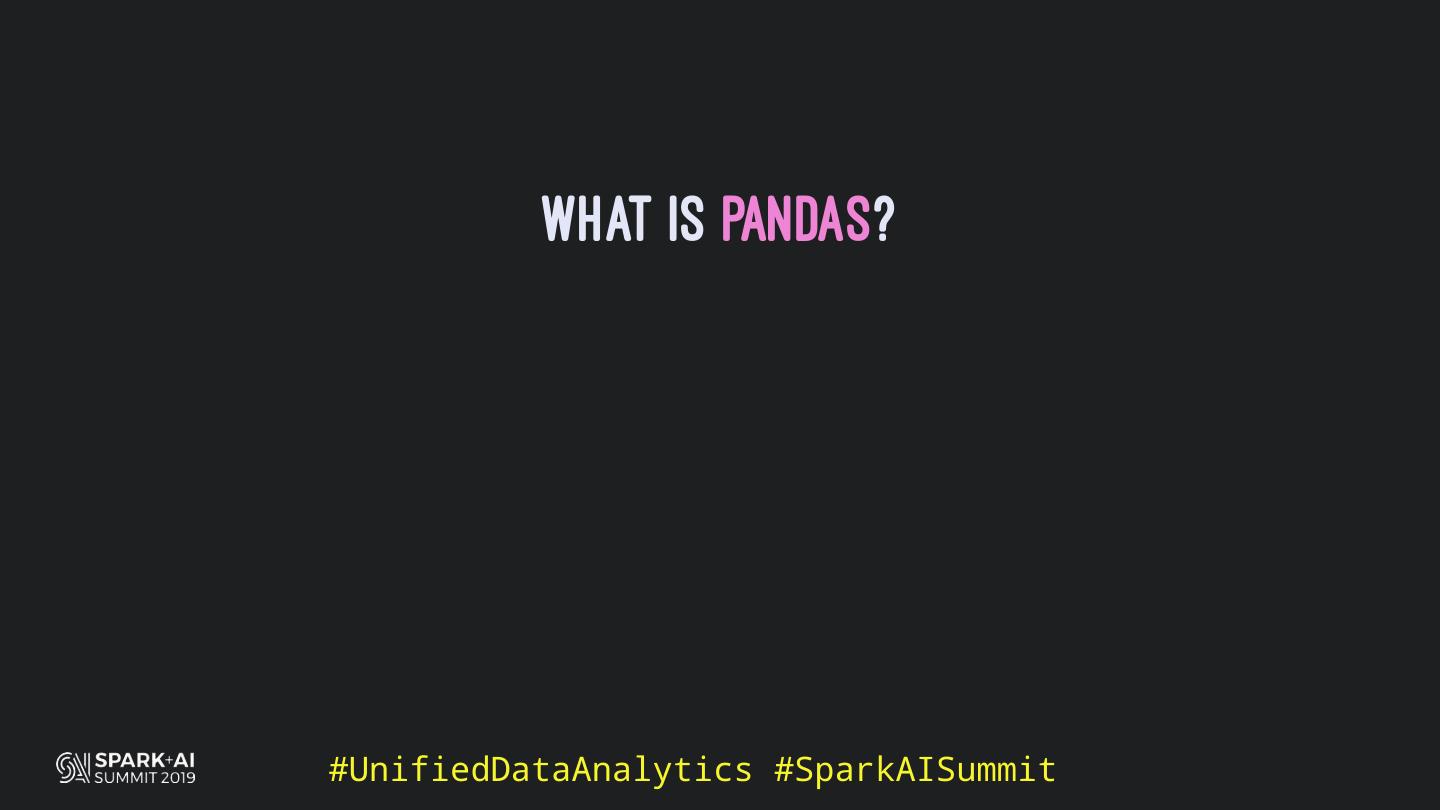Internals of Speeding up PySpark with Arrow
分享
点赞
12
收藏
5
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
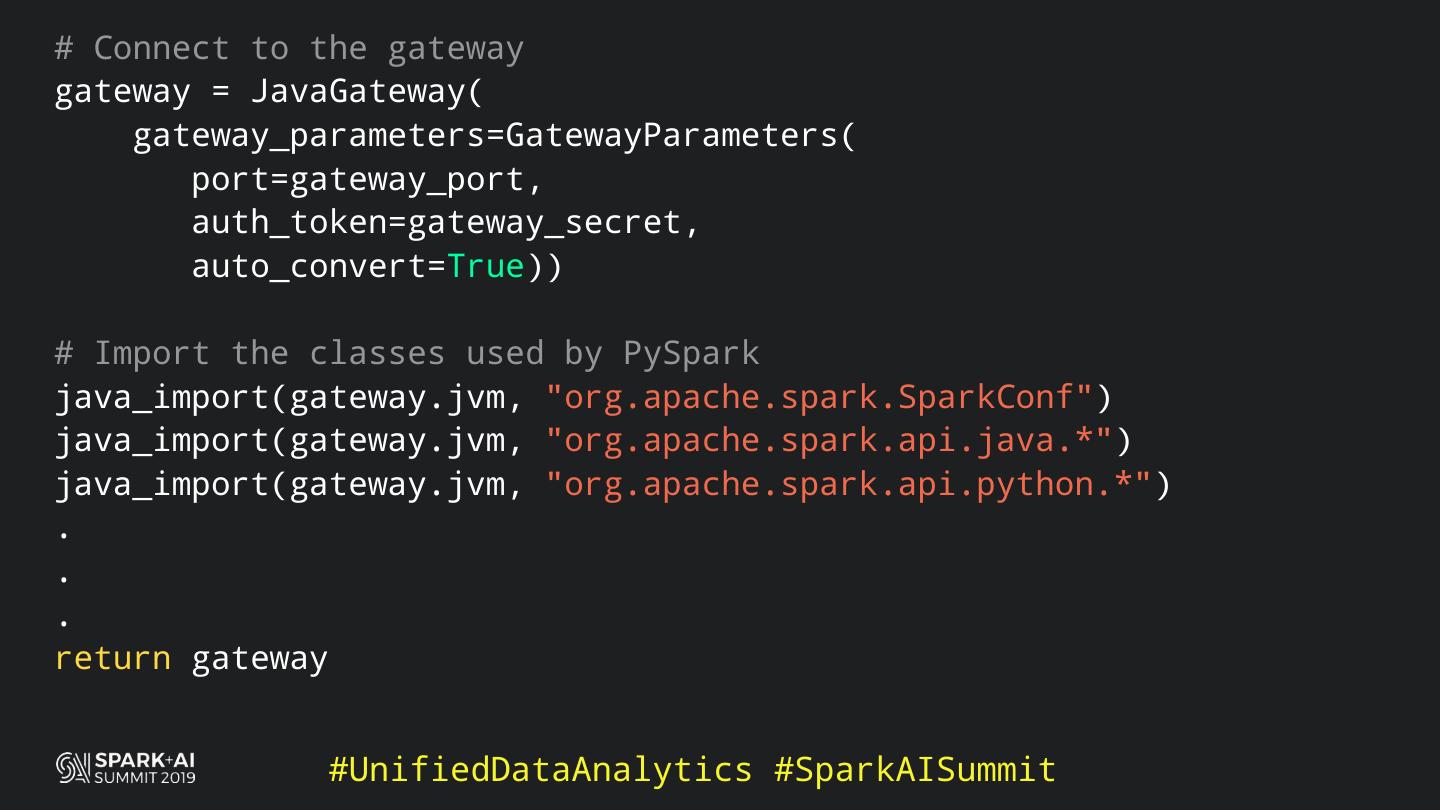
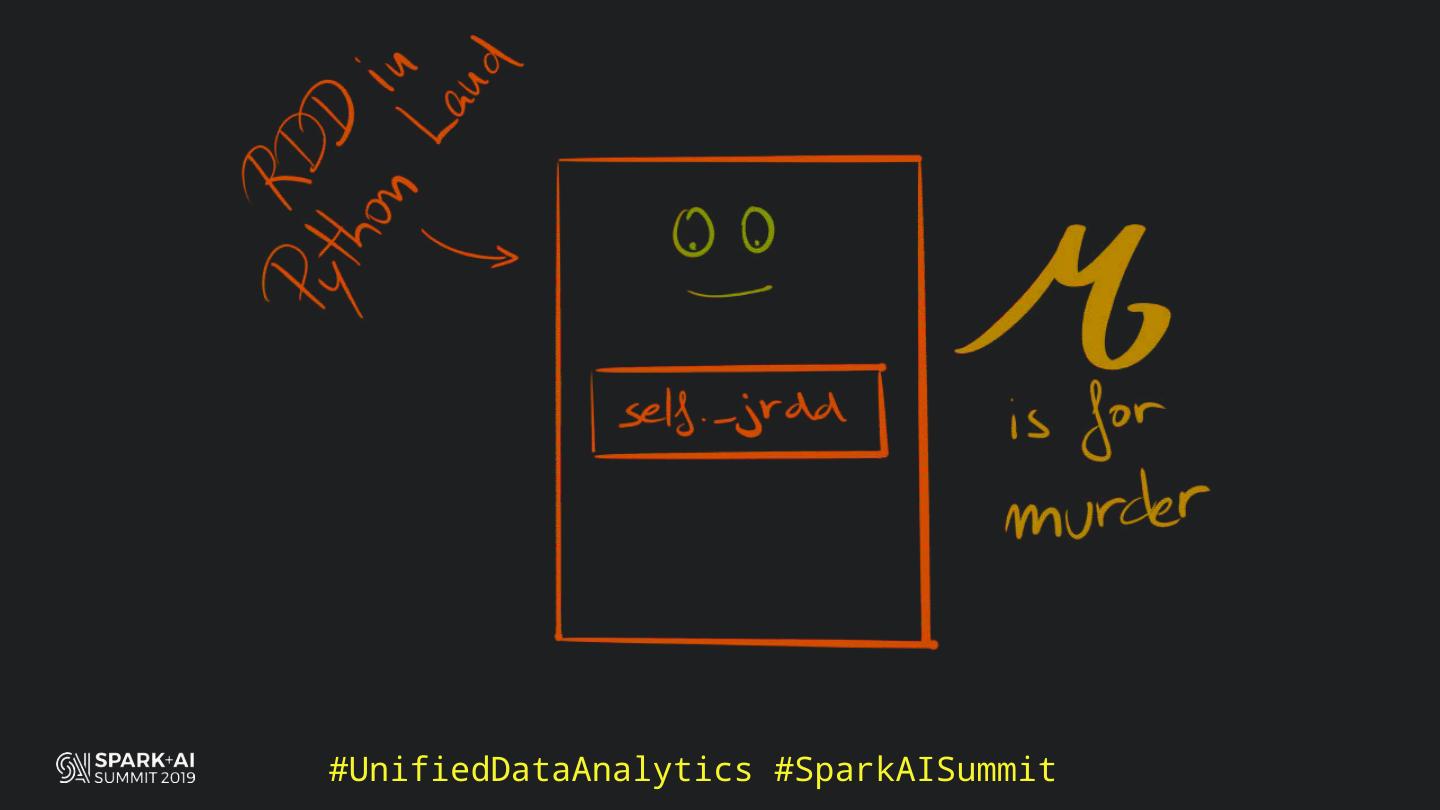
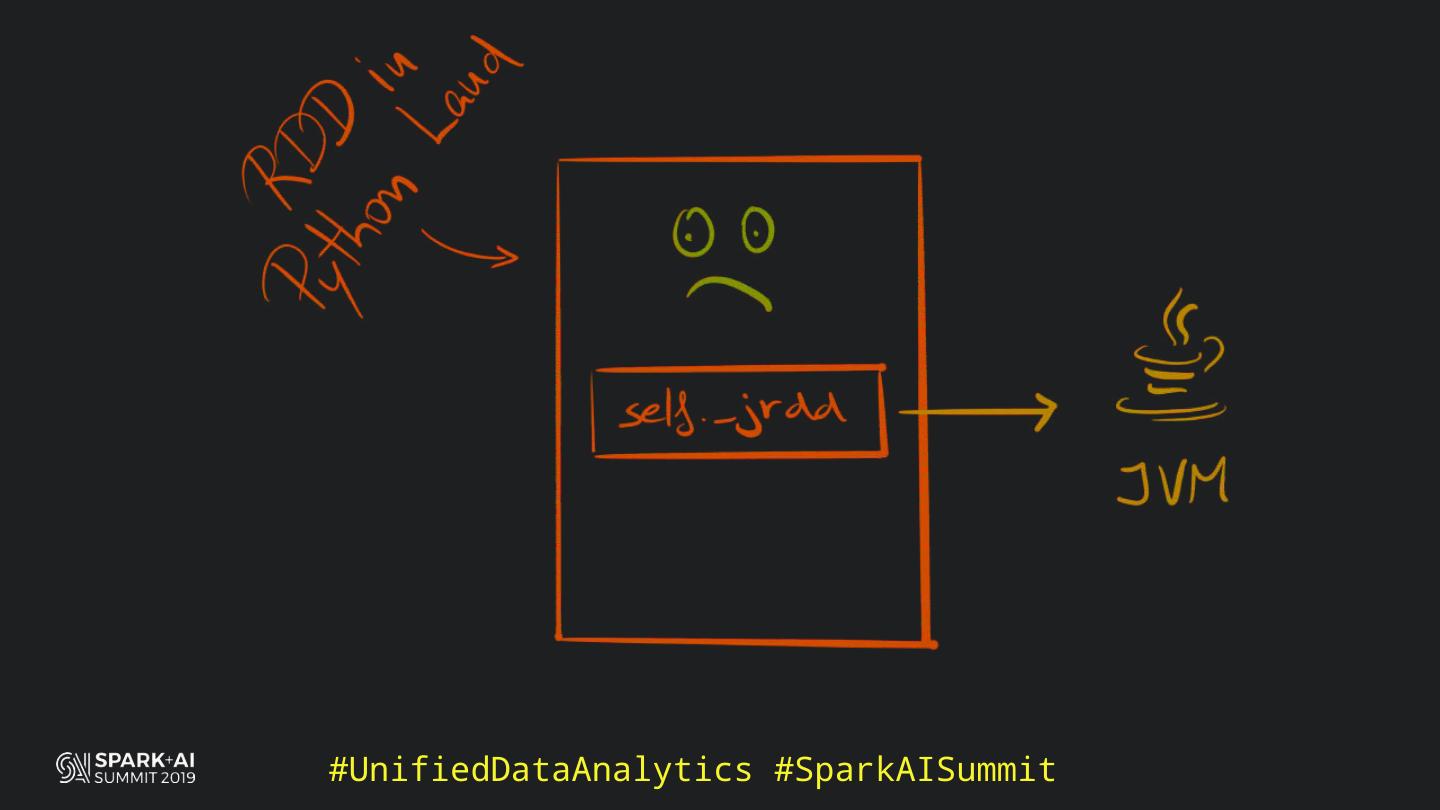
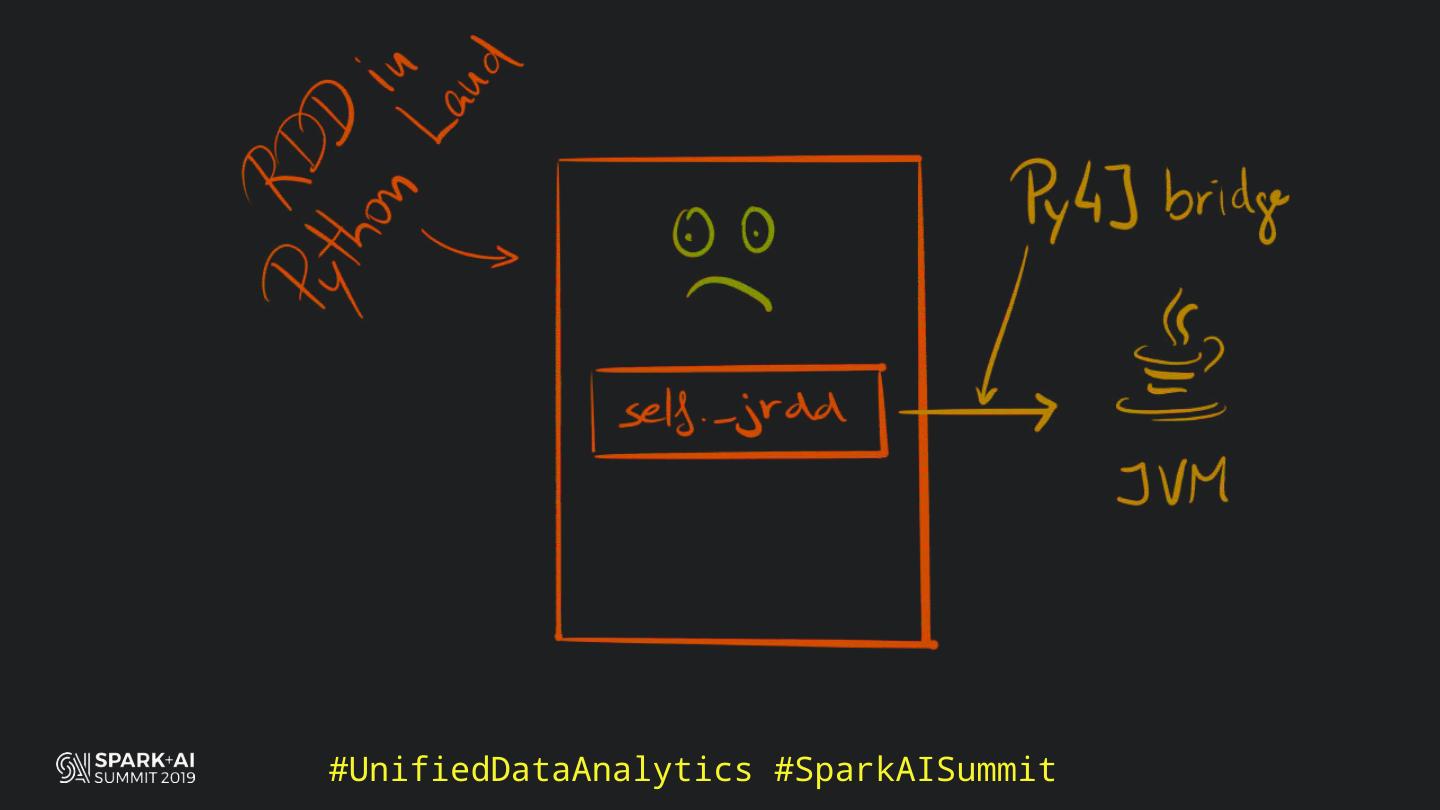
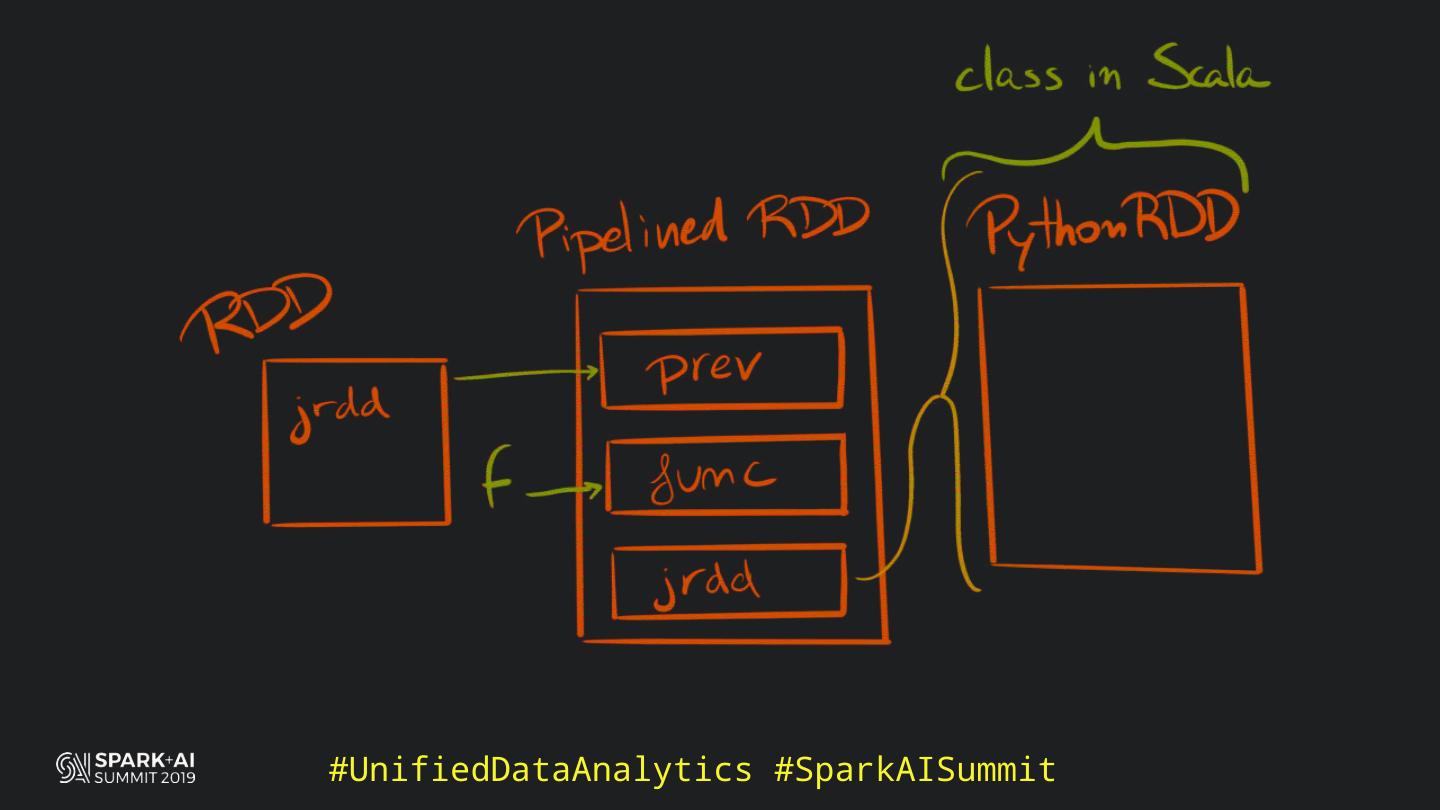
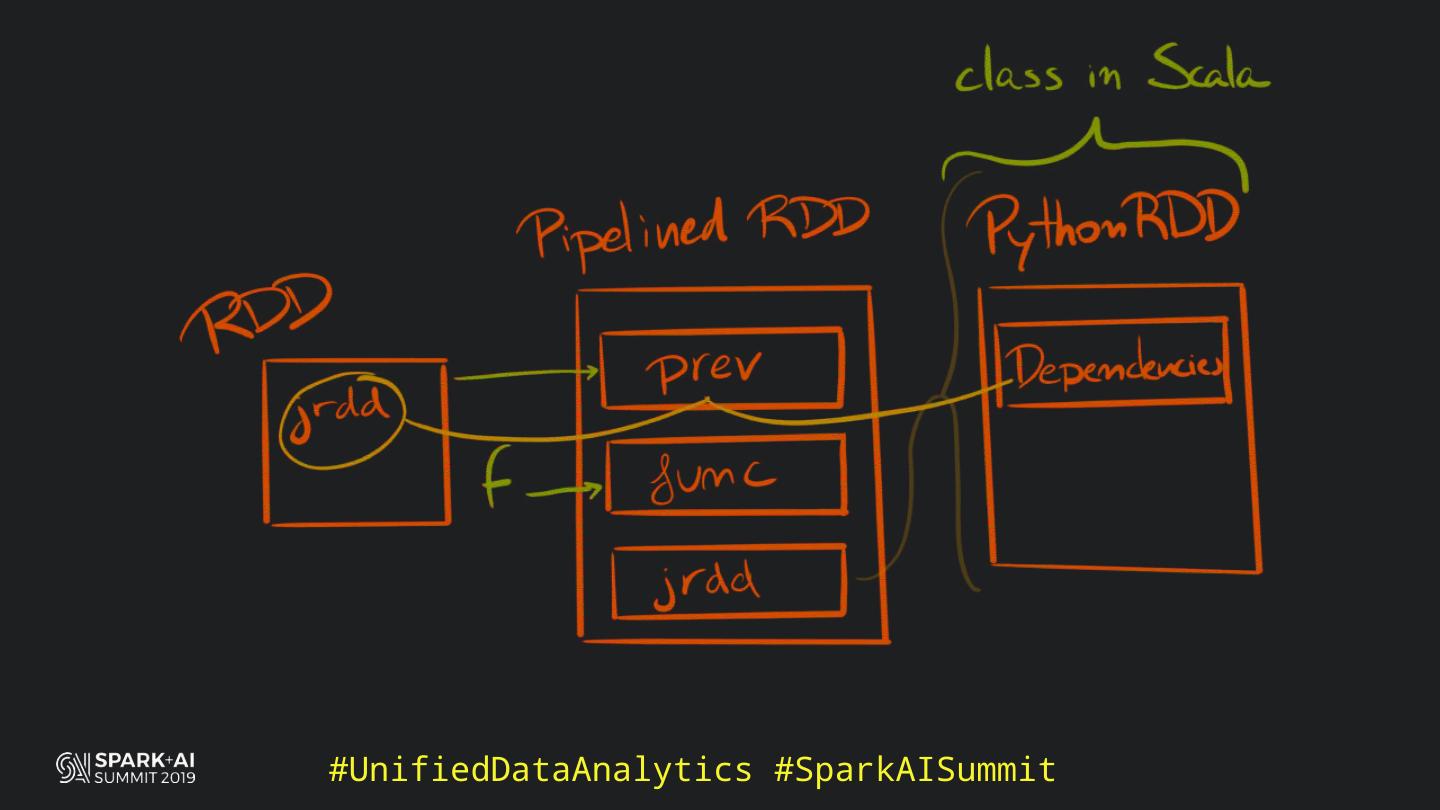
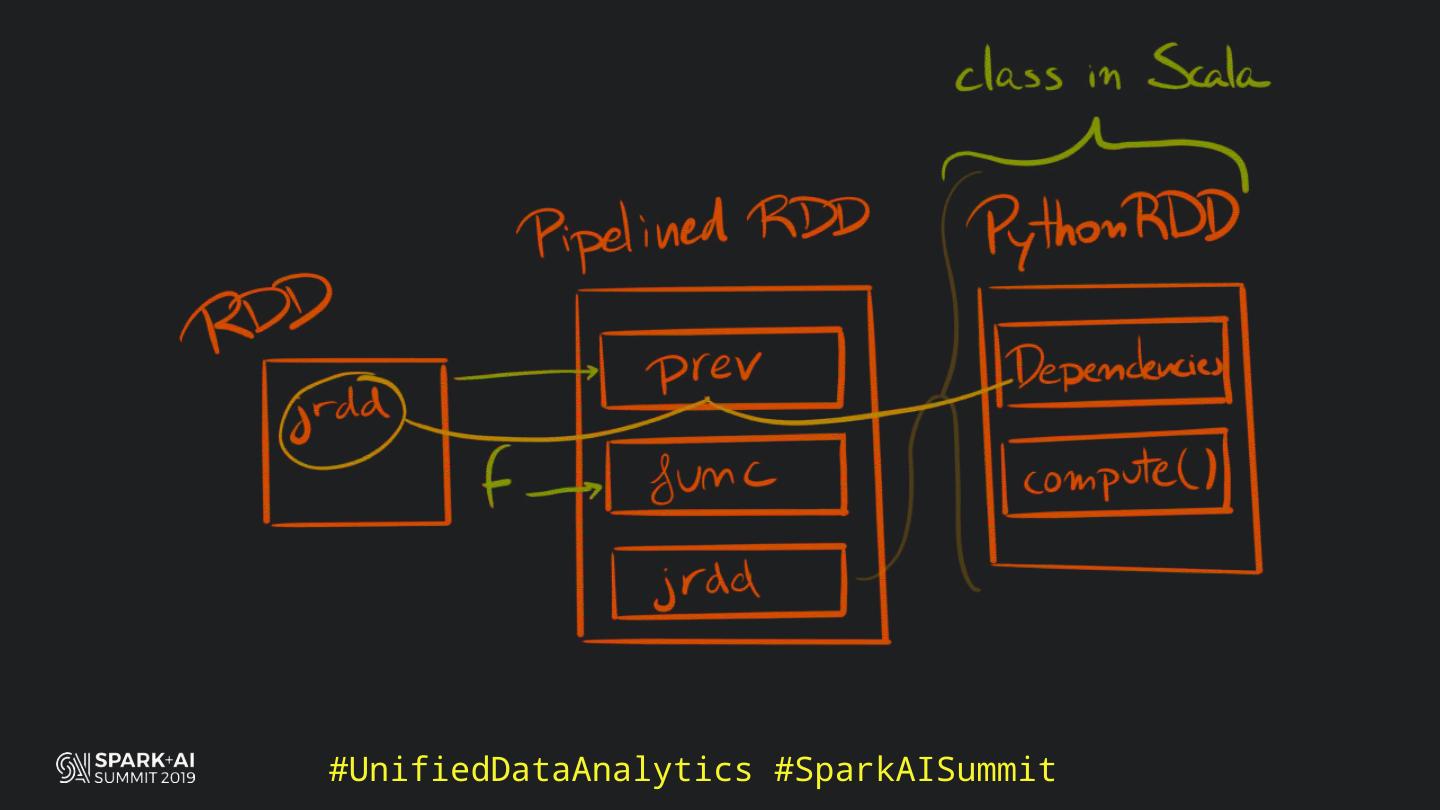
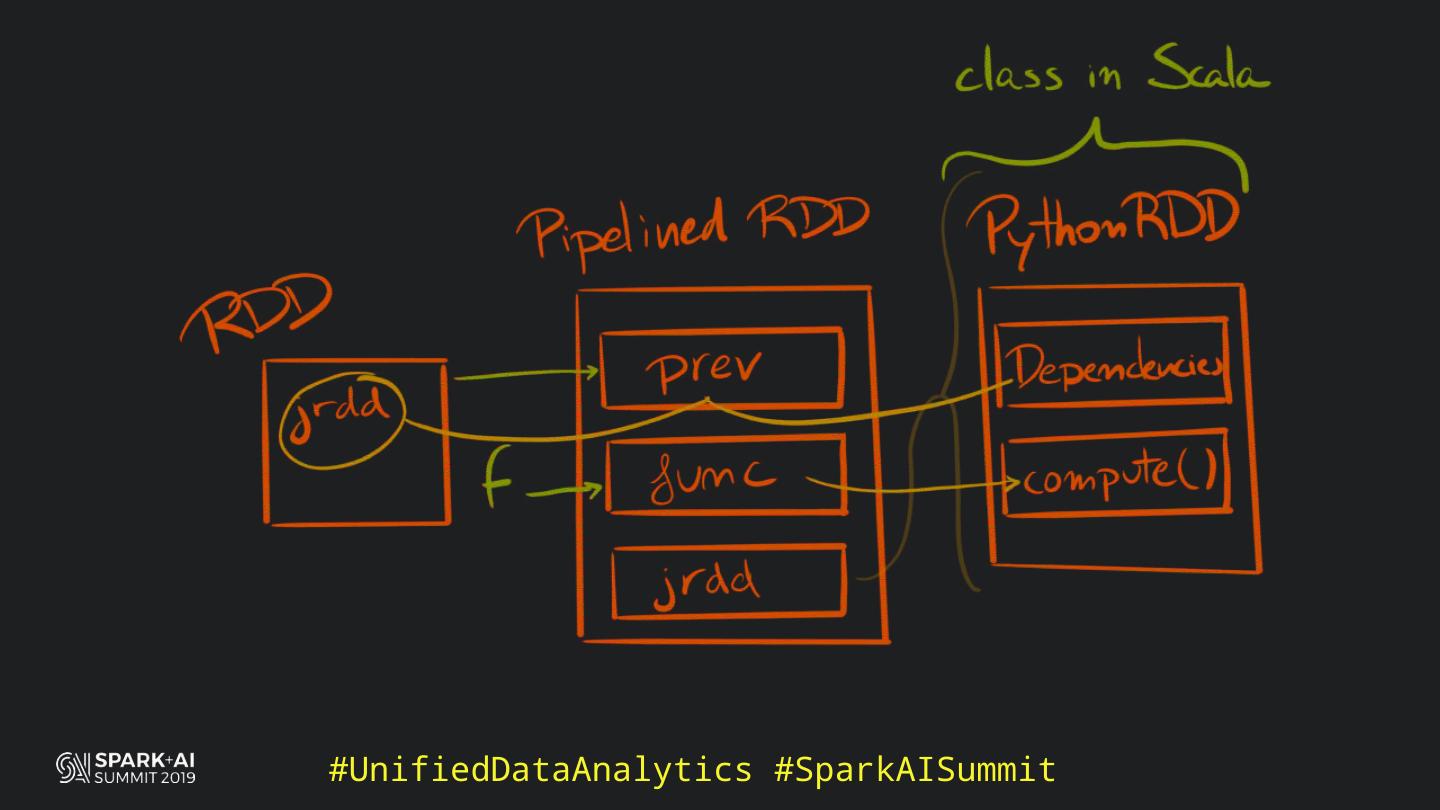
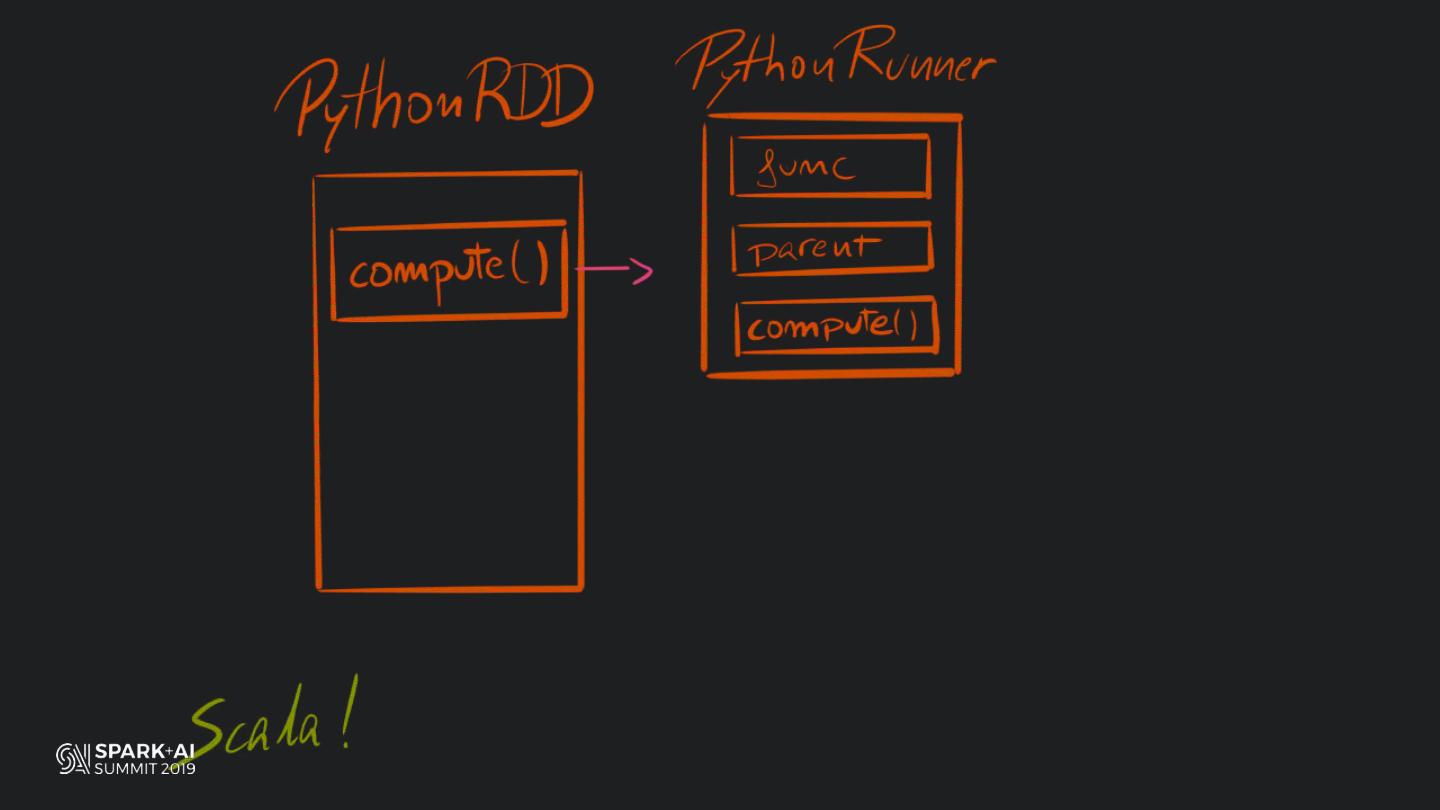
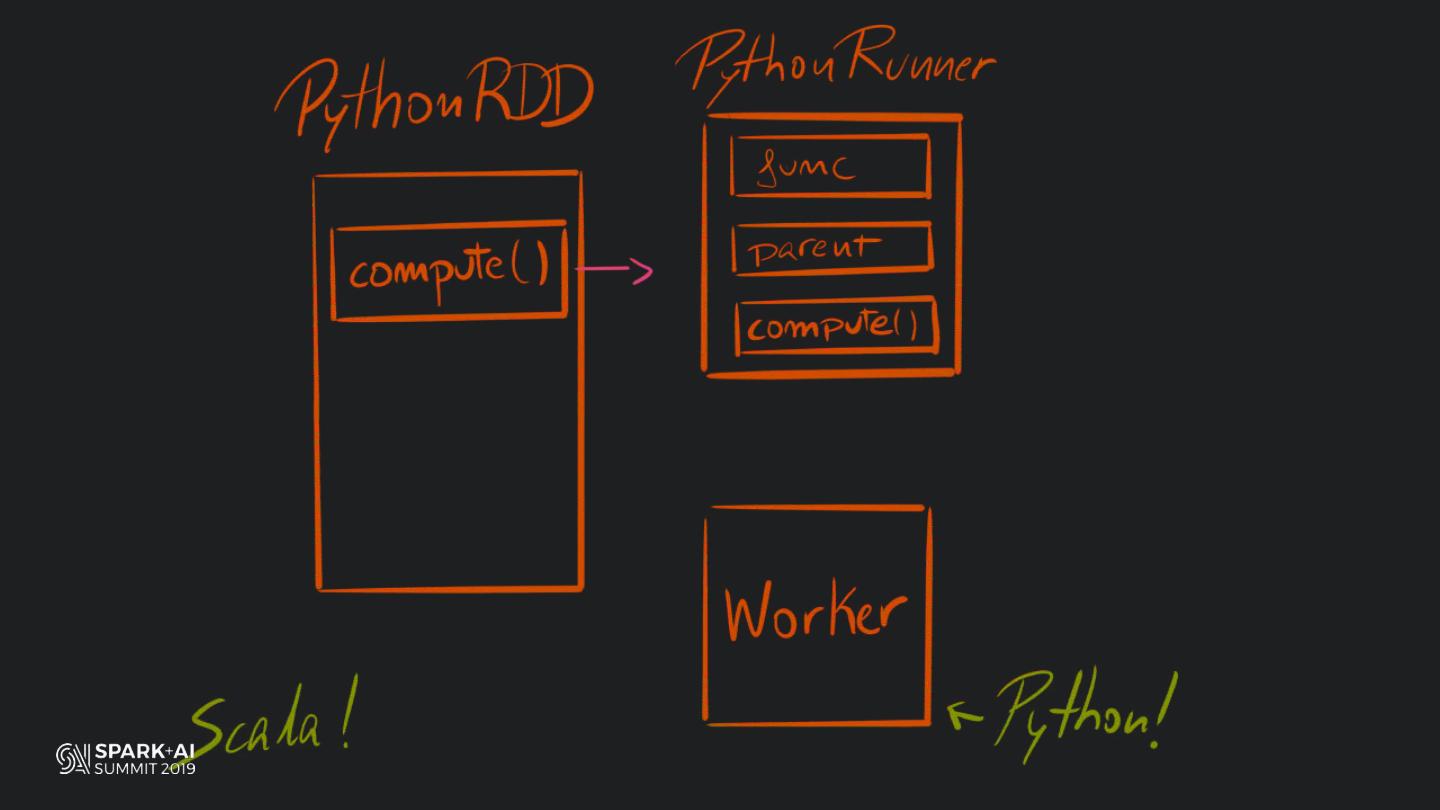
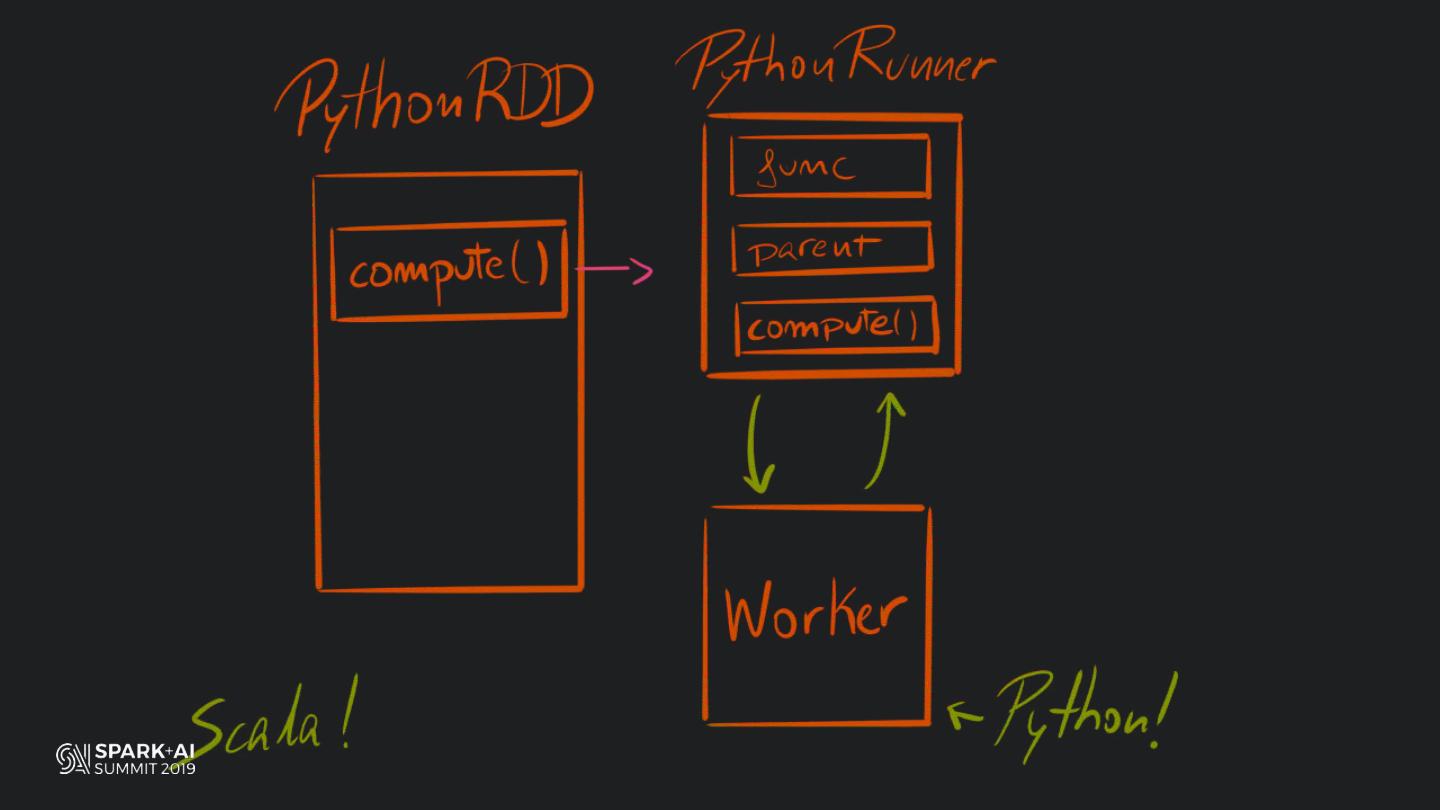
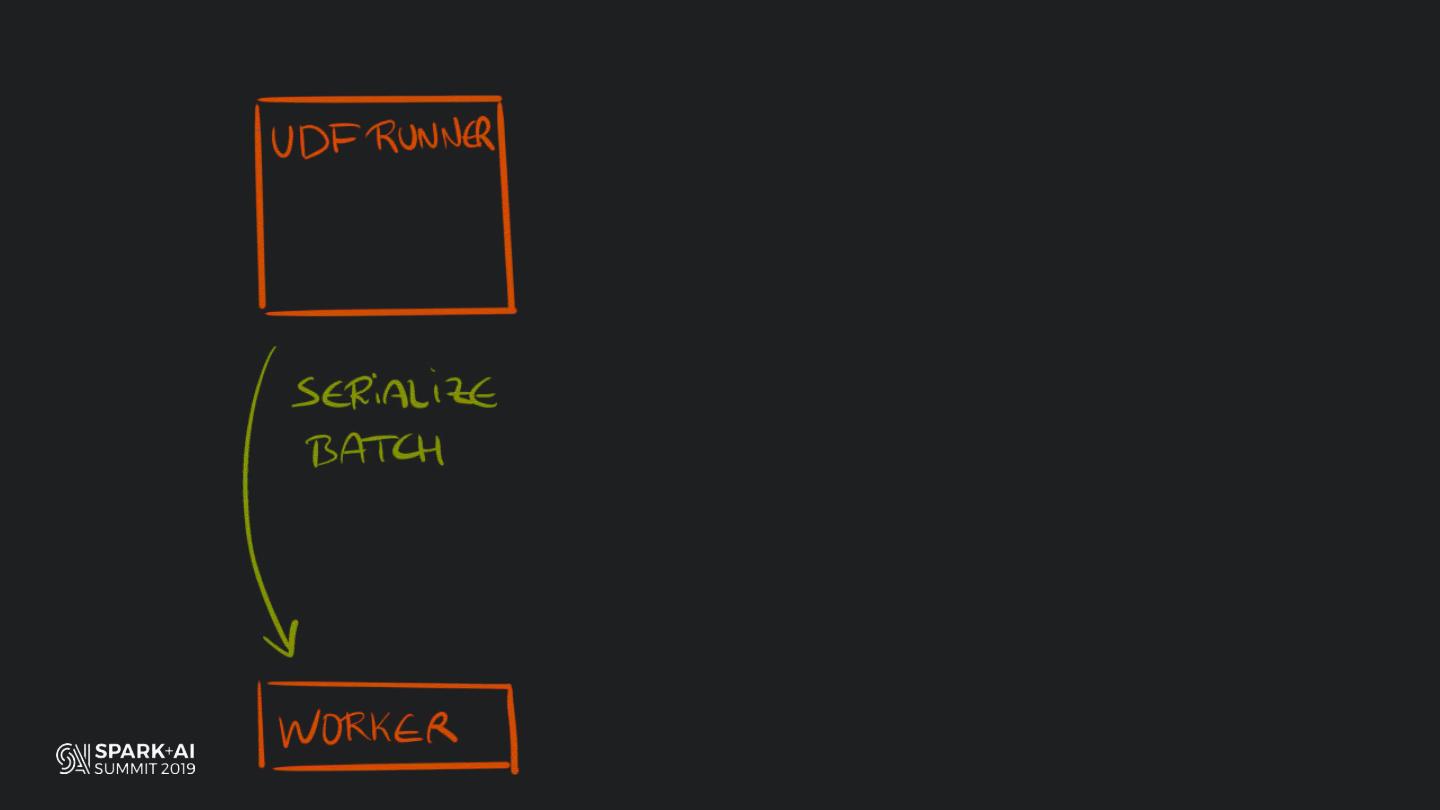
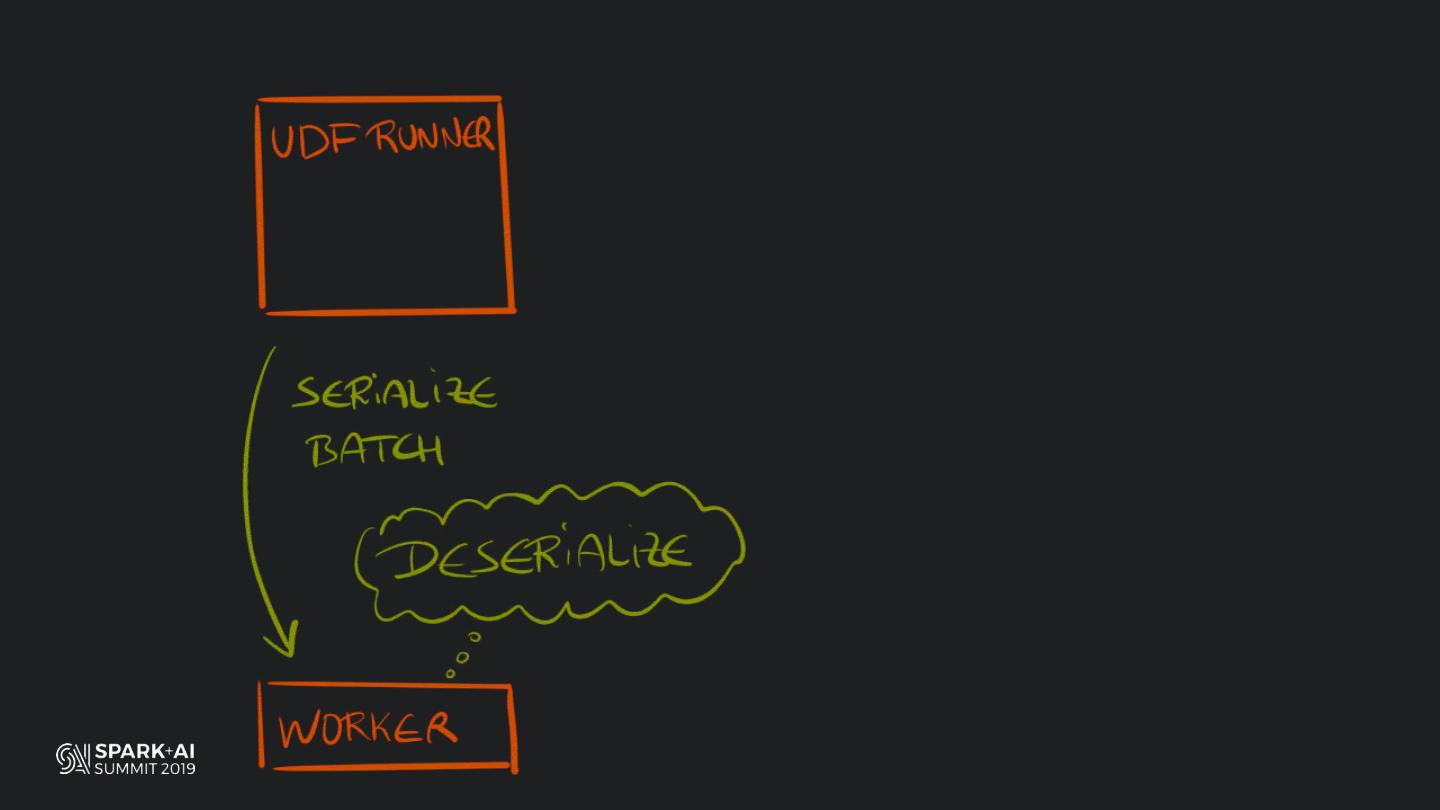
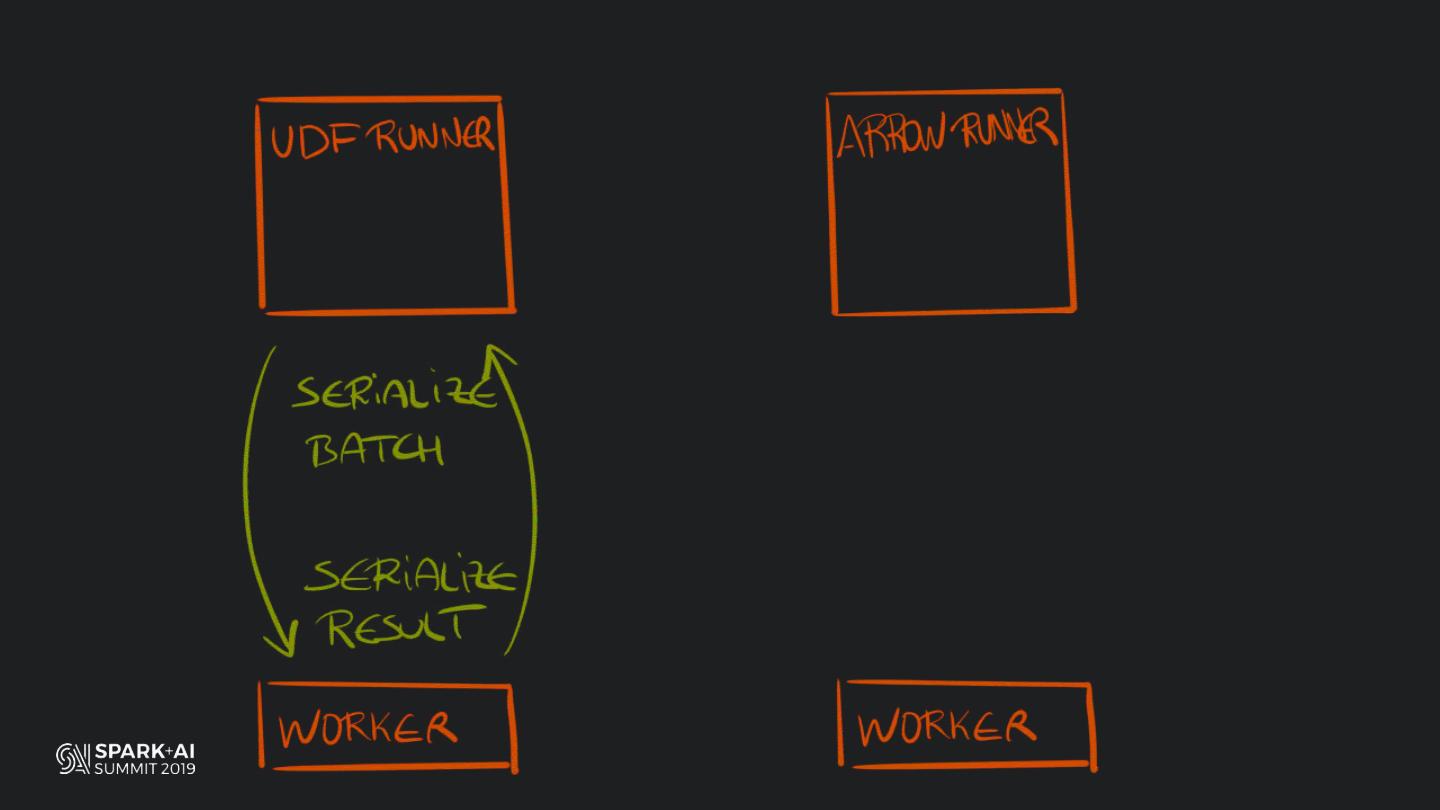
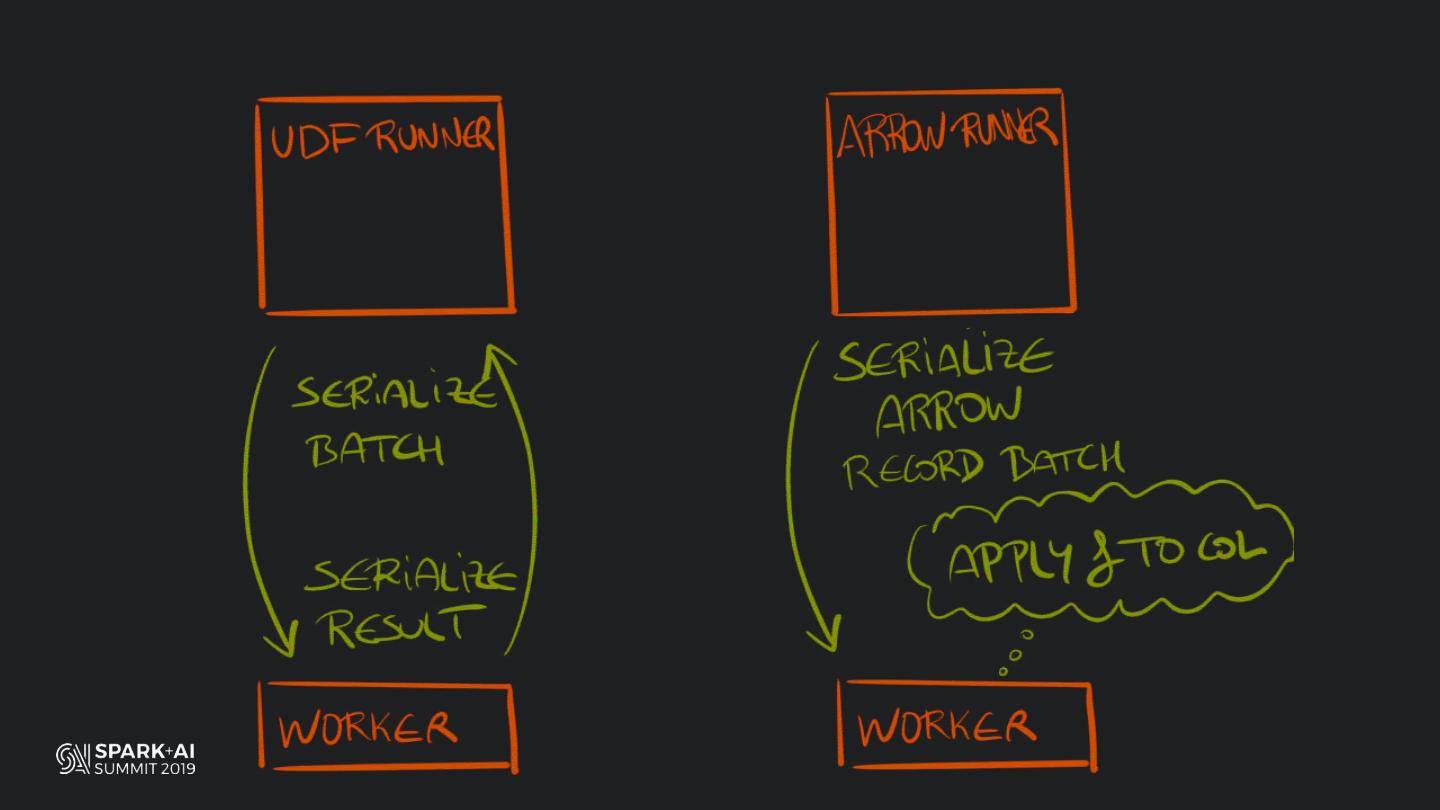
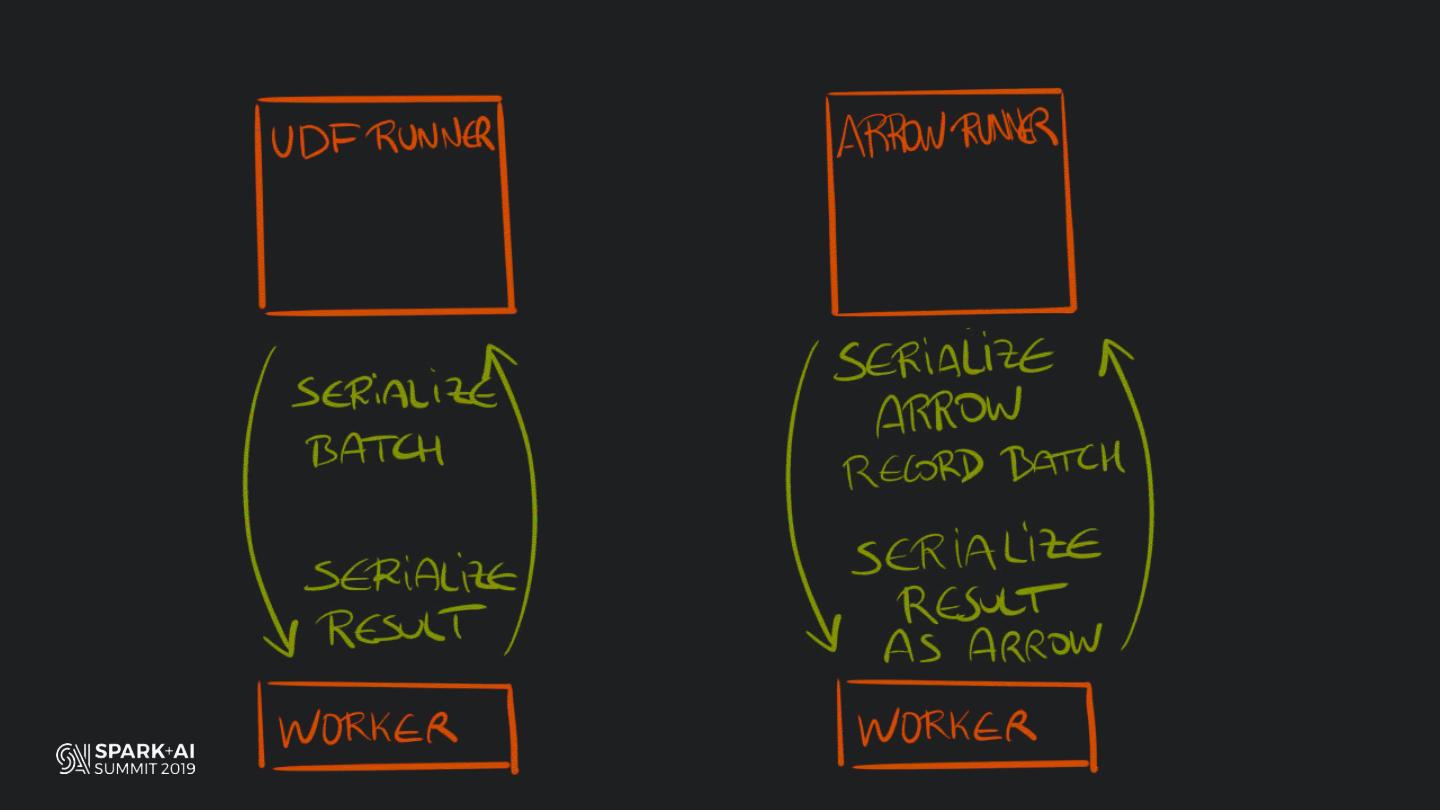
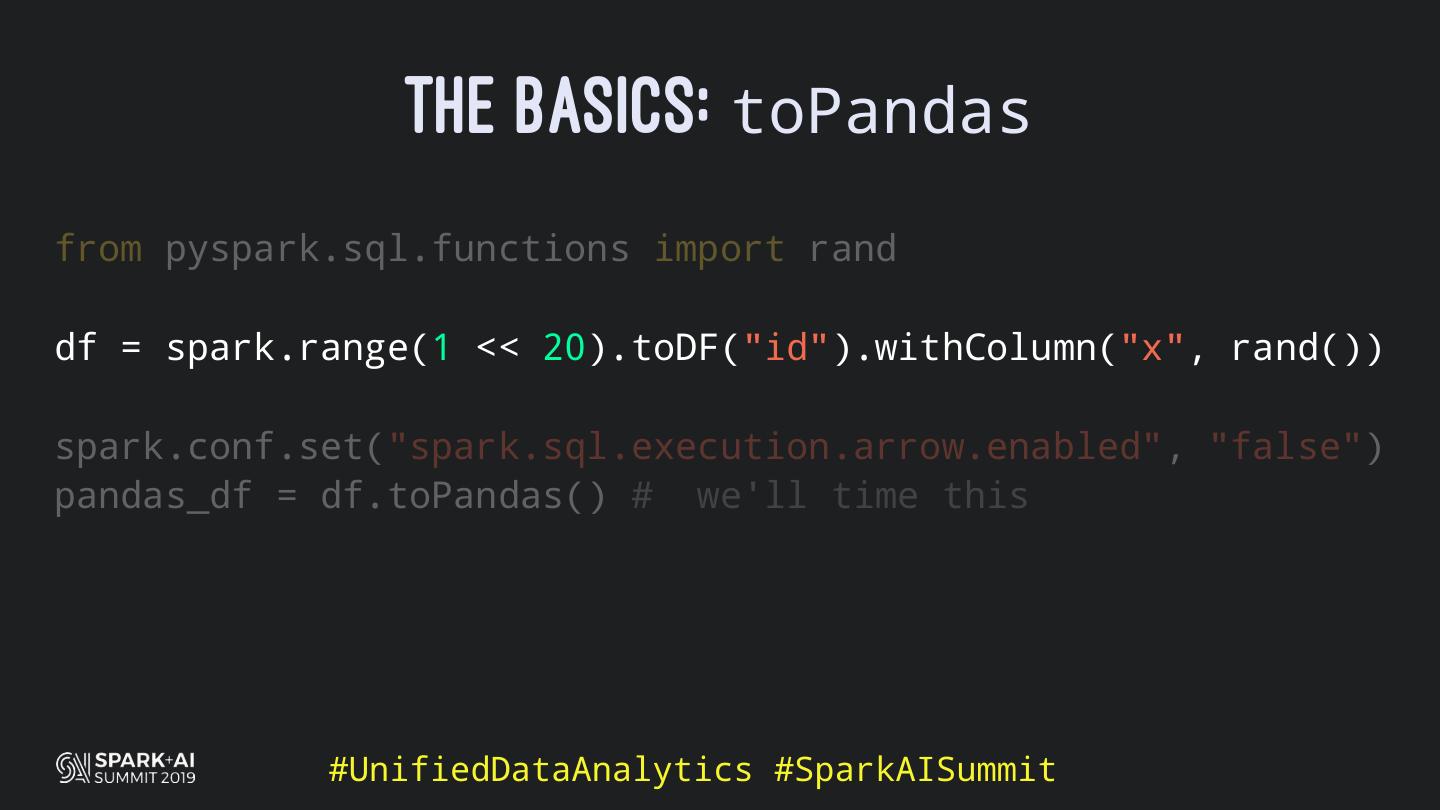
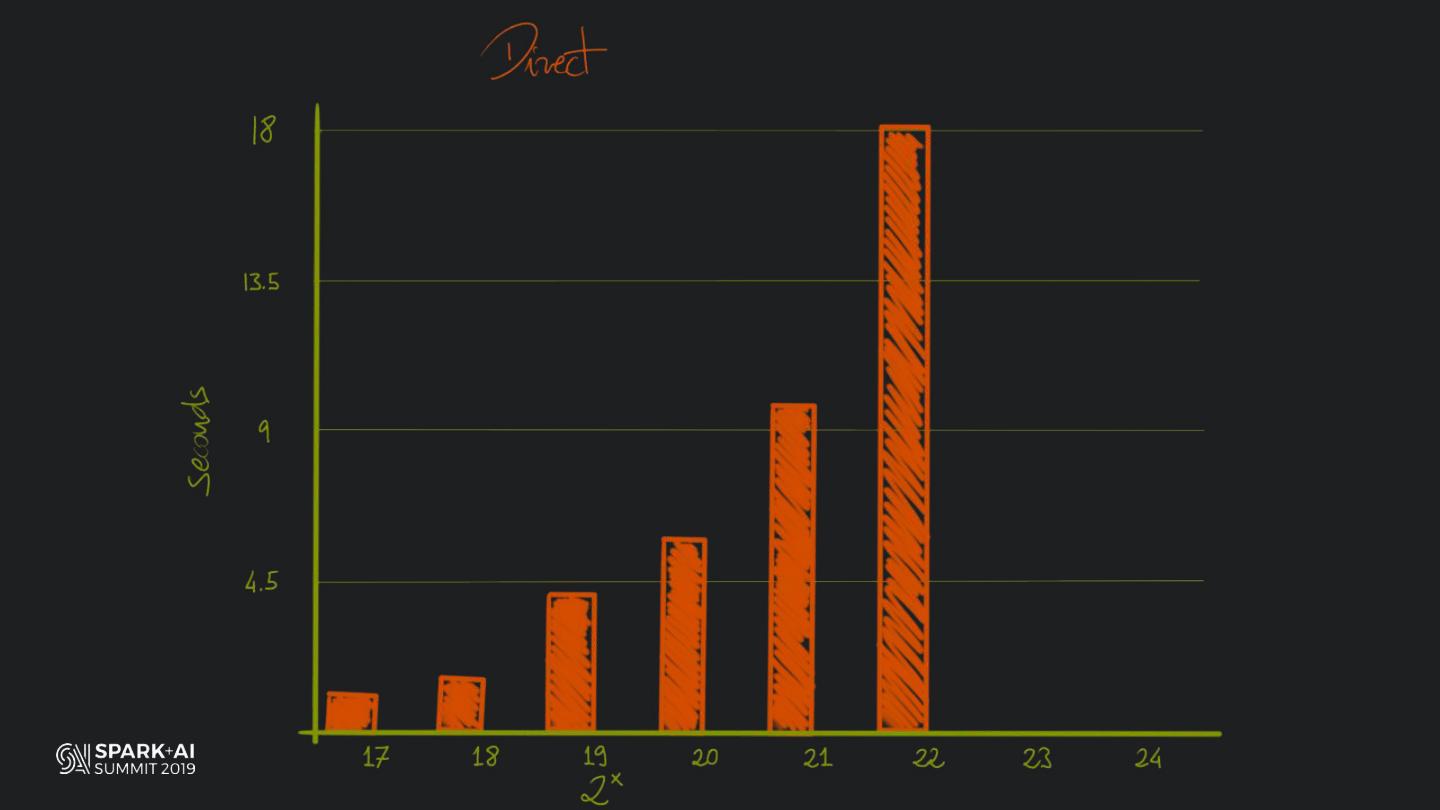
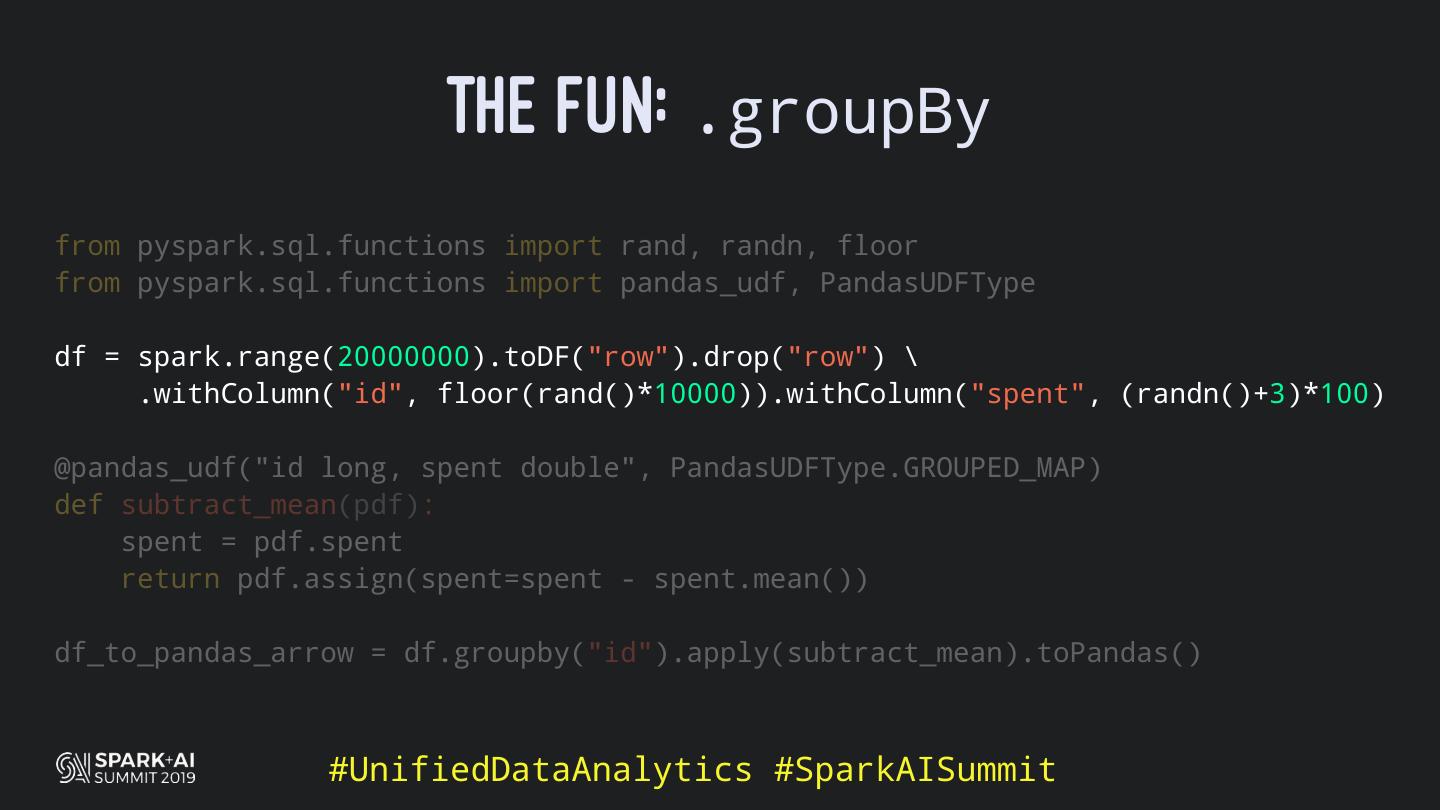
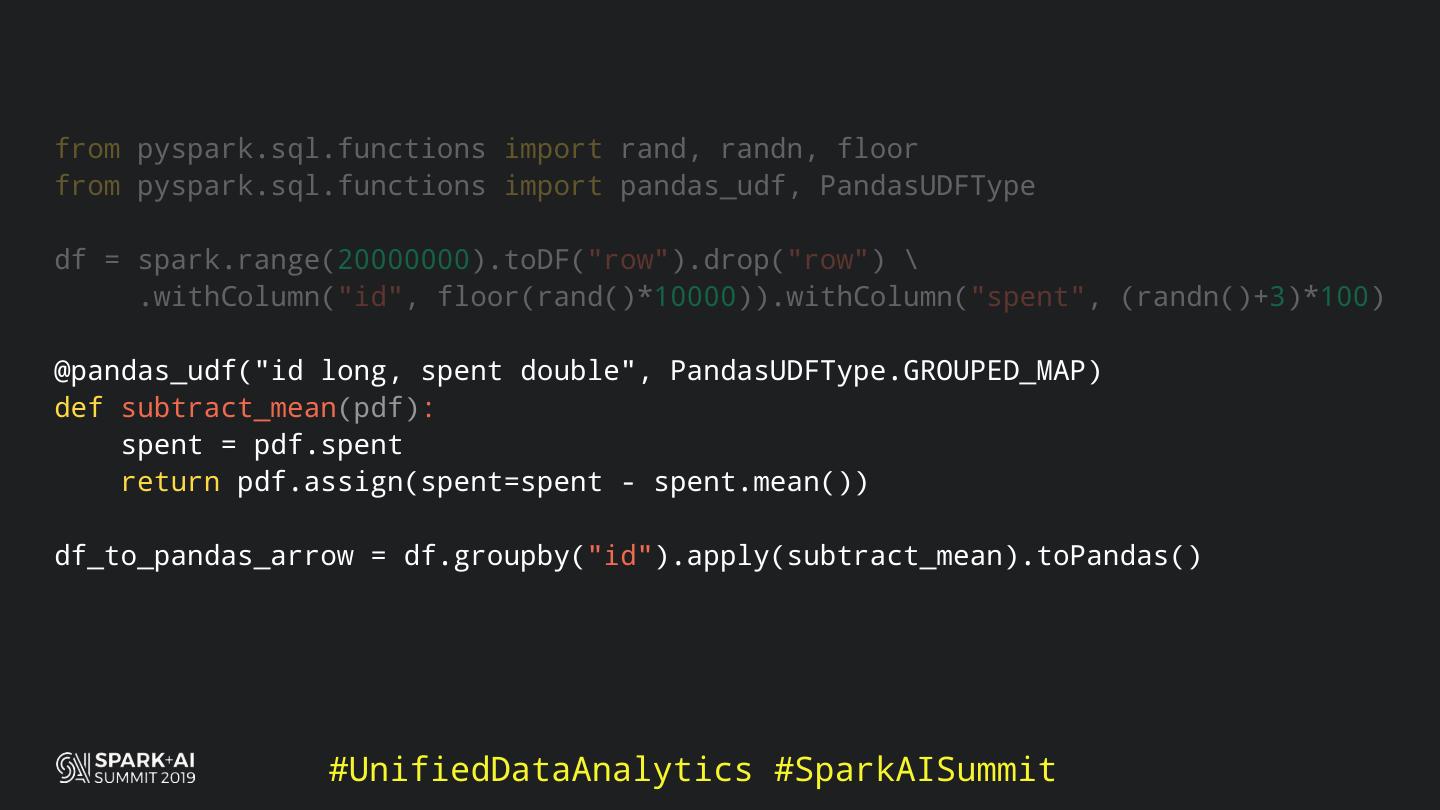
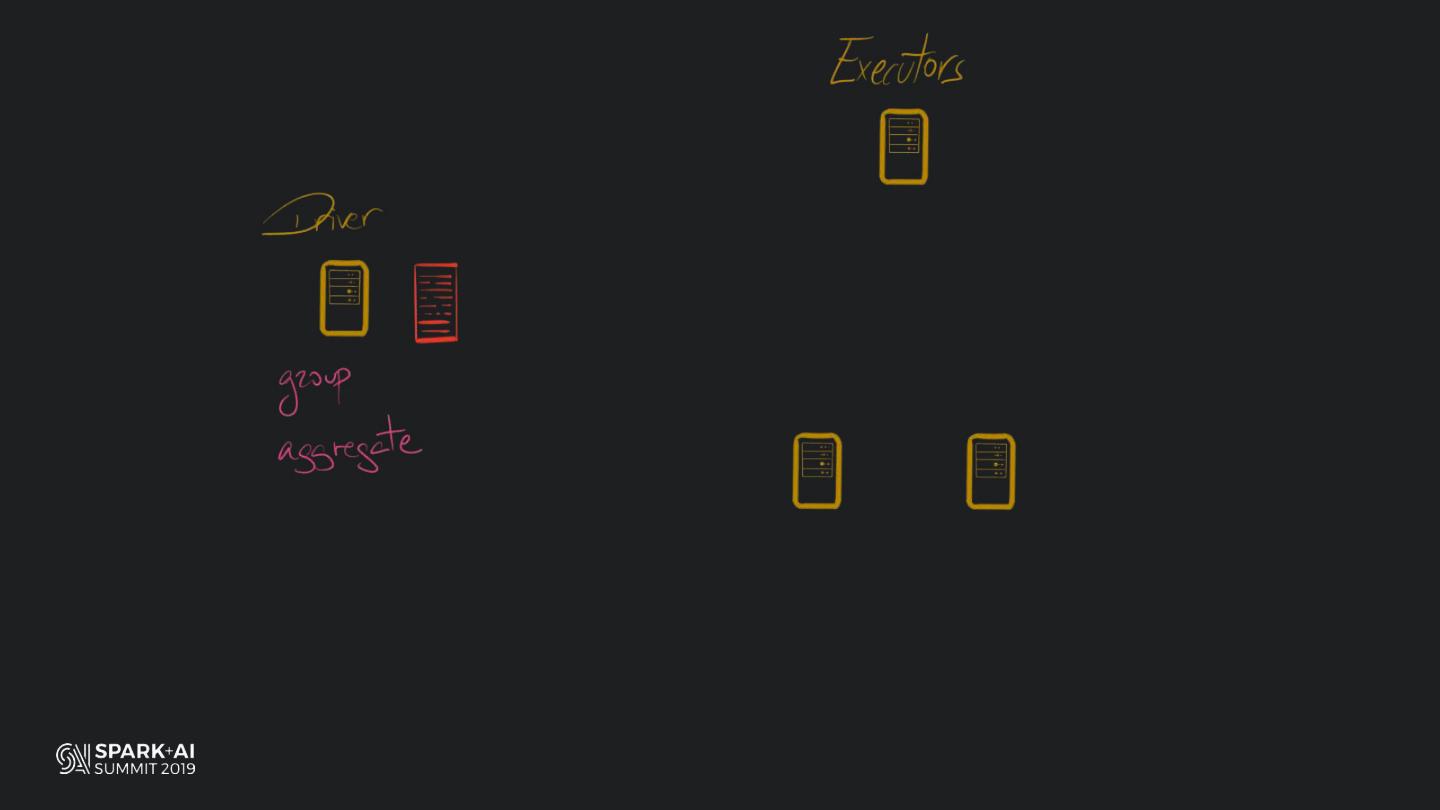
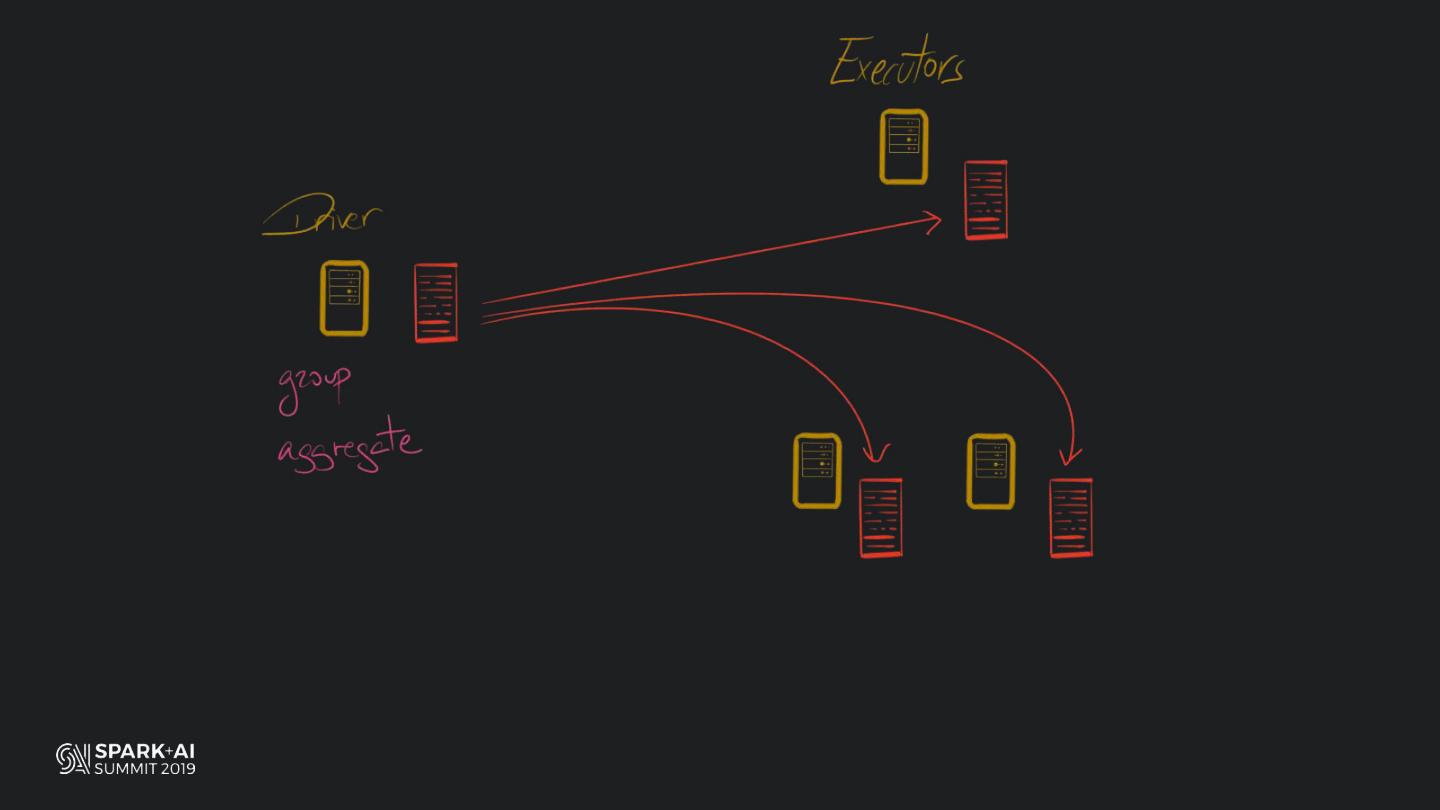
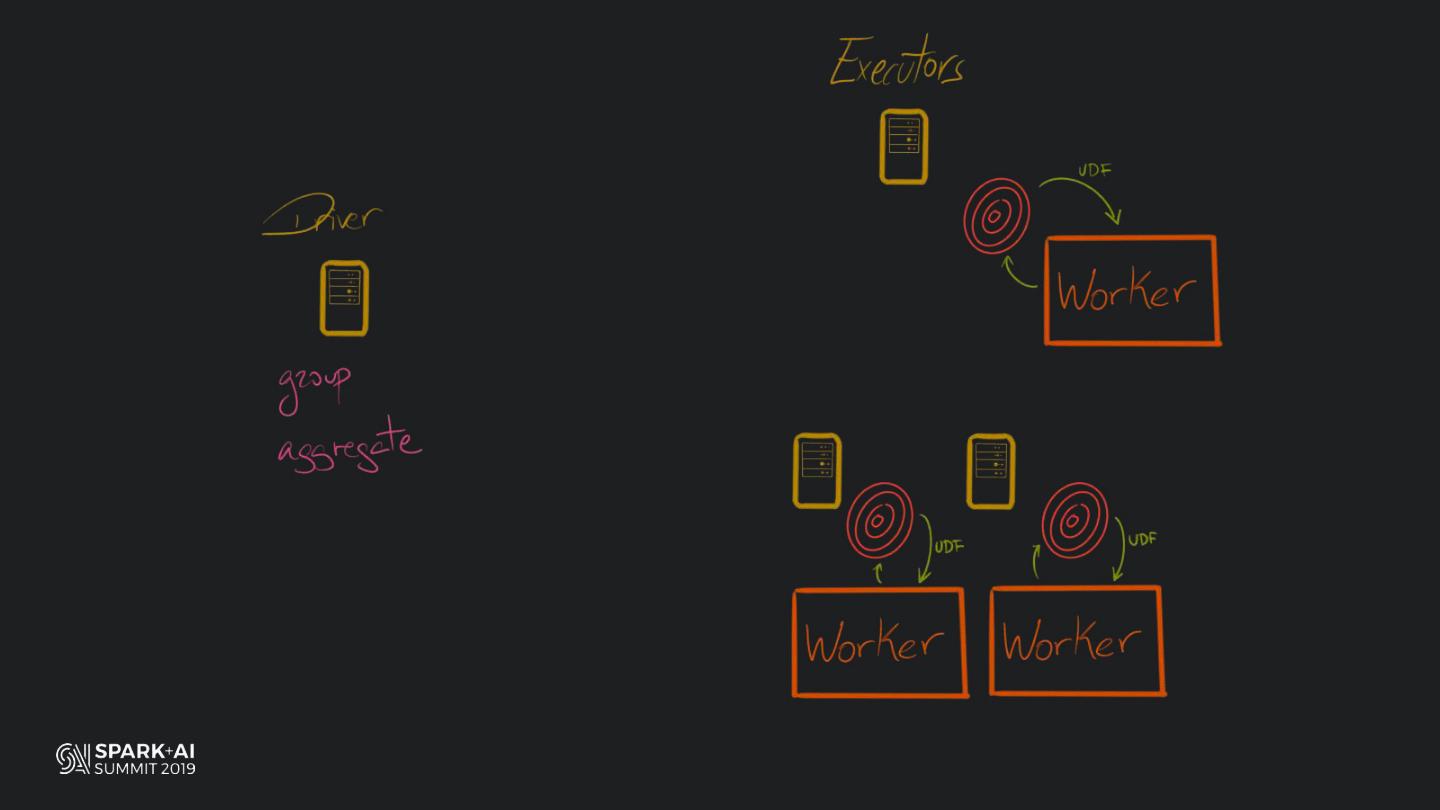
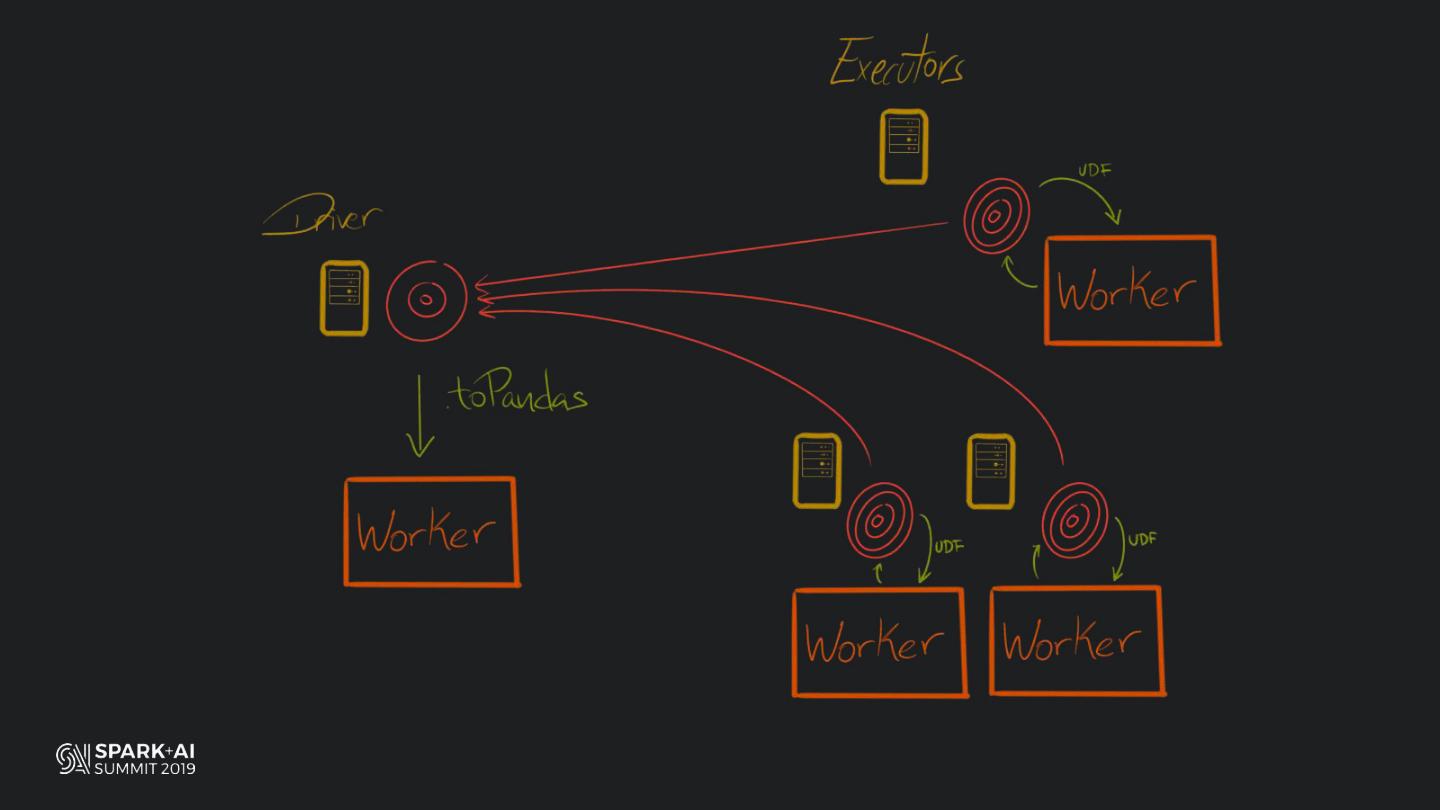
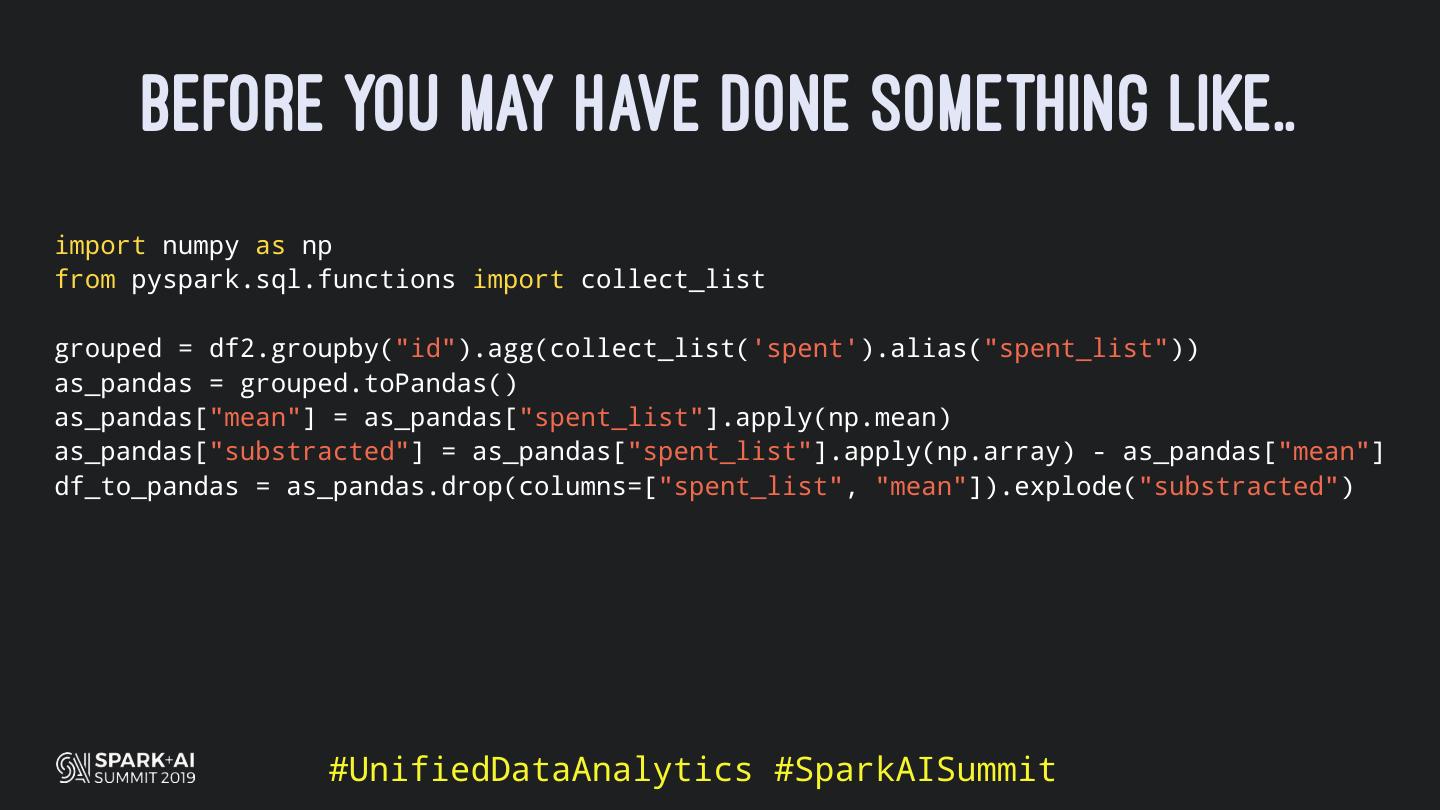
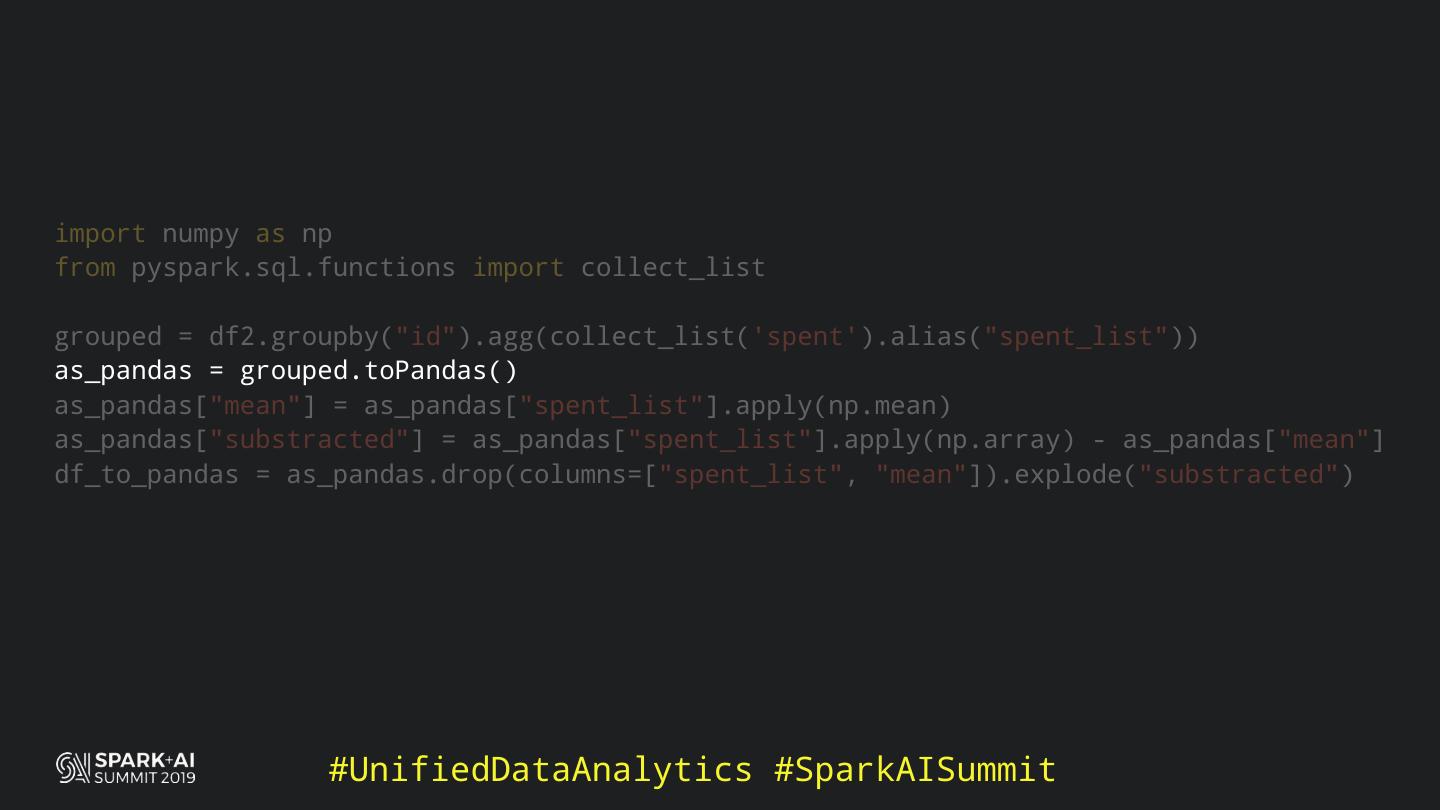
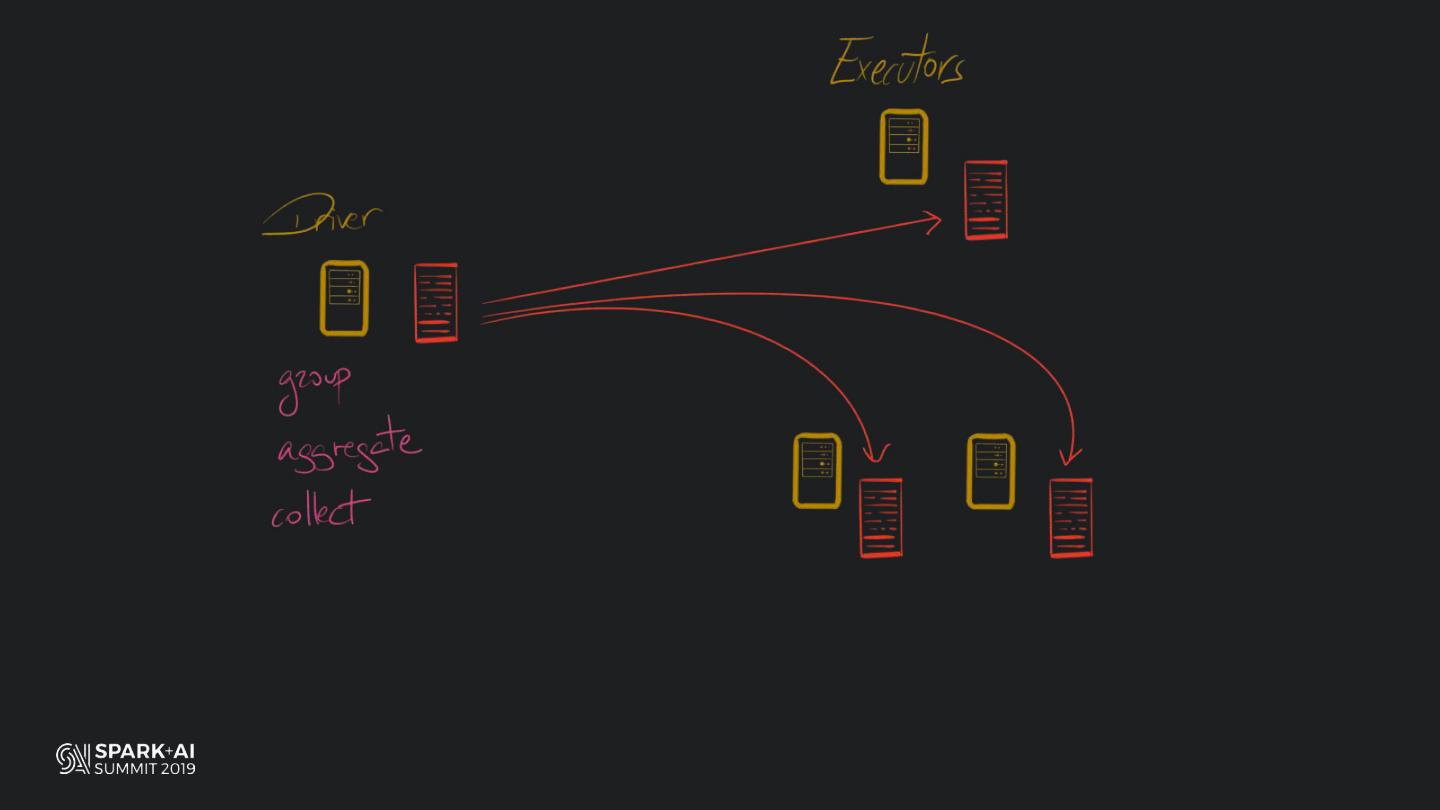
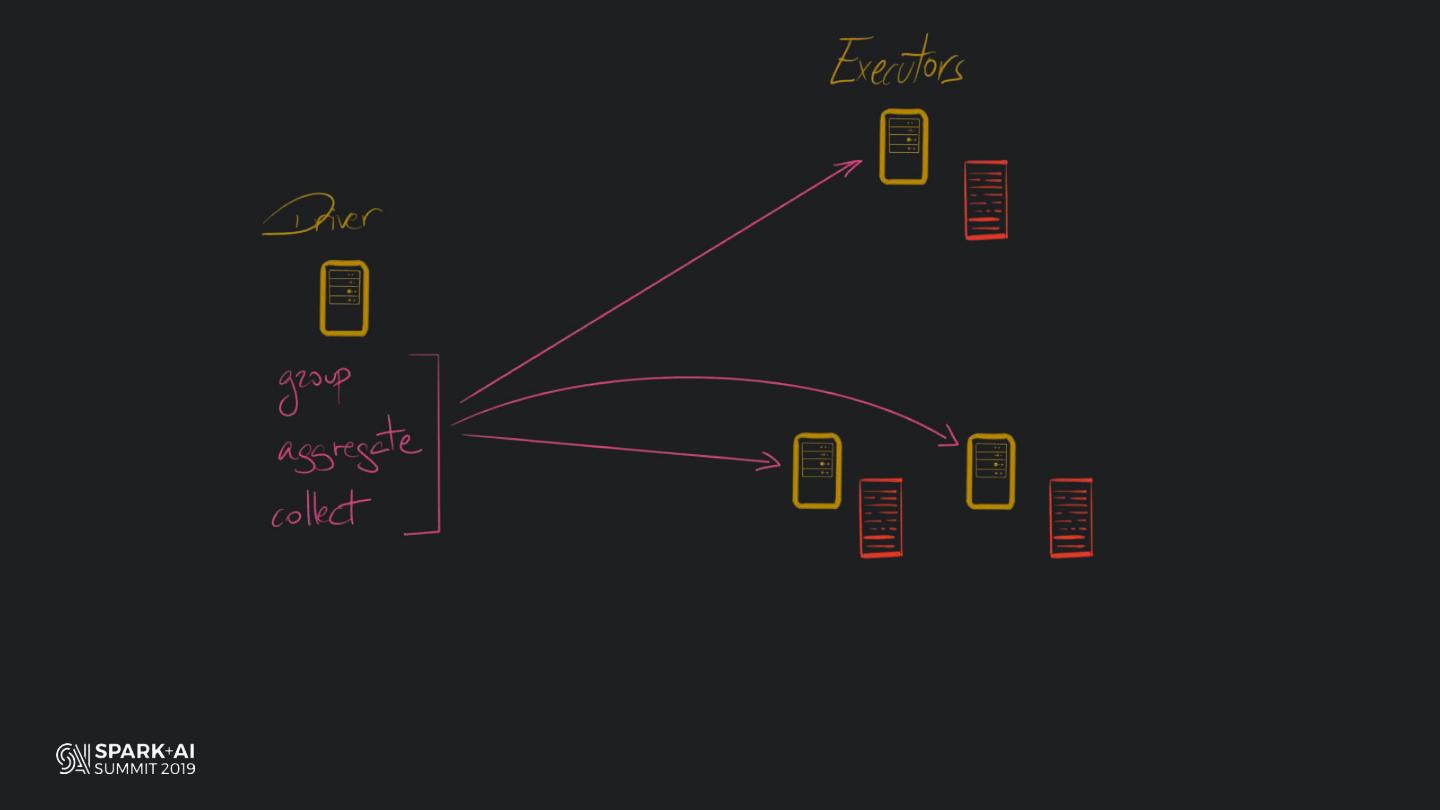
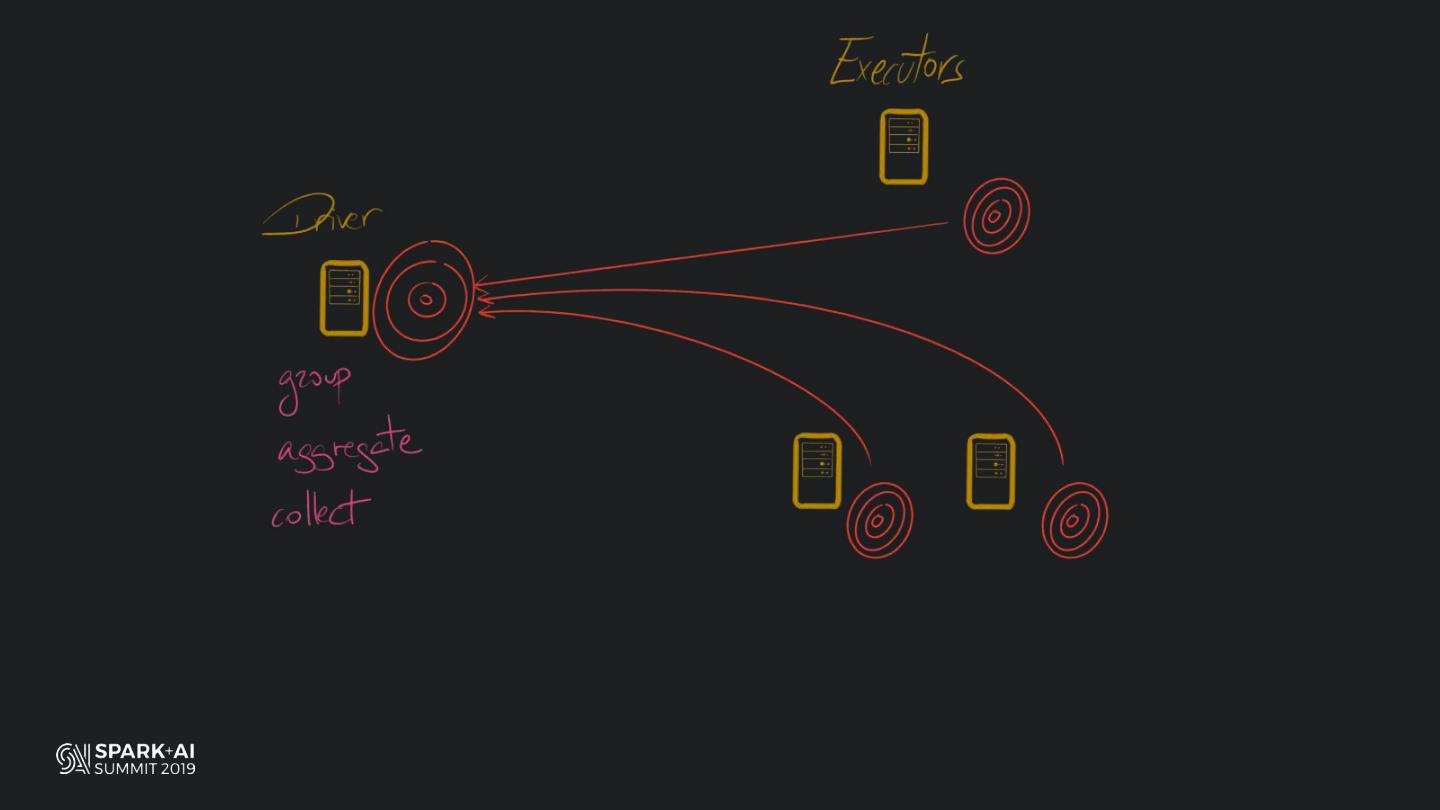
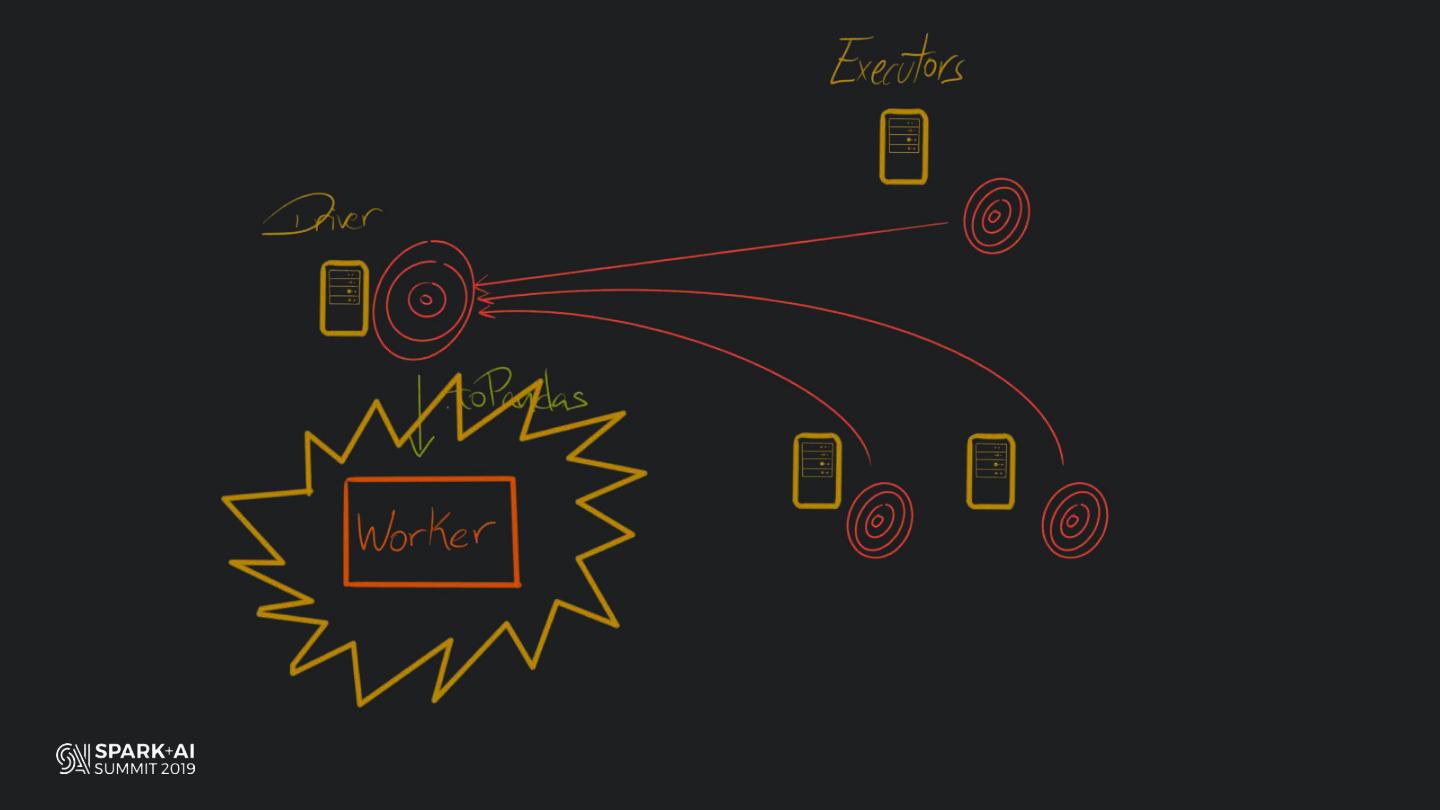
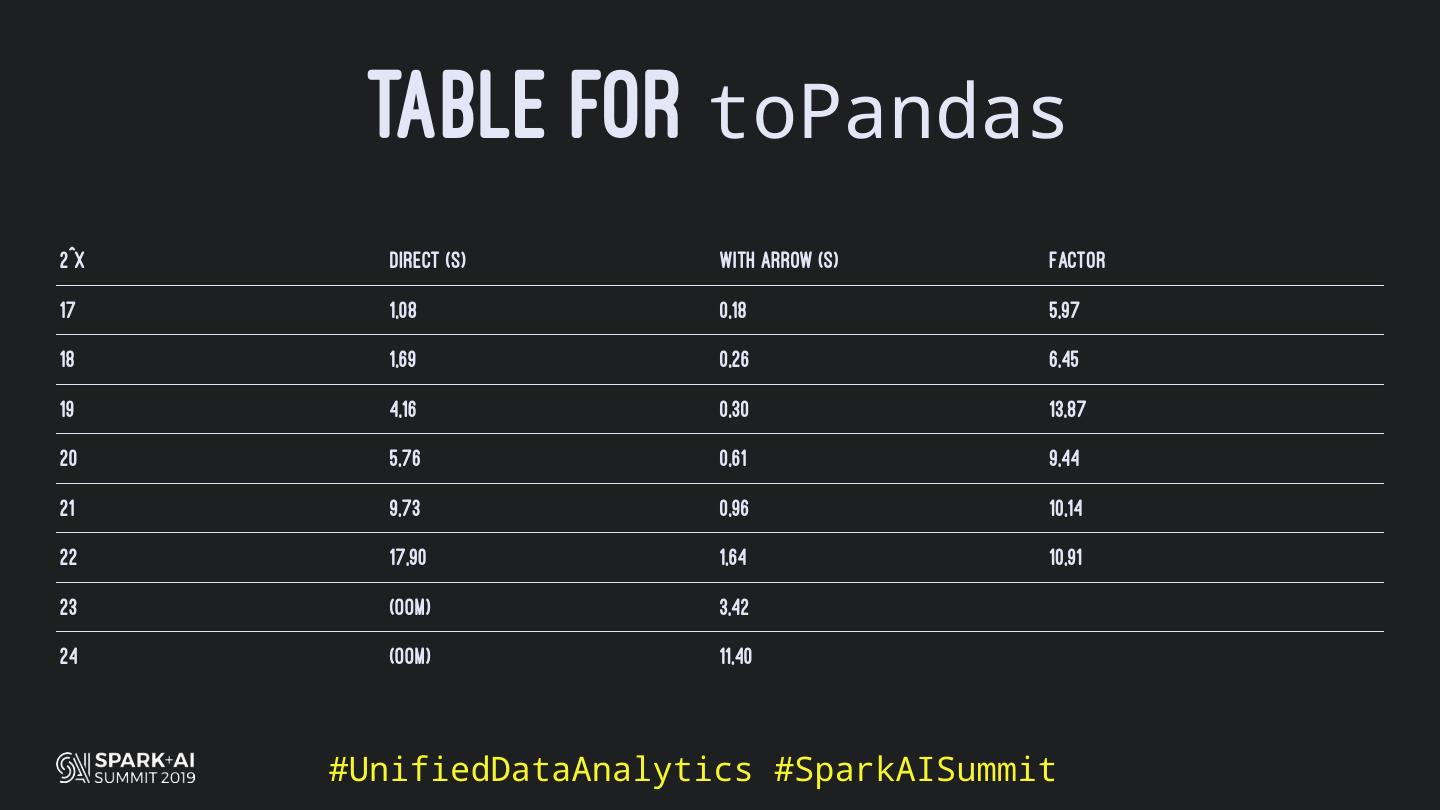
Back in the old days of Apache Spark, using Python with Spark was an exercise in patience. Data was moving up and down from Python to Scala, being serialised constantly. Leveraging SparkSQL and avoiding UDFs made things better, likewise did the constant improvement of the optimisers (Catalyst and Tungsten). But, after Spark 2.3, PySpark has sped up tremendously thanks to the addition of the Arrow serialisers. In this talk you will learn how the Spark Scala core communicates with the Python processes, how data is exchanged across both sub-systems and the development efforts present and underway to make it as fast as possible.
展开查看详情
4 . WHOAMI
> Ruben Berenguel (@berenguel)
> PhD in Mathematics
> (big) data consultant
> Lead data engineer using Python, Go and Scala
> Right now at Affectv
#UnifiedDataAnalytics #SparkAISummit
�
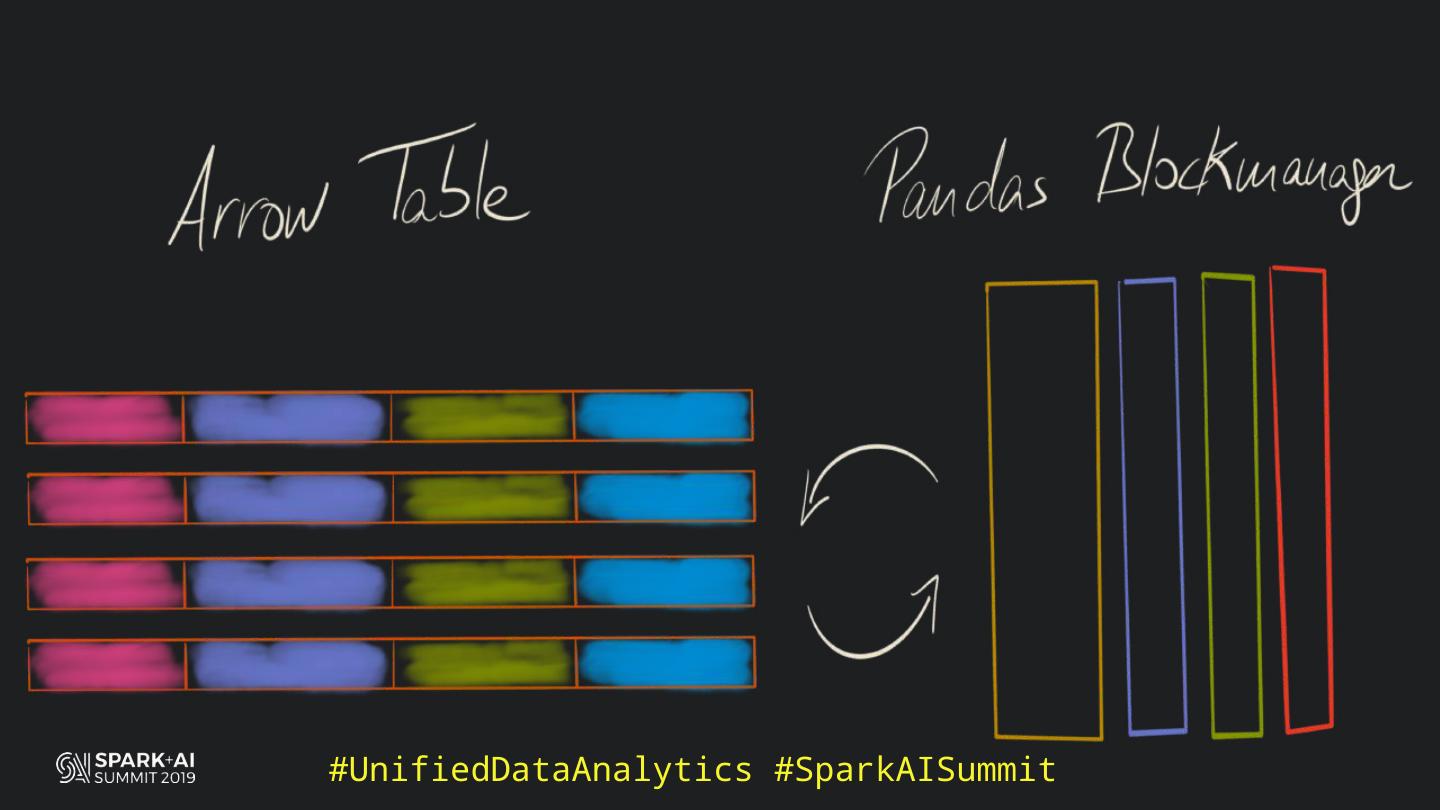
5 . What is Pandas?
#UnifiedDataAnalytics #SparkAISummit
�
6 . What is Pandas?
> Python Data Analysis library
#UnifiedDataAnalytics #SparkAISummit
�
7 . What is Pandas?
> Python Data Analysis library
> Used everywhere data and Python appear in job offers
#UnifiedDataAnalytics #SparkAISummit
�
8 . What is Pandas?
> Python Data Analysis library
> Used everywhere data and Python appear in job offers
> Efficient (is columnar and has a C and Cython backend)
#UnifiedDataAnalytics #SparkAISummit
�
9 .#UnifiedDataAnalytics #SparkAISummit
�
10 .#UnifiedDataAnalytics #SparkAISummit
�
11 .#UnifiedDataAnalytics #SparkAISummit
�
12 .#UnifiedDataAnalytics #SparkAISummit
�
13 .#UnifiedDataAnalytics #SparkAISummit
�
14 .#UnifiedDataAnalytics #SparkAISummit
�
15 .#UnifiedDataAnalytics #SparkAISummit
�
16 .#UnifiedDataAnalytics #SparkAISummit
�
17 .#UnifiedDataAnalytics #SparkAISummit
�
18 .#UnifiedDataAnalytics #SparkAISummit
�
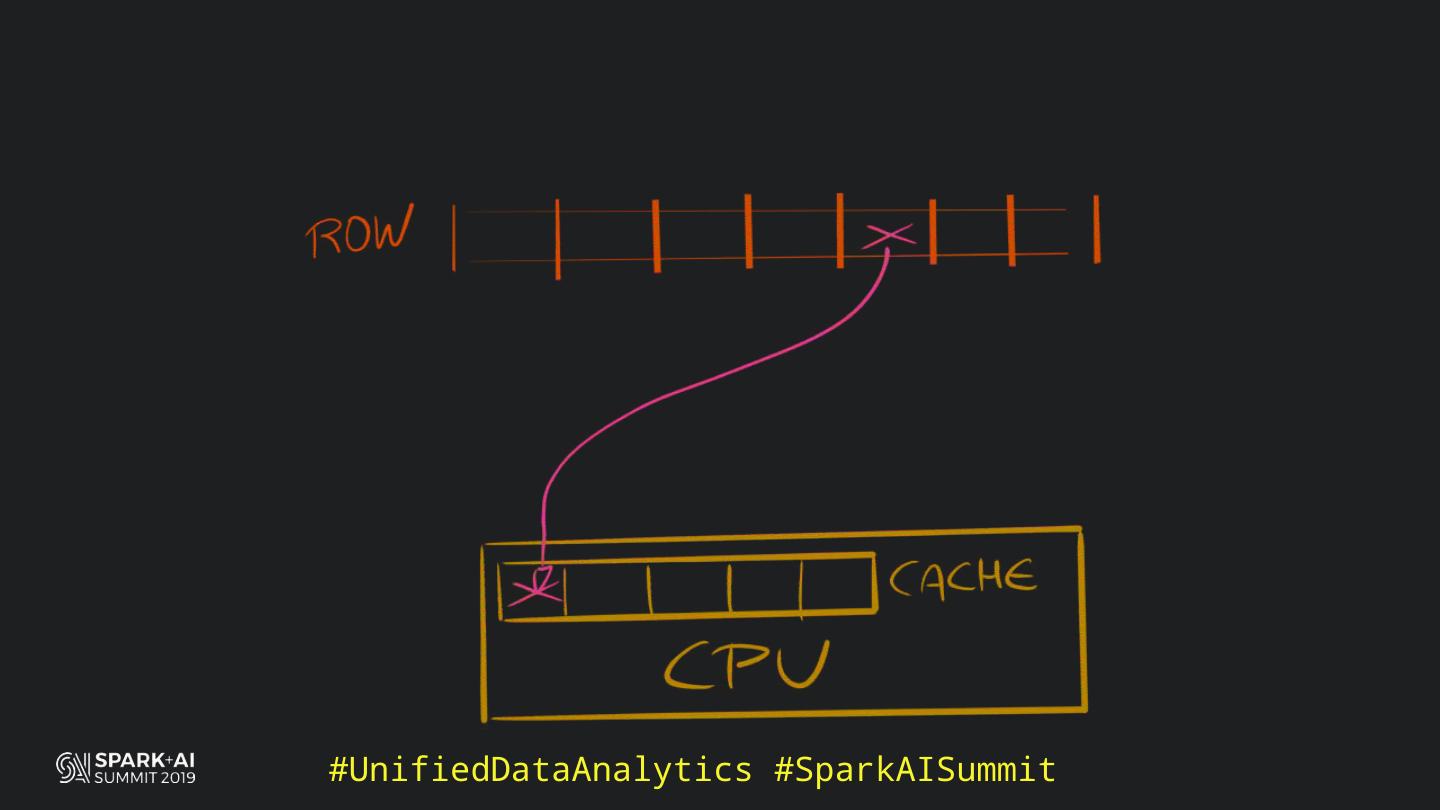
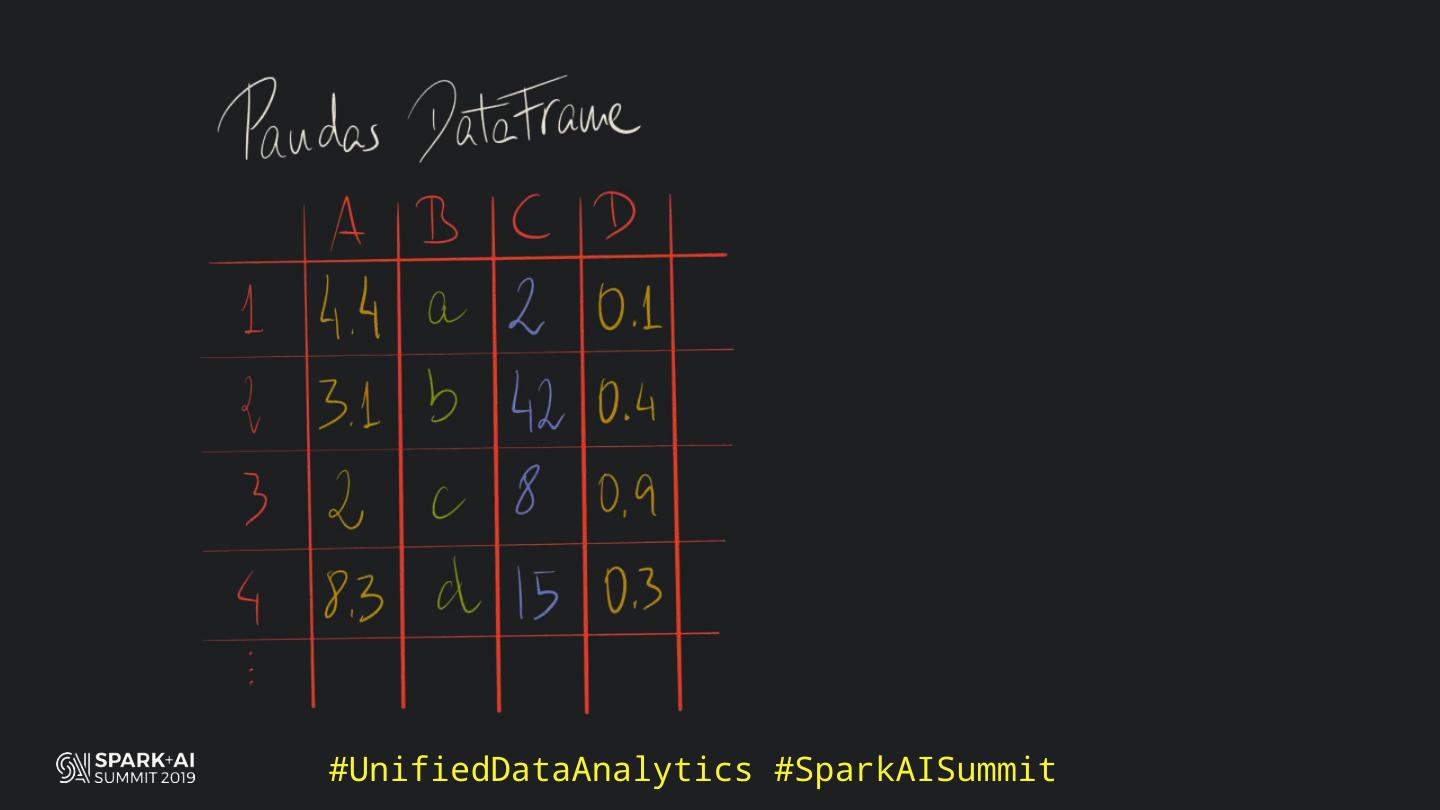
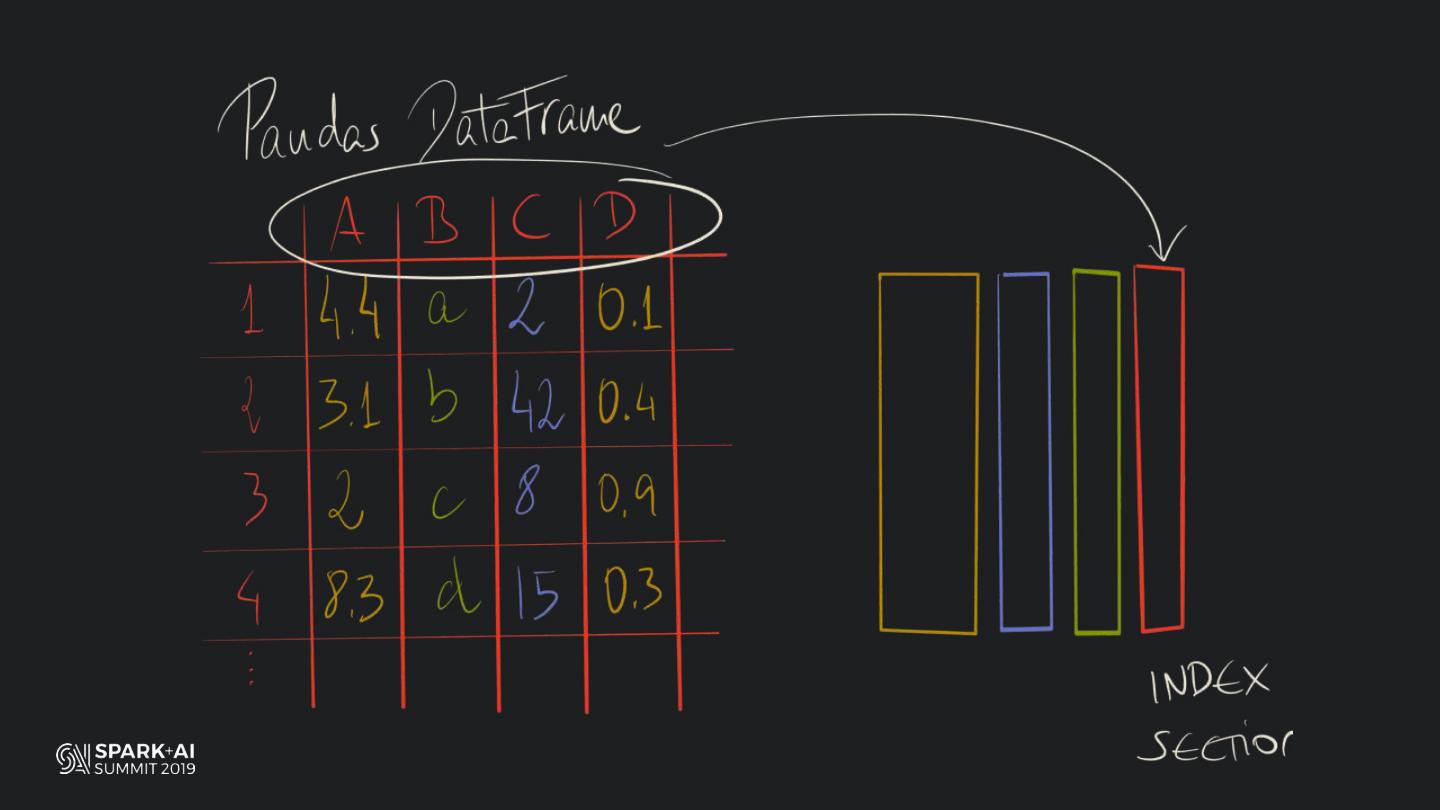
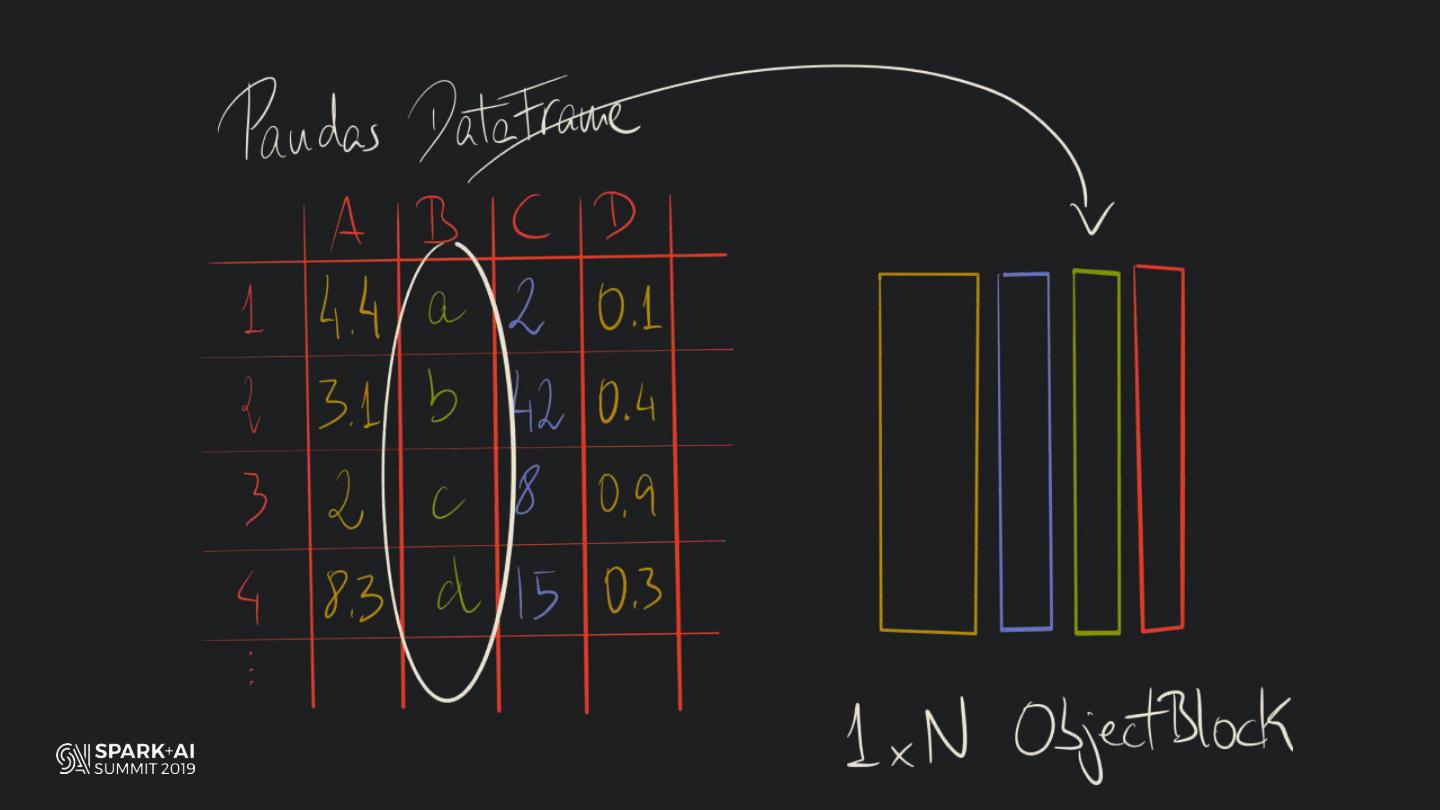
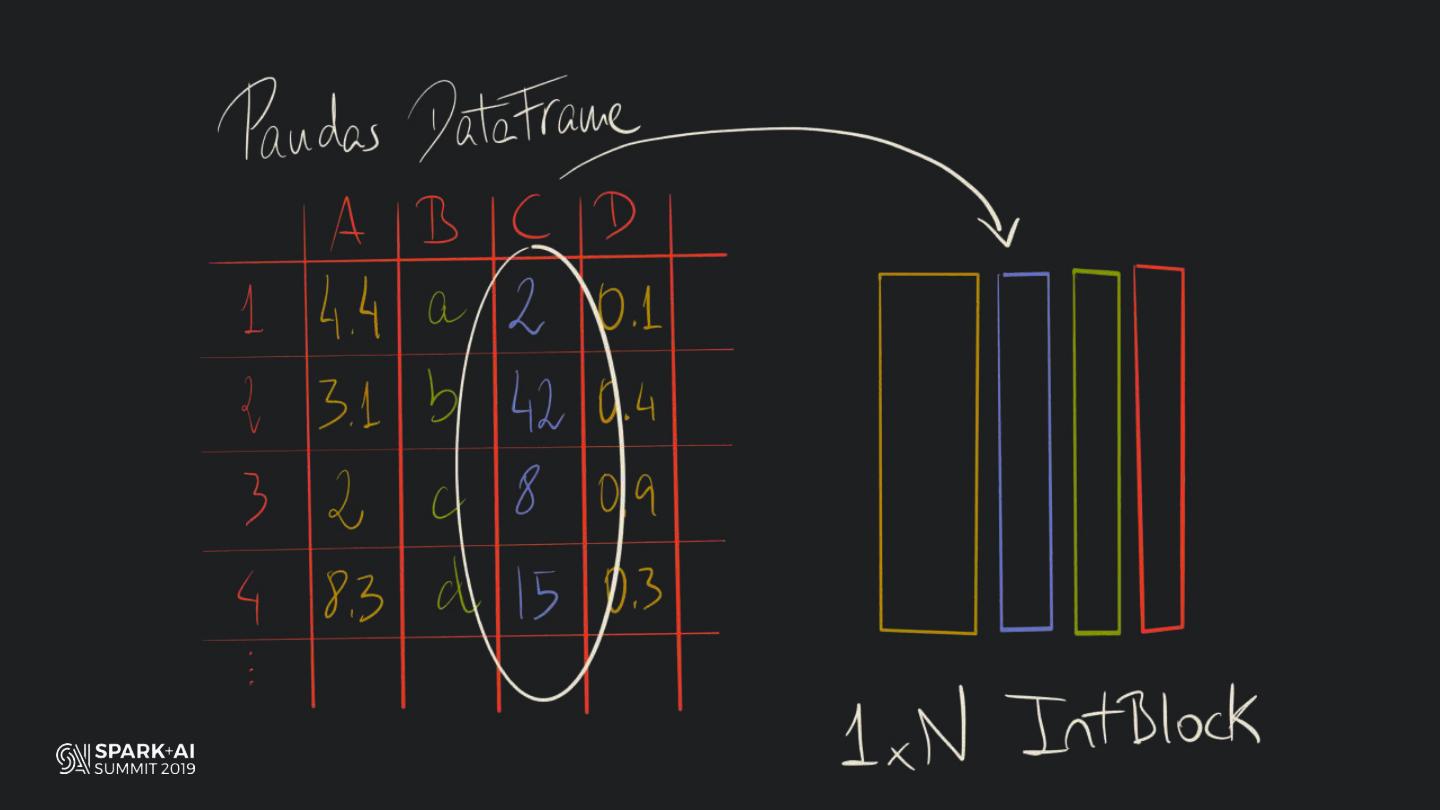
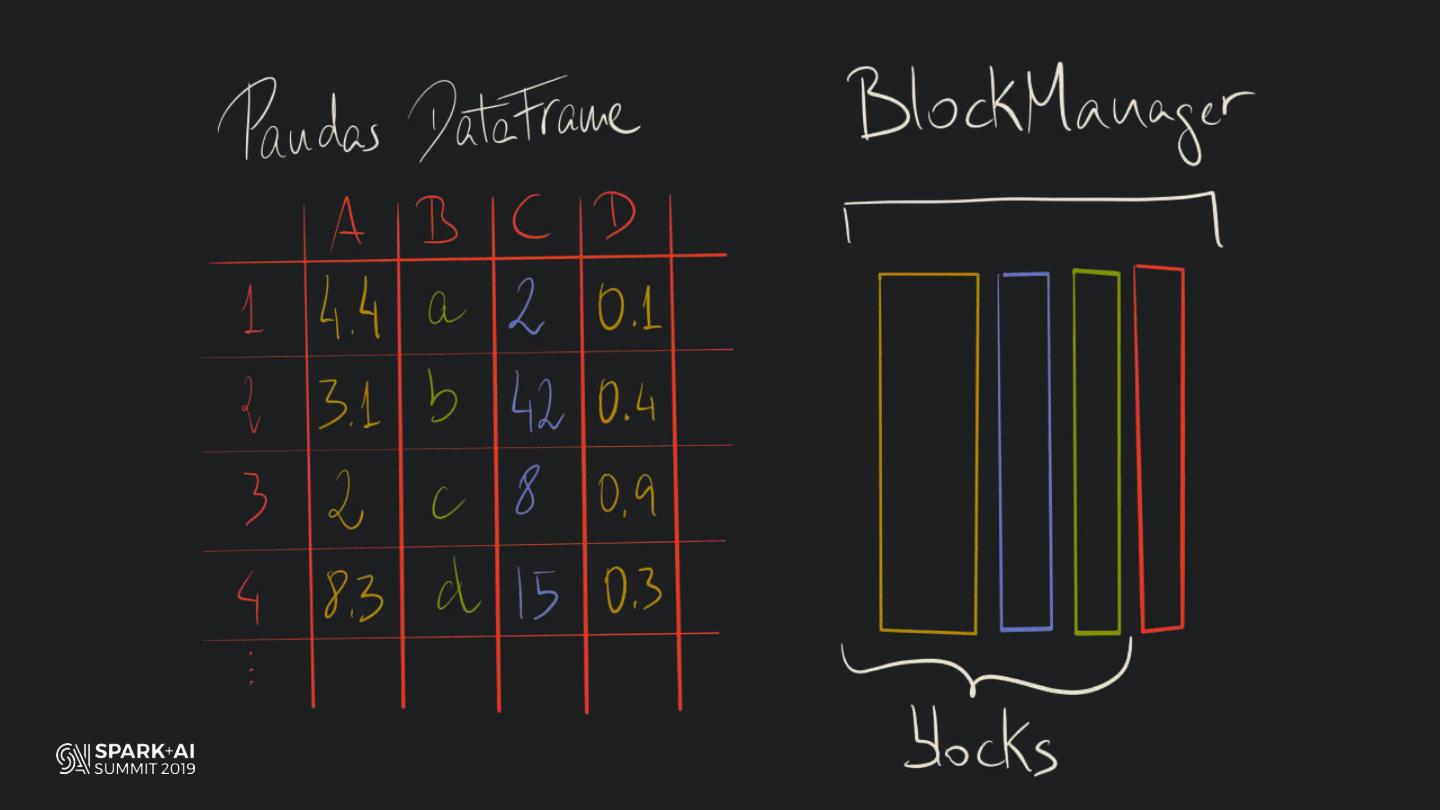
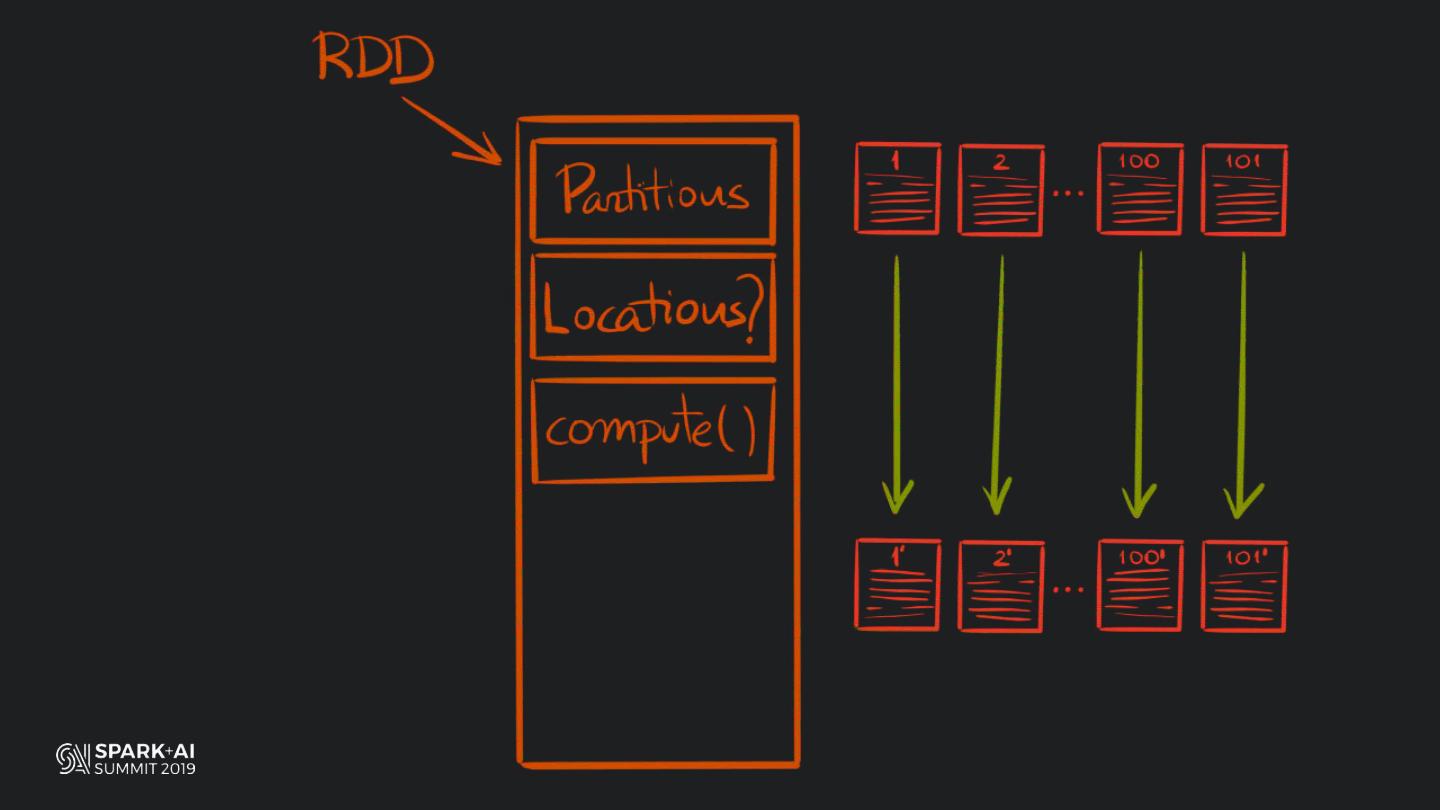
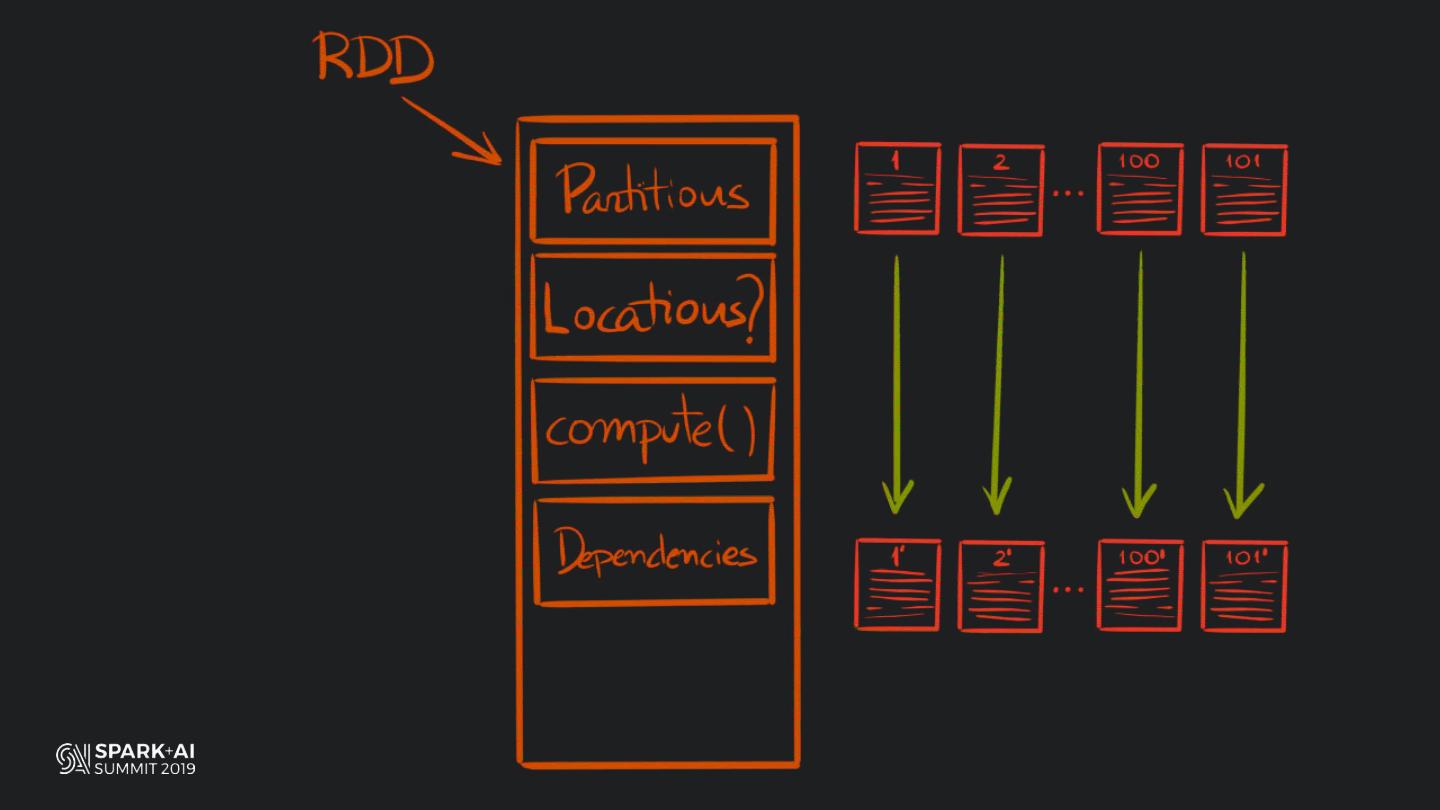
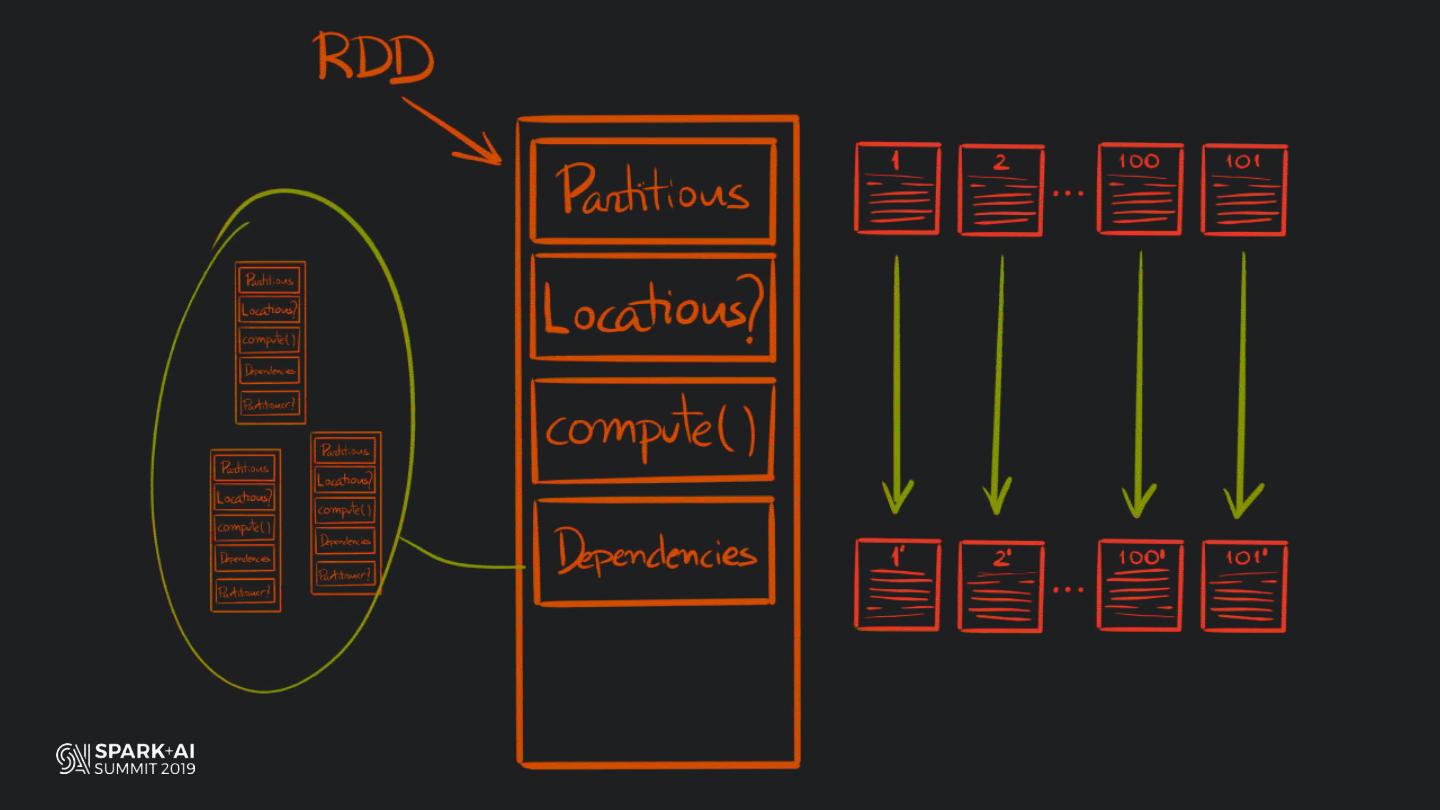
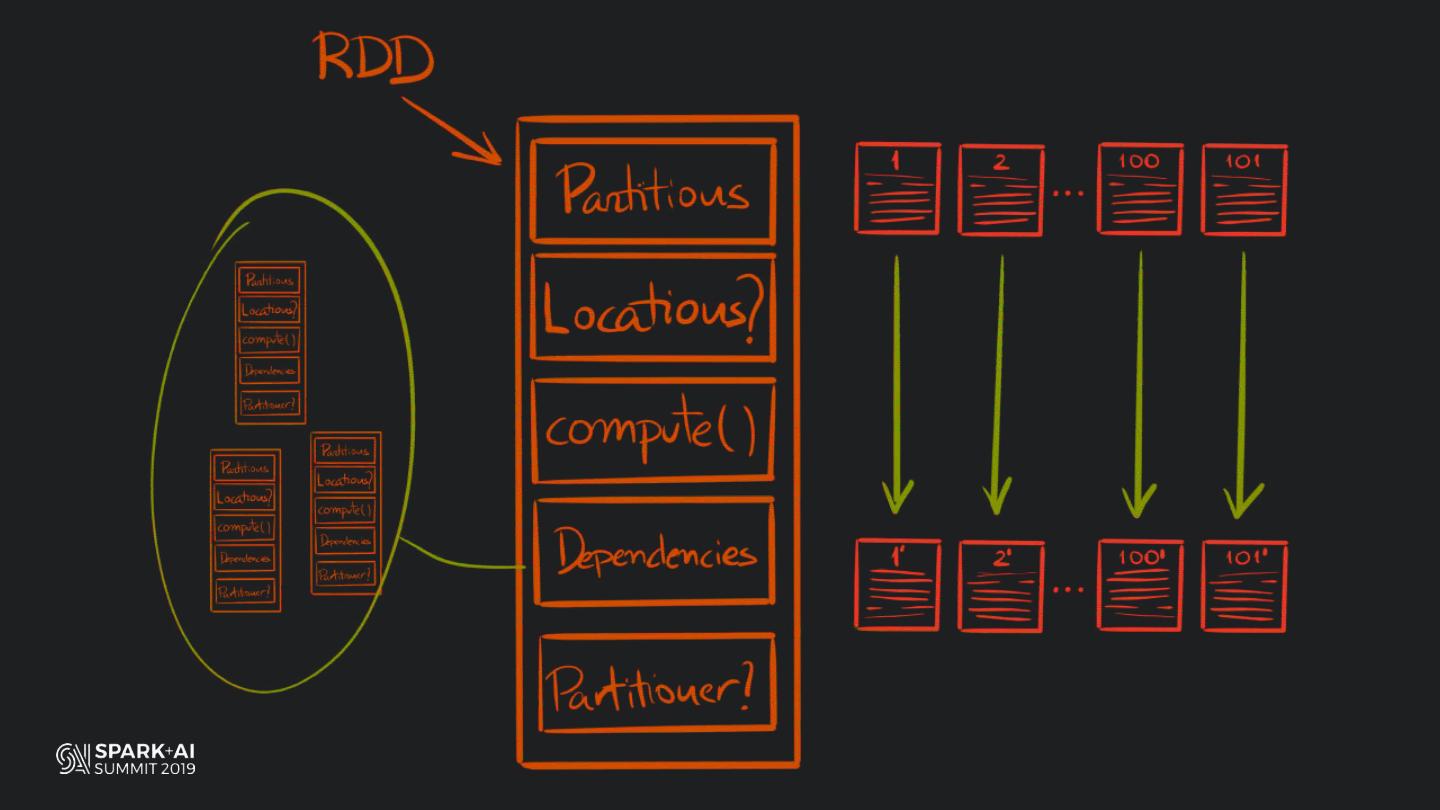
19 . HOW DOES PANDAS
MANAGE COLUMNAR DATA?
#UnifiedDataAnalytics #SparkAISummit
�
20 .#UnifiedDataAnalytics #SparkAISummit
�
21 .#UnifiedDataAnalytics #SparkAISummit
�
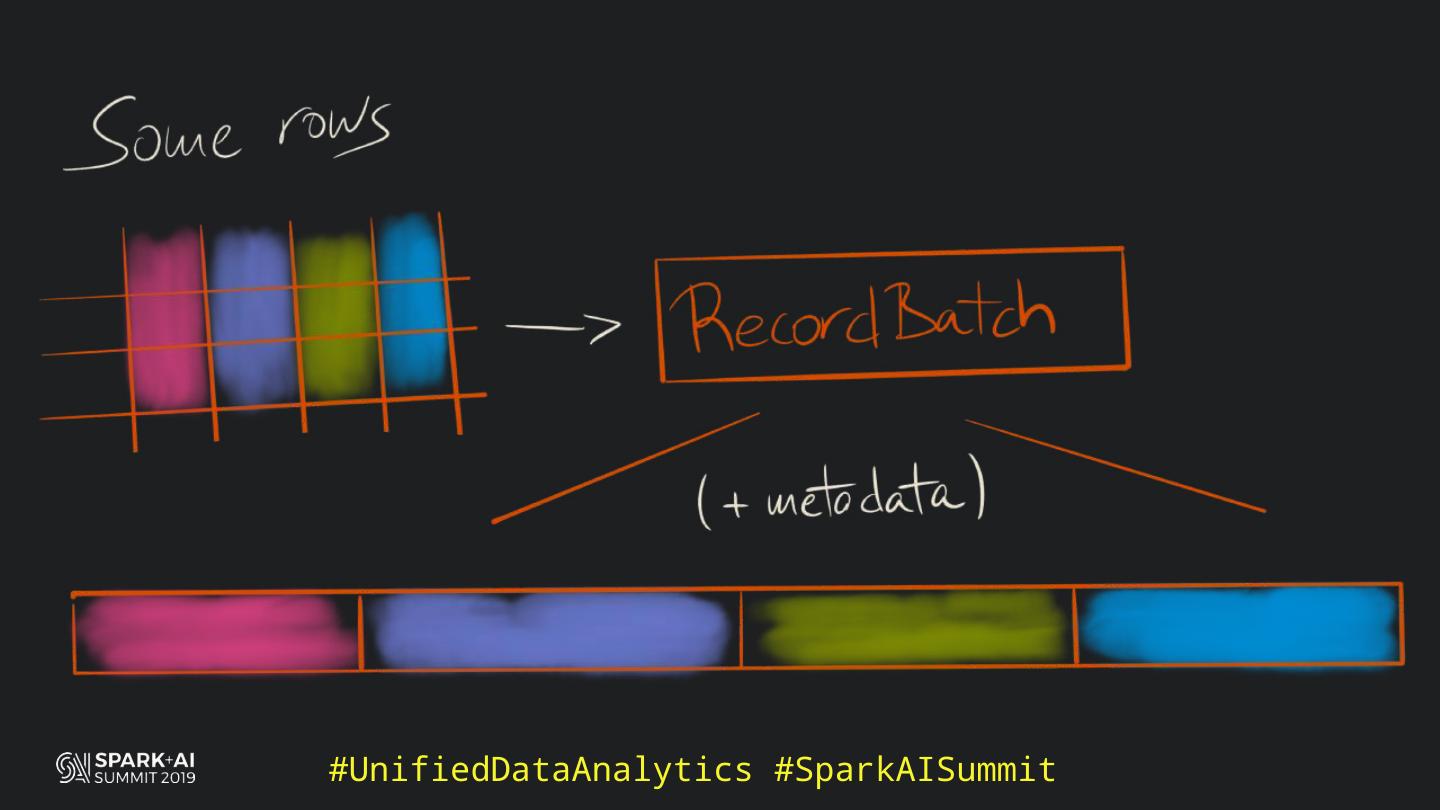
27 . WHAT IS ARROW?
#UnifiedDataAnalytics #SparkAISummit
�
28 . WHAT IS ARROW?
> Cross-language in-memory columnar format library
#UnifiedDataAnalytics #SparkAISummit
�
29 . WHAT IS ARROW?
> Cross-language in-memory columnar format library
> Optimised for efficiency across languages
#UnifiedDataAnalytics #SparkAISummit
�