





































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Fast and Reliable Apache Spark SQL Engine
Building the next generation Spark SQL engine at speed poses new challenges to both automation and testing. At Databricks, we are implementing a new testing framework for assessing the quality and performance of new developments as they produced. Having more than 1,200 worldwide contributors, Apache Spark follows a rapid pace of development. At this scale, new testing tooling such as random query and data generation, fault injection, longevity stress, and scalability tests are essential to guarantee a reliable and performance Spark later in production. By applying such techniques, we will demonstrate the effectiveness of our testing infrastructure by drilling-down into cases where correctness and performance regressions have been found early. In addition, showing how they have been root-caused and fixed to prevent regressions in production and boosting the continuous delivery of new features.
展开查看详情
1 . Fast and Reliable Apache Spark SQL Engine Cheng Lian @liancheng Spark + AI Summit @ SF | April, 2019 1
2 .About me CHENG LIAN • Software Engineer at Databricks • PMC member and committer of Apache Spark • Committer of Apache Parquet 2
3 .Databricks Unified Analytics Platform DATABRICKS WORKSPACE Notebooks Jobs Models APIs Dashboards End to end ML lifecycle DATABRICKS RUNTIME Databricks Delta ML Frameworks Reliable & Scalable Simple & Integrated DATABRICKS CLOUD SERVICE
4 .Databricks Customers Across Industries
5 .Databricks ecosystem DBR Cluster Manager Developers Tools Infrastructure Customers 5
6 .Databricks runtime (DBR) releases DBR 6.0* Spark 3.0 DBR 5.x (LTS)* Spark 2.4 DBR 5.0 Spark 2.4 DBR 4.3 Spark 2.3 Feb’18 Aug’18 Nov’18 Apr’19 Jul’19 Oct’19 Feb’20 Beta Full Support Marked for deprecation Deprecated Goal: making high quality releases automatic and frequent * dates and LTS-tag new releases are subject to change
7 .Apache Spark contributions Number of commits Hundreds of commits monthly to the Apache Spark project At this pace of development, mistakes are bound to happen 7
8 .Where do these contributions go? Over 200 built-in functions Query Scope of the testing Input data n tio u ra fig Developers put a significant engineering effort in testing Con 8
9 .Yet another brick in the wall Stress Customer testing workloads Fuzz Macro Failure testing E2E benchmarks testing Plan Micro stability Integration Benchmarks Unit testing Unit testing is not enough to guarantee correctness and performance
10 .Continuous integration pipeline New artifacts Metrics Alerts Dev Test Analyze - Merge - Correctness - Rules - Build - Performance - Policies 10
11 .Classification and alerting Correctness Classify Root-cause e il ur Fa Events Re-test Alert Reg re ssio - Minimize - Impact n Performance - Drill-down - Scope - Profile - Correlation - Compare - Confirm? - Validate 11
12 . Correctness Correctness Classify il ur e Re- Root-cause Fa tes t Events Alert Reg re ssio n Performance 12
13 .Random query generation Postgres Query vs Model Query profile translator 2.3 Spark Query vs 2.4 13
14 .DDL and datagen Random number of columns Random partition columns Choose a data type String ... ... Boolean BigInt ... Decimal SmallInt Integer Float ... Timestamp Random number of rows Random number of tables 14
15 .Recursive query model Query SQL Query Clause GROUP BY WITH SELECT JOIN ORDER BY UNION WHERE FROM Functions Expression Table Constant Alias Column 15
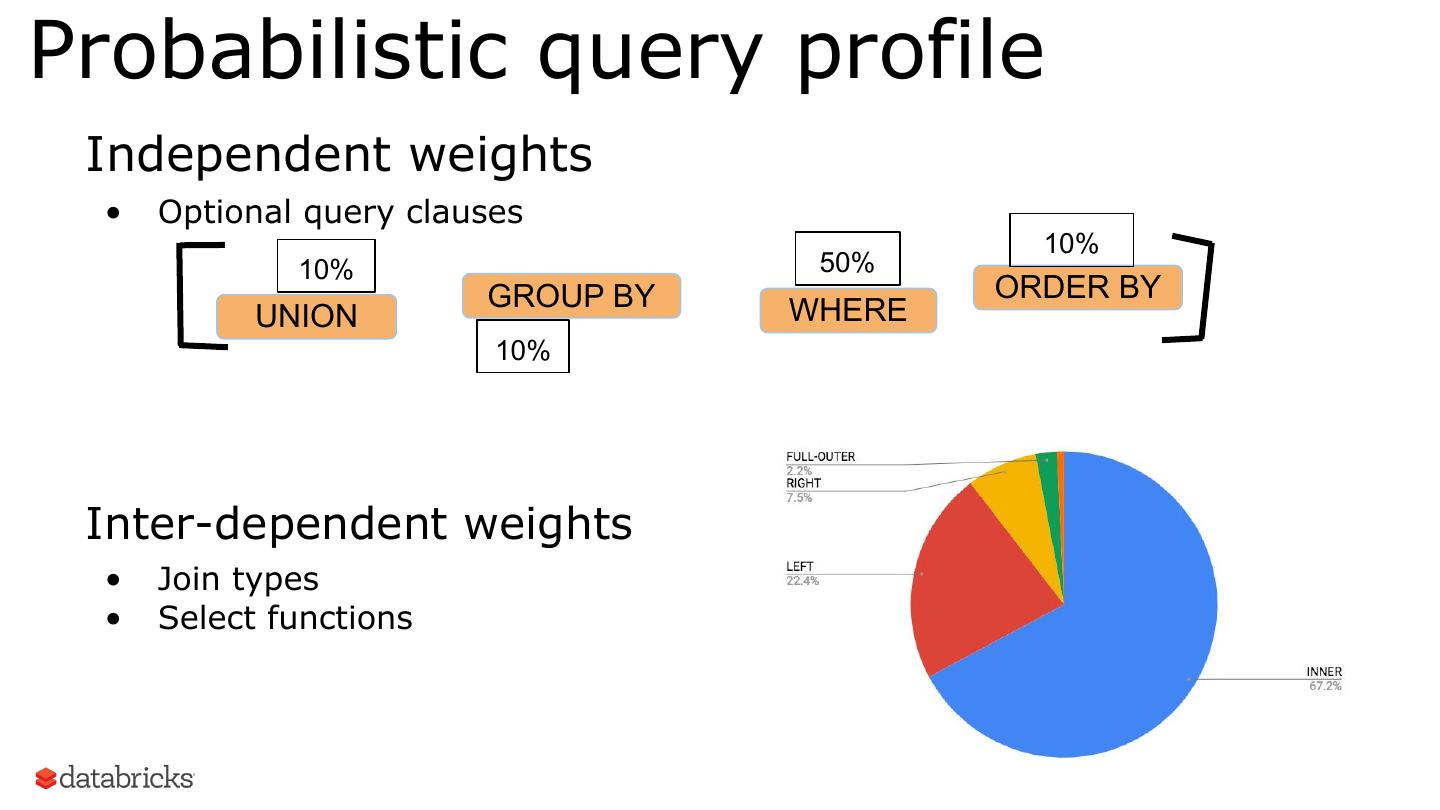
16 .Probabilistic query profile Independent weights • Optional query clauses 10% 10% 50% GROUP BY ORDER BY UNION WHERE 10% Inter-dependent weights • Join types • Select functions
17 .Coalesce flattening (1/5) SELECT COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3) AS int_col, IF(NULL, VARIANCE(COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3)), COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3)) AS int_col_1, STDDEV(t2.double_col_2) AS float_col, COALESCE(MIN((t1.smallint_col_3) - (COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3))), COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3), COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3)) AS int_col_2 FROM table_4 t1 INNER JOIN table_4 t2 ON (t2.timestamp_col_7) = (t1.timestamp_col_7) WHERE (t1.smallint_col_3) IN (CAST('0.04' AS DECIMAL(10,10)), t1.smallint_col_3) GROUP BY COALESCE(t2.smallint_col_3, t1.smallint_col_3, t2.smallint_col_3) Small dataset with 2 tables of 5x5 size Within 10 randomly generated queries Error: Operation is in ERROR_STATE
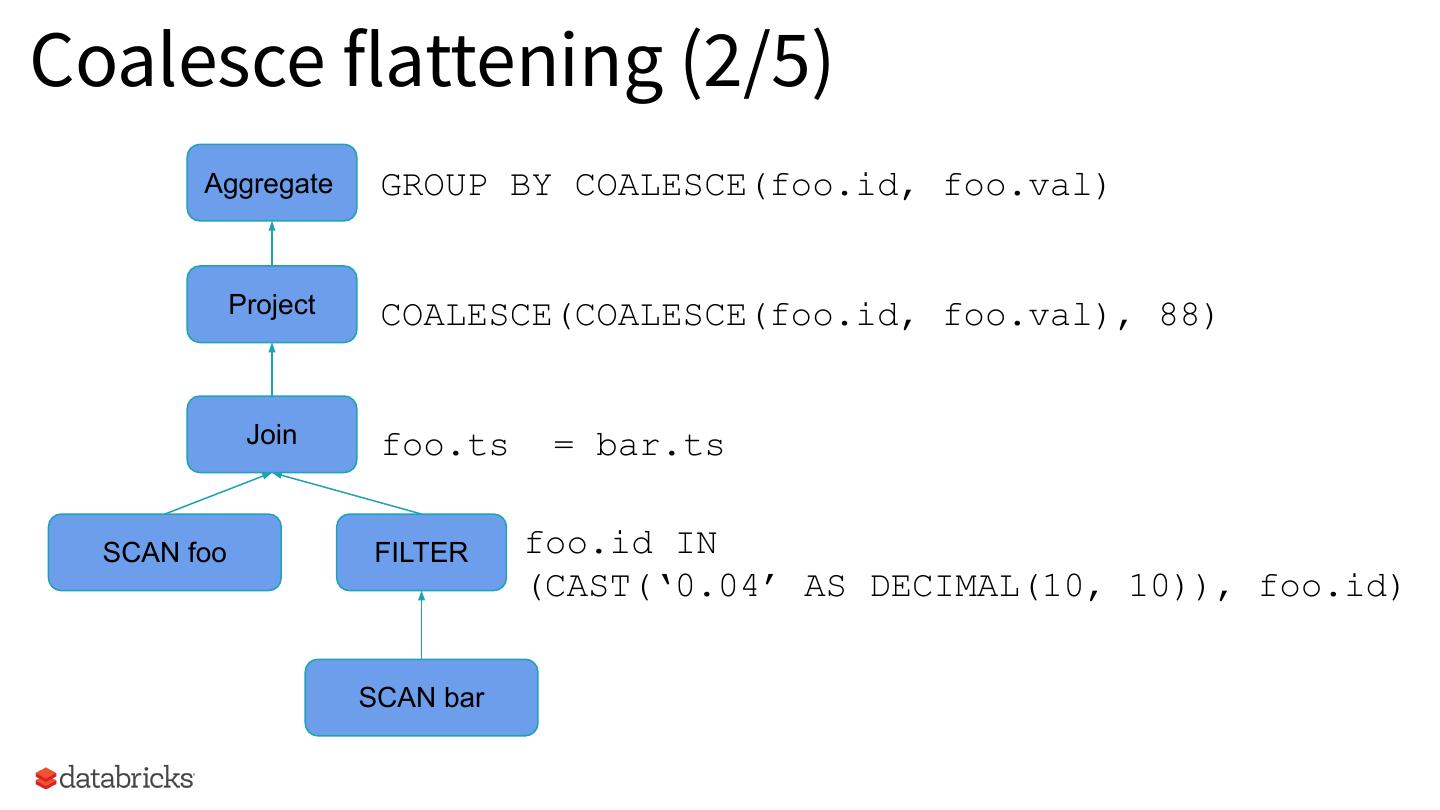
18 .Coalesce flattening (2/5) Aggregate GROUP BY COALESCE(foo.id, foo.val) Project COALESCE(COALESCE(foo.id, foo.val), 88) Join foo.ts = bar.ts SCAN foo FILTER foo.id IN (CAST(‘0.04’ AS DECIMAL(10, 10)), foo.id) SCAN bar
19 .Coalesce flattening (3/5) Aggregate COALESCE(foo.id, foo.val) Project COALESCE(COALESCE(foo.id, foo.val), 88) Join foo.ts = bar.ts SCAN t1 FILTER foo.id IN (CAST(‘0.04’ AS DECIMAL(10, 10)), foo.id) SCAN t2
20 .Coalesce flattening (4/5) Aggregate Minimized query: SELECT COALESCE(COALESCE(foo.id, foo.val), 88) Project FROM foo GROUP BY COALESCE(foo.id, foo.val) SCAN foo
21 .Coalesce flattening (5/5) Aggregate Minimized query: SELECT COALESCE(foo.id, foo.val, 88) Project FROM foo GROUP BY COALESCE(foo.id, foo.val) SCAN foo Analyzing the error ● The optimizer flattens the nested coalesce calls ● The SELECT clause doesn’t contain the GROUP BY expression ● Possibly a problem with any GROUP BY expression that can be optimized
22 .Lead function (1/3) SELECT (t1.decimal0803_col_3) / (t1.decimal0803_col_3) AS decimal_col, CAST(696 AS STRING) AS char_col, t1.decimal0803_col_3, (COALESCE(CAST('0.02' AS DECIMAL(10,10)), CAST('0.47' AS DECIMAL(10,10)), CAST('-0.53' AS DECIMAL(10,10)))) + (LEAD(-65, 4) OVER (ORDER BY (t1.decimal0803_col_3) / (t1.decimal0803_col_3), CAST(696 AS STRING))) AS decimal_col_1, CAST(-349 AS STRING) AS char_col_1 FROM table_16 t1 WHERE (943) > (889) Error: Column 4 in row 10 does not match: [1.0, 696, -871.81, <<-64.98>>, -349] SPARK row [1.0, 696, -871.81, <<None>>, -349] POSTGRESQL row
23 .Lead function (2/3) Project COALESCE(expr) + LEAD(-65, 4) OVER ORDER BY expr FILTER WHERE expr SCAN foo
24 .Lead function (3/3) Project COALESCE(expr) + LEAD(-65, 4) OVER ORDER BY expr FILTER WHERE expr SCAN foo Analyzing the error ● Using constant input values breaks the behaviour of the LEAD function ● SPARK-16633: https://github.com/apache/spark/pull/14284
25 .Query operator coverage analysis In 15m (500 queries), we reach the max coverage of the framework
26 . Performance Correctness Classify il ur e Root-cause Fa Events Alert st Reg -te re Performance Re ssio n 26 26
27 .Benchmarking tools • We use spark-sql-perf public library for TPC workloads • Provides datagen and import scripts https://github.com/databricks/spark-sql-perf – local, cluster, S3 – Dashboards for analyzing results CPU Flame Graph • The Spark micro benchmarks • And the async-profiler • to produce flamegraphs Source: http://www.brendangregg.com/flamegraphs.html 27
28 . ----------- journey TPC-DS runtime (sec) 15% Date
29 .Per query drill-down: q67 First, scope and validate Query 67: 18% regression From 320s to 390s • in 2.4-master (dev) compared • to 2.3 in DBR 4.3 (prod)
3秒后跳转登录页面
去登陆

