










































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Physical Plans in Spark SQL
In Spark SQL the physical plan provides the fundamental information about the execution of the query. The objective of this talk is to convey understanding and familiarity of query plans in Spark SQL, and use that knowledge to achieve better performance of Apache Spark queries. We will walk you through the most common operators you might find in the query plan and explain some relevant information that can be useful in order to understand some details about the execution. If you understand the query plan, you can look for the weak spot and try to rewrite the query to achieve a more optimal plan that leads to more efficient execution.
The main content of this talk is based on Spark source code but it will reflect some real-life queries that we run while processing data. We will show some examples of query plans and explain how to interpret them and what information can be taken from them. We will also describe what is happening under the hood when the plan is generated focusing mainly on the phase of physical planning. In general, in this talk we want to share what we have learned from both Spark source code and real-life queries that we run in our daily data processing.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Physical Plans in Spark SQL David Vrba, Socialbakers #UnifiedDataAnalytics #SparkAISummit
3 . ● David Vrba Ph.D. ● Data Scientist & Data Engineer at Socialbakers ○ Developing ETL pipelines in Spark ○ Optimizing Spark jobs ○ Productionalizing Spark applications ● Lecturing Spark trainings and workshops ○ Studying Spark source code #UnifiedDataAnalytics #SparkAISummit 3
4 .Goal ● Share what we have learned by studying Spark source code and by using Spark on daily basis ○ Processing data from social networks (Facebook, Twitter, Instagram, ...) ○ Regularly processing data on scales up to 10s of TBs ○ Understanding the query plan is a must for efficient processing #UnifiedDataAnalytics #SparkAISummit 4
5 .Outline ● Two part talk ○ In the first part we cover some theory ■ How query execution works ■ Physical Plan operators ■ Where to look for relevant information in Spark UI ○ In the second part we show some examples ■ Model queries with particular optimizations ■ Useful tips ○ Q/A #UnifiedDataAnalytics #SparkAISummit 5
6 .Part I ● Query Execution ● Physical Plan Operators ● Spark UI #UnifiedDataAnalytics #SparkAISummit 6
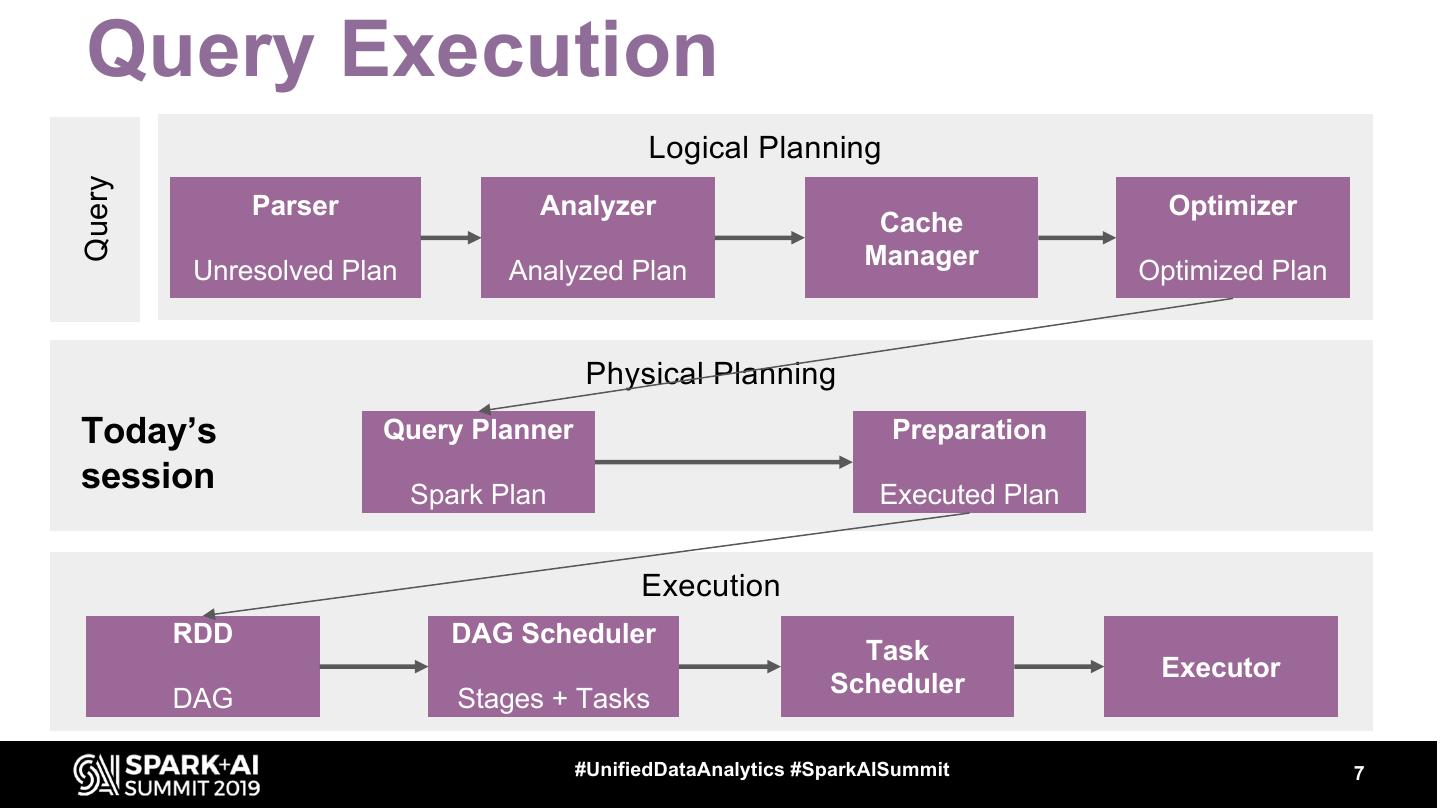
7 . Query Execution Logical Planning Query Parser Analyzer Optimizer Cache Manager Unresolved Plan Analyzed Plan Optimized Plan Physical Planning Today’s Query Planner Preparation session Spark Plan Executed Plan Execution RDD DAG Scheduler Task Executor Scheduler DAG Stages + Tasks #UnifiedDataAnalytics #SparkAISummit 7
8 . Logical Planning ● Logical plan is created, analyzed and optimized ● Logical plan ○ Tree representation of the query ○ It is an abstraction that carries information about what is supposed to happen ○ It does not contain precise information on how it happens ○ Composed of ■ Relational operators – Filter, Join, Project, ... (they represent DataFrame transformations) ■ Expressions – Column transformations, filtering conditions, joining conditions, ... #UnifiedDataAnalytics #SparkAISummit 8
9 .Physical Planning ● In the phase of logical planning we get Optimized Logical Plan ● Execution layer does not understand DataFrame / Logical Plan (LP) ● Logical Plan has to be converted to a Physical Plan (PP) ● Physical Plan ○ Bridge between LP and RDDs ○ Similarly to Logical Plan it is a tree ○ Contains more specific description of how things should happen (specific choice of algorithms) ○ Uses lower level primitives - RDDs #UnifiedDataAnalytics #SparkAISummit 9
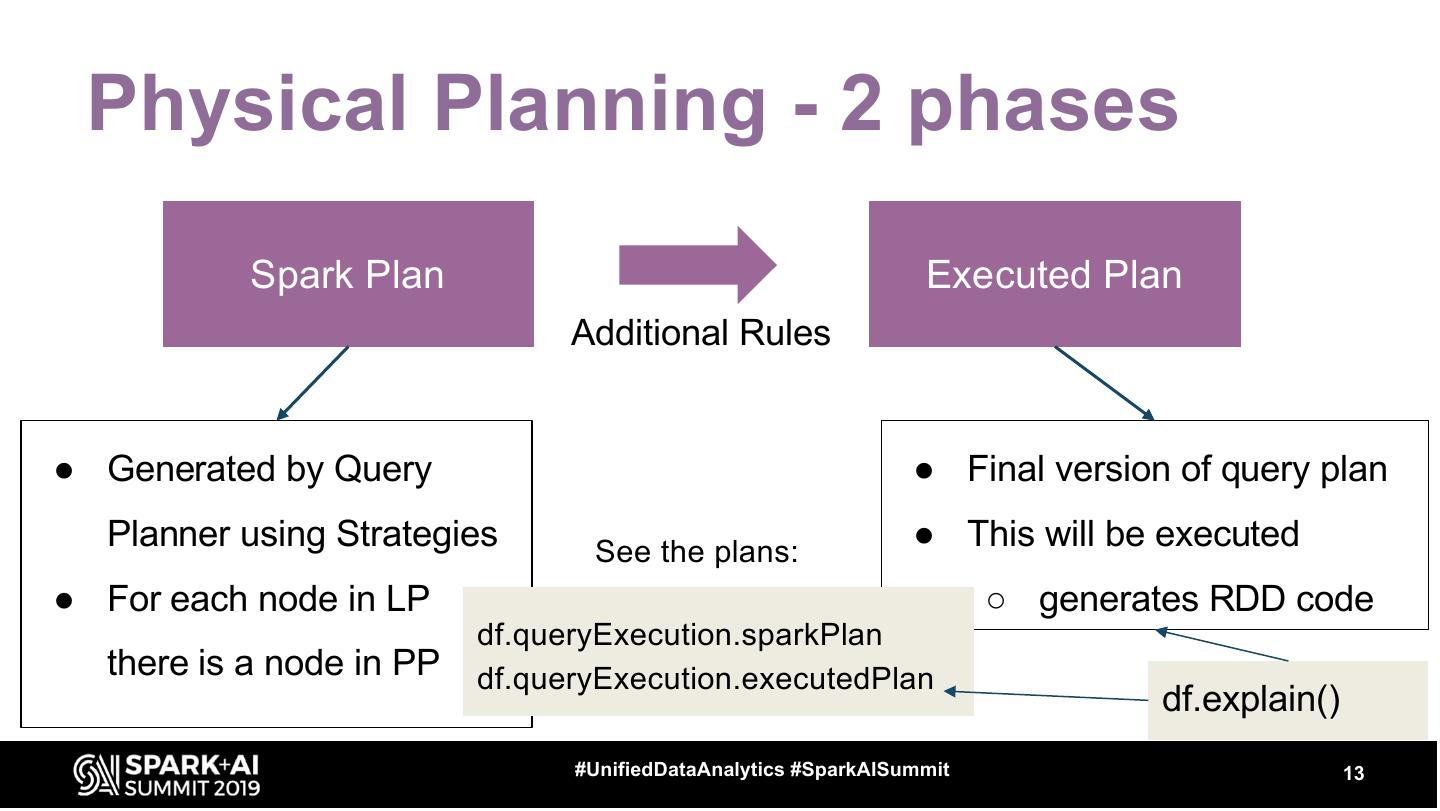
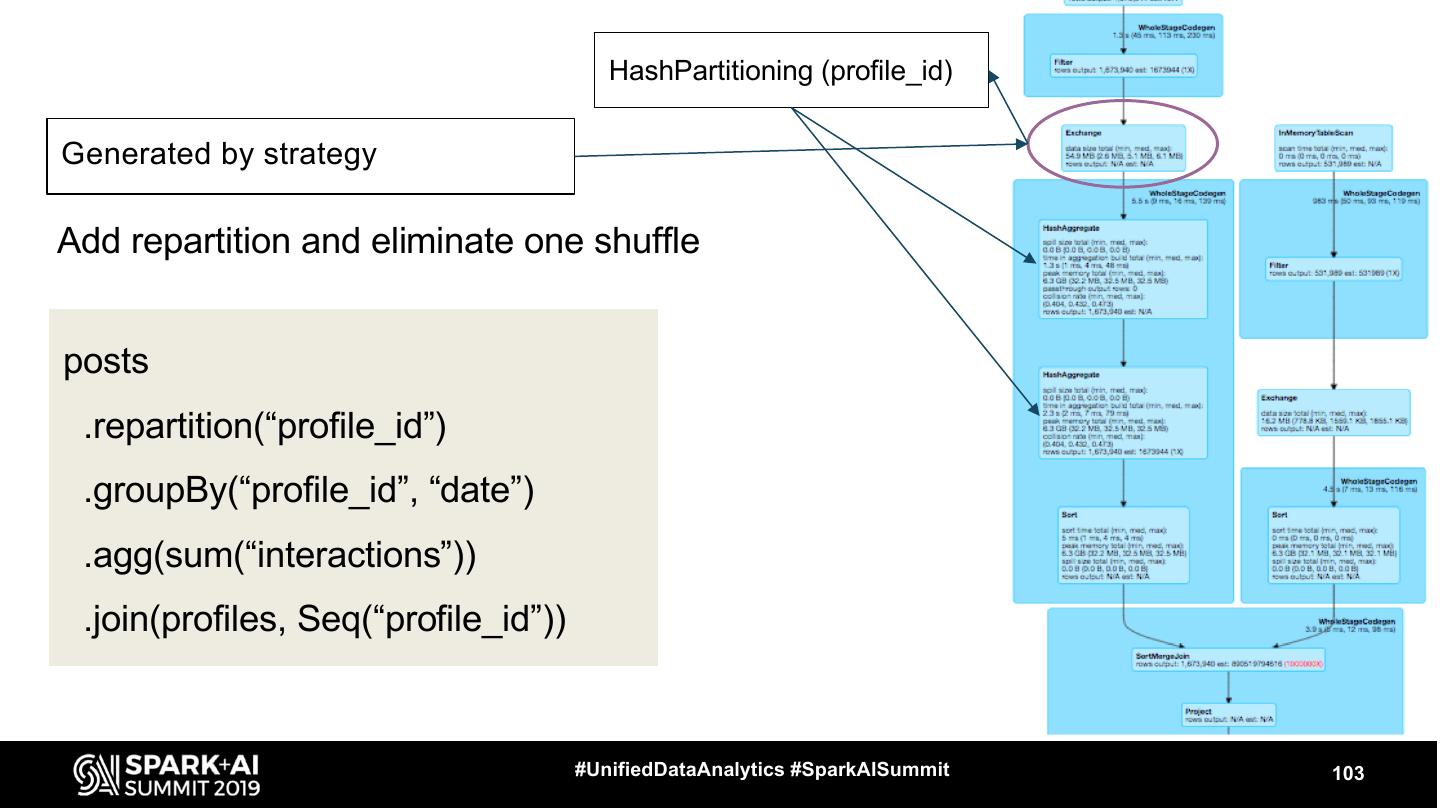
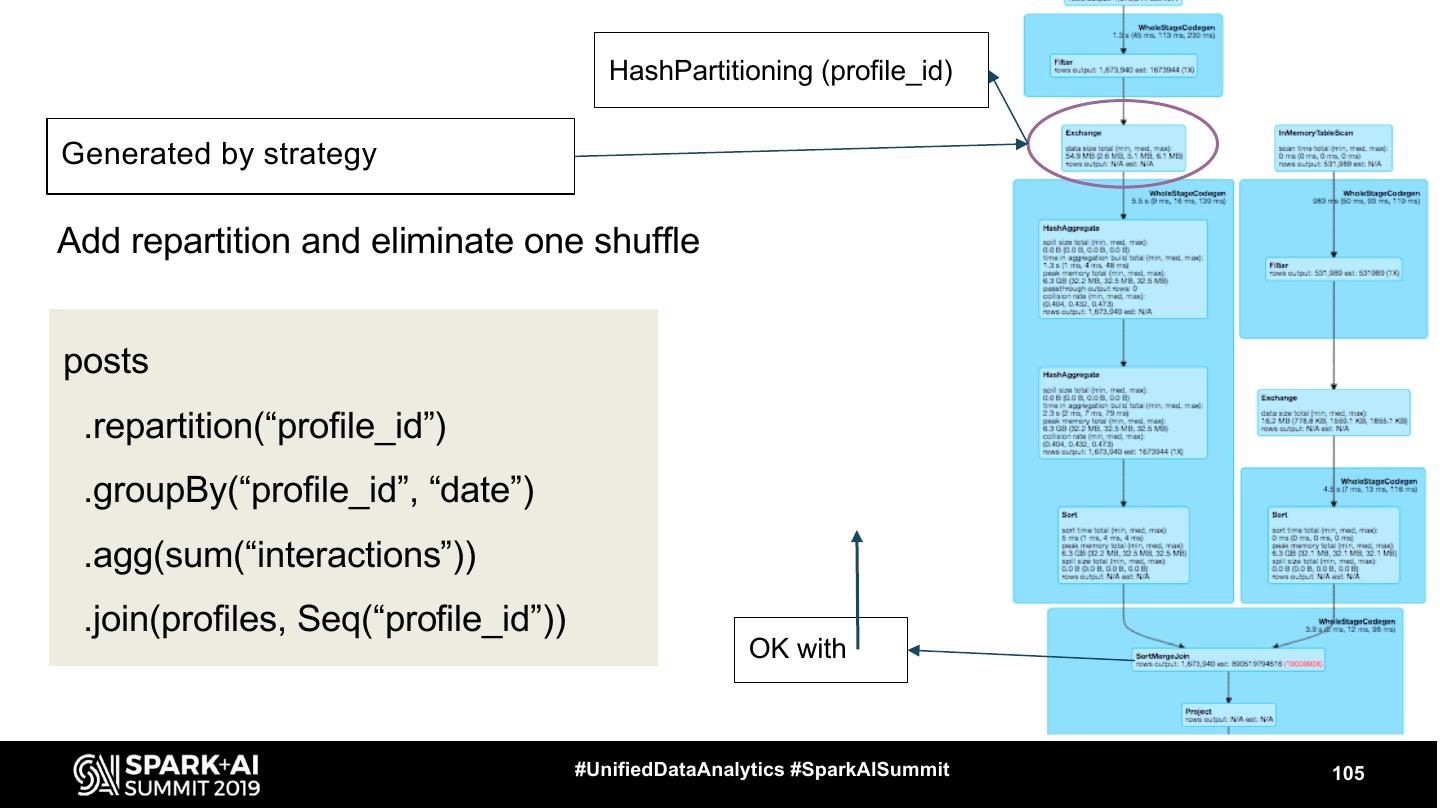
10 . Physical Planning - 2 phases Spark Plan Executed Plan Additional Rules ● Generated by Query Planner using Strategies ● For each node in LP there is a node in PP #UnifiedDataAnalytics #SparkAISummit 10
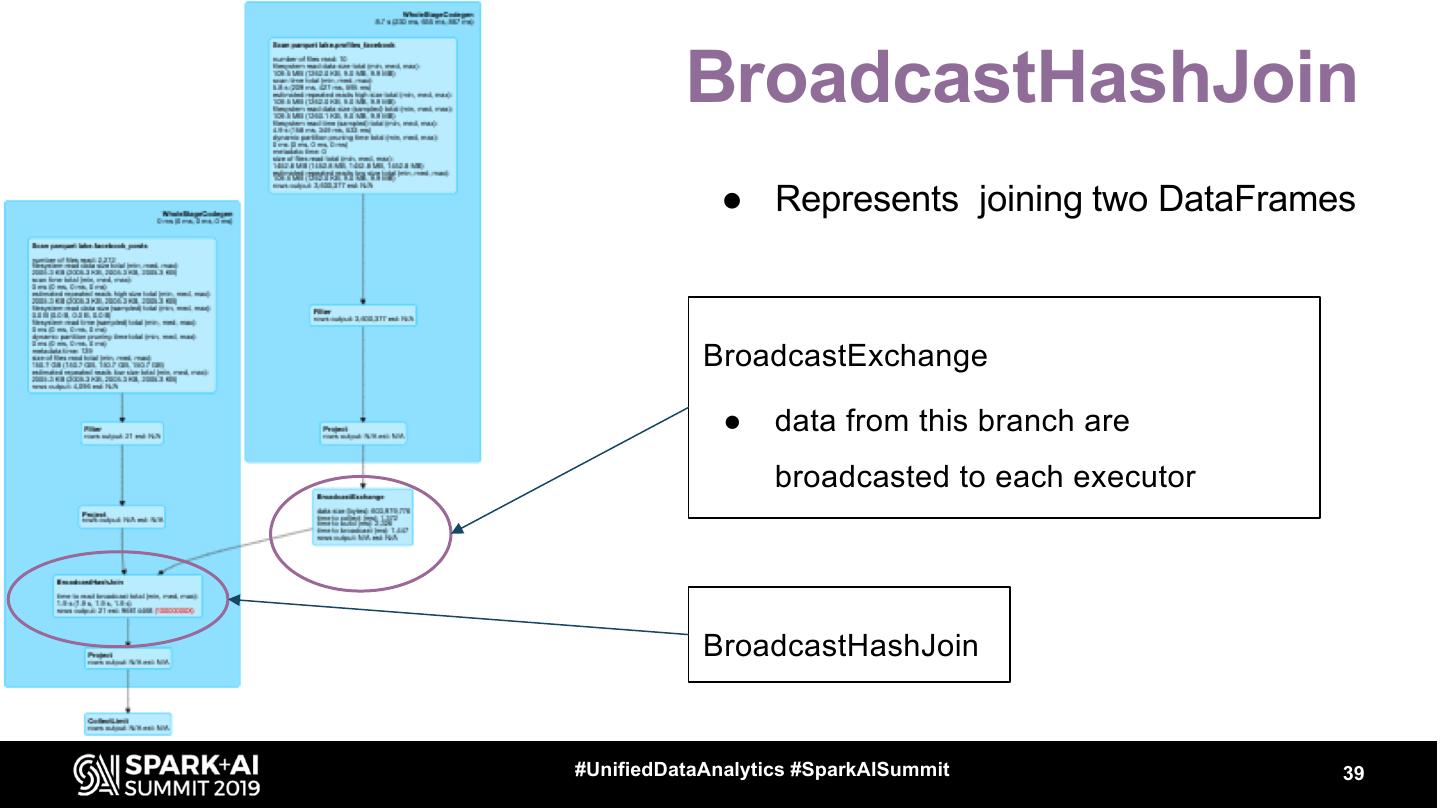
11 . Physical Planning - 2 phases Spark Plan Executed Plan Additional Rules Strategy example: JoinSelection ● Generated by Query In Physical Plan: Planner using Strategies In Logical Plan: SortMergeJoin ● For each node in LP Join there is a node in PP BroadcastHashJoin #UnifiedDataAnalytics #SparkAISummit 11
12 . Physical Planning - 2 phases Spark Plan Executed Plan Additional Rules ● Generated by Query ● Final version of query plan Planner using Strategies ● This will be executed ● For each node in LP ○ generates RDD code there is a node in PP #UnifiedDataAnalytics #SparkAISummit 12
13 . Physical Planning - 2 phases Spark Plan Executed Plan Additional Rules ● Generated by Query ● Final version of query plan Planner using Strategies See the plans: ● This will be executed ● For each node in LP ○ generates RDD code df.queryExecution.sparkPlan there is a node in PP df.queryExecution.executedPlan df.explain() #UnifiedDataAnalytics #SparkAISummit 13
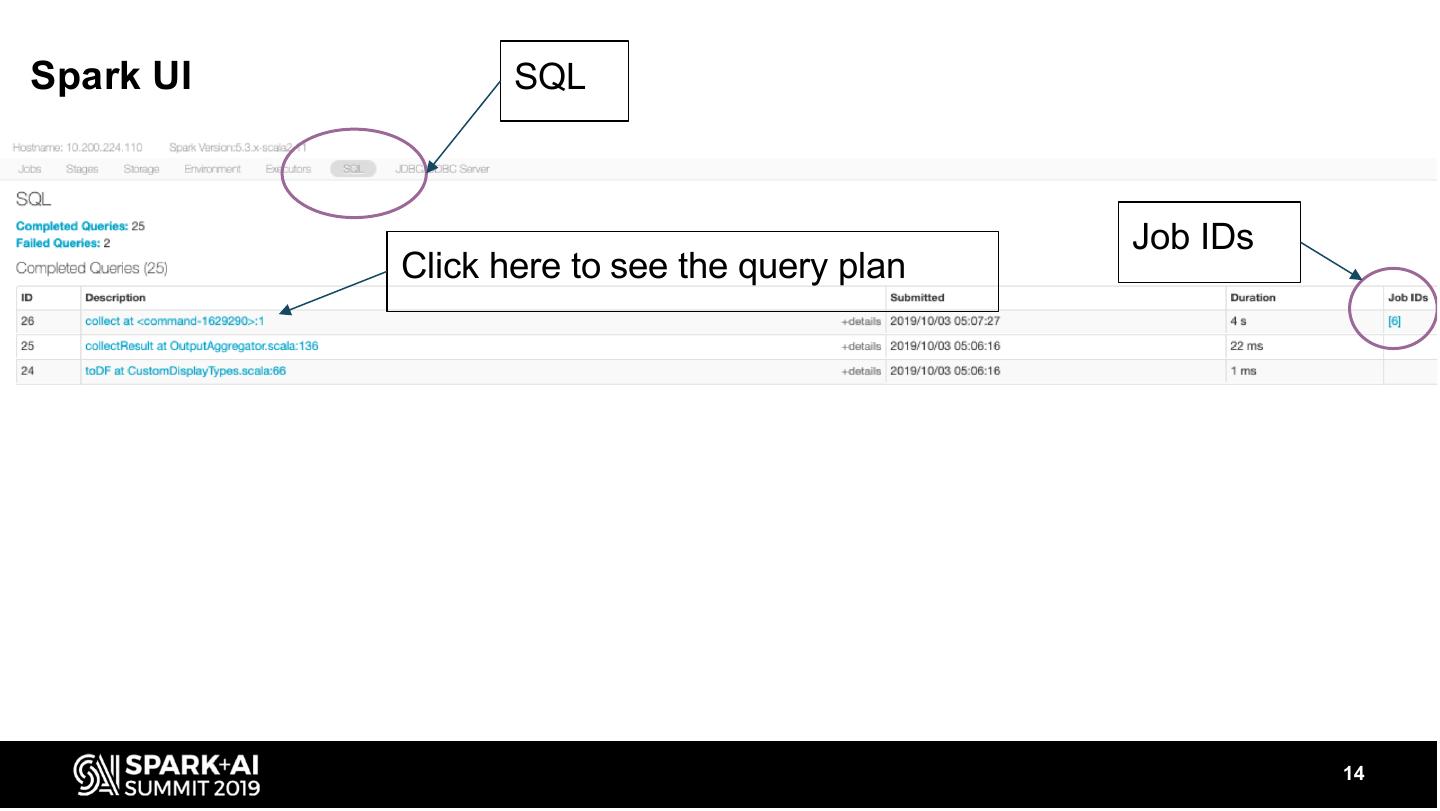
14 .Spark UI SQL Job IDs Click here to see the query plan 14
15 . Graphical representation of the Physical Plan - executed plan Details - string representation (LP + PP) 15
16 .16
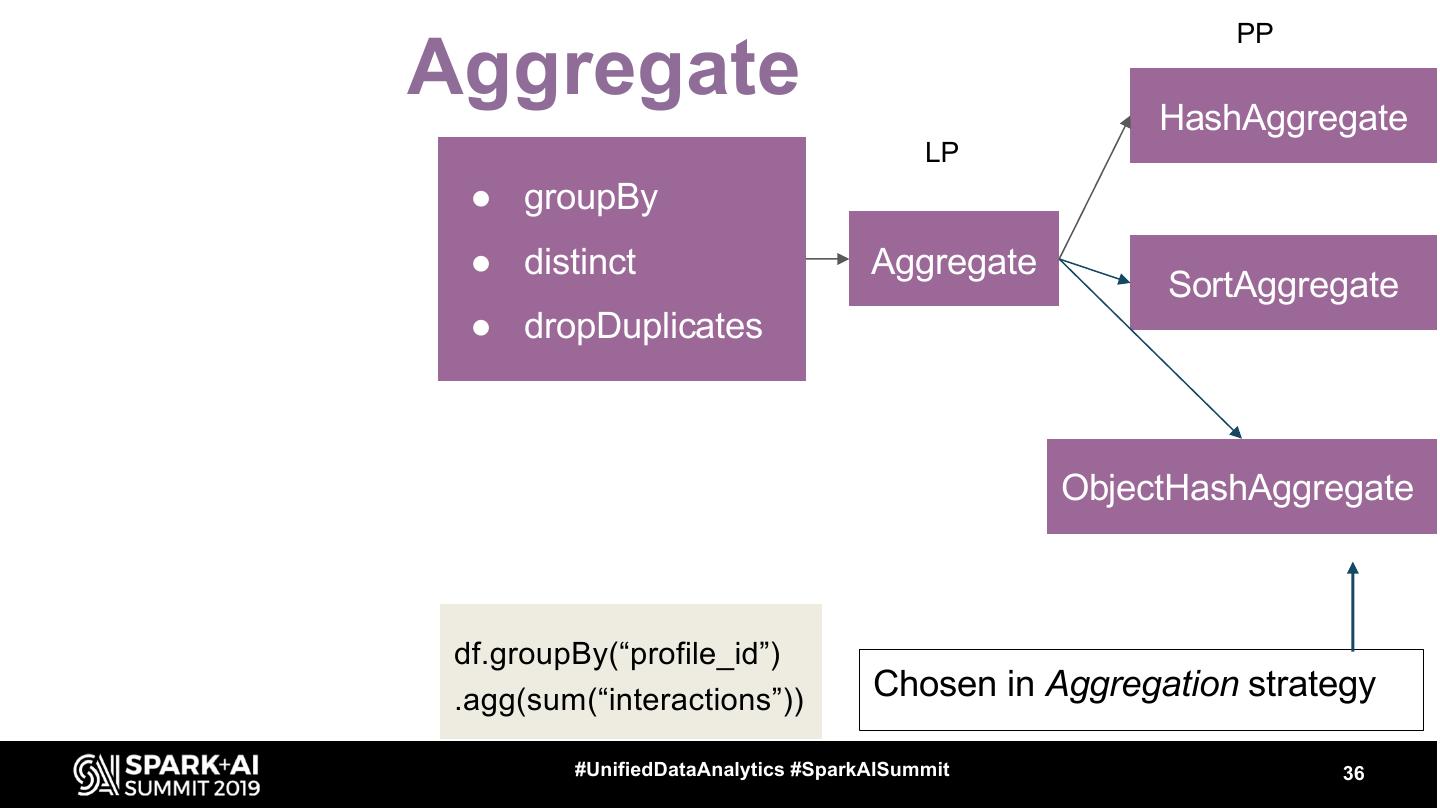
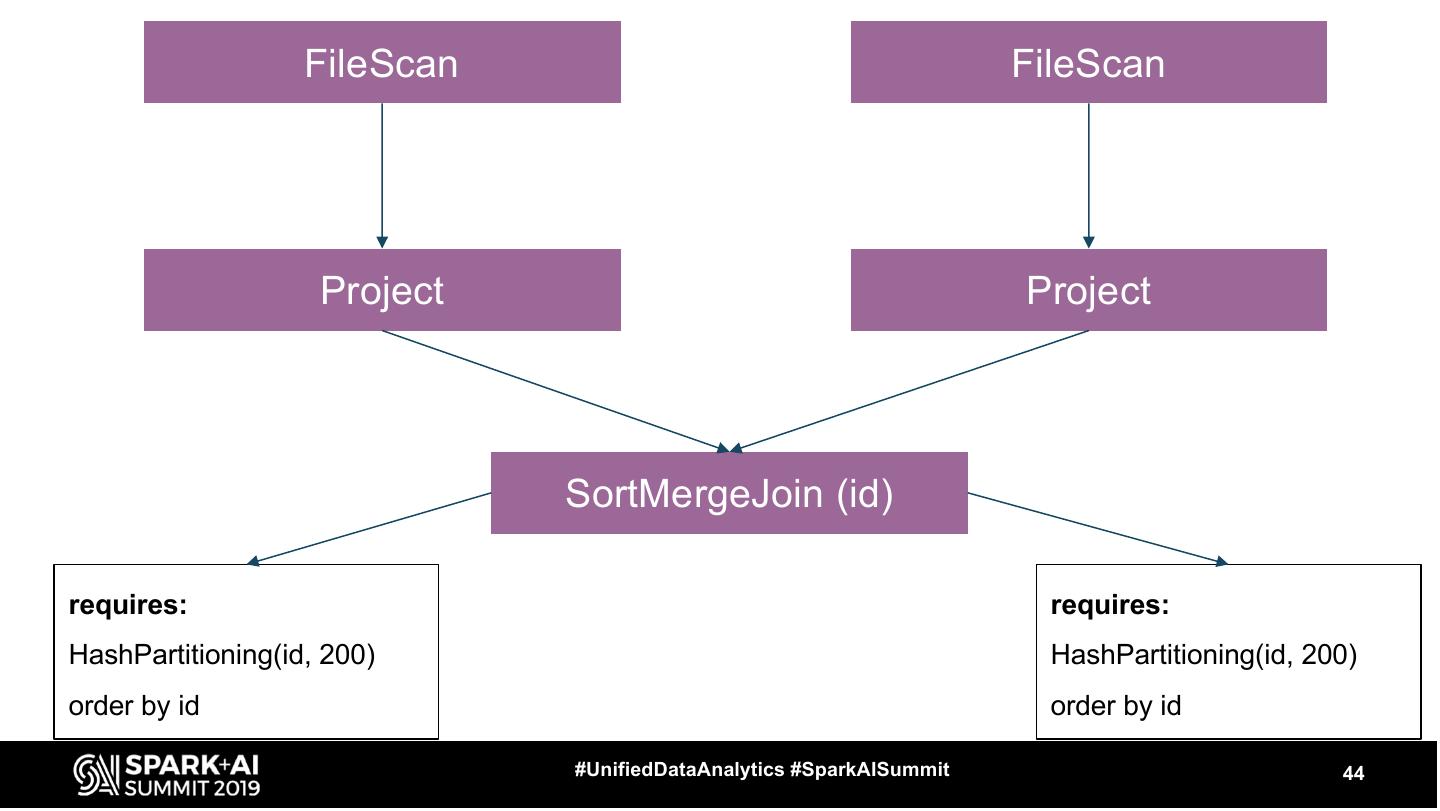
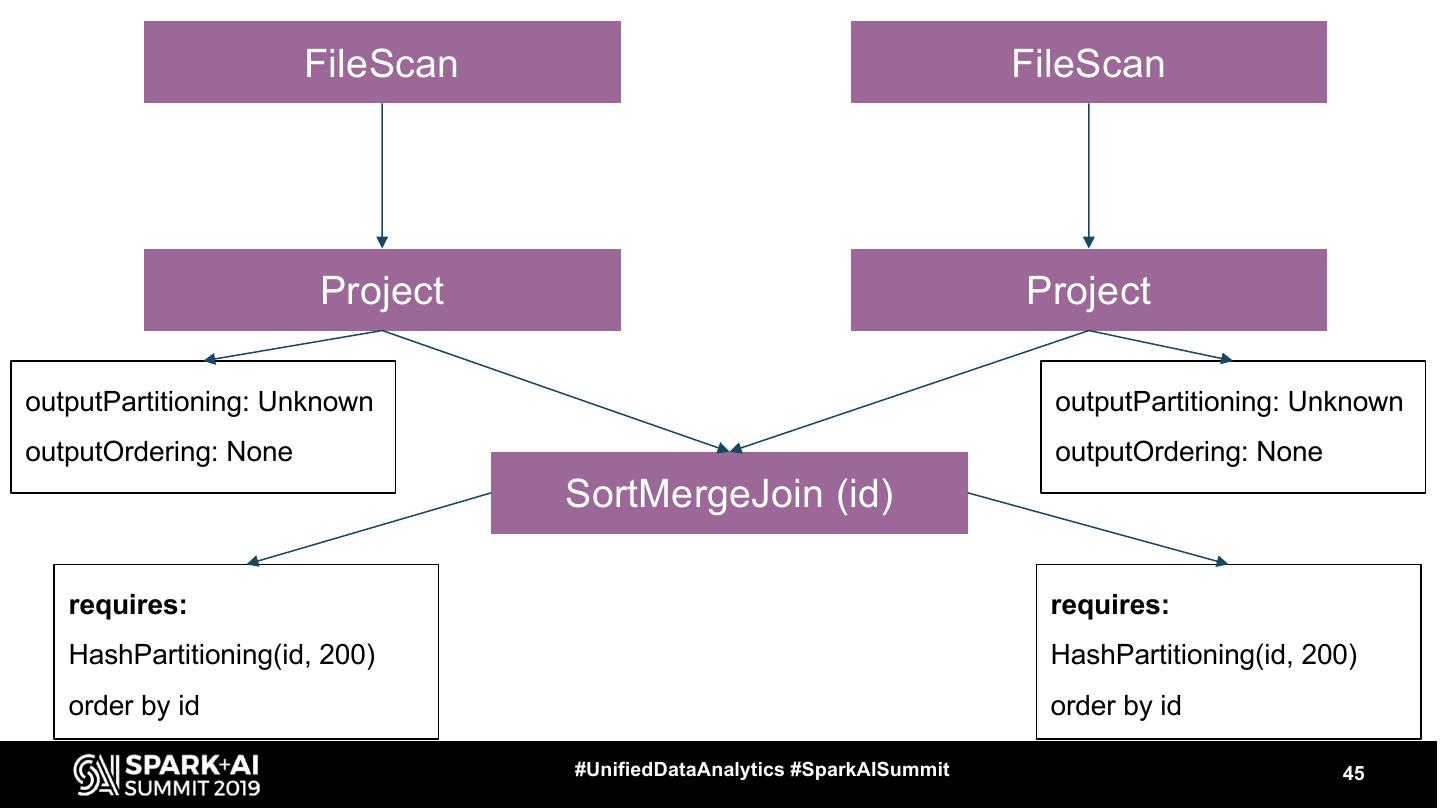
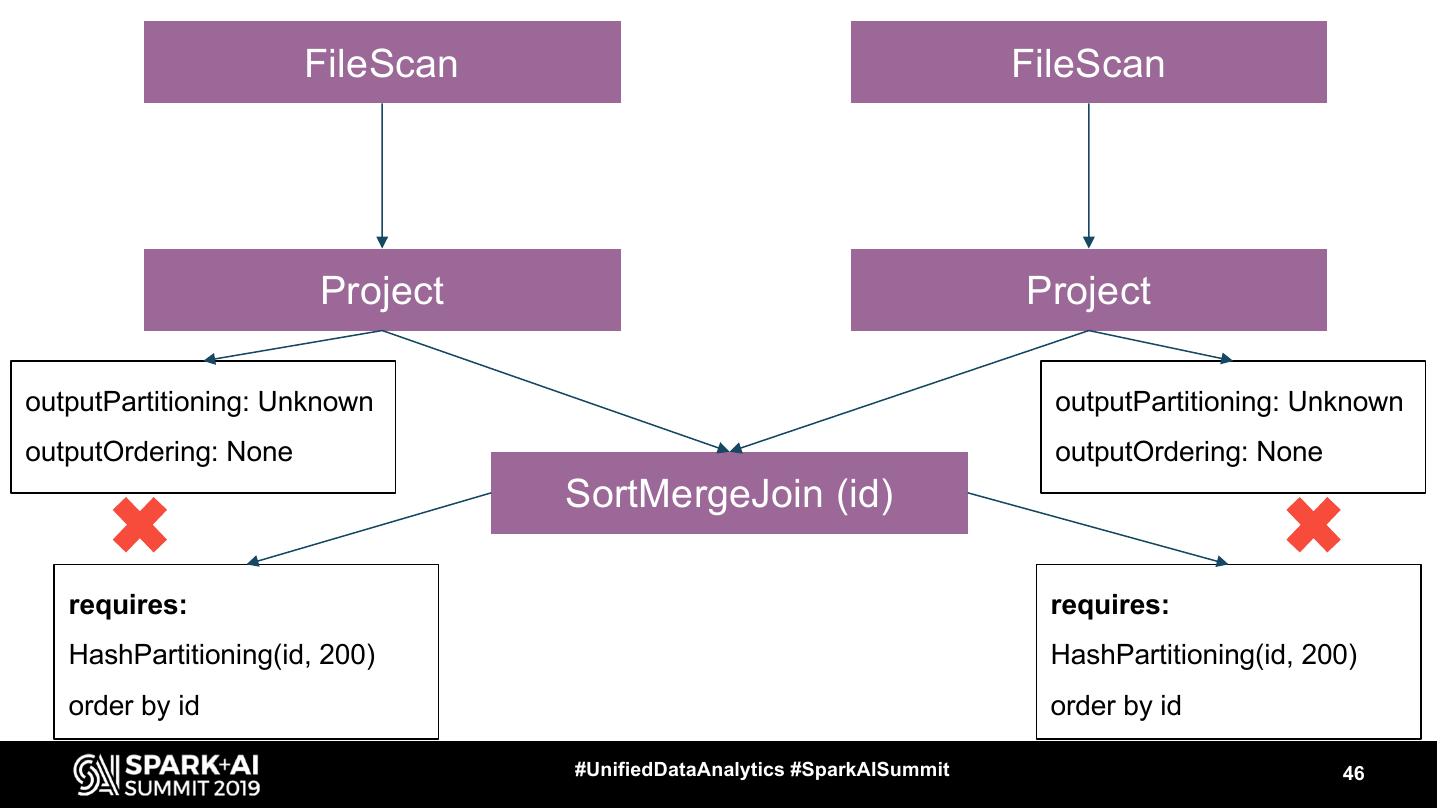
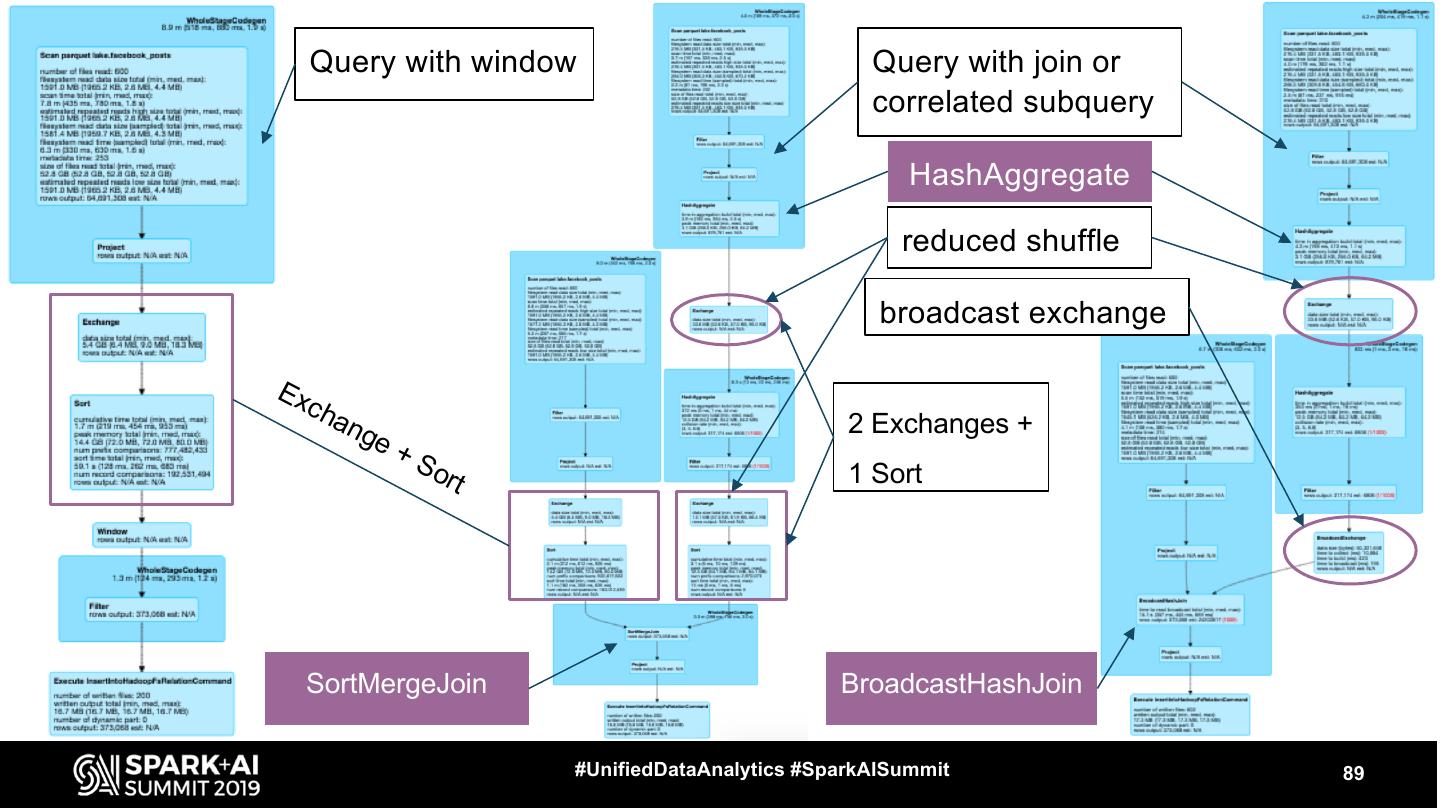
17 .Let’s see some operators ● FileScan ● Exchange ● HashAggregate, SortAggregate, ObjectHashAggregate ● SortMergeJoin ● BroadcastHashJoin #UnifiedDataAnalytics #SparkAISummit 17
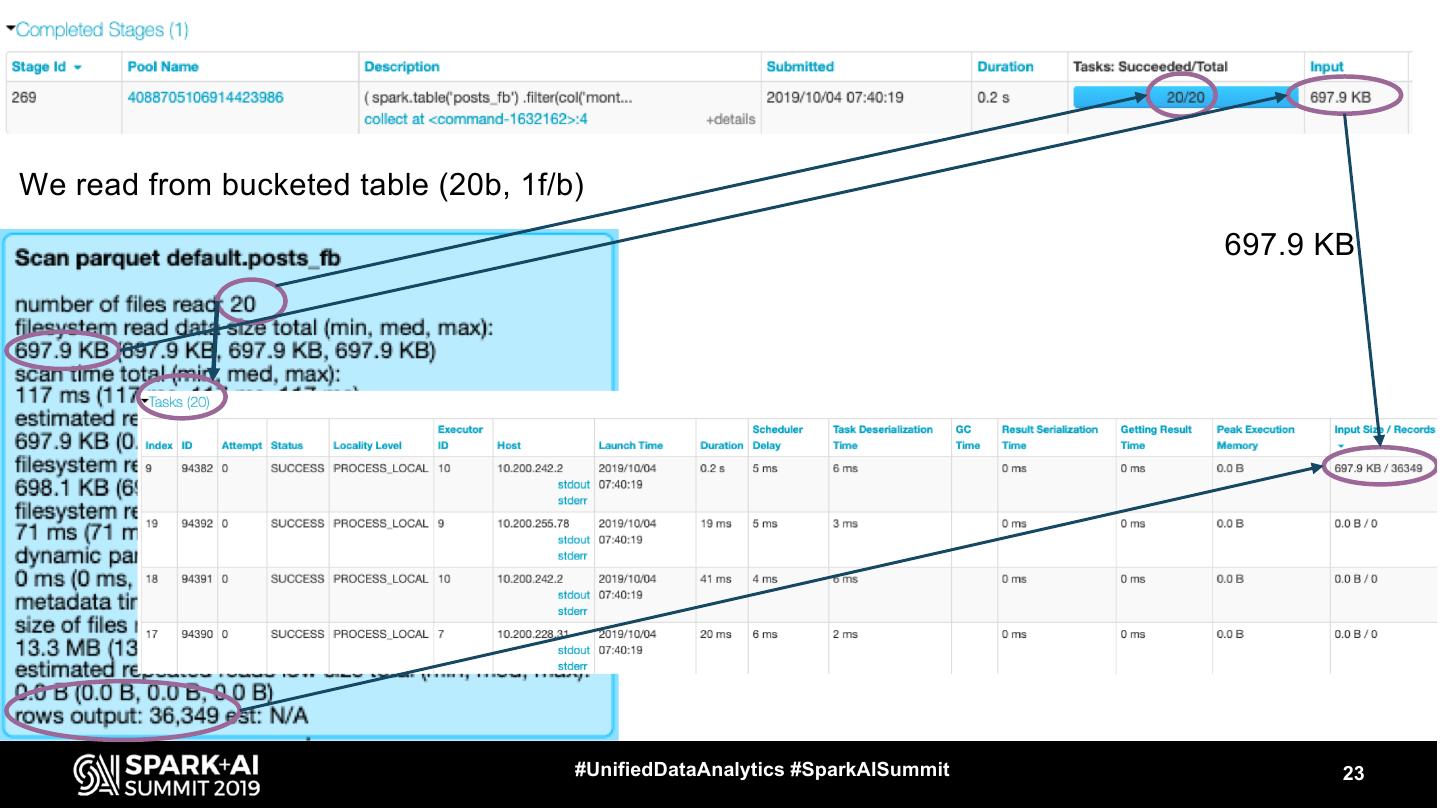
18 .FileScan ● Represents reading the data from a file format ● table: posts_fb spark.table(“posts_fb”) ● partitioned by month .filter($“month” === 5) ● bucketed by profile_id, 20b .filter($”profile_id” === ...) ● 1 file per bucket #UnifiedDataAnalytics #SparkAISummit 18
19 .FileScan number of files read filesystem read data size total size of files read total rows output #UnifiedDataAnalytics #SparkAISummit 19
20 .FileScan It is useful to pair these numbers with information in Jobs and Stages tab in Spark UI #UnifiedDataAnalytics #SparkAISummit 20
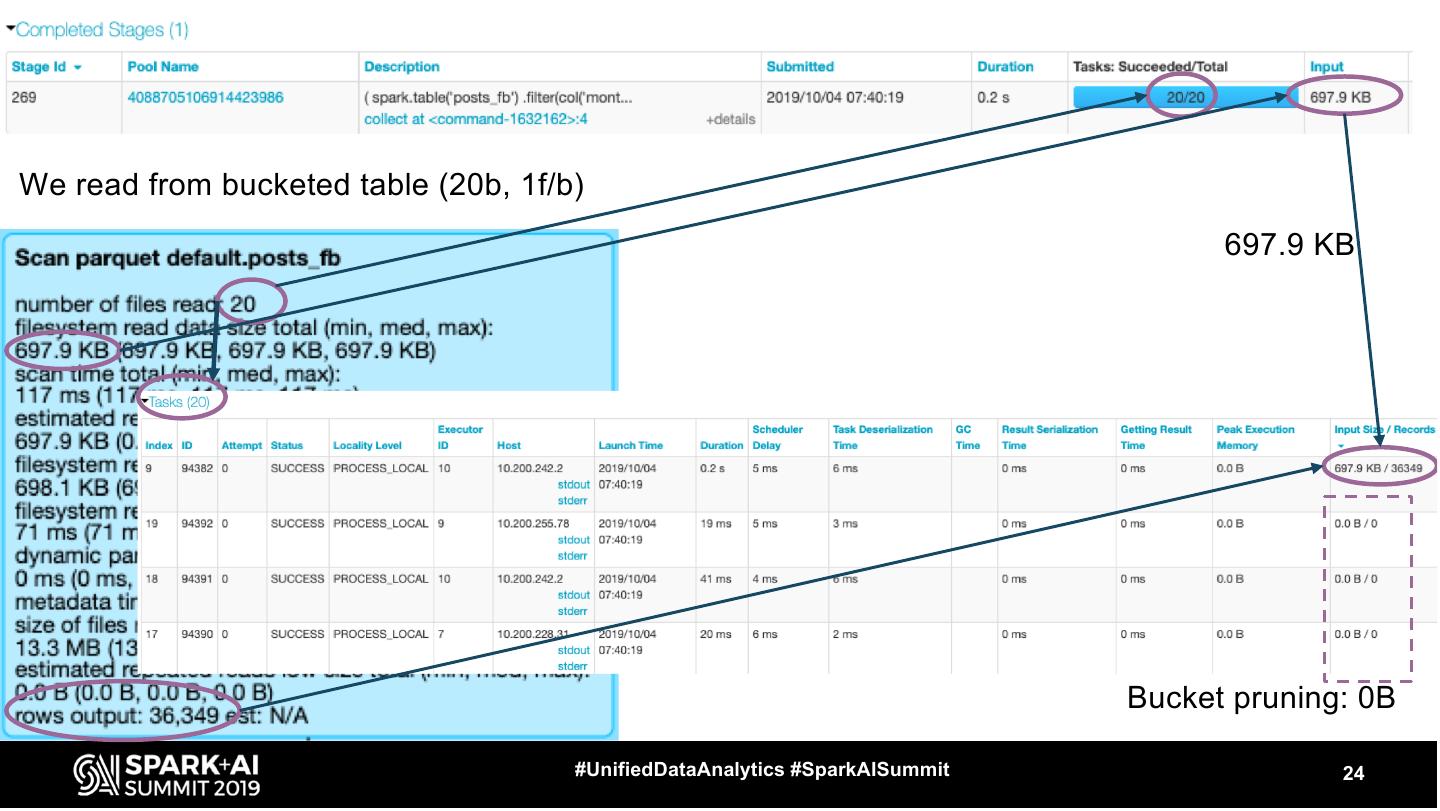
21 .We read from bucketed table (20b, 1f/b) #UnifiedDataAnalytics #SparkAISummit 21
22 .We read from bucketed table (20b, 1f/b) #UnifiedDataAnalytics #SparkAISummit 22
23 .We read from bucketed table (20b, 1f/b) 697.9 KB #UnifiedDataAnalytics #SparkAISummit 23
24 .We read from bucketed table (20b, 1f/b) 697.9 KB Bucket pruning: 0B #UnifiedDataAnalytics #SparkAISummit 24
25 .We read from bucketed table (20b, 1f/b) 697.9 KB spark.sql.sources.bucketing.enabled Bucket pruning: 0B #UnifiedDataAnalytics #SparkAISummit 25
26 . If bucketing is OFF: We read from bucketed table (20b, 1f/b) Size of the whole partition. This will be read if we turn off bucketing (no bucket pruning) #UnifiedDataAnalytics #SparkAISummit 26
27 . FileScan (string representation) DataFilters PartitionFilters PushedFilters #UnifiedDataAnalytics #SparkAISummit 27
28 . FileScan (string representation) DataFilters Format PartitionFilters PushedFilters SelectedBucketsCount PartitionCount (bucket pruning) (partition pruning) #UnifiedDataAnalytics #SparkAISummit 28
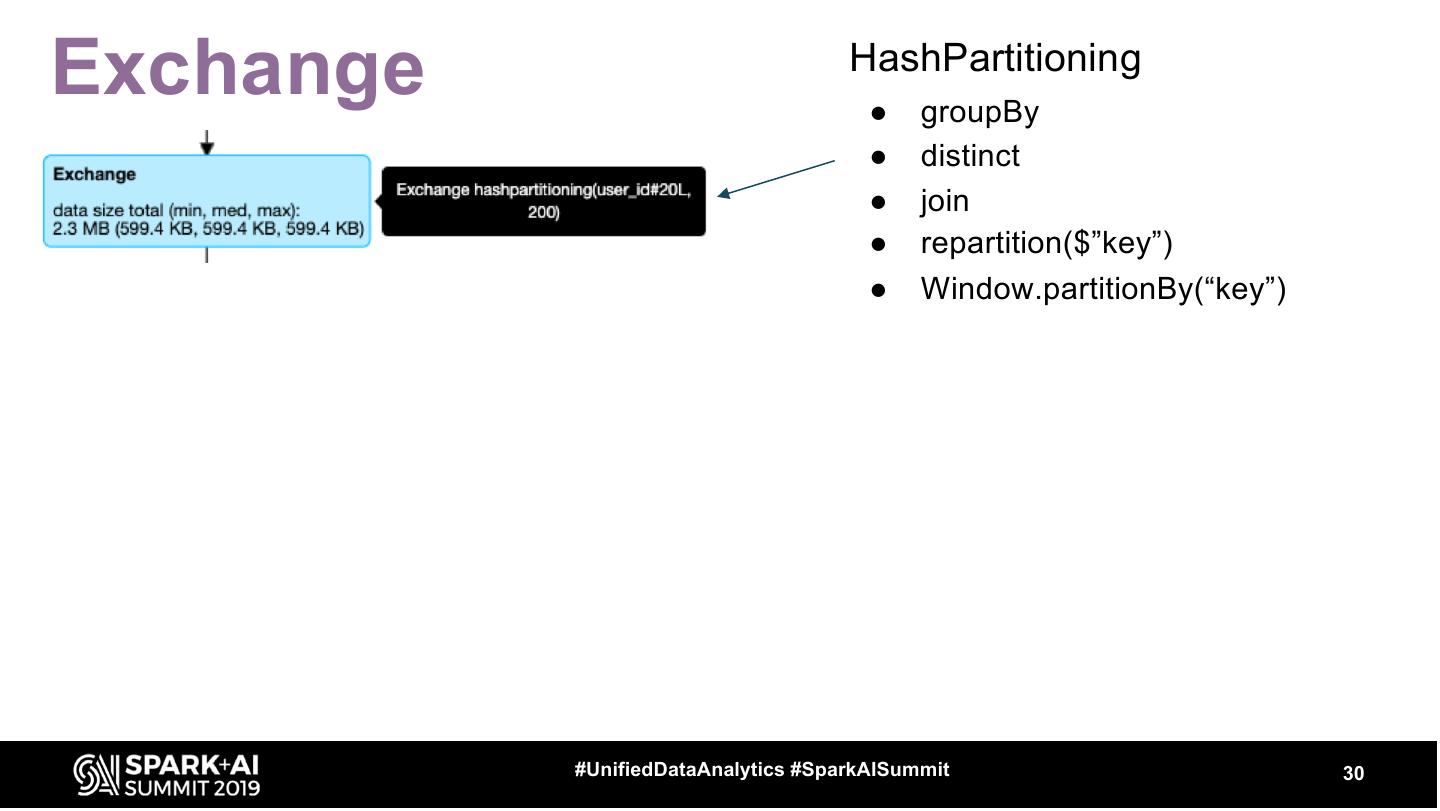
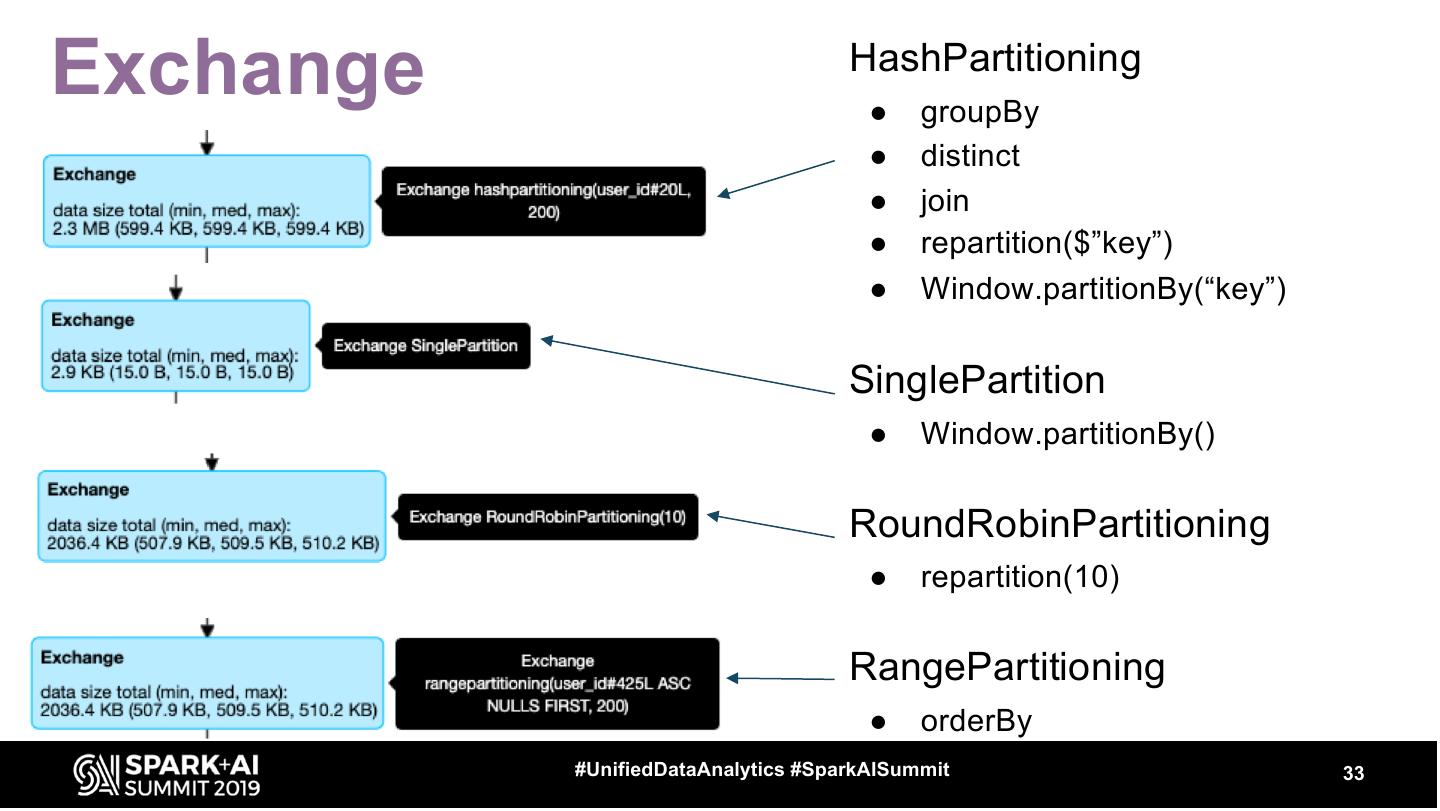
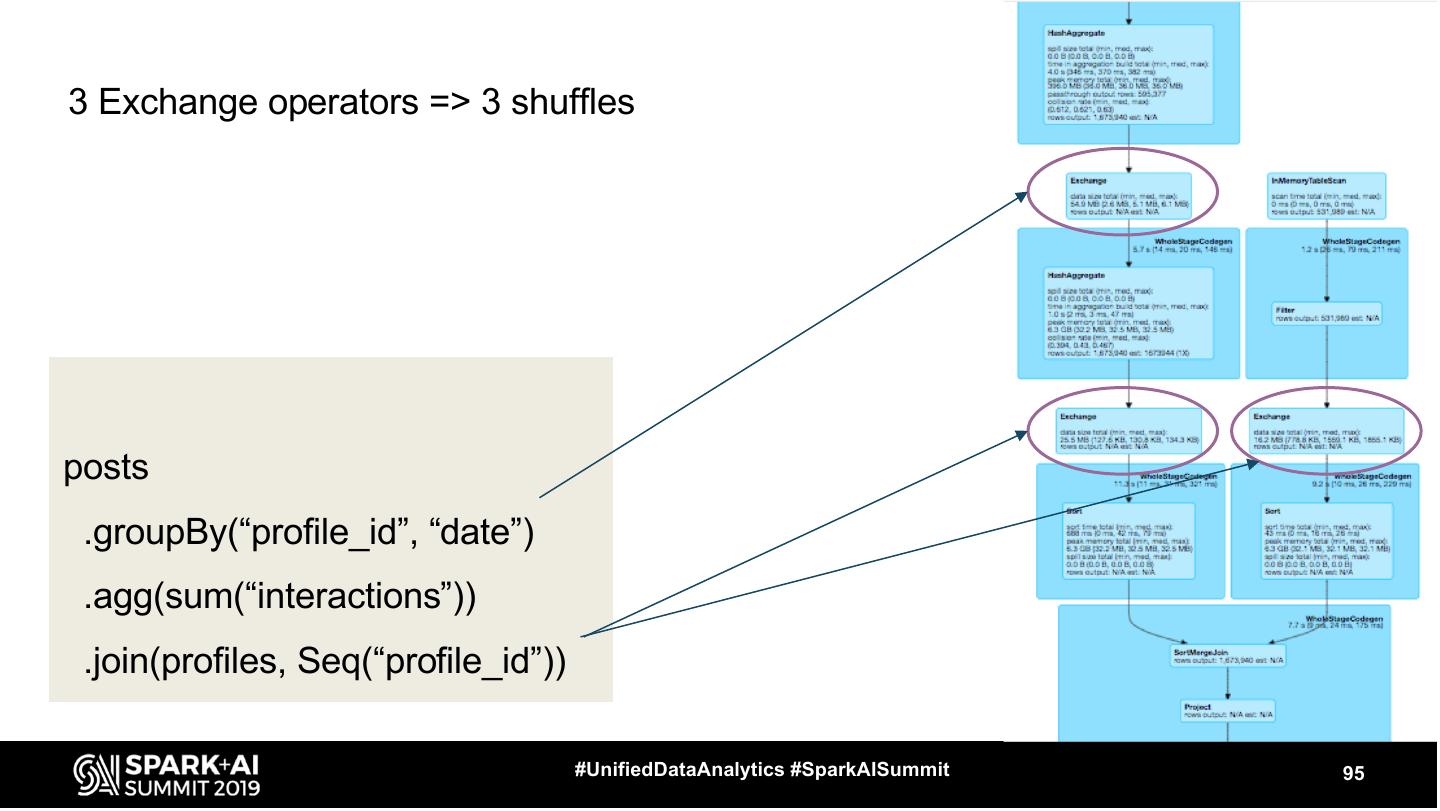
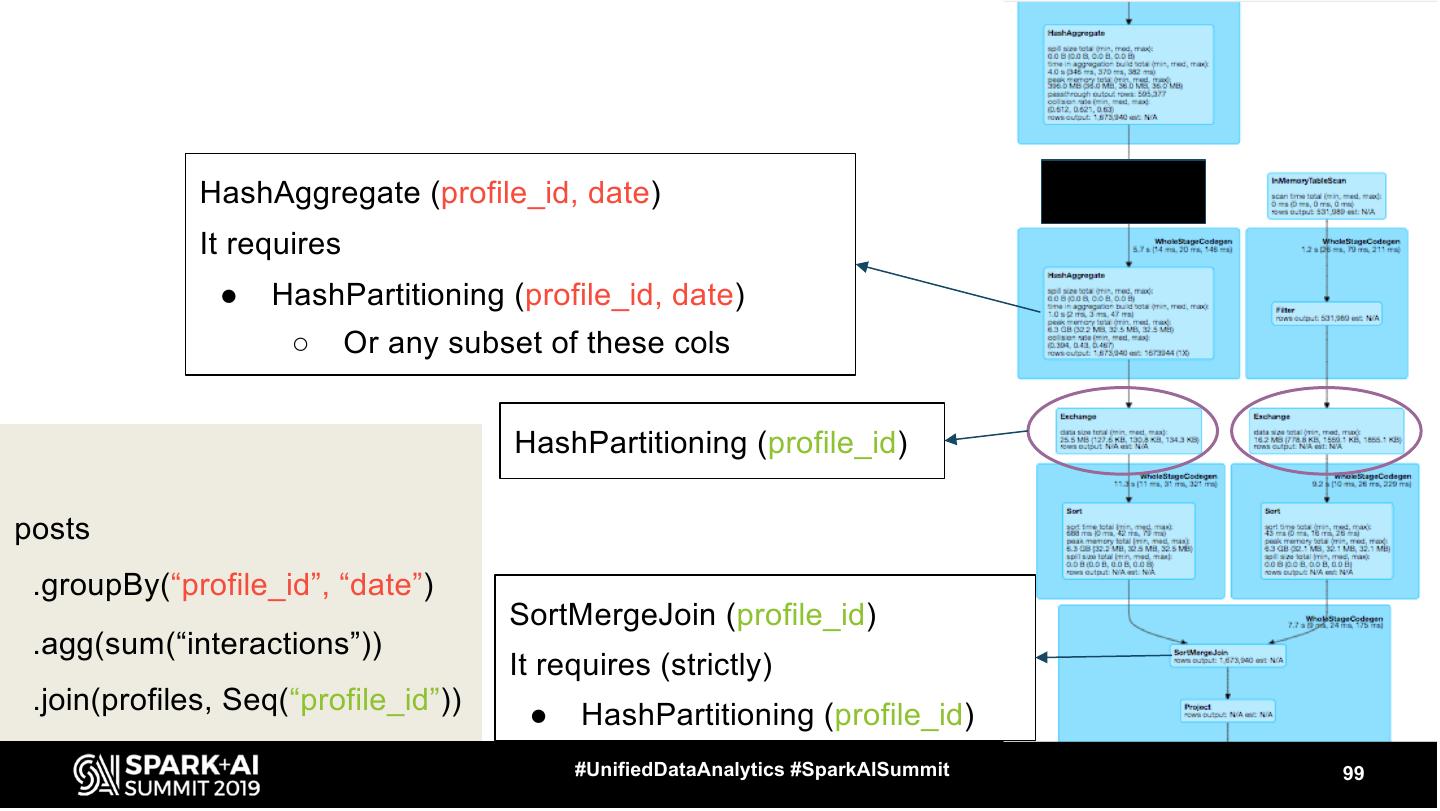
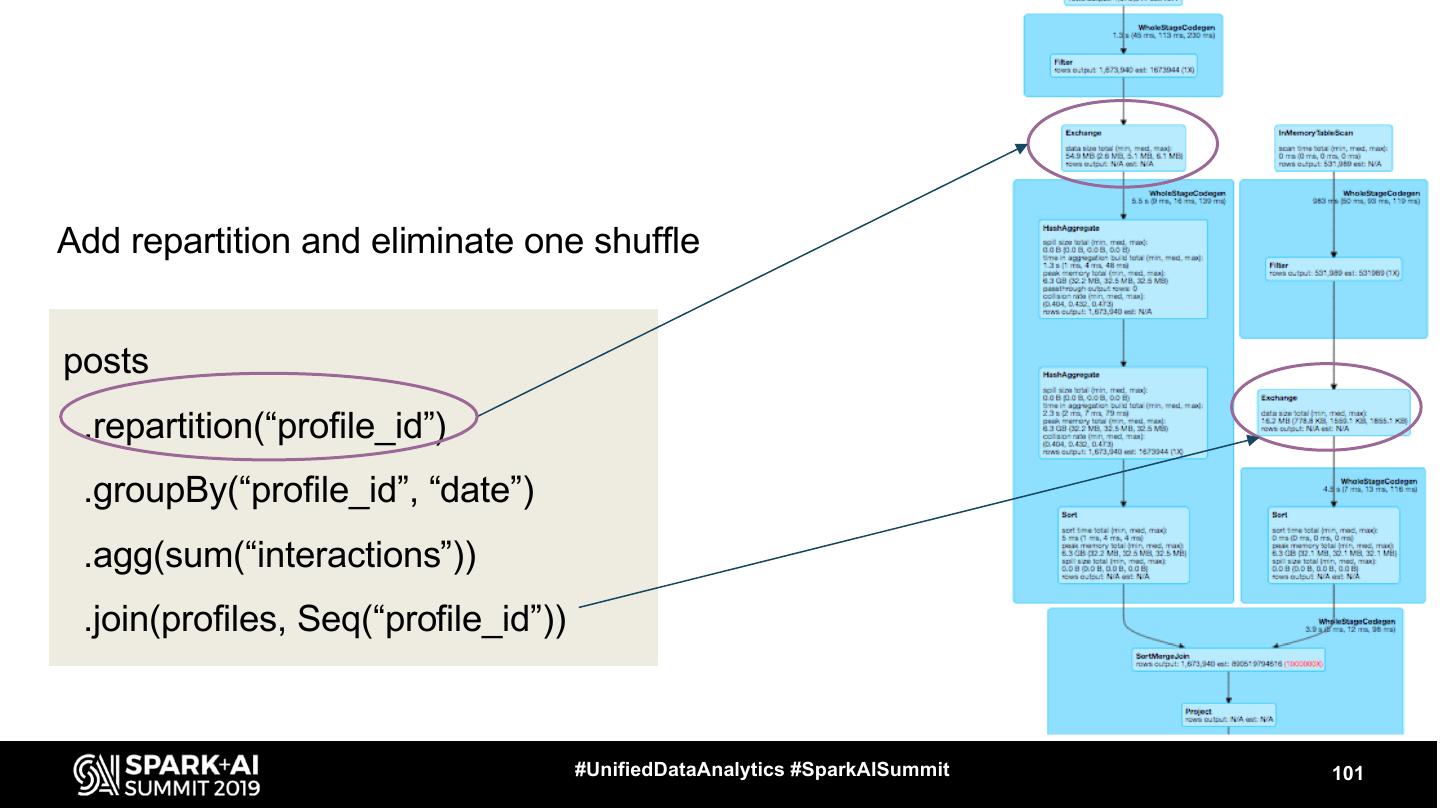
29 .Exchange ● Represents shuffle - physical data movement on the cluster ○ usually quite expensive #UnifiedDataAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

