展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Industrializing ML on
Azure with DataBricks
RADJI Yannick, SODEXO
#UnifiedDataAnalytics #SparkAISummit
�
3 .Who am I?
Using:
• Spark since 2015
• DataBricks since 2018
Work for:
• Industry
• Consulting
• Services
Data Data Data
Scientist Engineer Architect
3
�
4 .Agenda
• Sodexo
• Food service use case
• What was there?
• What are we using know?
• Our development practices
4
�
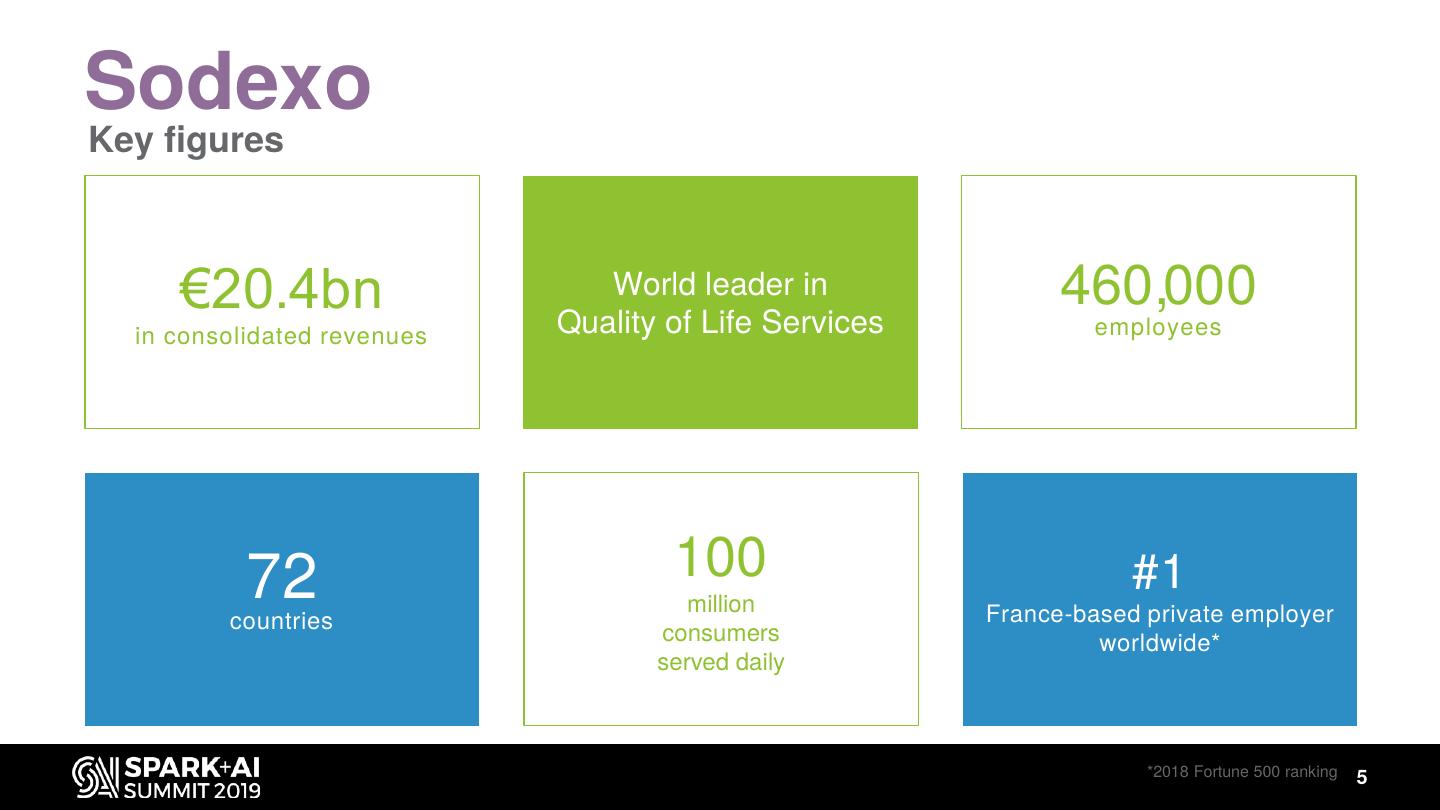
5 .Sodexo
Key figures
€20.4bn World leader in
Quality of Life Services
460,000
employees
in consolidated revenues
72 100 #1
million France-based private employer
countries
consumers worldwide*
served daily
*2018 Fortune 500 ranking 5
�
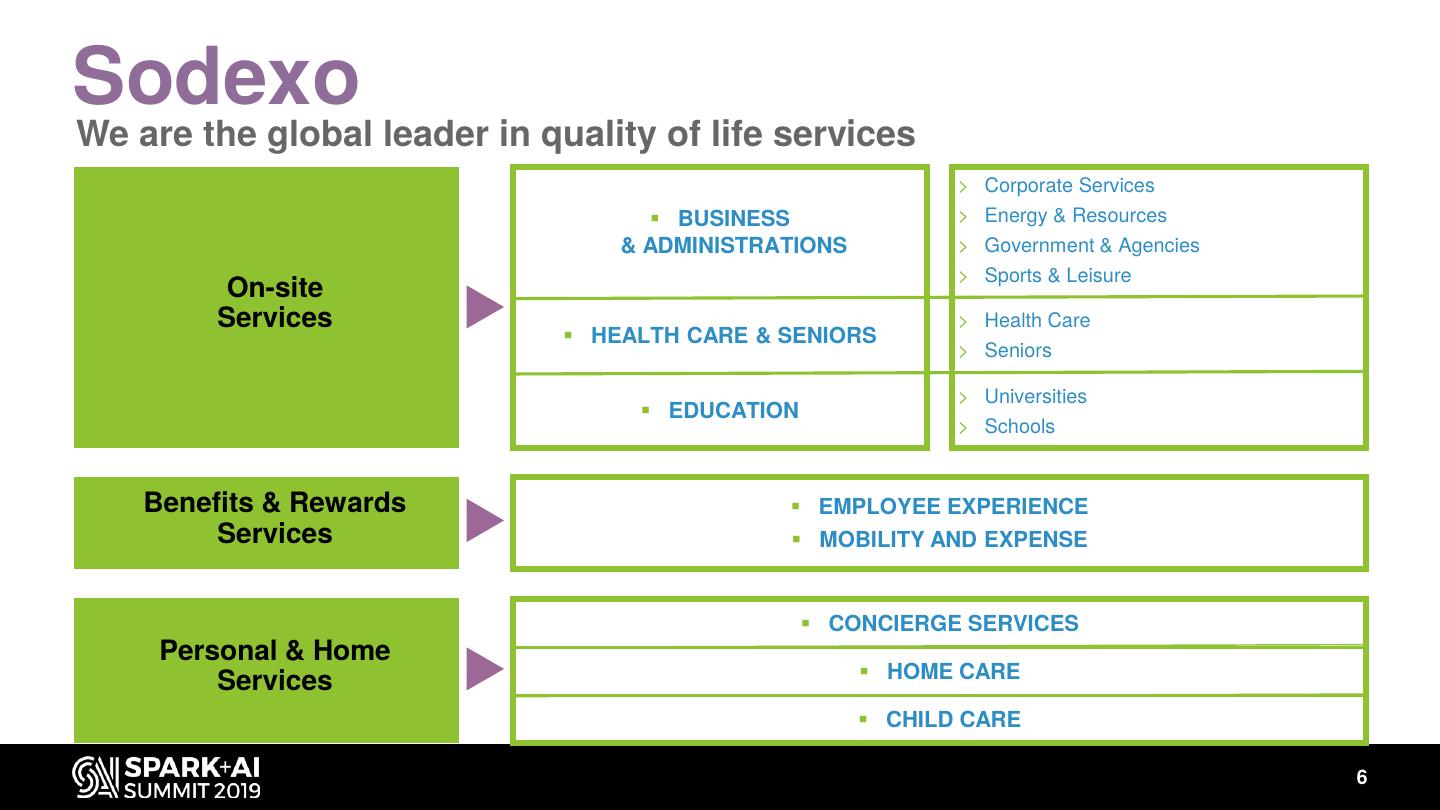
6 .Sodexo
We are the global leader in quality of life services
> Corporate Services
▪ BUSINESS > Energy & Resources
& ADMINISTRATIONS > Government & Agencies
> Sports & Leisure
On-site
Services > Health Care
▪ HEALTH CARE & SENIORS
> Seniors
> Universities
▪ EDUCATION
> Schools
Benefits & Rewards ▪ EMPLOYEE EXPERIENCE
Services ▪ MOBILITY AND EXPENSE
▪ CONCIERGE SERVICES
Personal & Home
Services ▪ HOME CARE
▪ CHILD CARE
6
�
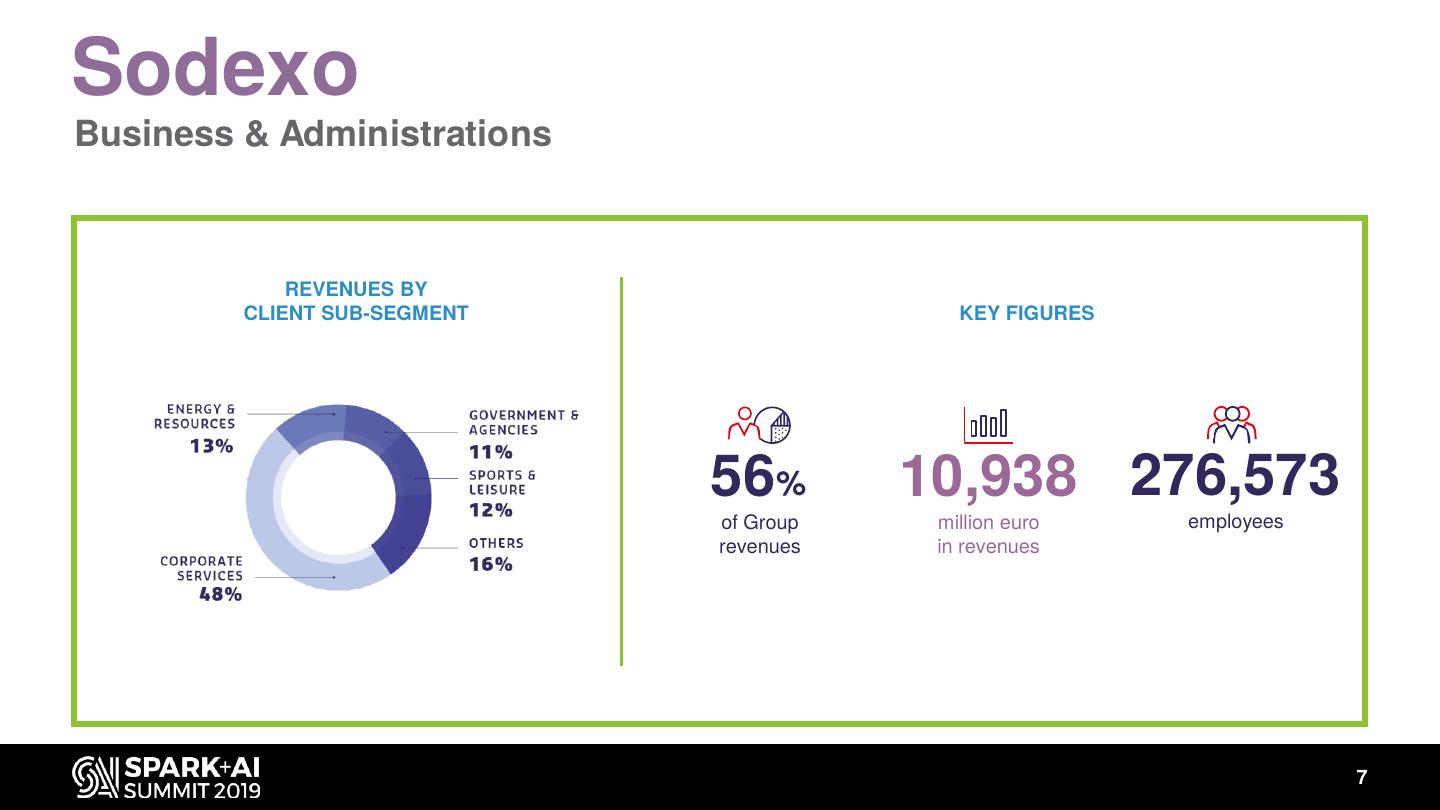
7 .Sodexo
Business & Administrations
REVENUES BY
CLIENT SUB-SEGMENT KEY FIGURES
56% 10,938 276,573
of Group million euro employees
revenues in revenues
7
�
8 .Food service use case
8
�
9 .What was there?
• Dozens of Jupyter’s notebooks running on Azure HDInsight
Apache Spark on Hive Query on
HDInsight HDInsight
Azure Blob Azure Data
Storage Lake Store
9
�
10 .What was there?
• Unversionned, no CI/CD
• Hard to maintain & operate with high costs
• No orchestration
• Not versatile
• Not secure
• Poor performances
• No live Data
• No re-usable design
• Library conflict
10
�
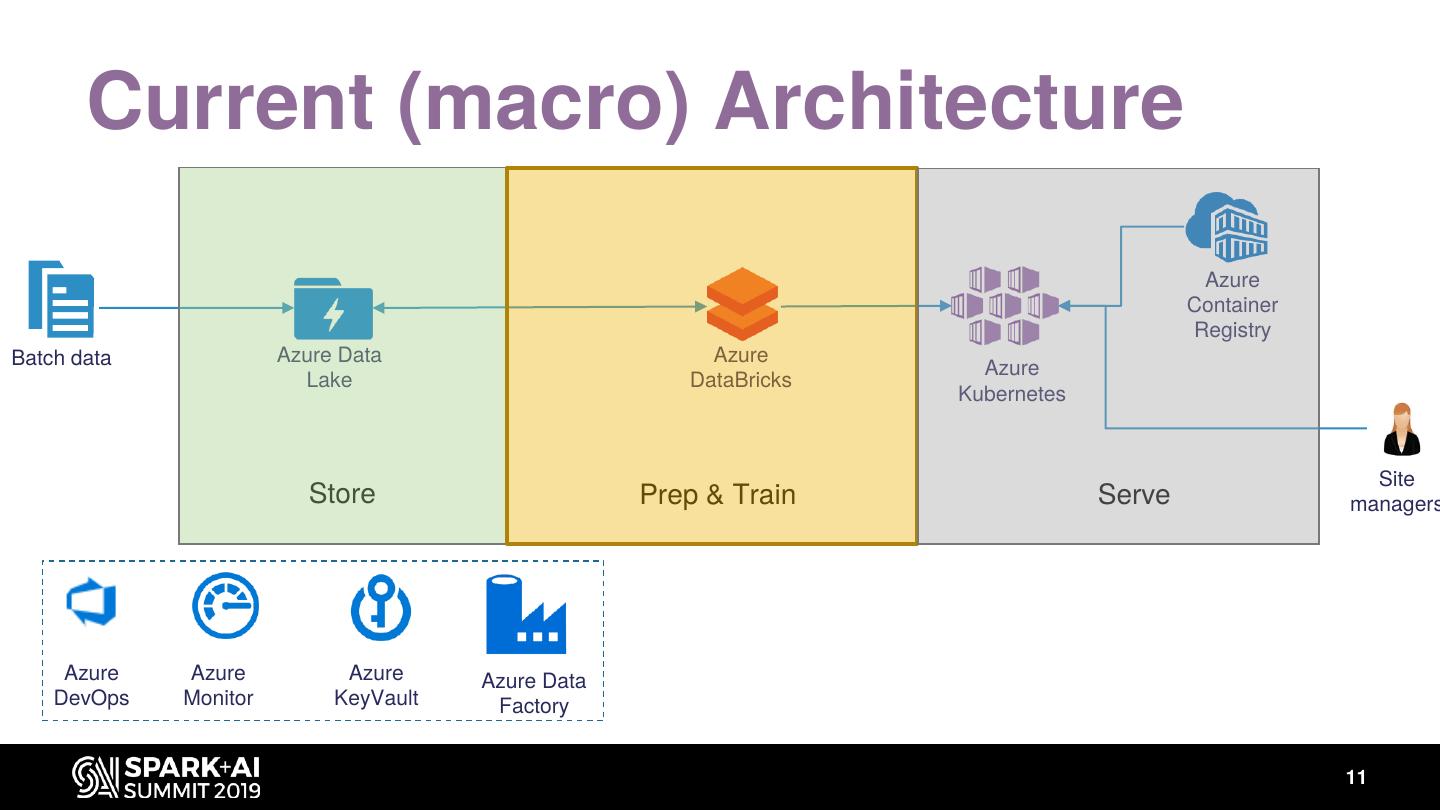
11 . Current (macro) Architecture
Azure
Container
Registry
Batch data Azure Data Azure
Azure
Lake DataBricks
Kubernetes
Site
Store Prep & Train Serve managers
Azure Azure Azure Azure Data
DevOps Monitor KeyVault Factory
11
�
12 .Azure DataBricks
Why migrate?
• Same tools used by data scientist exploration on notebooks &
industrialisation by data engineer
• Managed Spark cluster
• Large compatibility of Spark’s versions
• Centralize all the ETL in Spark whereas split it on several
technologies
12
�
13 .Azure DataBricks
Feedbacks:
• Cluster’s autoScaling gives fine results
• Pools helps to speed up jobs
13
�
14 .Azure DataFactory
Why we use it?
• Managed service
• Native integrated to all azure services and on premise DB
• Easy orchestrate & scheduling
• No limitations on data volume or on the number of files
14
�
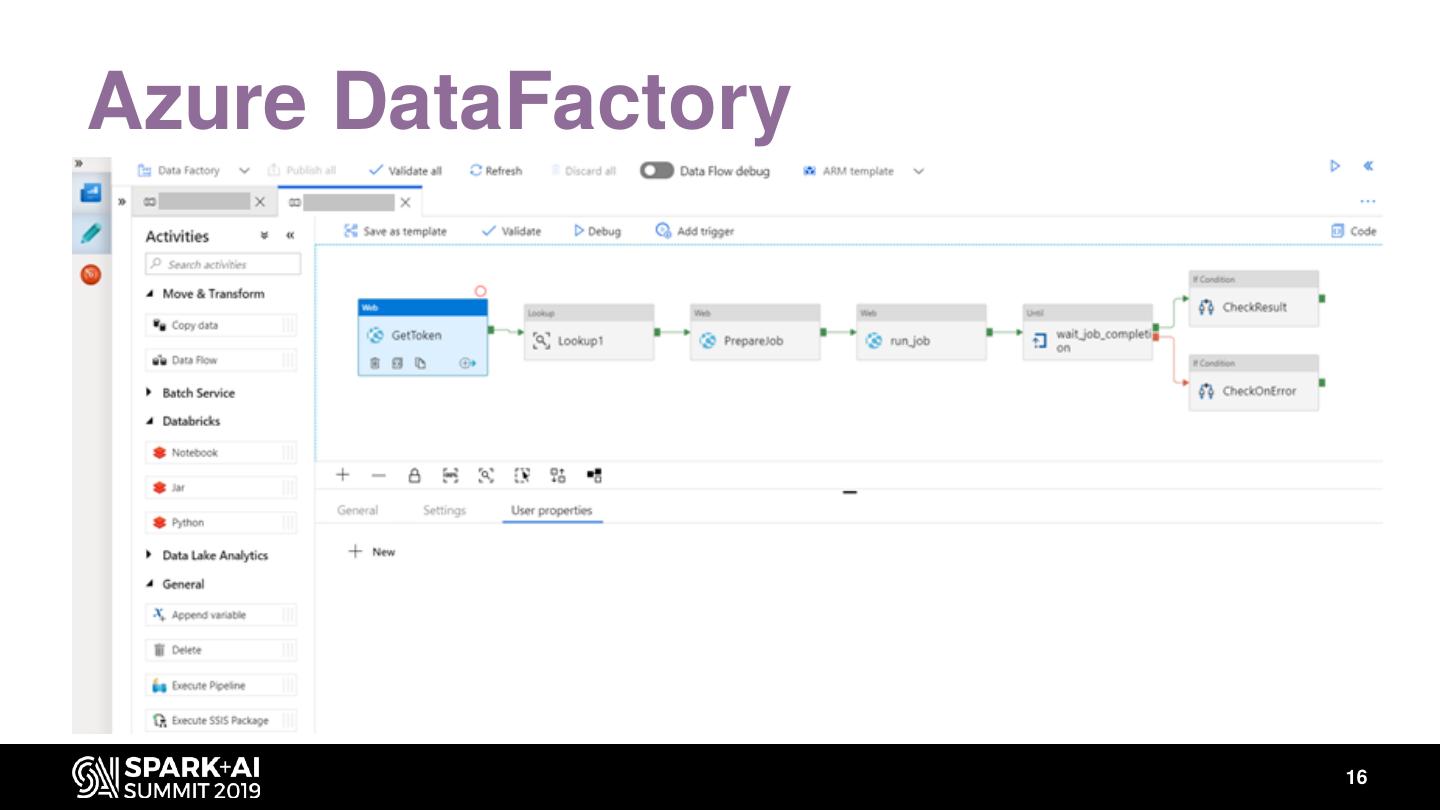
15 .Azure DataFactory
Lesson learned?
• Call to DataBricks via web activity or DataBricks activity
• Cost saving by using a DataBricks cluster job and argparse
compatible
• You can use 1 template for all jobs
15
�
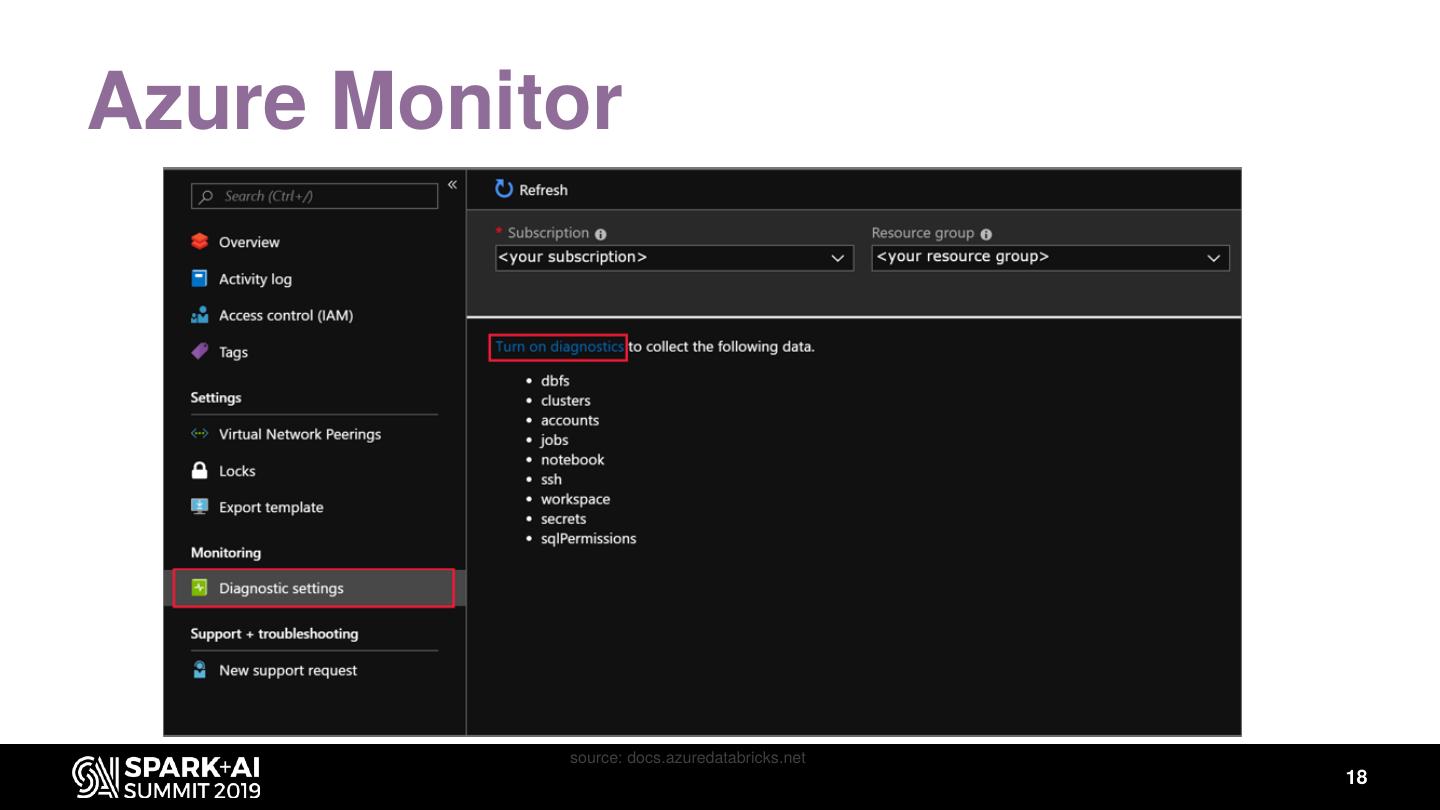
17 .Azure Monitor
Why we use it?
• Monitor, analyze daily run and send mails alerts
• Same tool to get metrics and logs from all the packages of our
software and services of Azure platform (including Databricks)
17
�
18 .Azure Monitor
source: docs.azuredatabricks.net
18
�
19 .Azure Monitor
source: docs.azuredatabricks.net
19
�
20 .Azure Monitor
Lesson learned?
• It uses KQL language with specificities so there is a little learning
curve is to plan
• You can do your own library but rather use SDK for python, java,
JS, C# & .NET to send app logs
20
�
21 .Azure Data Lake
Why we use it?
• Used to store the sources CSV files and output parquet files of
DataBricks jobs
Lesson learned?
• To easily use it, mount the Data Lake with dbutils
• Data Lake Storage Gen2 is converging of Azure Blob storage and
Azure Data Lake Storage Gen1
– not available in all regions
• Large number of files, propagating the permissions can take long
21
�
22 .Azure Kubernetes
Why we use it?
• To host our dashboard, REST API & DataBase
Lesson learned?
• The managed service save you some DevOps time to set up the
cluster
• Configure a secure network can be challenging
22
�
23 .Azure DevOps
• Azure Repos
• Azure Pipelines
source: docs.microsoft.com
23
�
24 .Azure DevOps
• Azure Boards
• Azure Test Plans
• Azure Artifacts
source: docs.microsoft.com
24
�
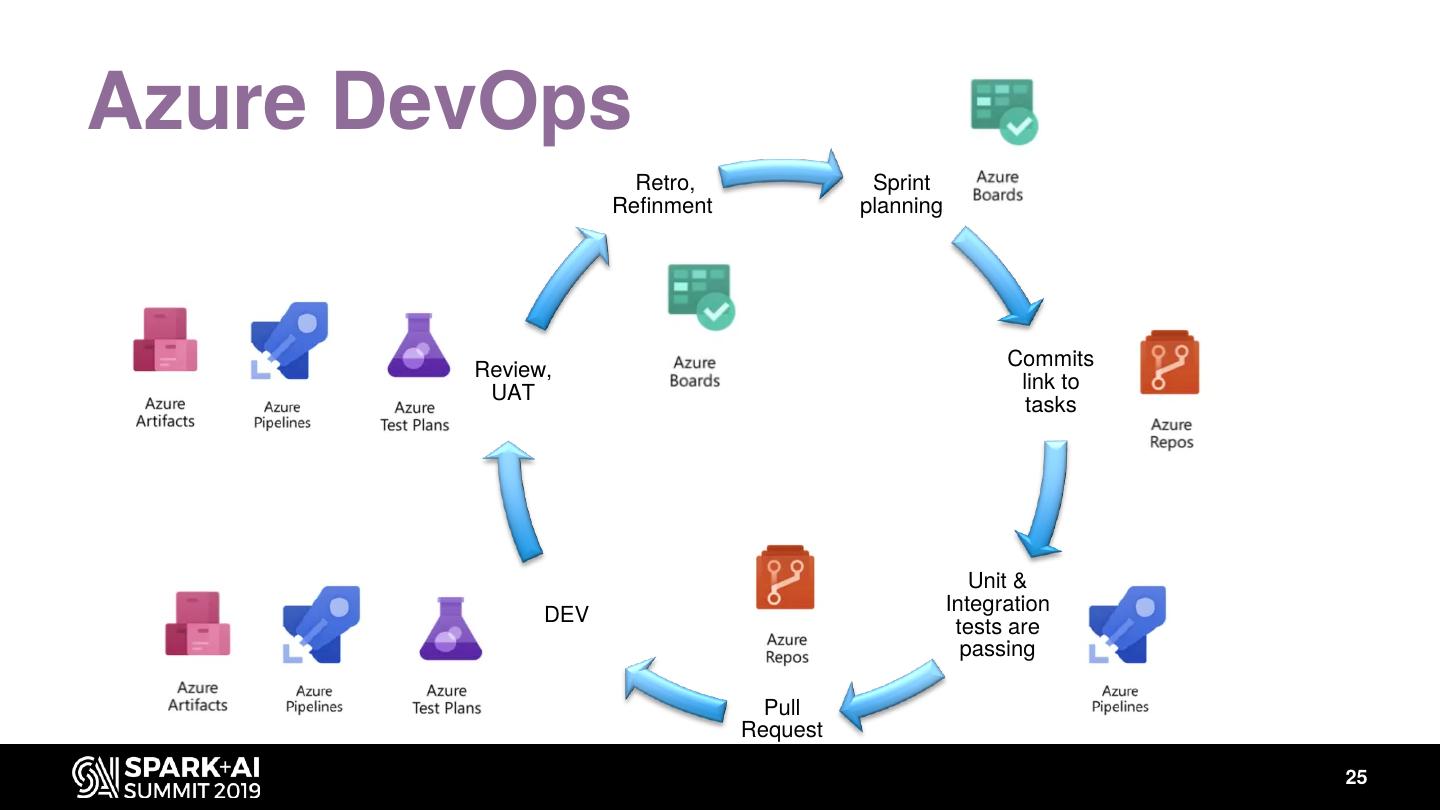
25 .Azure DevOps
Retro, Sprint
Refinment planning
Commits
Review,
link to
UAT
tasks
Unit &
Integration
DEV
tests are
passing
Pull
Request
25
�
26 .•
Our development practices
Use naming conventions
• Validate inputs config or parameters
• New code should come with new tests
• Documents
• Avoid repetitive code
• Use a logger do not print
• Take the time to think about the right data structure to use (a dictionary? Tuple?
Dataframe? Array?)
• Break down responsibilities between the classes
• Code should be easy to explain to a third person (avoid complex code)
• Developers should used an unify development environment
• Use dockerized environments to make simulation of real interactions
• Keep development, UAT, and production as similar as possible
• One codebase protected in revision control, many releases
• Strictly separate build and release stages
26
�
27 .Summary
• To industrialiaze you need to design an architecture that is :
– Versatile
– Easy to maintain
– Operate with low costs
• Azure provides managed services to:
– Orchestrate
– Store
– Set up all your DevOps
– Host
• Finally you need a good team with development practices
27
�
28 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
INTERNAL POSITIONS OPEN!
Please send me any suggestion
or your resume to:
yannick.radji@sodexo.com
SEARCH SPARK + AI SUMMIT
�
29 . Q&A
#UnifiedDataAnalytics #SparkAISummit
�