展开查看详情
1 .High-Performance Analytics
with spark-alchemy
Sim Simeonov, Founder & CTO, Swoop
@simeons / sim at swoop dot com
�
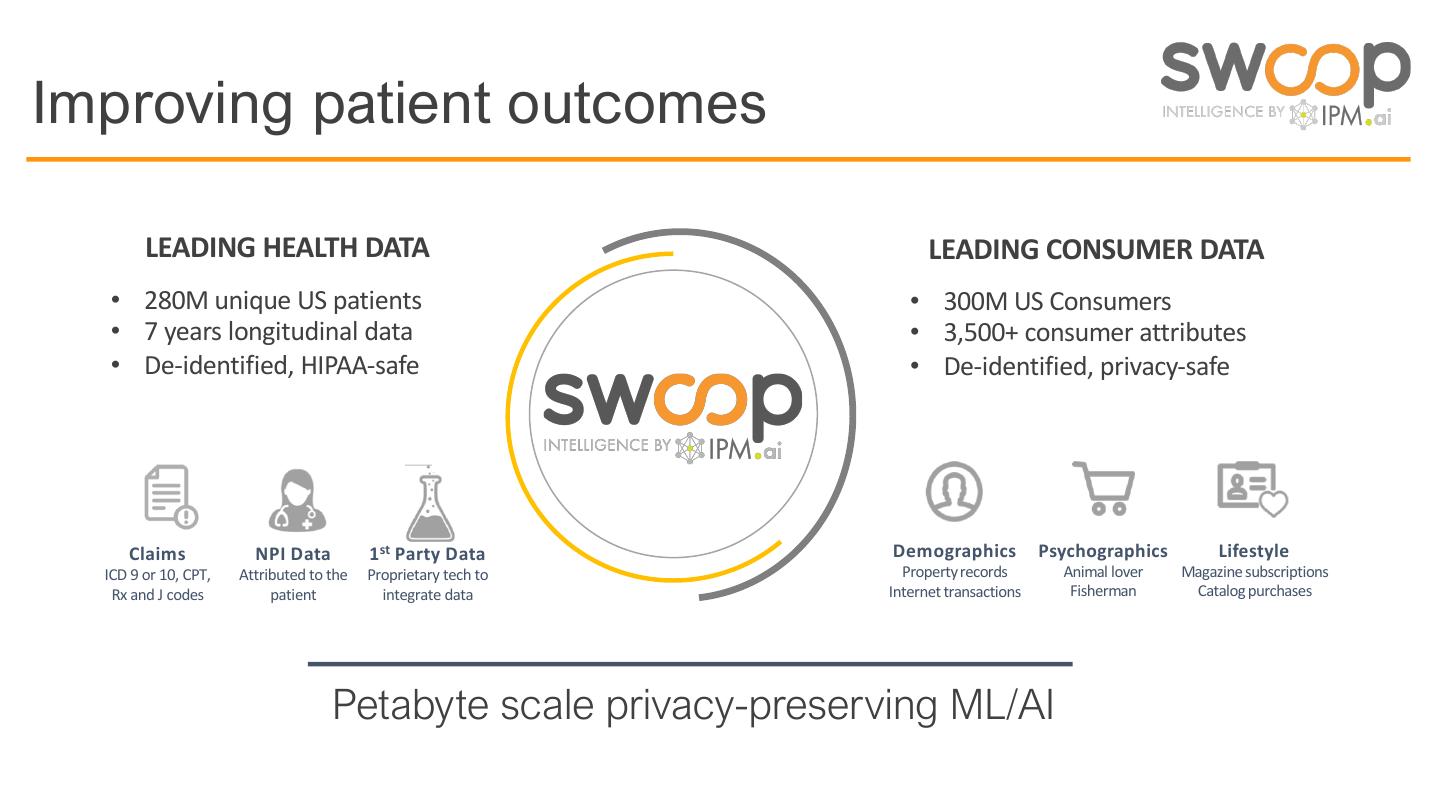
2 .Improving patient outcomes
LEADING HEALTH DATA LEADING CONSUMER DATA
• 280M unique US patients • 300M US Consumers
• 7 years longitudinal data • 3,500+ consumer attributes
• De-identified, HIPAA-safe • De-identified, privacy-safe
Claims NPI Data 1 st Party Data Demographics Psychographics Lifestyle
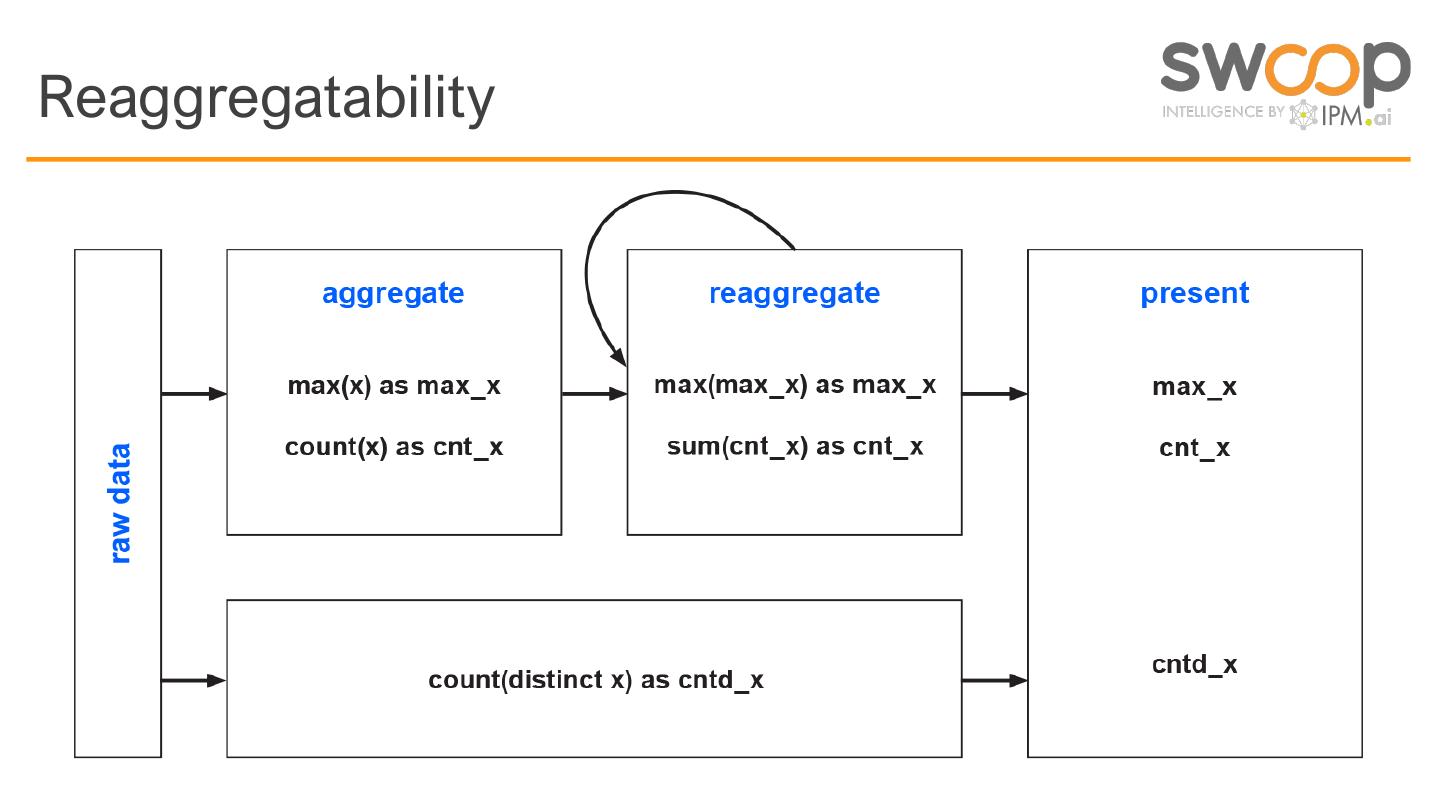
ICD 9 or 10, CPT, Attributed to the Proprietary tech to Propertyrecords Animal lover Magazine subscriptions
Rx and J codes patient integrate data Internet transactions Fisherman Catalog purchases
Petabyte scale privacy-preserving ML/AI
�
3 .http://bit.ly/spark-records
�
4 .http://bit.ly/spark-alchemy
�
5 .The key to high-performance analytics
process fewer rows of data
�
6 . the most important attribute of a
high-performance analytics system
is the reaggregatability of its data
�
7 . count(distinct …)
is the bane of high-performance analytics
because it is not reaggregatable
�
9 .Demo system: prescriptions in 2018
• Narrow sample root
|-- date: date
• 10.7 billion rows / 150Gb |-- generic: string
• Small-ish Spark 2.4 cluster |-- brand: string
|-- product: string
• 80 cores, 600Gb RAM |-- patient_id: long
• Delta Lake, fully cached |-- doctor_id: long
�
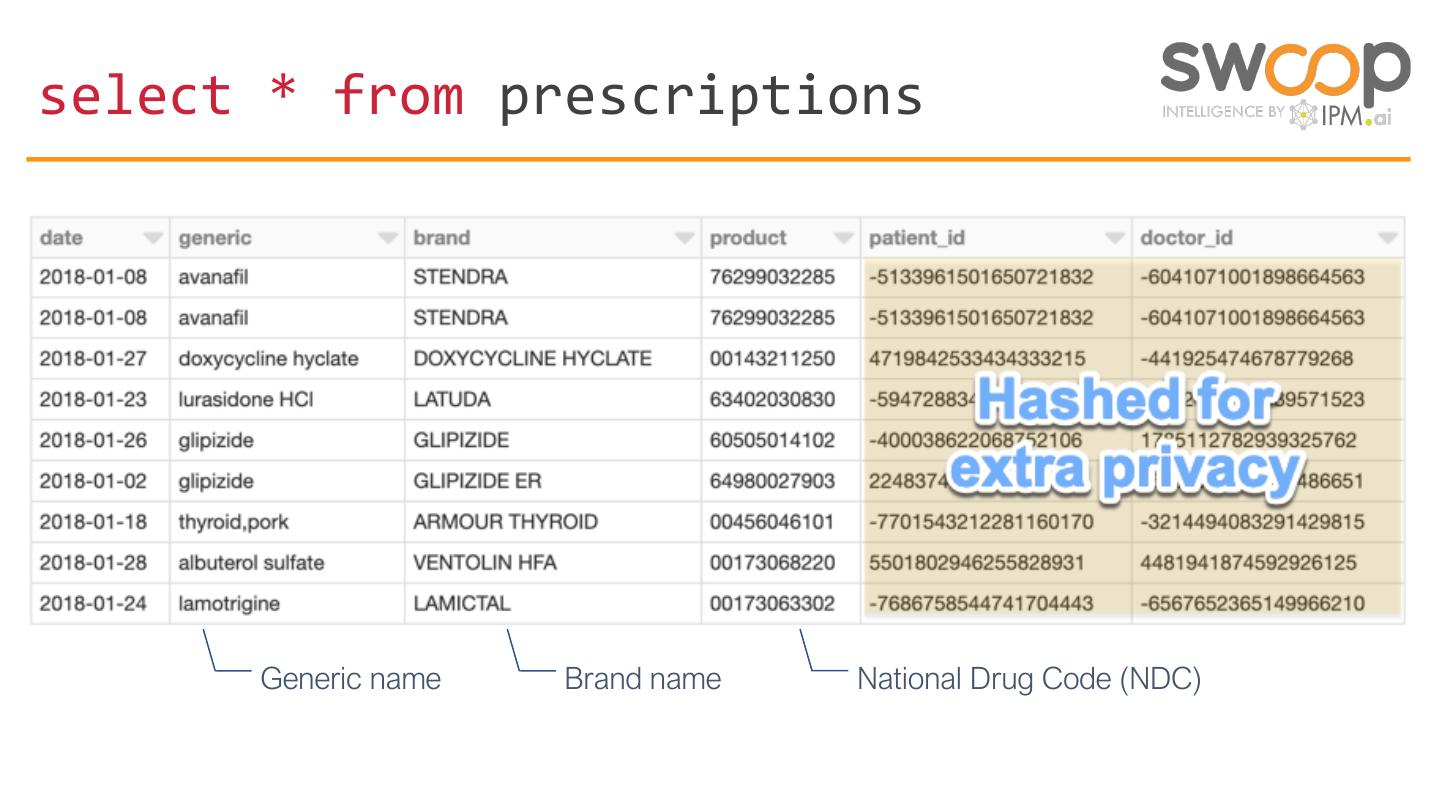
10 .select * from prescriptions
Generic name Brand name National Drug Code (NDC)
�
11 .Count scripts, generics & brands by month
select
to_date(date_trunc("month", date)) as date,
count(distinct generic) as generics,
count(distinct brand) as brands,
count(*) as scripts
from prescriptions
group by 1
Time: 145 secs
0Gb
order by 1
put: 10.7B rows / 1
In b
M rows / 1G
Shuffle: 39
�
12 .Divide & conquer
decompose aggregate(…) into
reaggregate(preaggregate(…))
Do this many times Do this once
�
13 .Preaggregate by generic & brand by month
create table prescription_counts_by_month
select
to_date(date_trunc("month", date)) as date,
generic,
brand,
count(*) as scripts
from prescriptions
group by 1, 2, 3
�
14 .Count scripts, generics & brands by month v2
select
to_date(date_trunc("month", date)) as date,
count(distinct generic) as generics,
count(distinct brand) as brands,
count(*) as scripts
from prescription_counts_by_month
group by 1 r)
e: 3 secs (50x faste
Tim 0Mb
order by 1
pu t: 2.6 M rows / 10
In 0Mb
M rows / 10
Shuffle: 2.6
�
15 .Only 50x faster because of job startup cost
select *, raw_count / agg_count as row_reduction
from
(select count(*) as raw_count from prescriptions)
cross join
(select count(*) as agg_count from prescription_counts_by_month)
�
16 .The curse of high cardinality (1 of 2)
high row reduction is only possible when
preaggregating low cardinality dimensions,
such as generic (7K) and brand (20K), but not
product (350K) or patient_id (300+M)
�
17 .The curse of high cardinality (2 of 2)
small shuffles are only possible with
low cardinality count(distinct …)
�
18 .Adding a high-cardinality distinct count
select
to_date(date_trunc("month", date)) as date,
count(distinct generic) as generics,
count(distinct brand) as brands,
count(distinct patient_id) as patients,
count(*) as scripts
from prescriptions
Time: 370 secs :(
1Gb
group by 1
put: 10.7B rows / 2 b
In 2G
order by 1 B rows / 10
Shuffle: 7.5
�
19 .Maybe approximate counting can help?
�
20 .Approximate counting, default 5% error
select
to_date(date_trunc("month", date)) as date,
approx_count_distinct(generic) as generics,
approx_count_distinct(brand) as brands,
approx_count_distinct(patient_id) as patients,
count(*) as scripts
from prescriptions
1 20 secs (3x faster)
group by 1 Time: ows / 21Gb
10 .7B r
Input: 7Mb
order by 1 : 6K rows /
Shuffle
�
21 .3x faster is not good enough
approx_count_distinct()
still has to look at every row of data
�
22 . How do we preaggregate
high cardinality data
to compute distinct counts?
�
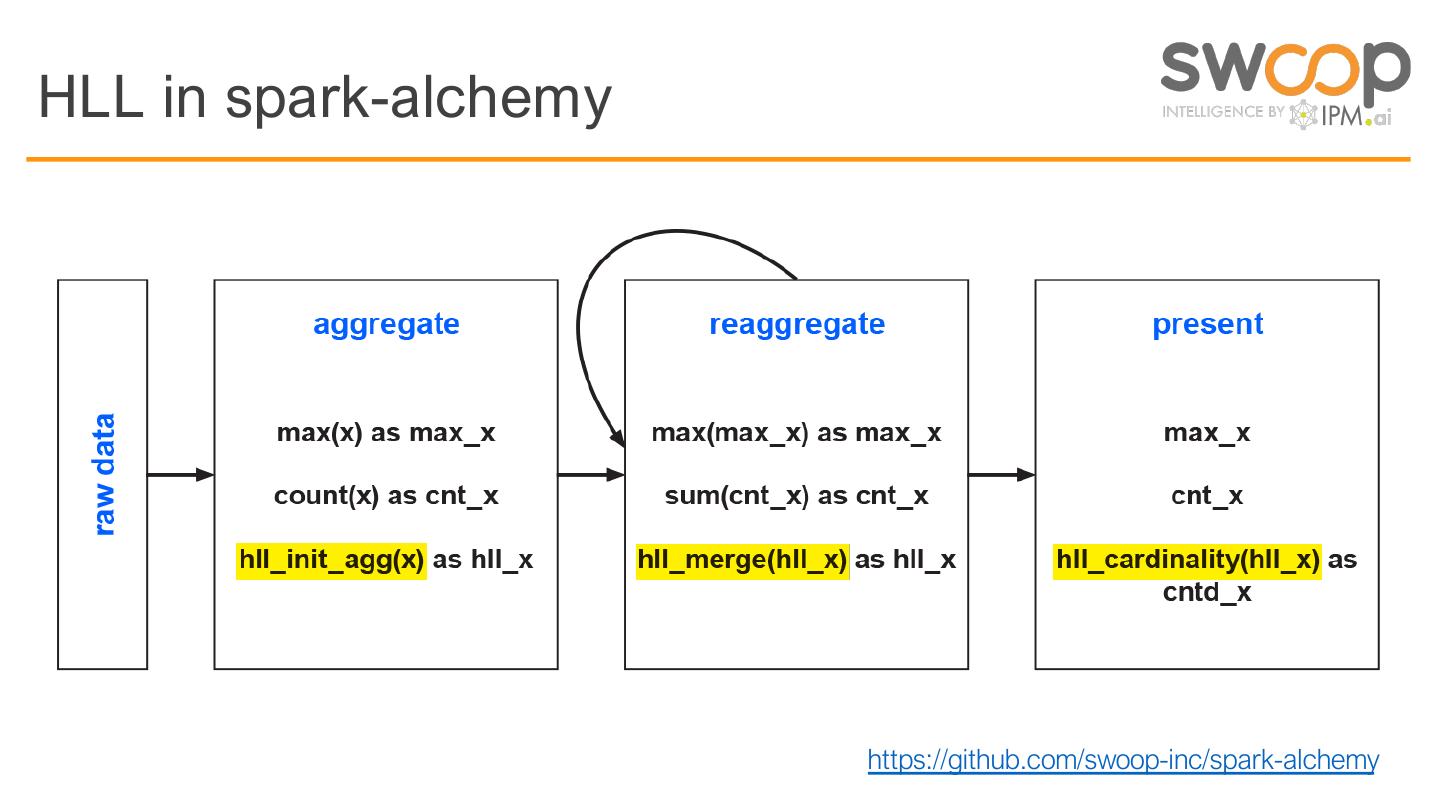
23 .Divide & conquer using HyperLogLog
1. Preaggregate
Create an HLL sketch from data for distinct counts
2. Reaggregate
Merge HLL sketches (into HLL sketches)
3. Present
Compute cardinality of HLL sketches
�
24 .HLL in spark-alchemy
https://github.com/swoop-inc/spark-alchemy
�
26 .Preaggregate with HLL sketches
create table prescription_counts_by_month_hll
select
to_date(date_trunc("month", date)) as date,
generic,
brand,
count(*) as scripts,
hll_init_agg(patient_id) as patient_ids,
from prescriptions
group by 1, 2, 3
�
27 .Reaggregate and present with HLL sketches
select
to_date(date_trunc("month", date)) as date,
count(distinct generic) as generics,
count(distinct brand) as brands,
hll_cardinality(hll_merge(patient_ids)) as patients,
count(*) as scripts
from prescription_counts_by_month_hll ter)
e: 7 secs (50x fas
Tim 0Mb
M rows / 20 b
group by 1
Inpu t: 2.6
ows / 100M
order by 1 ffle: 2.6M r
Shu
�
28 .the intuition behind HyperLogLog
�
29 .Distribute n items randomly in k buckets
* * *
E(min) ≅ +
⇒ 𝑛 ≅ /(12+) E(distance) ≅ +
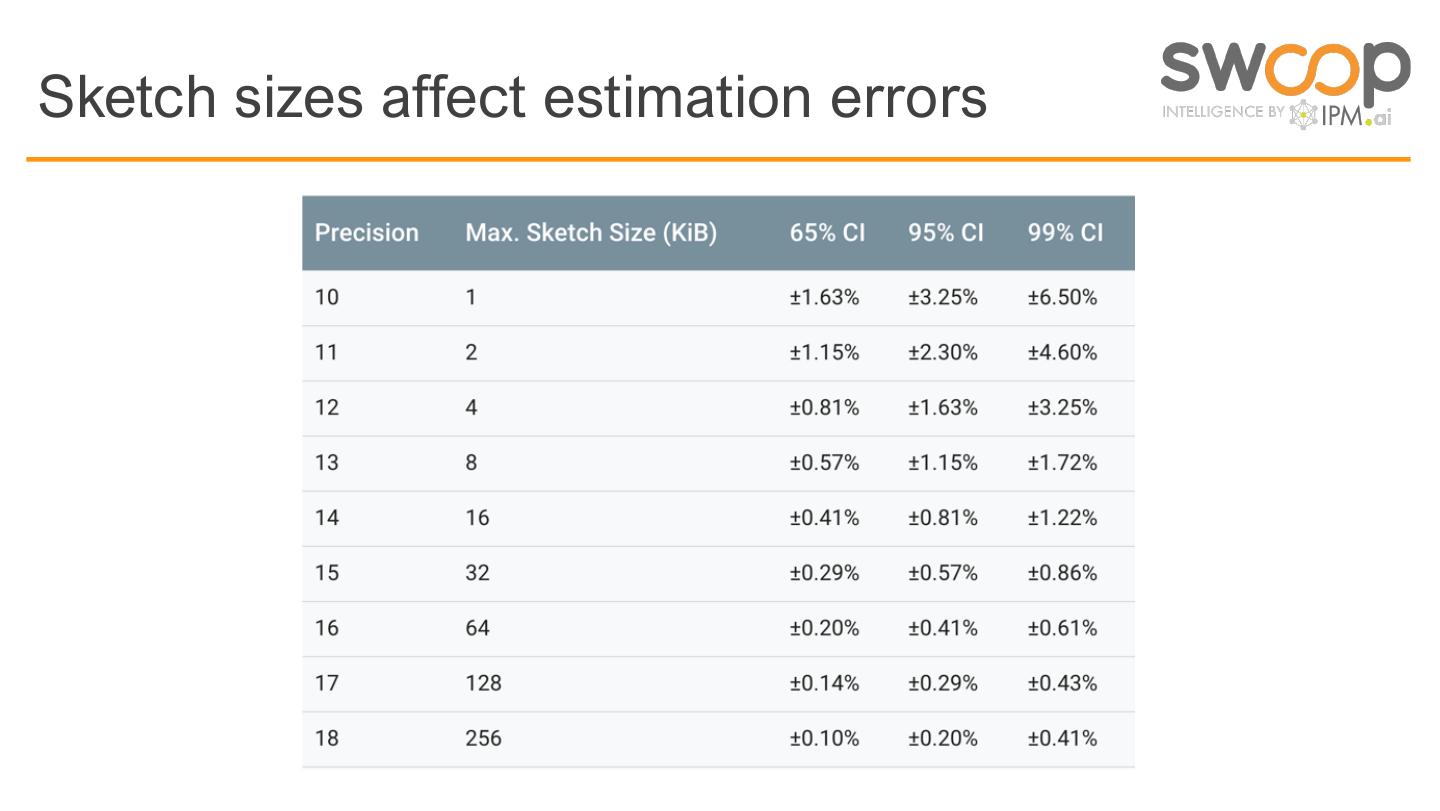
more buckets == greater precision
�