展开查看详情
1 .Distributed Models Over Distributed Data
with MLflow, Pyspark, and Pandas
Thunder Shiviah
thunder@databricks.com
Senior Solutions Architect, Databricks
SAIS EUROPE - 2019
�
2 .Abstract
● More data often improves DL models in high variance problem spaces (with semi or
unstructured data) such as NLP, image, video but does not significantly improve high
bias problem spaces where traditional ML is more appropriate.
● That said, in the limits of more data, there still not a reason to go distributed if you
can instead use transfer learning.
● Data scientists have pain points
○ running many models in parallel
○ automating the experimental set up
○ Getting others (especially analysts) within an organization to use their models
● Databricks solves these problems using pandas udfs, ml runtime and mlflow.
�
3 .Why do single node data science?
�
4 .Is more data always better?
The Unreasonable Effectiveness of Data, Alon Halevy, Peter Norvig, and Fernando Pereira,
Google 2009
�
6 .Team A came up with a very sophisticated algorithm using the Netflix
data. Team B used a very simple algorithm, but they added in
additional data beyond the Netflix set: information about movie genres
from the Internet Movie Database (IMDB). Guess which team did
better?
Team B got much better results, close to the best results on the Netflix
leaderboard! I'm really happy for them, and they're going to tune their
algorithm and take a crack at the grand prize.
But the bigger point is, adding more, independent data usually
beats out designing ever-better algorithms to analyze an existing
data set. I'm often surprised that many people in the business, and
even in academia, don't realize this. - "More data usually beats better algorithms", Anand
Rajaraman
�
7 .Okay, case closed. Right?
�
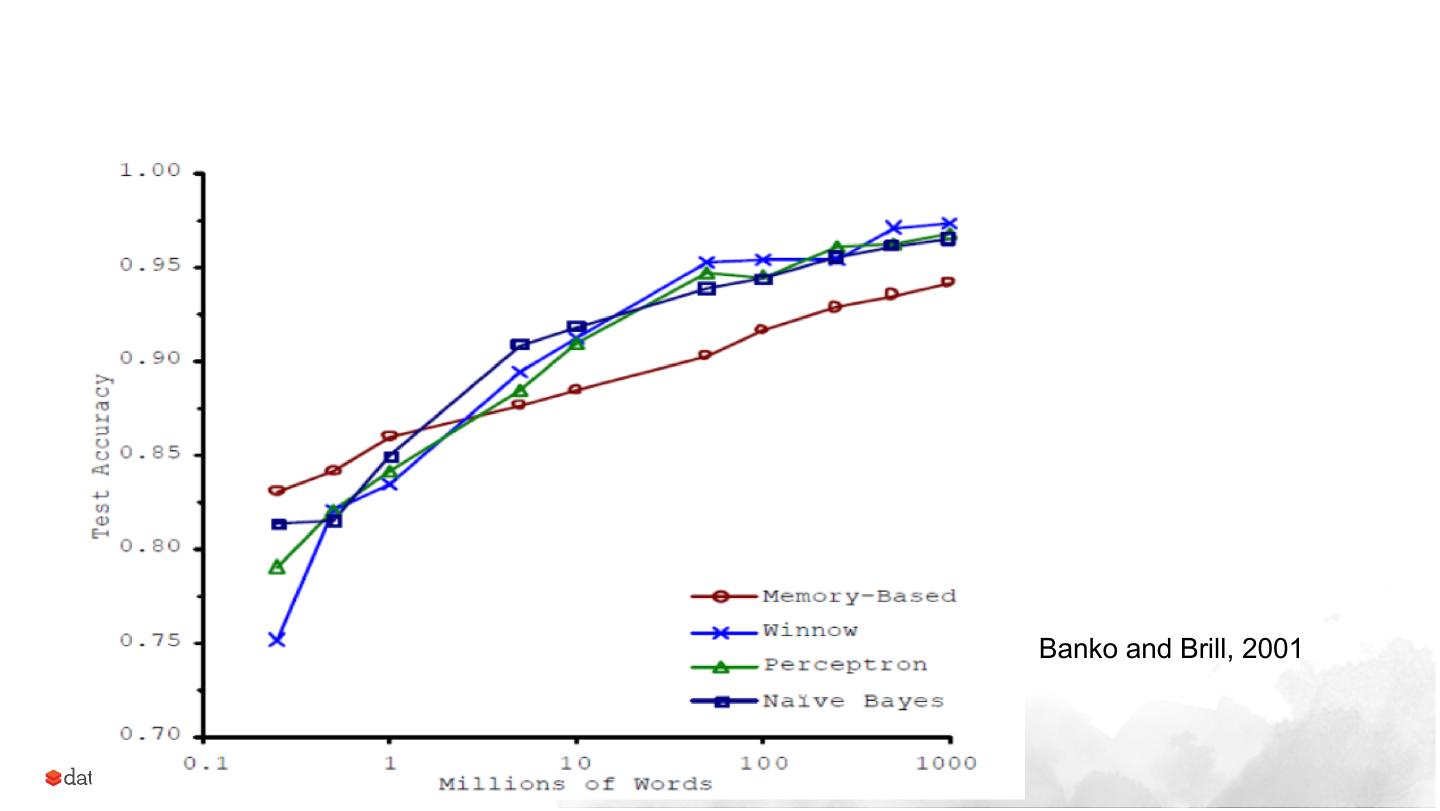
9 .● First Norvig, Banko & Brill were focused on NLP specifically, not general ML.
● Second, Norvig et al were not saying that ML models trained on more data are better
than ML models trained on less data. Norvig was comparing ML (statistical
learning) to hand coded language rules in NLP: “...a deep approach that relies on
hand-coded grammars and ontologies, represented as complex networks of relations;”
(Norvig, 2009)
● In his 2010 UBC Department of Computer Science's Distinguished Lecture Series
talk, Norvig mentions that regarding NLP, google is quickly hitting their limits
with simple models and is needing to focus on more complex models (deep
learning).
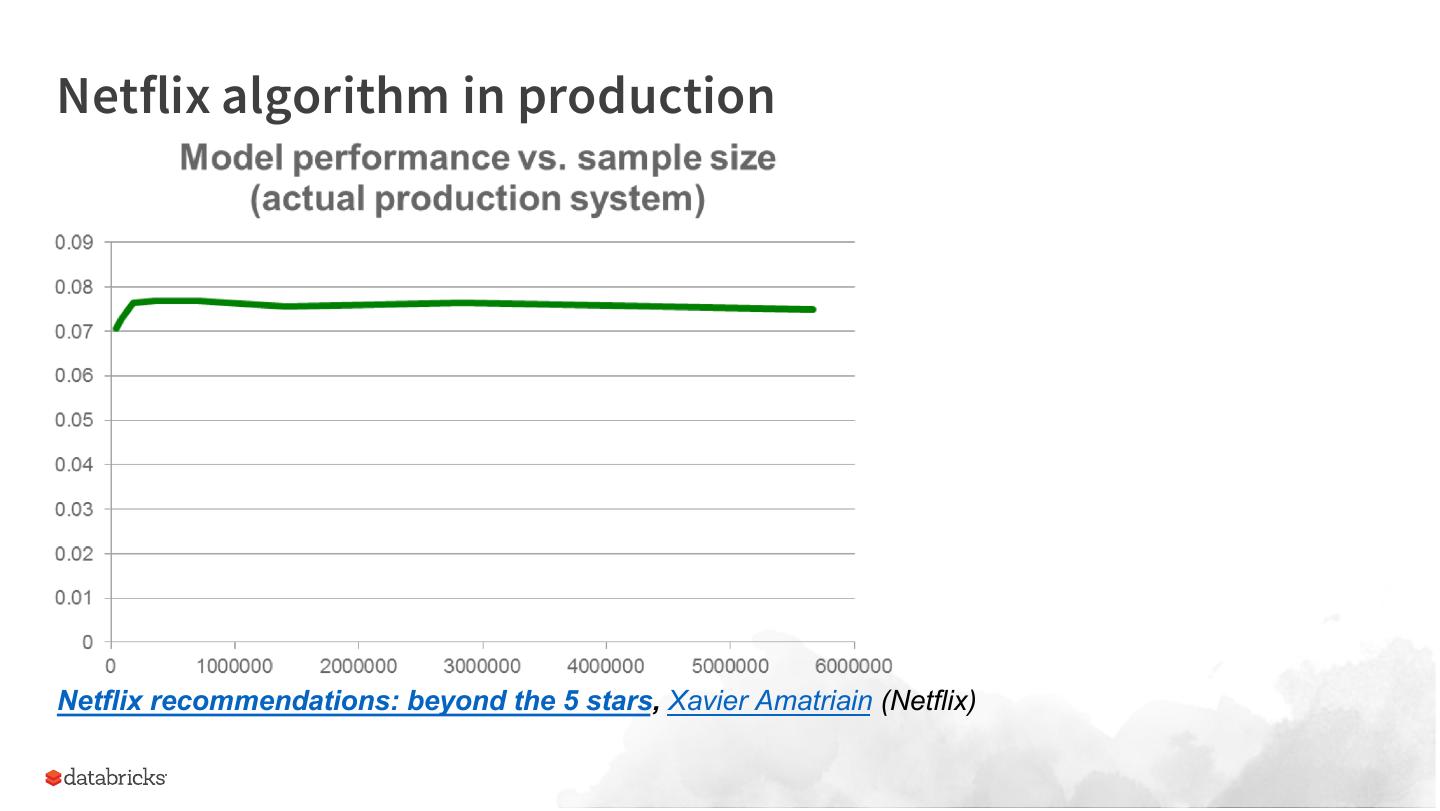
● Re: the Netflix data set: The winning team actually then commented and said
Our experience with the Netflix data is different.
IMDB data and the likes gives more information only about the movies, not about the users ... The test set is
dominated by heavily rated movies (but by sparsely rating users), thus we don't really need this extra
information about the movies.
Our experiments clearly show that once you have strong CF models, such extra data is redundant
and cannot improve accuracy on the Netflix dataset.
�
10 .Netflix algorithm in production
Netflix recommendations: beyond the 5 stars, Xavier Amatriain (Netflix)
�
11 .Oh, and what about the size of those data sets?
● 1 billion word corpus = ~2GB
● Netflix prize data = 700Mb compressed
○ 1.5 GB uncompressed (source)
�
12 .So where does that leave us?
�
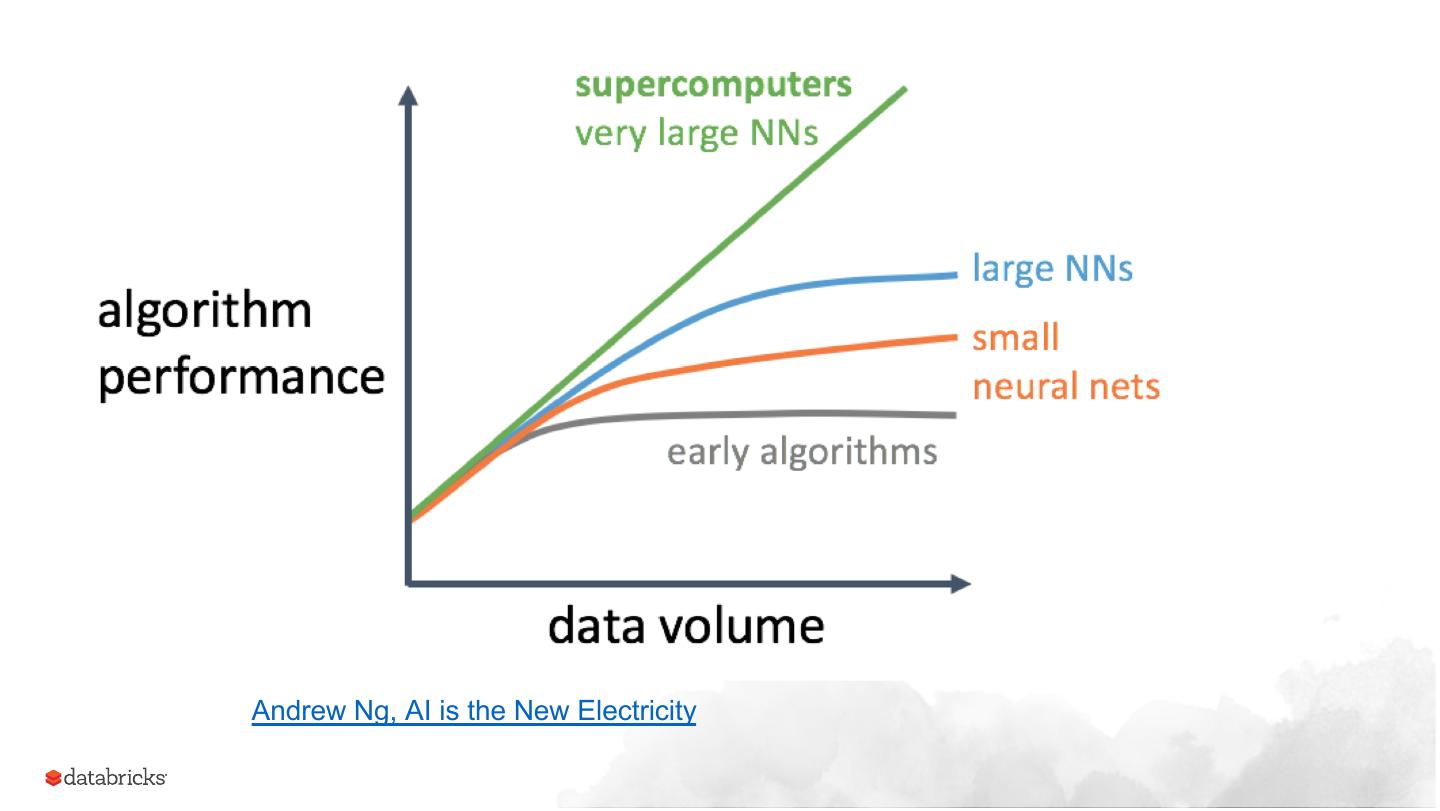
15 .Andrew Ng, AI is the New Electricity
�
16 .Conclusion: more data makes sense for high variance
(semi-structured or unstructured) problem domains like
text and images. Sampling makes sense for high bias
domains such as structured problem domains.
�
17 .Should we always use more data with deep learning?
�
18 .No! Transfer learning on smaller data often beats
training nets from scratch on larger data-sets.
Open AI pointed out that while the amount of compute has been a key component of AI
progress, “Massive compute is certainly not a requirement to produce important results.”
(source)
�
19 .In a benchmark run by our very own Matei Zaharia at Stanford, Fast.ai was able to win both
fastest and cheapest image classification:
Imagenet competition, our results were:
● Fastest on publicly available infrastructure, fastest on GPUs, and fastest on a single
machine (and faster than Intel’s entry that used a cluster of 128 machines!)
● Lowest actual cost (although DAWNBench’s official results didn’t use our actual cost,
as discussed below).Overall, our findings were:
● Algorithmic creativity is more important than bare-metal performance
(source)
�
20 .Transfer learning models with a small number of training examples can achieve better
performance than models trained from scratch on 100x the data
Introducing state of the art text classification with universal language models,
Jeremy Howard and Sebastian Ruder
�
21 .Take-away: Even in the case of deep learning, if an
established model exists, it’s better to use transfer
learning on small data then train from scratch on larger
data
�
22 .So where does databricks fit into this story?
�
23 .Training models (including hyperparameter search and
cross validation) is embarrassingly parallel
�
24 .Shift from distributed data to distributed models
Introducing Pandas UDF for PySpark: How to run your native Python code with PySpark, fast.
�
25 .Data Scientists spend lots of time setting up their
environment
�
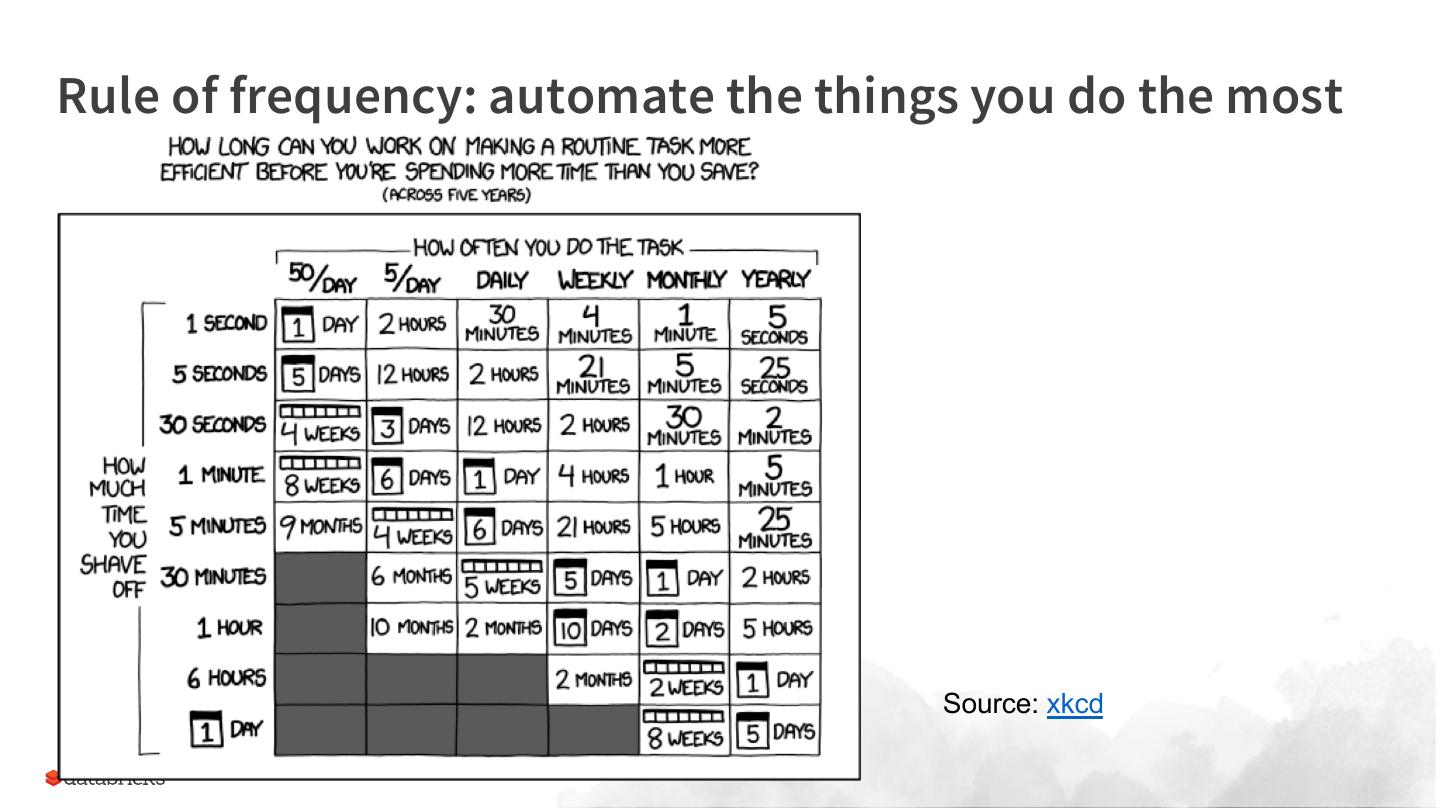
26 .Rule of frequency: automate the things you do the most
Source: xkcd
�
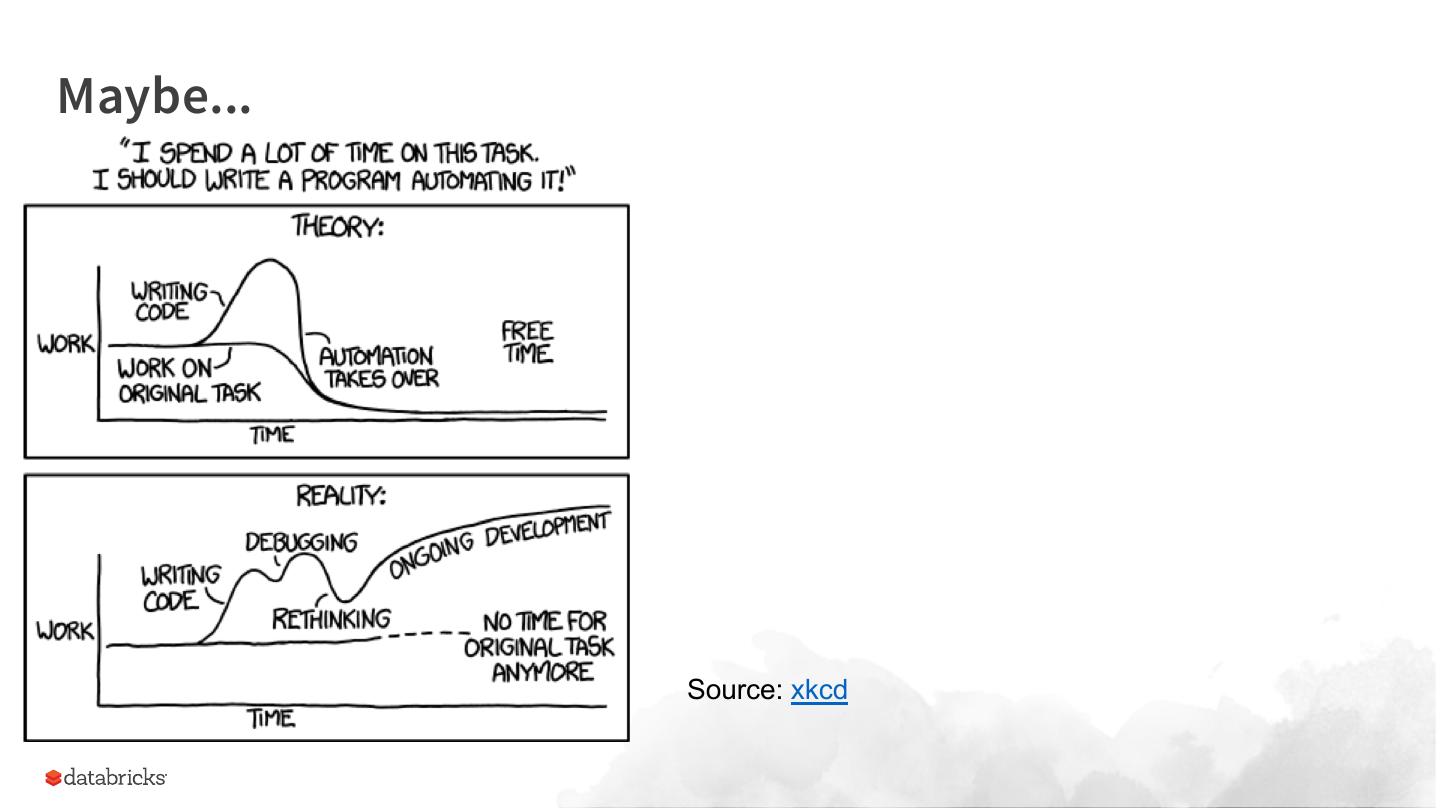
27 .Maybe...
Source: xkcd
�
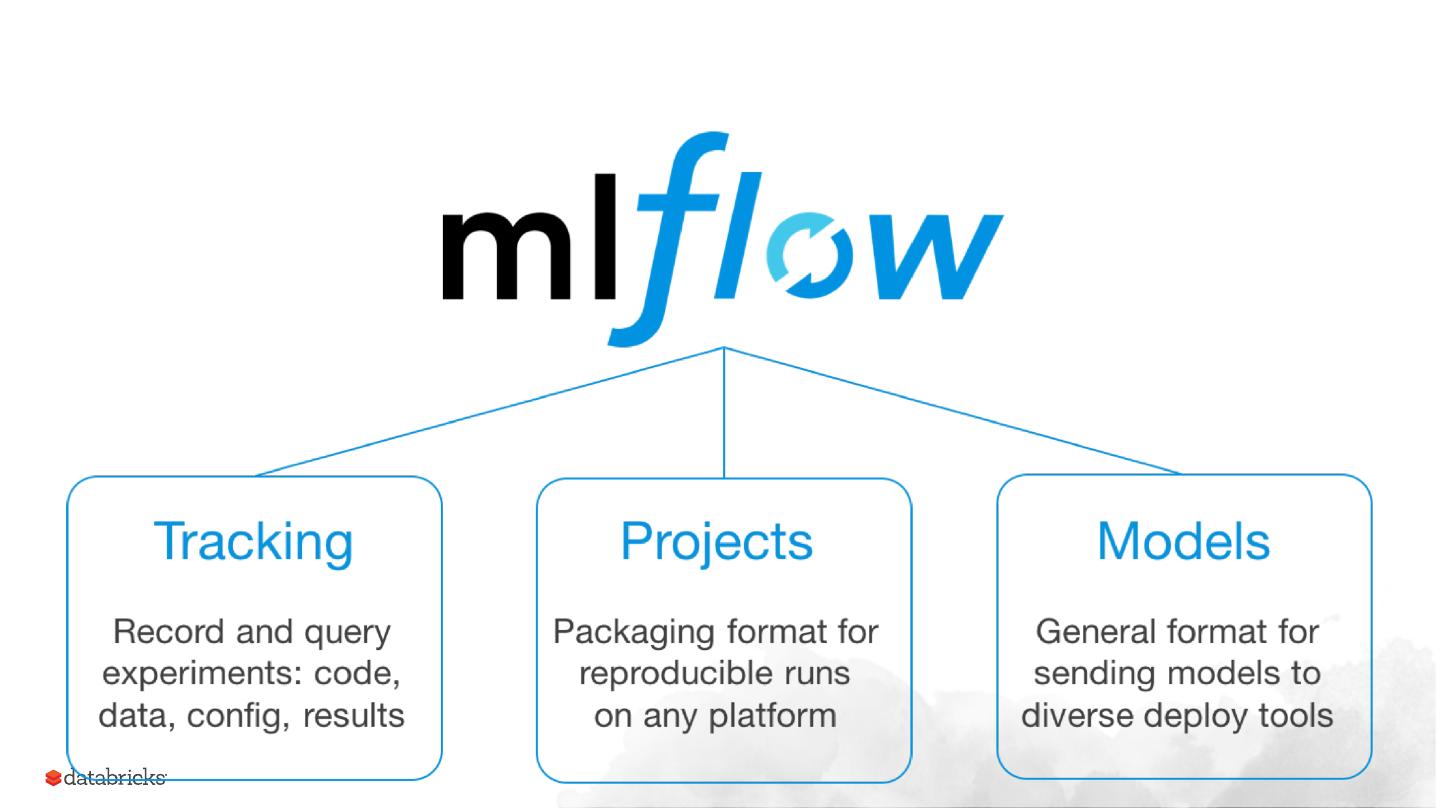
29 .Data Scientists have a difficult time tracking models
�