展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Near Real-Time Data
Warehousing with
Apache Spark and Delta
Lake
Jasper Groot, Eventbrite
#UnifiedDataAnalytics #SparkAISummit
�
3 .Introduction
Personal Introduction
- Data engineering in the event
industry for 4+ years
- Using spark for 3+ years
- Currently at Eventbrite
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Outline
• Structured Streaming
– In a nutshell
• Delta Lake
– How it works
• Data Warehousing
– Detailed example using these tools
– Gotchas
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Structured Streaming
In a nutshell
• Introduced in Spark 2.0
• Streams are unbounded dataframes
• Familiar API for anyone who has used
Dataframes
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Structured Streaming
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Structured Streaming
How streaming dataframes differ
• More restrictive operations
– Distinct
– Joins
– Aggregations
• Must be after joins
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Structured Streaming - Recovery
Recovery is done through checkpointing
• Checkpointing uses write-ahead logs
• Stores running aggregates and progress
• Must be a HDFS compatible FS
There are limitations on resuming from a
checkpoint after updating application logic
#UnifiedDataAnalytics #SparkAISummit 8
�
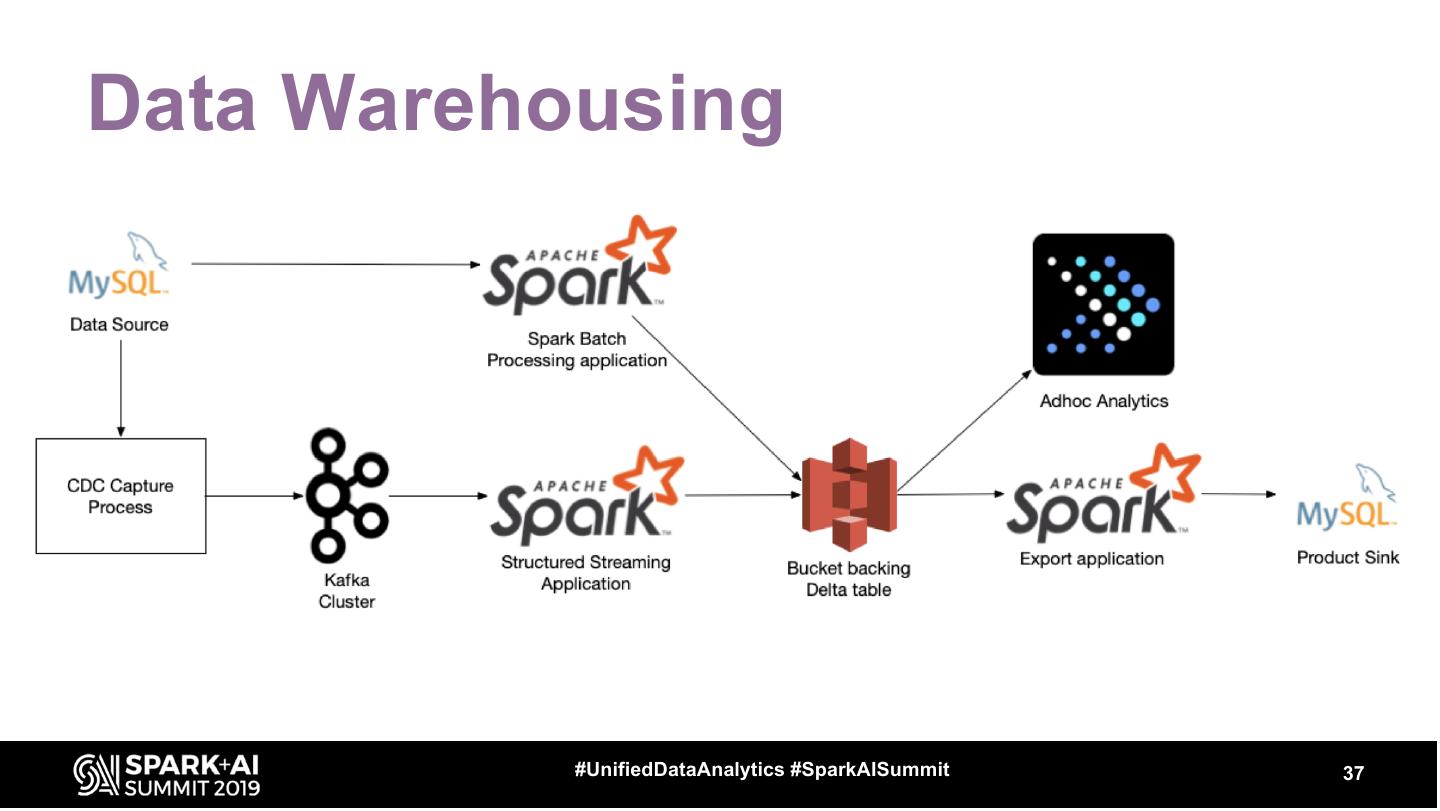
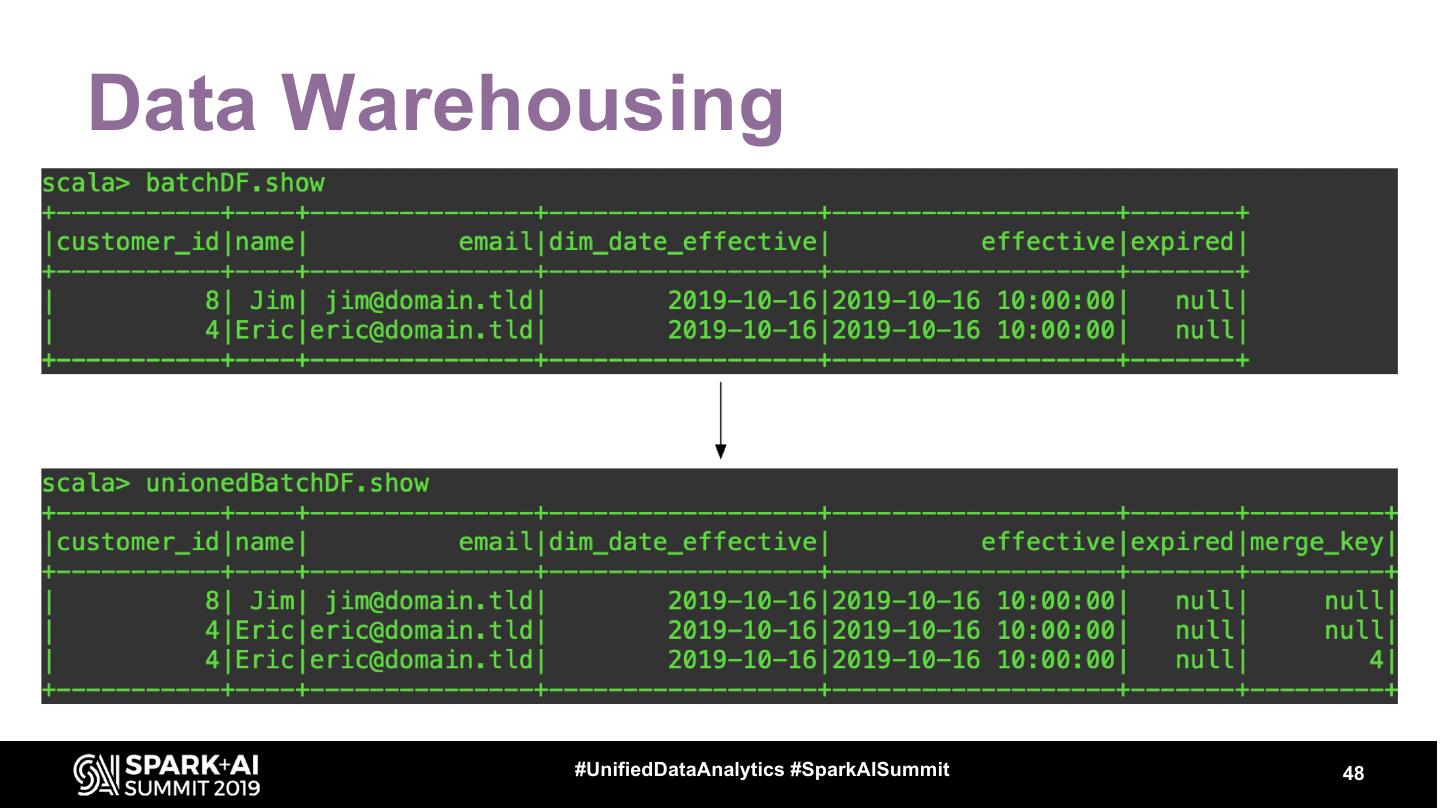
9 .Structured Streaming + Data
Warehousing
• Importance of watermarking
• Managing late data
• Using foreachBatch
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .#UnifiedDataAnalytics #SparkAISummit 10
�
11 .#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Delta Lake
• Open Sourced in 2019
• Parquet under the hood
• Enables ACID transactions
• Supports looking back in time
• UPDATE & DELETE existing records
• Schema management options
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Delta Lake
• Files can be backed by
– AWS S3
– Azure Blob Store
– HDFS
• Able to convert datasets between parquet and
delta lake
• Some SQL Support
#UnifiedDataAnalytics #SparkAISummit 13
�
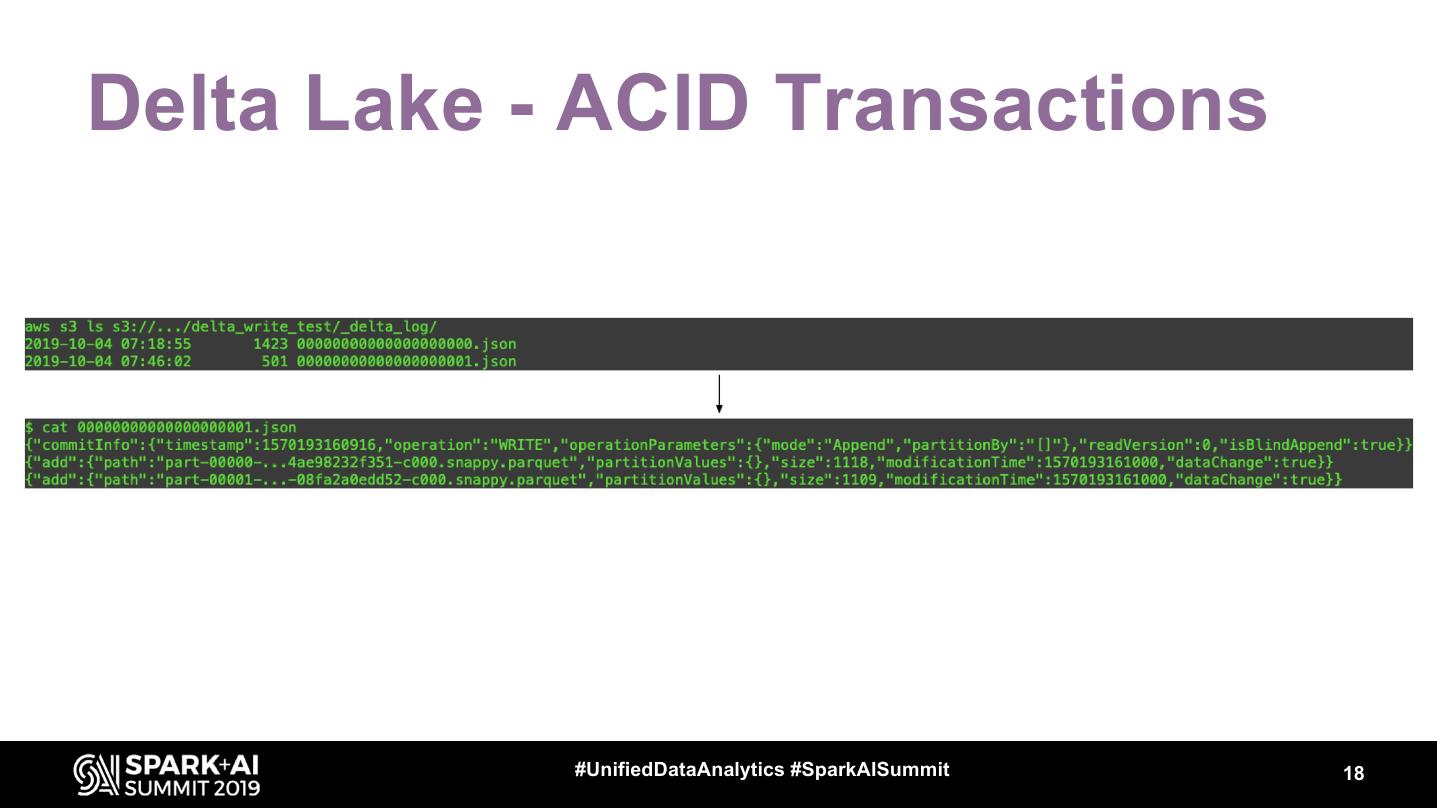
14 .Delta Lake - ACID Transactions
Works using a transaction log
• Transaction log tracks state
• Files will not be deleted during read
• Optimistic conflict resolution
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .Delta Lake - ACID Transactions
Update
Insert
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .Delta Lake - ACID Transactions
Aliases for merge
Join condition
Defining our dataset
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Delta Lake - ACID Transactions
Values to update
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .Delta Lake - ACID Transactions
If the join condition is not met, insert
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 25
�
26 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .Delta Lake - ACID Transactions
Delta tracks operations on files
• Not all operations are effective immediately
• New log file is created for each transaction
#UnifiedDataAnalytics #SparkAISummit 28
�
29 .Delta Lake - ACID Transactions
#UnifiedDataAnalytics #SparkAISummit 29
�