展开查看详情
1 .Flock: E2E platform
to democratize Data
Science
�
2 .Agenda
Chapter 1:
• GSL’s vantage point
• Why are we building (yet) another Data Science platform?
• Flock platform
• A technology showcase demo
Chapter 2:
• EGML applications in Microsoft: MLflow + ONNX + SQL Server
• Capturing provenance
• Future Work
�
3 .GSL’s vantage point
Applied research lab part of Office of the CTO, Azure Data
1.1M
LoC in products
0.5MLoC in OSS
600k Servers running
LoCin in OSS our code
Azure/Hydra
130+
Publications in top tier
conferences/journals
40Patents
6
GAed or Public Preview
features just this year
�
4 .Systems considered thus far
Cloud Providers Private Services OSS
�
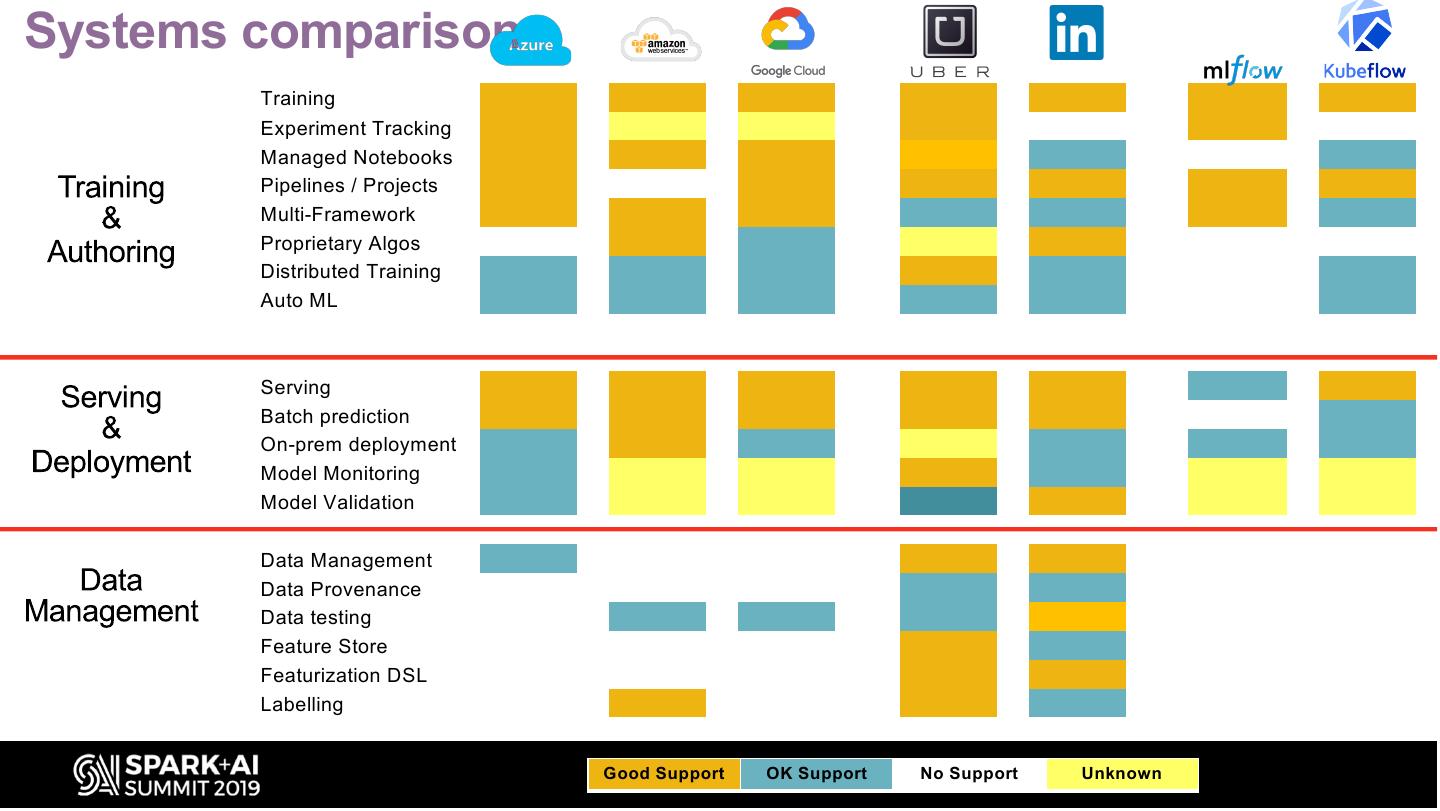
5 .Systems comparison
Training
Experiment Tracking
Managed Notebooks
Pipelines / Projects
Multi-Framework
Proprietary Algos
Distributed Training
Auto ML
Serving
Batch prediction
On-prem deployment
Model Monitoring
Model Validation
Data Management
Data Provenance
Data testing
Feature Store
Featurization DSL
Labelling
Good Support OK Support No Support Unknown
�
6 .Insights
– Data Science is all about data J
– There’s an emerging class of applications:
• Enterprise Grade Machine Learning (EGML – CIDR’20)
– Dichotomy of “smarts” with rudimentary process
» Challenge on account of dual nature of models – software & data
– Couple of key pillars to enable EGML are:
• Tools for automating DS lifecycle
– Only O(100) ipython notebooks in GitHub import mlflow over 1M+ analyzed
– O(1000) for sklearn pipelines
• Data Governance
• (Unified data access)
�
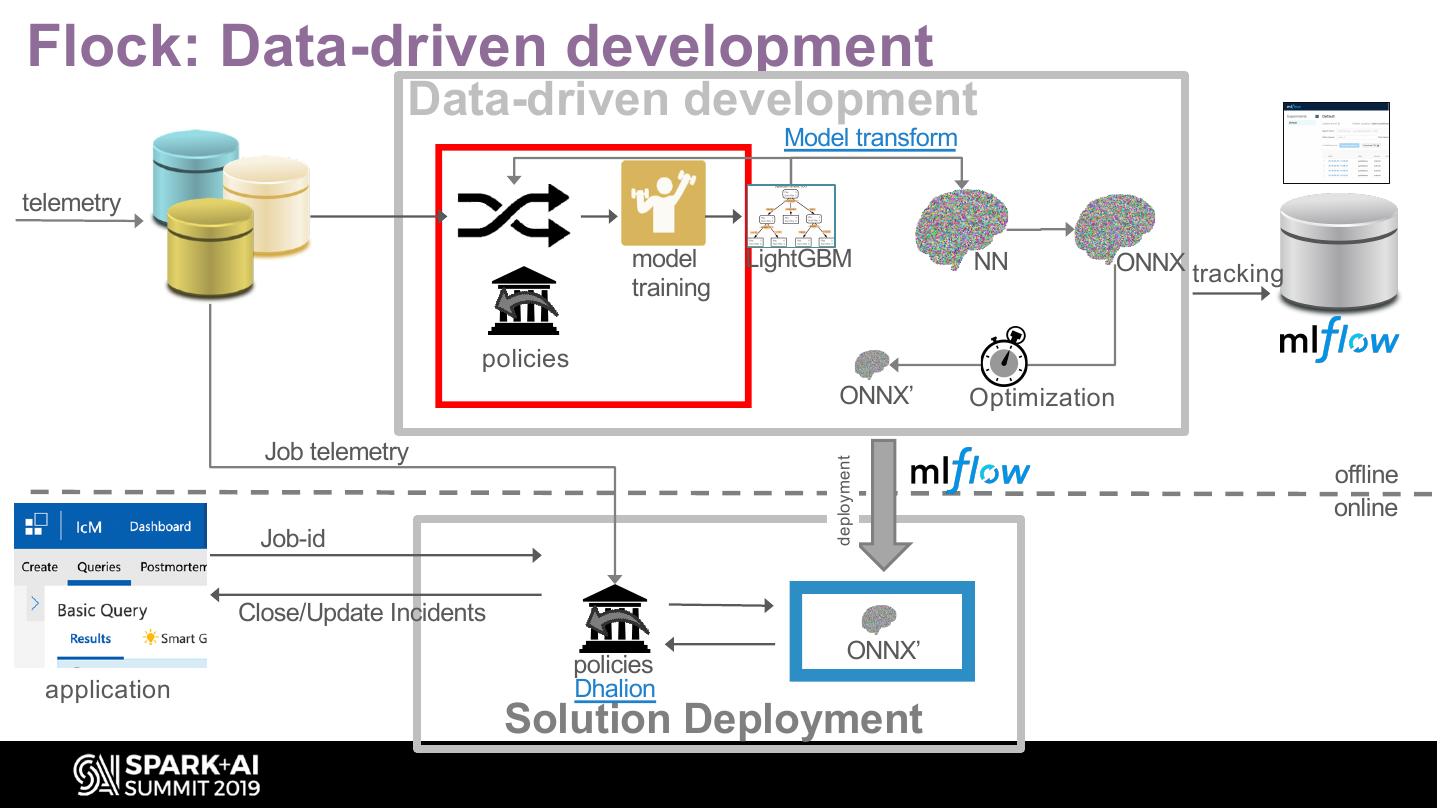
7 .Flock: Data-driven development
Data-driven development
Model transform
telemetry
model LightGBM NN ONNX tracking
training
policies
ONNX’ Optimization
Job telemetry
deployment
offline
online
Job-id
Close/Update Incidents
ONNX’
policies
application Dhalion
Solution Deployment
�
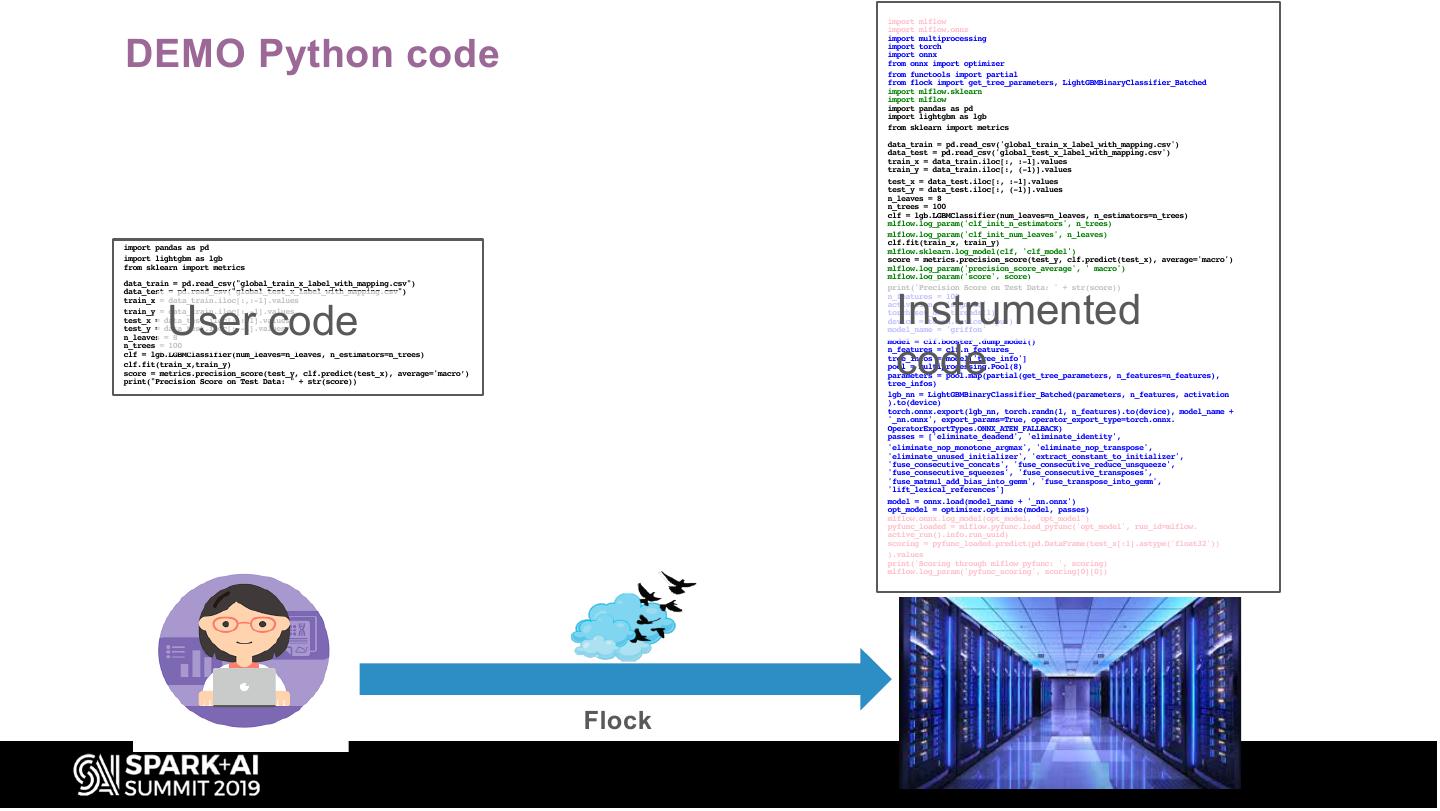
8 . import mlflow
import mlflow.onnx
DEMO Python code
import multiprocessing
import torch
import onnx
from onnx import optimizer
from functools import partial
from flock import get_tree_parameters, LightGBMBinaryClassifier_Batched
import mlflow.sklearn
import mlflow
import pandas as pd
import lightgbm as lgb
from sklearn import metrics
data_train = pd.read_csv('global_train_x_label_with_mapping.csv')
data_test = pd.read_csv('global_test_x_label_with_mapping.csv')
train_x = data_train.iloc[:, :-1].values
train_y = data_train.iloc[:, (-1)].values
test_x = data_test.iloc[:, :-1].values
test_y = data_test.iloc[:, (-1)].values
n_leaves = 8
n_trees = 100
clf = lgb.LGBMClassifier(num_leaves=n_leaves, n_estimators=n_trees)
mlflow.log_param('clf_init_n_estimators', n_trees)
mlflow.log_param('clf_init_num_leaves', n_leaves)
clf.fit(train_x, train_y)
import pandas as pd mlflow.sklearn.log_model(clf, 'clf_model')
import lightgbm as lgb score = metrics.precision_score(test_y, clf.predict(test_x), average='macro')
from sklearn import metrics mlflow.log_param('precision_score_average', ' macro')
mlflow.log_param('score', score)
data_train = pd.read_csv("global_train_x_label_with_mapping.csv") print('Precision Score on Test Data: ' + str(score))
Instrumented
data_test = pd.read_csv("global_test_x_label_with_mapping.csv") n_features = 100
User code
train_x = data_train.iloc[:,:-1].values activation = 'sigmoid'
train_y = data_train.iloc[:,-1].values torch.set_num_threads(1)
test_x = data_test.iloc[:,:-1].values device = torch.device('cpu')
test_y = data_test.iloc[:,-1].values model_name = 'griffon'
n_leaves = 8
code
n_trees = 100 model = clf.booster_.dump_model()
n_features = clf.n_features_
clf = lgb.LGBMClassifier(num_leaves=n_leaves, n_estimators=n_trees) tree_infos = model['tree_info']
clf.fit(train_x,train_y) pool = multiprocessing.Pool(8)
score = metrics.precision_score(test_y, clf.predict(test_x), average='macro’) parameters = pool.map(partial(get_tree_parameters, n_features=n_features),
print("Precision Score on Test Data: " + str(score)) tree_infos)
lgb_nn = LightGBMBinaryClassifier_Batched(parameters, n_features, activation
).to(device)
torch.onnx.export(lgb_nn, torch.randn(1, n_features).to(device), model_name +
'_nn.onnx', export_params=True, operator_export_type=torch.onnx.
OperatorExportTypes.ONNX_ATEN_FALLBACK)
passes = ['eliminate_deadend', 'eliminate_identity',
'eliminate_nop_monotone_argmax', 'eliminate_nop_transpose',
'eliminate_unused_initializer', 'extract_constant_to_initializer',
'fuse_consecutive_concats', 'fuse_consecutive_reduce_unsqueeze',
'fuse_consecutive_squeezes', 'fuse_consecutive_transposes',
'fuse_matmul_add_bias_into_gemm', 'fuse_transpose_into_gemm',
'lift_lexical_references']
model = onnx.load(model_name + '_nn.onnx')
opt_model = optimizer.optimize(model, passes)
mlflow.onnx.log_model(opt_model, 'opt_model')
pyfunc_loaded = mlflow.pyfunc.load_pyfunc('opt_model', run_id=mlflow.
active_run().info.run_uuid)
scoring = pyfunc_loaded.predict(pd.DataFrame(test_x[:1].astype('float32'))
).values
print('Scoring through mlflow pyfunc: ', scoring)
mlflow.log_param('pyfunc_scoring', scoring[0][0])
Flock
�
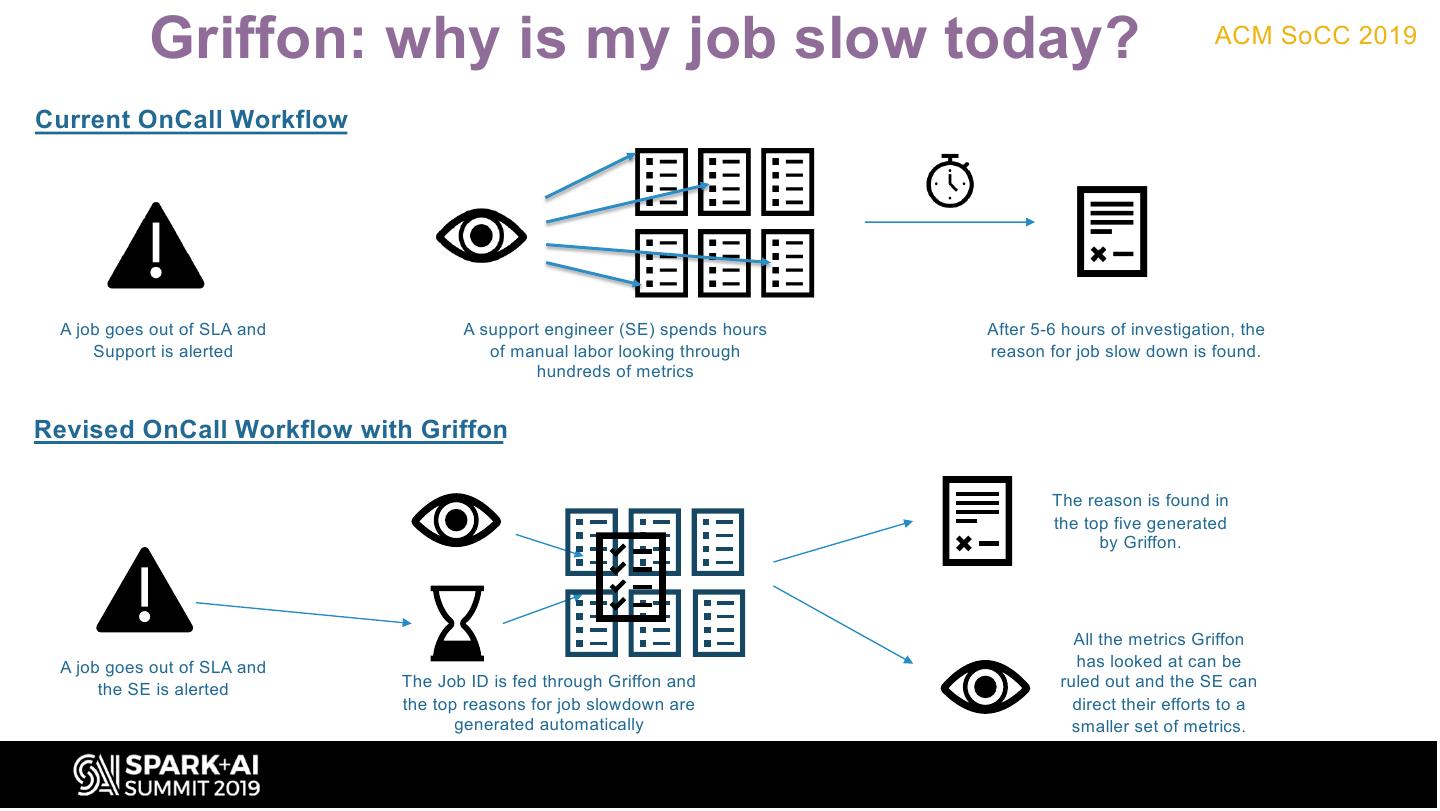
9 . Griffon: why is my job slow today? ACM SoCC 2019
Current OnCall Workflow
A job goes out of SLA and A support engineer (SE) spends hours After 5-6 hours of investigation, the
Support is alerted of manual labor looking through reason for job slow down is found.
hundreds of metrics
Revised OnCall Workflow with Griffon
The reason is found in
the top five generated
by Griffon.
All the metrics Griffon
A job goes out of SLA and has looked at can be
The Job ID is fed through Griffon and ruled out and the SE can
the SE is alerted
the top reasons for job slowdown are direct their efforts to a
generated automatically smaller set of metrics.
�
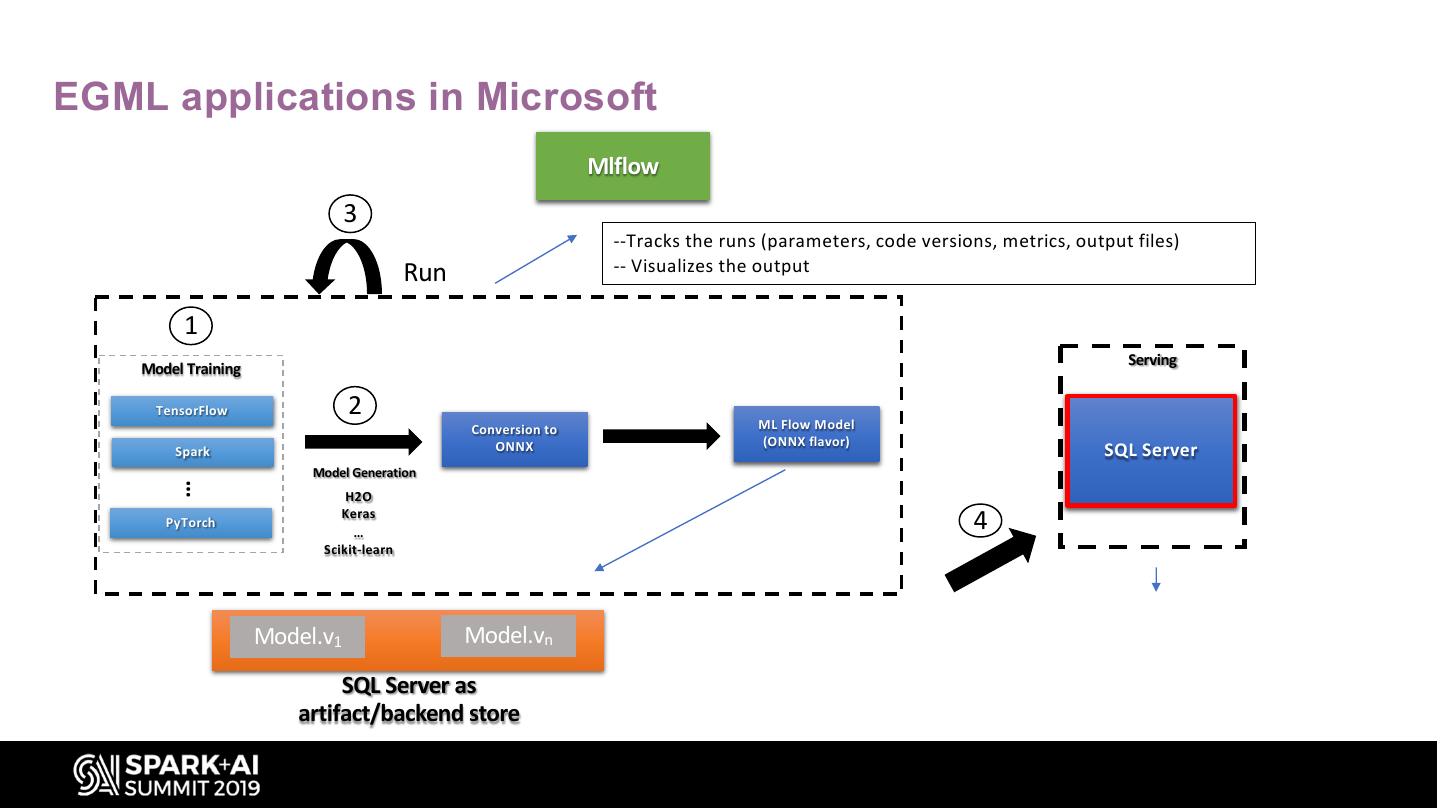
11 .EGML applications in Microsoft
Mlflow
3
--Tracks the runs (parameters, code versions, metrics, output files)
Run -- Visualizes the output
1
Serving
Model Training
TensorFlow 2
Conversion to ML Flow Model
ONNX (ONNX flavor)
Spark SQL Server
Model Generation
…
H2O
PyTorch
Keras
…
4
Scikit-learn
Model.v1 Model.vn
SQL Server as
artifact/backend store
�
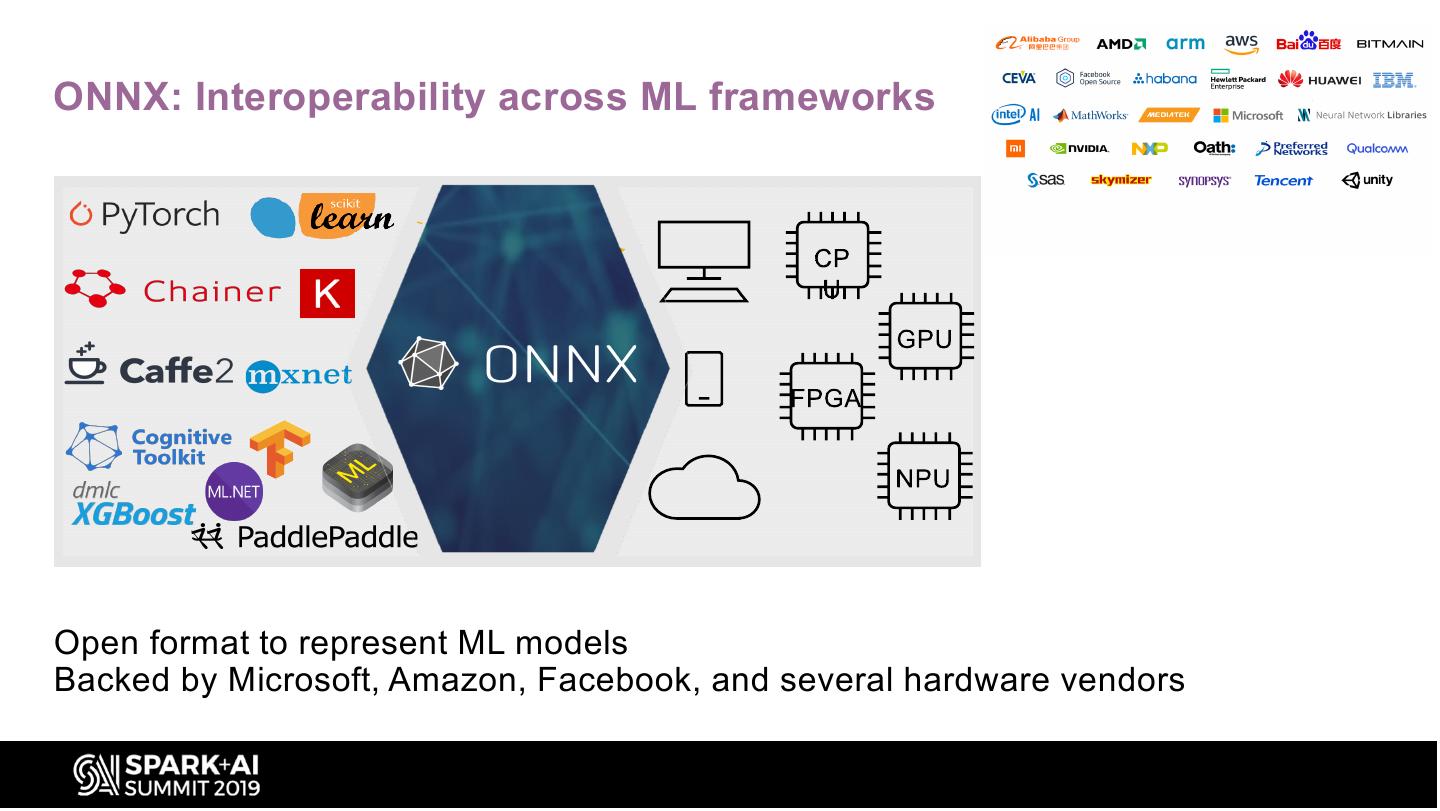
12 .ONNX: Interoperability across ML frameworks
Open format to represent ML models
Backed by Microsoft, Amazon, Facebook, and several hardware vendors
�
13 .ONNX exchange format
• Open format
• Enables interoperability across frameworks
• Many supported frameworks to import/export
– Caffe2, PyTorch, CNTK, MXNet, TensorFlow, CoreML
�
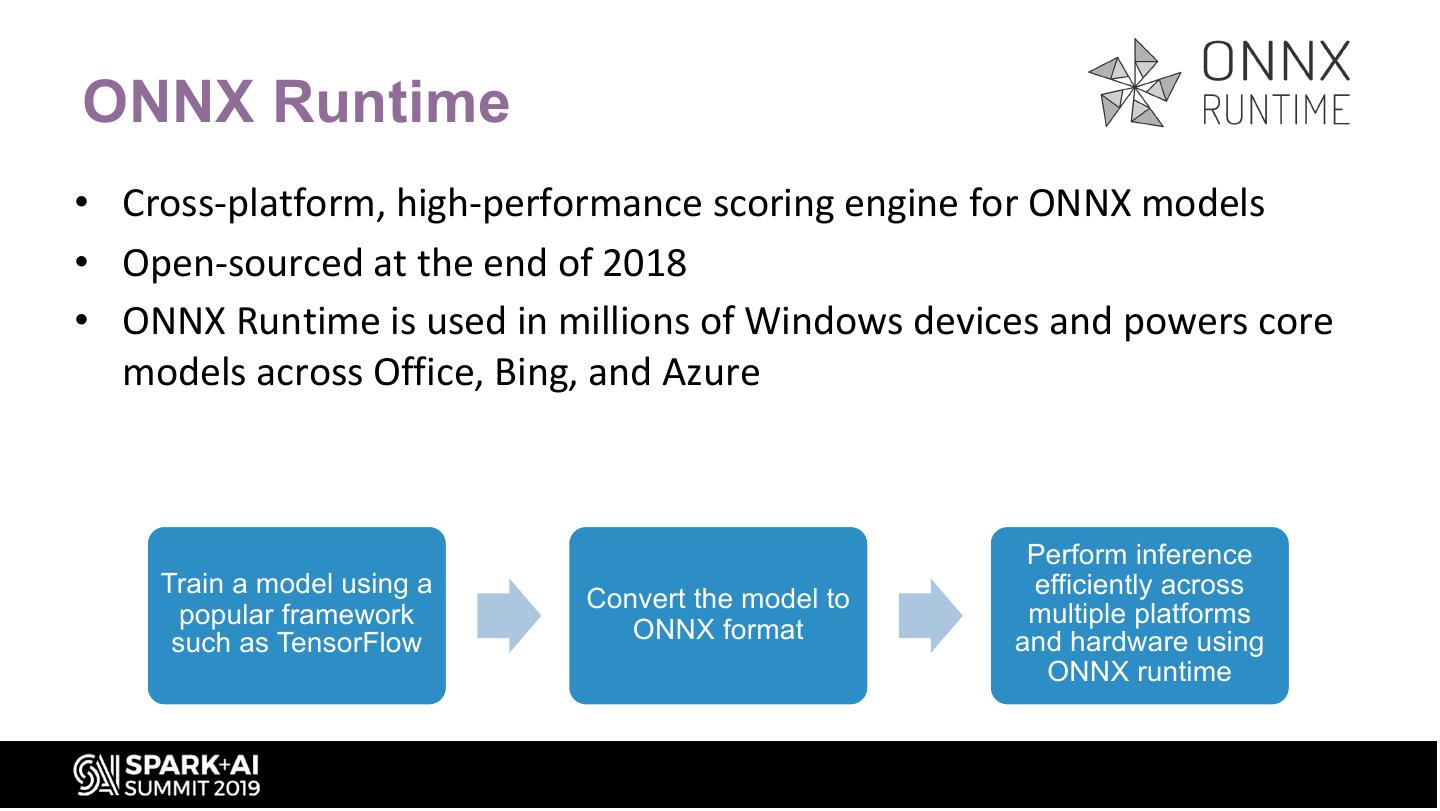
14 .ONNX Runtime
• Cross-platform, high-performance scoring engine for ONNX models
• Open-sourced at the end of 2018
• ONNX Runtime is used in millions of Windows devices and powers core
models across Office, Bing, and Azure
Perform inference
Train a model using a efficiently across
Convert the model to
popular framework multiple platforms
such as TensorFlow ONNX format and hardware using
ONNX runtime
�
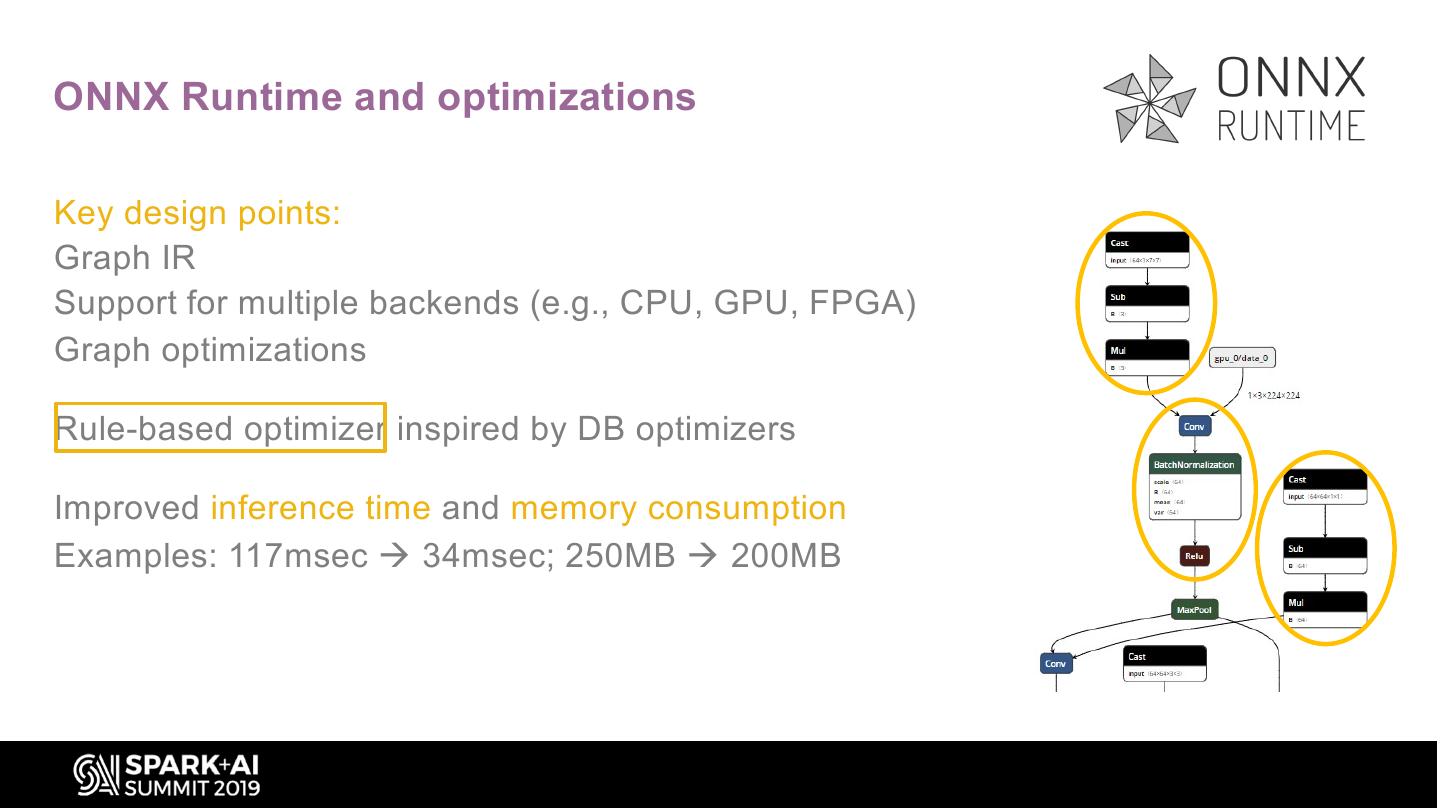
15 .ONNX Runtime and optimizations
Key design points:
Graph IR
Support for multiple backends (e.g., CPU, GPU, FPGA)
Graph optimizations
Rule-based optimizer inspired by DB optimizers
Improved inference time and memory consumption
Examples: 117msec à 34msec; 250MB à 200MB
�
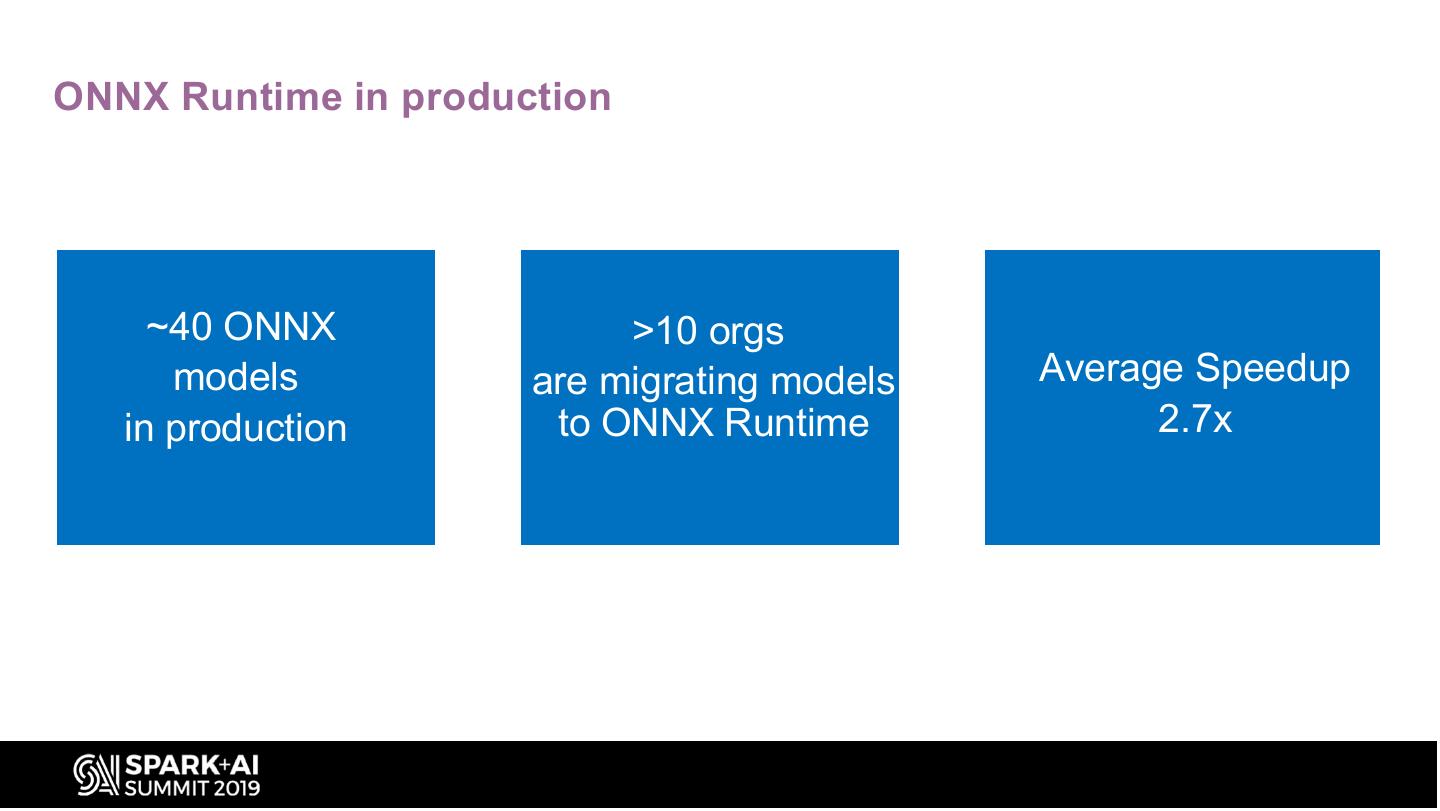
16 .ONNX Runtime in production
~40 ONNX >10 orgs
models are migrating models Average Speedup
in production to ONNX Runtime 2.7x
�
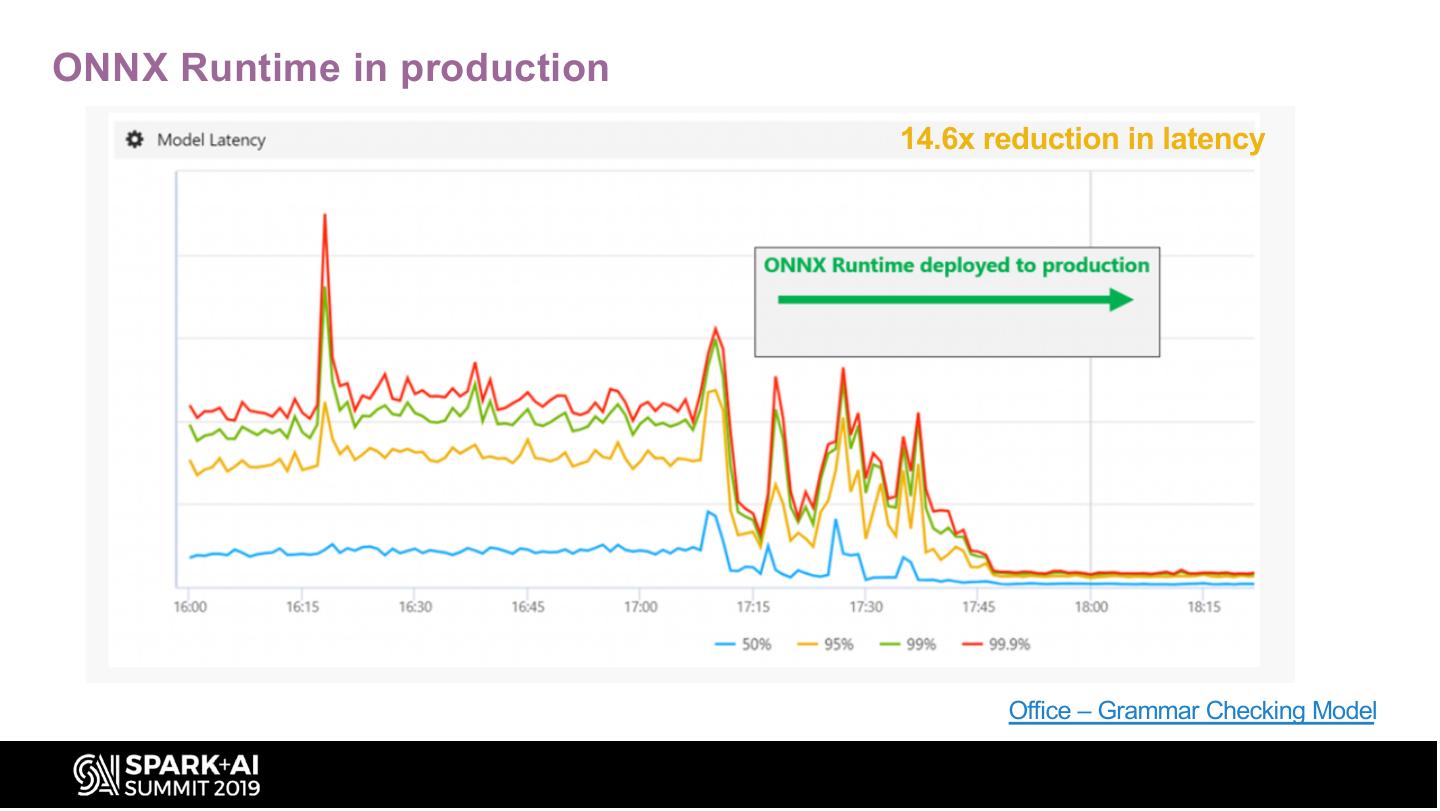
17 .ONNX Runtime in production
14.6x reduction in latency
Office – Grammar Checking Model
�
18 .MLflow + ONNX
• MLflow (1.0.0) has now built-in support for ONNX models
• ONNX model flavor for saving, loading and evaluating ONNX
models
Train a sklearn
model
�
19 . Serving the ONNX model
Deploy the server
mlflow models serve -m /artifacts/model -p 1234
Perform Inference
curl -X POST -H "Content-Type:application/json; format=pandas-split" --data '{"columns":["alcohol", "chlorides", "citric acid", "density", "fixed acidity", "free
sulfur dioxide", "pH", "residual sugar", "sulphates", "total sulfur dioxide", "volatile acidity"],"data":[[12.8, 0.029, 0.48, 0.98, 6.2, 29, 3.33, 1.2, 0.39, 75, 0.66]]}'
http://127.0.0.1:1234/invocations
[6.379428821398614]
ONNX Runtime is
automatically invoked
�
20 .MLflow + SQL Server
• MLflow can use SQL Server as an artifact store (and other
RDBMSs as well) (PR)
• The models are stored in binary format in the database along with
other metadata such as model name, size, run_id, etc.
client = MlflowClient()
exp_name = “test"
client.create_experiment(exp_name, artifact_location="mssql+pyodbc://sa:password@ipAddress:port/dbName?driver=ODBC+Driver+17+for+SQL+Server")
mlflow.set_experiment(exp_name)
mlflow.onnx.log_model(onnx, “model")
�
21 .Provenance in EGML applications
• Need for end-to-end provenance tracking
• Multiple systems involved in each pipeline
Data pre-processing Model Training
Python • Compliance
SQL
Script
• Keeping ML models up-to-date
�
22 . Tracking provenance in Python scripts
Semantic annotation
Python Dependencies
Python through a knowledge
AST between variables
Script base of common ML
generation and functions
libraries
• Automatically identify models, metrics, hyperparameters in python scripts
• Answer questions such as: “Which columns in a dataset were used for model
training?”
Dataset #Scripts %ML models %Training
covered Datasets Covered
Kaggle 49 95% 61%
Microsoft 37 100% 100%
�
23 .Future work
• MLflow:
– Integration with metadata management systems such as Apache Atlas
• Flock:
– Data Governance
– Generalize and extend coverage of auto-tracking and ML à NN
conversion.
– Provenance of end-to-end pipelines
• Combine with other systems (e.g., SQL, Spark)
�