




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

On-Prem Solution for the Selection of Wind Energy Models
On-Prem Solution for the Selection of Wind Energy Models
On-Prem Solution for the Selection of Wind Energy Models
The renewable energy industry has only recently started to rely on data-driven models on applications that have traditionally required complex physical solutions. In this talk, we would like to show how we leverage Spark, Keras and (in our case, on-prem) high performance computing (HPC) infrastructure to potentially tackle common and interesting problems in the wind-related industry (saving hours of CPU-consuming simulations).
We use:
Apache Spark and Hive for data preparation and a combination of different data sources (some of them in the range of the petabytes scale).
Keras for model training/generation.
HPC for coordination and node-wide training of hyperparameters.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .On-Prem Solution for the Selection of Wind Energy Models Ana M. Martinez, Vestas Wind Systems A/S #UnifiedDataAnalytics #SparkAISummit
3 .Is this a good piece of art? pixabay.com Classification: Public 3
4 .Is this a good piece of art? pixabay.com Classification: Public 4
5 .Is this a good site? Classification: Public 5
6 .Is this a good site? Classification: Public 6
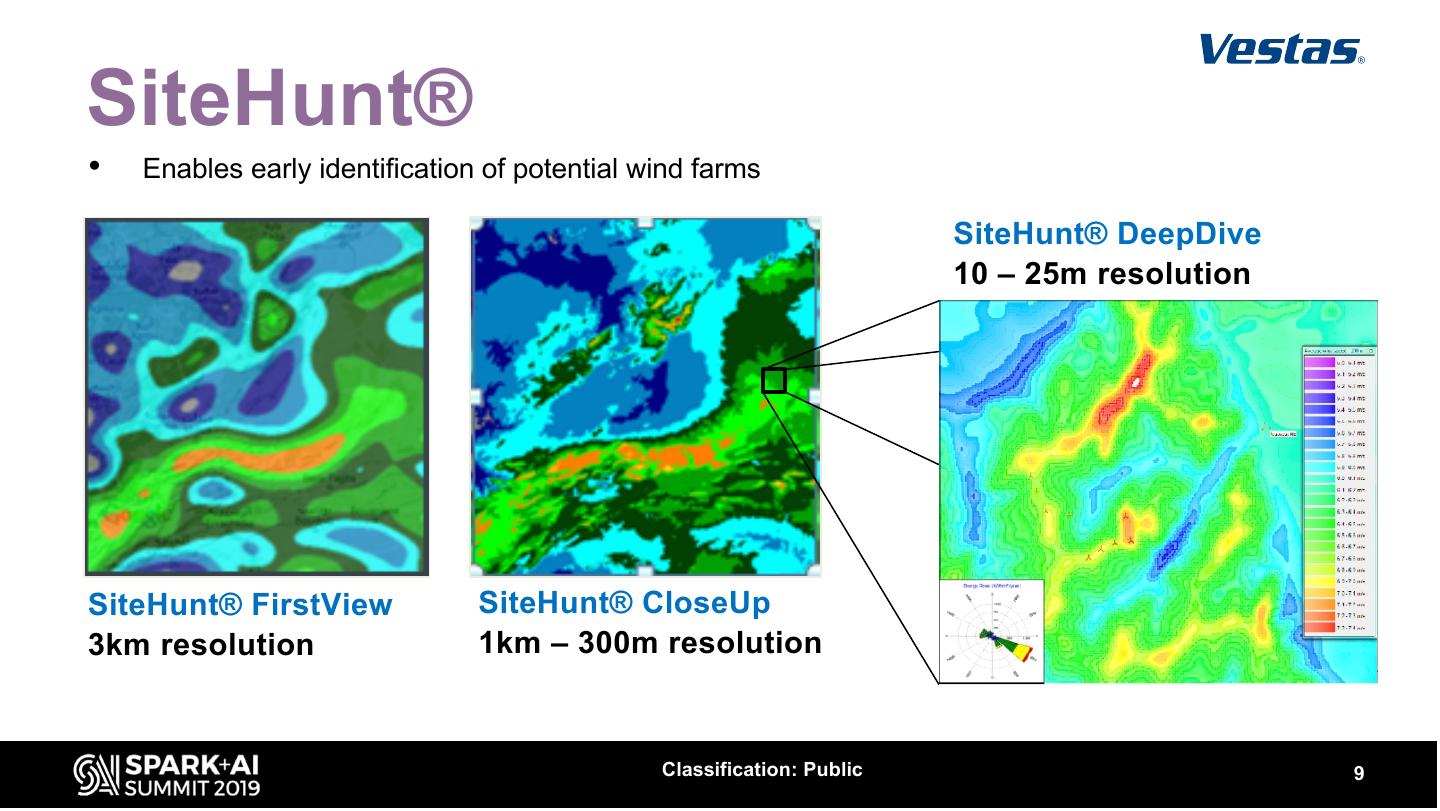
7 .SiteHunt® • Enables early identification of potential wind farms SiteHunt® FirstView 3km resolution Classification: Public 7
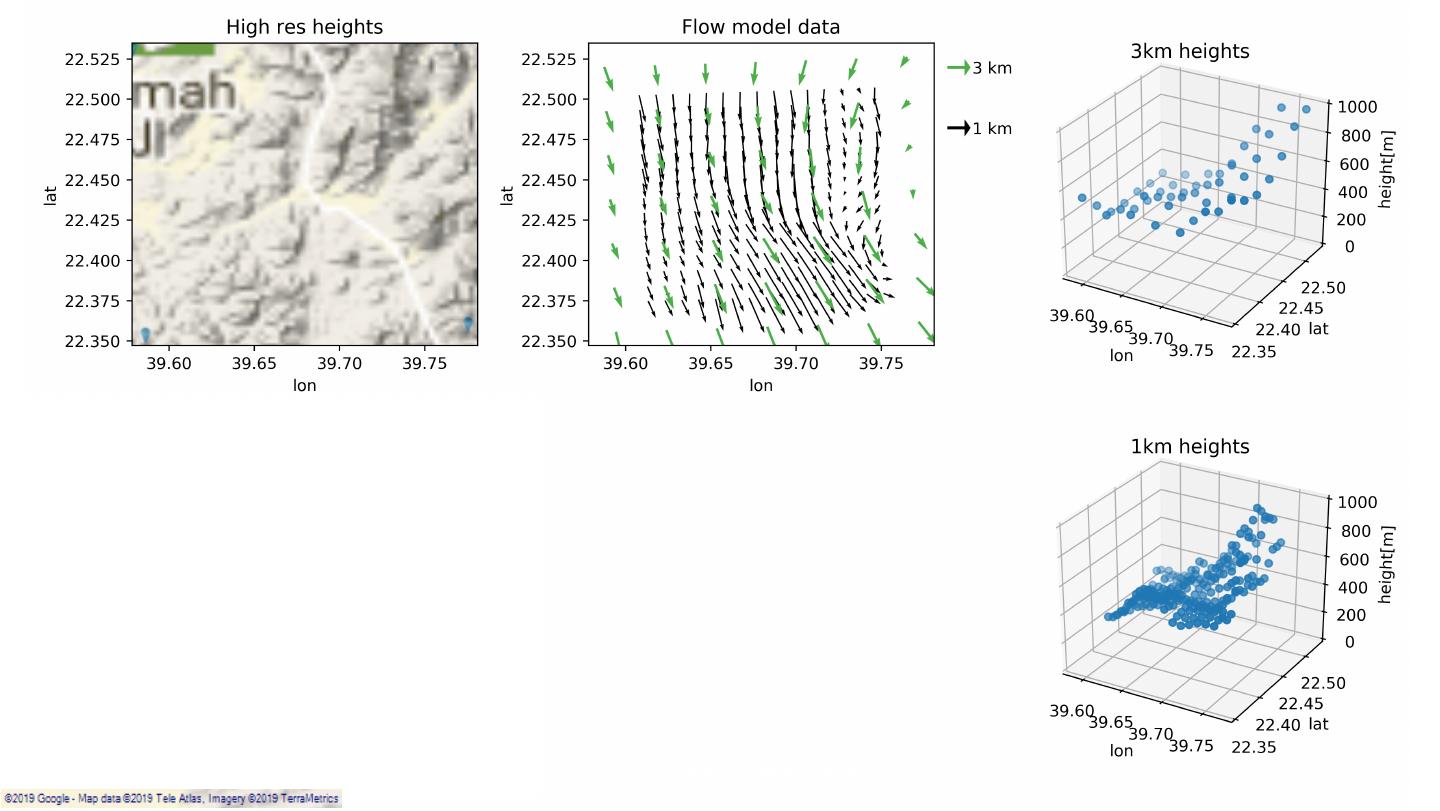
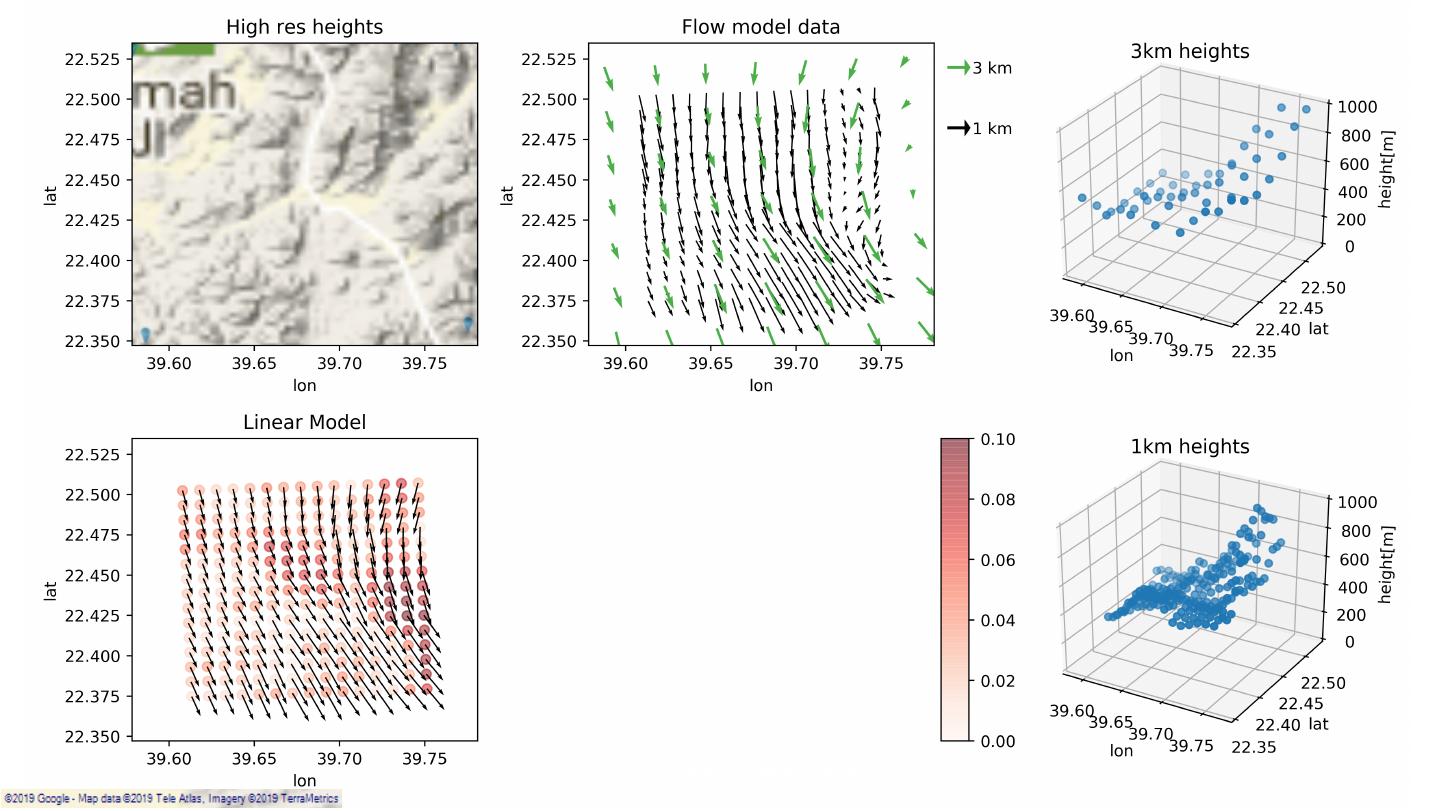
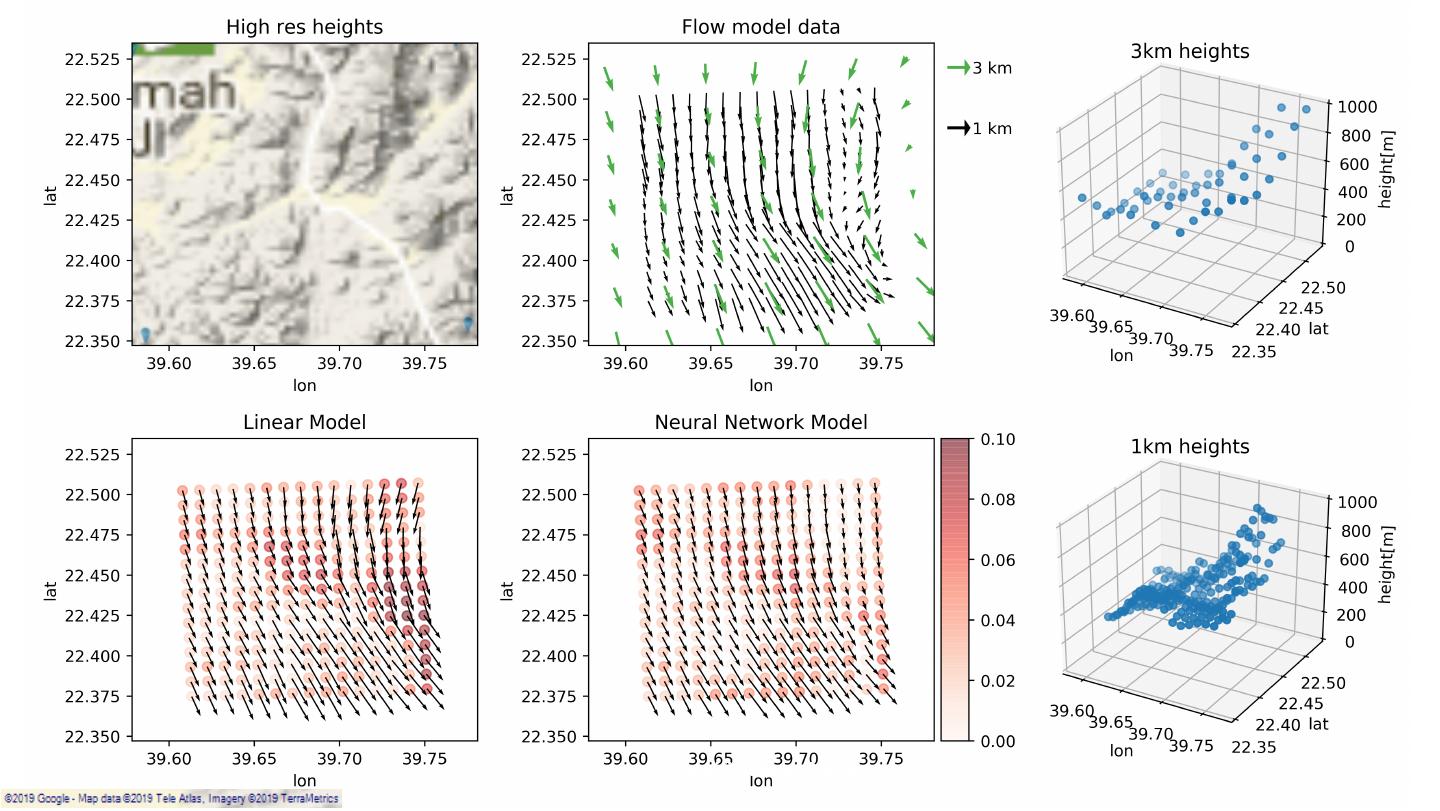
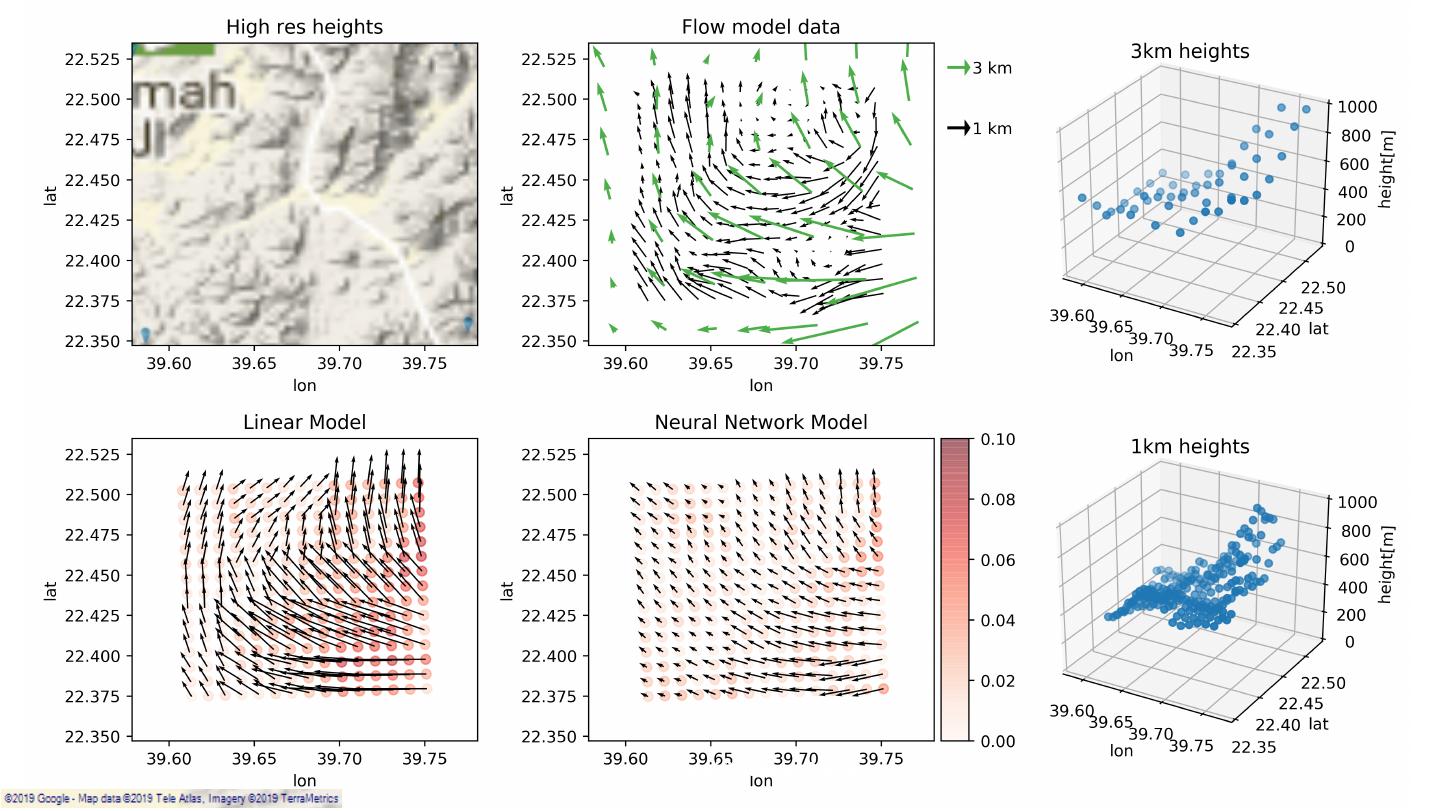
8 .SiteHunt® • Enables early identification of potential wind farms SiteHunt® FirstView SiteHunt® CloseUp 3km resolution 1km – 300m resolution Classification: Public 8
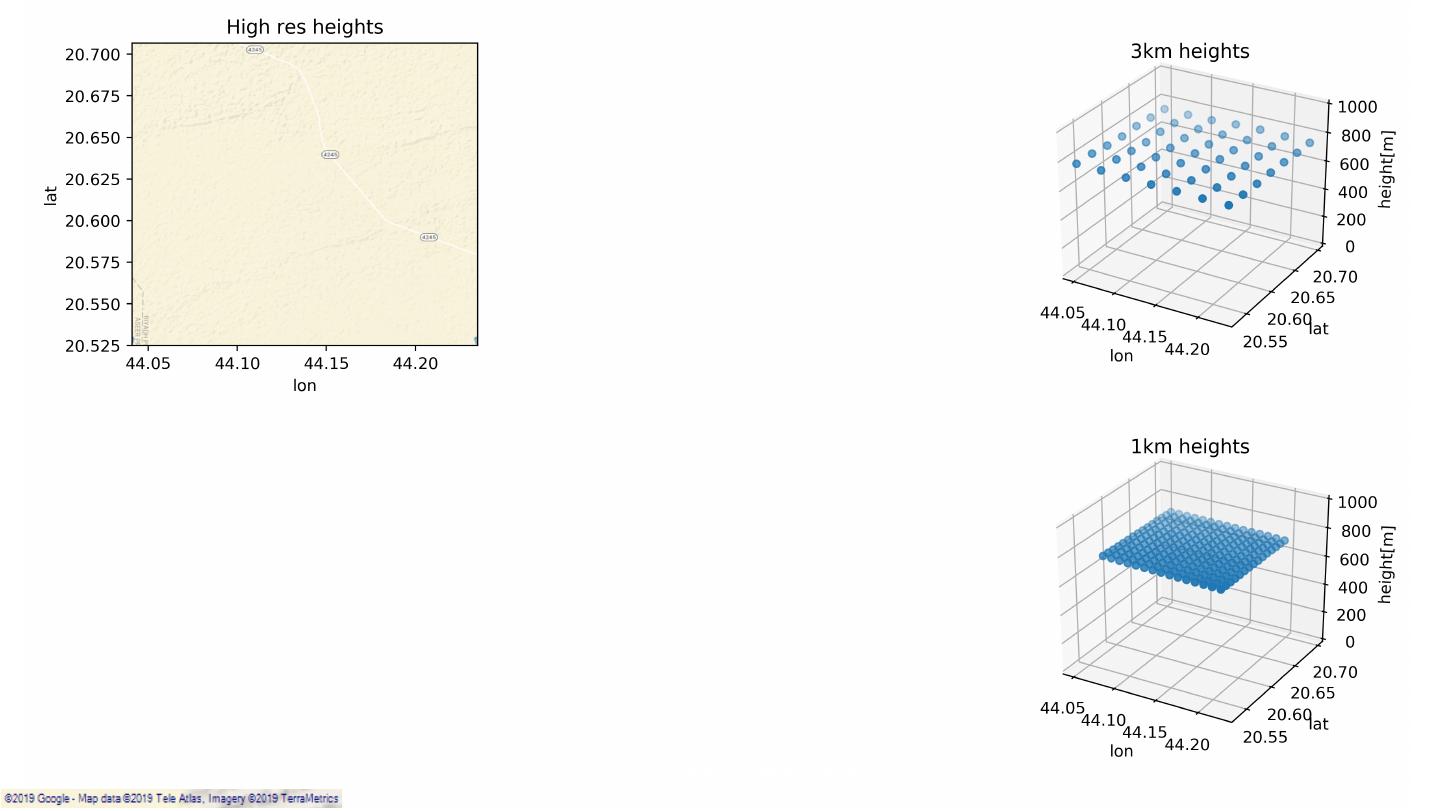
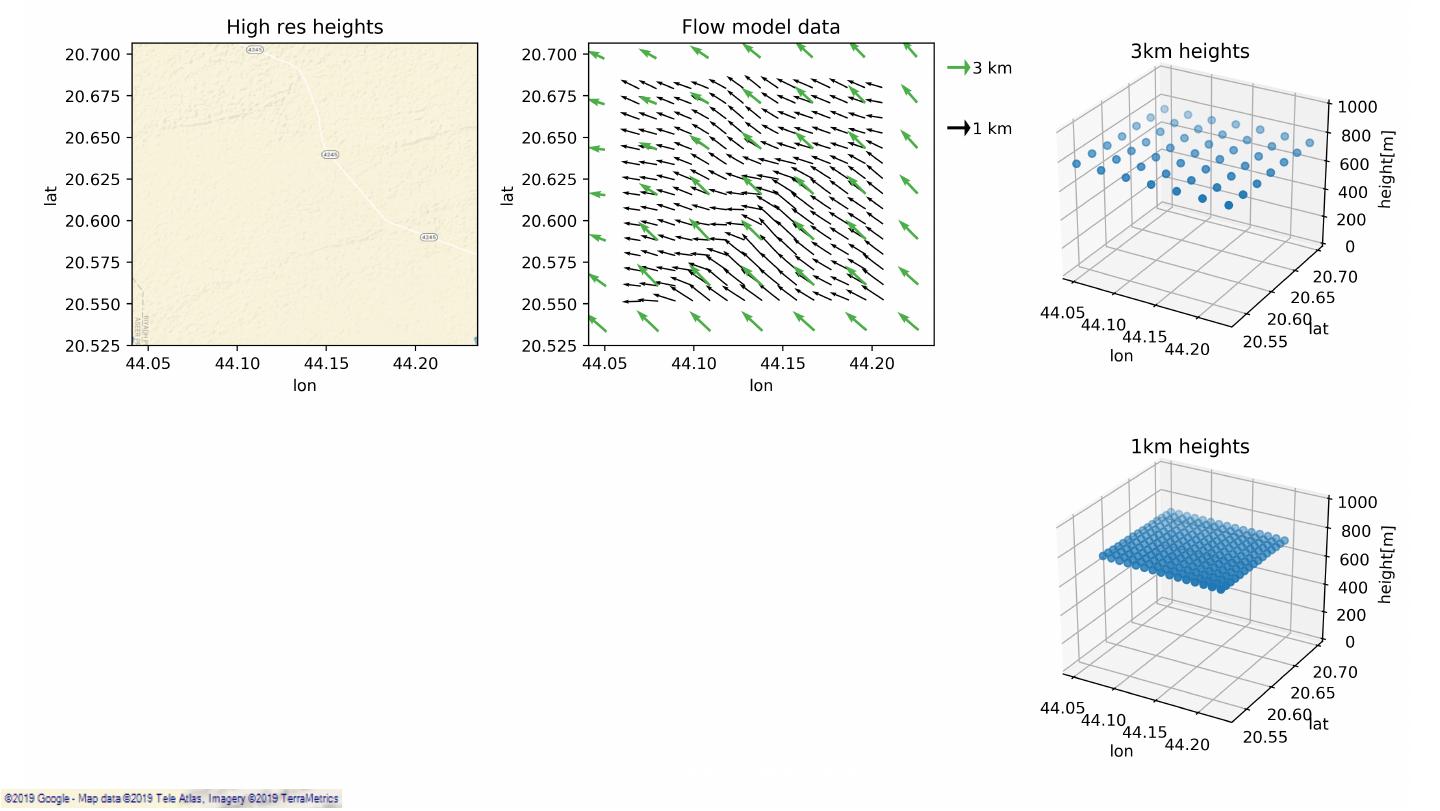
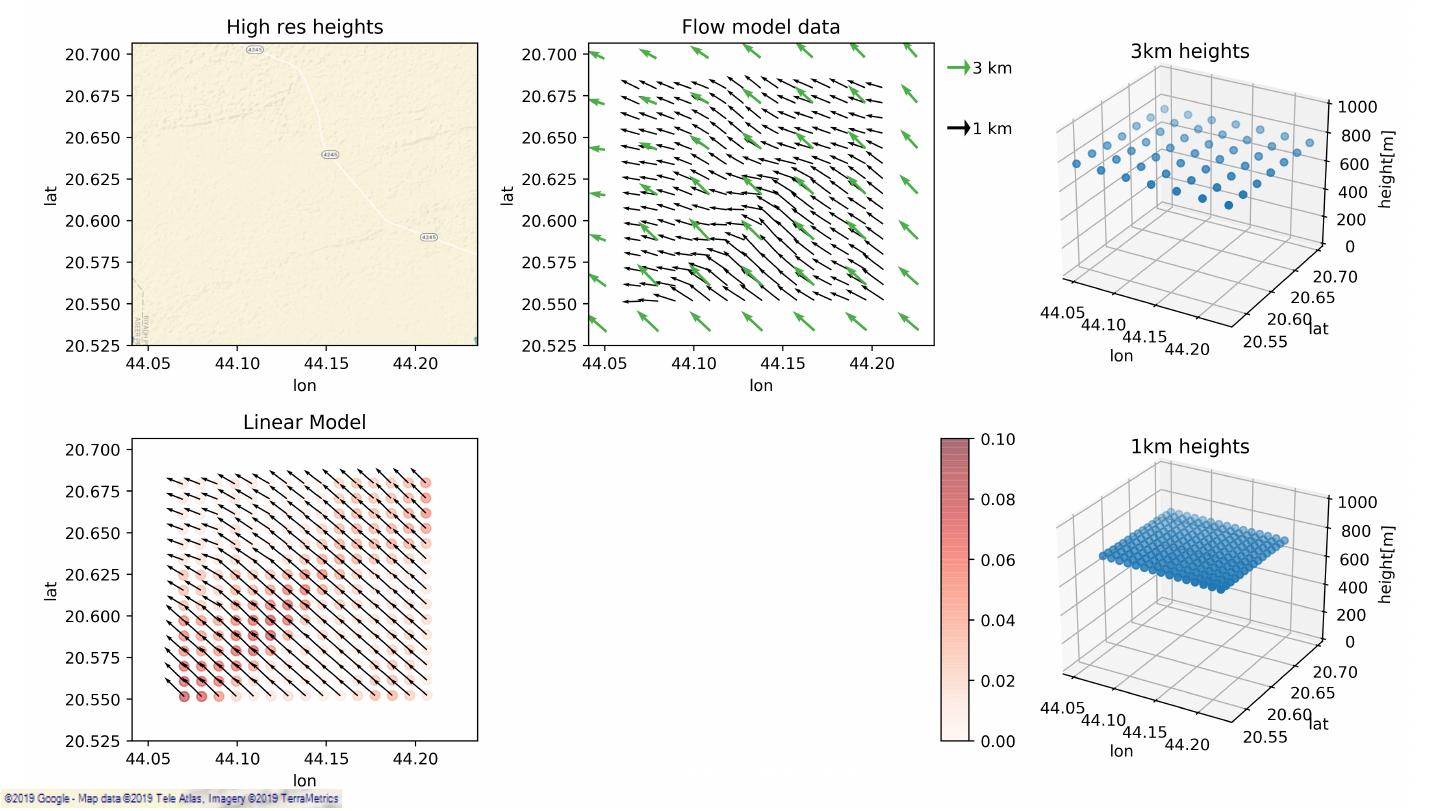
9 .SiteHunt® • Enables early identification of potential wind farms SiteHunt® DeepDive 10 – 25m resolution SiteHunt® FirstView SiteHunt® CloseUp 3km resolution 1km – 300m resolution Classification: Public 9
10 .Wind resources enrichment Existing modelling options: – Physical modelling leads to time-consuming simulations. – Sub-optimal geostatistical approaches. Classification: Public 10
11 .Motivation • DL technology has been recently proved successful on similar tasks with data that has hierarchical structure. • What tools and data do we have at Vestas for this task? • What is missing? Classification: Public 11
12 .HPC is our primary tool • 650 compute nodes (Lenovo). • ~ 16000 CPU cores. • Total memory > 100 TB. • >5 PB HDD storage (EMC Isilon). • 56Gb/s IB. • ~500 TFLOPS. • 20 GPU nodes. • Sun Grid Engine scheduler. 12 Classification: Public
13 .Data is our spine • Vestas Climate Library (peta-byte scale). – Hourly wind resource data from 2000-01-01 to present in 3km horizontal resolution. – More than 50 parameters. – From ground level to beyond 500m. – ORC database, started in 2012. • Elevation database. • Roughness database. Classification: Public 13
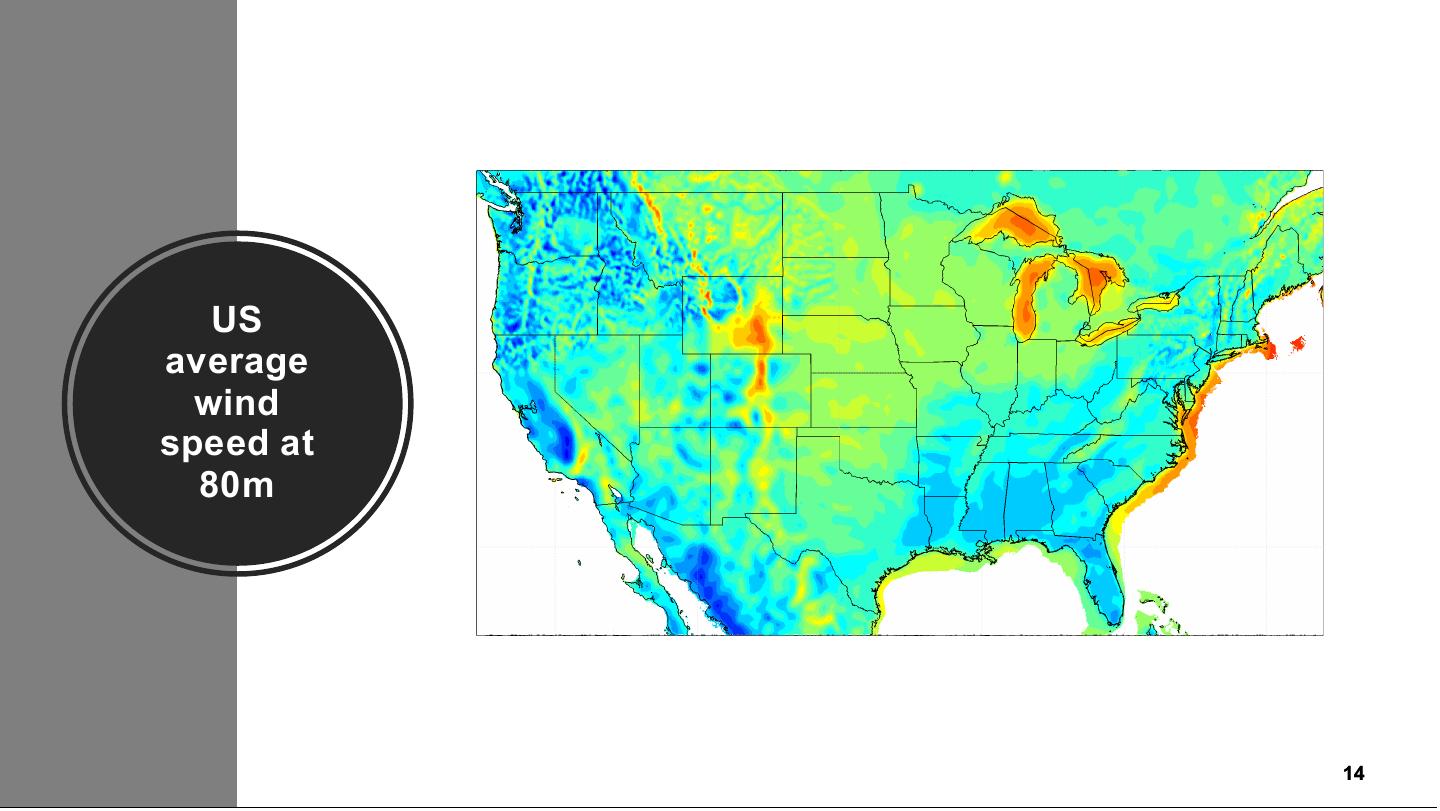
14 . US average wind speed at 80m Classification: Public 14
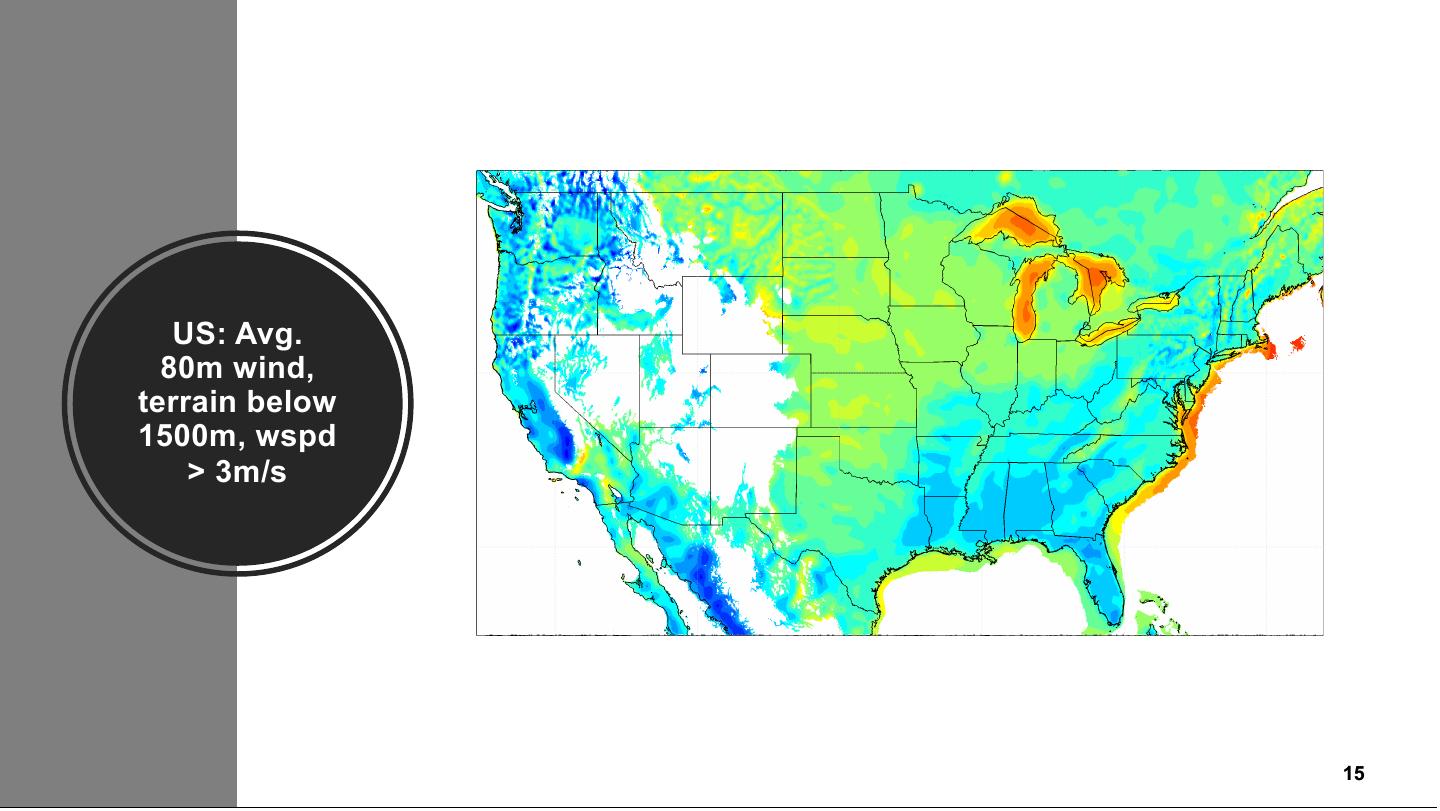
15 . US: Avg. 80m wind, terrain below 1500m, wspd > 3m/s Classification: Public 15
16 . US: Exclude National Parks, protected areas, national forests and federal land Classification: Public 16
17 .US: Remove urban areas and airports Classification: Public 17
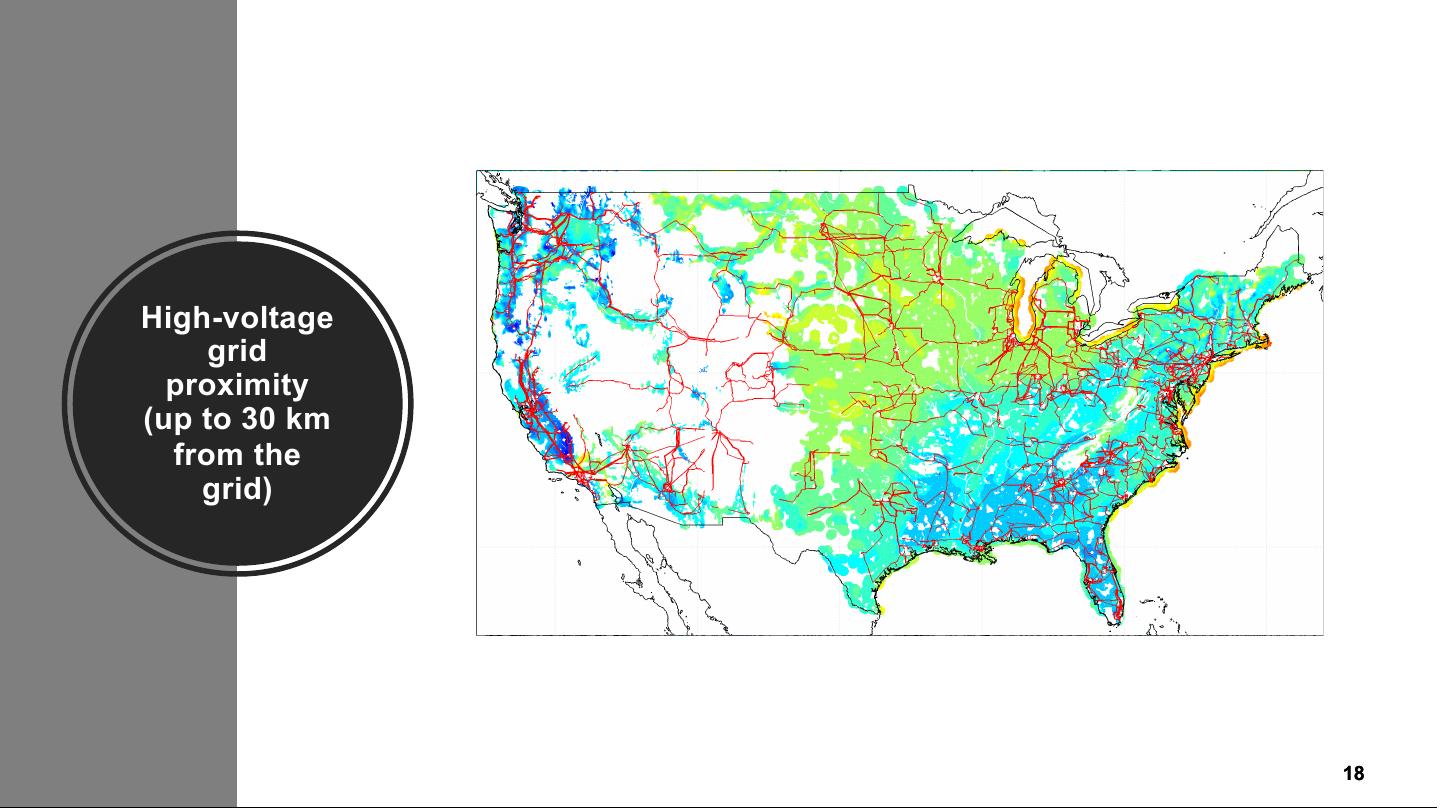
18 .High-voltage grid proximity (up to 30 km from the grid) Classification: Public 18
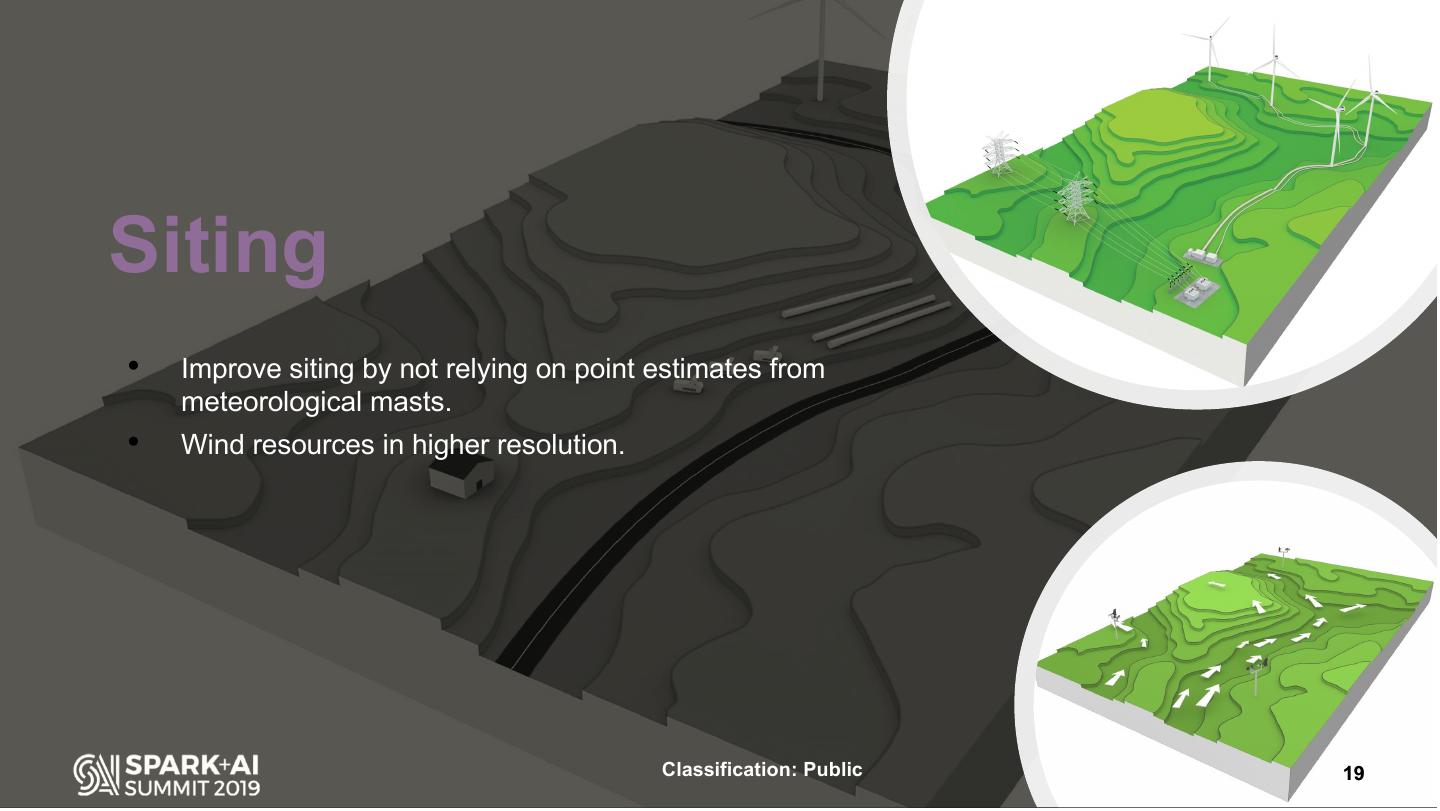
19 .Siting • Improve siting by not relying on point estimates from meteorological masts. • Wind resources in higher resolution. Classification: Public 19
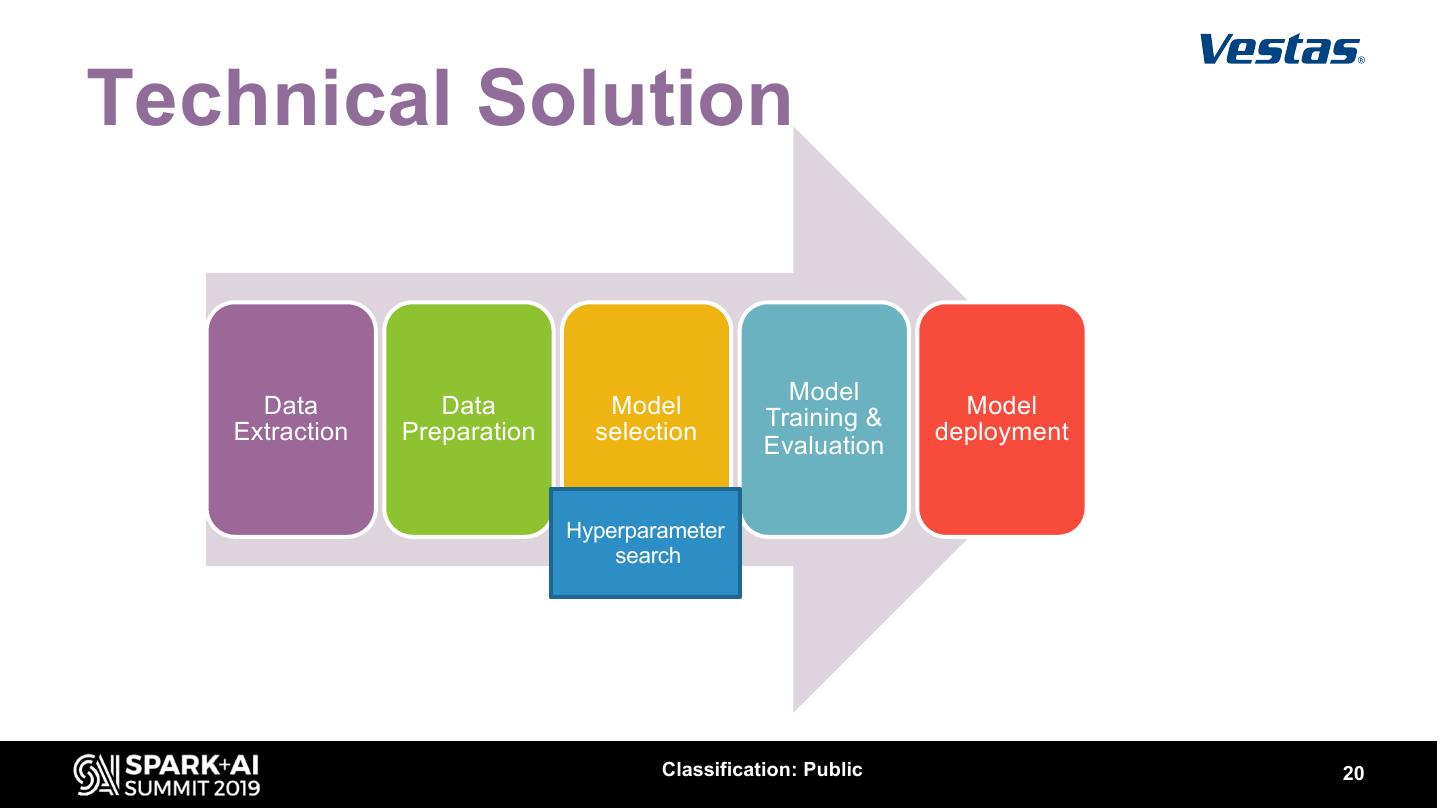
20 .Technical Solution Model Data Data Model Training & Model Extraction Data Preparation selection deployment Evaluation Preparation Hyperparameter search Classification: Public 20
21 .PoC Example Wind resource downscale Classification: Public 21
22 . Data Extraction & Preparation Wind data Derived features vector field (HR/LR) Curl, divergence, laplacian orc format ~1.5PB Apache Spark* Elevation Apache Apache Data (VHR) Spark* hgt format Hive* (pyspark) ~400GB python Roughness (HR) GeoTIFF format * All product names, logos and brands are property of their respective owners. All company, product and service names used in this document are for identification purposes only. Use of these names, logos and brands does not imply endorsement. Classification: Public 22
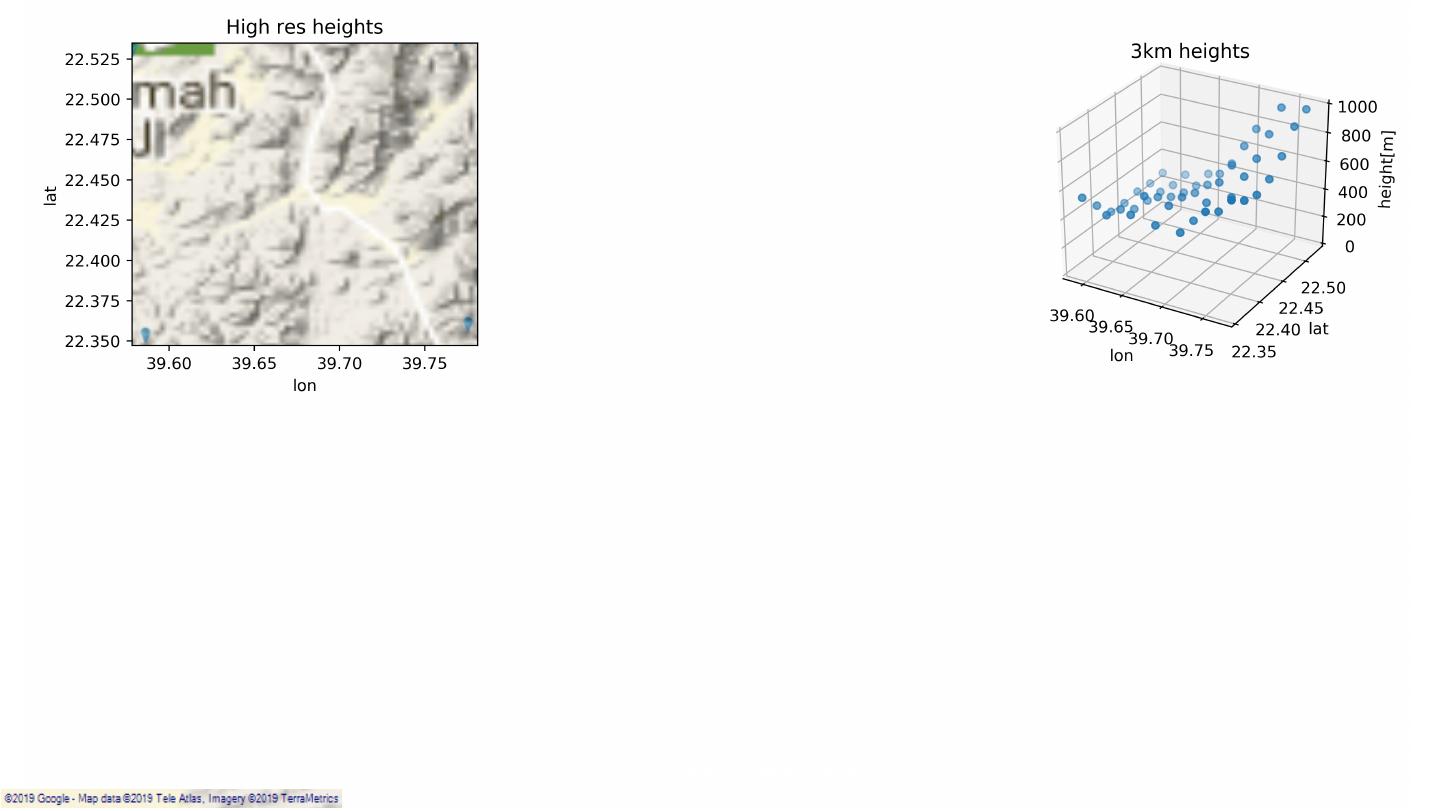
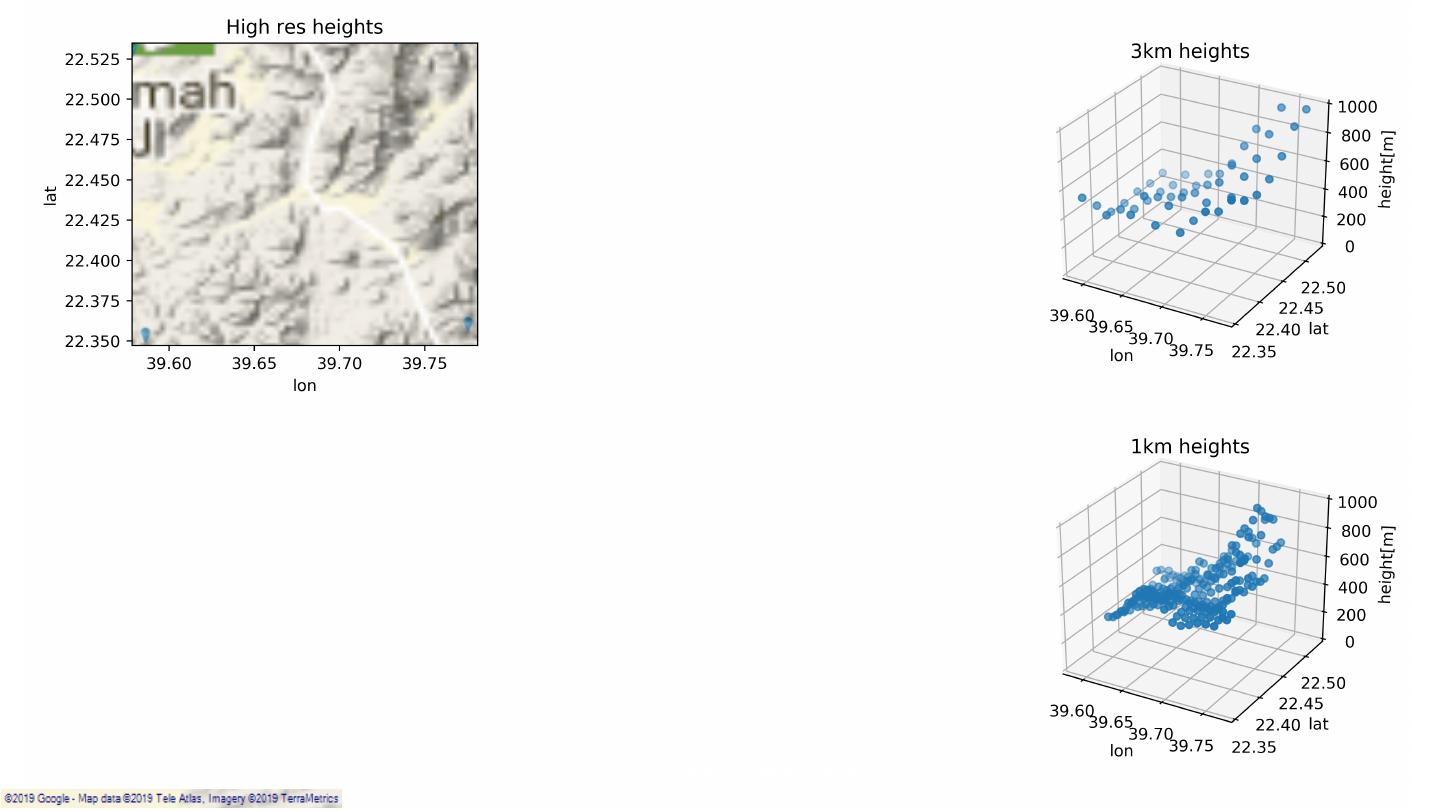
23 .Data Extraction & Preparation 3km VCL 3km point – global coverage (19 years). Classification: Public 23
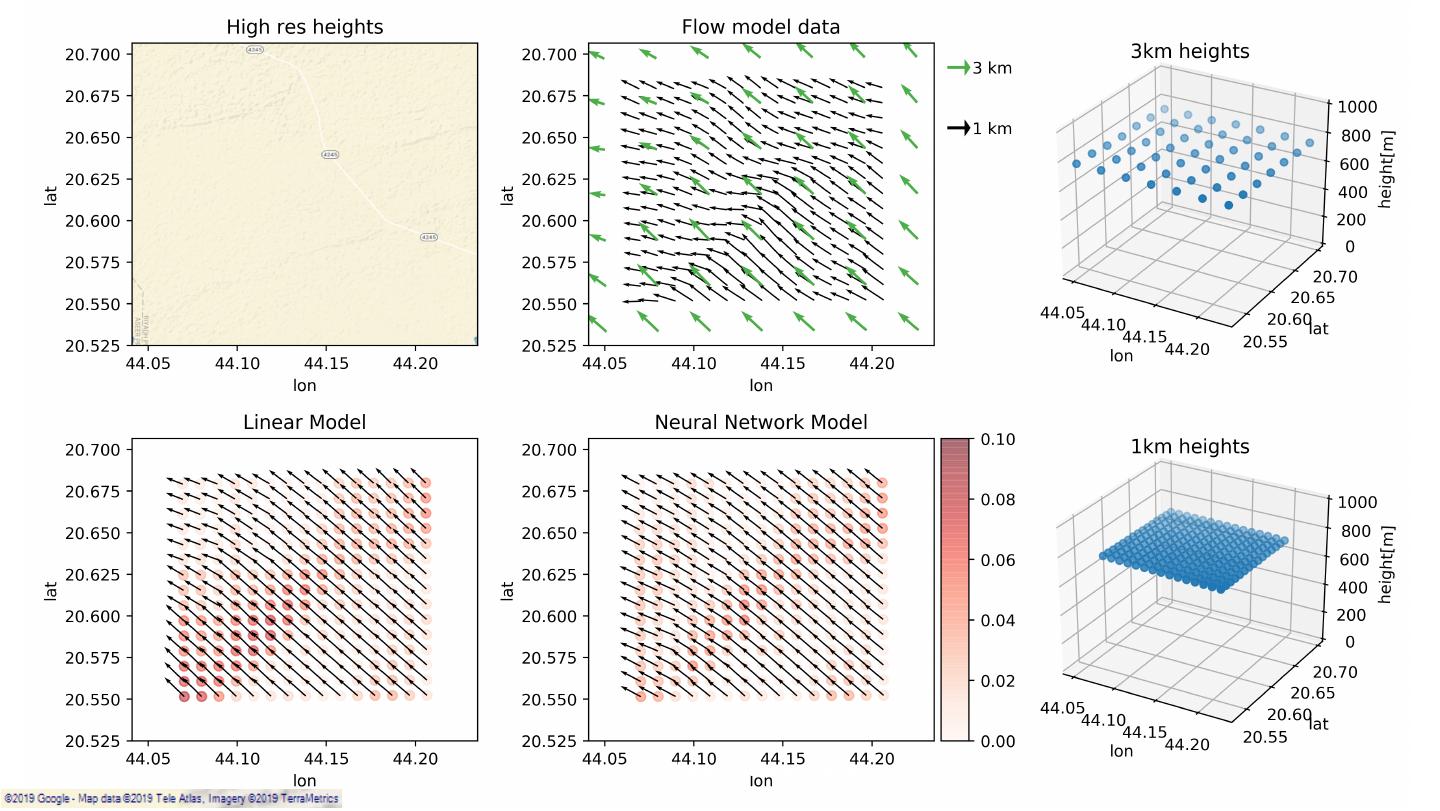
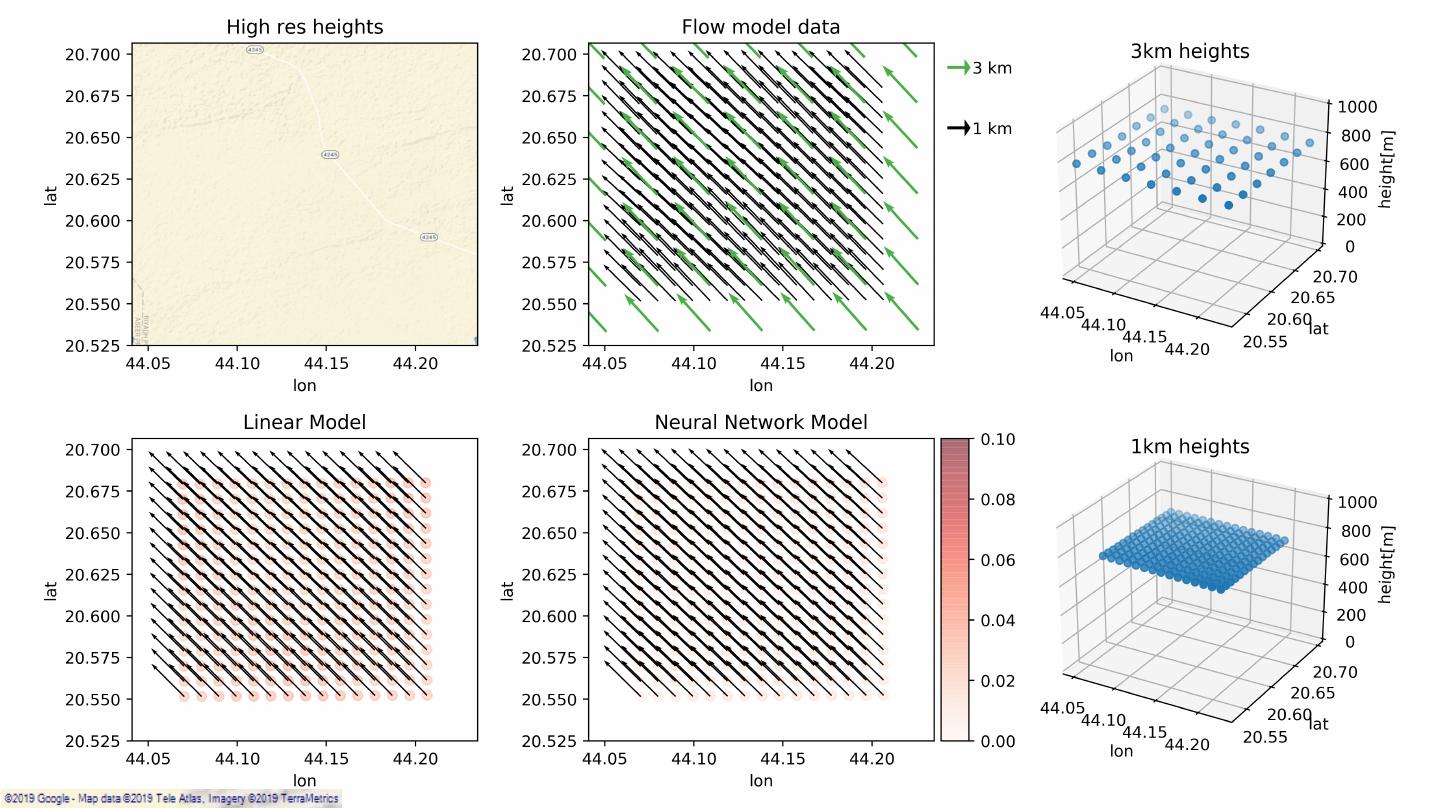
24 .Data Extraction & Preparation 1km 3km VCL 3km point – global coverage (19 years). VCL 1km point – Saudi Arabia coverage (1 year). Classification: Public 24
25 .Data Extraction & Preparation VCL 3km point – global coverage (19 years). VCL 1km point – Saudi Arabia coverage (1 year). Terrain data - SRTM (very high resolution, up to 30m). Classification: Public 25
26 .Data Extraction & Preparation VCL 3km point – global coverage (19 years). VCL 1km point – Saudi Arabia coverage (1 year). Terrain data - SRTM (very high resolution, up to 30m). Each red point generates 1 row per timesptamp on the dataset Classification: Public 26
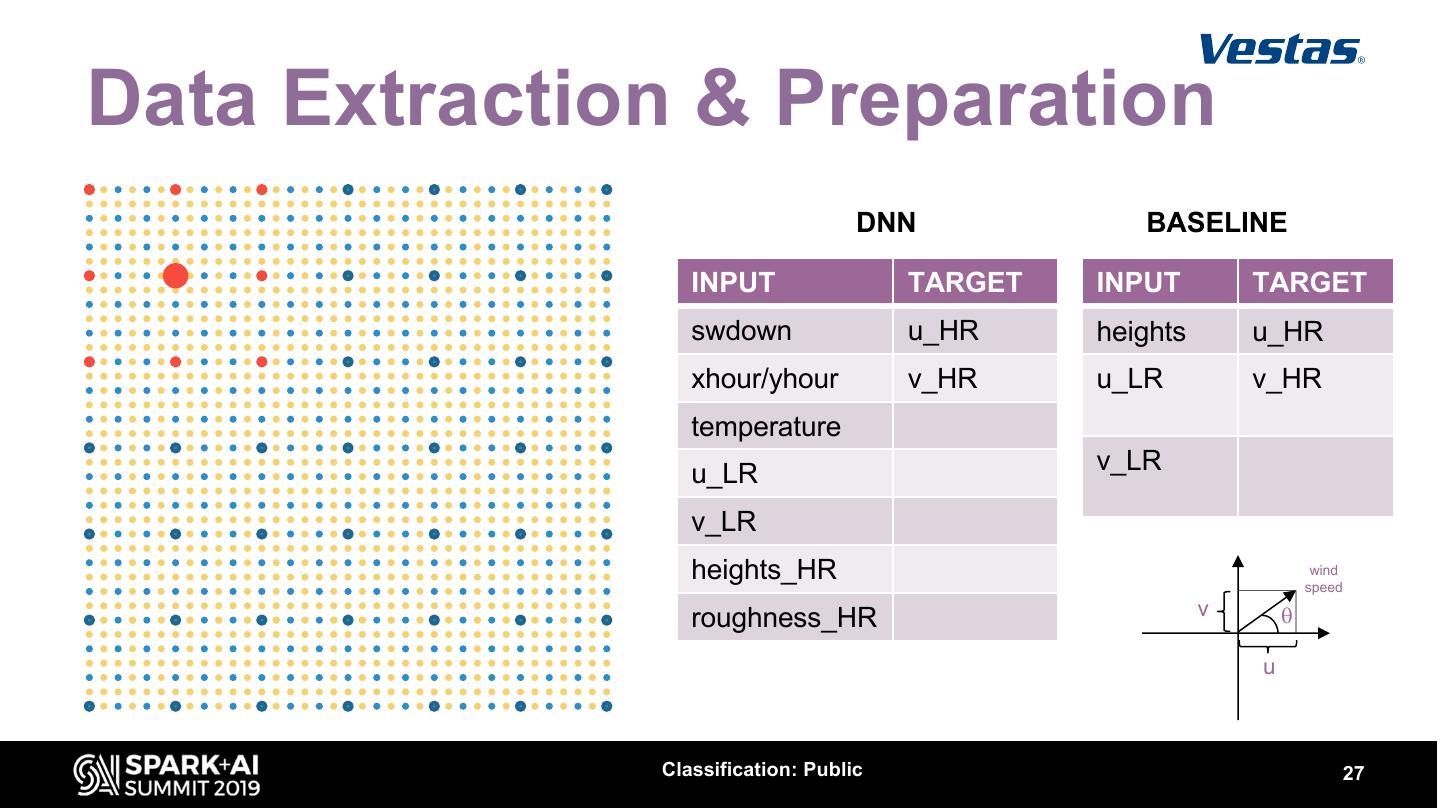
27 .Data Extraction & Preparation DNN BASELINE INPUT TARGET INPUT TARGET swdown u_HR heights u_HR xhour/yhour v_HR u_LR v_HR temperature u_LR v_LR v_LR heights_HR wind speed roughness_HR v q u Classification: Public 27
28 .Feed Forward neural network Input parameters first_neuron (width) Shape (brick) Hidden layers Output parameters Classification: Public 28
29 .Hyperparameter selection #neurons #hidden #epochs dropout layers 12 1 200 0.2 56 1 200 0.2 128 1 200 0.2 256 1 200 0.2 12 5 200 0.2 56 5 200 0.2 … … 256 10 400 0.5 48 combinations Classification: Public 29
3秒后跳转登录页面
去登陆

