


































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Getting Started Contributing to Apache Spark – From PR, CR, JIRA and Beyond
Getting Started Contributing to Apache Spark – From PR, CR, JIRA and Beyond
Getting Started Contributing to Apache Spark – From PR, CR, JIRA and Beyond
随着社区正在努力准备Apache Spark的下一版本,您可能会问自己“我如何参与其中?”由于Spark代码已经很庞大,因此很难知道如何开始自己做出贡献。 Holden Karau提供了一个以开发人员为中心,带您逐步找到如何发现好的问题点,如何格式化代码,寻找代码评审者以及在代码评审过程中期望得到什么。 除了如何编写代码之外,我们还探讨Apache Spark做出贡献的其他方法,从帮助测试RC(Release Candidaate候选版本)到进行所有重要的代码评审,错误分类等等,也包括例如回答别人的技术问题。
展开查看详情
1 .Thanks for coming early! Want to make clothes from code? https://haute.codes Want to hear about a KF book? http://www.introtomlwithkubeflow.com Teach kids Apache Spark? http://distributedcomputing4kids.com
2 . Starting to Contribute to Apache Spark Spark Summit EU 2019 I am on the PMC but this represents my own personal views @holdenkarau
3 . Who am I? Holden ● Prefered pronouns: she/her ● Co-author of the Learning Spark & High Performance Spark books ● Spark PMC & Committer ● Twitter @holdenkarau ● Live stream code & reviews: http://bit.ly/holdenLiveOSS ● Spark Dev in the bay area (no longer @ Google) @holdenkarau
4 .@holdenkarau
5 . What we are going to explore together! Torsten Reuschling Getting a change into Apache Spark & the components involved: ● The current state of the Apache Spark dev community ● Reason to contribute to Apache Spark ● Different ways to contribute ● Places to find things to contribute ● Tooling around code & doc contributions @holdenkarau
6 . Who I think you wonderful humans are? ● Nice* people ● Don’t mind pictures of cats ● May know some Apache Spark? ● Want to contribute to Apache Spark @holdenkarau
7 . Why I’m assuming you might want to contribute: ● Fix your own bugs/problems with Apache Spark ● Learn more about distributed systems (for fun or profit) ● Improve your Scala/Python/R/Java experience ● You <3 functional programming and want to trick more people into using it ● “Credibility” of some vague type ● You just like hacking on random stuff and Spark seems shiny @holdenkarau
8 . What’s the state of the Spark dev community? gigijin ● Really large number of contributors ● Active PMC & Committer’s somewhat concentrated ○ Better than we used to be ● Also a lot of SF Bay Area - but certainly not exclusively so @holdenkarau
9 . How can we contribute to Spark? Andrey ● Direct code in the Apache Spark code base ● Code in packages built on top of Spark ● Code reviews ● Yak shaving (aka fixing things that Spark uses) ● Documentation improvements & examples ● Books, Talks, and Blogs ● Answering questions (mailing lists, stack overflow, etc.) ● Testing & Release Validation @holdenkarau
10 . Which is right for you? romana klee ● Direct code in the Apache Spark code base ○ High visibility, some things can only really be done here ○ Can take a lot longer to get changes in ● Code in packages built on top of Spark ○ Really great for things like formats or standalone features ● Yak shaving (aka fixing things that Spark uses) ○ Super important to do sometimes - can take even longer to get in @holdenkarau
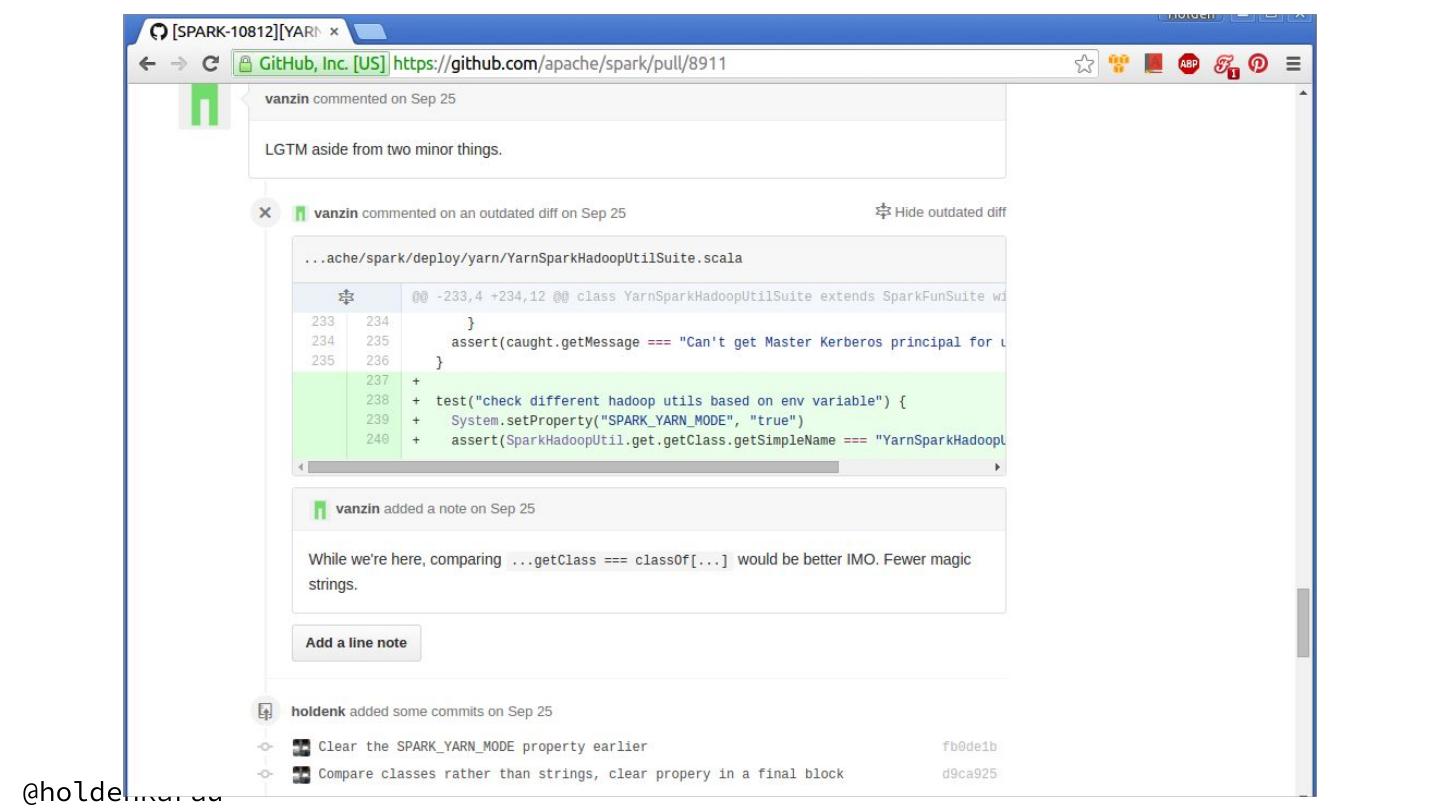
11 . Which is right for you? (continued) romana klee ● Code reviews ○ High visibility to PMC, can be faster to get started, easier to time box ○ Less tracked in metrics ● Documentation improvements & examples ○ Lots of places to contribute - mixed visibility - large impact ● Advocacy: Books, Talks, and Blogs ○ Can be high visibility @holdenkarau
12 . Testing/Release Validation ● Join the dev@ list and look for [VOTE] threads ○ Check and see if Spark deploys on your environment ○ If your application still works, or if we need to fix something ○ Great way to keep your Spark application working with less work ● Adding more automated tests is good too ○ Especially integration tests ● Check out release previews ○ Run mirrors of your production workloads if possible and compare the results ○ The earlier we know the easier it is to improve ○ Even if we can't fix it, gives you a heads up on coming changes @holdenkarau
13 . Helping users Mitchell Friedman ● Join the user@ list to answer peoples questions ○ You'll probably want to make some filter rules so you see the relevant ones ○ I tried this with ML once -- it didn't go great. Now I look for specific Python questions. ● Contribute to docs (internal and external) ● Stackoverflow questions ● Blog posts ● Tools to explain errors ● Pay it forward ● Stream your experiences -- there is value in not being alone @holdenkarau
14 . Contributing Code Directly to Spark Jon Nelson ● Maybe we encountered a bug we want to fix ● Maybe we’ve got a feature we want to add ● Either way we should see if other people are doing it ● And if what we want to do is complex, it might be better to find something simple to start with ● It’s dangerous to go alone - take this http://spark.apache.org/contributing.html @holdenkarau
15 . The different pieces of Spark: 3+? Scala, Java, Spark Structured Python, & bagel & ML Streaming R Graph X SQL & Language Graph Community Streaming MLLib DataFrames APIs Tools Packages Apache Spark “Core” Spark on Spark on Spark on Standalone Yarn @holdenkarau Mesos Kubernetes Spark
16 . Choosing a component? Rikki's Refuge ● Core ○ Conservative to external changes, but biggest impact ● ML / MLlib ○ ML is the home of the future - you can improve existing algorithms - new algorithms face uphill battle ● Structured Streaming ○ Current API is in a lot of flux so it is difficult for external participation ● SQL ○ Lots of fun stuff - very active - I have limited personal experience ● Python / R ○ Improve coverage of current APIs, improve performance @holdenkarau
17 . Choosing a component? (cont) Rikki's Refuge ● GraphX - See (external) GraphFrames instead ● Kubernetes ○ New, lots of active work and reviewers ● YARN ○ Old faithful, always needs a little work. ● Mesos ○ Needs some love, probably easy-ish-path to committer (still hard) ● Standalone ○ Not a lot going on @holdenkarau
18 . Onto JIRA - Issue tracking funtimes ● It’s like bugzilla or fog bugz ● There is an Apache JIRA for many Apache projects ● You can (and should) sign up for an account ● All changes in Spark (now) require a JIRA ● https://www.youtube.com/watch?v=ca8n9uW3afg ● Check it out at: ○ https://issues.apache.org/jira/browse/SPARK @holdenkarau
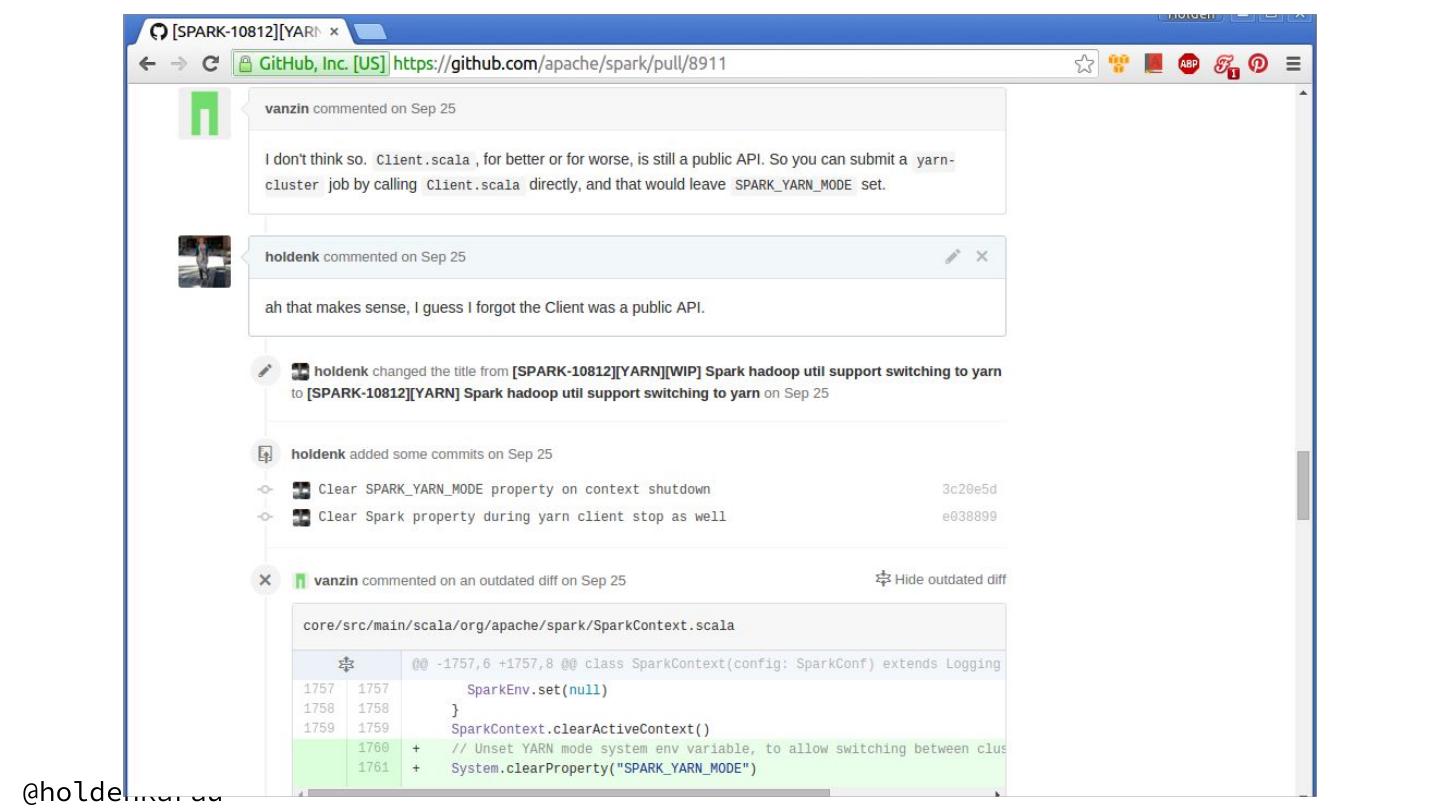
19 . What we can do with ASF JIRA? ● Search for issues (remember to filter to Spark project) ● Create new issues ○ search first to see if someone else has reported it ● Comment on issues to let people know we are working on it ● Ask people for clarification or help ○ e.g. “Reading this I think you want the null values to be replaced by a string when processing - is that correct?” ○ @mentions work here too @holdenkarau
20 . What can’t we do with ASF JIRA? ● Assign issues (to ourselves or other people) ○ In lieu of assigning we can “watch” & comment ● Post long design documents (create a Google Doc & link to it from the JIRA) ● Tag issues ○ While we can add tags, they often get removed @holdenkarau
21 .@holdenkarau
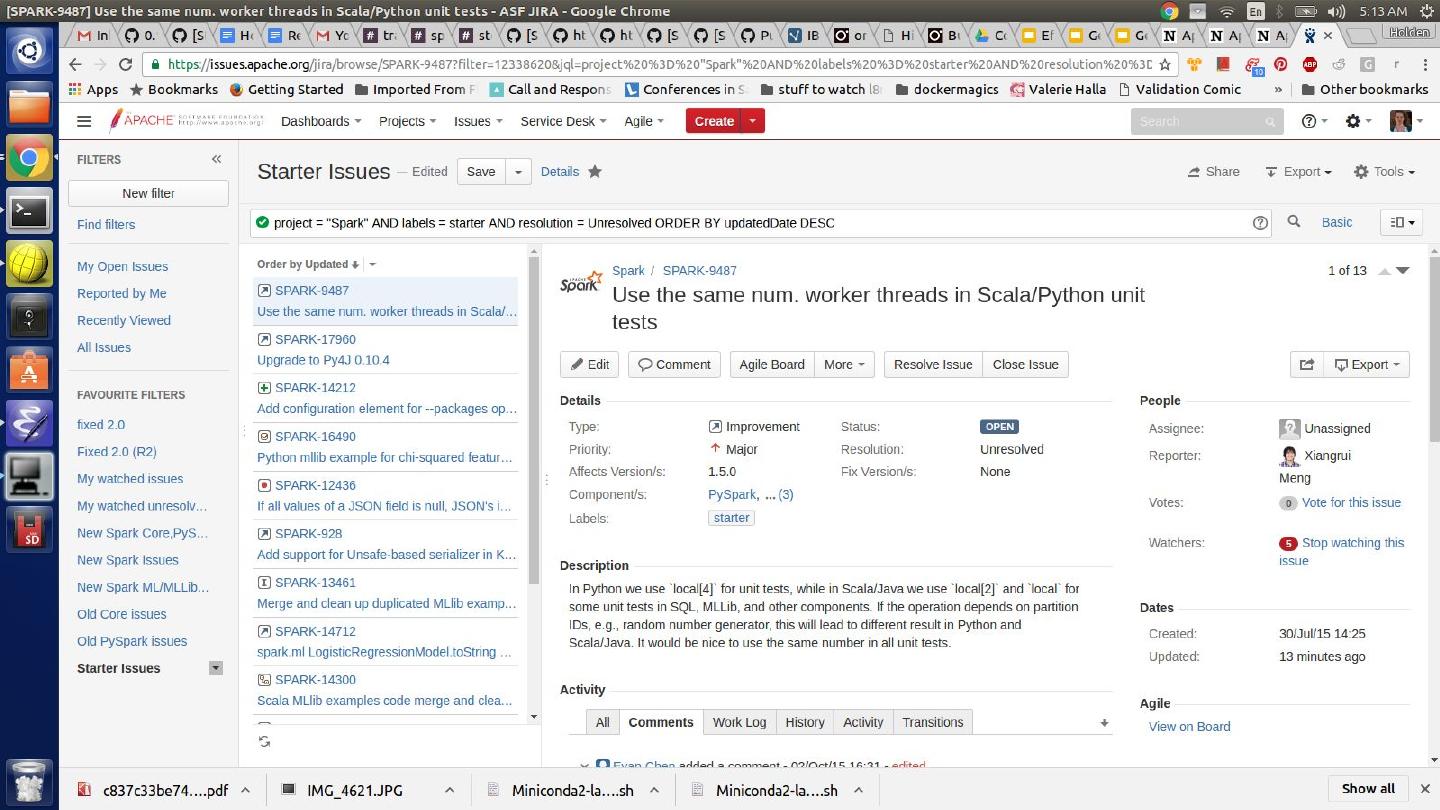
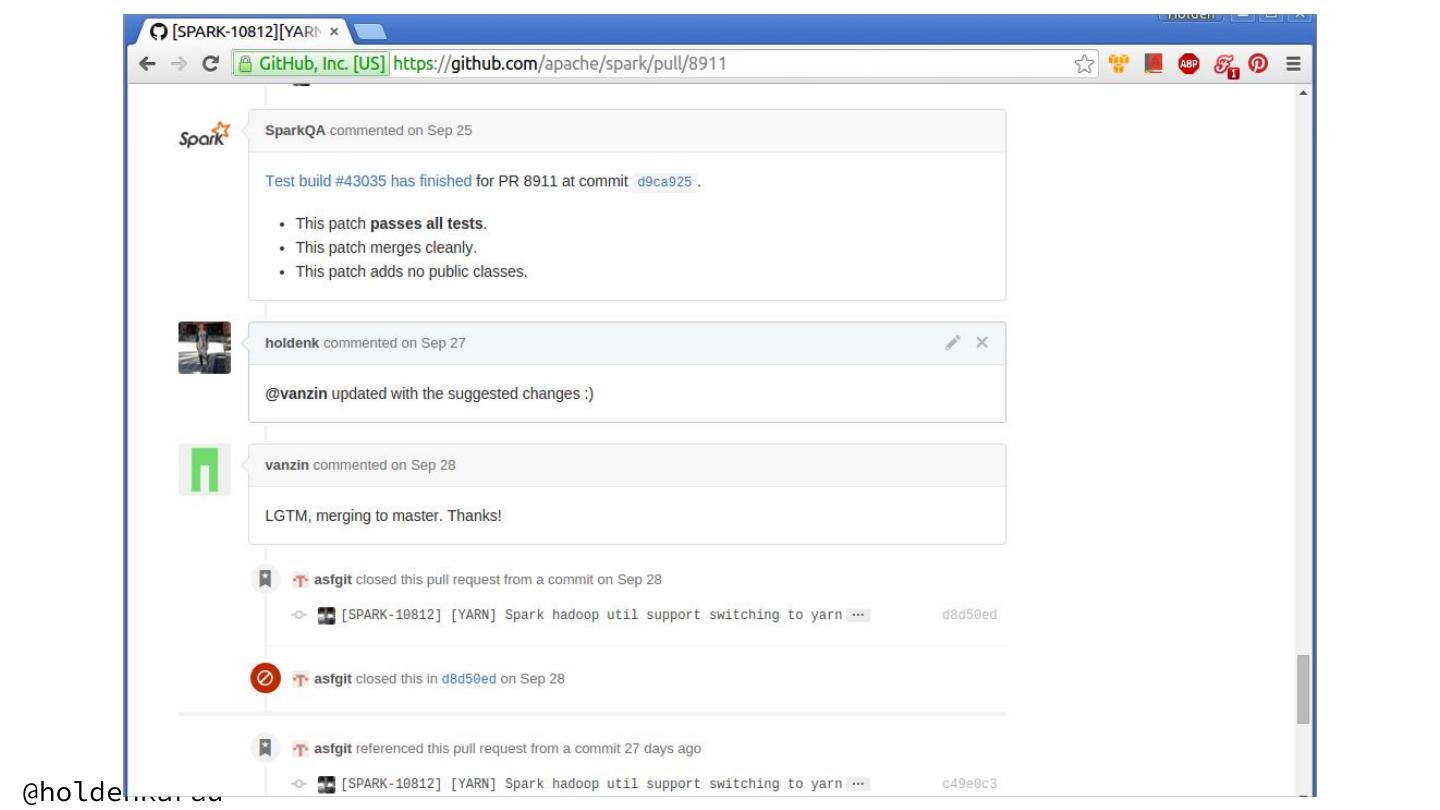
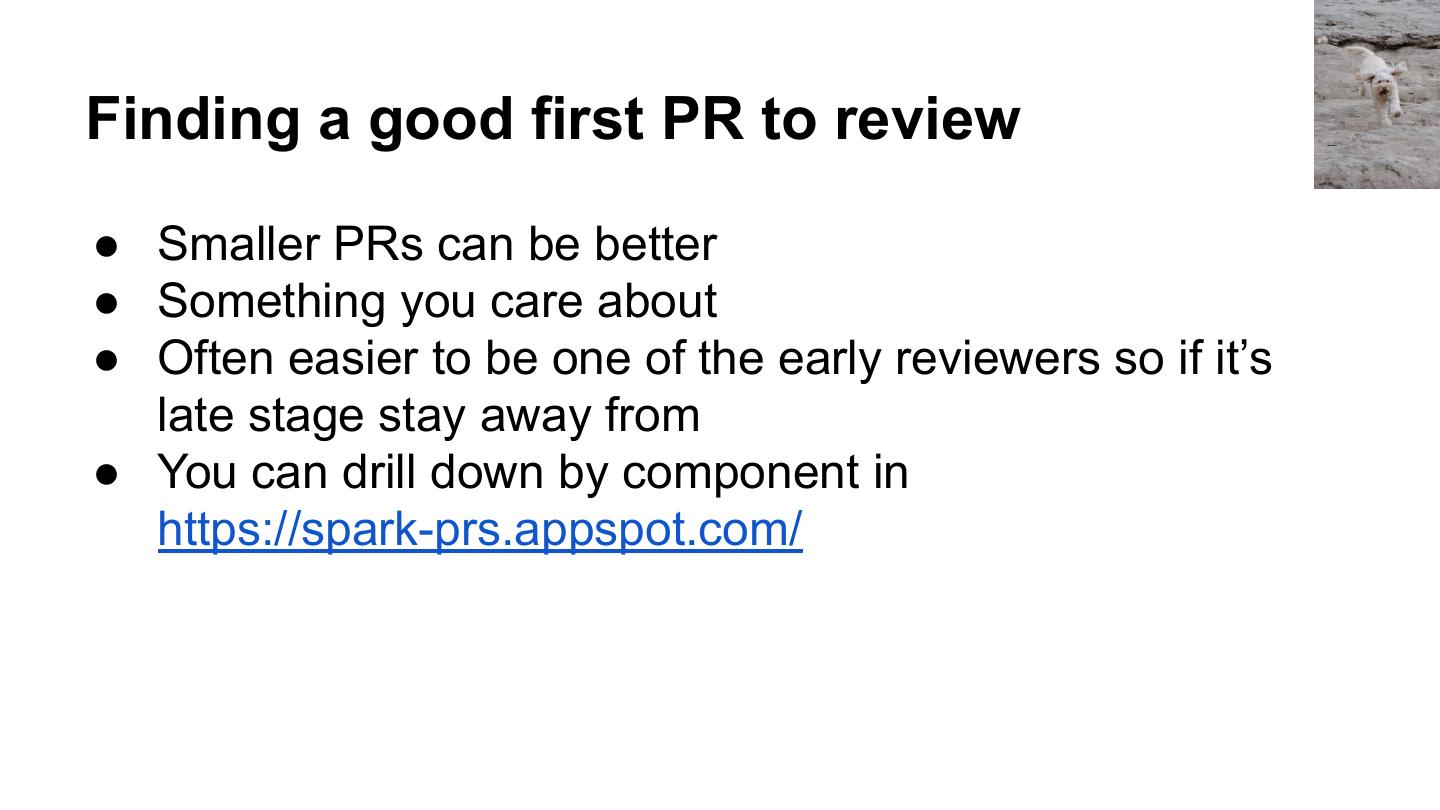
22 . Finding a good “starter” issue: ● https://issues.apache.org/jira/browse/SPARK ○ Has an starter issue tag, but inconsistently applied ● Instead read through and look for simple issues ● Pick something in the same component you eventually want to work in ● Look at the reporter and commenters - is there a committer or someone whose name you recognize? ● Leave a comment that says you are going to start working on this ● Look for old issues that we couldn't fix because of API compatibility @holdenkarau
23 . Going beyond reported issues: neko kabachi Read the user list & look for issues Grep for TODO in components you are interested in (e.g. grep -r TODO ./python/pyspark or grep -R TODO ./core/src) Look between language APIs and see if anything is missing that you think is interesting Check deprecations (internal & external) @holdenkarau
24 . While we are here: Bug Triage Carol VanHook ● Add tags as you go ○ e.g. Found a good starter issue in another area? Tag it! ● Things that are questions in the bug tracker? ○ Redirect folks to the dev/user lists gently and helpfully ● Data correctness issues tagged as "minor"? ○ Help us avoid missing important issues with "blockers" ● Additional information required to be useful? ○ Let people know what would help the bug be more actionable ● Old issue - not sure if it's fixed? ○ Try and repro. A repro from a 2nd person is so valuable ● It's ok that not to look at all of the issues @holdenkarau
25 . Finding SPIPs: Warrick Wynne https://issues.apache.org/jira/browse/SPARK-24374?jql=projec t%20%3D%20SPARK%20AND%20status%20in%20(Open%2C%20%22In%20Pro gress%22%2C%20Reopened)%20AND%20text%20~%20%22SPIP%22 Large pieces of work Not the easiest to contribute to, but can see design @holdenkarau
26 .@holdenkarau
27 . But before we get too far: Meagan Fisher ● Spark wishes to maintain compatibility between releases ● We're working on 3 though so this is the time to break things @holdenkarau
28 . Getting at the code: yay for GitHub :) dougwoods ● https://github.com/apache/spark ● Make a fork of it ● Clone it locally @holdenkarau
29 .@holdenkarau
3秒后跳转登录页面
去登陆

