






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

How to Automate Performance Tuning for Apache Spark
How to Automate Performance Tuning for Apache Spark
How to Automate Performance Tuning for Apache Spark
Spark has made writing big data pipelines much easier than before. But a lot of effort is required to maintain performant and stable data pipelines in production over time. Did I choose the right type of infrastructure for my application? Did I set the Spark configurations correctly? Can my application keep running smoothly as the volume of ingested data grows over time? How to make sure that my pipeline always finishes on time and meets its SLA?
These questions are not easy to answer even for a handful of jobs, and this maintenance work can become a real burden as you scale to dozens, hundreds, or thousands of jobs. This talk will review what we found to be the most useful piece of information and parameters to look at for manual tuning, and the different options available to engineers who want to automate this work, from open-source tools to managed services provided by the data platform or third parties like the Data Mechanics platform.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Automating performance tuning for Apache Spark Jean-Yves Stephan & Julien Dumazert, Founders of Data Mechanics #UnifiedDataAnalytics #SparkAISummit
3 .What is performance tuning? Cluster parameters Spark configurations ● Size ● Parallelism ● Instance type ● Shuffle ● # of processors ● Storage ● # of memory ● JVM tuning ● Disks ● Feature flags ● ... ● ... 3
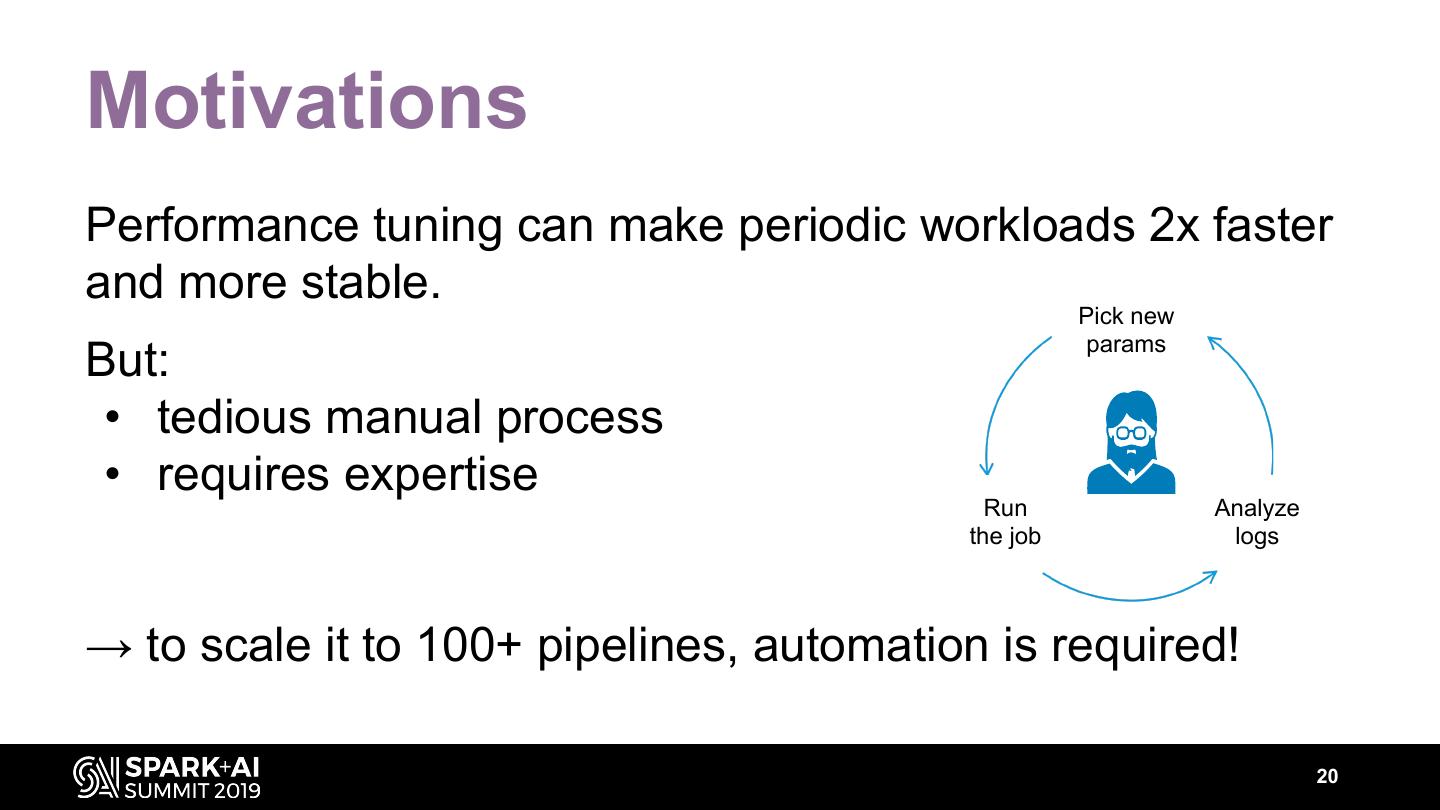
4 .Why automate performance tuning? Pick new params Run Analyze the job logs 4
5 .Why automate performance tuning? Pick new Hard manual work params 30% of your engineers time Frequent outages Pager ringing at 3am Run Analyze Slow and expensive the job logs Missing SLAs every week 5
6 .Agenda Manual Automated performance tuning performance tuning 6
7 .Hands-on performance tuning
8 .Perf tuning is an iterative process For the first run There are rules of thumb for some params: • # of partitions: 3x the number of cores in the cluster • # of cores per executor: 4-8 • memory per executor: 85% * (node memory / # executors by node) For the other params: make an educated guess! 8
9 .Perf tuning is an iterative process On the first attempt, the job crashes or does not meet the SLA. What to do? Pick new params • Ensure stability of the job • Solve performance issues Run Analyze the job logs • Adjust speed-cost trade-off 9
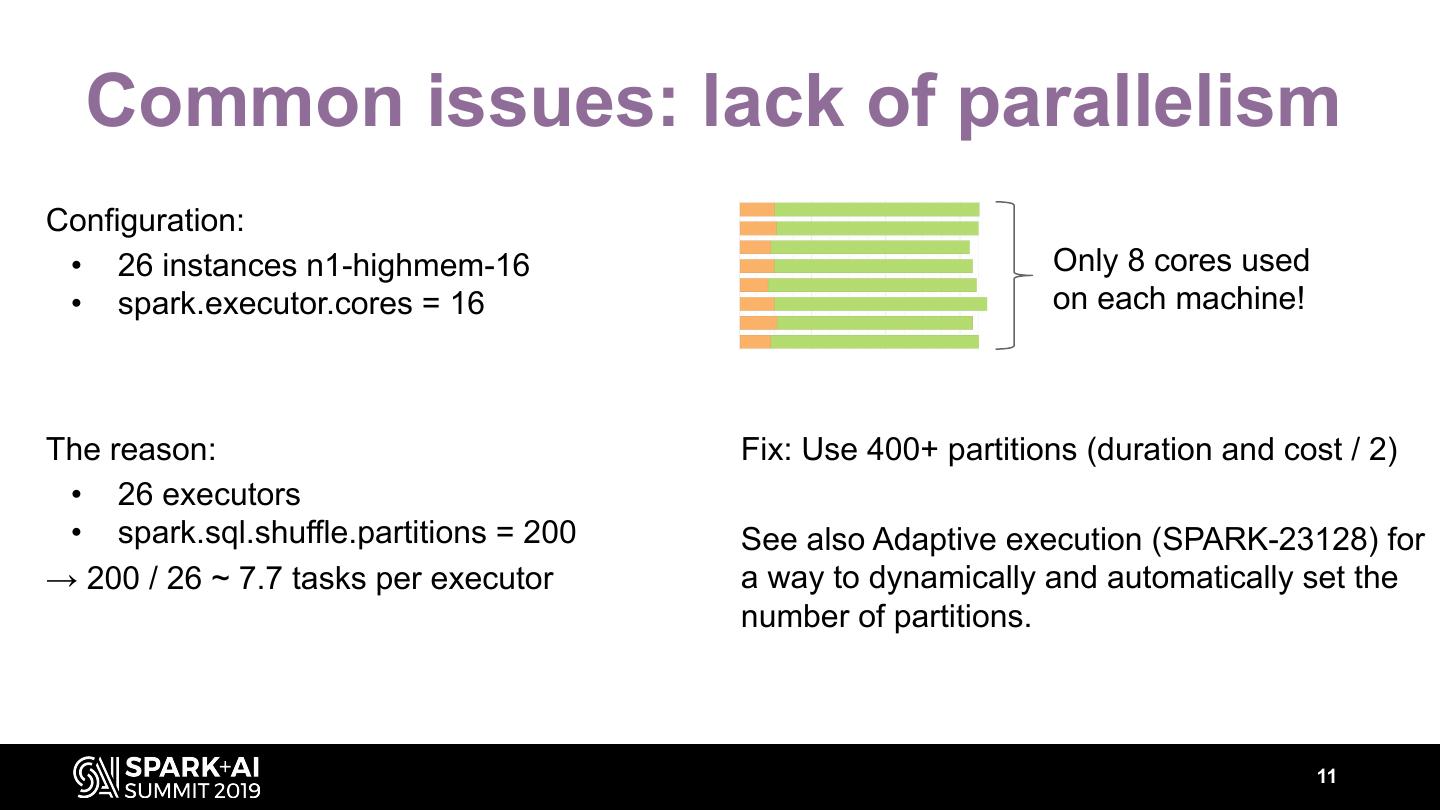
10 . Common issues: lack of parallelism Configuration: • 26 instances n1-highmem-16 Only 8 cores used • spark.executor.cores = 16 on each machine! 10
11 . Common issues: lack of parallelism Configuration: • 26 instances n1-highmem-16 Only 8 cores used • spark.executor.cores = 16 on each machine! The reason: Fix: Use 400+ partitions (duration and cost / 2) • 26 executors • spark.sql.shuffle.partitions = 200 See also Adaptive execution (SPARK-23128) for → 200 / 26 ~ 7.7 tasks per executor a way to dynamically and automatically set the number of partitions. 11
12 . Common issues: shuffle spill The deserialized data produced by the map Fixes: stages in a shuffle does not fit in memory. 1. Reduce the input data of each task by increasing the number of partitions Spark temporarily writes it to disk, which degrades performance. 2. Increase the memory available to each task – by increasing spark executor memory – by decreasing the number of cores per executor 12
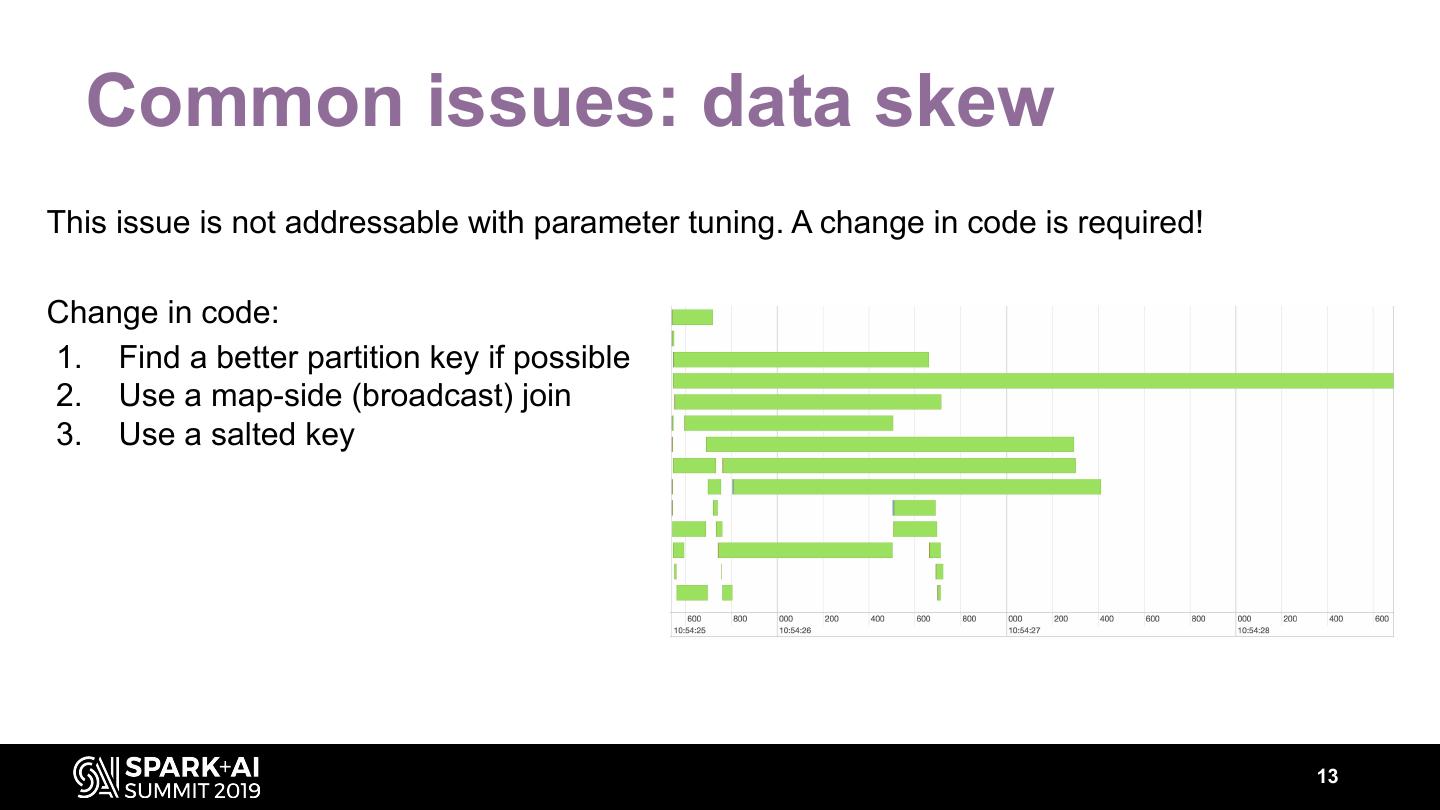
13 . Common issues: data skew This issue is not addressable with parameter tuning. A change in code is required! Change in code: 1. Find a better partition key if possible 2. Use a map-side (broadcast) join 3. Use a salted key 13
14 . Improvements based on node metrics ● Low CPU Usage => Consider oversubscription, ie telling Spark to schedule say 2x more tasks per executor than the number of cores ● Low Memory Usage => Consider pruning the excess memory and switching to CPU-intensive instances ● IO bound queries => Consider switching instance type or Spark IO configurations such as compression or IO buffer sizes 14
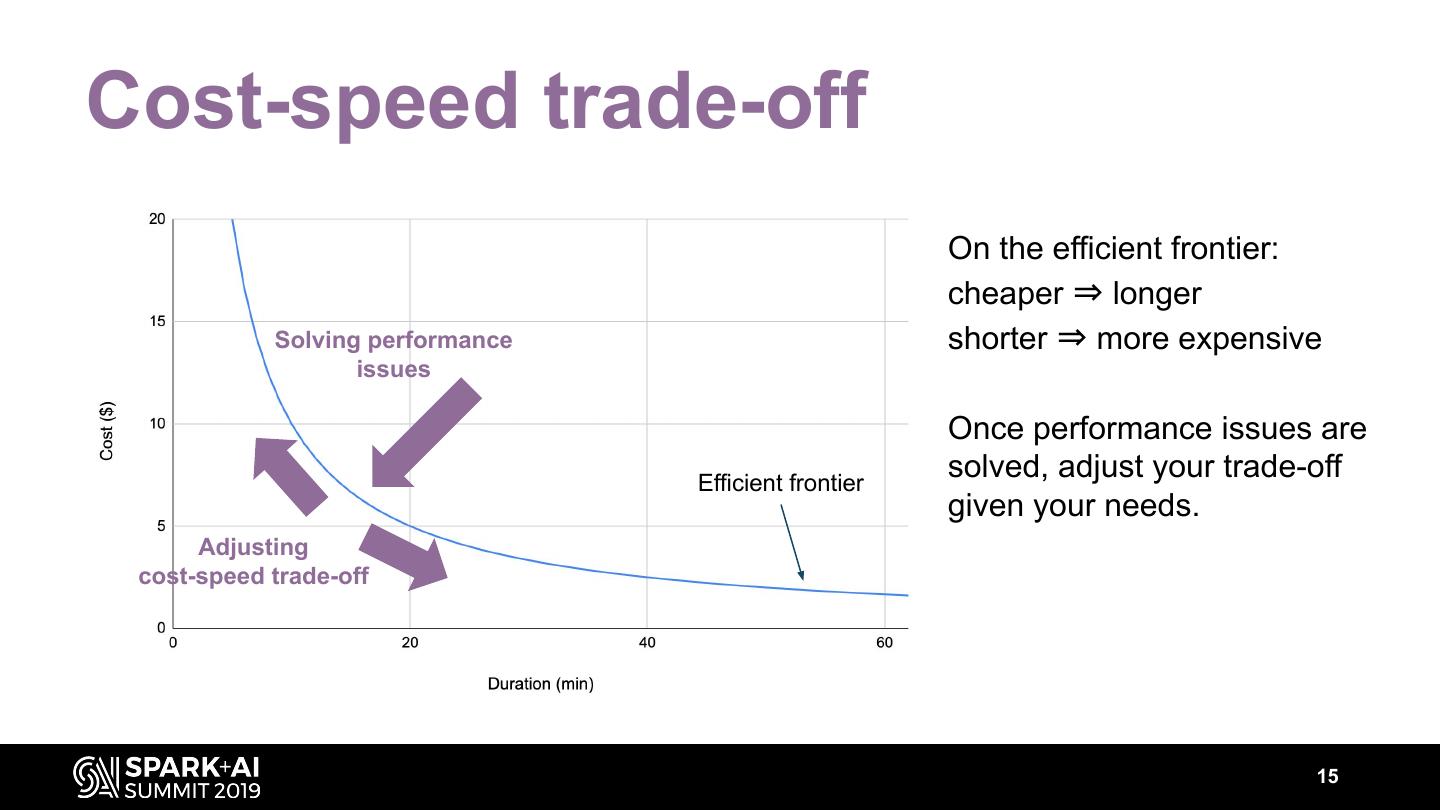
15 .Cost-speed trade-off On the efficient frontier: cheaper ⇒ longer Solving performance shorter ⇒ more expensive issues Once performance issues are Efficient frontier solved, adjust your trade-off given your needs. Adjusting cost-speed trade-off 15
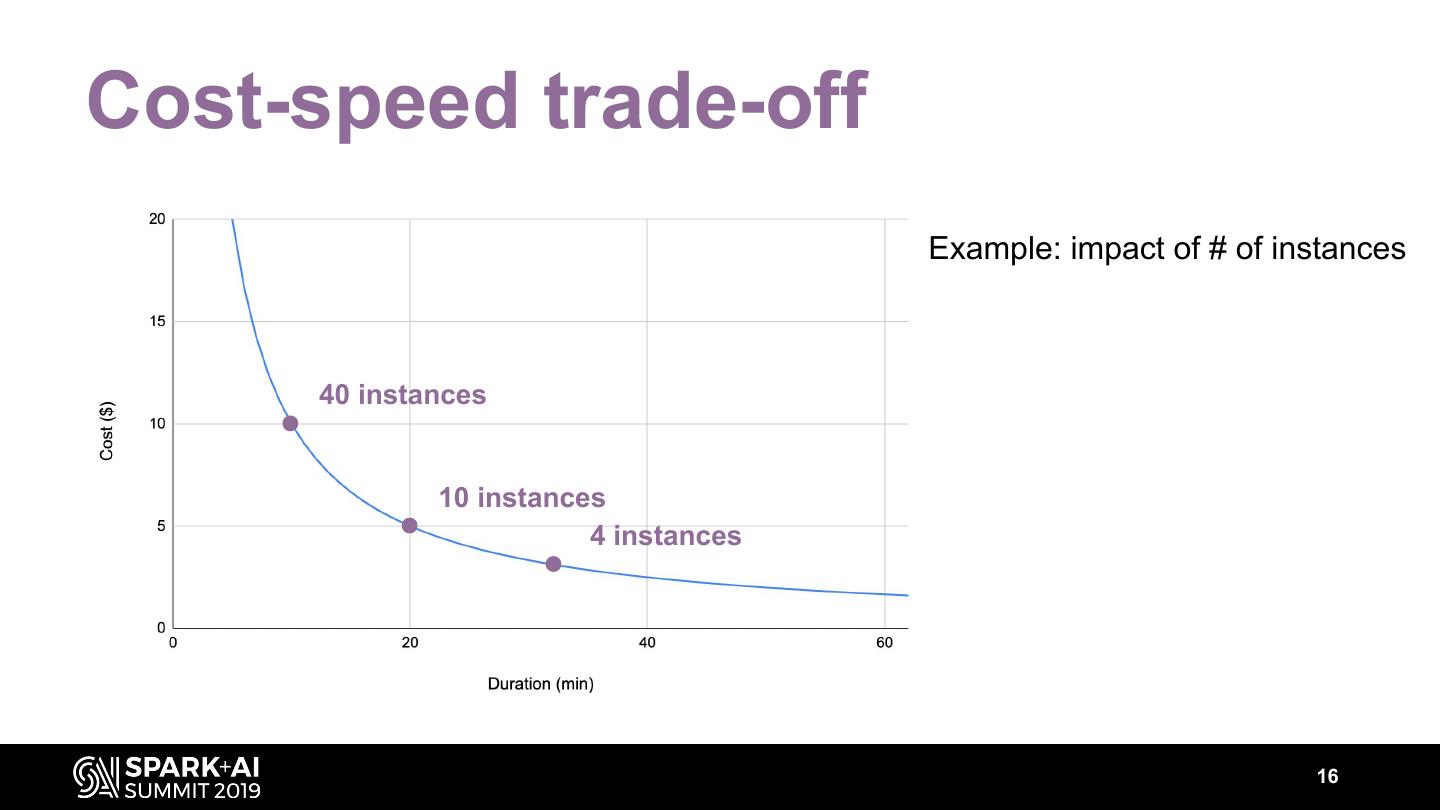
16 .Cost-speed trade-off Example: impact of # of instances 40 instances 10 instances 4 instances 16
17 .Recap: manual perf tuning Iterative process: Most of the impact comes from a few parameters: Solve performance issues • # and type of instances for execs and driver • executor and driver size (memory, # of cores) Adjust cost-speed • # of partitions tradeoff 17
18 .Open source tuning tools To detect performance issues: DrElephant (LinkedIn) To simulate cost-speed trade-off: SparkLens (only supports adjusting # of executors) 18
19 .Automated performance tuning
20 .Motivations Performance tuning can make periodic workloads 2x faster and more stable. Pick new params But: • tedious manual process • requires expertise Run Analyze the job logs → to scale it to 100+ pipelines, automation is required! 20
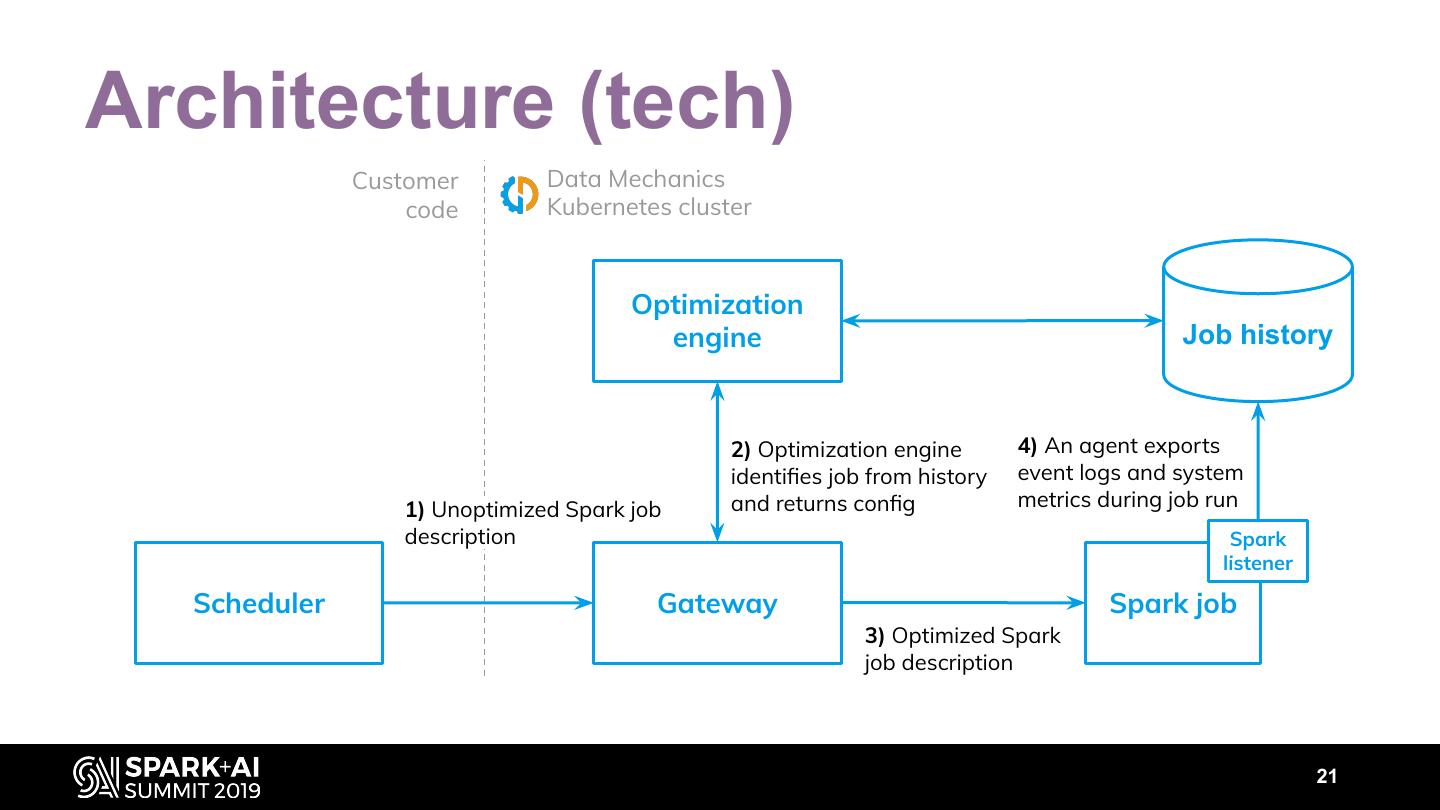
21 .Architecture (tech) Customer Data Mechanics code Kubernetes cluster Optimization engine Job history 2) Optimization engine 4) An agent exports identifies job from history event logs and system 1) Unoptimized Spark job and returns config metrics during job run description Spark listener Scheduler Gateway Spark job 3) Optimized Spark job description 21
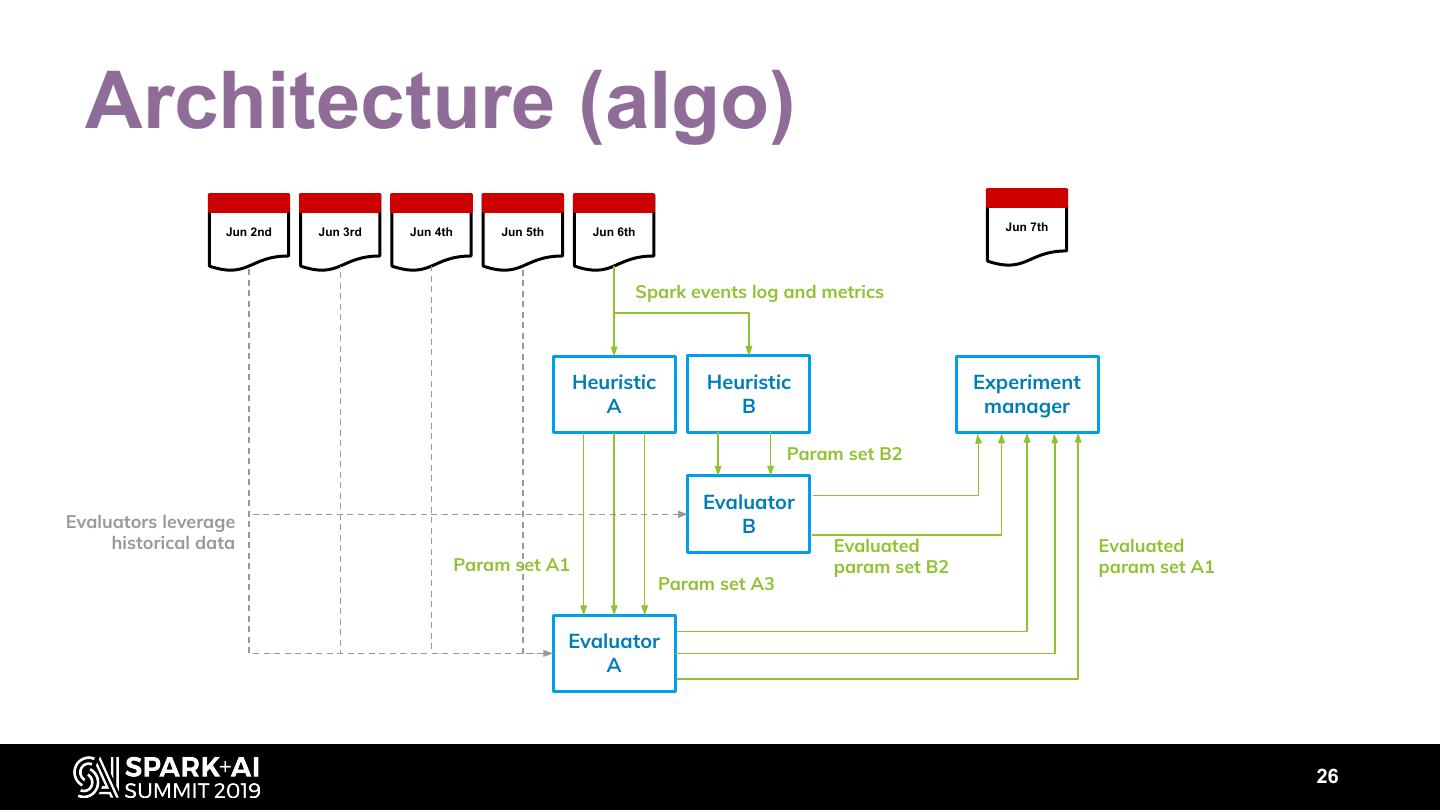
22 .Architecture (algo) Jun 2nd Jun 3rd Jun 4th Jun 5th Jun 6th Jun 7th 23
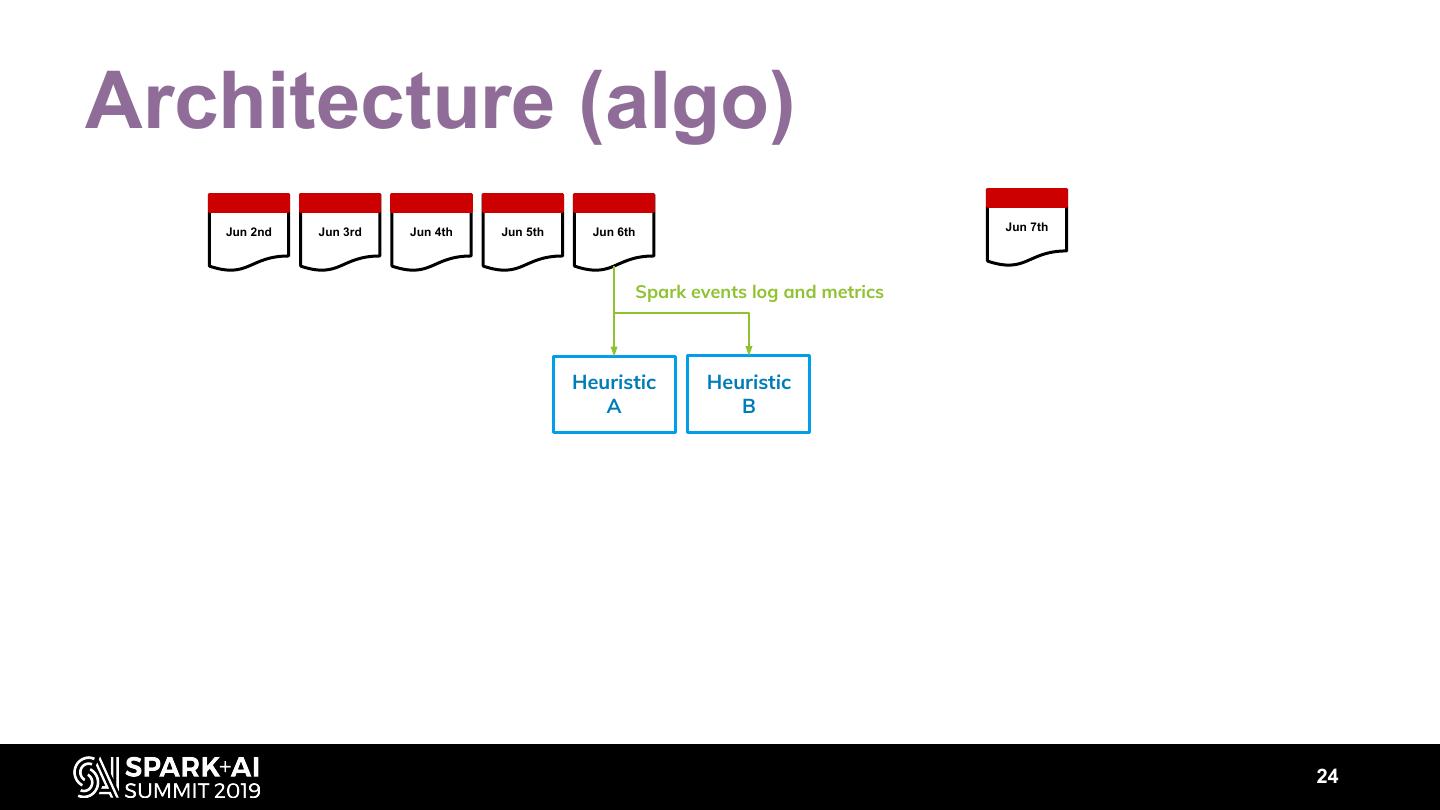
23 .Architecture (algo) Jun 2nd Jun 3rd Jun 4th Jun 5th Jun 6th Jun 7th Spark events log and metrics Heuristic Heuristic A B 24
24 . Architecture (algo) Jun 2nd Jun 3rd Jun 4th Jun 5th Jun 6th Jun 7th Spark events log and metrics Heuristic Heuristic A B Param set B2 Evaluator Evaluators leverage B historical data Param set A1 Param set A3 Evaluator A 25
25 . Architecture (algo) Jun 2nd Jun 3rd Jun 4th Jun 5th Jun 6th Jun 7th Spark events log and metrics Heuristic Heuristic Experiment A B manager Param set B2 Evaluator Evaluators leverage B historical data Evaluated Evaluated Param set A1 param set B2 param set A1 Param set A3 Evaluator A 26
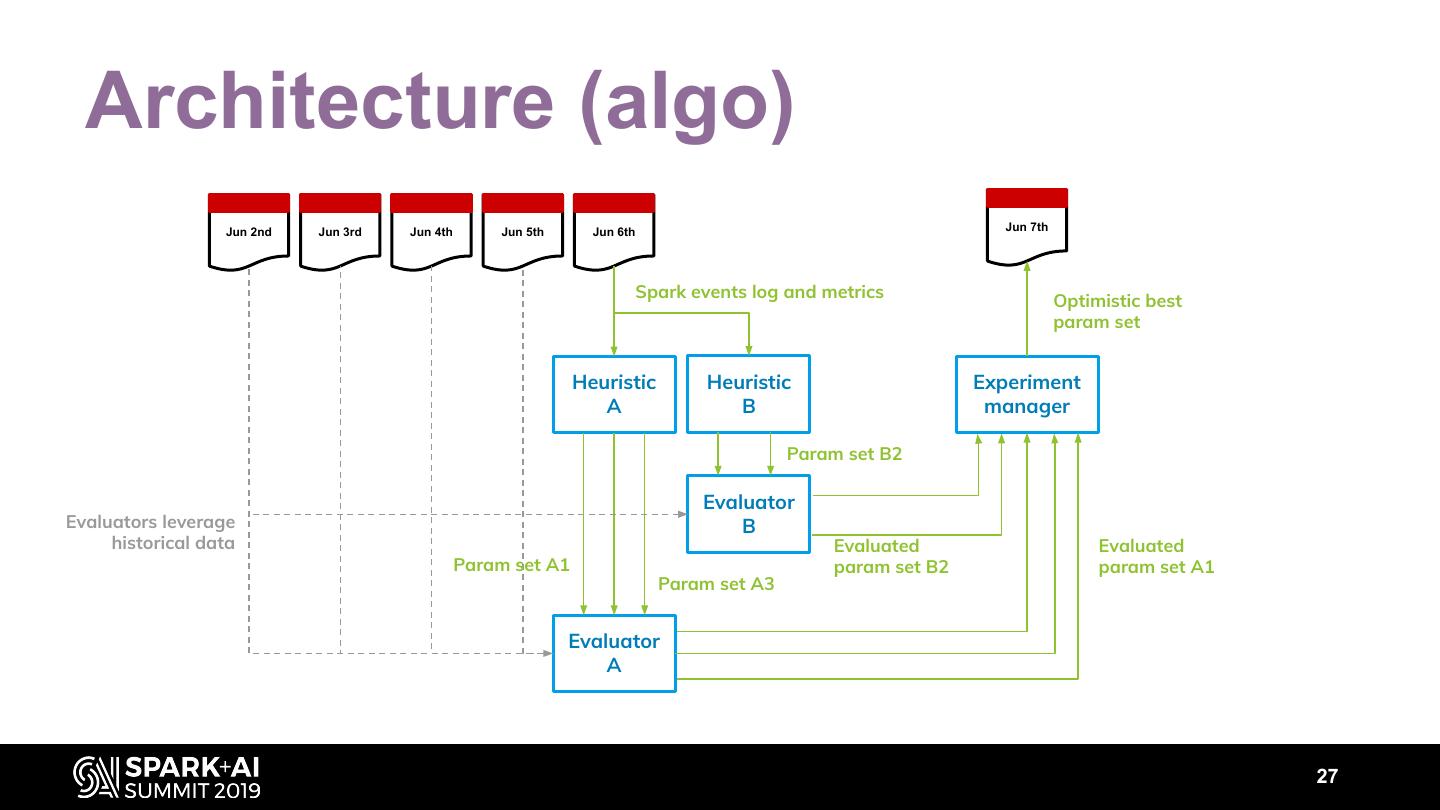
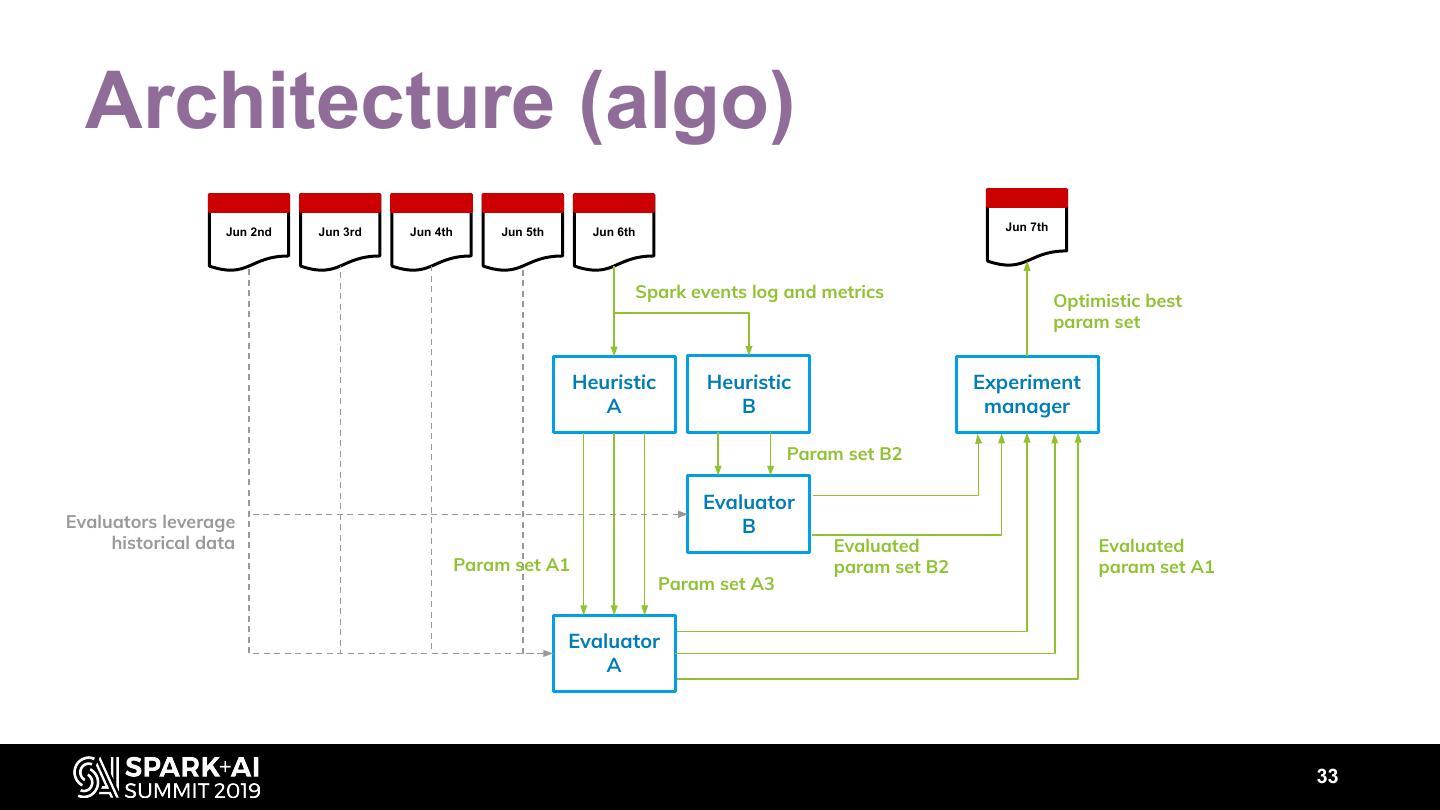
26 . Architecture (algo) Jun 2nd Jun 3rd Jun 4th Jun 5th Jun 6th Jun 7th Spark events log and metrics Optimistic best param set Heuristic Heuristic Experiment A B manager Param set B2 Evaluator Evaluators leverage B historical data Evaluated Evaluated Param set A1 param set B2 param set A1 Param set A3 Evaluator A 27
27 . Heuristics Heuristics look for performance issues: Or push in a given direction: • FewerTasksThanTotalCores • IncreaseDefaultNumPartitions • ShuffleSpill • IncreaseTotalCores • LongShuffleReadTime • … • LongGC Jun 6th • ExecMemoryLargerThanNeeded • TooShortTasks Spark events log and metrics • CPUTimeShorterThanComputeTime • … Heuristic Heuristic A B Every heuristic proposes different param sets. Param sets 28
28 . Heuristics example FewerTasksThanTotalCores If a stage has fewer tasks than the total number of cores: 1. Increase the default number of partitions if applicable 2. Decrease the number of instances Jun 6th 3. Decrease the # of cores per instance (and adjust Spark events log and metrics memory) Heuristic Heuristic A B Param sets 29
29 .Ranking param sets Unevaluated param sets Evaluator Evaluator A B Param sets cost and duration are evaluated by Evaluators. The Experiment manager selects the best solution Experiment according to customer settings. manager Optimistic best param set 30
3秒后跳转登录页面
去登陆

