展开查看详情
1 .Extending Spark SQL 2.4
with New Data Sources
Live Coding Session
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl / Spark+AI Summit 2019
�
2 .Jacek Laskowski
● Freelance IT consultant
● Specializing in Spark, Kafka, Kafka Streams, Scala
● Development | Consulting | Training | Speaking
● "The Internals Of" online books
● Among contributors to Apache Spark
● Among Confluent Community Catalyst (Class of 2019 - 2020)
● Contact me at jacek@japila.pl
● Follow @JacekLaskowski on twitter for more #ApacheSpark
#ApacheKafka #KafkaStreams
�
3 .Friendly reminder
Pictures...take a lot of pictures! 📷
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
4 .Why Should You Care?
1. Why would you ever consider developing a new data
source for Spark SQL?
2. Let structured queries access data in external systems
(e.g. Splice Machine, Google Cloud Spanner)
3. Make loading or writing process self-contained
a. Hidden from developers who'd focus on what to do with the data
not how to make the data available in a proper format
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
5 .Data Source / Data Provider
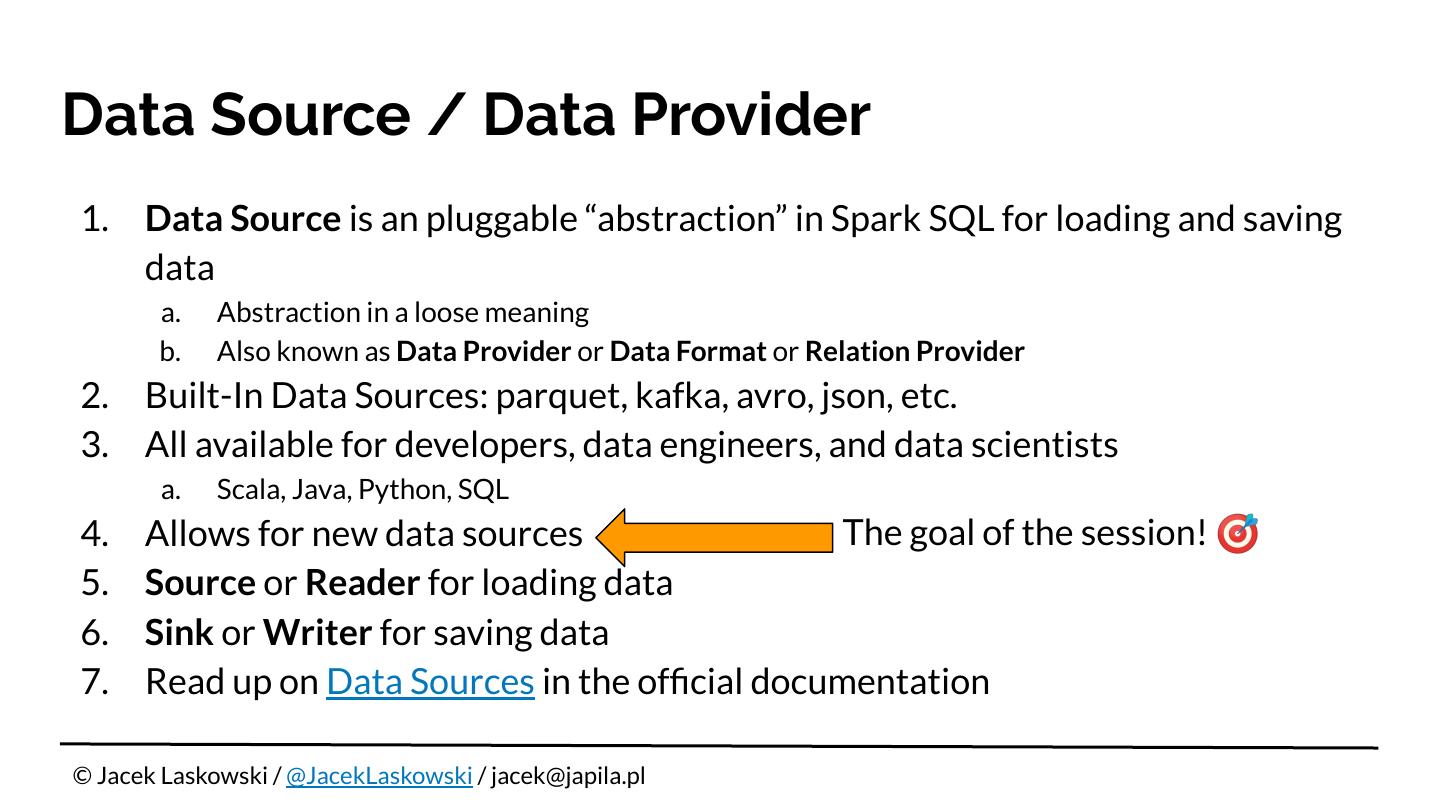
1. Data Source is an pluggable “abstraction” in Spark SQL for loading and saving
data
a. Abstraction in a loose meaning
b. Also known as Data Provider or Data Format or Relation Provider
2. Built-In Data Sources: parquet, kafka, avro, json, etc.
3. All available for developers, data engineers, and data scientists
a. Scala, Java, Python, SQL
4. Allows for new data sources The goal of the session! 🎯
5. Source or Reader for loading data
6. Sink or Writer for saving data
7. Read up on Data Sources in the official documentation
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
6 .Before Developing New Data Source
1. What Apache Spark version?
2. Data Source API V1 vs Data Source API V2?
3. Loading and/or Saving Data?
4. Spark SQL only?
5. Spark Structured Streaming?
a. Micro-Batch Stream Processing?
b. Continuous Stream Processing?
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
7 .DataFrameReader (1 of 2)
1. SparkSession.read to start describing a data flow
a. Creates a DataFrameReader
2. DataFrameReader is a fluent interface to describe the
input data source
3. Used to “load” data from external storage systems (e.g.
file systems, key-value stores, etc.)
a. No physical data movement yet
b. Metadata of an input node in a data flow (graph)
4. DataFrameReader.load to finish describing the input
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
8 .DataFrameReader (2 of 2)
Worth noticing:
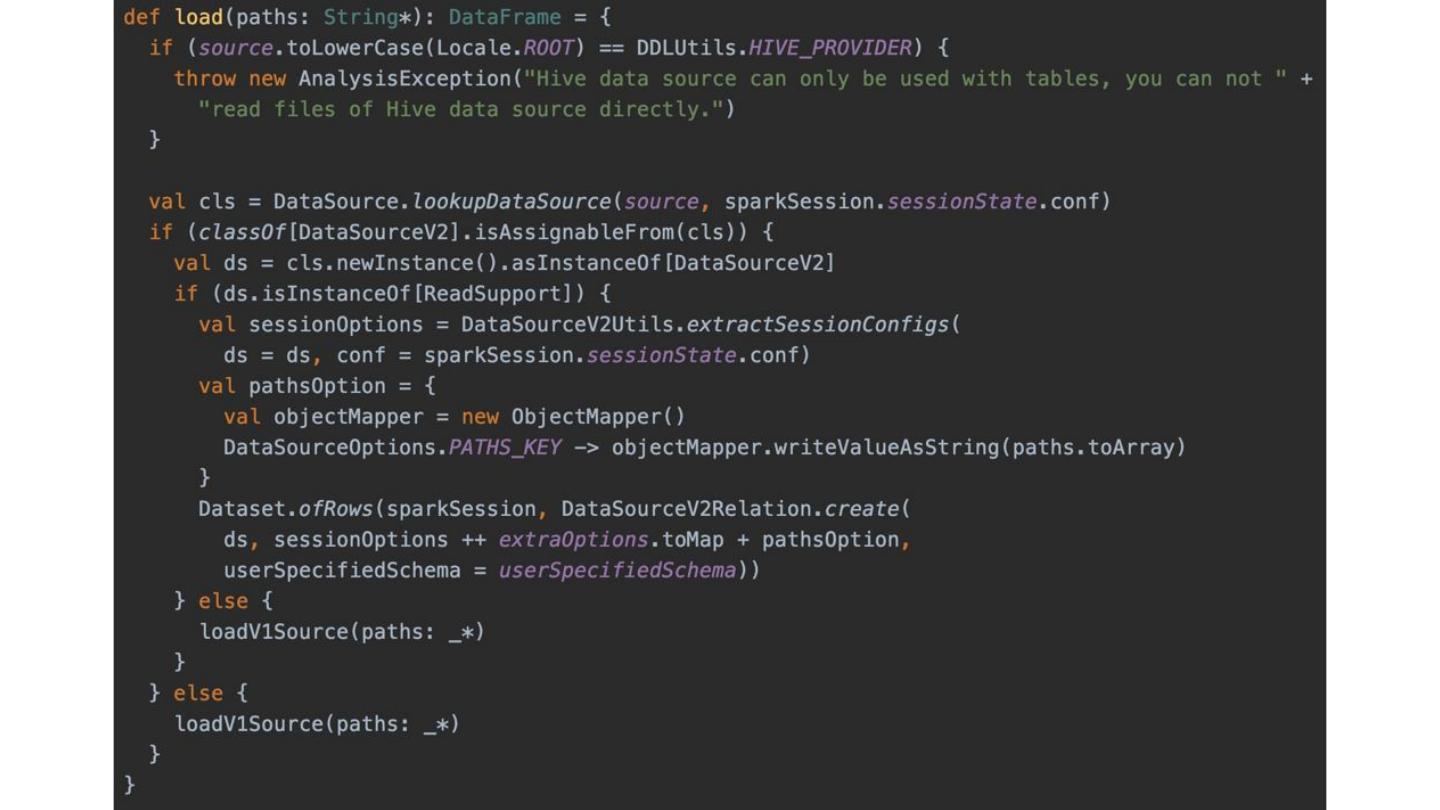
1. DataSource.lookupDataS
ource
2. DataSourceV2
3. ReadSupport
4. DataSourceV2Relation
5. loadV1Source
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
10 .loadV1Source = DataSource.resolveRelation
1. loadV1Source loads a DataSource API V1 data source
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
11 .Data Source API
1. DataSourceRegister
2. 👉 Data Source API V1
3. 👉 Data Source API V2
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
12 .Friendly reminders
1. Pictures...take a lot of pictures! 📷
2. It should be a live coding, shouldn’t it? 🤔
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
13 .Data Source API V1
1. DataSourceRegister
a. SchemaRelationProvider
b. RelationProvider
c. FileFormat
d. CreatableRelationProvider
2. BaseRelation
a. PrunedFilteredScan
b. InsertableRelation
c. PrunedScan
d. TableScan
e. CatalystScan
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
14 .Data Source API V2
1. DataSourceRegister
2. DataSourceV2
3. ReadSupport
4. WriteSupport
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�
15 .“The Internals Of” Online Books
1. The Internals of Spark SQL
2. The Internals of Spark Structured Streaming
3. The Internals of Apache Spark
�
16 .Questions?
1. Follow @jaceklaskowski on twitter (DMs open)
2. Upvote my questions and answers on StackOverflow
3. Contact me at jacek@japila.pl
4. Connect with me at LinkedIn
© Jacek Laskowski / @JacekLaskowski / jacek@japila.pl
�