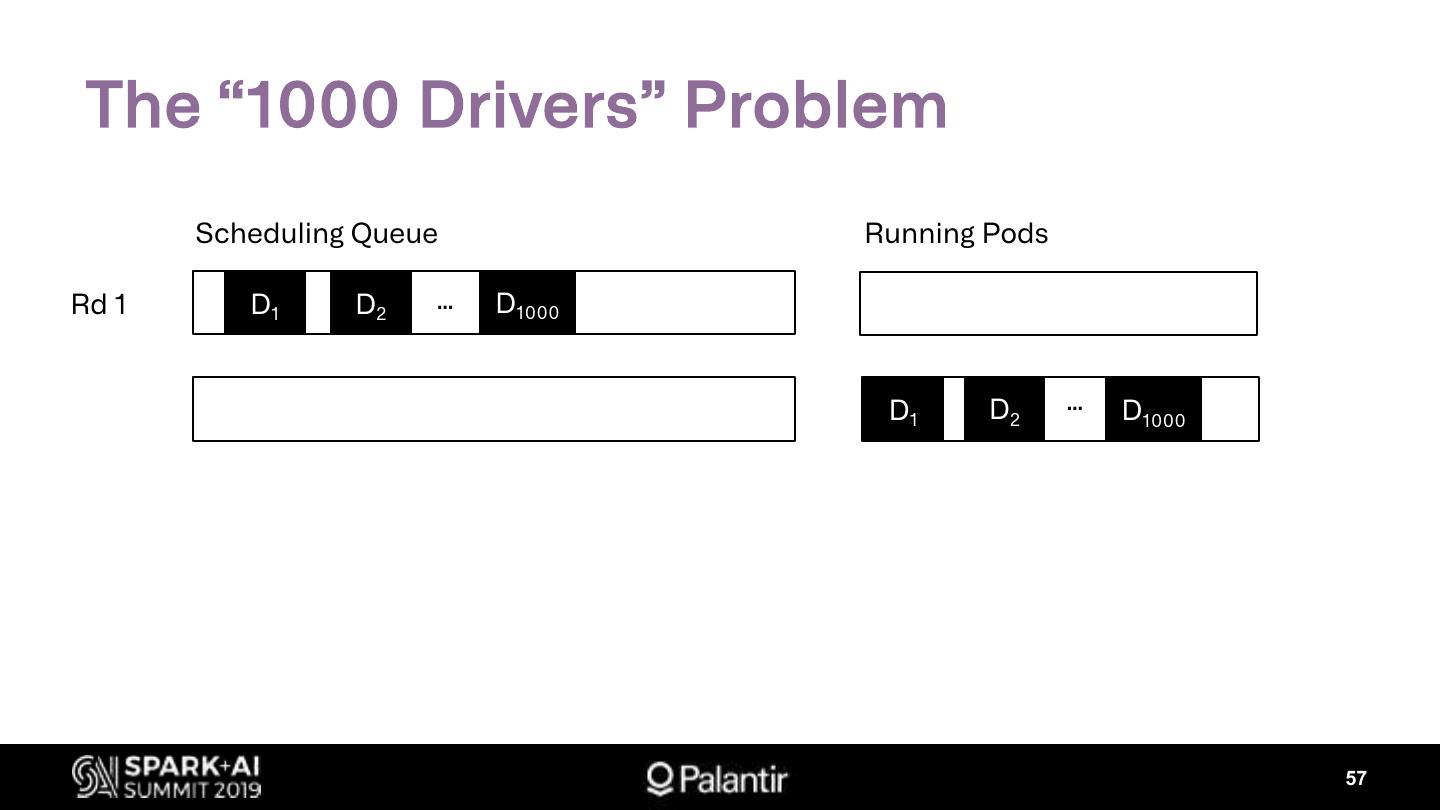
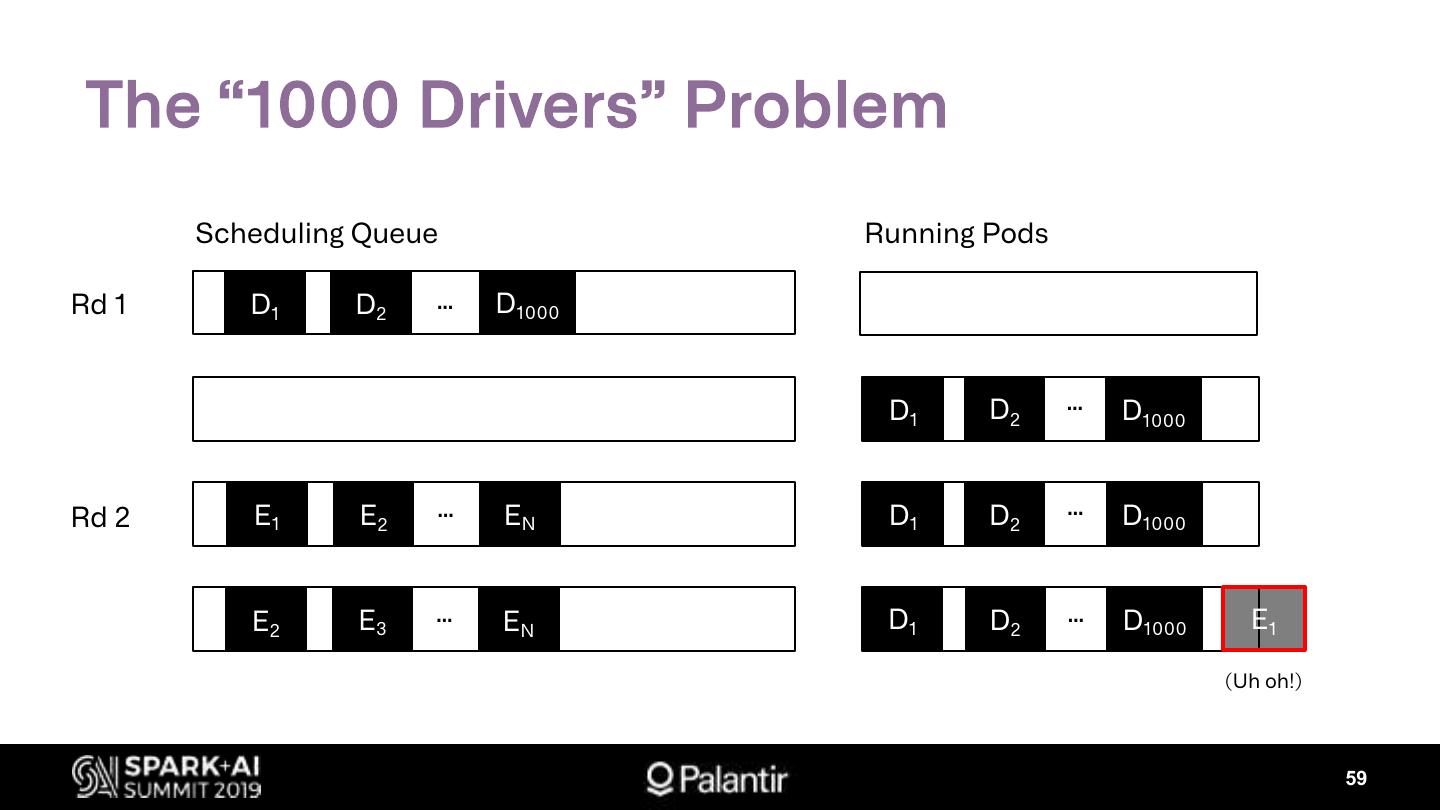
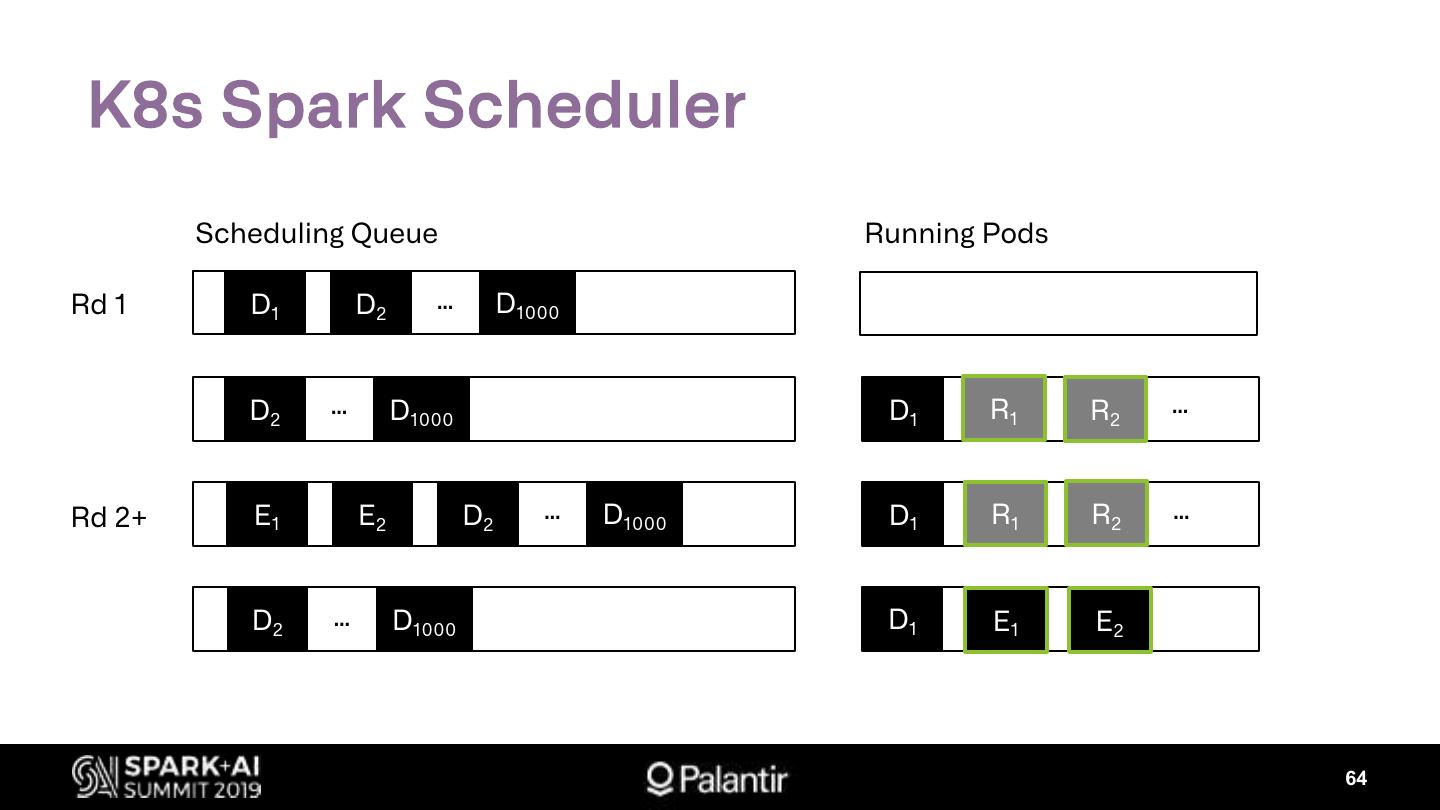
Ø Kubernetes Scheduling
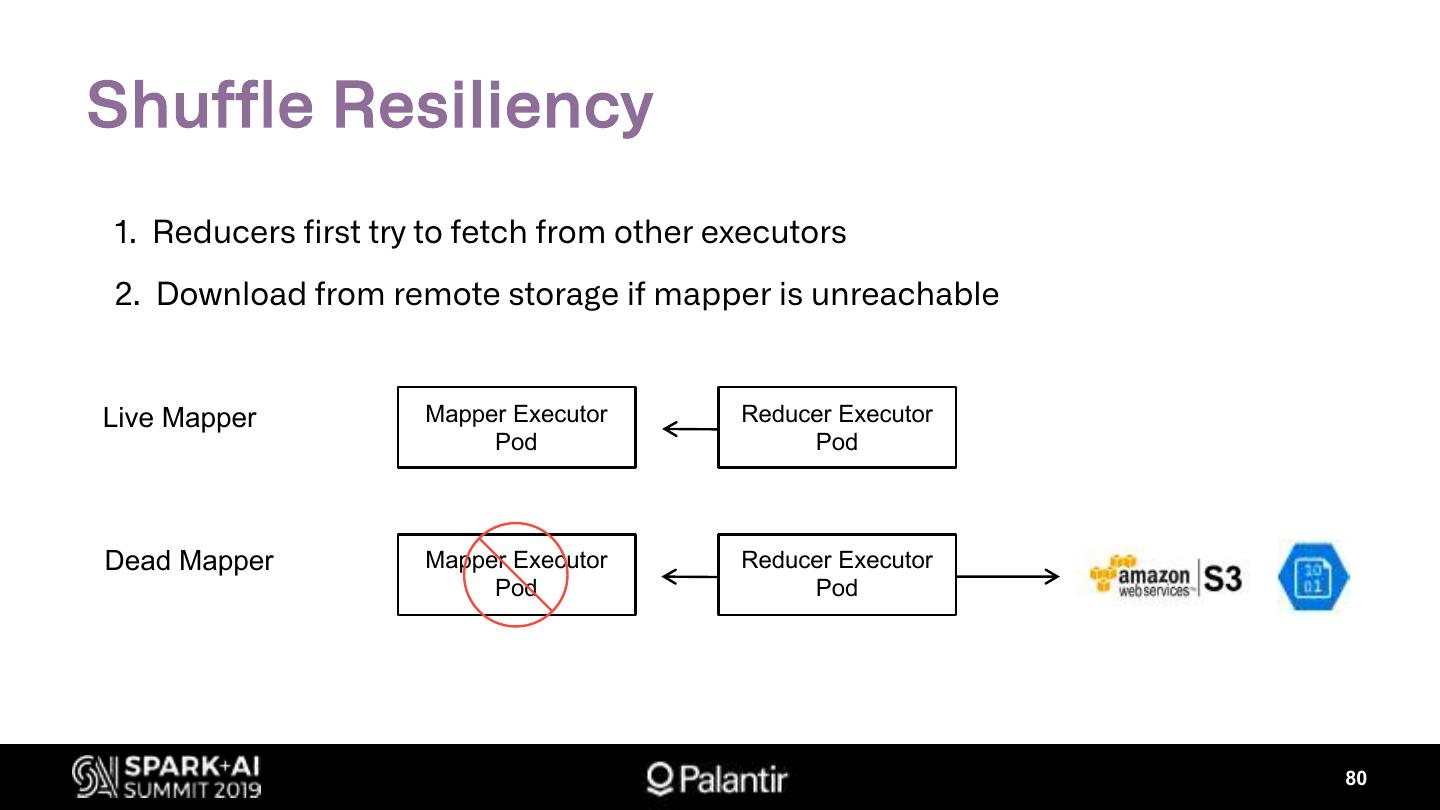
Ø Shuffle Resiliency
5
�
6 .A (Very) Quick Primer on Palantir
… and how Spark on Kubernetes helps power Palantir Foundry
�
7 .Who are we?
Headquartered Palo Alto, CA
Presence Global
Employees ~2500 / Mostly Engineers
Founded 2004
Software Data Integration
7
�
8 .Supporting Counterterrorism
From intelligence operations
to mission planning in the field.
8
�
9 .Energy
Institutions must evolve or die.
Technology and data are driving
this evolution.
9
�
10 .Manufacturing
Ferrari uses Palantir Foundry
to increase performance + reliability.
10
�
11 .Aviation Safety
Palantir and Airbus founded
Skywise to help make air travel
safer and more economical.
11
�
12 .Cancer Research
Syntropy brings together the greatest
minds and institutions to advance
research toward the common goal
of improving human lives.
12
�
13 .Products Built
for a Purpose
Integrate, manage, secure,
and analyze all of your
enterprise data.
Amplify and extend the power
of data integration.
13
�
14 .Enabling analytics in Palantir Foundry
Executing untrusted code on behalf of trusted users in a multitenant environment
– Users can author code (e.g., using Spark SQL
or pySpark) to define complex data
transformations or to perform analysis
– Our users want to write code once and have it
keep working the same way indefinitely
14
�
15 .Enabling analytics in Palantir Foundry
Executing untrusted code on behalf of trusted users in a multitenant environment
– Users can author code (e.g., using Spark SQL – Foundry is responsible for executing arbitrary
or pySpark) to define complex data code on users’ behalf securely
transformations or to perform analysis
– Our users want to write code once and have it – Even though the customer might trust the
keep working the same way indefinitely user, Palantir infrastructure can’t
15
�
16 .Enabling collaboration across organizations
Using Spark on Kubernetes to enable multitenant compute
Engineers from Airline A
Airbus Employees
Engineers from Airline B
16
�
17 .Enabling analytics in Palantir Foundry
Executing untrusted code on behalf of trusted users in a multitenant environment
– Users can author code (e.g., using Spark SQL – Foundry is responsible for executing arbitrary
or pySpark) to define complex data code on users’ behalf securely
transformations or to perform analysis
– Our users want to write code once and have it – Even though the customer might trust the
keep working the same way indefinitely user, Palantir infrastructure can’t
Repeatable Performance Security
17
�
18 .Why We Moved from YARN
�
19 .Hadoop/YARN Security
Two modes
1. Kerberos
19
�
20 .Hadoop/YARN Security
Two modes
1. Kerberos
2. None (only mode until Hadoop 2.x)
NB: I recommend reading Steve Loughran’s “Madness Beyond the Gate” to learn more
20
�
21 .Hadoop/YARN Security
Containerization as of 3.1.1 (late 2018)
21
�
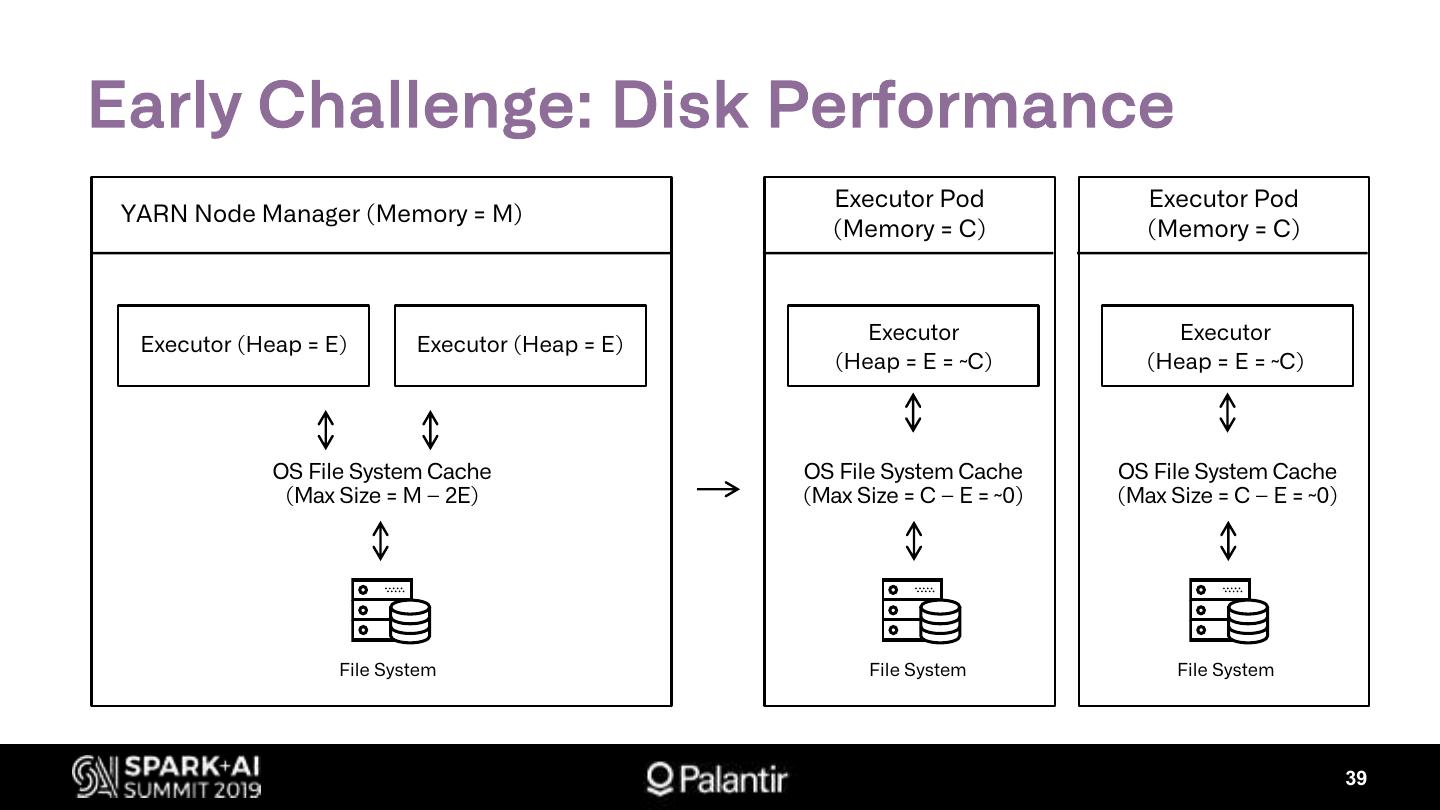
22 .Performance in YARN
YARN’s scheduler attempts to maximize utilization
22
�
23 .Performance in YARN
YARN’s scheduler attempts to maximize utilization
Spark on YARN with dynamic allocation is great at:
– extracting maximum performance from static resources
– providing bursts of resources for one-off batch work
– running “just one more thing”
23
�
24 .Performance in YARN
YARN’s scheduler attempts to maximize utilization
Spark on YARN with dynamic allocation is great at:
– extracting maximum performance from static resources
– providing bursts of resources for one-off batch work
– running “just one more thing”
24
�
25 .YARN: Clown Car Scheduling
(Image Credit: 20th Century Fox Television)
25
�
26 .Performance in YARN
YARN’s scheduler attempts to maximize utilization
Spark on YARN with dynamic allocation is terrible at:
– providing consistency from run to run
– isolating performance between different users/tenants
(i.e., if you kick off a big job, then my job is likely to run slower)
26
�
27 .So… Kubernetes?
ü Native containerization
ü Extreme extensibility (e.g., scheduler, networking/firewalls)
ü Active community with a fast-moving code base
ü Single platform for microservices and compute*
*Spoiler alert: the Kubernetes scheduler is excellent
for web services, not optimized for batch
27
�
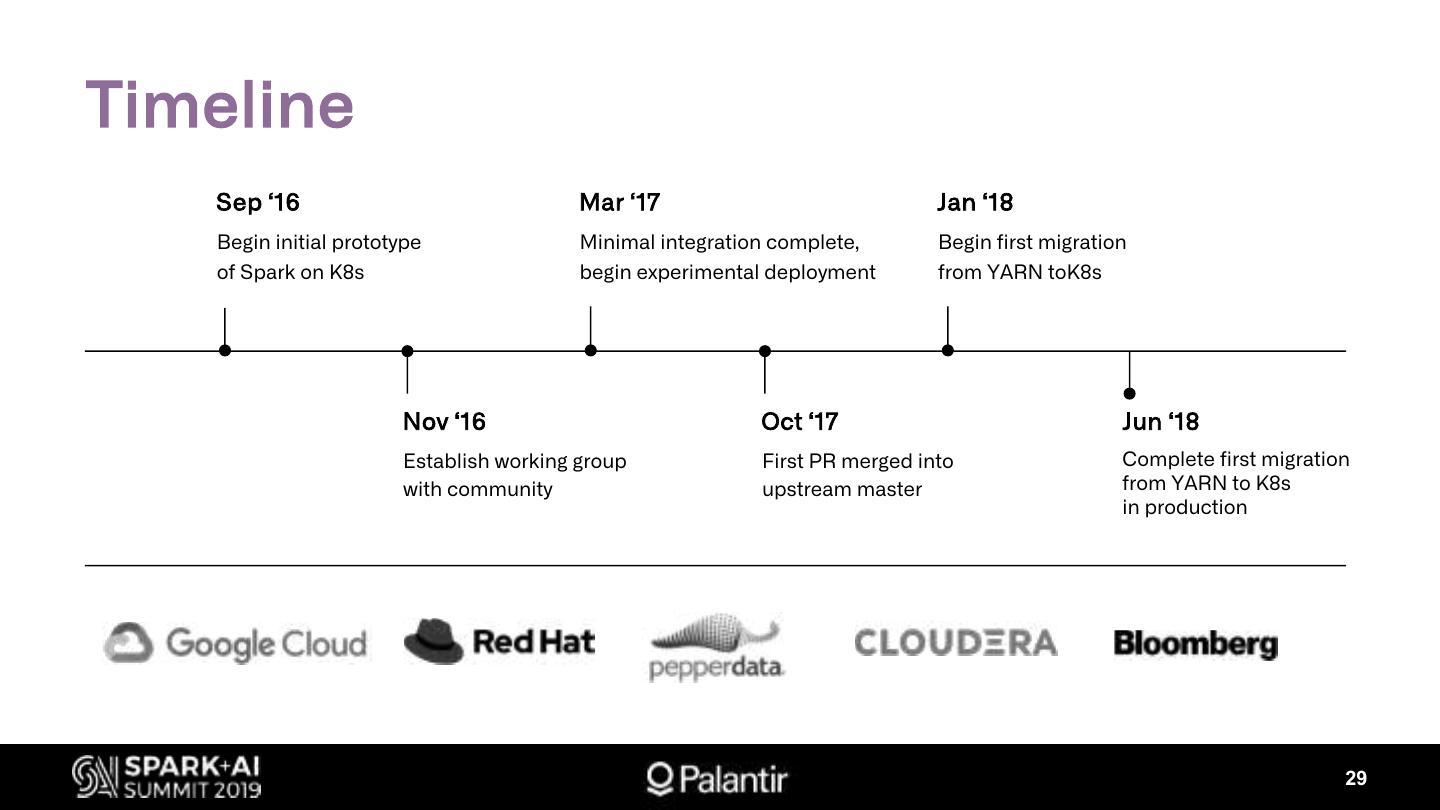
29 .Timeline
Sep ‘16 Mar ‘17 Jan ‘18
Begin initial prototype Minimal integration complete, Begin first migration
of Spark on K8s begin experimental deployment from YARN toK8s
Nov ‘16 Oct ‘17 Jun ‘18
Establish working group First PR merged into Complete first migration
with community upstream master from YARN to K8s
in production
29
�