展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Maps and Meaning
Graph-based Entity Resolution
Hendrik Frentrup, systemati.co
#UnifiedDataAnalytics #SparkAISummit
�
3 .Maps and Meaning
Graph based Entity Resolution
Data
is the
new oil #UnifiedDataAnalytics #SparkAISummit
Source: Jordi Guzmán (creative commons)3
�
4 .Building Value Streams
Data Warehousing
Data Refining
Data Extraction
Source: Malcolm Manners (creative commons)
�
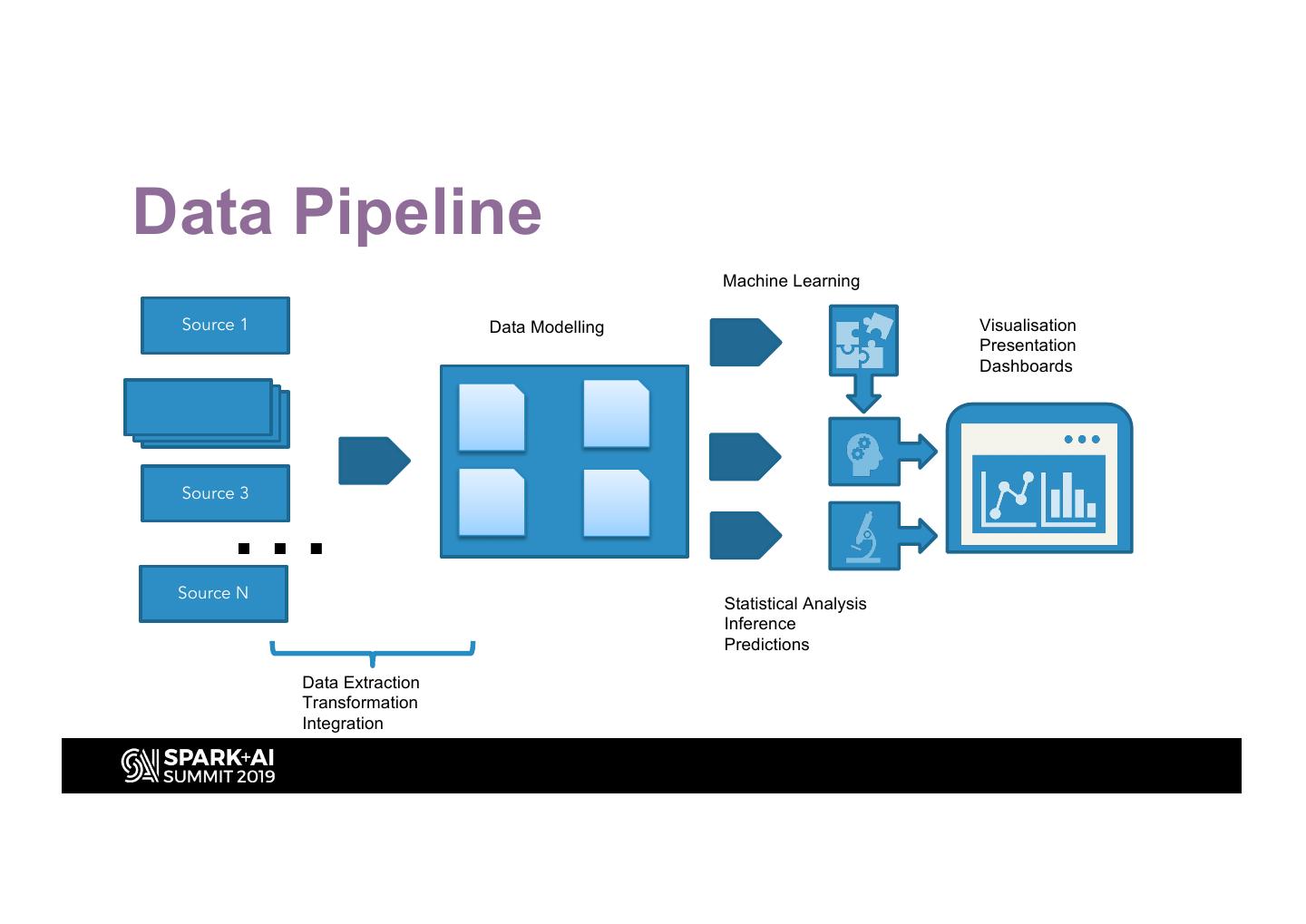
5 .Data Pipeline
Machine Learning
Source 1 Data Modelling Visualisation
Presentation
Dashboards
…
Source 3
Source N
Statistical Analysis
Inference
Predictions
Data Extraction
Transformation
Integration
�
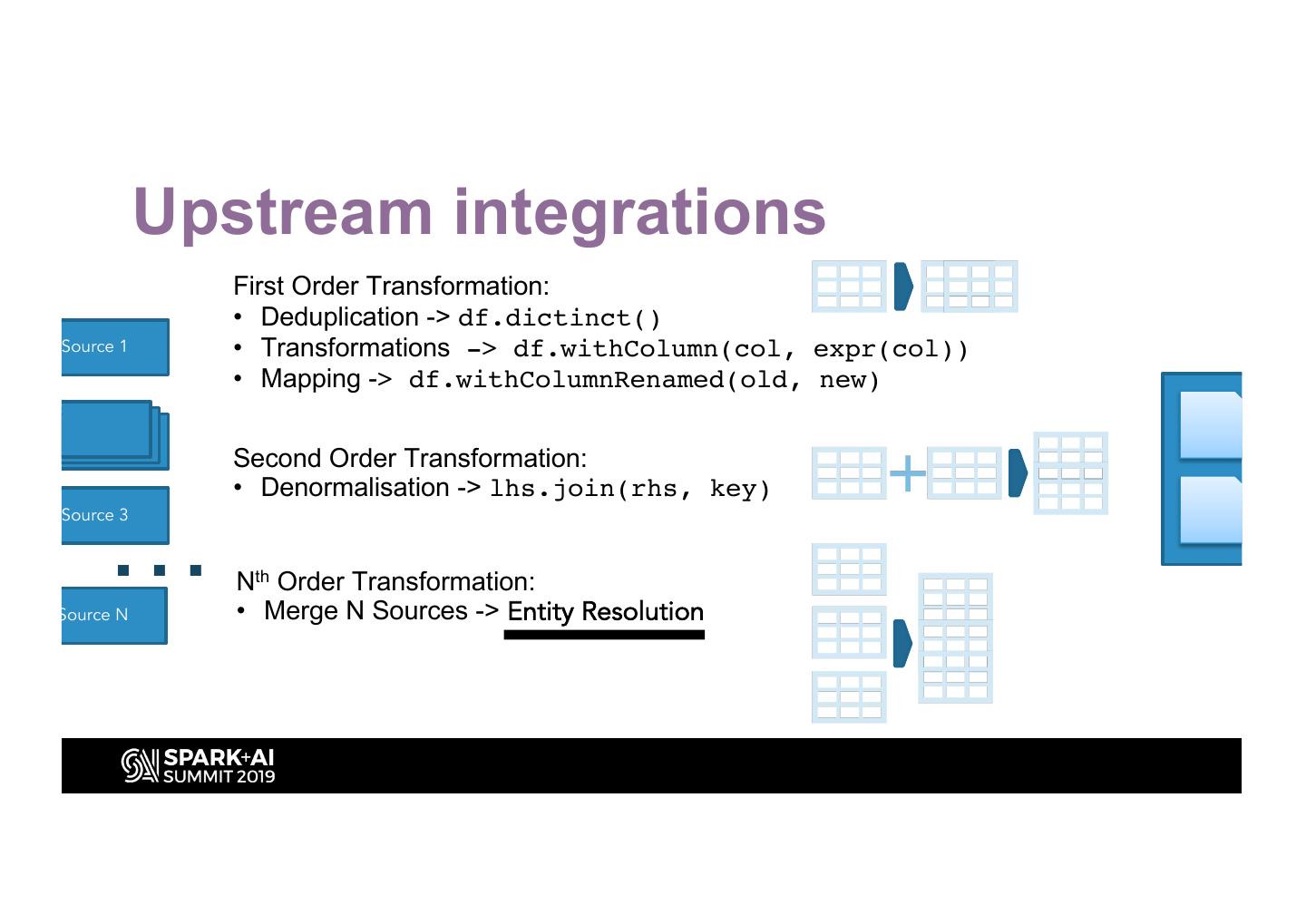
6 . Upstream integrations
First Order Transformation:
• Deduplication -> df.dictinct()
Source 1 • Transformations -> df.withColumn(col, expr(col))
• Mapping -> df.withColumnRenamed(old, new)
Second Order Transformation:
• Denormalisation -> lhs.join(rhs, key)
…
Source 3
Nth Order Transformation:
Source N • Merge N Sources -> Entity Resolution
�
7 .Outline
• Motivation
• Entity Resolution Example
• Graph-based Entity Resolution Algorithm
• Data Pipeline Architecture
• Implementation
– In GraphFrames (Python API)
– In GraphX (Scala API)
• The Role of Machine Learning in Entity Resolution
�
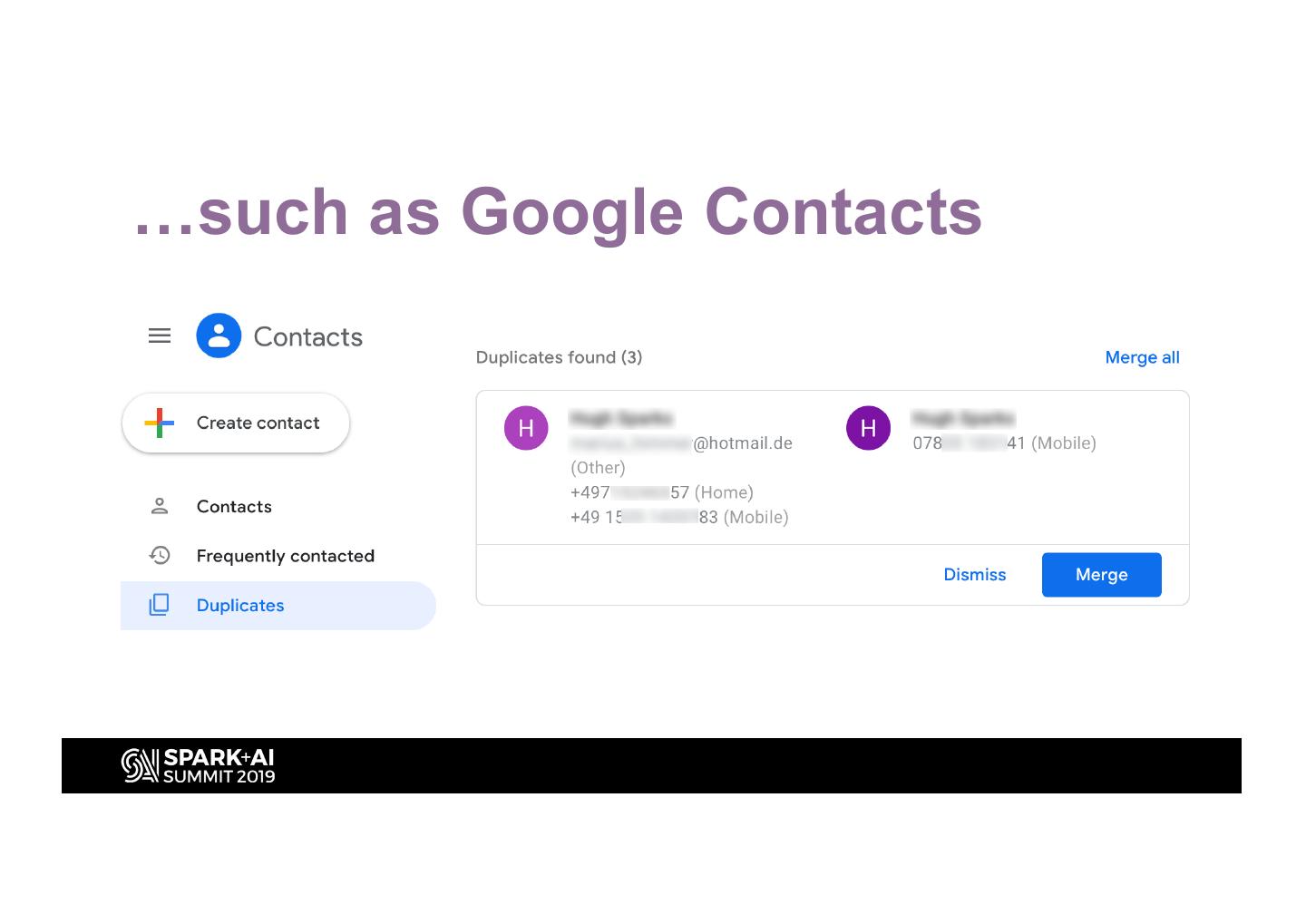
8 . Example: Find Duplicates
• Merge records in your Address Book
ID First Name Last Name Email Mobile Number Phone Number
1 Harry Mulisch harry@mulisch.nl +31 101 1001
2 HKV Mulisch Harry.Mulish@gmail.com +31 666 7777
3 author@heaven.nl +31 101 1001
4 Harry Mulisch +31 123 4567 +31 666 7777
ID First Name Last Name Email Mobile Number Phone Number
1 Harry/HKV Mulisch harry@mulisch.nl, +31 101 1001, +31 666 7777
Harry.Mulish@gmail.com, +31 123 4567
author@heaven.nl
�
9 .…such as Google Contacts
�
10 . Example: Resolving records
ID First Name Last Name Email Mobile Number Phone Number Source
1 Harry Mulisch harry@mulisch.nl +31 101 1001 Phone
2 S Nadolny +49 899 9898 Phone
3 Harry Mulisch +31 123 4567 +31 666 7777 Phone
4 author@heaven.nl +31 101 1001 Gmail
5 Sten Nadolny sten@slow.de +49 899 9898 Gmail
6 Max Frisch max@andorra.ch Outlook
7 HKV Harry.Mulish@gmail.com +31 666 7777 Outlook
�
11 .Graph Algorithm Walkthrough
�
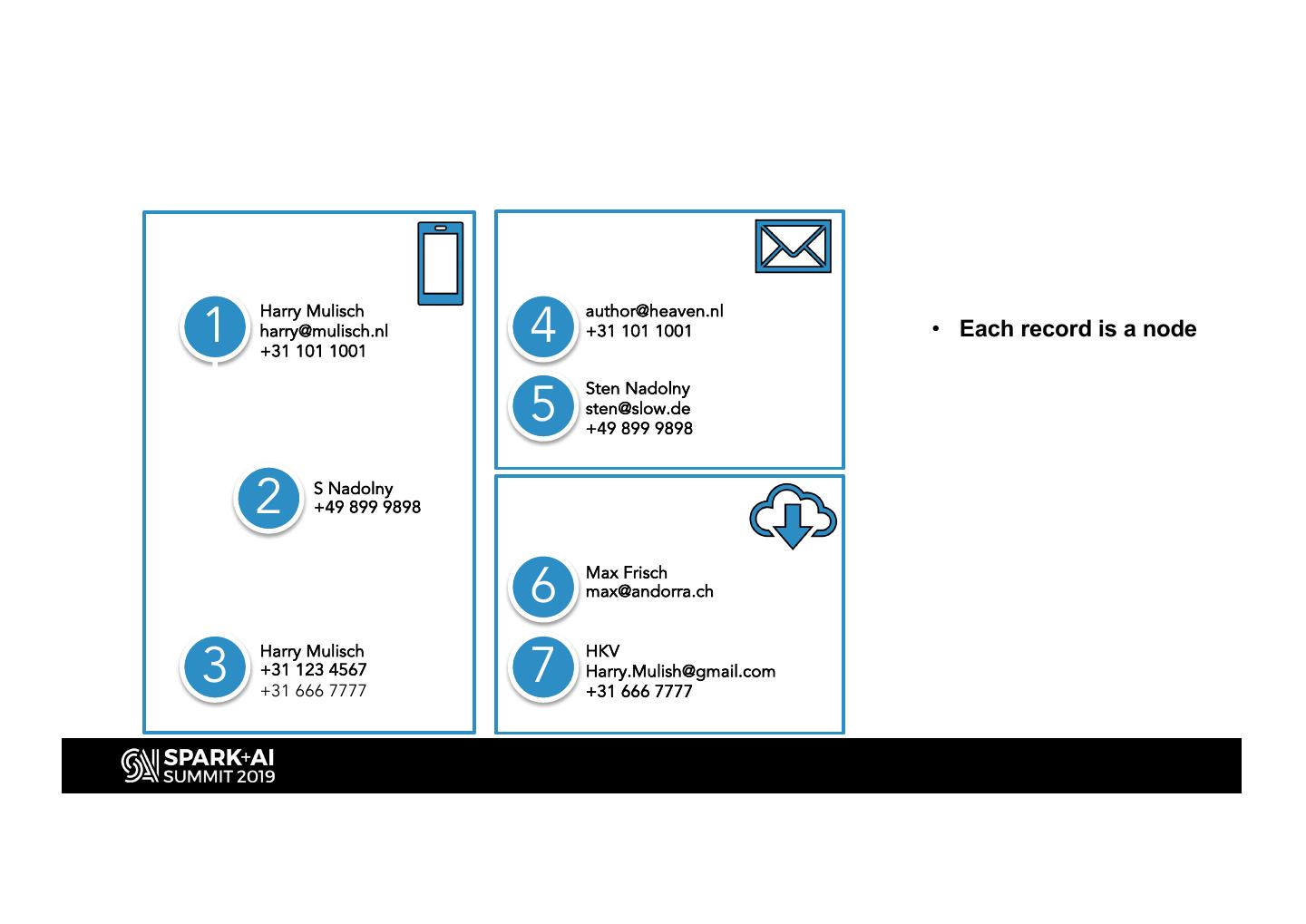
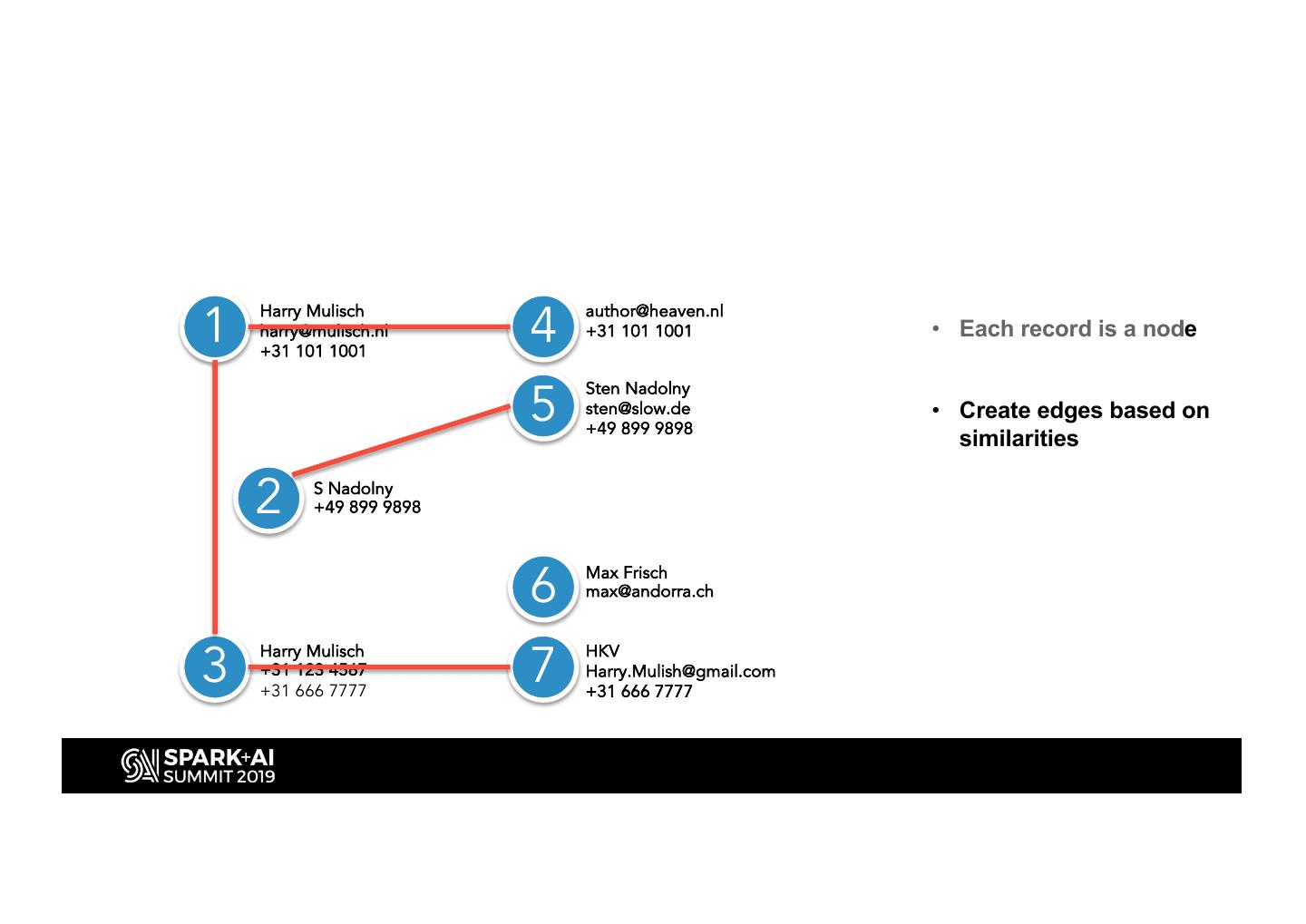
12 .1 4
Harry Mulisch author@heaven.nl
harry@mulisch.nl +31 101 1001 • Each record is a node
+31 101 1001
5
Sten Nadolny
sten@slow.de • Create edges based on
+49 899 9898
similarities
2 S Nadolny
+49 899 9898
• Collect connected
nodes
6 Max Frisch
max@andorra.ch
• Consolidate
3 7
Harry Mulisch HKV
+31 123 4567 Harry.Mulish@gmail.com
information in records
+31 666 7777 +31 666 7777
�
13 .1 4
Harry Mulisch author@heaven.nl
harry@mulisch.nl +31 101 1001 • Each record is a node
+31 101 1001
5
Sten Nadolny
sten@slow.de • Create edges based on
+49 899 9898
similarities
2 S Nadolny
+49 899 9898
• Collect connected
nodes
6 Max Frisch
max@andorra.ch
• Consolidate
3 7
Harry Mulisch HKV
+31 123 4567 Harry.Mulish@gmail.com
information in records
+31 666 7777 +31 666 7777
Copyright 2019 © systemati.co
�
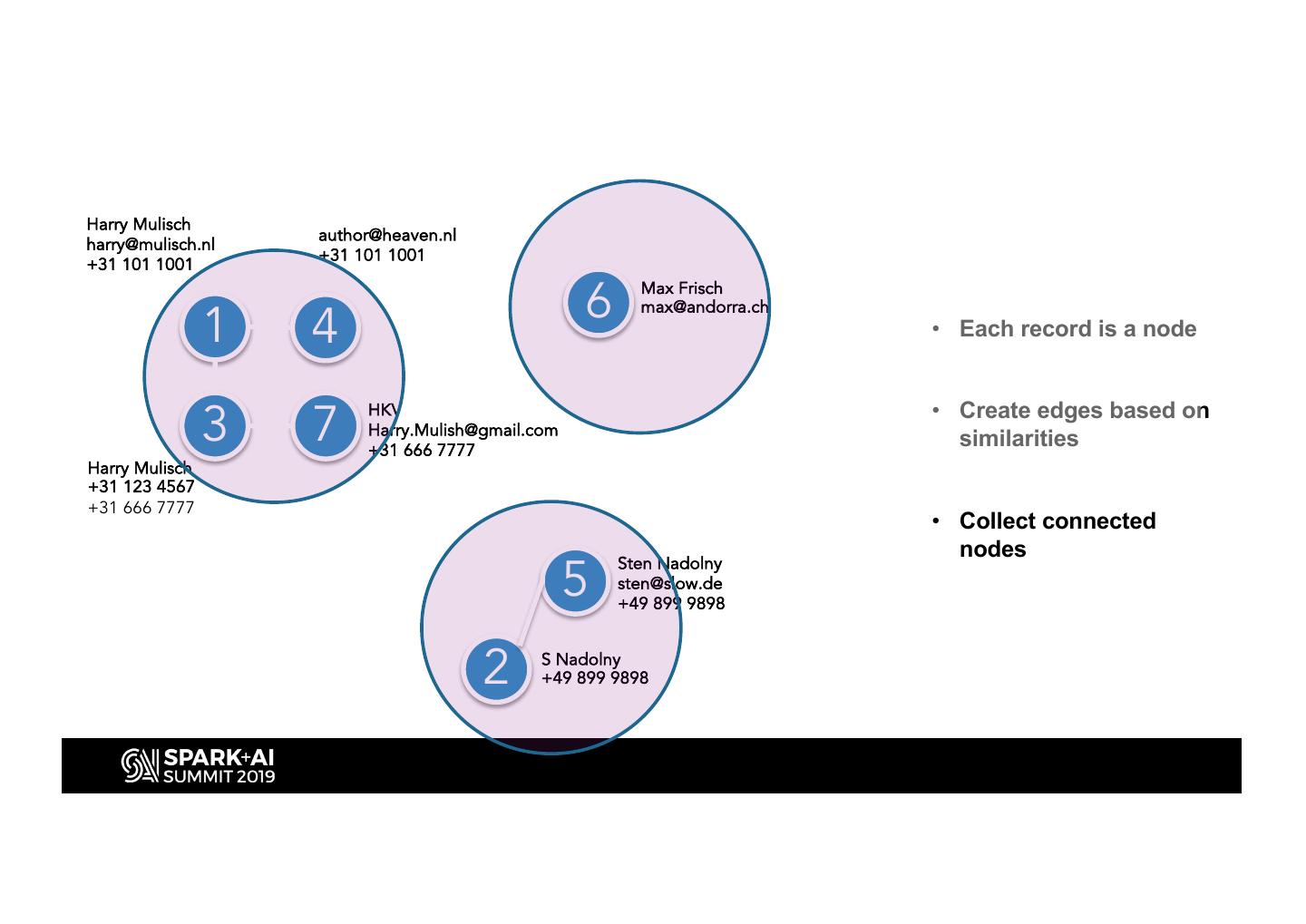
14 .Harry Mulisch
author@heaven.nl
harry@mulisch.nl
+31 101 1001
+31 101 1001
1 6 Max Frisch
4
max@andorra.ch
• Each record is a node
3 7 • Create edges based on
HKV
Harry.Mulish@gmail.com
+31 666 7777
similarities
Harry Mulisch
+31 123 4567
+31 666 7777
• Collect connected
nodes
5
Sten Nadolny
sten@slow.de
+49 899 9898
• Consolidate
2 S Nadolny
+49 899 9898
information in records
�
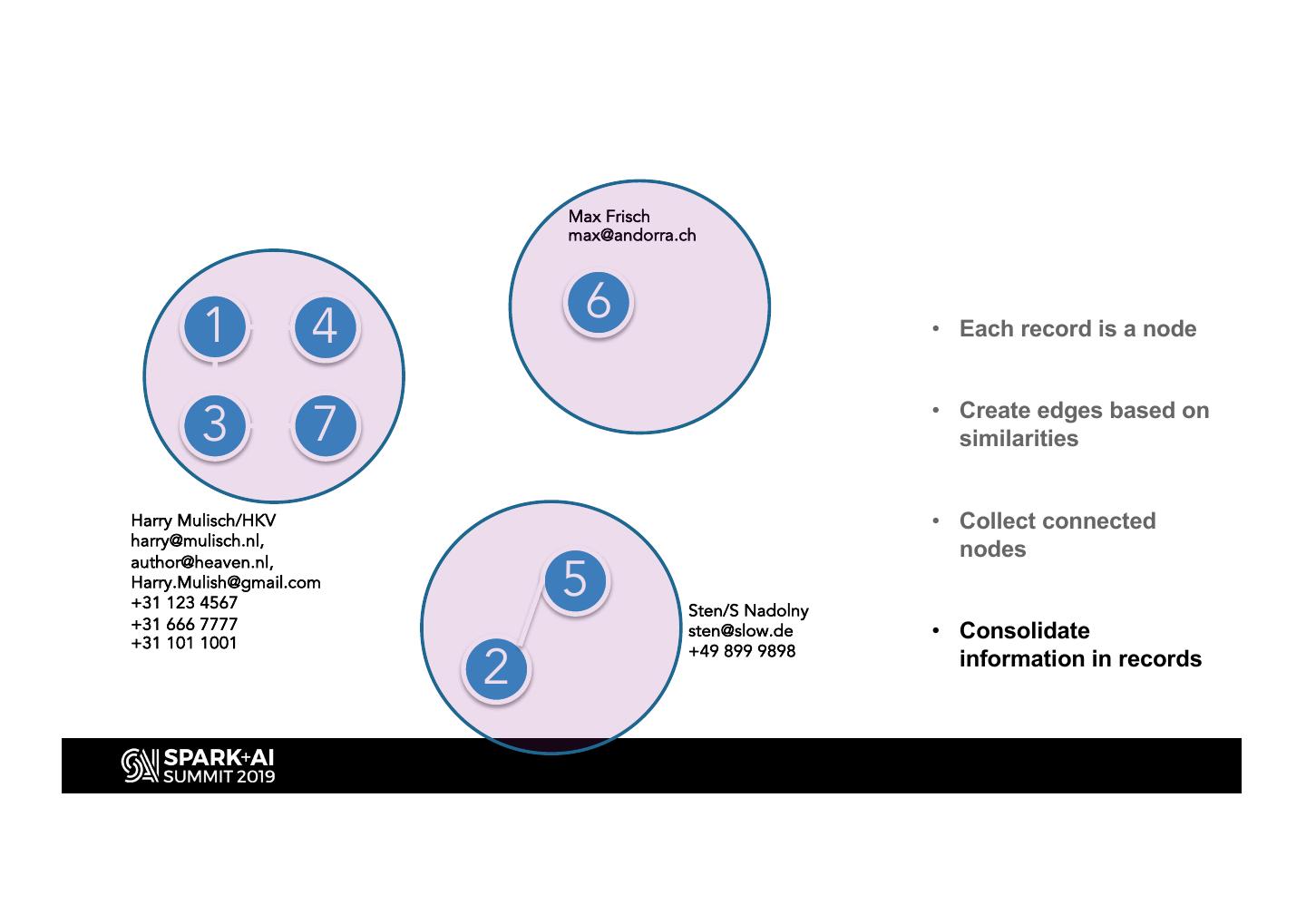
15 . Max Frisch
max@andorra.ch
1 6
4 • Each record is a node
3 7 • Create edges based on
similarities
Harry Mulisch/HKV • Collect connected
harry@mulisch.nl,
nodes
5
author@heaven.nl,
Harry.Mulish@gmail.com
+31 123 4567 Sten/S Nadolny
+31 666 7777
+31 101 1001
sten@slow.de • Consolidate
2
+49 899 9898
information in records
�
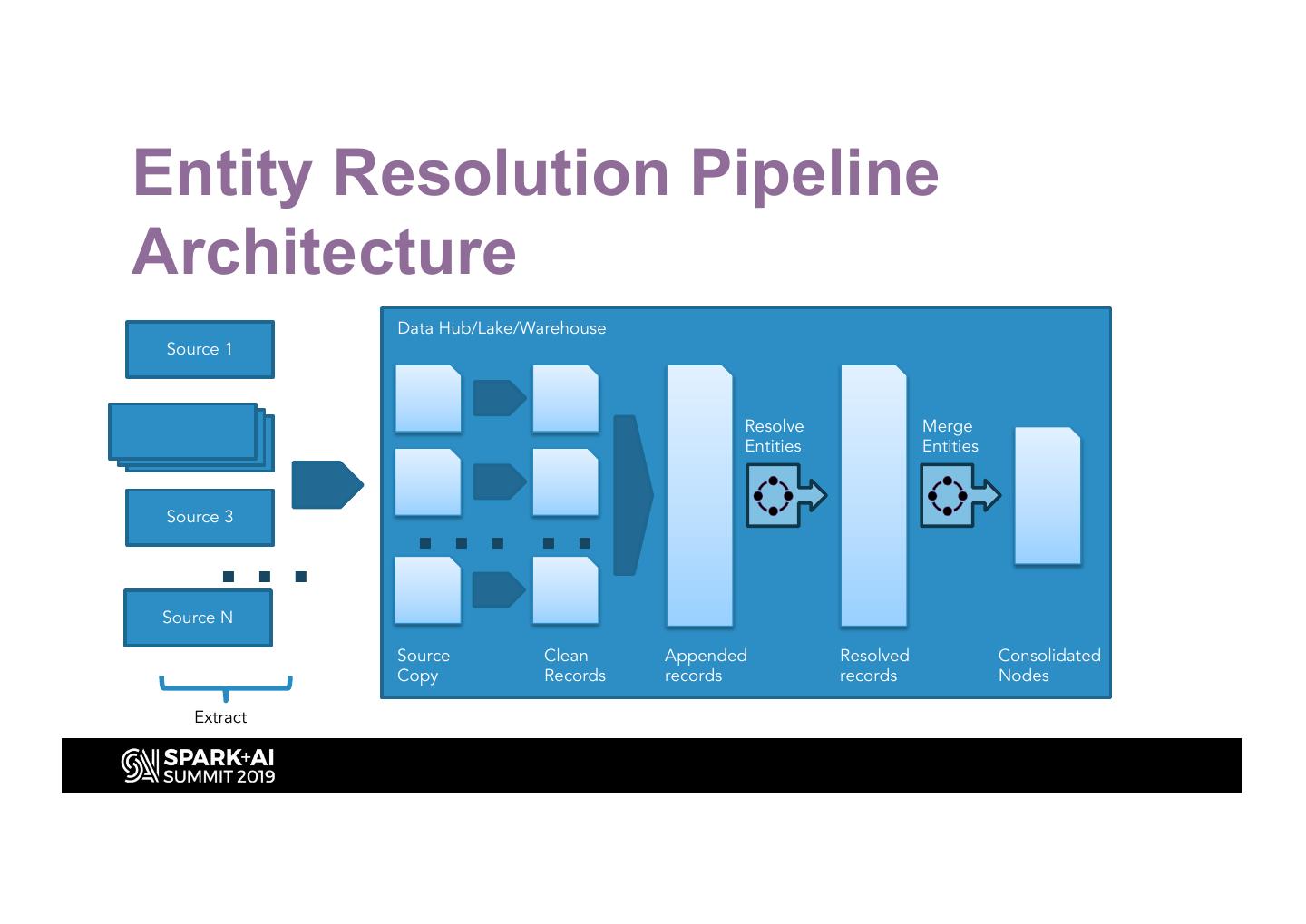
16 .Entity Resolution Pipeline
Architecture
Data Hub/Lake/Warehouse
Source 1
Resolve Merge
Entities Entities
… …
Source 3
…
Source N
Source Clean Appended Resolved Consolidated
Copy Records records records Nodes
Extract
�
17 .Technical Implementation
�
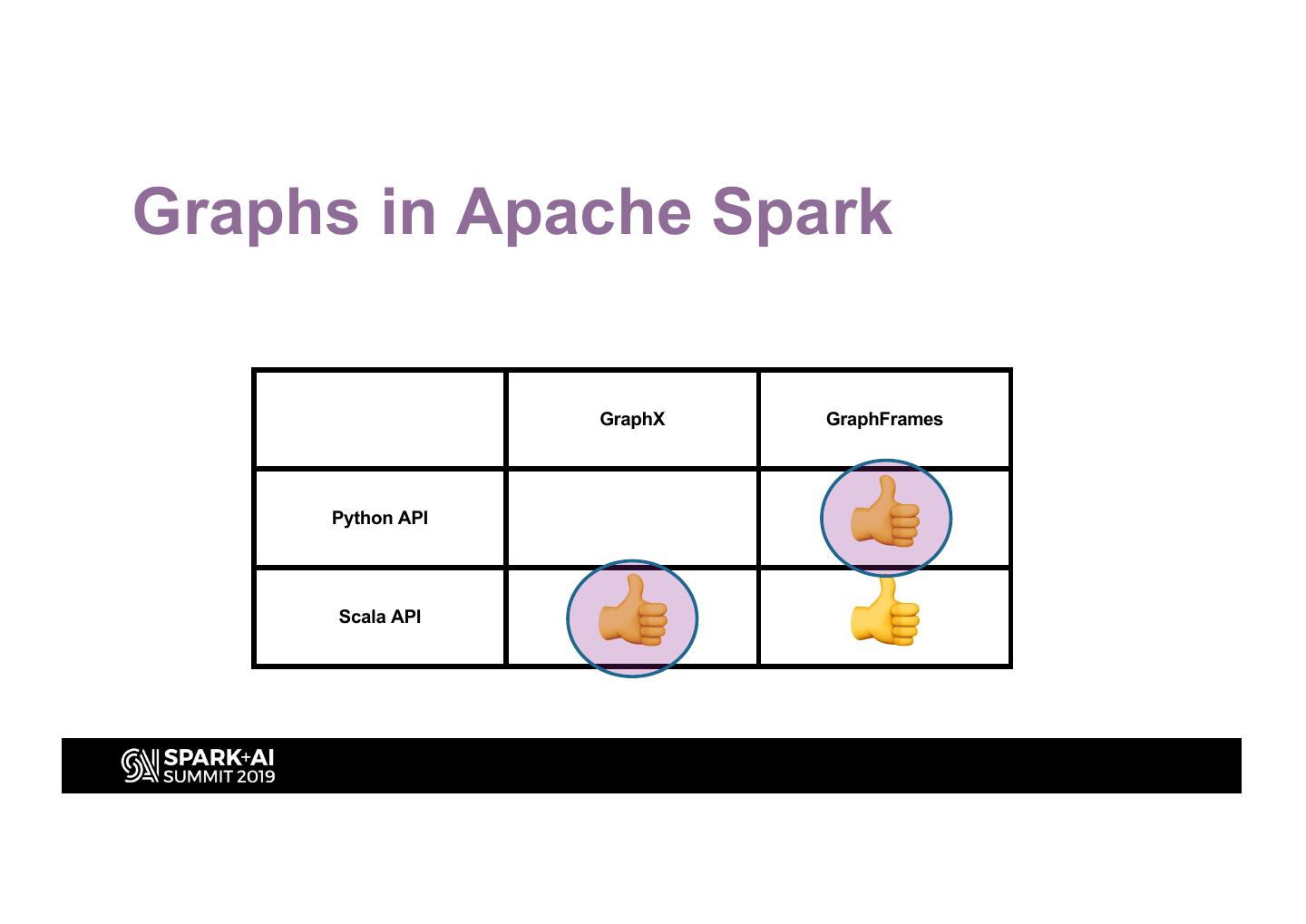
18 .Graphs in Apache Spark
GraphX GraphFrames
Python API
👍
Scala API
👍 👍
�
20 . Create nodes
• Add an id column to the dataframe of records
from pyspark.sql.functions import monotonically_increasing_id
nodes = records.withColumn("id", monotonically_increasing_id())
Identifiers Attributes
+---+------------+-----------+-----------+---------+----------+--------------+
| id| ssn| email| phone| address| DoB| Name|
+---+------------+-----------+-----------+---------+----------+--------------+
| 0| 714-12-4462| len@sma.ll| 6088881234| ...| 15/4/1937| Lennie Small |
| 1| 481-33-1024| geo@mil.tn| 6077654980| ...| 15/4/1937| Goerge Milton|
�
21 .Edge creation
match_cols = [”ssn", ”email"]
mirrorColNames = [f"_{col}" for col in records.columns]
mirror = records.toDF(*mirrorColNames)
mcond = [col(c) == col(f'_{c}') for c in match_cols]
cond = [(col("id") != col("_id")) & \
reduce(lambda x,y: x | y, mcond)]
edges = records.join(mirror, cond)
cond:
[Column<b'((NOT (id = _id)) AND (((ssn = _ssn) OR (email = _email))
�
22 .Resolve entities and consolidation
• Connected Components
graph = gf.GraphFrame(nodes, edges)
sc.setCheckpointDir("/tmp/checkpoints")
cc = graph.connectedComponents()
• Consolidate Components
entities = cc.groupby(”components”).collect_set(”name”)
�
24 .Strongly Typed Scala
• Defining the schema of our data
val record_schema = StructType( Seq(
StructField(name = ”id", dataType = LongType, nullable = false),
StructField(name = ”name", StringType, true),
StructField(name = ”email", StringType, true),
StructField(name = ”ssn", LongType, true),
StructField(name = ”attr", StringType, true)
))
24
�
25 .Node creation
• Add an ID column to records
• Turn DataFrame into RDD
val nodesRDD = records.map(r => (r.getAs[VertexId]("id"), 1)).rdd
�
26 . Edge creation
val mirrorColNames = for (col <- records.columns) yield "_"+col.toString
val mirror = records.toDF(mirrorColNames: _*)
def conditions(matchCols: Seq[String]): Column = {
col("id")=!=col("_id") &&
matchCols.map(c => col(c)===col("_"+c)).reduce(_ || _)
}
val edges = records.join(mirror, conditions(Seq(”ssn", ”email”)))
val edgesRDD = edges
.select("id","_id")
.map(r => Edge(r.getAs[VertexId](0),r.getAs[VertexId](1),null))
.rdd
�
27 .Resolve entities and consolidation
• Connected Components
val graph = Graph(nodesRDD, edgesRDD)
val cc = graph.connectedComponents()
• Consolidate Components
val entities = cc.vertices.toDF()
val resolved_records = records.join(entities, $"id"===$"_1")
val res_records = resolved_records
.withColumnRenamed("_2", ”e_id")
.groupBy(”e_id")
.agg(collect_set($”name"))
�
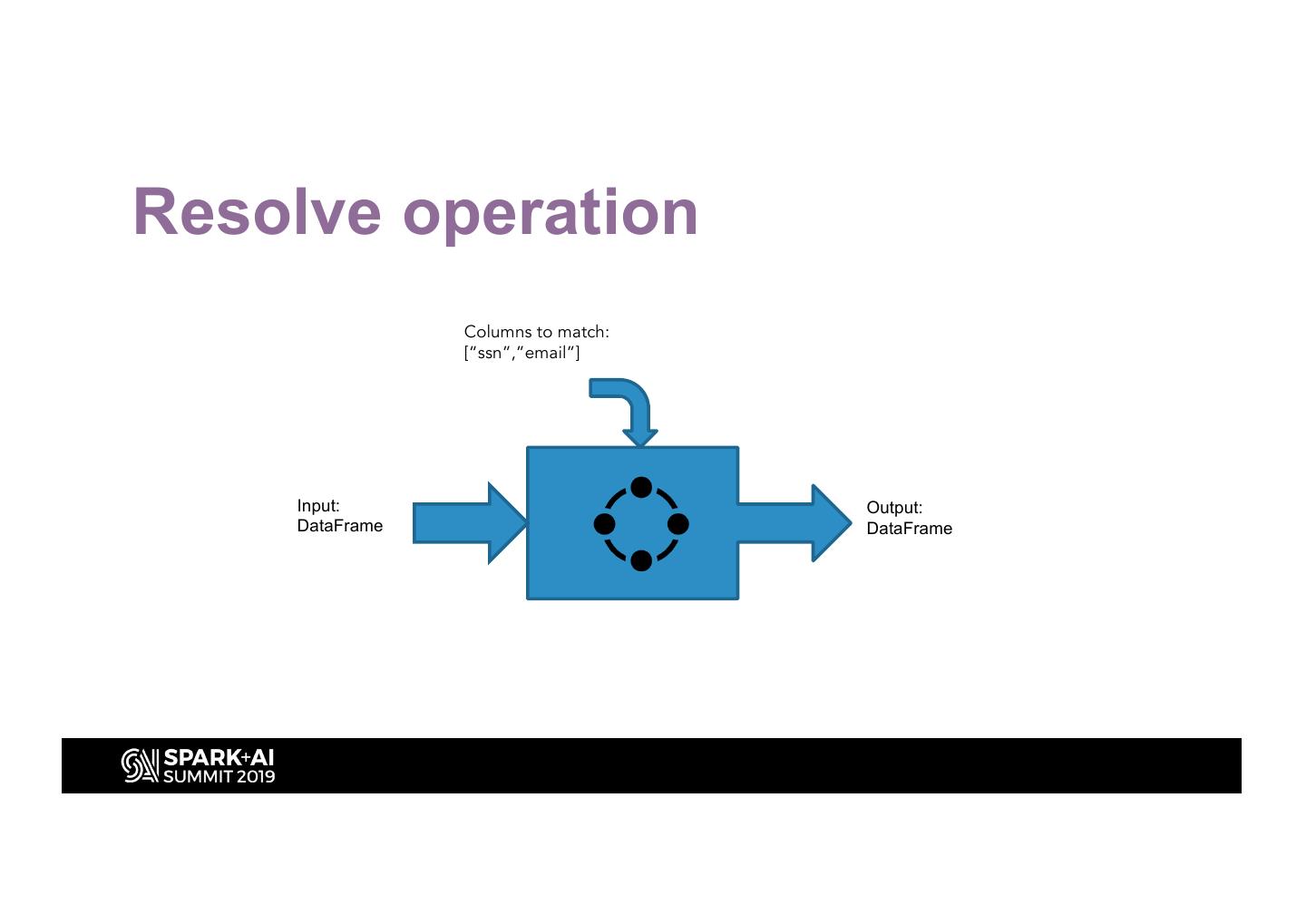
28 .Resolve operation
Columns to match:
[“ssn”,”email”]
Input: Output:
DataFrame DataFrame
�
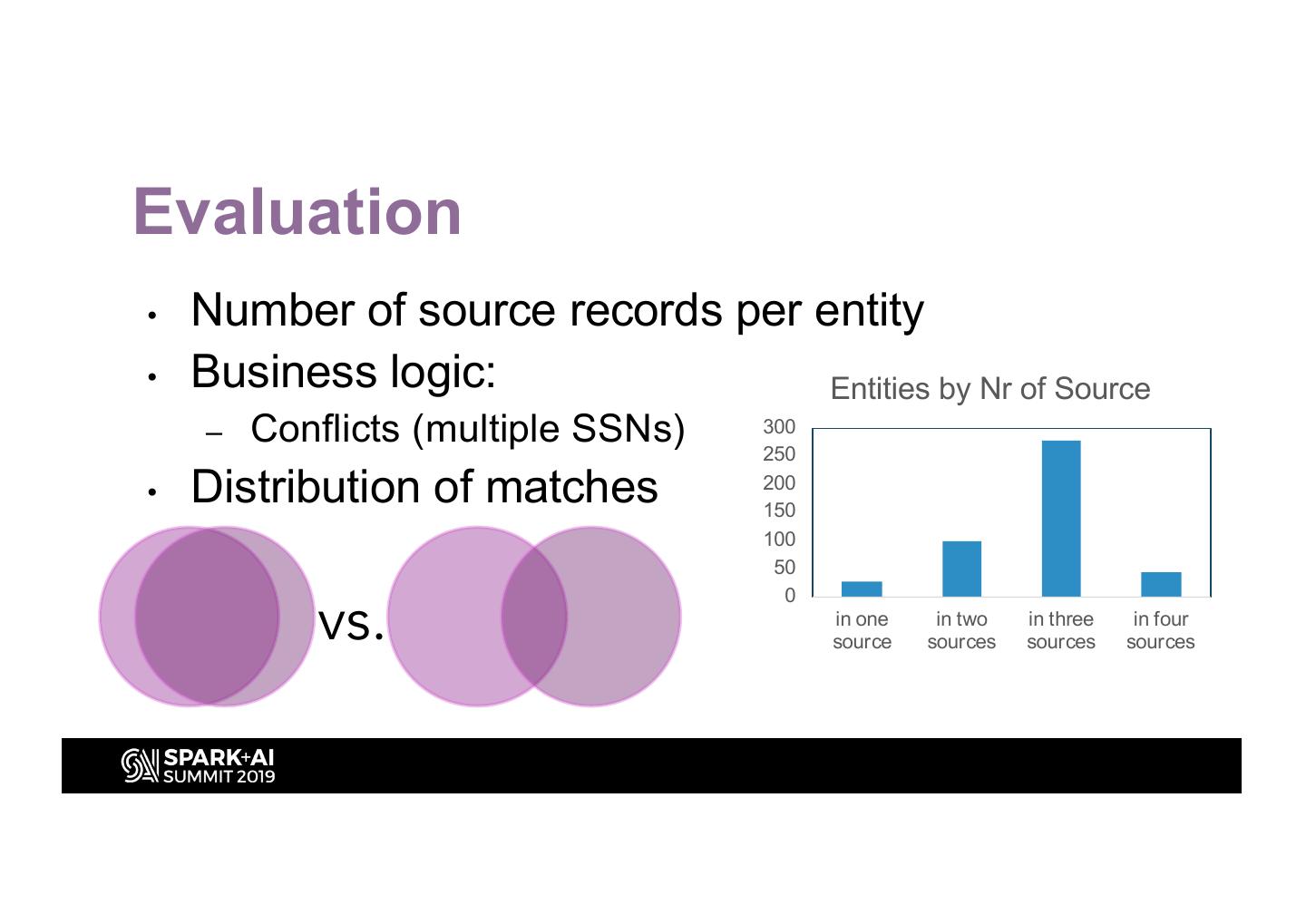
29 .Evaluation
• Number of source records per entity
• Business logic: Entities by Nr of Source
– Conflicts (multiple SSNs) 300
250
• Distribution of matches 200
150
100
50
vs.
0
in one in two in three in four
source sources sources sources
�