
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

From HelloWorld to Configurable and Reusable Apache Spark Application in Scala
From HelloWorld to Configurable and Reusable Apache Spark Application in Scala
From HelloWorld to Configurable and Reusable Apache Spark Application in Scala
We can think of an Apache Spark application as the unit of work in complex data workflows. Building a configurable and reusable Apache Spark application comes with its own challenges, especially for developers that are just starting in the domain. Configuration, parametrization, and reusability of the application code can be challenging. Solving these will allow the developer to focus on value-adding work instead of mundane tasks such as writing a lot of configuration code, initializing the SparkSession or even kicking-off a new project.
This presentation will describe using code samples a developer’s journey from the first steps into Apache Spark all the way to a simple open-source framework that can help kick-off an Apache Spark project very easy, with a minimal amount of code. The main ideas covered in this presentation are derived from the separation of concerns principle.
The first idea is to make it even easier to code and test new Apache Spark applications by separating the application logic from the configuration logic.
The second idea is to make it easy to configure the applications, providing SparkSessions out-of-the-box, easy to set-up data readers, data writers and application parameters through configuration alone.
The third idea is that taking a new project off the ground should be very easy and straightforward. These three ideas are a good start in building reusable and production-worthy Apache Spark applications.
The resulting framework, spark-utils, is already available and ready to use as an open-source project, but even more important are the ideas and principles behind it.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .From HelloWorld to Configurable and Reusable Apache Spark Applications In Scala Oliver Țupran #UnifiedDataAnalytics #SparkAISummit
3 . whoami Oliver Țupran Software Engineer Aviation, Banking, Telecom... olivertupran Scala Enthusiast tupol Apache Spark Enthusiast @olivertupran Intro #UnifiedDataAnalytics #SparkAISummit 3
4 . Audience ● Professionals starting with Scala and Apache Spark ● Basic Scala knowledge is required ● Basic Apache Spark knowledge is required Intro #UnifiedDataAnalytics #SparkAISummit 4
5 . Agenda ● Hello, World! ● Problems ● Solutions ● Summary Intro #UnifiedDataAnalytics #SparkAISummit 5
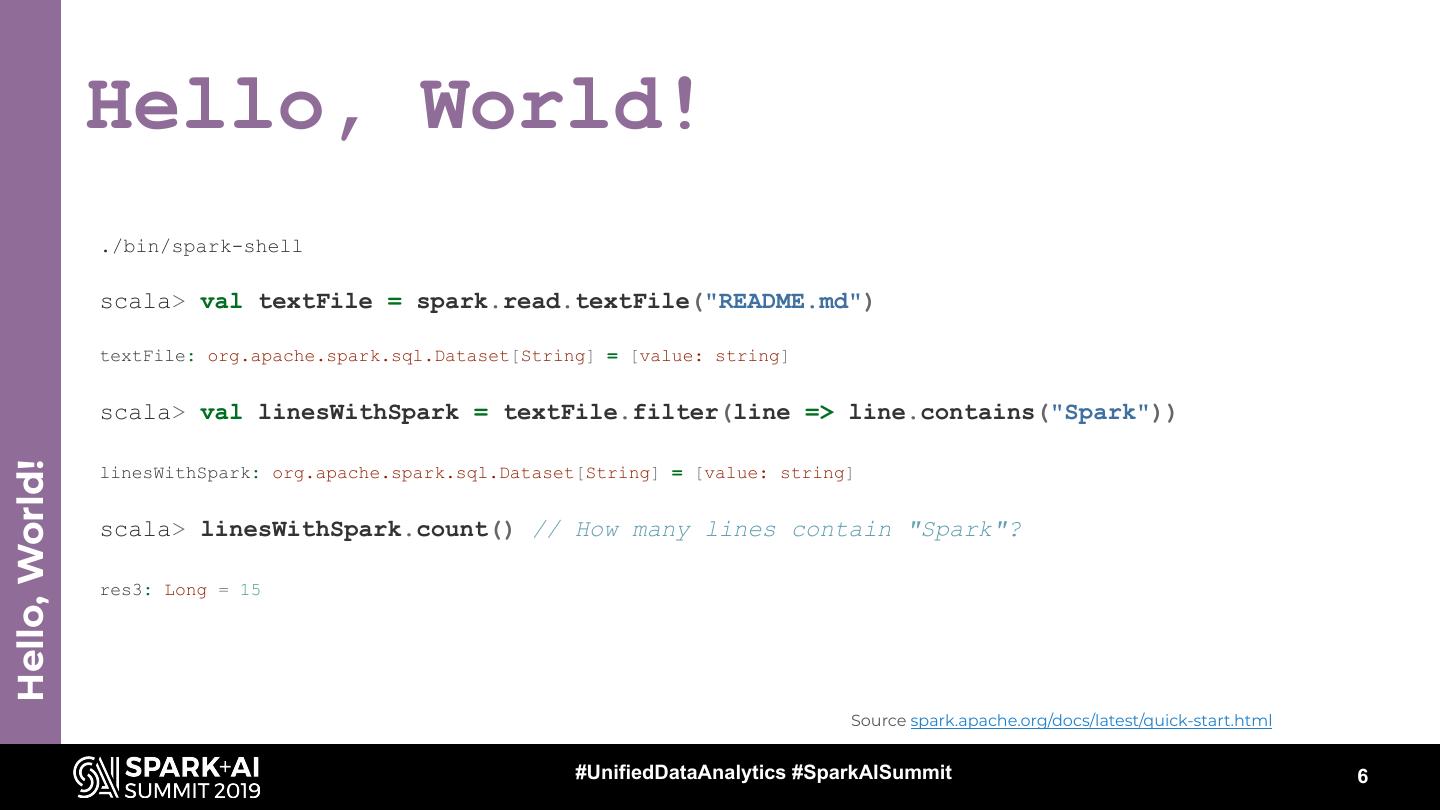
6 . Hello, World! ./bin/spark-shell scala> val textFile = spark.read.textFile("README.md") textFile: org.apache.spark.sql.Dataset[String] = [value: string] scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) Hello, World! linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string] scala> linesWithSpark.count() // How many lines contain "Spark"? res3: Long = 15 Source spark.apache.org/docs/latest/quick-start.html #UnifiedDataAnalytics #SparkAISummit 6
7 . Hello, World! object SimpleApp { def main(args: Array[String]) { val spark = SparkSession.builder.appName("Simple Application").getOrCreate() val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val logData = spark.read.textFile(logFile).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() Hello, World! println(s"Lines with a: $numAs, Lines with b: $numBs") spark.stop() } } Source spark.apache.org/docs/latest/quick-start.html #UnifiedDataAnalytics #SparkAISummit 7
8 . Problems ● Configuration mixed with the application logic ● IO can be much more complex than it looks ● Hard to test Problems #UnifiedDataAnalytics #SparkAISummit 8
9 . Solutions ● Clean separation of the business logic ● Spark session out of the box ● Configuration and validation support ● Encourage and facilitate testing Solutions tupol/spark-utils #UnifiedDataAnalytics #SparkAISummit 9
10 . Business Logic Separation /** * @tparam Context The type of the application context class. * @tparam Result The output type of the run function. */ trait SparkRunnable[Context, Result] { /** * @param context context instance containing all the application specific configuration * @param spark active spark session * @return An instance of type Result */ def run(implicit spark: SparkSession, context: Context): Result Solutions } Source github.com/tupol/spark-utils #UnifiedDataAnalytics #SparkAISummit 10
11 . Stand-Alone App Blueprint trait SparkApp[Context, Result] extends SparkRunnable[Context, Result] with Logging { def appName: String = . . . private def applicationConfiguration(implicit spark: SparkSession, args: Array[String]): com.typesafe.config.Config = . . . def createSparkSession(runnerName: String): SparkSession = . . . def createContext(config: com.typesafe.config.Config): Context def main(implicit args: Array[String]): Unit = { // Create a SparkSession, initialize a Typesafe Config instance, // validate and initialize the application context, Solutions // execute the run() function, close the SparkSession and // return the result or throw and Exception . . . } } Source github.com/tupol/spark-utils #UnifiedDataAnalytics #SparkAISummit 11
12 . Back to SimpleApp object SimpleApp { def main(args: Array[String]) { val spark = SparkSession.builder.appName("Simple Application").getOrCreate() val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val logData = spark.read.textFile(logFile).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println(s"Lines with a: $numAs, Lines with b: $numBs") Solutions spark.stop() } } Source spark.apache.org/docs/latest/quick-start.html #UnifiedDataAnalytics #SparkAISummit 12
13 . SimpleApp as SparkApp 1 object SimpleApp extends SparkApp[Unit, Unit]{ override def createContext(config: Config): Unit = Unit override def run(implicit spark: SparkSession, context: Unit): Unit { val logFile = "YOUR_SPARK_HOME/README.md" val logData = spark.read.textFile(logFile).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() Solutions println(s"Lines with a: $numAs, Lines with b: $numBs") } } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 13
14 . SimpleApp as SparkApp 2 object SimpleApp extends SparkApp [Unit, Unit]{ override def createContext (config: Config): Unit = Unit override def run(implicit spark: SparkSession , context: Unit): Unit = { val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system val logData = spark.read.textFile (logFile).cache() val (numAs, numBs) = appLogic(logData ) println (s"Lines with a: $numAs, Lines with b: $numBs") } def appLogic(data: Dataset[String]): (Long, Long) = { Solutions val numAs = data.filter(line => line.contains ("a")).count() val numBs = data.filter(line => line.contains ("b")).count() (numAs, numBs) } Source github.com/tupol/spark-utils-demos/ } #UnifiedDataAnalytics #SparkAISummit 14
15 . SimpleApp as SparkApp 3 case class SimpleAppContext(input: FileSourceConfiguration , filterA: String, filterB: String) object SimpleApp extends SparkApp [SimpleAppContext, Unit]{ override def createContext(config: Config): SimpleAppContext = ??? override def run(implicit spark: SparkSession , context: SimpleAppContext ): Unit = { val logData = spark.source(context.input).read.as[ String].cache val (numAs, numBs) = appLogic(logData ) println (s"Lines with a: $numAs, Lines with b: $numBs") } Solutions def appLogic (data: Dataset[String] , context: SimpleAppContext): (Long, Long) = { val numAs = data.filter(line => line.contains (context.filterA )).count() val numBs = data.filter(line => line.contains (context.filterB )).count() (numAs, numBs) } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 15
16 . Why Typesafe Config? ● supports files in three formats: Java properties, JSON, and a human-friendly JSON superset ● merges multiple files across all formats ● can load from files, URLs or classpath ● users can override the config with Java system properties, java -Dmyapp.foo.bar=10 ● supports configuring an app, with its framework and libraries, all from a single file such as application.conf ● extracts typed properties ● JSON superset features: ○ comments ○ includes ○ substitutions ("foo" : ${bar}, "foo" : Hello ${who}) Solutions ○ properties-like notation (a.b=c) ○ less noisy, more lenient syntax ○ substitute environment variables (logdir=${HOME}/logs) ○ lists Source github.com/lightbend/config #UnifiedDataAnalytics #SparkAISummit 16
17 . Application Configuration File Hocon Java Properties SimpleApp { input { format: text SimpleApp.input.format=text path: SPARK_HOME/README.md SimpleApp.input.path=SPARK_HOME/README.md } SimpleApp.filterA=A filterA: A SimpleApp.filterB=B Solutions filterB: B } #UnifiedDataAnalytics #SparkAISummit 17
18 . Configuration and Validation case class SimpleAppContext(input: FileSourceConfiguration , filterA: String, filterB: String) object SimpleAppContext extends Configurator[SimpleAppContext] { import org.tupol.utils.config._ override def validationNel(config: com.typesafe.config.Config): scalaz .ValidationNel [Throwable , SimpleAppContext ] = { config.extract[FileSourceConfiguration]("input") .ensure(new IllegalArgumentException ( "Only 'text' format files are supported" ).toNel)(_.format == FormatType .Text) |@| Solutions config.extract[ String]("filterA" ) |@| config.extract[ String]("filterB" ) apply SimpleAppContext .apply } } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 18
19 . Configurator Framework? ● DSL for easy definition of the context ○ config.extract[Double](“parameter.path”) ○ |@| operator to compose the extracted parameters ○ apply to build the configuration case class ● Type based configuration parameters extraction ○ extract[Double](“parameter.path”) ○ extract[Option[Seq[Double]]](“parameter.path”) ○ extract[Map[Int, String]](“parameter.path”) Solutions ○ extract[Either[Int, String]](“parameter.path”) ● Implicit Configurators can be used as extractors in the DSL ○ config.extract[SimpleAppContext](“configuration.path”) ● The ValidationNel contains either a list of exceptions or the application context #UnifiedDataAnalytics #SparkAISummit 19
20 . SimpleApp as SparkApp 4 case class SimpleAppContext (input: FileSourceConfiguration , filterA: String, filterB: String) object SimpleApp extends SparkApp [SimpleAppContext , (Long, Long)]{ override def createContext (config: Config): SimpleAppContext = SimpleAppContext(config).get override def run(implicit spark: SparkSession , context: SimpleAppContext ): (Long, Long) = { val logData = spark.source(context.input).read.as[ String].cache val (numAs, numBs) = appLogic(logData ) println (s"Lines with a: $numAs, Lines with b: $numBs") (numAs, numBs) Solutions } def appLogic (data: Dataset[String] , context: SimpleAppContext ): (Long, Long) = { . . . } } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 20
21 . Data Sources and Data Sinks CSV JSON XML JDBC ... format URI (connection URL, file path…) schema sep primitivesAsString rowTag table encoding prefersDecimal samplingRatio columnName quote allowComments excludeAttribute lowerBound escape allowUnquotedFieldNames treatEmptyValuesAsNulls upperBound comment allowSingleQuotes mode numPartitions header allowNumericLeadingZeros columnNameOfCorruptRecord connectionProperties inferSchema allowBackslashEscapingAnyCharacter attributePrefix ignoreLeadingWhiteSpace mode valueTag ignoreTrailingWhiteSpace columnNameOfCorruptRecord charset nullValue dateFormat ignoreSurroundingSpaces nanValue timestampFormat Solutions positiveInf negativeInf dateFormat timestampFormat maxColumns maxCharsPerColumn maxMalformedLogPerPartition mode Source spark.apache.org/docs/latest/ #UnifiedDataAnalytics #SparkAISummit 21
22 . Data Sources and Data Sinks import org.tupol.spark.implicits._ import org.tupol.spark.io._ import spark.implicits._ . . . val input = config.extract[FileSourceConfiguration]("input").get val lines = spark.source(input).read.as[String] // org.tupol.spark.io.FileDataSource(input).read // spark.read.format(...).option(...).option(...).schema(...).load() Solutions val output = config.extract[FileSinkConfiguration]("output").get lines.sink(output).write // org.tupol.spark.io.FileDataSink(output).write(lines) // lines.write.format(...).option(...).option(...).partitionBy(...).mode(...) #UnifiedDataAnalytics #SparkAISummit 22
23 . Data Sources and Data Sinks ● Very concise and intuitive DSL ● Support for multiple formats: text, csv, json, xml, avro, parquet, orc, jdbc, ... ● Specify a schema on read ● Schema is passed as a full json structure, as serialised by the StructType ● Specify the partitioning and bucketing for writing the data Structured streaming support Solutions ● ● Delta Lake support ● ... #UnifiedDataAnalytics #SparkAISummit 23
24 . Test! Test! Test! class SimpleAppSpec extends FunSuite with Matchers with SharedSparkSession { A World of Opportunities . . . val DummyInput = FileSourceConfiguration("no path", TextSourceConfiguration()) val DummyContext = SimpleAppContext(input = DummyInput, filterA = "", filterB = "") test("appLogic should return 0 counts of a and b for an empty DataFrame") { val testData = spark.emptyDataset[String] val result = SimpleApp.appLogic(testData, DummyContext) result shouldBe (0, 0) } . . . } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 24
25 . Test! Test! Test! class SimpleAppSpec extends FunSuite with Matchers with SharedSparkSession { . . . test("run should return (1, 2) as count of a and b for the given data") { val inputSource = FileSourceConfiguration("src/test/resources/input-test-01", TextSourceConfiguration()) val context = SimpleAppContext(input = inputSource, filterA = "a", filterB = "b") val result = SimpleApp.run(spark, context) result shouldBe (1, 2) Solutions } . . . } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 25
26 . Format Converter case class MyAppContext(input : FormatAwareDataSourceConfiguration, output: FormatAwareDataSinkConfiguration) object MyAppContext extends Configurator[MyAppContext] { import scalaz.ValidationNel import scalaz.syntax.applicative._ def validationNel(config: Config): ValidationNel[Throwable, MyAppContext] = { config.extract[FormatAwareDataSourceConfiguration]("input") |@| config.extract[FormatAwareDataSinkConfiguration]("output") apply Solutions MyAppContext.apply } } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 26
27 . Format Converter object MyApp extends SparkApp[MyAppContext, DataFrame] { override def createContext(config: Config): MyAppContext = MyAppContext(config).get override def run(implicit spark: SparkSession, context: MyAppContext): DataFrame = { val data = spark.source(context.input).read data.sink(context.output).write } } Solutions Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 27
28 . Beyond Format Converter object MyApp extends SparkApp[MyAppContext, DataFrame] { override def createContext(config: Config): MyAppContext = MyAppContext(config).get override def run(implicit spark: SparkSession, context: MyAppContext): DataFrame = { val inputData = spark.source(context.input).read val outputData = transform(inputData) outputData.sink(context.output).write } Solutions def transform(data: DataFrame)(implicit spark: SparkSession, context: MyAppContext) = { data // Transformation logic here } } Source github.com/tupol/spark-utils-demos/ #UnifiedDataAnalytics #SparkAISummit 28
29 . Summary ● Write Apache Spark applications with minimal ceremony ○ batch ○ structured streaming ● IO and general application configuration support ● Facilitates testing ● Increase productivity Summary tupol/spark-utils spark-tools spark-utils-demos spark-apps.seed.g8 #UnifiedDataAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

