展开查看详情
1 .Thanks for coming early!
Want to make clothes from code?
https://haute.codes
Want to hear about a KF book?
http://www.introtomlwithkubeflow.com
Teach kids Apache Spark?
http://distributedcomputing4kids.com
�
2 .Spark ML to Spark + TF
Alternate: Things that almost work
An Adventure powered by
Kubeflow
Presented by
@holdenkarau
�
3 .Holden:
● My name is Holden Karau
● Prefered pronouns are she/her
● Open Source Dev @ Apple
● Apache Spark PMC
● co-author of Learning Spark & High Performance Spark
● Twitter: @holdenkarau
● Slide share http://www.slideshare.net/hkarau
● Code review livestreams: https://www.twitch.tv/holdenkarau /
https://www.youtube.com/user/holdenkarau
● Spark Talk Videos http://bit.ly/holdenSparkVideos
● Talk feedback: http://bit.ly/holdenTalkFeedback
�
5 .Today's adventure: Sucram Yef
● Who our players are (Spark, Kubeflow, Tensorflow)
● Why you would want to do this
● How to do make this "work"
● Some alternatives to all this effort
● Illustrated with existing projects of ML on Spark mailing lists & ML on code
● No demos because 0.7RC1 broke "everything"*
�
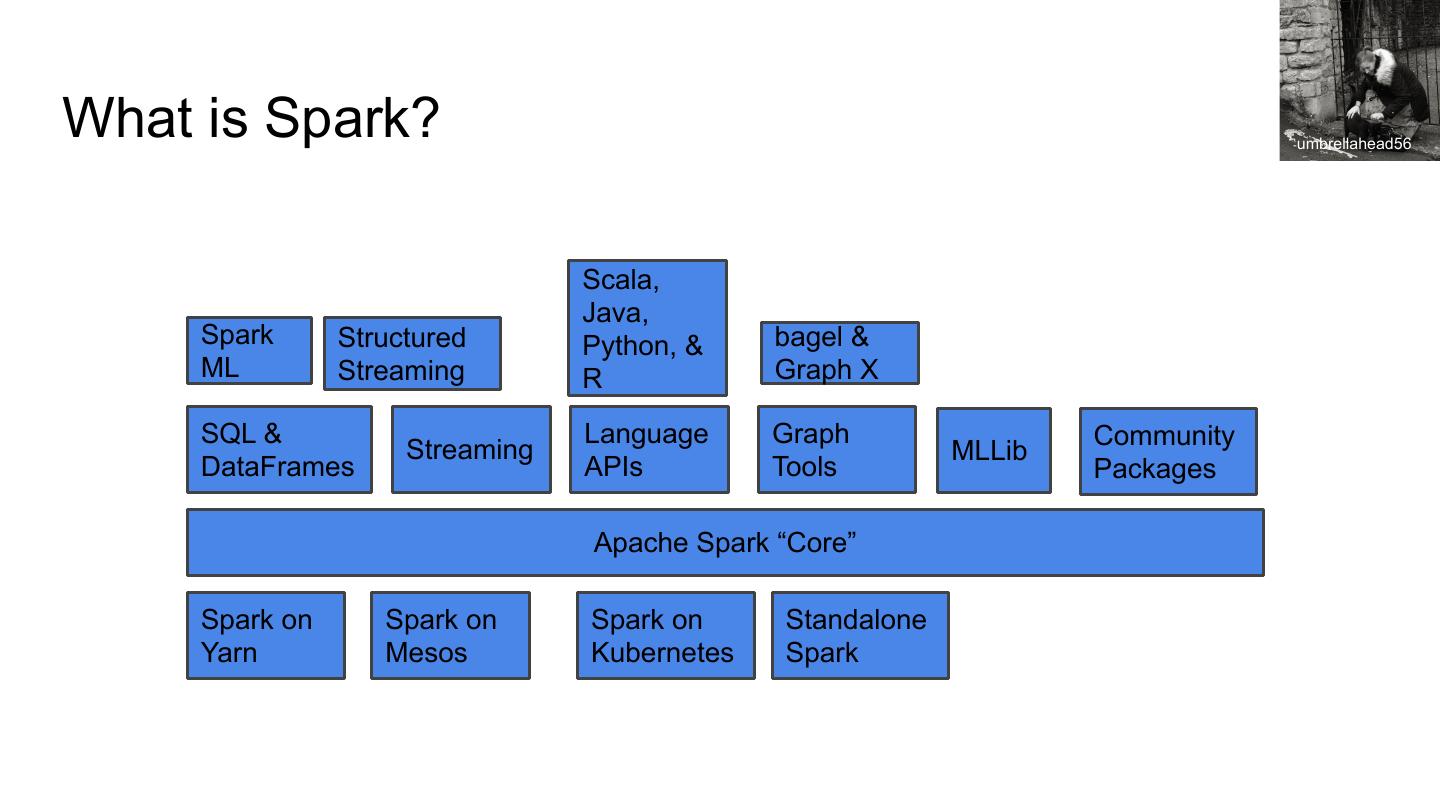
6 .What is Spark? umbrellahead56
Scala,
Java,
Spark Structured Python, & bagel &
ML Streaming R Graph X
SQL & Language Graph Community
Streaming MLLib
DataFrames APIs Tools Packages
Apache Spark “Core”
Spark on Spark on Spark on Standalone
Yarn Mesos Kubernetes Spark
�
7 .What is Tensorflow?
Tak H.
● Fancy machine learning tool
● Big enough it has it's own conference now too
● More deep learning options than inside of Spark ML
�
8 .What is Tensorflow Extended (TFX)? Miguel Discart
● Tools to create and manage Tensorflow pipelines
● Includes things like serving, data validation, data transformation, etc.
● Many parts of it's data ecosystem depend on Apache Beam's Python interface
which has challenges in open source
�
9 .What is Kubeflow?
Mr Thinktank
● "The Machine Learning Toolkit for Kubernetes" (kubeflow.org)
● Provides a buffet-like collection of ML related tools
● Very very unstable
● But aiming for a 1.0 release "soon"
�
10 .Why would want to augment Spark ML?
Tamsin Cooper
● Spark ML doesn't have a huge variety of algorithms
● Serving Spark models is painful
● Raising money from venture capitalists is easier with tensorflow
● A chance to revisit our base assumptions
�
11 .How could we do this? ivva
● Install Kubeflow
● Take our Spark job and split it into feature prep & model training
● Have our feature prep job save the results in a TF-compatabile format
● Create a TF-job
● Create a Kubeflow (or Argo, or…) pipeline to train or new model
● Optional: Use katib to do hyper-parameter tuning
● Validate if our classic ML or new fancy ML works "better"
�
12 .What is the catch?
Dale Cruse
● Kubeflow is alpha software
● Kubeflow had Spark integrated in 0.5, broke in 0.6, and there's a PR to add fix
it in 0.7
● So… using this is a bit tricky (for now)
● To be clear: DO NOT DO THINGS I SHOW YOU IN PRODUCTION
○ It's like that "professional drivers" warning on TV except maybe a different word than
professional
○ Unless you're trying to get fired, in which case I have some PRs for you to try
�
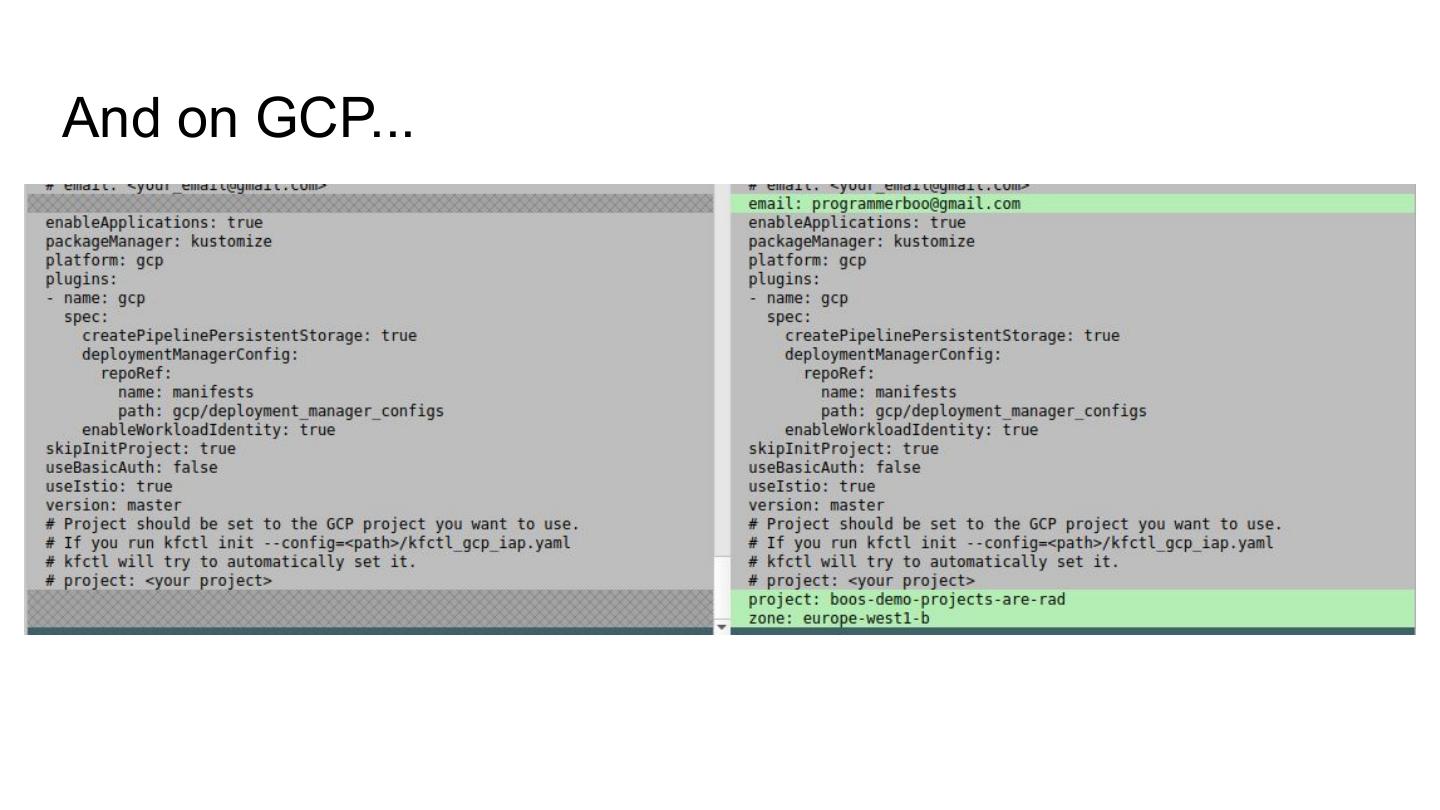
13 .Setting up KF
Marco Verch
● Download kfctl from https://api.github.com/repos/kubeflow/kubeflow/release
○ Get the latest rc, leave an offering to Cthulhu, and add it to your path
● Download a config from
https://github.com/kubeflow/manifests/tree/master/kfdef (not
https://github.com/kubeflow/kubeflow/tree/master/bootstrap/config )
○ Edit as you need (for us we need to add Spark) & configure our cluster
○ You can point to manifest PR#441 for now (e.g.
https://github.com/kubeflow/manifests/blob/50516461ce327624ad4e107a9286c69e5332e150/kfdef/kfctl_gcp_iap.yaml )
○ Edit the yaml URI to point to the PR, put in the app name
● Run the magic incantation
�
16 .The magic incantation*
I am R.
CONFIG="my_app.yaml"
KFAPP="cheeseburger"
kkdir ${KFAPP} && pushd ${KFAPP} && cp ${CONFIG} ./ && kfctl apply all -f
`pwd`/${CONFIG} -V
# As of 0.7RC1 appdir is ignored and everything is under /tmp
#Now take a 5~30 minute nap depending on your deployment. Long story.
Official documentation: https://www.kubeflow.org/docs/started/ (not yet updated to
0.7rcs)
�
17 .Using Spark on Kubeflow options:
Eden, Janine and Jim
● Use the spark-operator
○ Use PR#441
○ Or helm install the operator into the KF namespae
● Add Spark to your notebook image
○ This one kind of broke with new KF & Istio
○ If you understand istio reasonably well please come talk to me after
● Wait for PR#441 to be merged
● Wait for 0.7
● Or wait for 1.0
�
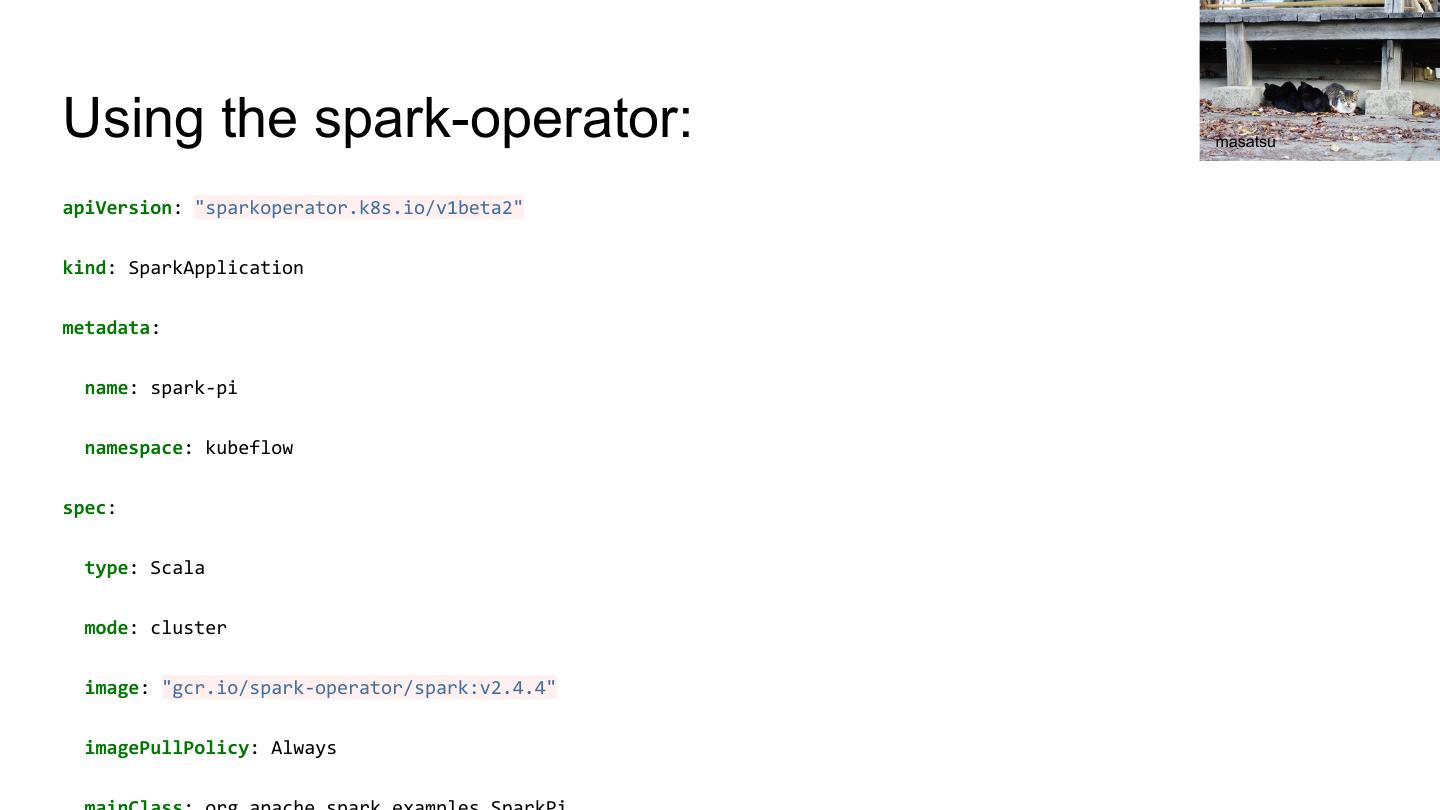
18 .Using the spark-operator: masatsu
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: kubeflow
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.4"
imagePullPolicy: Always
�
19 . Using spark in a notebook on KF*:
slgckgc
*Does not work in 0.7. Needs more istio magic
�
20 . Using spark in a notebook on KF*:
agirlnamednee
*Does not work in 0.7, I think I need to do more istio magic
�
21 .No demo, but cat picture: jeri leandera
● We're going to skip the demo because Kubeflow 0.7 RCs aren't quite there
○ RC1 broke the webui on GCP :(
�
22 .A "traditional" Spark ML pipeline (1 of 2): alljengi
val extensionIndexer = new StringIndexer()
.setHandleInvalid("keep") // Some files no extensions
.setInputCol("extension")
.setOutputCol("extension_index")
val tokenizer = new
RegexTokenizer().setInputCol("text").setOutputCol("tokens")
val word2vec = new
Word2Vec().setInputCol("tokens").setOutputCol("wordvecs")
�
23 .A "traditional" Spark ML pipeline (2 of 2): alljengi
prepPipeline.setStages(Array(
extensionIndexer,
tokenizer,
word2vec,
featureVec, classifier))
�
24 .Splitting our Spark pipeline
Roy Wolfe
prepPipeline.setStages(Array(
extensionIndexer,
tokenizer,
word2vec,
featureVec))
�
25 .Saving the results in a TF friendly way
Maxime Goossens
● Use Tensorflow's specific format
○ Build https://github.com/tensorflow/ecosystem/tree/master/spark/spark-tensorflow-connector and add as a jar
with --jar (or publish to local maven)
○ That seems… stable
● Use CSVs
○ What could go wrong? Oh you have strings… well… oh and a byte array… ummm...
● Wait for Tensorflow/TFX to adopt Arrow as an input format
○ https://github.com/tensorflow/community/pull/162
�
26 .Making a TF job to use the Spark job output
Oregon State University
● There are many great introduction to Tensorflow resources
○ And a talk @ 4pm introducing Tensorflow 2 you should totally check out
● That our output came from Spark doesn't matter to TF
○ Although the format does
● Although when we go to do inference things are complicated
○ This is where tensorflow-transform could be really awesome
�
27 .Putting our training together in a KF pipeline
● KF pipeline documentation:
https://www.kubeflow.org/docs/pipelines/overview/concepts/pipeline/
● Python!
● Can involve a surprising amount of YAML templating
�
28 .Our options for Spark in a pipeline:
● We can use the Kubeflow pipeline dsl elements + Spark operator
○ "ResourceOp" - create a Spark job
● We can also use the Kubeflow pipeline DSL elements + notebook
○ Each "step" will set up and tear down the Spark cluster, so do your Spark work in one step
�
29 .Spark in KF Pipeline using the operator from PR
import kfp.dsl as dsl
import kfp.gcp as gcp
import kfp.onprem as onprem
from string import Template
import json
@dsl.pipeline(
name='Simple spark pipeline demo',
description='Shows how to use Spark operator inside KF'
�