Petabytes, Exabytes, and Beyond - Managing Delta Lakes for Inter
分享
点赞
6
收藏
2
下载 1
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
Data production continues to scale up and the techniques for managing it need to scale too. Building pipelines that can process petabytes per day in turn create data lakes with exabytes of historical data. At Databricks, we help our customers turn these data lakes into gold mines of valuable information using Apache Spark. This talk will cover techniques to optimize access to these data lakes using Delta Lakes, including range partitioning, file-based data skipping, multi-dimensional clustering, and read-optimized files. We’ll cover sample implementations and see examples of querying petabytes of data in seconds, not hours.
We’ll also discuss tradeoffs that data engineers deal with everyday like read speed vs. write throughput, managing storage costs, and duplicating data to support multiple query profiles. We’ll also discuss combining batch with streaming to achieve desired query performance. After this session, you will have new ideas for managing truly massive Delta Lakes.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Petabytes, Exabytes,
and Beyond
Managing Delta Lakes for
Interactive Queries at Scale
Chris Hoshino-Fish, Databricks
#UnifiedDataAnalytics #SparkAISummit
�
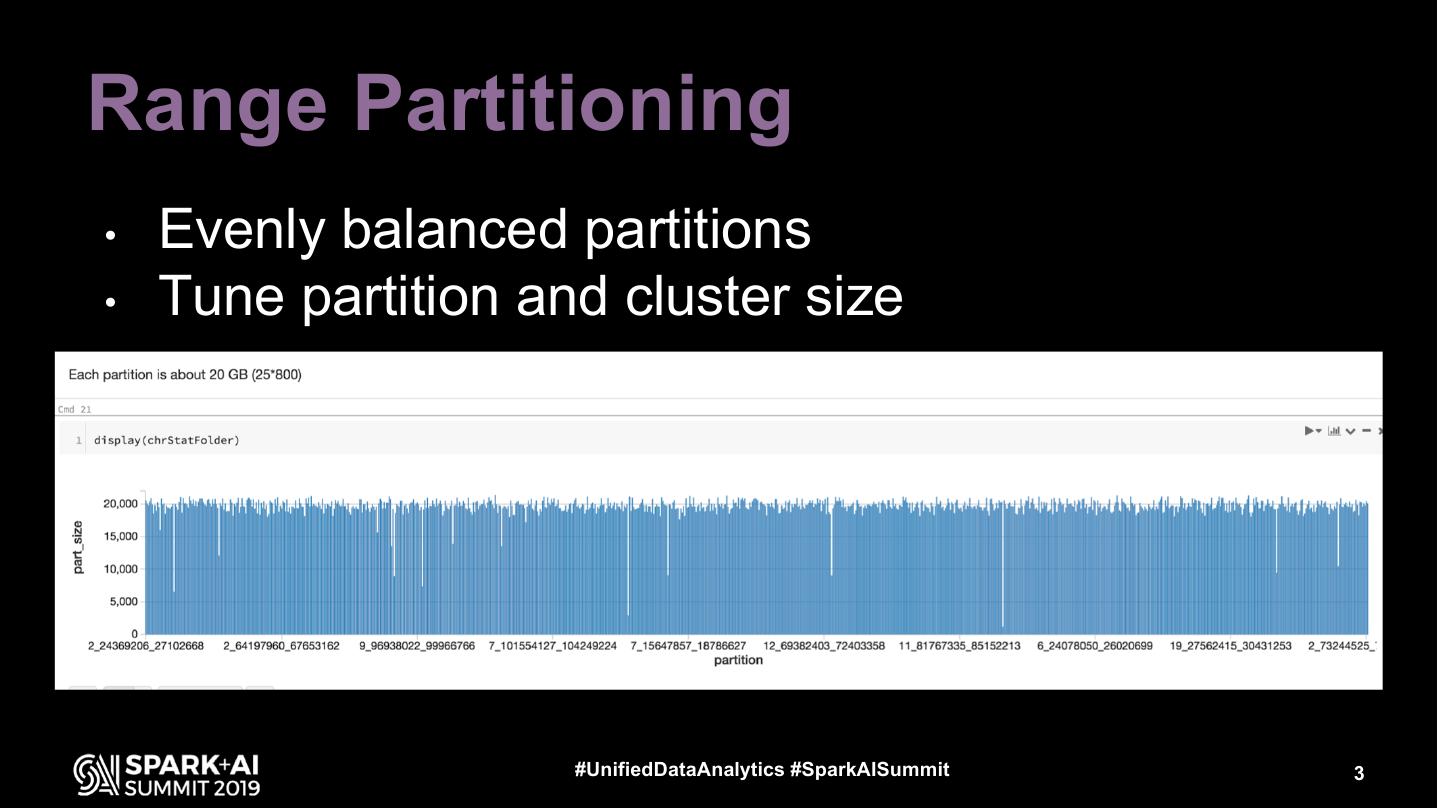
3 .Range Partitioning
• Evenly balanced partitions
• Tune partition and cluster size
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .ZOrder Indexing
• Multidimensional
clustering
• Maps multiple
columns to 1-
dimensional binary
space
• Effectiveness falls off
after 3-5 columns
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Dataskipping
• Collects metadata
about files
• Uses metadata to
improve query plans
• Combined with
ZOrder, can reduce
data needed to read
by 90% or more
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Tuning File Size
• Smaller files - dataskipping can be more
effective
• Write/Read cost - performance and $
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Multiple Query Profiles
• Assess common query patterns
• Understand end-users’ needs
• If possible, map secondary queries to use
primary index
• Create second table with different ZOrder
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Write Throughput vs. Query Speed
• More frequent writes -> new data is
unoptimized
• Tradeoff performance for recency
• ZOrder is incremental - only creates new ZCube
after threshold of new data
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Streaming vs. Batch
• Streaming has incremental processing and
reduces compute load, improves stability, and
can reduce latency
• RocksDB StateStore to scale up state
management
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�