展开查看详情
1 .Downscaling: The Achilles heel of
Autoscaling Apache Spark Clusters
Prakhar Jain
Venkata Sowrirajan
#UnifiedDataAnalytics #SparkAISummit
�
2 .Agenda
• Why Autoscaling on cloud?
• How nodes in spark cluster are used?
• Scale up easy, scale down difficult
• Optimizations
�
3 .Autoscaling on cloud
• Cloud for compute provides elasticity
– Launch nodes when required
– Take them away when you are done
– Pay-as-you-go model. No long term commitments.
• Autoscaling clusters are needed to use this elastic nature of the cloud
– Add nodes to the cluster when required
– Remove nodes from the cluster when the cluster utilization is low
• Use Cloud object stores to store the actual data and just use the
elastic clusters on the cloud for data processing/ML etc
�
4 .How are nodes used?
Nodes/Instances in a Spark cluster are used for
• Compute
– Executors are launched on these nodes which do the actual processing of Data
• Intermediate temporary data
– Nodes are also used as temporary storage e.g. for storing temporary application
related shuffle/cache data
– Writing temporary data to object store (like s3 etc) deteriorates the overall
performance of the application
�
5 .Upscale easy, downscale difficult
• Upscaling a cluster on cloud is easy
– When the workload on the cluster is high, simply add more nodes
– Can be achieved using simple Load balancer
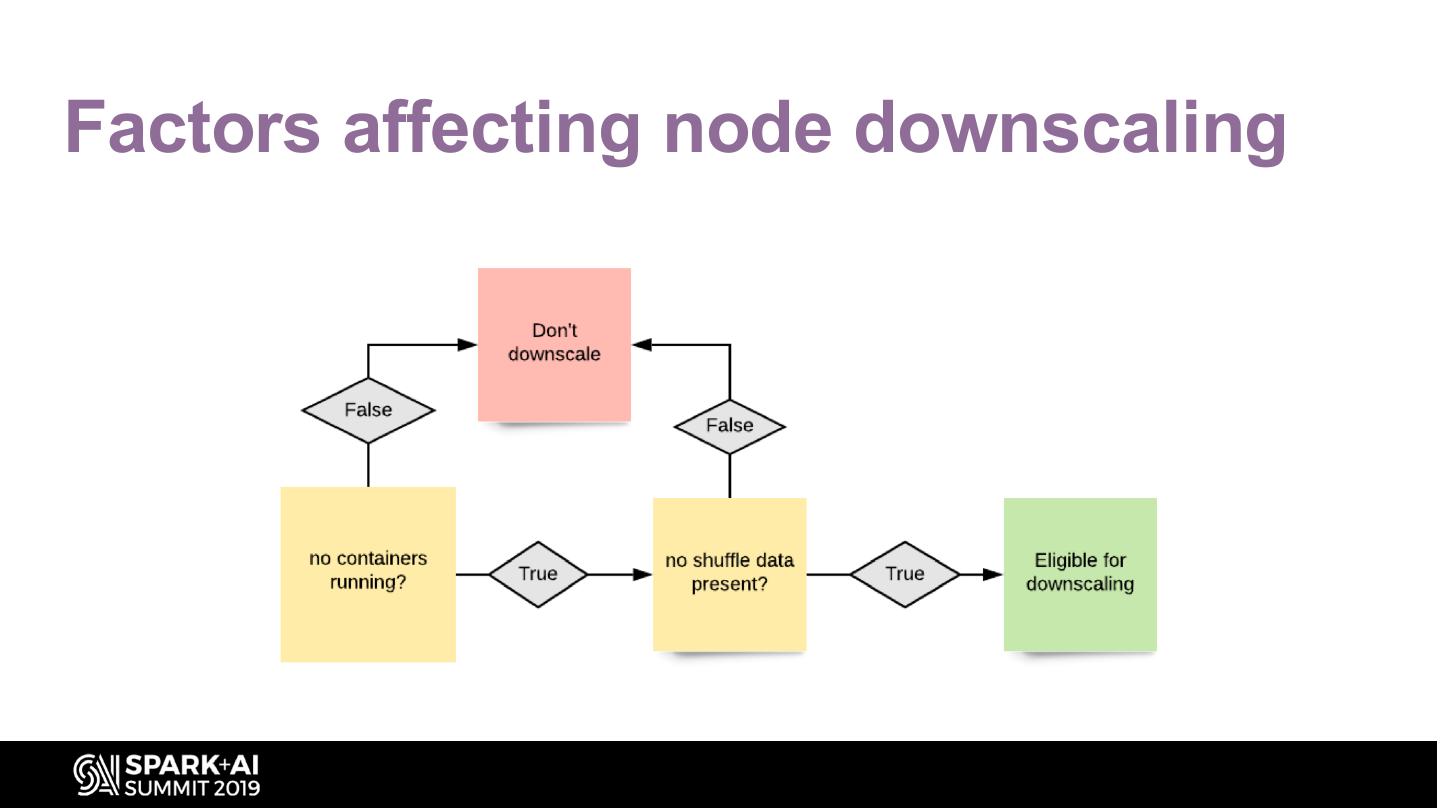
• Downscaling nodes are difficult
– No running containers
– No shuffle/cache data stored on disks
– Container fragmentation within cluster nodes
– Some nodes have no containers running but are used for storage and vice versa
�
6 .Factors affecting node downscaling
�
7 .Terminology
Any cluster generally comprises of following entities:
• Resource Manager
– Administrator for allocating and managing resources in a cluster. e.g.
YARN/Mesos etc
• Application Driver
– Brain of the application
– Interacts with Resource Scheduler and negotiates for resources
• Ask for executors when needed
• Release executors when not needed
– e.g. Spark/Tez/MR etc
• Executor
– Actual worker responsible for running smallest unit of execution - task
�
8 .Current resource allocation
strategy
1 2 3
Problem: Executors fragmentation
Current allocation strategy
allocates on emptier nodes first
Driver
�
9 .Can we improve?
● Packing of executors
�
10 . Priority in which jobs are allocated to nodes in Qubole Model
2 1 3
Low Usage Medium Usage High Usage
Jobs are prevented from
being assigned first to
low usage nodes, instead
priority is given to medium
usage nodes.This
ensures that low usage
nodes can be
downscaled.
Job n Job... Job 5 Job 4 Job 3 Job 2 Job 1
�
11 . Cost Savings 2 1 3
Terminated Low Usage Medium Usage High Usage
Nodes
In the meanwhile, once
the tasks in the low usage
nodes are completed, the
node is freed up for
termination.
Job 2 Job 1
Job 1 & 2 allocated to medium usage nodes and these
Job n Job... Job 5 Job 4 Job 3 nodes are moved into high usage category as the
utilization increases due to these new jobs
�
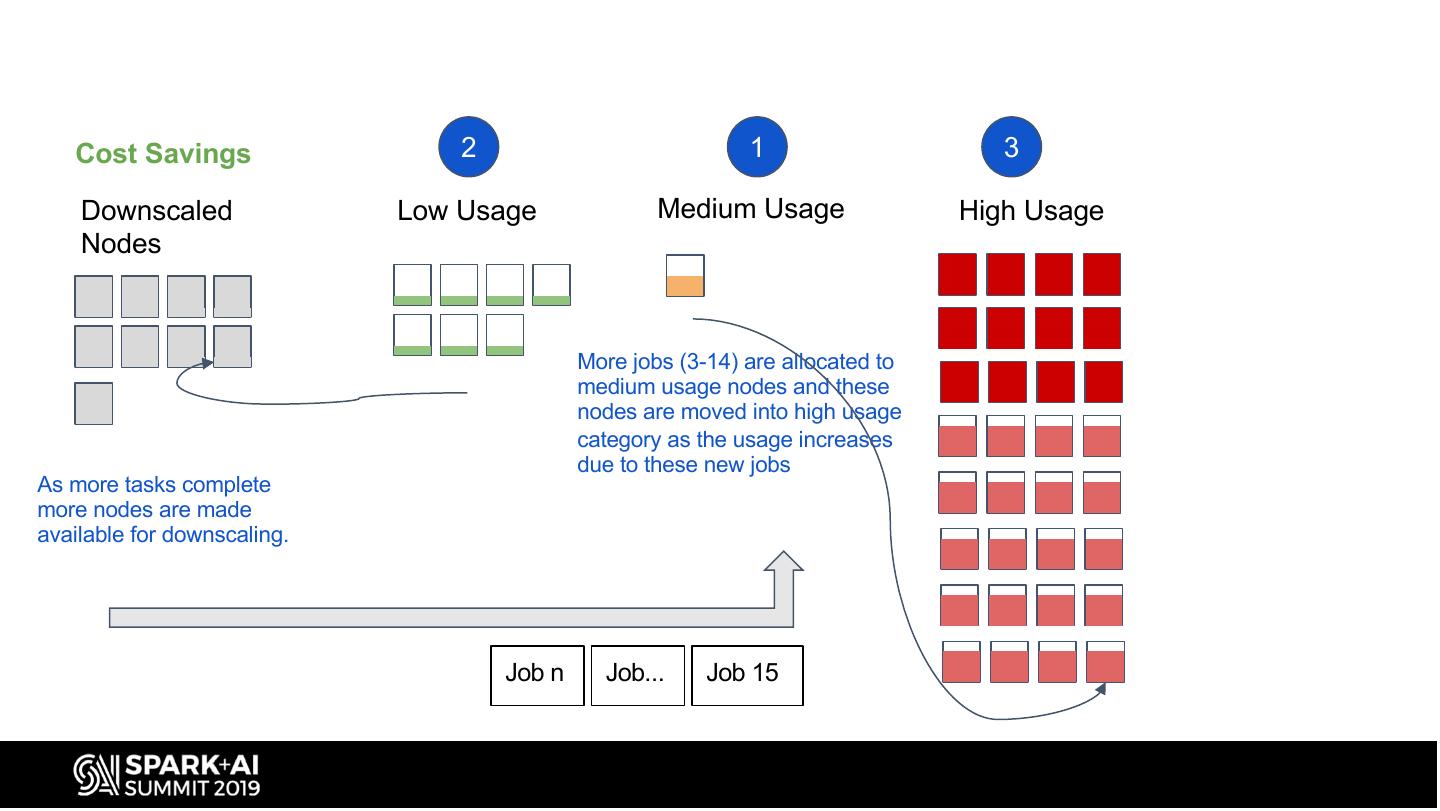
12 . Cost Savings 2 1 3
Downscaled Low Usage Medium Usage High Usage
Nodes
More jobs (3-14) are allocated to
medium usage nodes and these
nodes are moved into high usage
category as the usage increases
due to these new jobs
As more tasks complete
more nodes are made
available for downscaling.
Job n Job... Job 15
�
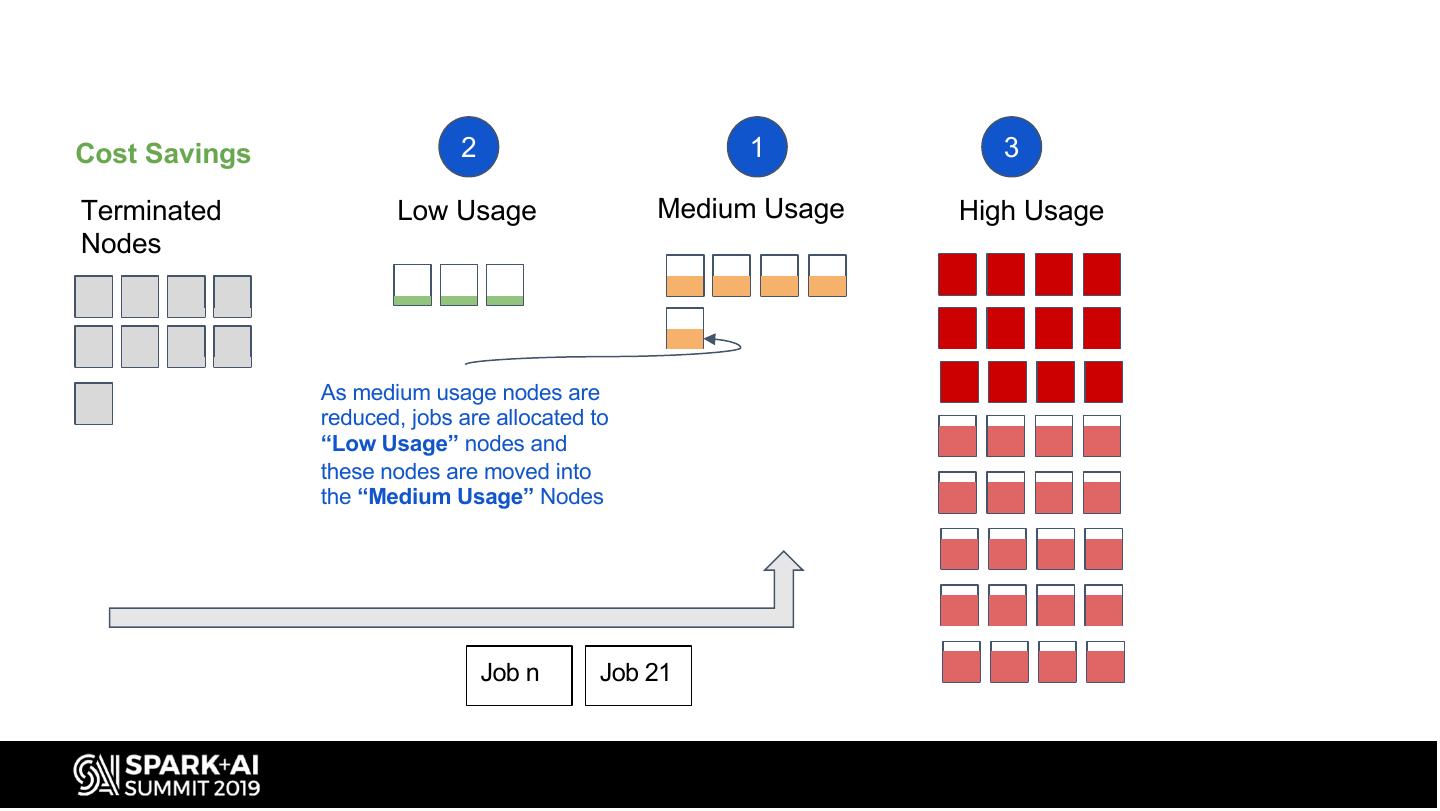
13 .Cost Savings 2 1 3
Terminated Low Usage Medium Usage High Usage
Nodes
As medium usage nodes are
reduced, jobs are allocated to
“Low Usage” nodes and
these nodes are moved into
the “Medium Usage” Nodes
Job n Job 21
�
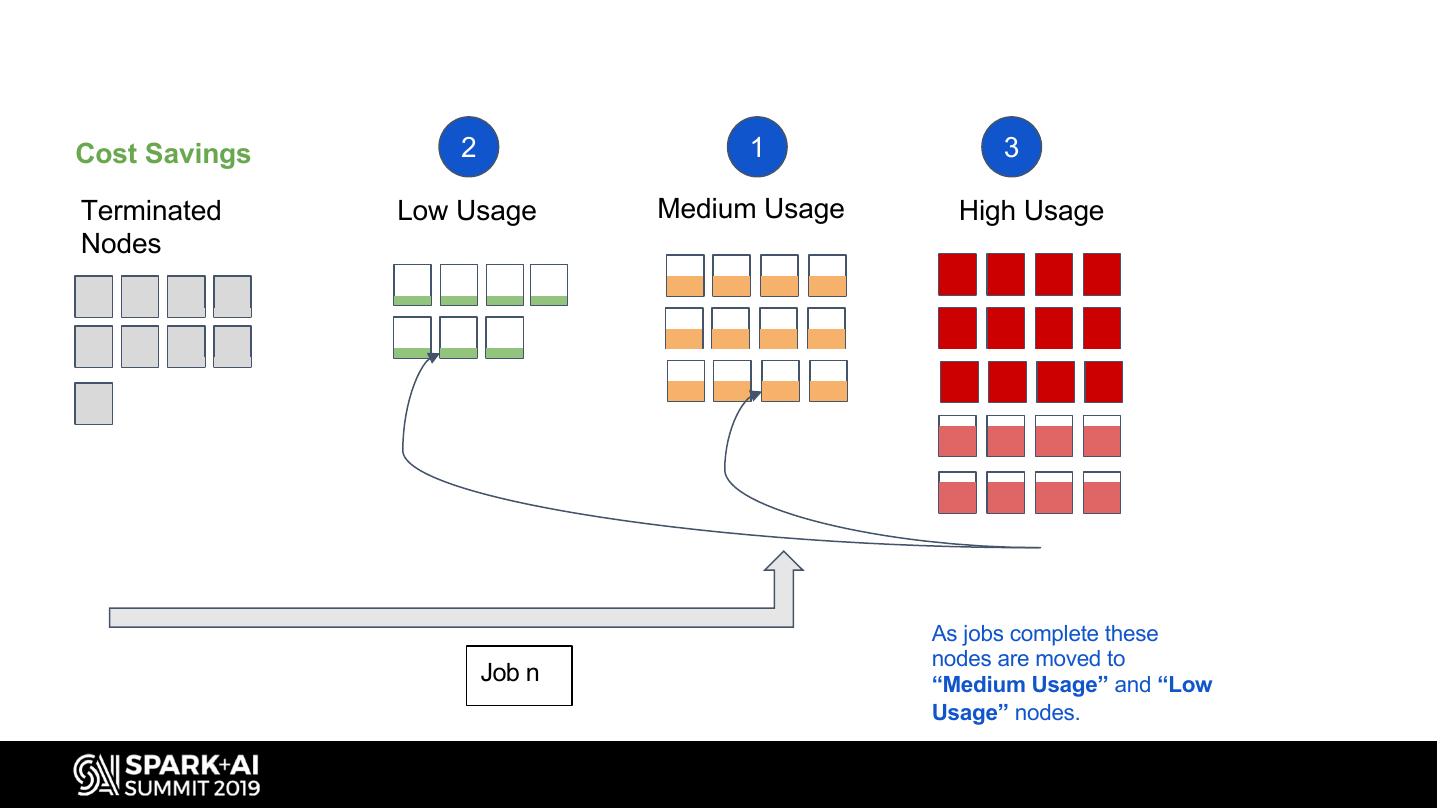
14 .Cost Savings 2 1 3
Terminated Low Usage Medium Usage High Usage
Nodes
As jobs complete these
nodes are moved to
Job n “Medium Usage” and “Low
Usage” nodes.
�
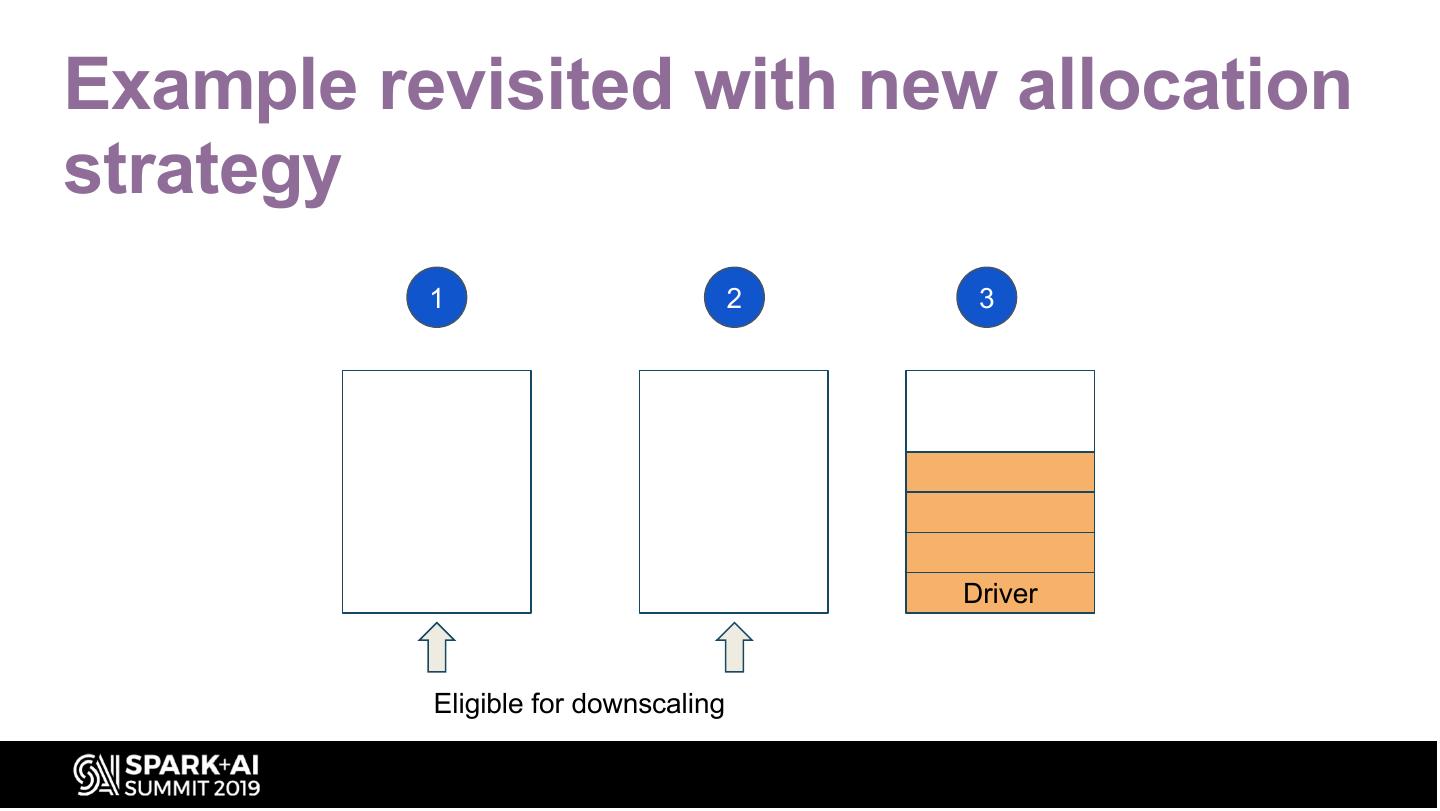
15 .Example revisited with new allocation
strategy
1 2 3
Driver
Eligible for downscaling
�
16 .#UnifiedDataAnalytics #SparkAISummit
#UnifiedDataAnalytics #SparkAISummit
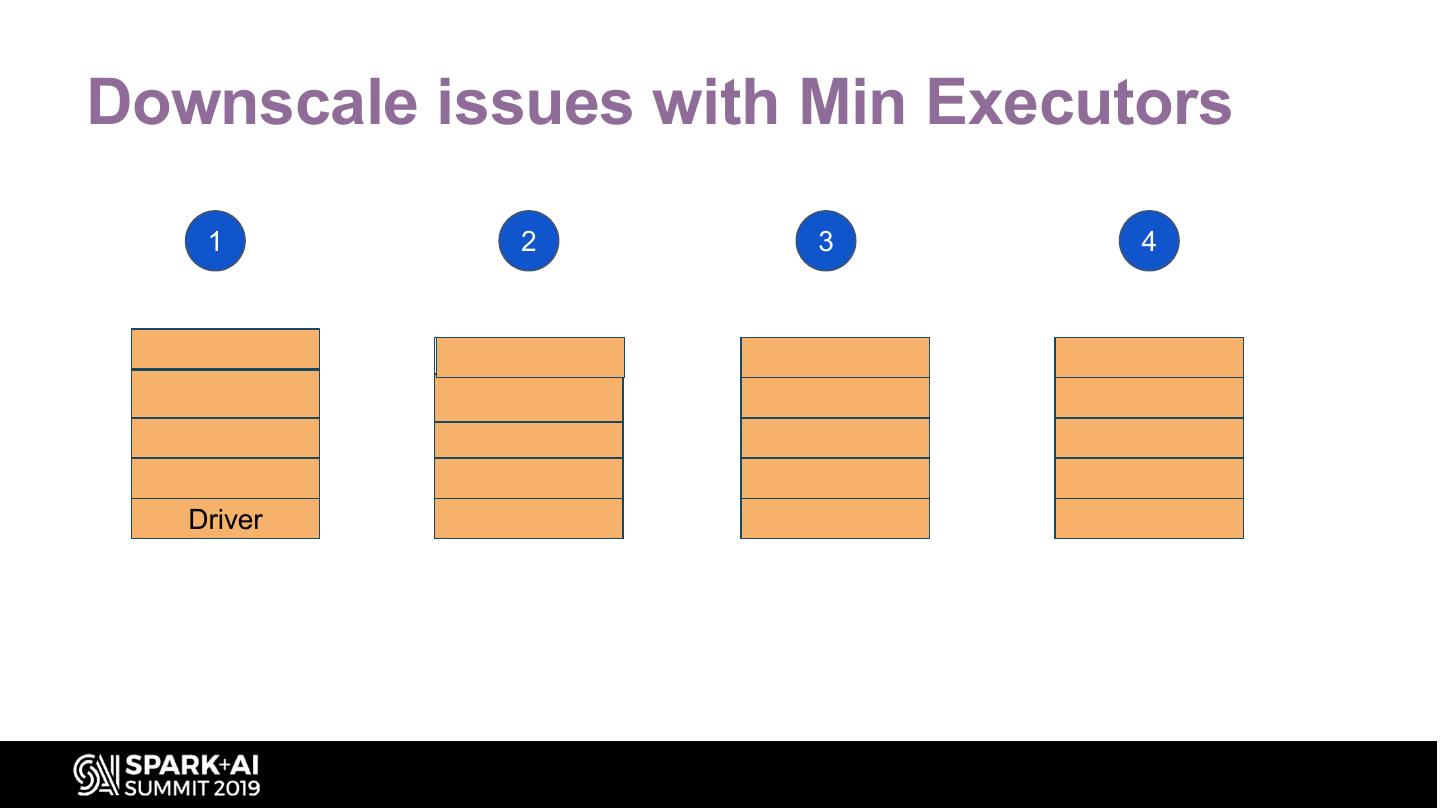
Downscale issues with Min Executors
1 2 3 4
Driver
�
17 .#UnifiedDataAnalytics #SparkAISummit
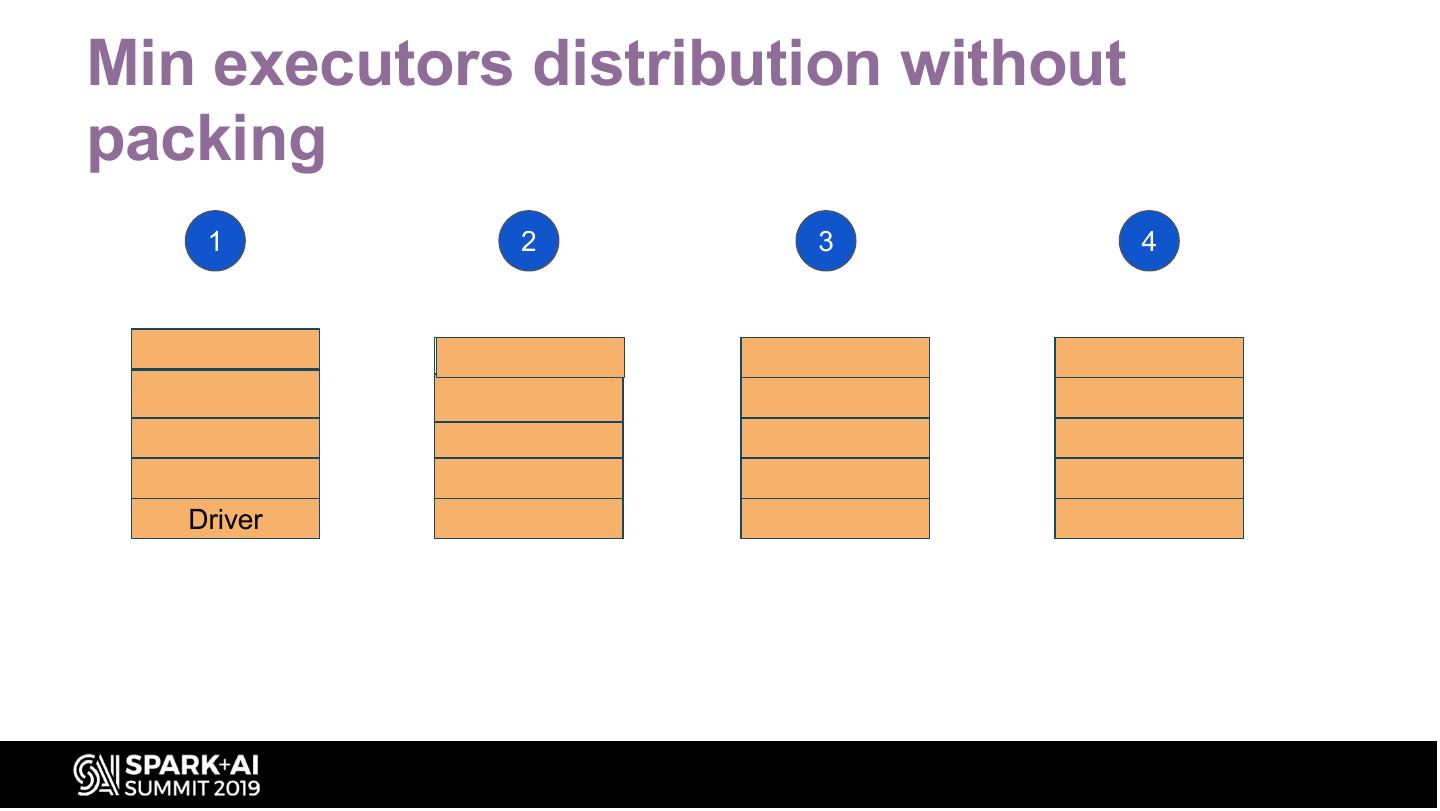
Min executors distribution without
#UnifiedDataAnalytics #SparkAISummit
packing
1 2 3 4
Driver
�
18 . Min executors distribution with packing
1 2 3 4
Driver
Rotate/refresh executors by killing them
and let resource scheduler do packing to
defragment the cluster
Nodes eligible for downscaling
�
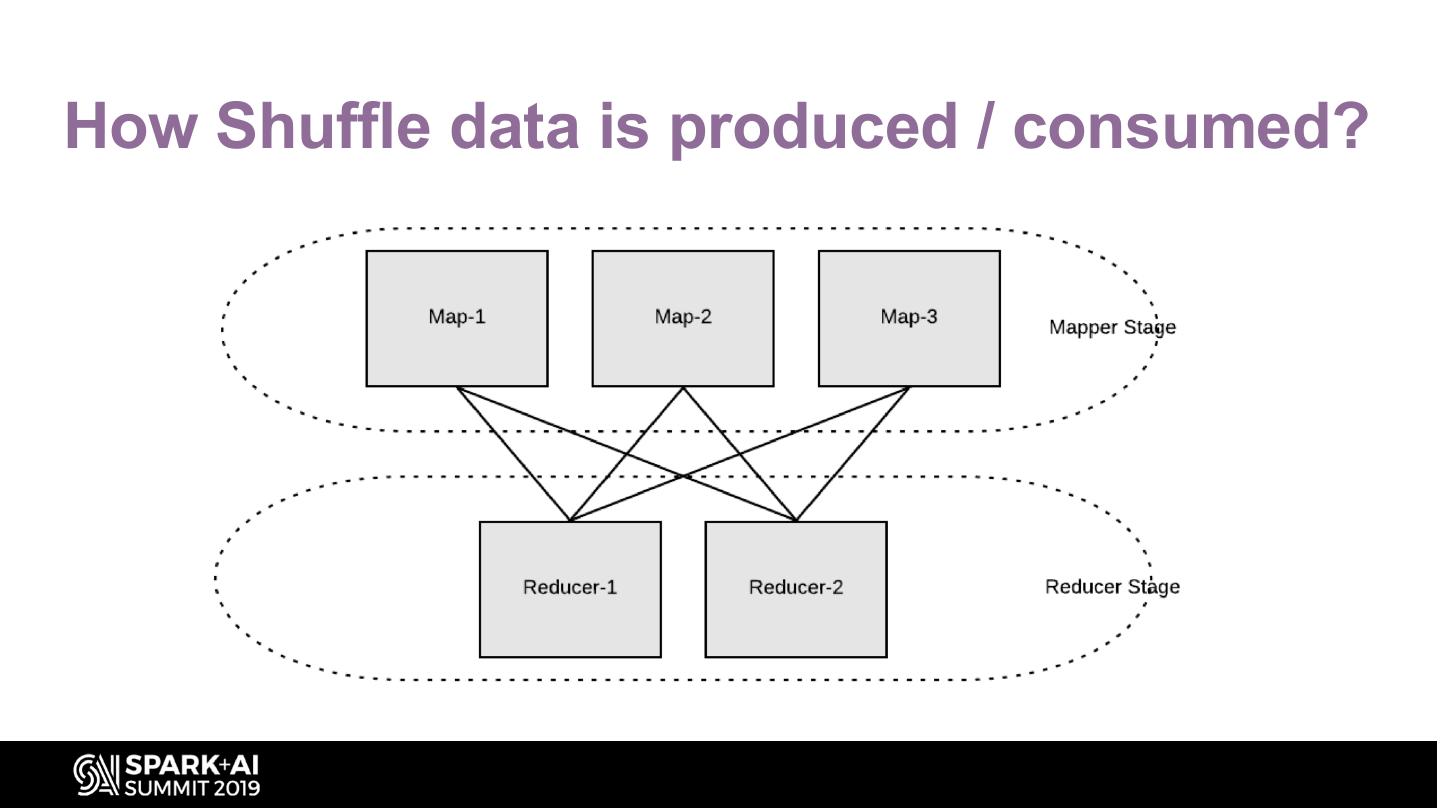
19 .How Shuffle data is produced / consumed?
�
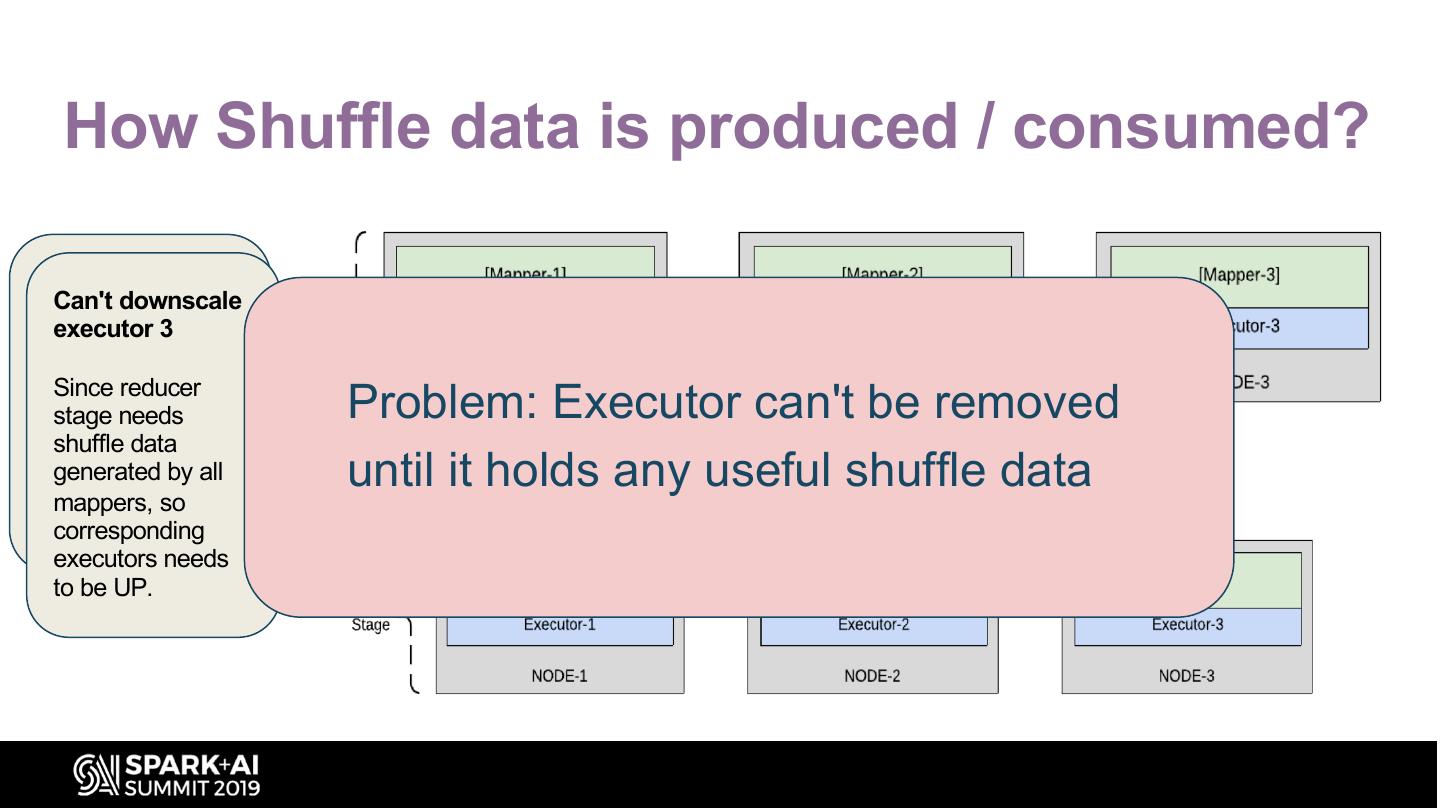
20 . How Shuffle data is produced / consumed?
Can't downscale
executor 3
Stage-1 (mapper
stage) with 3 tasks
Since reducer
----------
stage needs
Stage-2
Problem: Executor can't be removed
shuffle (reducer
data
stage) with 2by
generated tasks
all until it holds any useful shuffle data
mappers, so
corresponding
executors needs
to be UP.
�
21 .External Shuffle Service
• Root cause of problem: Executor which generated shuffle data is also
responsible for serving it. This ties shuffle data with executor
• Solution: Offload the responsibility of serving shuffle data to external
service
�
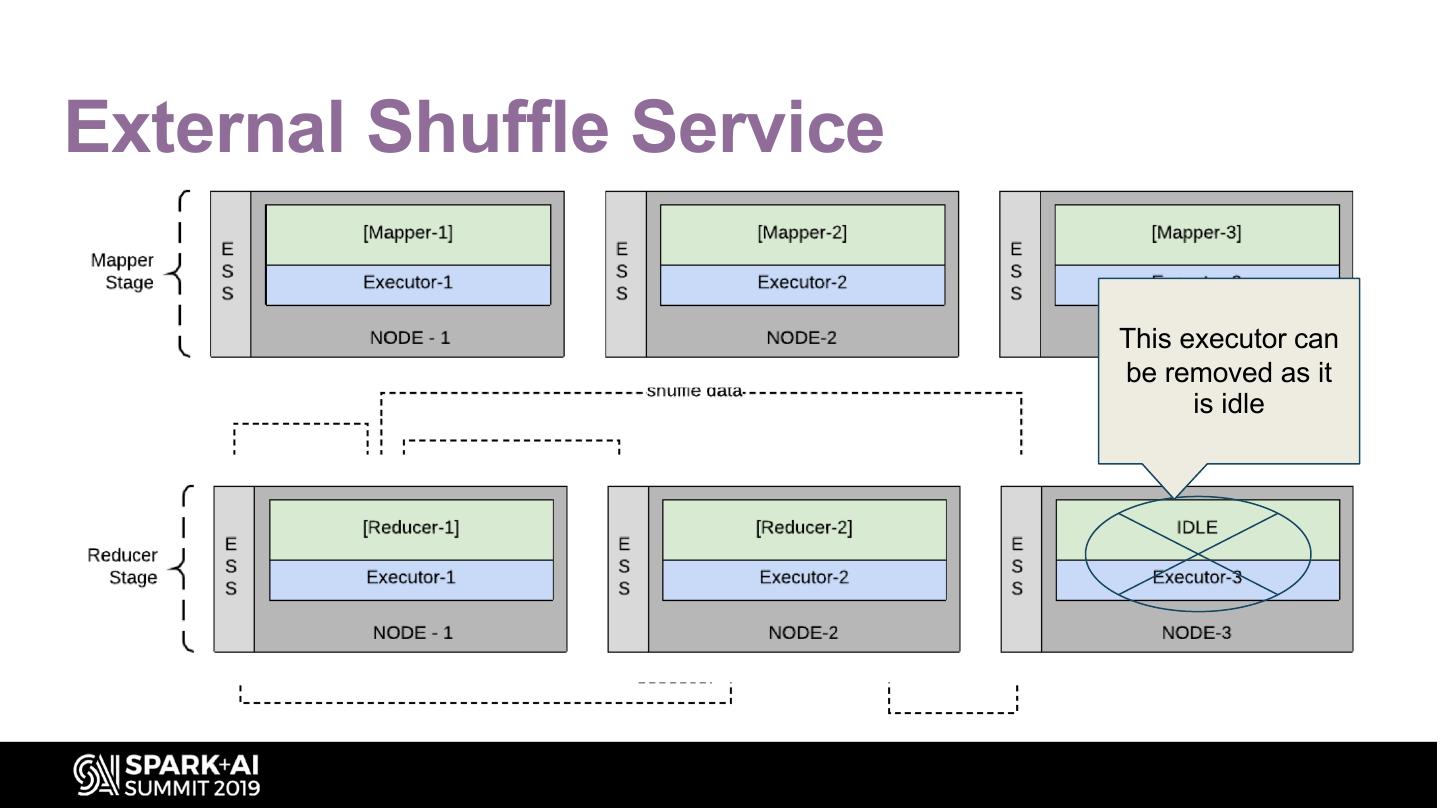
22 .External Shuffle Service
This executor can
be removed as it
is idle
�
23 .External Shuffle Service
• One ESS per node
– Responsible for serving shuffle data generated by any executor on that node
– Once the executor is idle, it can be taken away
• At Qubole:
– Once the node doesn't have any containers and ESS reports no shuffle data =>
node is downscaled
�
24 .ESS at Qubole
• Also tracks information about presence of shuffle
data on the node
– This information is useful taking decision about node
downscaling
�
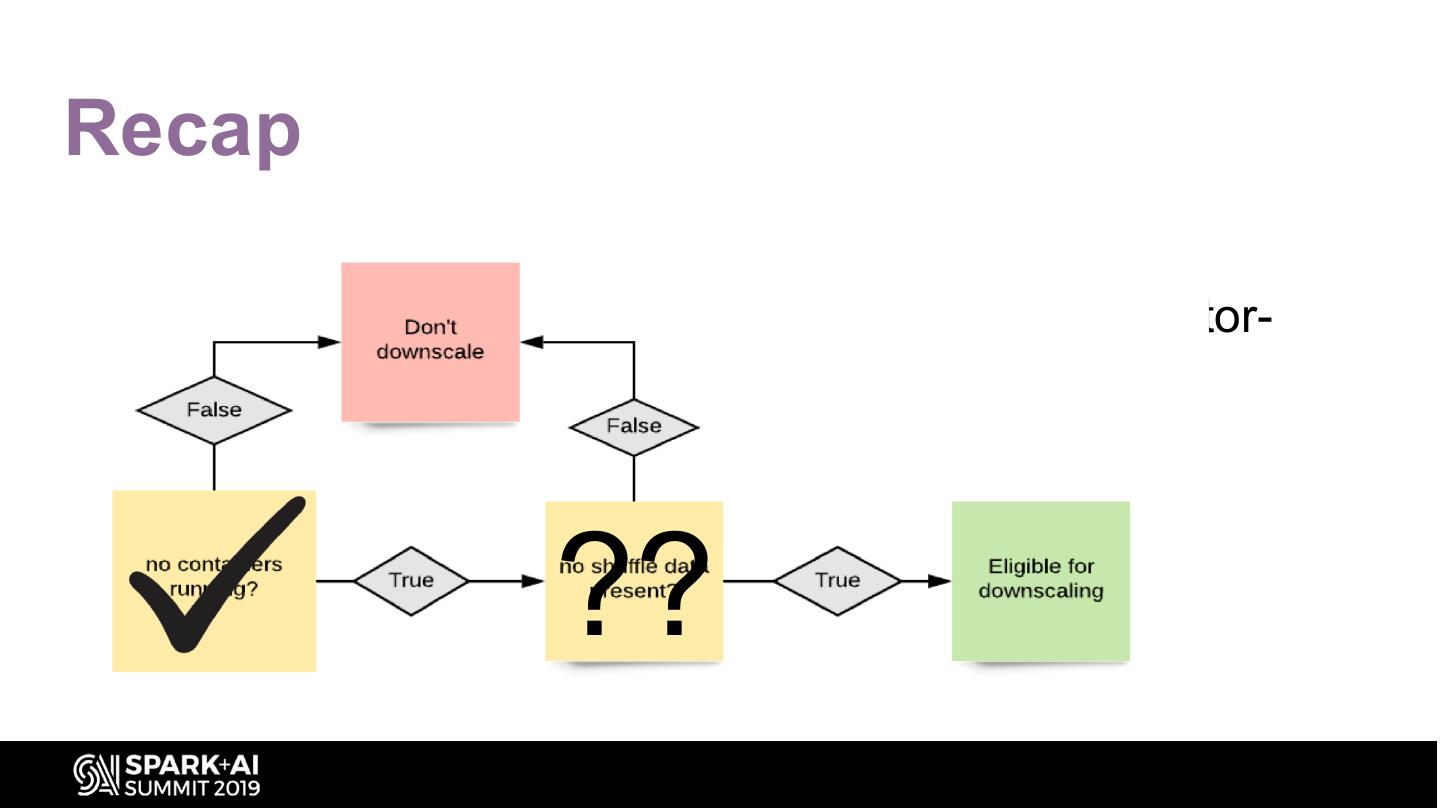
25 .Recap
• Till now we have seen
– How to schedule executors using YARN-executor-
packing scheduling strategy
– How to re-pack min executors
– How to use External shuffle service (ESS) to
??
downscale executors
• What about shuffle data?
�
26 .Shuffle Cleanup
• Shuffle data is deleted at the end of application by ESS
– In long running Spark applications (ex. interactive notebooks), it keeps on
accumulating
– Results in poor node downscaling
• Can it be deleted before end of application?
– What shuffle files are useful at a point of time?
�
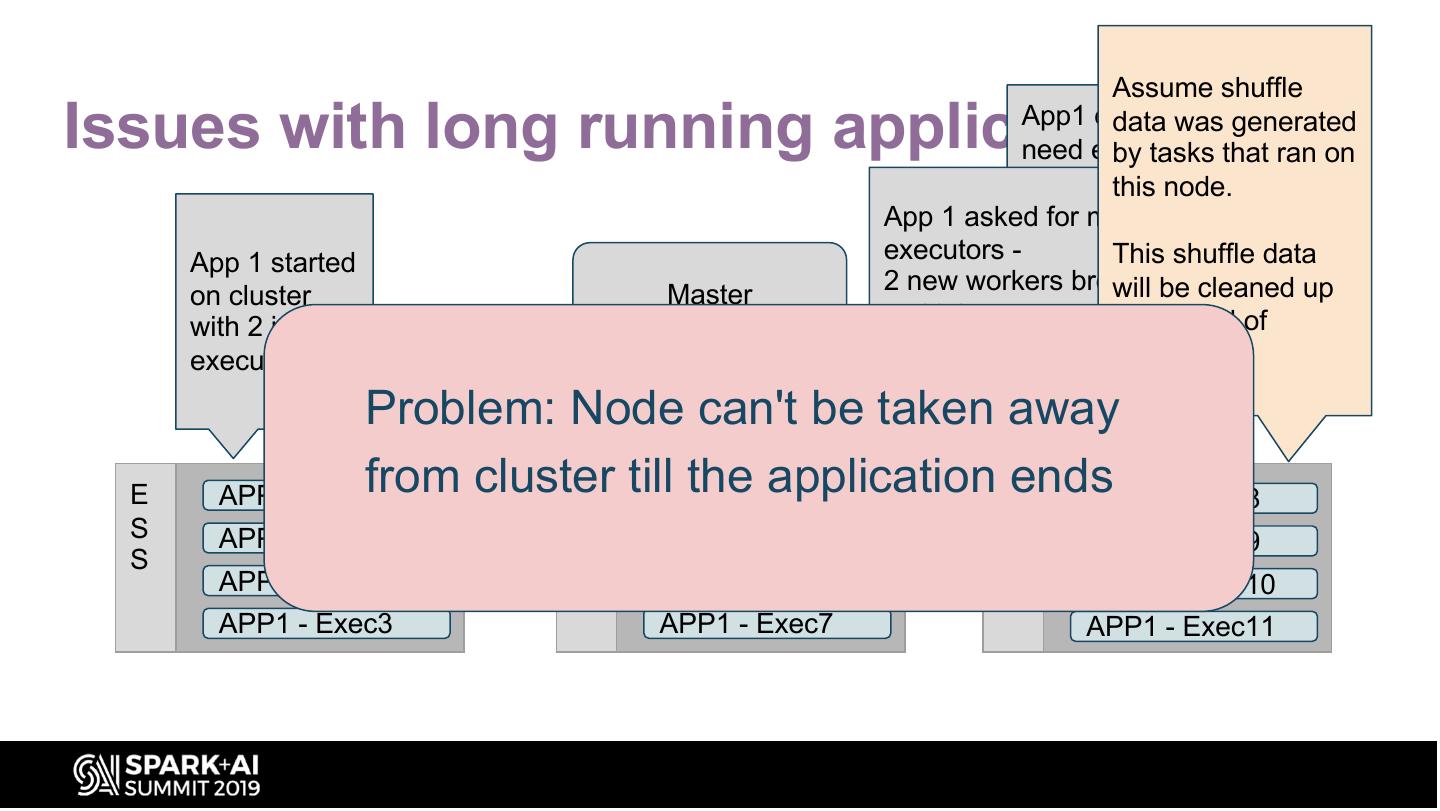
27 . Assume shuffle
Issues with long running applications App1 doesn't
data was generated
need extra
by tasks that ran on
executorsthis node.
App 1 askedanymore
for more-
App 1 started executors -downscaling
This shuffle data
2 new workers brought
everything upcleaned up
will other
be
on cluster Master
with 2 initial multiple new executors
than at theadded
min end of
executors executors (say
application.
2)
Problem: Node can't be taken away
E from cluster
APP1 - Driver E till the- Exec4
APP1 applicationEends
APP1 - Exec8
S APP1 - Exec1 S APP1 - Exec5 S APP1 - Exec9
S S S
APP1 - Exec2 APP1 - Exec6 APP1 - Exec10
APP1 - Exec3 APP1 - Exec7 APP1 - Exec11
�
28 .Shuffle reuse in Spark
Skipped
�
29 .Shuffle Cleanup
• Dataframe goes out of scope => shuffle data cannot be accessed
anymore
– Delete shuffle files when that dataframe goes out of scope
• Helps us in downscaling by making sure that unnecessary shuffle
data is deleted
– Saw 30-40% downscaling improvements
• SPARK-4287
�