展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
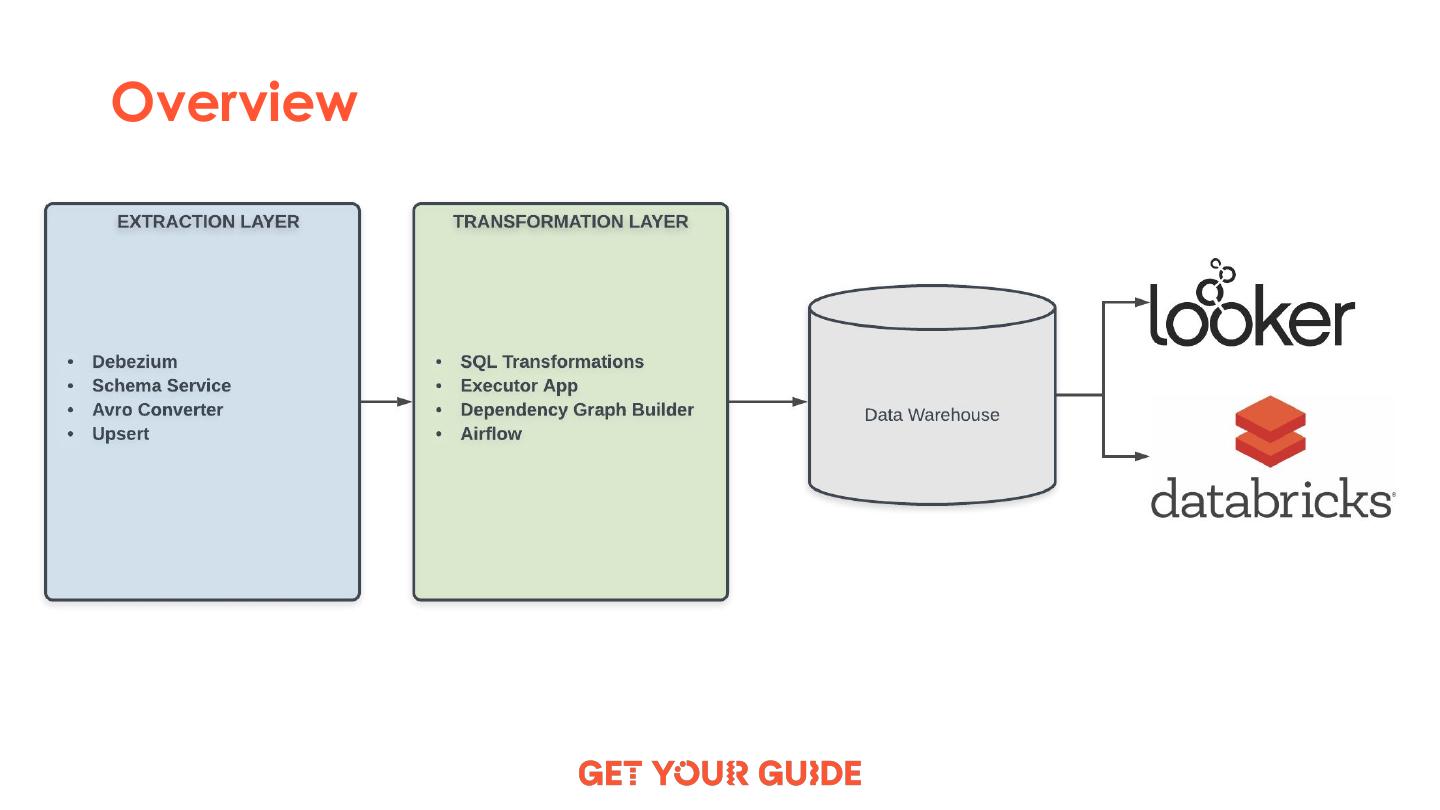
2 .Modern ETL Pipelines
with Change Data Capture
Thiago Rigo and David Mariassy, GetYourGuide
#UnifiedDataAnalytics #SparkAISummit
�
3 .Who are we?
Software engineer for the past 7 5 years of experience in
years, last 3 focused on data Business Intelligence and Data
engineering. Engineering roles from the Berlin
e-commerce scene.
Senior Data Engineer, Data
Platform. Data Engineer, Data Platform.
�
4 .Agenda
1 Intro to GetYourGuide
2 GYG’s Legacy ETL Pipeline
3 Rivulus ETL Pipeline
4 Conclusion
5 Questions
�
6 .We make it simple to book and enjoy
incredible experiences
�
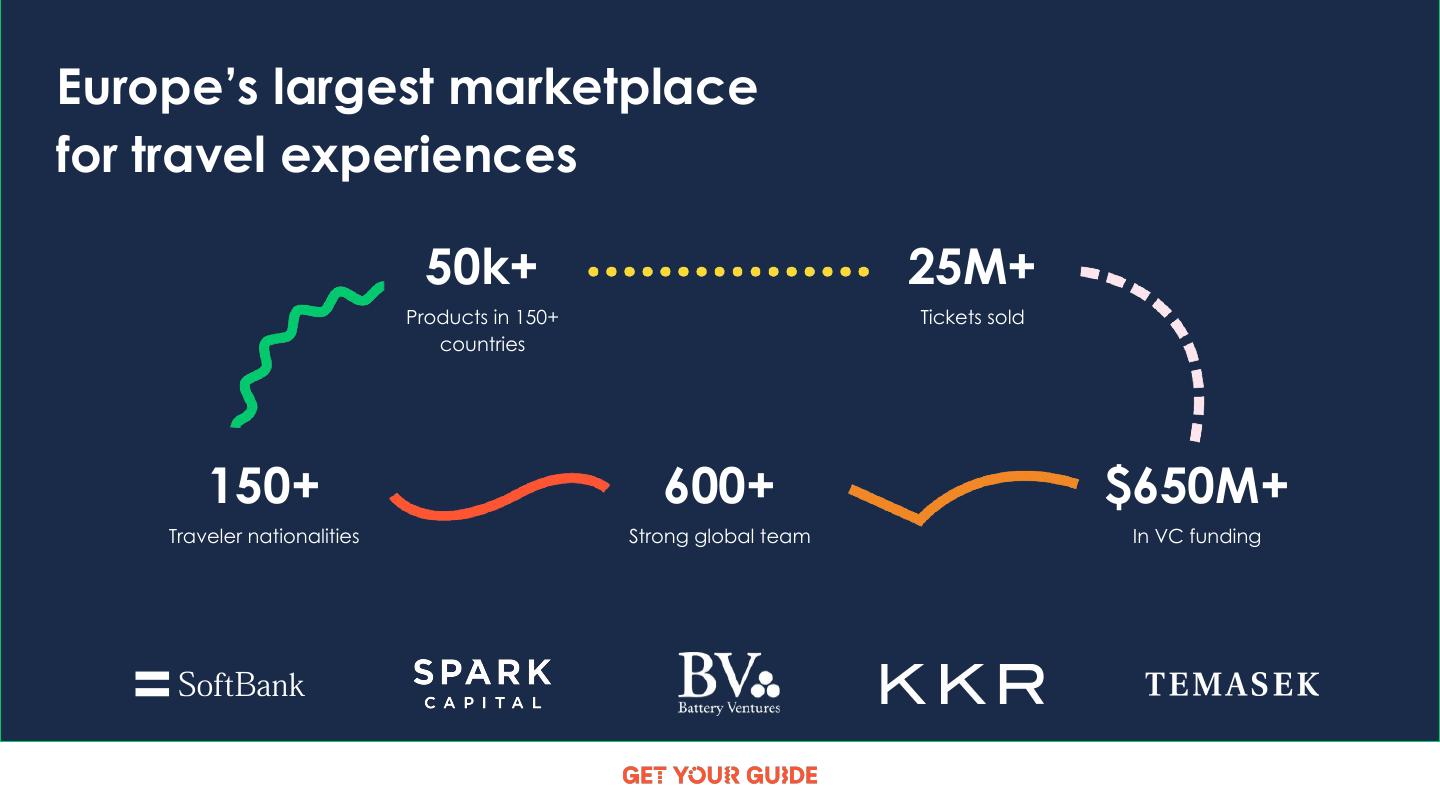
7 .Europe’s largest marketplace
for travel experiences
50k+ 25M+
Products in 150+ Tickets sold
countries
150+ 600+ $650M+
Traveler nationalities Strong global team In VC funding
�
8 .GYG’s Legacy ETL Pipeline
�
9 . Where we started
Breaking
Requires Long
schema Difficult to
special recovery Bad SLAs
changes test
knowledge times
upstream
�
10 . What we wanted
Automatic
Breaking
Requires
Familiar Long
handling
schemaof Maximum Difficult
Built forto
tooling
special
(Scala, recovery Better
Bad SLAs
SLAs
changes
schema parallelism testability
test
knowledge
SQL) times
upstream
changes
�
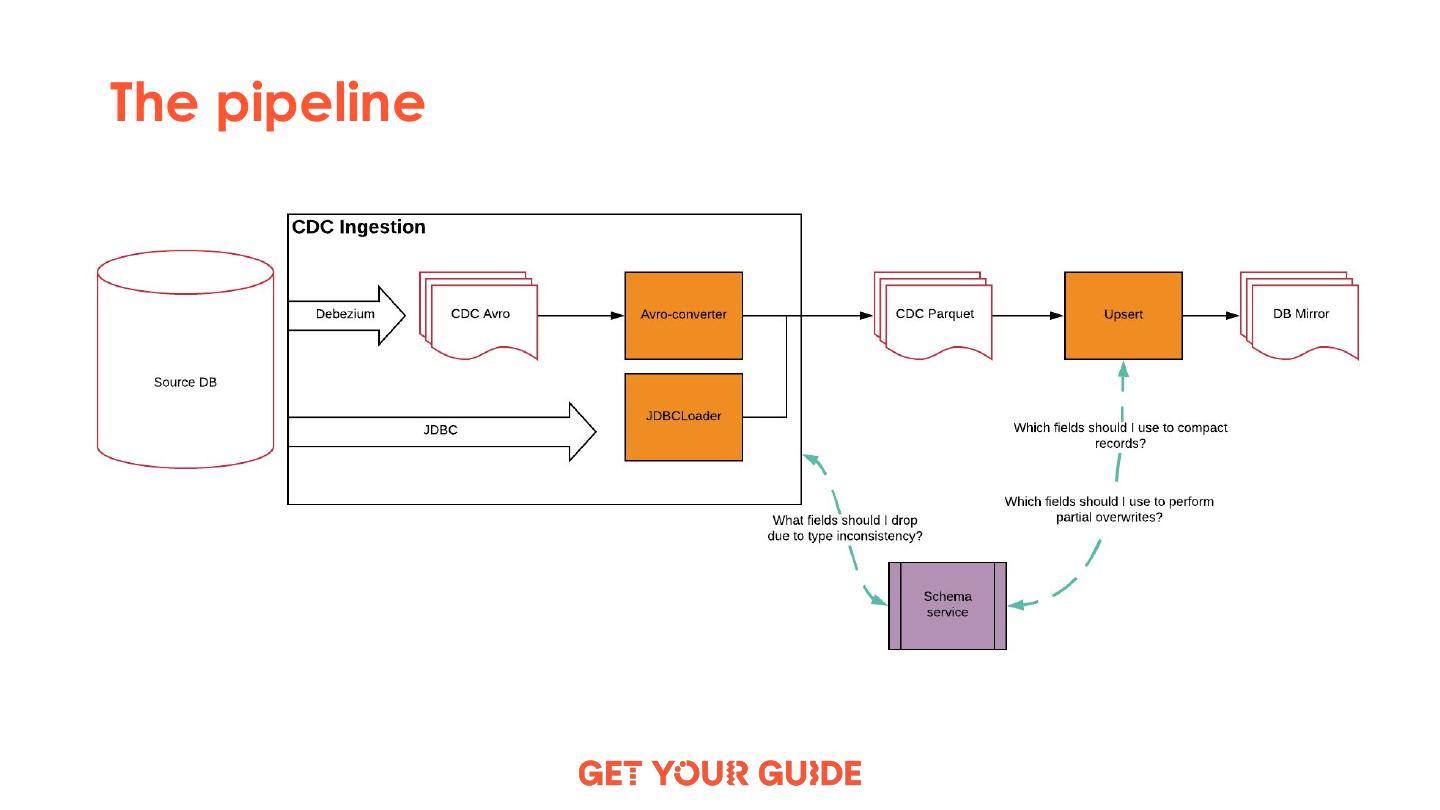
15 .Debezium
● Open source distributed platform for change
data capture
● Can read several databases
○ MySQL, Postgres, Cassandra, Oracle, SQL
Server, and Mongo DB
● It works as a connector part of Kafka Connect
● It streams the database's event log into Kafka
● Streams those changes to Kafka
�
16 .Schema Service
● Scala library
● Keeps track of all schema changes applied to
the tables
● Holds PK, timestamp and partition columns
● Prevents breaking changes from being
introduced
○ Type changes
● Upcast types
● Schema Service works on column level
Automatic
handling of
schema
changes
�
17 .Avro Converter
● Regular Scala application
● Runs as part of Airflow DAG
● Reads raw Avro files from S3
● Communicates with Schema Service to handle
schema changes automatically
● Writes out Parquet files
Automatic
handling of
schema
changes
�
18 .Upsert
● Spark application
● Runs as part of Airflow DAG
● Reads in new Parquet files
● Communicates with Schema Service to get PK,
timestamp and partition columns
● Compacts the data based on table’s PK
● Creates Hive table which contains a replica of
source DB
�
20 .The performance penalty of managing
transformation dependencies
inefficiently
�
21 .The gradual forsaking of performance on the altar
of dependency management
Humble
beginnings
● Small set of
transformations.
● Small team / single
engineer.
● Simple one-to-one type
dependencies.
● Defining an optimal
dependency model by
hand is possible.
�
22 .The gradual forsaking of performance on the altar
of dependency management
Humble Complexity on
beginnings the horizon
● Growing set of transformations.
● Growing team.
● One-to-many / many-to-many type
dependencies.
● Defining a dependency model by
hand becomes cumbersome and
error-prone
�
23 .The gradual forsaking of performance on the altar
of dependency management
The hard
choice
Humble Complexity on between
beginnings the horizon performance
and
correctness
● As optimal dependency models
become ever more difficult to maintain
and expand manually without making
errors, teams decide to optimise for
correctness over performance.
● This results in crude dependency
models with a lot of sequential
execution in places where
parallelization would be possible.
�
24 .The gradual forsaking of performance on the altar
of dependency management
The hard
choice The
Humble Complexity on between performance
beginnings the horizon performance bottleneck
and strikes back
correctness
● Sequential execution results in
long execution and long recovery
times. In other words Poor SLAs.
● 💣🔥
�
25 .Rivulus SQL for automated dependency
inference
Maximum
parallelism
�
26 .Main components
● SQL transformations
○ A collection of Rivulus SQL files that make use of a set of
custom template variables.
● Executor app
○ Spark app that executes a single transformation at a
time.
● DGB (Dependency Graph Builder)
○ Parses all files in the SQL library and builds a
dependency graph of the transformations by
interpolating Rivulus SQL template vars.
● Airflow
○ Executes the transformations on Databricks in the order
specified by the DGB.
�
27 .Rivulus SQL syntax
● {% reference:target ‘dim_tour’ %}
○ Declares a dependency between this transformation and the
dim_tour transformation that must be defined in the same SQL
library
● {% reference:source ‘gyg__customer’ %}
○ Declares a dependency between this transformation and a raw
data source (gyg.customer) that is loaded to Hive by an
extraction job
● {% load ‘file.sql’ %}
○ Loads a reusable subquery defined in file.sql into this
transformation.
Familiar
tooling (Scala,
SQL)
�
28 . SELECT
Example
nps_feedback_id
, nps_feedback_stage_id
, booking_id
, score Rivulus SQL
{ , feedback
"fact_nps_feedback": { , update_timestamp
"source_dependencies": [ , source
"gyg__nps_feedback" FROM {% reference:source 'gyg__nps_feedback' %} AS nf
], Build time LEFT JOIN {% reference:target 'dim_nps_feedback_stage' %} nfs
"transformation_dependencies": [
"dim_nps_feedback_stage" ON nfs.nps_feedback_stage_name = nf.stage
]
}
}
DGB
Executor
Build time Airflow app
invocations
Runtime on DB
�
29 . A word on testing
● Maximum parallelism enhances testability Built for
testability
● Separation of config from code
○ Configurable input and output paths
�