No REST till Production – Building and Deploying 9 Models to Production
分享
点赞
6
收藏
2
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
The state of the art in productionizing machine Learning models today primarily addresses building RESTful APIs. In the Digital Ecosystem, RESTful APIs are a necessary, but not sufficient, part of the complete solution for productionizing ML models. And according to recent research by the McKinsey Global Institute, applying AI in marketing and sales has the most potential value.
In the digital ecosystem, productionizing ML models at an accelerated pace becomes easy with:
Feature Store with commonly used features that is available for all data scientists
Feature Stores that distill visitor behavior is ready to use feature vectors in a semi supervised manner
Data pipeline that can support the challenging demands of the digital ecosystem to feed the Feature Store on an ongoing basis
Pipeline templates that support the challenging demands of the digital ecosystem that feed feature store, predict and distribute predictions on an ongoing basis. With these, a major electronics manufacturer was able to build and productionize a new model in 3 weeks.
The use case for the model is retargeting advertising; it analyzes the behavior of website visitors and builds customized audiences of the visitors that are most likely to purchase 9 different products. Using the model, this manufacturer was able to maintain the same level of purchases with half of the retargeting media spend -increasing the efficiency of their marketing spend by 100%.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .No REST till Production –
Building and Deploying 9 Models to
Production in 3 weeks
Charmee Patel, Syntasa
#UnifiedDataAnalytics #SparkAISummit
�
3 .About SYNTASA
• Offices in Washington, DC and London
• Marketing AI Platform used by large Enterprises
• Fit natively in all Hadoop distros & Clouds
• Customers include several household brands
Washington, DC
London
3
�
4 .About SYNTASA
• 50+ production models
• 100s of behavioural data sources
• 100s of experimental models
• ~1B unique visitors and customer activities
• 30B Million events monthly
• Billions of predictions served
• Trillions of historical records
4
�
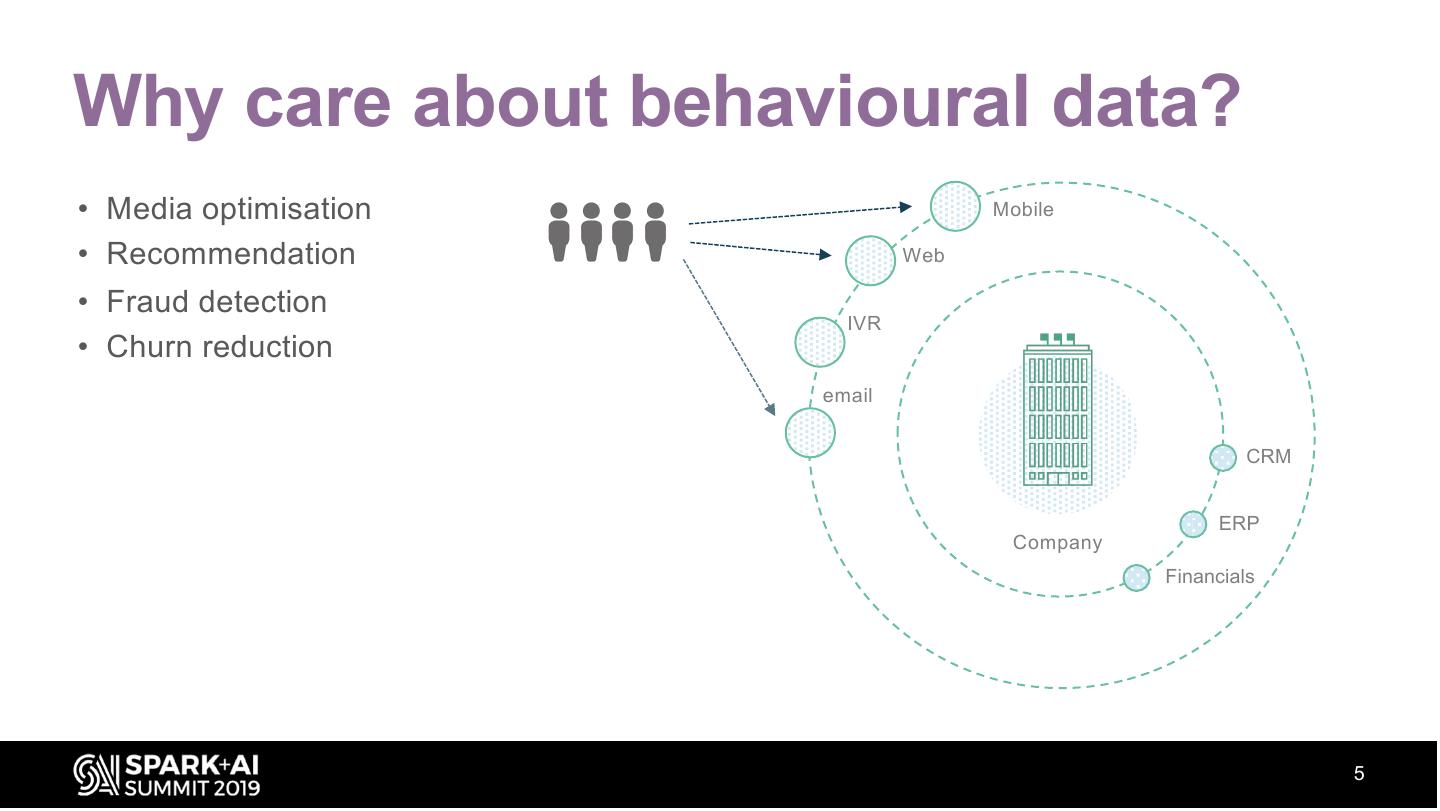
5 .Why care about behavioural data?
• Media optimisation Mobile
• Recommendation Web
• Fraud detection
IVR
• Churn reduction
email
CRM
ERP
Company
Financials
5
�
6 .Our Christmas Project
Support media buying decisions for certain product segments
Background ~2M Visitors
• Clickstream data
• ~2M visitors a day
• ~100k SKUs
~100k SKUs
• Products of interest
– <0.1% conversion rate
Existing Marketing activity
<0.1%
• Building rules-based audiences conversion rate
• Using black-box AI models in their
Martech and Adtech tools
We built bespoke models using their behavioral + enterprise data
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Challenges
• High volume
• Complex
• Non-stationary
• Hard to featurise
• Training requires the full data
• Reliability in productionizing model
• Timely inference at scale
• Models drift
7
�
8 .User Activity & Time
Lookback Window Prediction
Lookback Window Prediction
Lookback Window Prediction
Lookback Window Prediction
1 2 3 4 5 6 7 8
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Feature Store
Features @ Visitor level
• Last 7 days
• Interaction with certain pages, products, cart
• ~400 form elements that were available in tracking
• Total general activity
• Features include zero and non-zero counts of fields and one-hot encoded values
Initial ~1,000 features, down-weighing features based on variance
resulting in ~400 features
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Experiment setup
3 datasets Business Metrics
• Training period Nov 2018 • If we have a good model but what does that mean
Split in test & train for campaign?
• Additional evaluation on Dec 2018 • Campaigns need minimum sample size for A/B testing
• How do we find right audience and confirm projected
positive results for audience
Statistical Metrics
• Lift projections
• F1score due to class imbalance
– Lift @ 5%
– Lift @ 20%
10
�
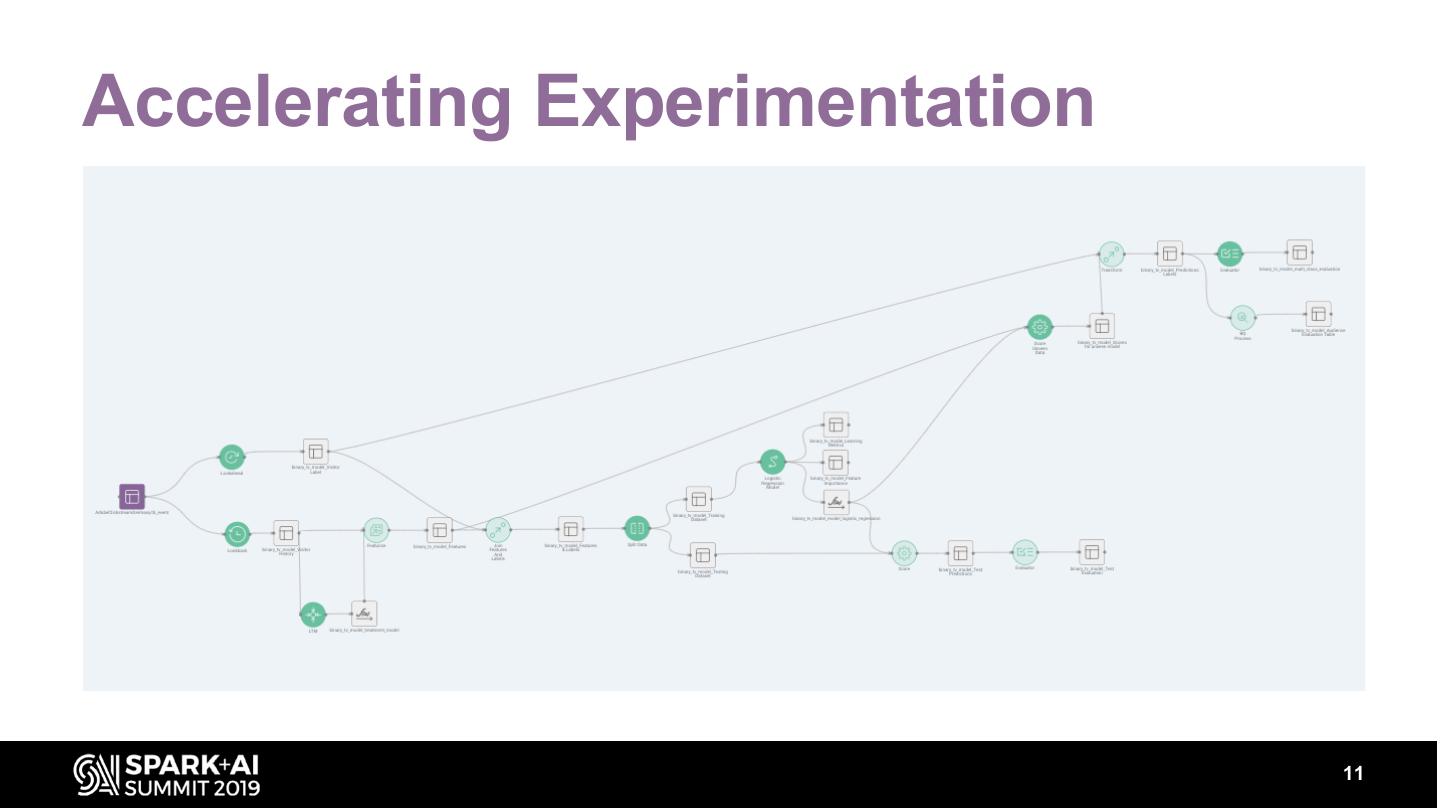
11 .Accelerating Experimentation
11
�
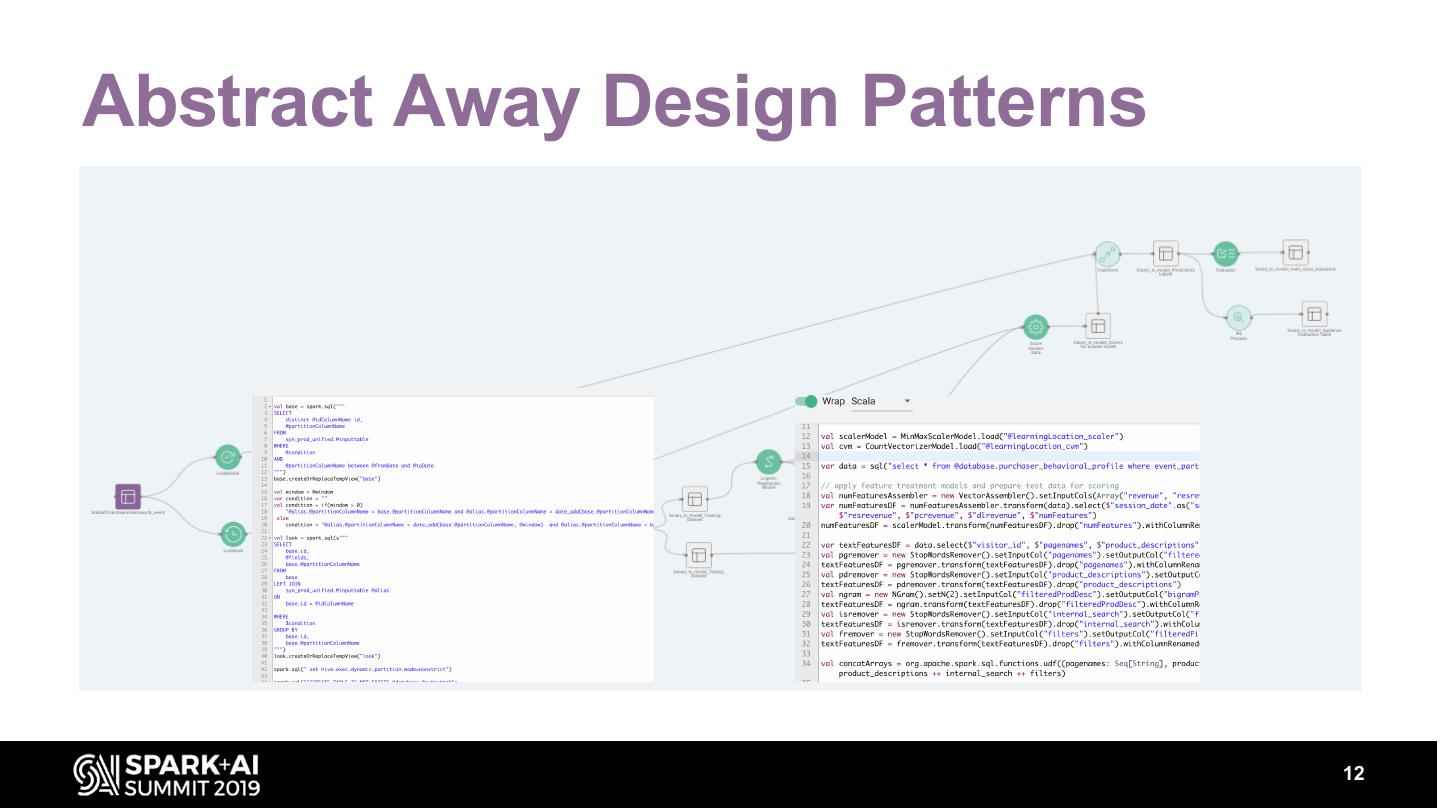
12 .Abstract Away Design Patterns
12
�
13 .Process Template
Dataset à Processes à Dataset
• aka Functors
Why Processes?
• UDFs/UDAFs not always the right fit
• Custom transformers on top of Spark transform is too cumbersome
• Abstracts away Spark idiosyncrasies
• Allows re-use by team members of different skill levels
• Battle tested and unit tested
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .Experiments
Multiclass model X First best model results – Random forest
• Severe class imbalance (<0.1%) • Learning (f1score) – 0.9
• Poor learning and evaluation metrics • Eval on test split (f1score) – 0.85
• Eval on December – 0.7!!
What if we build several • Lift @ 5% - 9.5x
binary models?
• Initial results promising Next best model results – Logistic Regression
• Learning (f1score) – 0.89
Several algorithms and hyper • Eval on test split (f1score) – 0.87
params tested (LR, RF, GBM) • Eval on December – 0.78
• Lift @ 5% – 9x
14
�
15 .Production
• Several Models for each Product
• Ensemble predictions for each product separately
• Call REST API to push predictions @ scale to Ad Networks
#UnifiedDataAnalytics #SparkAISummit 15
�
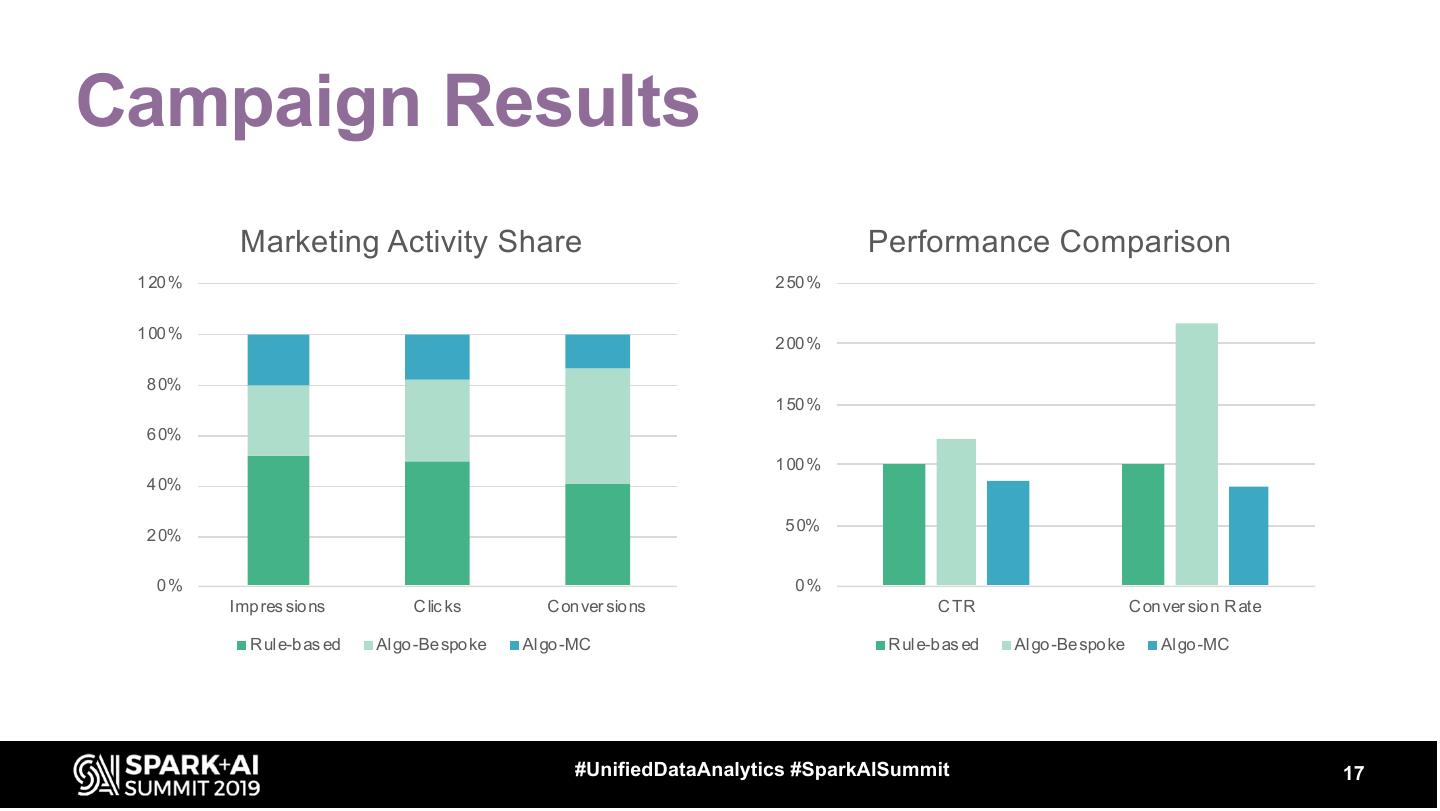
17 .Campaign Results
Marketing Activity Share Performance Comparison
1 20 % 2 50 %
1 00 %
2 00 %
8 0%
1 50 %
6 0%
1 00 %
4 0%
5 0%
2 0%
0% 0%
Imp res sio ns C lic ks C on ver sio ns C TR C on ver sio n R ate
R ul e-b as ed Al go -Be spo ke Al go -MC R ul e-b as ed Al go -Be spo ke Al go -MC
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�